文章目录
@[TOC] 一:整体的优化思路二:优化思路流程1:sql 优化 嗯哼 优化什么 sql吗? 哪来的sql 呀2:那么一条sql语句查询慢了的话 我们应该回顾 该sql的 执行历程 分析可优化的部分3:从客户端发送sql 到连接器4查询缓存5:词法分析跟语法分析6:预处理器7:优化器(1):优化索引(2):合理使用索引 8:其他优化
一:整体的优化思路
定位查询慢的sql回顾一条sql的查询历程分析在查询的历程当中 我们可以优化的部分二:优化思路流程
1:sql 优化 嗯哼 优化什么 sql吗? 哪来的sql 呀
所有第一步我们需要先定位出 查询比较慢的sql 然后的话 我们将其单拎出来 进行优化
打开慢查询日志更开慢查询日志中的的 默认限制时间 (就是当我们查询时间超过一个值得时候 该日志就会被记录下来该sql语句)找到慢查询的sql2:那么一条sql语句查询慢了的话 我们应该回顾 该sql的 执行历程 分析可优化的部分
那么我们应该 回顾一下 我们的sql select历程
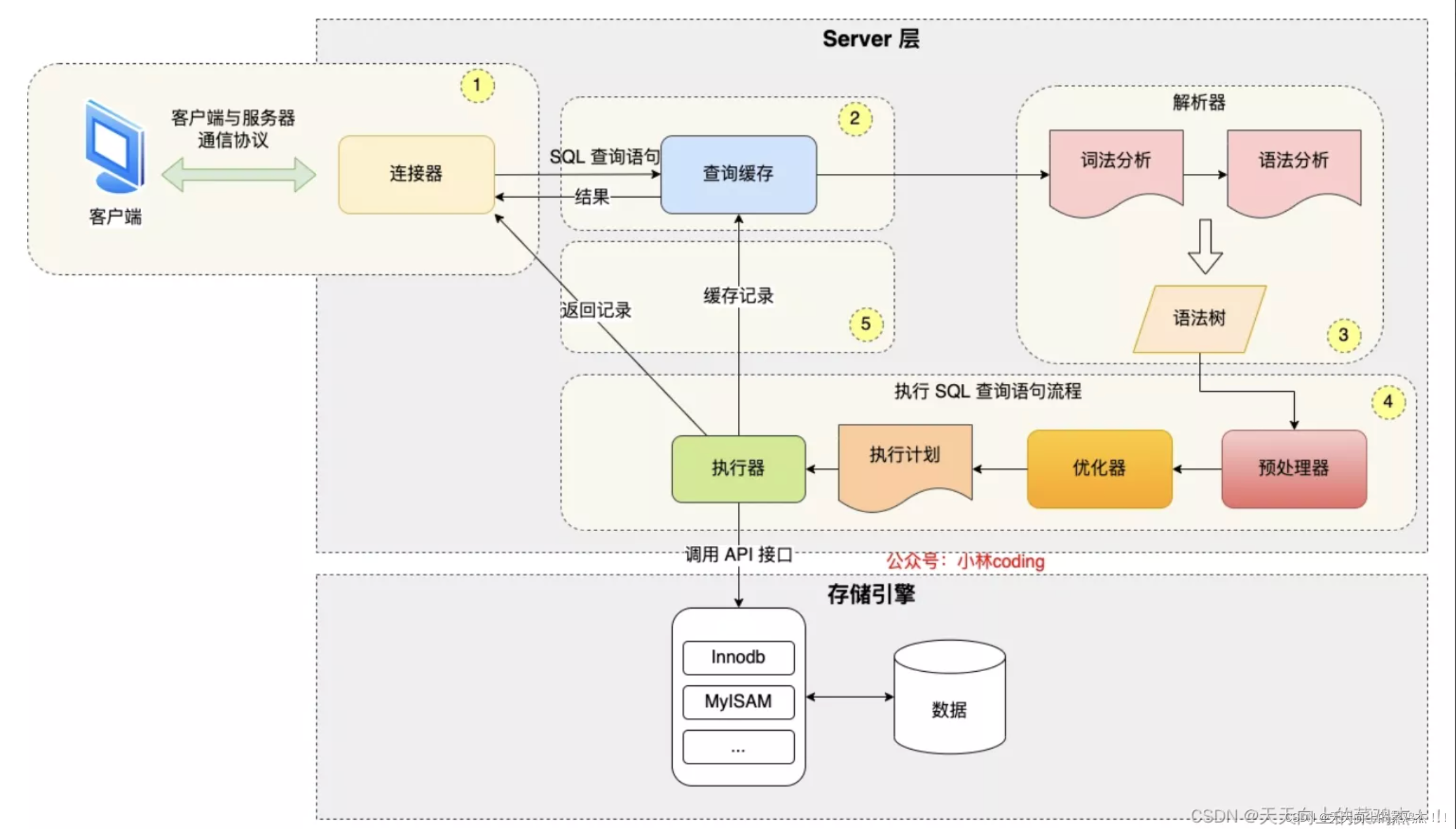
3:从客户端发送sql 到连接器
这个阶段是没有什么可优化的
4查询缓存
这个过程在mysql8.0已经取消了 为甚取消了呢 因为在我们读写操作比较多的时候 这个缓存需要频繁的更新 那么我们还没有用到这个缓存 他就已经更新了
根据实际情景 如果我们的数据库是读写比较多的话 那么我们可以在相关配置文件中关掉这个 缓存 这样可以适当提高我们查询速度5:词法分析跟语法分析
在这里的话 ,如果我们的sql又臭又长的话 那么肯定是解析的比较慢的
每次执行SQL的时候都要建立网络连接、进行权限校验、进行SQL语句的查询优化、发送执行结果,这个过程是非常耗时的,因此应该尽量避免过多的执行SQL语句,能够压缩到一句SQL执行的语句就不要用多条来执行。6:预处理器
任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段
避免使用 select *如果只查询一行就使用 limit 17:优化器
优化器主要会在索引的选择上做出预判
(1):优化索引
避免在索引上进行计算在where字句中,如果索引列是计算或者函数的一部分,DBMS的优化器将不会使用索引而使用全表查询,函数
属于计算的一种同时在in和exists中通常情况下使用EXISTS,因为in不走索引 not in 也是
未优化的sql(主要就是优化 带有not in 的sql):SELECT id,name,email FROM customer WHERE id NOT IN(SELECT id FROM payment)优化完的sql:这就造成了会循环多次来查找子表来确认是否满足过滤条件,如果子查询恰好是一个很大的表的话,这样做的效率会非常低,所以我们在进行 SQL 开发时,最好把这类查询自行改写成关联查询。select a.id,a.name,a.email from customer a left join payment b where b.id = null;未优化的sql:select id from t where num is null;将其优化为:可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num = 0;(2):合理使用索引
在差别较大的列上建立索引(比如性别 sex 就不适合做索引)合理控制索引的数量对于唯一性校验的可以使用唯一索引、不要求数据唯一的使用普通索引8:其他优化
用union all替换union (但是得根据使用情景) 当SQL语句需要union两个查询结果集合时,即使检索结果中不会有重复的记录,如果使用union这两个结果集同样会尝试进行合并,然后在输出最终结果前进行排序,因此如果可以判断检索结果中不会有重复的记录时候,应该用union all,这样效率就会因此得到提高。数据结构优化:用varchar 代替 char