Keras深度学习实战(9)——卷积神经网络的局限性
0. 前言1. 卷积神经网络的局限性2. 情景1——训练数据集图像尺寸较大3. 情景2——训练数据集图像尺寸较小4. 情景3——在训练尺寸较大的图像时使用更大池化小结系列链接
0. 前言
在《卷积神经网络详解与实现》中,我们已经看到了卷积神经网络 (Convolutional Neural Network, CNN) 的强大性能。虽然卷积神经网络的局部连接、权值共享和层次化表达等特性保证了网络模型可以有效的从大量样本中学习到数据的相应特征、避免了复杂的特征提取过程,但与其它模型一样,卷积神经网络同样也具有一定的局限性,本节将通过一系列实战来介绍卷积神经网络的一些局限性。
1. 卷积神经网络的局限性
为了了解卷积神经网络的局限性,我们继续使用在《卷积神经网络实现性别分类》中进行的任务,即尝试识别给定的图像中的人物性别。在继续介绍之前,首先回顾下卷积神经网络预测图像中对象类别的简要流程:
不同卷积核通常可以识别由图像的不同部分: 例如,识别图像中的特定图案,鼻子、头发 池化层可以确保图像尺寸变换后也能被很好的识别: 在增加池化操作后,图像的尺寸会变小,希望被检测到的对象将只占图像的较小部分,便于后续识别 我们通常将经过卷积或池化后得到的输出特征称为特征图 (feature map)最终的展平层 (Flatten) 展平了通过各种卷积和池化操作提取的所有特征,并送入全连接层中进行分类 但如果训练数据集中的图像数量很少,模型将没有足够的数据量来训练神经网络模型。此外,考虑到卷积网络必须从头开始学习各种图像特征,如果训练数据集包含的图像尺寸较大,则模型可能需要训练更多的时间才能得到较好的准确率。为了证明以上猜想,接下来,我们将构建卷积神经网络对比以下场景:
数据集图像尺寸为256 x 256,模型训练 10 个 epoch数据集图像尺寸为 50 x 50,模型训练 10 个 epoch 为了同时验证数据量对模型的影响,我们只使用训练集中少量的图像 (1600 张图像),并测试使用不同尺寸图像训练的卷积神经网络模型的准确率。接下来,我们将对不同图像尺寸的数据集分别训练,第一种情况下的图像大小为 256 x 256,第二种情况下的图像大小为 50 x 50。
2. 情景1——训练数据集图像尺寸较大
首先,导入所需库并加载数据集。对于此分析,我们继续使用在《卷积神经网络实现性别分类》中使用的性别分类数据集,准备输入和输出数据:
import numpy as npfrom skimage import iofrom glob import globfrom matplotlib import pyplot as pltimport cv2x = []y = []for i in glob('man_woman/a_resized/*.jpg')[:800]: try: image = io.imread(i) x.append(image) y.append(0) except: continuefor i in glob('man_woman/b_resized/*.jpg')[:800]: try: image = io.imread(i) x.append(image) y.append(1) except: continue plt.subplot(221)plt.imshow(x[0])plt.title('Male')plt.subplot(222)plt.imshow(x[1])plt.title('Male')plt.subplot(223)plt.imshow(x[-1])plt.title('FeMale')plt.subplot(224)plt.imshow(x[-2])plt.title('FeMale')plt.show()获取的图像样本如下所示:

打印加载后的图像尺寸,可以看到,图像的尺寸均为 256 x 256 x 3:
print(x[0].shape)# (256, 256, 3)对输入和输出数据进行预处理,将数组列表转换为 numpy 数组并将使用 reshape 函数整形输入尺寸,以便可以将其传递到卷积神经网络中:
x = np.array(x)x = x.reshape(x.shape[0], x.shape[1], x.shape[2], 3)接下来,缩放输入数组并创建输入和输出数组,并分割数据集创建训练和测试数据集:
x = x / 255.y = np.array(y)# 创建训练和测试数据集from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)定义模型并进行编译:
from keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activation, Flattenfrom keras.layers import Conv2D, MaxPooling2Dfrom keras.optimizers import SGDfrom keras import backend as Kmodel = Sequential()model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=(x.shape[1], x.shape[2], 3)))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', padding='same'))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Conv2D(256, kernel_size=(3, 3), activation='relu', padding='same'))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Conv2D(512, kernel_size=(3, 3), activation='relu', padding='same'))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Flatten())model.add(Dense(128, activation='relu'))model.add(Dense(1, activation='sigmoid'))model.summary()在以上代码中,我们构建了一个具有多个卷积层、池化层的模型。此外,我们将最后一个池化层的输出传递到展平层,然后将展平层的输出连接具有 128 个节点的全连接层,最后连接到输出层。该模型的简要架构信息输出如下:
Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param # =================================================================conv2d (Conv2D) (None, 254, 254, 64) 1792 _________________________________________________________________max_pooling2d (MaxPooling2D) (None, 127, 127, 64) 0 _________________________________________________________________conv2d_1 (Conv2D) (None, 127, 127, 128) 73856 _________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 63, 63, 128) 0 _________________________________________________________________conv2d_2 (Conv2D) (None, 63, 63, 256) 295168 _________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 31, 31, 256) 0 _________________________________________________________________conv2d_3 (Conv2D) (None, 31, 31, 512) 1180160 _________________________________________________________________max_pooling2d_3 (MaxPooling2 (None, 15, 15, 512) 0 _________________________________________________________________flatten (Flatten) (None, 115200) 0 _________________________________________________________________dense (Dense) (None, 128) 14745728 _________________________________________________________________dense_1 (Dense) (None, 1) 129 =================================================================Total params: 16,296,833Trainable params: 16,296,833Non-trainable params: 0_________________________________________________________________接下来,我们使用二分类交叉熵编译模型,并监测模型训练过程中的准确率;最后,拟合模型:
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])history = model.fit(x_train, y_train, batch_size=32, epochs=20, verbose=1, validation_data=(x_test, y_test))如下图所示,可以观察到模型训练过程,随着 epoch 的增加,模型损失和准确率的变化情况,同时可以看到该模型预测准确率大约为 90%:
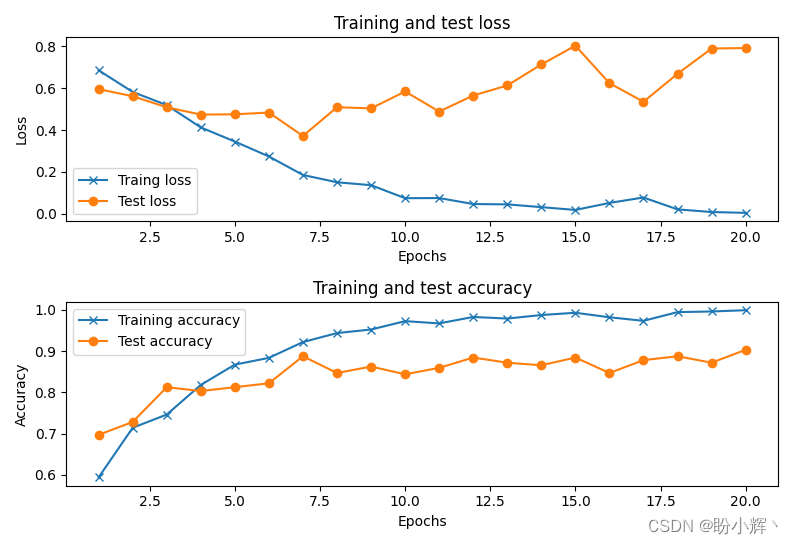
3. 情景2——训练数据集图像尺寸较小
本节中,我们将修改数据集中输入图像尺寸:将尺寸从 256 x 256 减少到 64 x 64;而模型架构与上一节中所用的模型完全相同。
首先,缩放数据集图像尺寸 (64 x 64 x 3) 以构建模型输入数据:
x = []y = []for i in glob('man_woman/a_resized/*.jpg')[:800]: try: image = io.imread(i) x.append(image) y.append(0) except: continuefor i in glob('man_woman/b_resized/*.jpg')[:800]: try: image = io.imread(i) x.append(image) y.append(1) except: continuex2 = []for i in range(len(x)): img2 = cv2.resize(x[i], (64, 64)) x2.append(img2)构建训练、测试所需的输入和输出数组,并对数据集进行划分:
x2 = np.array(x2)x2 = x2.reshape(x2.shape[0], x2.shape[1], x2.shape[2], 3)x2 = x2 / 255.y = np.array(y)# 划分数据集from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(x2, y, test_size=0.2)构建模型,并进行编译和拟合:
from keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activation, Flattenfrom keras.layers import Conv2D, MaxPooling2Dfrom keras.optimizers import SGDfrom keras import backend as Kmodel = Sequential()model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=(x2.shape[1], x2.shape[2], 3)))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', padding='same'))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Conv2D(256, kernel_size=(3, 3), activation='relu', padding='same'))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Conv2D(512, kernel_size=(3, 3), activation='relu', padding='same'))model.add(MaxPooling2D(pool_size=(2,2)))model.add(Flatten())model.add(Dense(128, activation='relu'))model.add(Dense(1, activation='sigmoid'))model.summary()model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])history = model.fit(x_train, y_train, batch_size=32, epochs=20, verbose=1, validation_data=(x_test, y_test))该模型的简要架构信息输入如下:
Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param # =================================================================conv2d (Conv2D) (None, 62, 62, 64) 1792 _________________________________________________________________max_pooling2d (MaxPooling2D) (None, 31, 31, 64) 0 _________________________________________________________________conv2d_1 (Conv2D) (None, 31, 31, 128) 73856 _________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 15, 15, 128) 0 _________________________________________________________________conv2d_2 (Conv2D) (None, 15, 15, 256) 295168 _________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 7, 7, 256) 0 _________________________________________________________________conv2d_3 (Conv2D) (None, 7, 7, 512) 1180160 _________________________________________________________________max_pooling2d_3 (MaxPooling2 (None, 3, 3, 512) 0 _________________________________________________________________flatten (Flatten) (None, 4608) 0 _________________________________________________________________dense (Dense) (None, 128) 589952 _________________________________________________________________dense_1 (Dense) (None, 1) 129 =================================================================Total params: 2,141,057Trainable params: 2,141,057Non-trainable params: 0_________________________________________________________________随着 epoch的 增加,在训练和测试数据集上,模型训练和测试的准确率和损失变化如下:
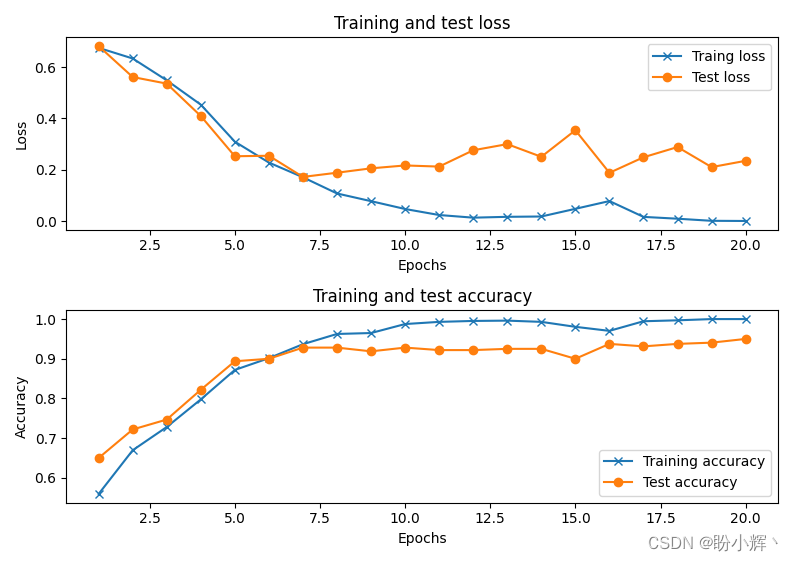
如图所示,在训练和测试数据集中准确性都得到了提高,在测试数据集上的准确率可以达到 95% 左右。由此可见,在模型架构配置等相同情况下,输入大小较小时,卷积神经网络的效果更好,这是由于卷积核的(较小)尺寸决定了它必须从图像中的较小局部中学习有用特征。而随着图像尺寸的增加,卷积神经网络学习的难度将不断提高。
4. 情景3——在训练尺寸较大的图像时使用更大池化
通过情景 2 和情景 3 的对比,我们已经看到图像尺寸会影响模型训练的准确率,因此在本节中,我们使用更大尺寸的池化以确保将尺寸较大的图像 (256 x 256 x 3) 快速缩小为较小的图像。
在卷积神经网络的每个池化层使用更大的池化窗口,该模型的体系结构如下:
model = Sequential()model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=(x.shape[1], x.shape[2], 3)))model.add(MaxPooling2D(pool_size=(3,3)))model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', padding='same'))model.add(MaxPooling2D(pool_size=(3,3)))model.add(Conv2D(256, kernel_size=(3, 3), activation='relu', padding='same'))model.add(MaxPooling2D(pool_size=(3,3)))model.add(Conv2D(512, kernel_size=(3, 3), activation='relu', padding='same'))model.add(MaxPooling2D(pool_size=(3,3)))model.add(Flatten())model.add(Dense(128, activation='relu'))model.add(Dense(1, activation='sigmoid'))model.summary()在此体系结构中,池化核大小为 3 x 3 而不是 2 x 2,模型架构的简要信息输出如下:
Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param # =================================================================conv2d (Conv2D) (None, 254, 254, 64) 1792 _________________________________________________________________max_pooling2d (MaxPooling2D) (None, 84, 84, 64) 0 _________________________________________________________________conv2d_1 (Conv2D) (None, 84, 84, 128) 73856 _________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 28, 28, 128) 0 _________________________________________________________________conv2d_2 (Conv2D) (None, 28, 28, 256) 295168 _________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 9, 9, 256) 0 _________________________________________________________________conv2d_3 (Conv2D) (None, 9, 9, 512) 1180160 _________________________________________________________________max_pooling2d_3 (MaxPooling2 (None, 3, 3, 512) 0 _________________________________________________________________flatten (Flatten) (None, 4608) 0 _________________________________________________________________dense (Dense) (None, 128) 589952 _________________________________________________________________dense_1 (Dense) (None, 1) 129 =================================================================Total params: 2,141,057Trainable params: 2,141,057Non-trainable params: 0_________________________________________________________________在训练数据集上拟合模型后,观察模型在训练和测试数据集上的准确率和损失的变化:
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])history = model.fit(x_train, y_train, batch_size=32, epochs=20, verbose=1, validation_data=(x_test, y_test))以下是模型拟合过程中,随着 epoch 的增加,模型准确率和损失值的变化情况。我们可以看到,最终模型在测试数据集中分类图像中的人物性别方面具有约 92% 的准确率:
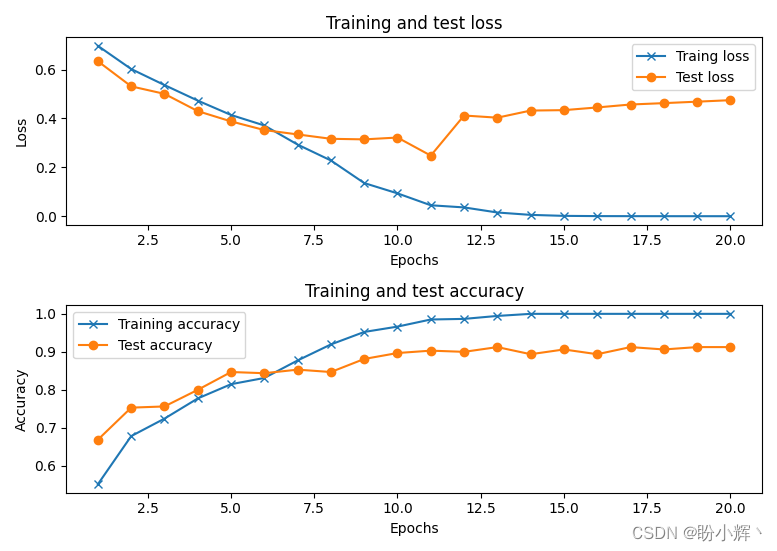
但是,可以看到在模型在训练过程中存在过拟合现象(损失在训练数据集上稳步减少,而在测试数据集上第 12 个 epoch 以后损失基本没有减少)。
小结
本节主要通过实战介绍了卷积神经神经网络的一些局限性,主要包括需要大量数据集和时间进行训练等,在之后的学习中,我们将学习利用迁移学习快速得到一个性能良好的神经网络模型。
系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
Keras深度学习实战(7)——卷积神经网络详解与实现
Keras深度学习实战(8)——使用数据增强提高神经网络性能