近日,腾讯TEG数据平台部机器学习团队与北京大学-腾讯协同创新实验室,合作研发了全新的稀疏大模型训练加速解决方案HET,其研究成果《HET: Scaling out Huge Embedding Model Training via Cache-enabled Distributed Framework》已被国际顶会VLDB 2022录用。HET提出了一种新颖的基于Embedding缓存的训练方法,能够显著降低稀疏大模型分布式训练时通信开销,提升模型训练整体效率。
HET目前已正式开源:https://github.com/PKU-DAIR/Hetu
稀疏大模型日益多见,通信瓶颈或成训练效率“致命”问题
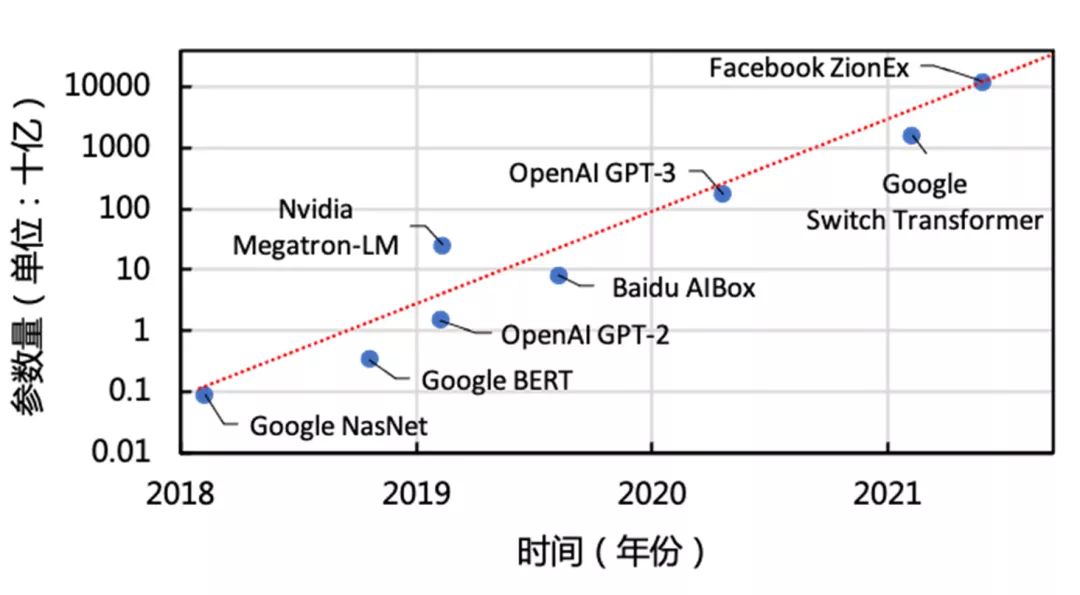
图1 深度学习模型规模发展情况
稀疏大模型,是目前重要的深度学习模型类型之一,广泛应用在搜索广告推荐、图表示学习等场景。近年来,随着数据规模的逐步增长,工业界稀疏大模型的规模日益庞大,参数量可以达到万亿规模。如图1所示,Facebook今年提出的ZionEX[详见注解1]系统所支持的推荐模型(DLRM)大小已经超过10万亿规模,远远超过了Google之前发布的1.6万亿参数的Switch Transformer[详见注解2]模型。
稀疏模型的参数,即Embedding参数,可以达到总模型参数量的99%以上。相比于其他模型,这类模型有着更低的计算密度和更大的模型规模,这也对分布式深度学习系统带来了严峻的挑战。近年来,如何提升稀疏大模型的训练效率逐渐成为了学术界和工业界都在关注的热点问题。
对于万亿规模的模型,仅模型参数就需要3.7TB的内存空间。由于稀疏大模型中的稀疏参数规模极大,因此工业界目前普遍采用基于参数服务器(Parameter Server)的解决方案,将Embedding均匀地切分到不同服务器上。在训练过程中,计算节点采用稀疏通信的形式,动态地从参数服务器上拉取所需的Embedding向量,完成当前轮次的计算后,再将Embedding的梯度提交回参数服务器。尽管这种方式可以灵活地扩展模型规模,但是也面临着严重的通信瓶颈。以主流深度学习框架TensorFlow为例,在实际数据测试中,通信时间甚至会占到总训练时间的80%以上。目前大多数改进方向是在参数服务器的工程实现上进行优化,例如充分挖掘硬件性能来提高整个系统的吞吐率。然而并没有从根本上解决稀疏参数通信量大的问题,通信仍然是系统的核心痛点。因此需要一种从源头上解决通信问题的方案。
HET:基于Embedding缓存的稀疏大模型训练系统
核心思路
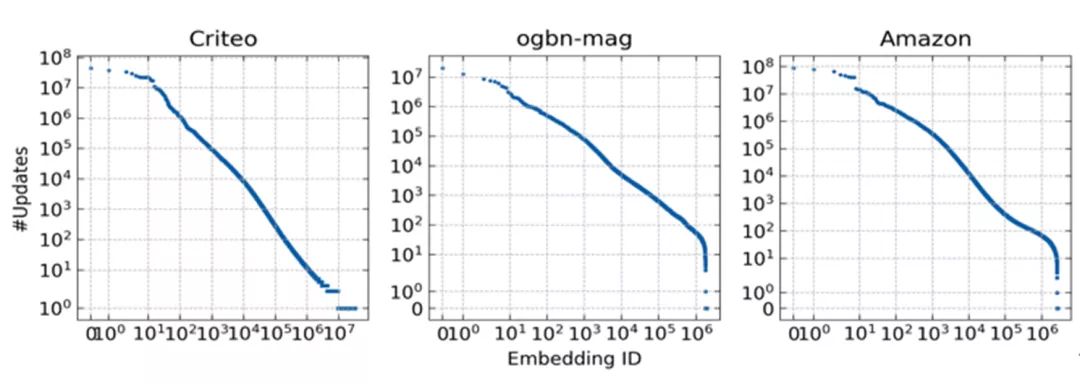
图2 三个常用公开数据集上的Embedding访问频率分布情况
根据来自在业务场景中的观察,高维稀疏大模型的输入数据特征往往具有倾斜分布的特性,具有幂律分布(如图2所示),从而导致模型在训练过程中对Embedding向量的不均衡访问。以推荐数据集Criteo为例,约有10%的Embedding向量引发了整个数据集90%的Embedding访问。训练过程中,这些高频Embedding会被频繁地拉取和推送,成为了通信的主要负载。
我们利用这一特性,提出了Embedding缓存的思想:如果能够在计算节点利用有限的内存空间缓存这些高频Embedding,那就有机会避免大量的远程Embedding访问,从而缓解通信瓶颈。根据这一思想,我们提出了基于Embedding缓存的新一代稀疏大模型训练框架HET。
技术点1:支持Embedding参数缓存的混合通信架构
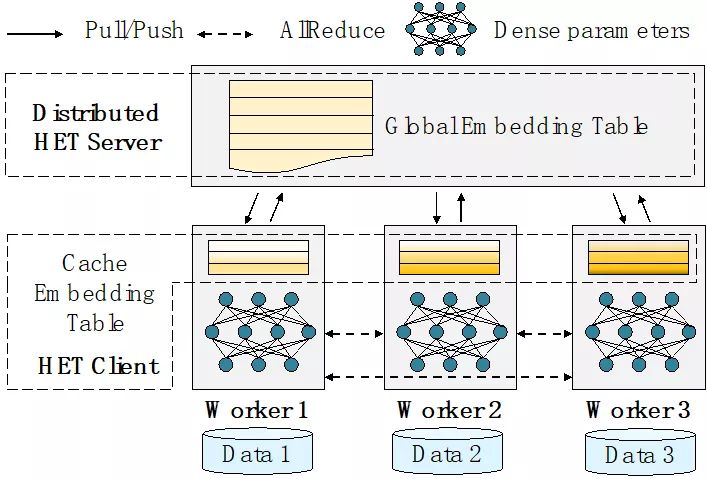
图3 HET系统架构
针对稀疏大模型参数中同时存在稀疏以及稠密部分的特点,HET整体上采用参数服务器(Parameter Server,PS)加全局规约(AllReduce)的混合通信架构,以充分发挥两者优势,如图3所示。其中AllReduce适合于稠密参数的同步,可借助NCCL等通信库充分发挥GPU间带宽,而参数服务器则天然支持稀疏通信,并且在同步协议上也具有较高的灵活性。同时,我们还在计算节点上设计了Cache Embedding Table结构,用于缓存高频访问的Embedding参数。
每个计算节点上采用Cache Embedding Table可节省大量的通信量,但是也带来了一个新的问题,即对于某个特定的Embedding来说,其副本可能同时存在于多个不同的计算节点缓存当中。如果不考虑副本间的一致性,可能会导致模型训练发散,无法收敛。为此,我们进一步提出了一种基于细粒度Embedding时钟的有限异步协议,来解决如何在不同的节点间同步这些Embedding副本的问题。
技术点2:基于细粒度Embedding时钟的有限异步协议
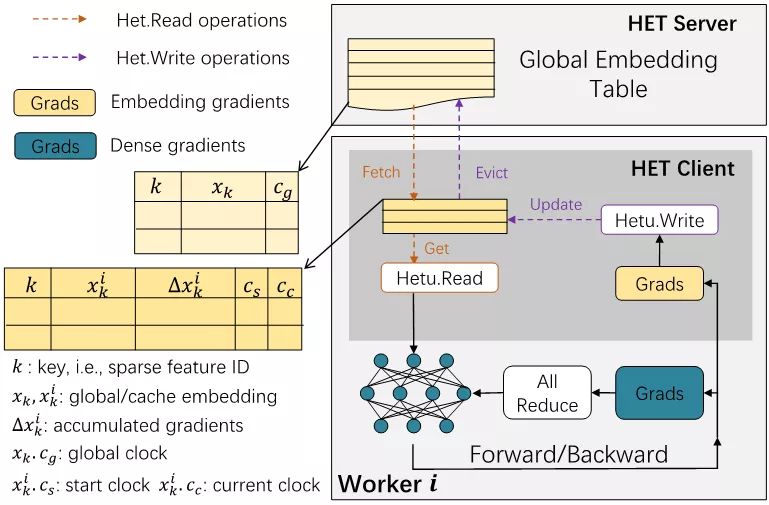
图4 HET中的Cache Embedding Table结构
一般来说,Embedding参数采用表的方式进行组织以支持稀疏访问。为了衡量Embedding副本间的一致性,我们对于每个Embedding向量,在常规的key-value数据结构基础之上,引入了一个重要的Lamport时钟,用来记录Embedding向量的状态。在模型训练过程中,通过比较Embedding的时钟,就可以知道该副本的延迟或超前程度。

图5 HET中的Cache读写操作
对于Embedding缓存表,我们既允许读取较为陈旧的Embedding,也允许延迟写回缓存上的梯度更新。为了在充分发挥缓存加速效果的同时保证模型的训练质量,我们限制了每个Embedding副本和全局Embedding间的时钟相差不超过一个预先设定的阈值。在这种情况下,Embedding的每个副本都不会过于超前或落后于它的其他副本。
从全局视角来看,整个模型的稀疏和稠密部分分别采用不同的同步模式,稠密参数采用全同步协议进行通信,稀疏参数采用基于细粒度Embedding时钟的有限异步协议进行通信。经过理论分析,我们进一步证明了,这种基于细粒度Embedding时钟的有限异步协议可以保证和全同步协议相似的收敛性。(详情见论文链接)
实验结果
我们将HET和基于传统参数服务器架构的TensorFlow以及同样是参数服务器加全局规约的混合通信架构的Parallax[详见注解3]进行了对比,选取的数据集和模型包括:推荐模型Wide&Deep(WDL)、DeepFM(DFM)、Deep&Cross(DCN)和数据集Criteo,拥有三千多万稀疏特征,当Embedding维度扩大到4K时,模型参数可以达到万亿级别;以及图学习模型GraphSAGE和数据集Reddit、Amazon、ogbn-mag(OGB也是目前最权威的图学习基准数据集之一,Open Graph Benchmark)。
端到端对比
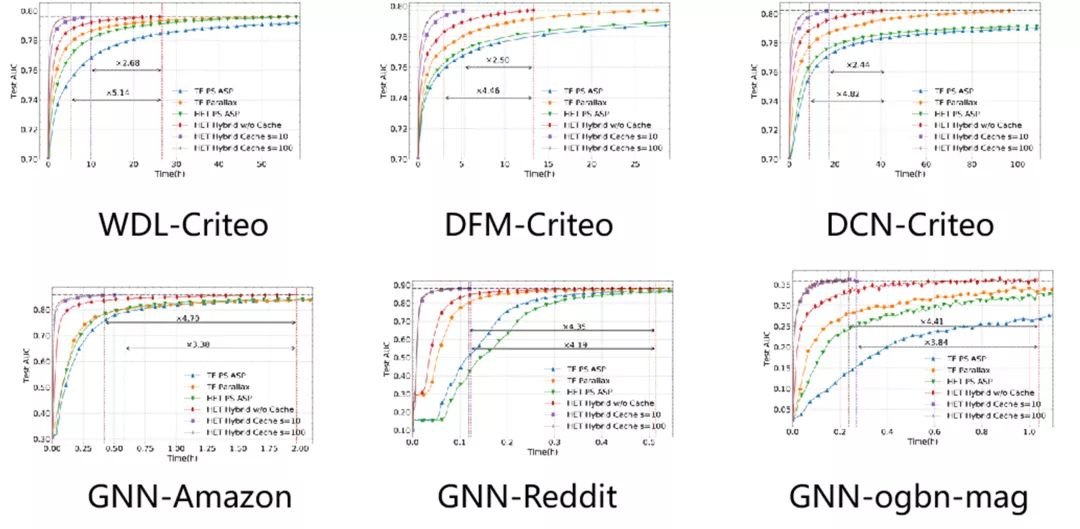
图6 收敛效果对比
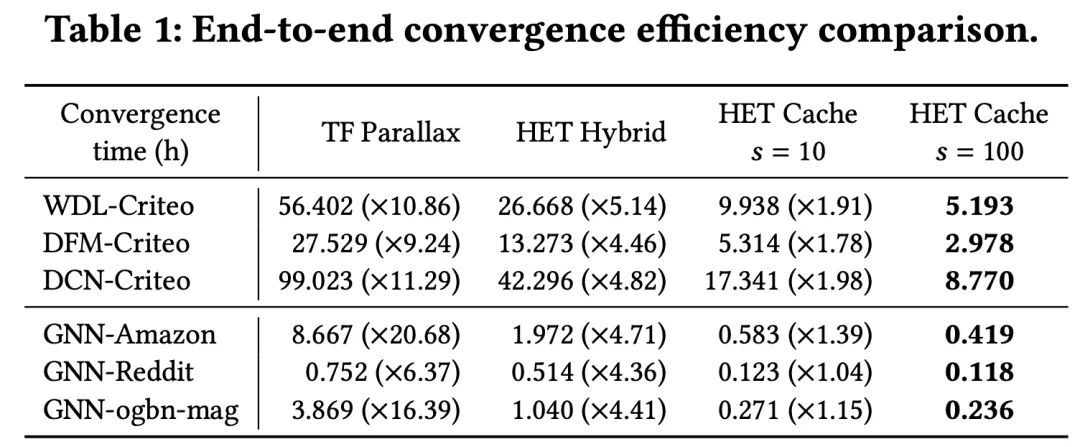
图7 端到端收敛速度对比
结合图6和图7,我们可以看出,在时钟相差阈值上界设置为100时,相比于TensorFlow和Parallax,HET可以实现6.37-20.68倍的加速,并且不会对模型收敛性造成显著影响。对于HET本身,细粒度Embedding缓存带来了4.36-5.14倍的加速,最多可以减少88%的稀疏参数通信。
缓存效果对比:
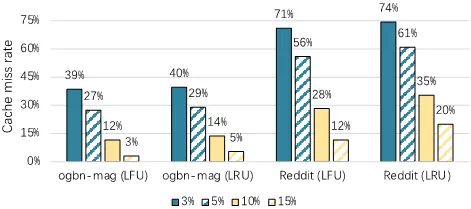
图8 在不同Cache空间大小情况下Cache失效率情况
从图8可以看出,只需要很少的Cache空间,比如15%的总参数量大小,就可以实现几乎97%的缓存命中率,即97%的Embedding访问都可以通过本地缓存访问,而无需通信。另外我们也注意到,不同的Cache实现策略在效果上也稍有不同,LFU可以捕获长期访问倾向性,从而比LRU失效率更低。
可扩展性:
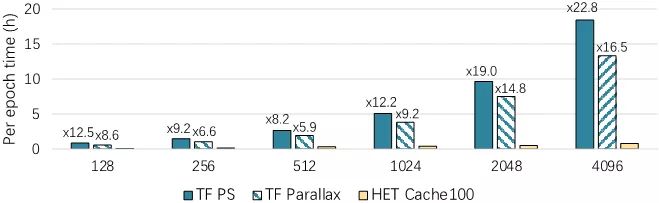
图9 在不同参数规模情况下的收敛效果
我们将模型扩展到32节点,Embedding维度设置到4096,此时总参数量已经达到了万亿规模,从图9可以看到HET执行时间仍然显著优于其他基线方案,从而说明了HET的有效性。
腾讯TEG数据平台部机器学习团队:
该团队致力于研发腾讯分布式机器学习平台Angel,解决高维模型和稀疏数据训练问题。Angel诞生于腾讯大数据生态中,通过融合大数据、传统机器学习和深度学习生态,建立起一个端到端机器学习平台,功能涵盖传统机器学习、图挖掘、图学习、深度学习和隐私计算等。在腾讯公司内部, Angel已经广泛应用于广告推荐、金融风控、用户画像和短视频推荐等业务。除了服务于公司内部业务外,Angel于2017年对外开源,是国内第一个LF AI基金会顶级项目。
针对模型规模扩大后对性能和扩展性带来的挑战。Angel平台工程师联合北京大学-腾讯协同创新实验室,推出了稀疏大模型训练框架HEAP,并在广告推荐全链路中,依托腾讯内部业务需求对各种规模模型的训练提速增效,开展了包含基于Embedding缓存的新一代稀疏大模型训练,基于层次化参数服务器的万亿Embedding模型训练、多GPU分布式训练性能优化等在内的多项前瞻研究,并落地到广告精排、粗排、预排序和召回等多个业务模型的训练中,在腾讯各个业务线条累计获取GMV提升约4%。本次发表的研究成果HET也是在该框架下进行的新的探索。
北京大学-腾讯协同创新实验室:
北京大学-腾讯协同创新实验室成立于2017年,主要在人工智能、大数据等领域展开前沿探索和人才培养,打造国际领先的校企合作科研平台和产学研用基地。
实验室通过合作研究,在理论和技术创新、系统研发和产业应用方面取得重要成果和进展,已在国际顶级学术会议和期刊发表学术论文20余篇,除合作研发Angel外,实验室还自主开发了多个开源系统,例如:
分布式深度学习系统河图(Hetu)
https://github.com/PKU-DAIR/Hetu
黑盒优化系统OpenBox
https://github.com/PKU-DAIR/open-box
今年8月,实验室已经宣布,将自研深度学习框架“河图”融入Angel生态,北京大学与腾讯团队将联合共建Angel4.0——新一代分布式深度学习平台,面向拥有海量训练数据、超大模型参数的深度学习训练场景,为产业界带来新的大规模深度学习破局之策。
详细了解HET,请访问下方链接地址:
论文地址(预览版):
https://github.com/Hsword/Het/blob/main/vldb2021_het.pdf
项目地址:
https://github.com/PKU-DAIR/Hetu
参考资料:
[1] Mudigere D, Hao Y, Huang J, et al. High-performance, distributed training of large-scale deep learning recommendation models[J]. arXiv preprint arXiv:2104.05158, 2021.
[2] Fedus W, Zoph B, Shazeer N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity[J]. arXiv preprint arXiv:2101.03961, 2021.
[3] Kim S, Yu G I, Park H, et al. Parallax: Sparsity-aware data parallel training of deep neural networks[C]//Proceedings of the Fourteenth EuroSys Conference 2019. 2019: 1-15.