初入红尘,不知人间疾苦,
暮然回首,已是苦中之人。
这杯中 酒三分,
这酒中 悲七分。
关关难过 关关过,
夜夜难熬 夜夜熬。
愿这世间爱恨情仇尽融于酒,
将这风尘作酒
一饮消愁!
这是枕上诗书里的一句话,粗略一读就有一股"网抑云"的气息扑面而来,吓得我赶紧打开我的收藏观摩一番,果然看美女使人心情愉悦

什么!你没有收藏!那今天教教你怎么让你有自己的收藏。
今天爬一下彼岸网,这个网站比较简单,适合新手练习(注意别太狠,这个还是会封id的)
说一下我的开发环境:python3.8
计算机系统:Windows10
开发工具:pycharm
要用的包:requests、os、re
网址:https://pic.netbian.com/
打开网址先看检查一下,发现图片都储存在 li 标签中的 img 标签不过这里储存的是缩略图,想要高清图要爬取a标签里的链接,进入后在爬取高清图

先获取这个网页的数据
import os
import re
import requests
def get_page(url, headers):
response = requests.get(url=url, headers=headers)
response.encoding = 'gbk' # 这里注意一下,这个网站的编码是gbk要是设置一下
if response.status_code == 200:
return response.text
这里注意一下,这个网站的编码是gbk要是设置一下
def main():
url = 'https://pic.netbian.com/'
headers = {
'User-Agent': 'Fiddler/5.0.20204.45441 (.NET 4.8; WinNT 10.0.19042.0; zh-CN; 8xAMD64; Auto Update; Full Instance; Extensions: APITesting, AutoSaveExt, EventLog, FiddlerOrchestraAddon, HostsFile, RulesTab2, SAZClipboardFactory, SimpleFilter, Timeline)'
}
html = get_page(url,headers)
print(html)
if __name__ == '__main__':
main()
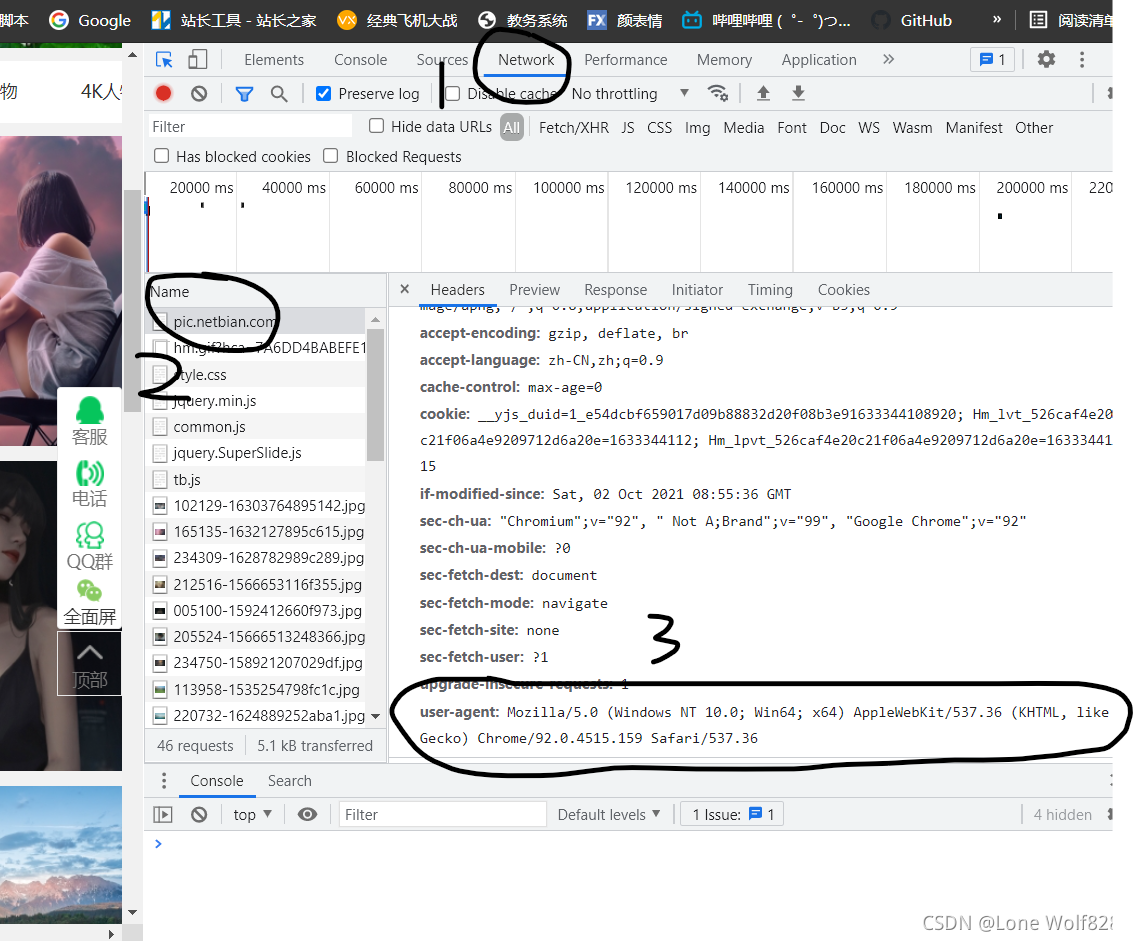
每次写爬虫之前都要记得设一下UA伪装
UA伪装怎么弄随便打开一个网页F12检查,点击Network在Name里随便点击一个,在右面往下滑找到User-Agent复制下来就行 格式换成字典类型的,具体参考我上方的代码及下方的图片
运行一下得到网页的源码

因为要得到所有的a标签里的链接所以这里我用的是re,用正则表达式来匹配链接
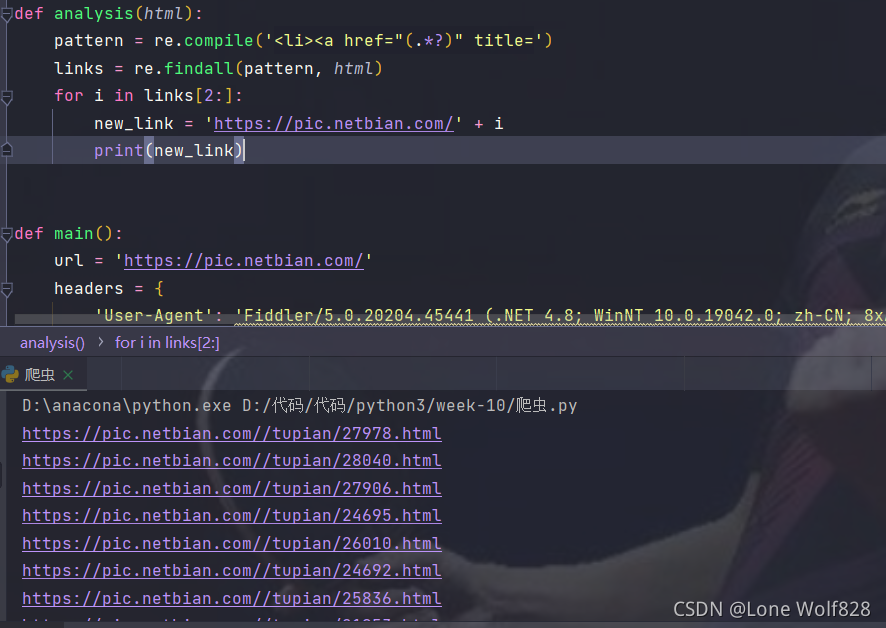
def analysis(html):
pattern = re.compile('<li><a href="(.*?)" title=')
links = re.findall(pattern, html)
print(links)

可以看到得到了所有的链接,不过有两个不速之客,可以用索引来分割,还有一个问题,这些链接都是不完整的我们要自己给他们拼接起来

可以看到缺失的内容如上图所示我们在前面加上即可
可以看到这些链接已经拼接成了完整的链接并且可以访问,创一个空列表把链接放进去,第一部分已经写完了,我们再写个循环访问这些链接再从中获取到图片信息
解析网页就用之前写的get_page()就行
将解析到的页面源码再用正则匹配得到图片链接还有名称为之后的存储做准备
这些链接还是不完整的需要拼接一下,在拼接之前要用’’.join()转换成字符串类型,因为re.findall()返回的是列表
def analysis2(html):
name = re.compile('<h1>(.*?)</h1>')
new_name = re.findall(name, html)
pattern = re.compile('<a href="" id="img"><img src="(.*?)" data')
img = re.findall(pattern, html)
img = ''.join(img)
new_name = ''.join(new_name)
new_ink = 'https://pic.netbian.com' + img
return new_name, new_ink
这里return返回一个元组,直接用索引得到想要的内容
进行持久化存储要先建一个文件夹不然会直接储存在你当前文件夹中
我新建了一个happy(你懂得)文件夹
if not os.path.exists('./happy'):
os.mkdir('./happy')
for i in inks:
html = get_page(i, headers)
ink = analysis2(html)
ee = requests.get(url=ink[1], headers=headers).content
new_img_name = 'happy/' + ink[0] + '.jpg'
with open(new_img_name, 'wb') as f:
f.write(ee)
print(new_img_name, '下载成功')
用with进行存储就大功告成了
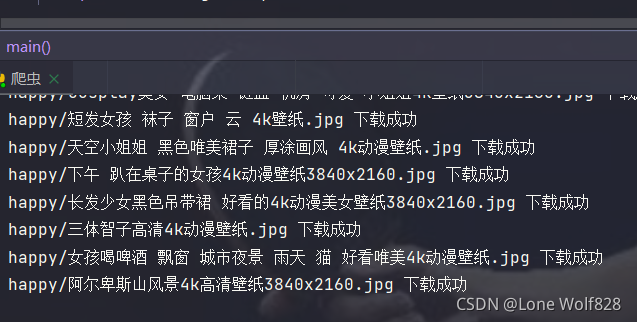


这不就非常happy吗!!
这些代码比较简单就没有写注释(才不是我不愿意写呢)
全部代码如下:
import os
import re
import requests
if not os.path.exists('./happy'):
os.mkdir('./happy')
def get_page(url, headers):
response = requests.get(url=url, headers=headers)
response.encoding = 'gbk'
if response.status_code == 200:
return response.text
def analysis(html):
list_links = []
pattern = re.compile('<li><a href="(.*?)" title=')
links = re.findall(pattern, html)
for i in links[2:]:
new_link = 'https://pic.netbian.com' + i
list_links.append(new_link)
return list_links
def analysis2(html):
name = re.compile('<h1>(.*?)</h1>')
new_name = re.findall(name, html)
pattern = re.compile('<a href="" id="img"><img src="(.*?)" data')
img = re.findall(pattern, html)
img = ''.join(img)
new_name = ''.join(new_name)
new_ink = 'https://pic.netbian.com' + img
return new_name, new_ink
def main():
url = 'https://pic.netbian.com/'
headers = {
'User-Agent': 'Fiddler/5.0.20204.45441 (.NET 4.8; WinNT 10.0.19042.0; zh-CN; 8xAMD64; Auto Update; Full Instance; Extensions: APITesting, AutoSaveExt, EventLog, FiddlerOrchestraAddon, HostsFile, RulesTab2, SAZClipboardFactory, SimpleFilter, Timeline)'
}
html = get_page(url, headers)
inks = analysis(html)
for i in inks:
html = get_page(i, headers)
ink = analysis2(html)
ee = requests.get(url=ink[1], headers=headers).content
new_img_name = 'happy/' + ink[0] + '.jpg'
with open(new_img_name, 'wb') as f:
f.write(ee)
print(new_img_name, '下载成功')
if __name__ == '__main__':
main()
短短57行代码就实现了快乐,难道男人的快乐就这么简单吗!!