目录
8.1datetime模块
8.1.1datetime的构造
8.1.2数据转换
8.2时间序列基础
8.2.1时间序列构造
8.2.2索引与切片
8.3日期
8.3.1日期范围
8.3.2频率与移动
8.4时期
8.4.1时期基础
8.4.2频率转换
8.4.3时期数据转换
8.5频率转换与重采样
8.5.1重采样
8.5.2降采样
8.5.3升采样
8.6综合示例-自行车租赁数据
8.6.1数据来源
8.6.2定义问题
8.6.3数据清洗
8.6.4数据探索
在许多行业中,时间序列数据是一种重要的结构化数据类型。本章主要讲解datetime的数据类型及字符串的想换转换方法;时间序列的构造和使用放啊;日期和时期数据的使用方法;时间序列的频率转换与重采样。最后通过一个案例,讲解时间序列数据的处理与分析方法。
8.1datetime模块
本节将讲解Python标准库中的datetime库的使用方法,以及datetime库的数据和字符串数据的转换方法。
8.1.1datetime的构造
Python的标准库datetime可用于创建时间数据类型。如下表所示为datetime库的时间数据类型。
| 类型 | 使用说明 |
| date | 日期(年月日) |
| time | 时间(时分秒毫秒) |
| datetime | 日期和时间 |
| timedelta | 两个datetime的差(日秒毫秒) |
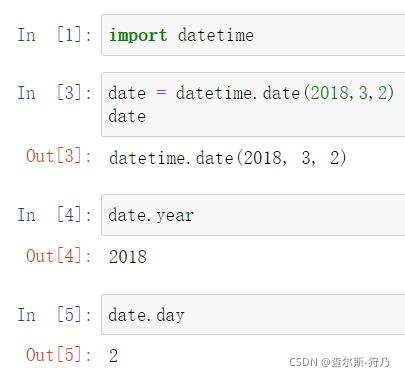
其中date类数据可用于创建日期类数据,通过年、月、日来进行存储,如下图
time类数据用于存储时间数据,通过时、分、秒、毫秒进行存储,如下图

datetime类数据可以看做时date类和time类的组合,通过now方法可以查看当前的时间,如下图

timedelta类数据为两个datetime类数据的差,也可以通过daetime类对象加或减去timedelta类对象,以此获取新的datetime类对象,如下图

8.1.2数据转换
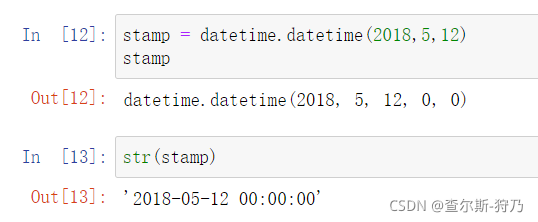
在数据分析中,字符串和datetime类数据需要进行转换,通过str方法可以直接将datetime类数据转换为字符串
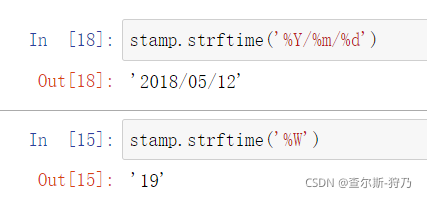
如果需要将datetime类数据转换为特定格式的字符串数据(格式化),需要使用strftime方法,如下图
下表所示为部分格式化编码
| 代码 | 使用说明 |
| %Y | 4位数的年 |
| %y | 2位数的年 |
| %m | 2位数的月 |
| %d | 2位数的填 |
| %H | 时(24小时制) |
| %I | 时(12小时制) |
| %M | 2位数的分 |
| %W | 每年的第几周,星期一为每周第一天 |
通过datetime.strptime方法可将字符串格式转换为datetime数据类型,如下图

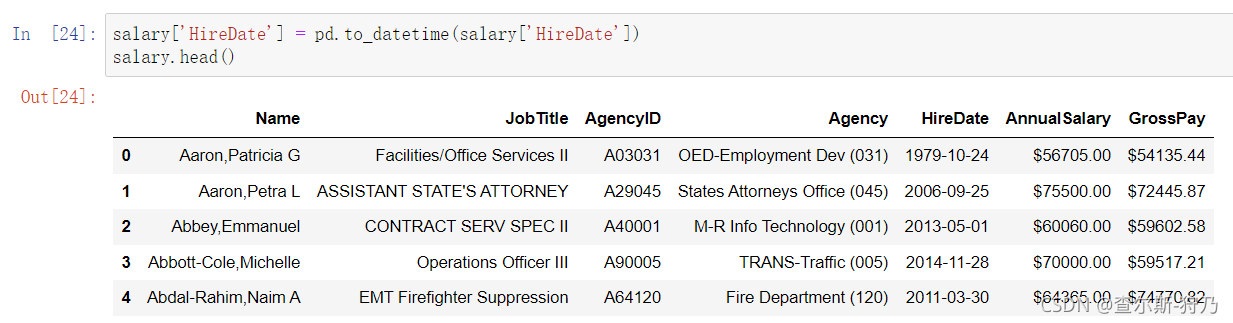
在pandas中,可通过to_datetime方法将一列字符串数据转换为时间数据。以前面章节的示例为例,可以看出HireDate字段的数据类型为字符串

通过to_datetime方法可以将HireDate字段进行转换,如下图,该数据为TimeStamp (时间戳)
8.2时间序列基础
时间序列是以时间戳为索引的Series或DataFrame。本节将讲解时间序列的构造方法,以及时间序列的索引和切片
8.2.1时间序列构造
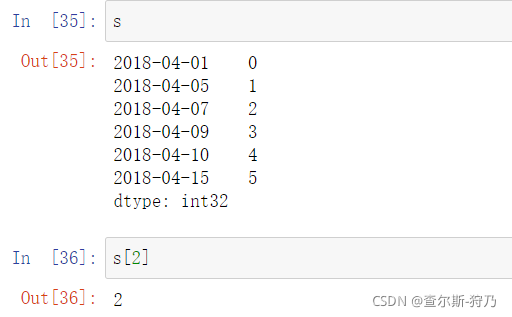
pandas中的时间序列指的是以时间数据为索引的Series或DataFrame。如下图,为创建一个时间序列的Series

创建的这个时间序列Series的索引为DatetimeIndex对象,如下图
而DatetimeIndex对象的每个标量值是pandas的Timestamo对象,如下图,该对象以保存频率信息,后面会 讲解其用途。
跟普通的series一样,不同索引的时间序列的算数运算会按照索引对齐,如下图

8.2.2索引与切片
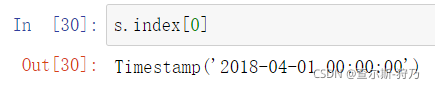
时间序列的索引用法和pandas基础数据类型的用法是一样的,如下图
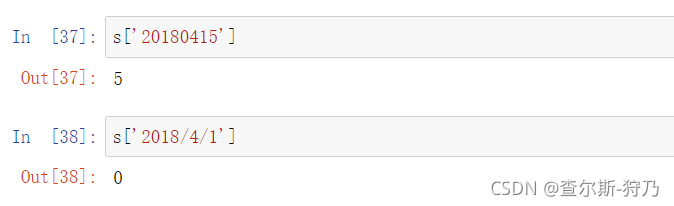
传入一个可用于解释的日期字符串,同样也可以完成索引工作,这是一种比较方便的用法,如下图
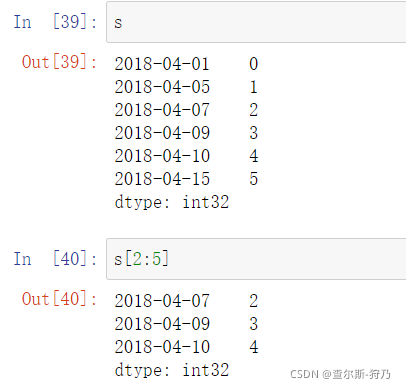
切片的使用方法和pandas基础数据用法也是一样的,如下图所示
同样的传入日期字符串或者datetime类数据也可以完成切片。由于大部分时间序列数据是按照时间先后顺序进行排序的,如果索引值不在该时间序列中也可以实现切片,如下图
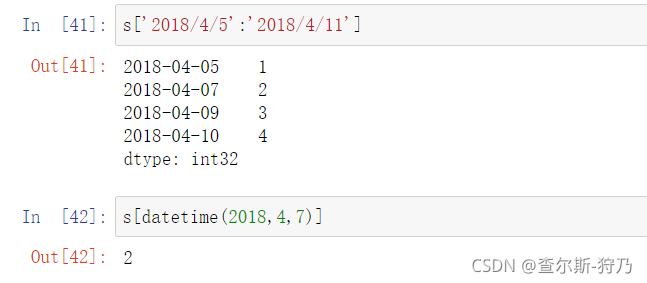
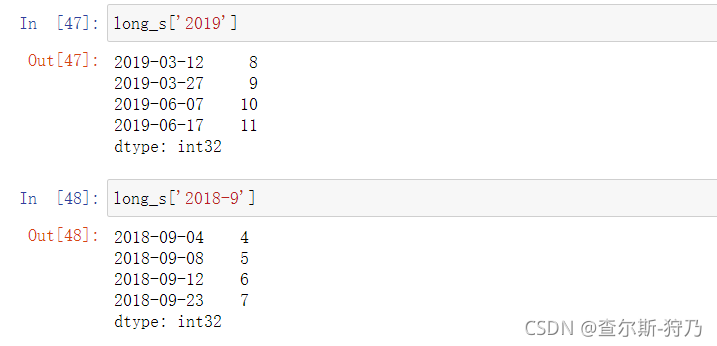
对于长时间序列来说,可以通过年、月来轻松获取时间序列的切片,如下图

注:时间序列的DataFrame的索引和切片使用方法同上面一样,不再赘述。
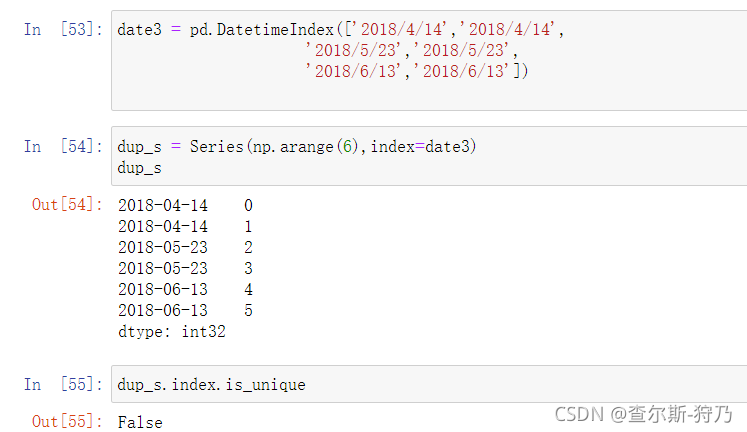
对于具有重复索引的时间序列,可通过索引的is_unique属性进行检查,如下图
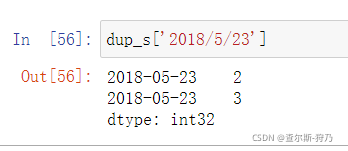
对重复索引的时间序列进行索引时,产生的是切片,如下图
这样可通过groupby函数对其进行聚合,如下图

8.3日期
本节将讲解如何生成指定长度的DatetimeIndex,时间序列中的基础频率及如何移动时间数据。
8.3.1日期范围
使用pd.date_range函数可以创建指定长度的DatetimeIndex索引,如下图
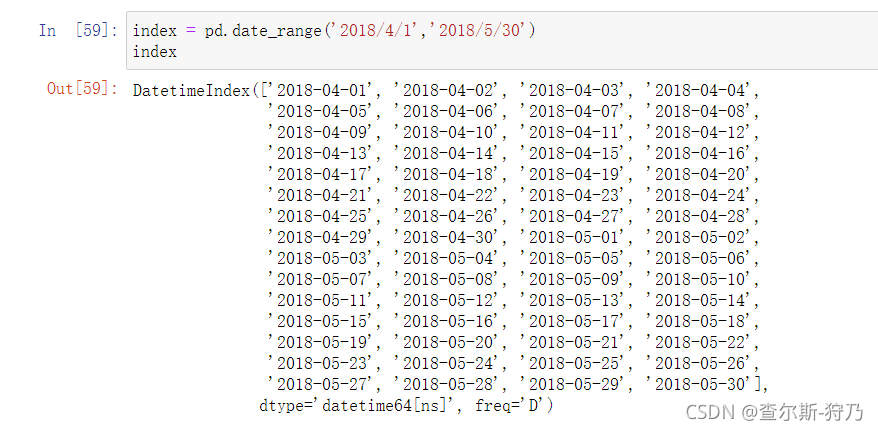
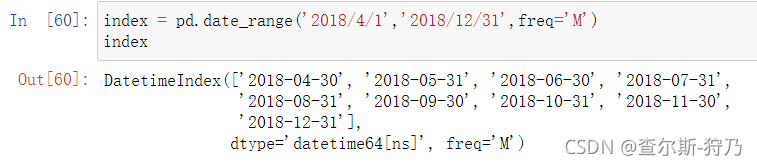
如下图,默认情况下,产生的DatetimeIndex索引的间隔为天,也就是说,时间频率是填。通过freq参数可以使用其他频率,如下图
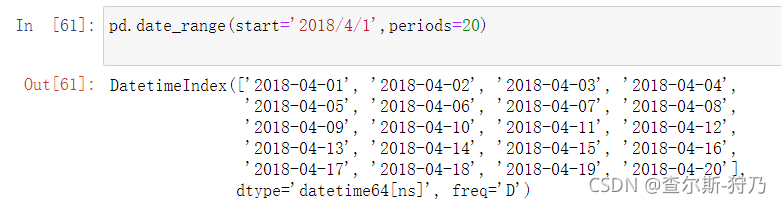
在pd.date_range函数中传入起始或者结束如期,在传入一个表示一段时间的数据,就可以创建指定长度的DatetimeIndex索引,如下图
默认情况下,pd.date_range函数会保留完整的时间信息,但可以通过normalize参数使其规范化,如下图所示

8.3.2频率与移动
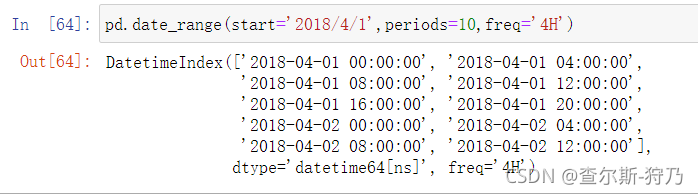
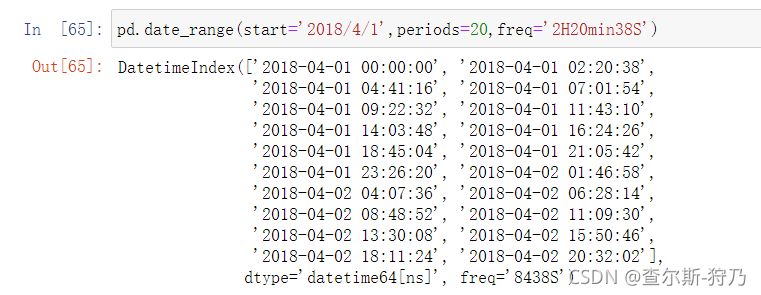
时间序列的频率由基础频率和日期偏移量组成。例如,通过4H就可以创建4个小时为频率的DatetimeIndex索引,如下图
更为复杂的频率字符串,也可以被搞笑解析为相对应的频率,如下图
时间序列的常用基础频率如下表
| 别名 | 使用说明 |
| D | 每日历日 |
| B | 每工作日 |
| H | 每小时 |
| S | 每秒 |
| T或者min | 每分钟 |
| M | 每月最后一个日历日 |
| BM | 每月最后一个工作日 |
| A-JAN、A-EFB | 每年指定月份的最后一个日历日 |
移动数据就是沿着时间索引将数据向前或者向后移动。通过shift方法可以完成移动数据的操作,如下图
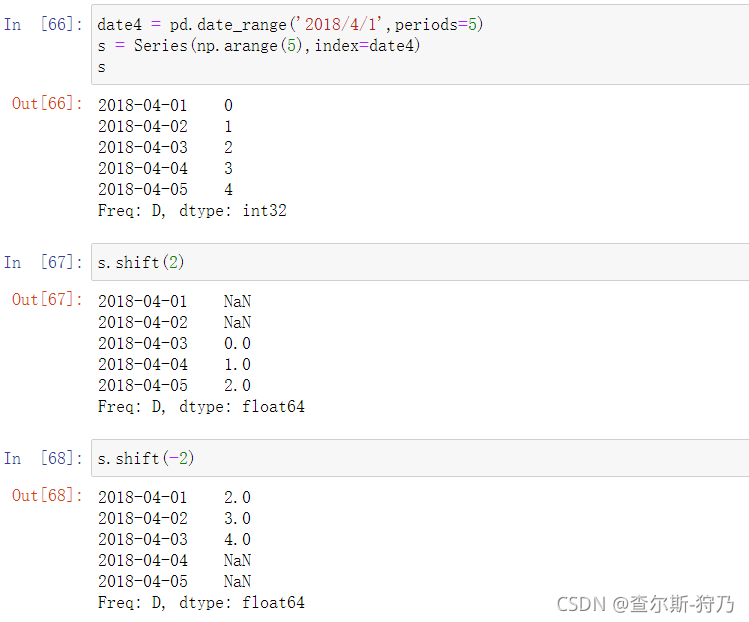
这种单纯的移动不会修改索引,而是使部分数据被丢弃。如果在shift方法中传入参数,这样就是修改索引了,如下图

8.4时期
时期表示的时间区间,如数日,数月和数年等。本节将讲解时期的构造方法、时期数据的频率转换和其数据结构
8.4.1时期基础
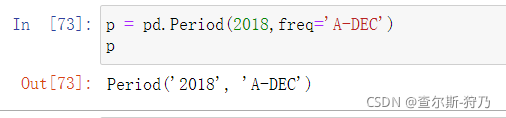
Period可以创建时期数据类型,传入字符串或者整数、频率即可,如下图。下图中的Period对象表示从2018年1也1日到2018年12月31日之间的整段时间。
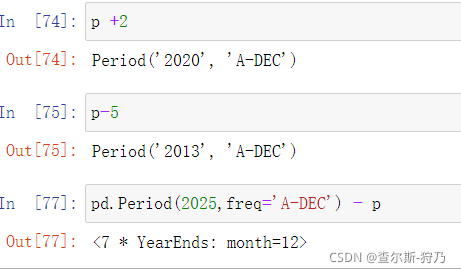
该Period对象可以进行加减计算,使其进行时间的品阿姨。两个Period对象如果由相同的频率,则他们的差为他们之间的单位数量。
类似于pd.date_range,pd.period_range函数可以创建时期范围,PeriodIndex索引同样可以构Series或DataFrame数据
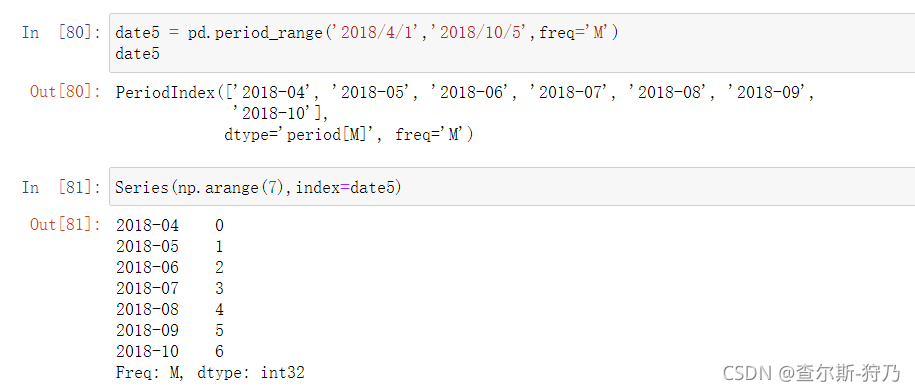
8.4.2频率转换
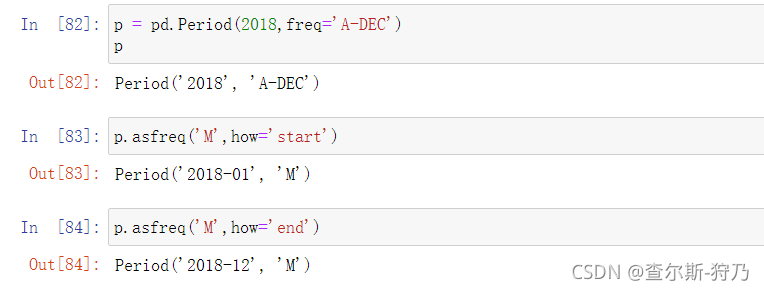
Period和PeriodIndex对象可以通过asfreq方法转换频率,如下图所示将年度时期转换为月度时期
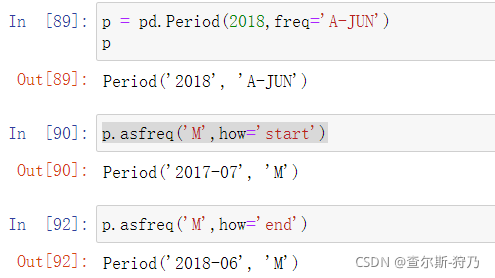
当年度的频率不是位于12月时,转换频率就会发生变化,如下图
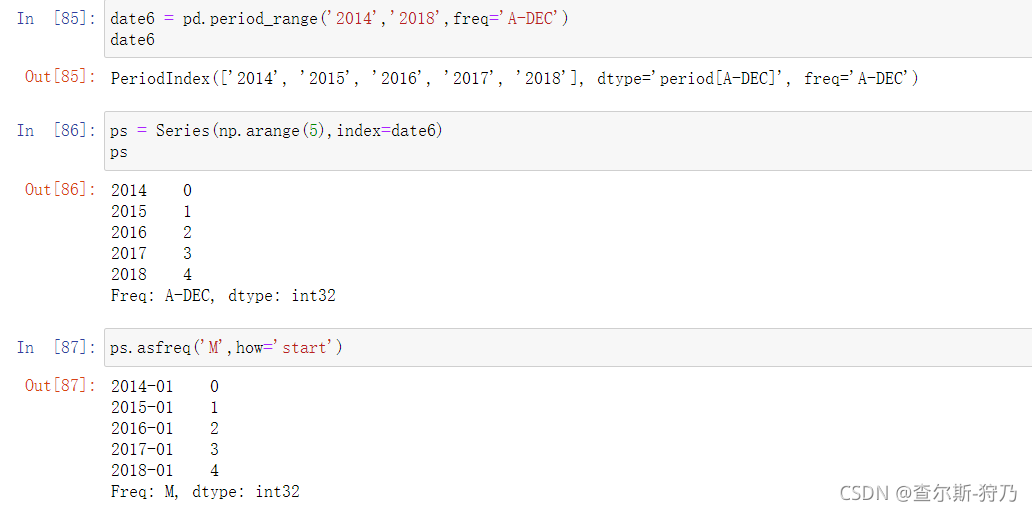
PeriodIndex对象的频率转换方式也一样,如下图
8.4.3时期数据转换
利用to_period方法可以将由时间戳索引的时间序列数据转换为时期为索引,如下图
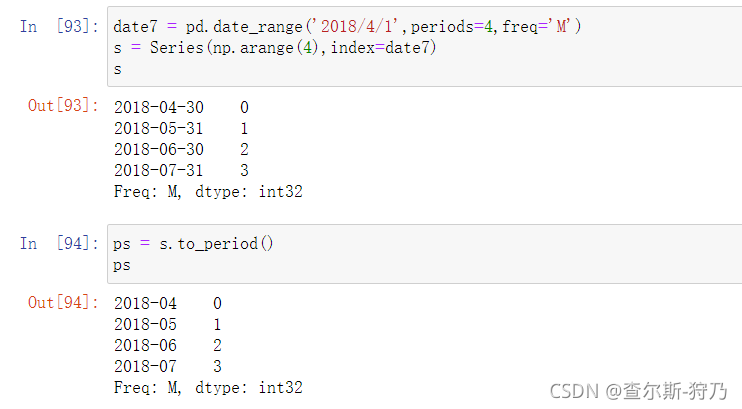
当然,也可以指定转换的频率,如图所示

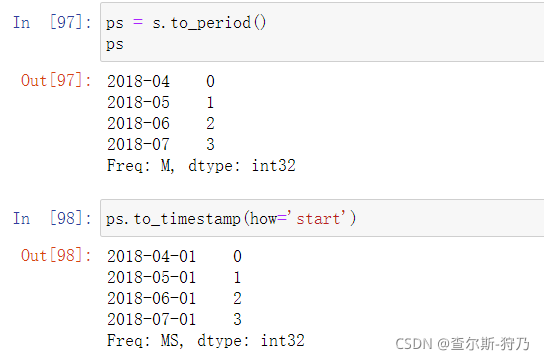
通过to_timestamp方法可进行逆操作,如下图
8.5频率转换与重采样
重采样时时间序列频率转换的处理过程。高频率聚合到低频率成为降采样,而低频率转换为高频率为高采样。
8.5.1重采样
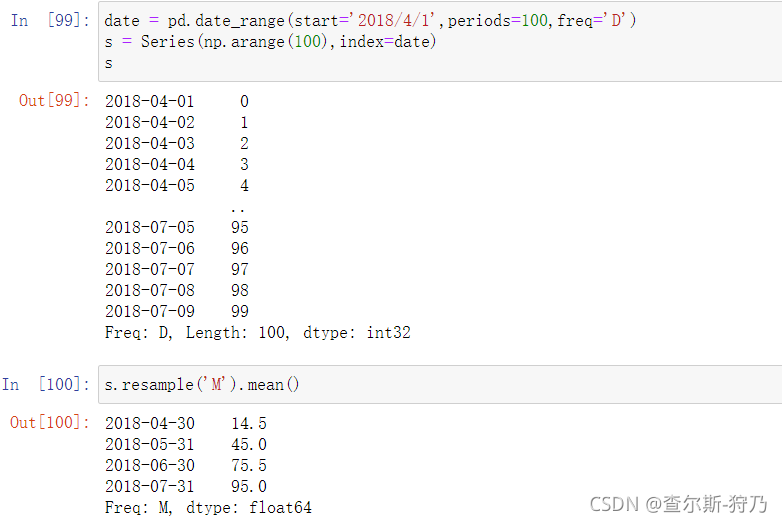
pandas中的resample方法用于各种频率的转换工作,如下图所示为将间隔为’天‘的频率转换为间隔为’月度‘的频率,这里的聚合方法为平均值。
如下表所示为resample方法的参数及说明,具体使用方法后面会详细解说
| 参数 | 使用说明 |
| freq | 转换频率 |
| axies=0 | 重采样的轴 |
| closed=’right | 在降采样中,设置各时间段哪端是闭合的 |
| label=‘right’ | 在降采样中,如何设置聚合值的标签 |
| loffset=None | 设置时间偏移量 |
| kind=None | 聚合到时期或时间戳,默认为时间序列得索引类型 |
| convention=None | 升采样所采用得约定(start或end)。默认为end |
8.5.2降采样
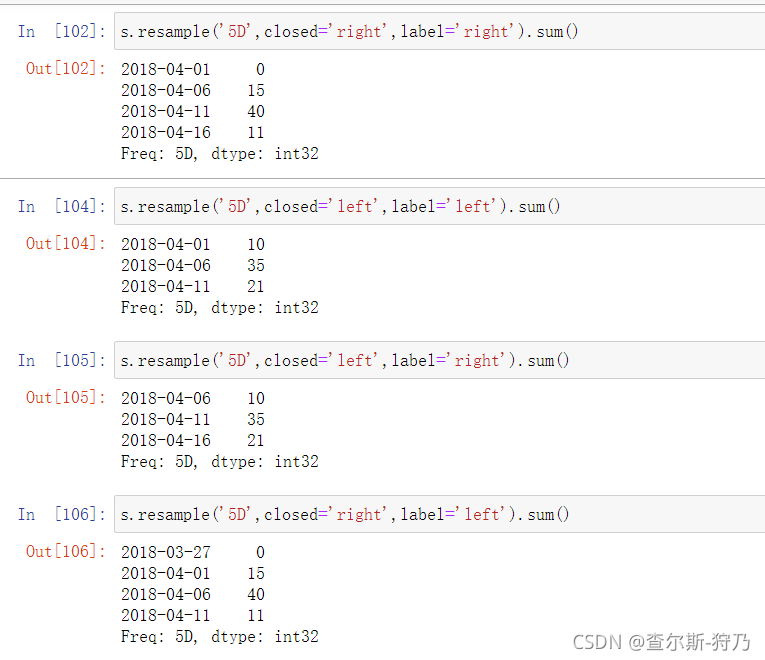
在降采样中,重点需要考虑得是closed和label参数,这两个参数分别表示哪边区间是闭合的,哪边用于标记。如图所示为将两个参数值都设置为right

如下图所示将closed和label参数值均设为left。大家可以思考一下这两个参数的变化带来的影响。多看两遍就可以掌握了,其实很简单。
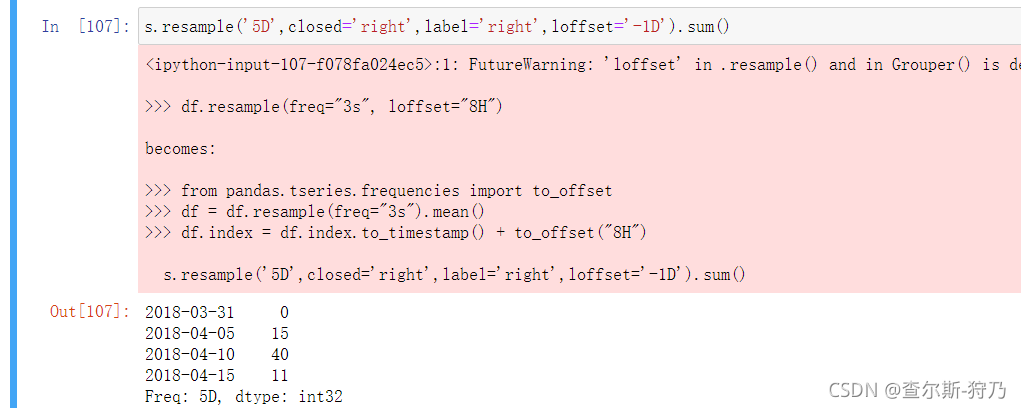
通过设置loffset日期偏移量,也可以看出其时间戳所属的区间,如下图,红色的是未来改版的警告信息,大家按照他那个写法改改就好。
 8.5.3升采样
8.5.3升采样
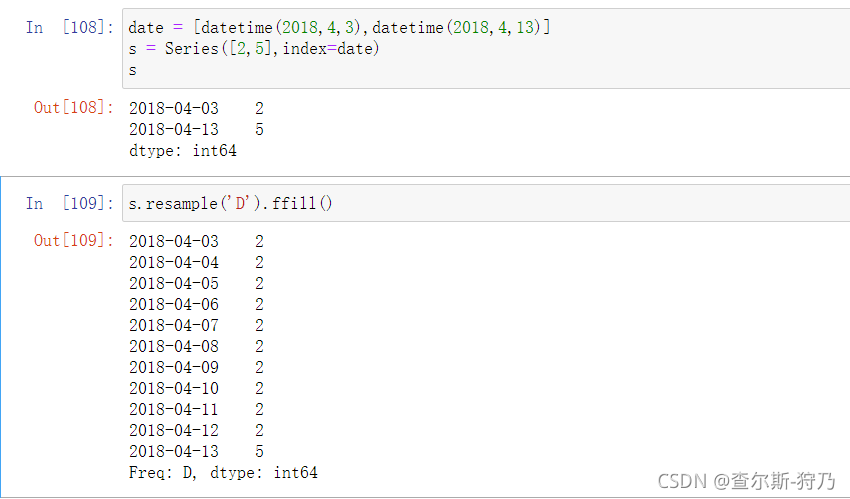
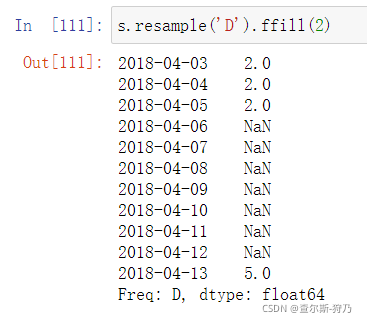
在升采样中用到的就不再是聚合,而是需要对缺失值进行填充,其填充方法与前面介绍的fillna一样,如下图所示,也可以设置填充的个数。
8.6综合示例-自行车租赁数据
8.6.1数据来源
该案例使用的数据及可在Kaggle(https://www.kaggle.com/c/bike/-sharing-demand/data)网站中下载,这里下载训练集。
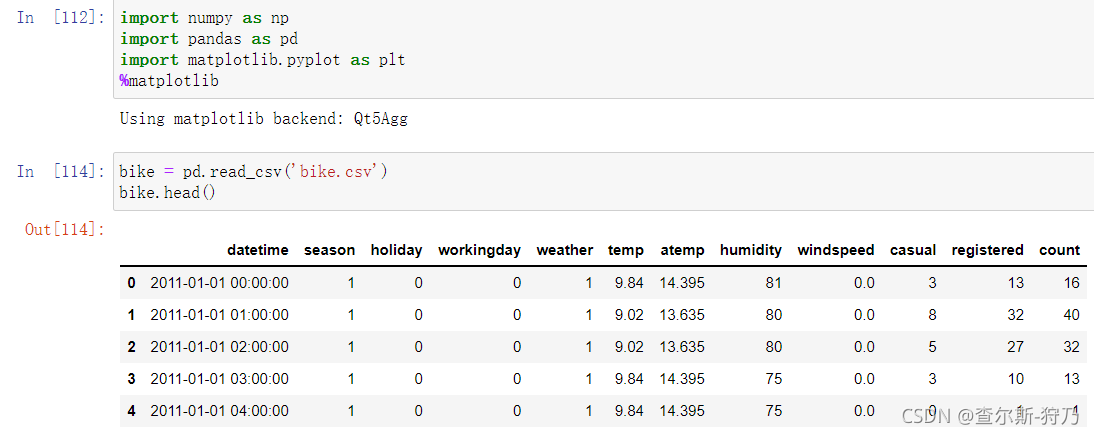
数据说明:datetime为租赁时间:season为季节,1为春季,2为夏季以此类推:holiday表示是否为假期:0为非假期,1为假期:workingday与holday值正好相反,0为非工作日,1为工作日:weather为天气情况,数字越大,天气越差;temp和atemp为气温;humidity为湿度;windspeed为风俗;casual为普通用户;registered为注册用户;count为租赁自行车数量。读取文件如下:
8.6.2定义问题
本次分析围绕时间提出问题:时间段与自行车租赁的关系情况
8.6.3数据清洗
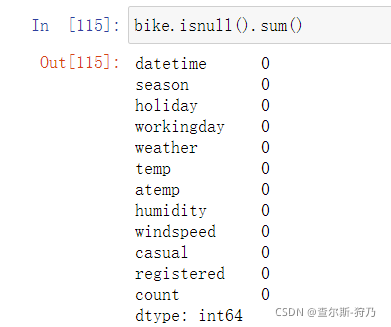
查看缺失值,如下图可以看出没有缺失值。
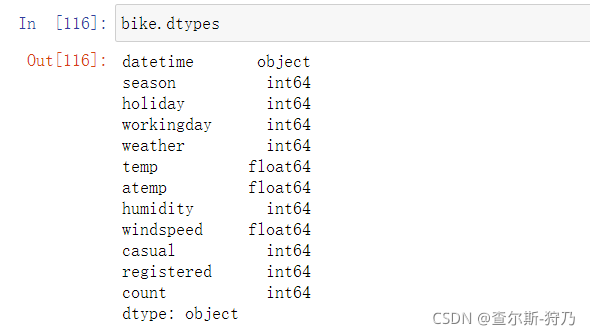
然后查看各字段数据类型,发现datetime字段不是时间数据类型,如下图
此时利用pd.to_datetime函数将其转换为datetime类数据,如下图

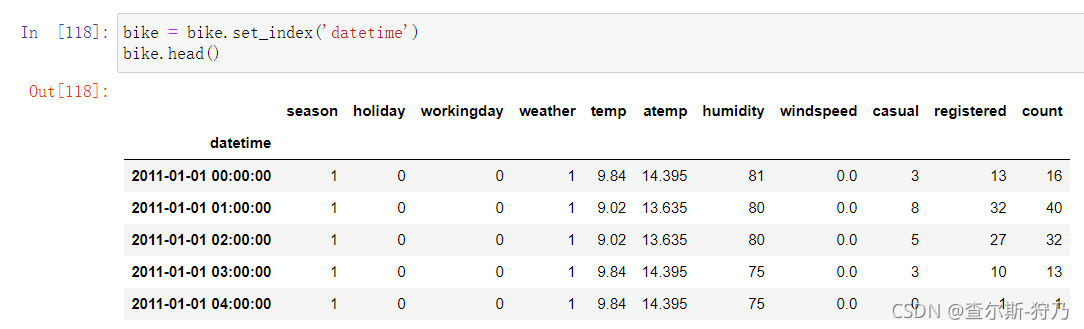
最后将datetime字段设置为DataFrame的索引,这样就成为了时间序列数据,如下图
8.6.4数据探索
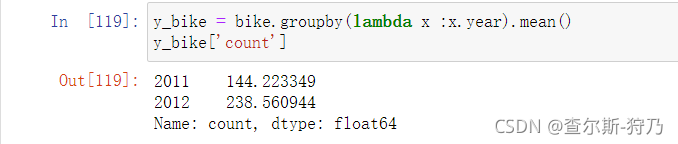
首先利用groupby方法也可以进行降采样,这里降采样到年份数据,如下图可以看出,2012年的租赁要高于2011年
然后通过下面的代码绘制柱状图:


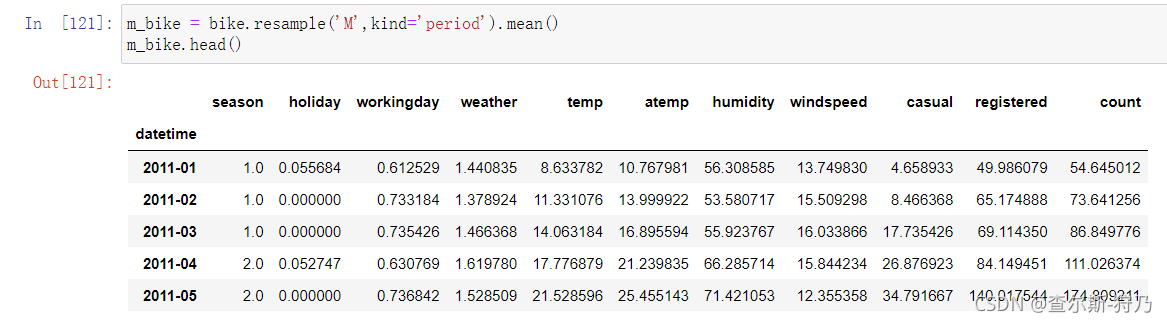
接着再利用resample方法,将数据重采样到月份,类型为时期类型,如下图
然后利用plot方法绘制时间序列图,如下图由图可知,2011年和2012年去世大致相同,前几个月增加,到了5、6月达到峰值,再到9月份减少


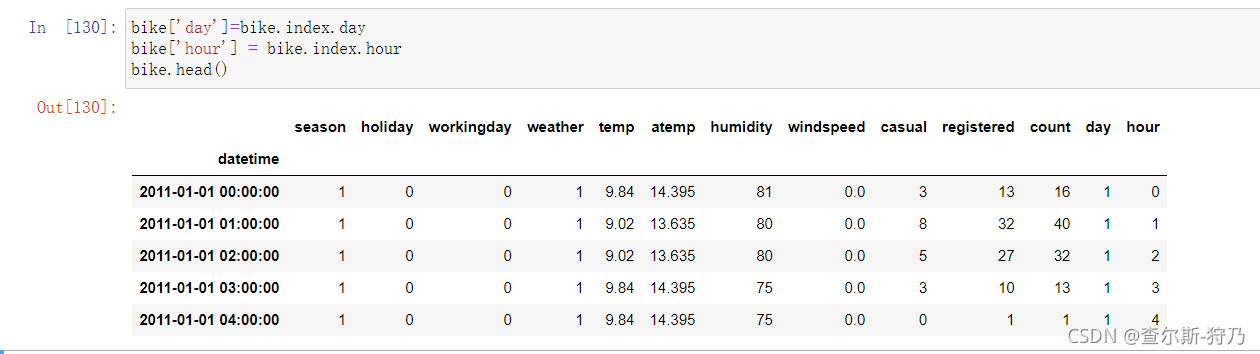
为了分析每天和每小时的租赁分布情况,对日(day)和时(hour)的数据进行单独存储如下图
然后对day字段进行分组统计,如下图
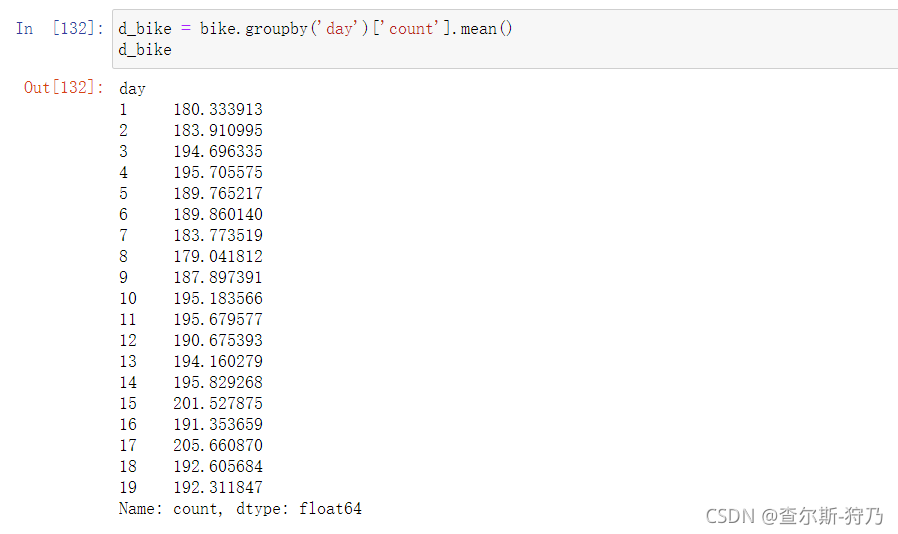
注意:训练数据只有前19天
进行可视化


同样的,在对hour字段和weather字段进行上述处理。这里不再展示。