全网最详细的大数据ELK文章系列,强烈建议收藏加关注!
新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。
目录
猎聘网职位搜索案例
一、需求
数据集介绍
二、创建索引
1、创建带有映射的索引
2、字段的类型
3、创建保存职位信息的索引
4、查看索引映射
5、查看Elasticsearch中的所有索引
6、删除索引
7、指定使用IK分词器
三、添加一个职位数据
1、需求
2、PUT请求
3、添加职位信息请求
四、修改职位薪资
1、需求
2、执行update操作
五、删除一个职位数据
1、需求
2、DELETE操作
六、批量导入JSON数据
1、bulk导入
2、查看索引状态
七、根据ID检索指定职位数据
1、需求
2、实现
八、根据关键字搜索数据
1、需求
2、实现
九、根据关键字分页搜索
1、使用from和size来进行分页
2、使用scroll方式进行分页
猎聘网职位搜索案例
一、需求
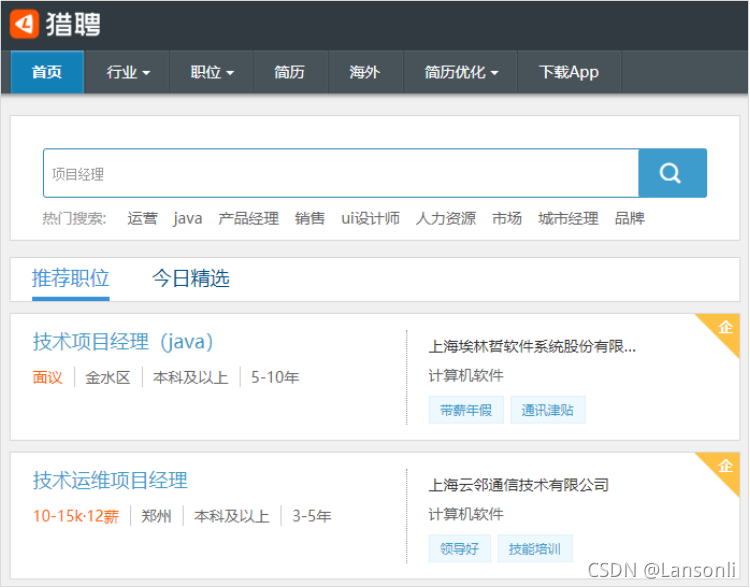
本次案例,要实现一个类似于猎聘网的案例,用户通过搜索相关的职位关键字,就可以搜索到相关的工作岗位。我们已经提前准备好了一些数据,这些数据是通过爬虫爬取的数据,这些数据存储在CSV文本文件中。我们需要基于这些数据建立索引,供用户搜索查询。
数据集介绍
| 字段名 | 说明 | 数据 |
| doc_id | 唯一标识(作为文档ID) | 29097 |
| area | 职位所在区域 | 工作地区:深圳-南山区 |
| exp | 岗位要求的工作经验 | 1年经验 |
| edu | 学历要求 | 大专以上 |
| salary | 薪资范围 | ¥ 6-8千/月 |
| job_type | 职位类型(全职/兼职) | 实习 |
| cmp | 公司名 | 乐有家 |
| pv | 浏览量 | 61.6万人浏览过 / 14人评价 / 113人正在关注 |
| title | 岗位名称 | 桃园 深大销售实习 岗前培训 |
| jd | 职位描述 | 【薪酬待遇】 本科薪酬7500起 大专薪酬6800起 以上无业绩要求,同时享有业绩核算比例55%~80% 人均月收入超1.3万 【岗位职责】 1.爱学习,有耐心: 通过公司系统化培训熟悉房地产基本业务及相关法律、金融知识,不功利服务客户,耐心为客户在房产交易中遇到的各类问题; 2.会聆听,会提问: 详细了解客户的核心诉求,精准匹配合适的产品信息,具备和用户良好的沟通能力,有团队协作意识和服务意识; 3.爱琢磨, |
二、创建索引
为了能够搜索职位数据,我们需要提前在Elasticsearch中创建索引,然后才能进行关键字的检索。这里先回顾下,我们在MySQL中创建表的过程。在MySQL中,如果我们要创建一个表,我们需要指定表的名字,指定表中有哪些列、列的类型是什么。同样,在Elasticsearch中,也可以使用类似的方式来定义索引。
1、创建带有映射的索引
Elasticsearch中,我们可以使用RESTful API(http请求)来进行索引的各种操作。创建MySQL表的时候,我们使用DDL来描述表结构、字段、字段类型、约束等。在Elasticsearch中,我们使用Elasticsearch的DSL来定义——使用JSON来描述。例如:
PUT /my-index
{
"mapping": {
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
} 
2、字段的类型
在Elasticsearch中,每一个字段都有一个类型(type)。以下为Elasticsearch中可以使用的类型:
| 分类 | 类型名称 | 说明 |
| 简单类型 | text | 需要进行全文检索的字段,通常使用text类型来对应邮件的正文、产品描述或者短文等非结构化文本数据。分词器先会将文本进行分词转换为词条列表。将来就可以基于词条来进行检索了。文本字段不能用户排序、也很少用户聚合计算。 |
|
| keyword | 使用keyword来对应结构化的数据,如ID、电子邮件地址、主机名、状态代码、邮政编码或标签。可以使用keyword来进行排序或聚合计算。注意:keyword是不能进行分词的。 |
|
| date | 保存格式化的日期数据,例如:2015-01-01或者2015/01/01 12:10:30。在Elasticsearch中,日期都将以字符串方式展示。可以给date指定格式:”format”: “yyyy-MM-dd HH:mm:ss” |
|
| long/integer/short/byte | 64位整数/32位整数/16位整数/8位整数 |
|
| double/float/half_float | 64位双精度浮点/32位单精度浮点/16位半进度浮点 |
|
| boolean | “true”/”false” |
|
| ip | IPV4(192.168.1.110)/IPV6(192.168.0.0/16) |
| JSON分层嵌套类型 | object | 用于保存JSON对象 |
|
| nested | 用于保存JSON数组 |
| 特殊类型 | geo_point | 用于保存经纬度坐标 |
|
| geo_shape | 用于保存地图上的多边形坐标 |
3、创建保存职位信息的索引
- 使用PUT发送PUT请求
- 索引名为 /job_idx
- 判断是使用text、还是keyword,主要就看是否需要分词
| 字段 | 类型 |
| area | text |
| exp | text |
| edu | keyword |
| salary | keyword |
| job_type | keyword |
| cmp | text |
| pv | keyword |
| title | text |
| jd | text |
创建索引:
PUT /job_idx
{
"mappings": {
"properties" : {
"area": { "type": "text", "store": true},
"exp": { "type": "text", "store": true},
"edu": { "type": "keyword", "store": true},
"salary": { "type": "keyword", "store": true},
"job_type": { "type": "keyword", "store": true},
"cmp": { "type": "text", "store": true},
"pv": { "type": "keyword", "store": true},
"title": { "type": "text", "store": true},
"jd": { "type": "text", "store": true}
}
}
}
4、查看索引映射
使用GET请求查看索引映射
// 查看索引映射
GET /job_idx/_mapping
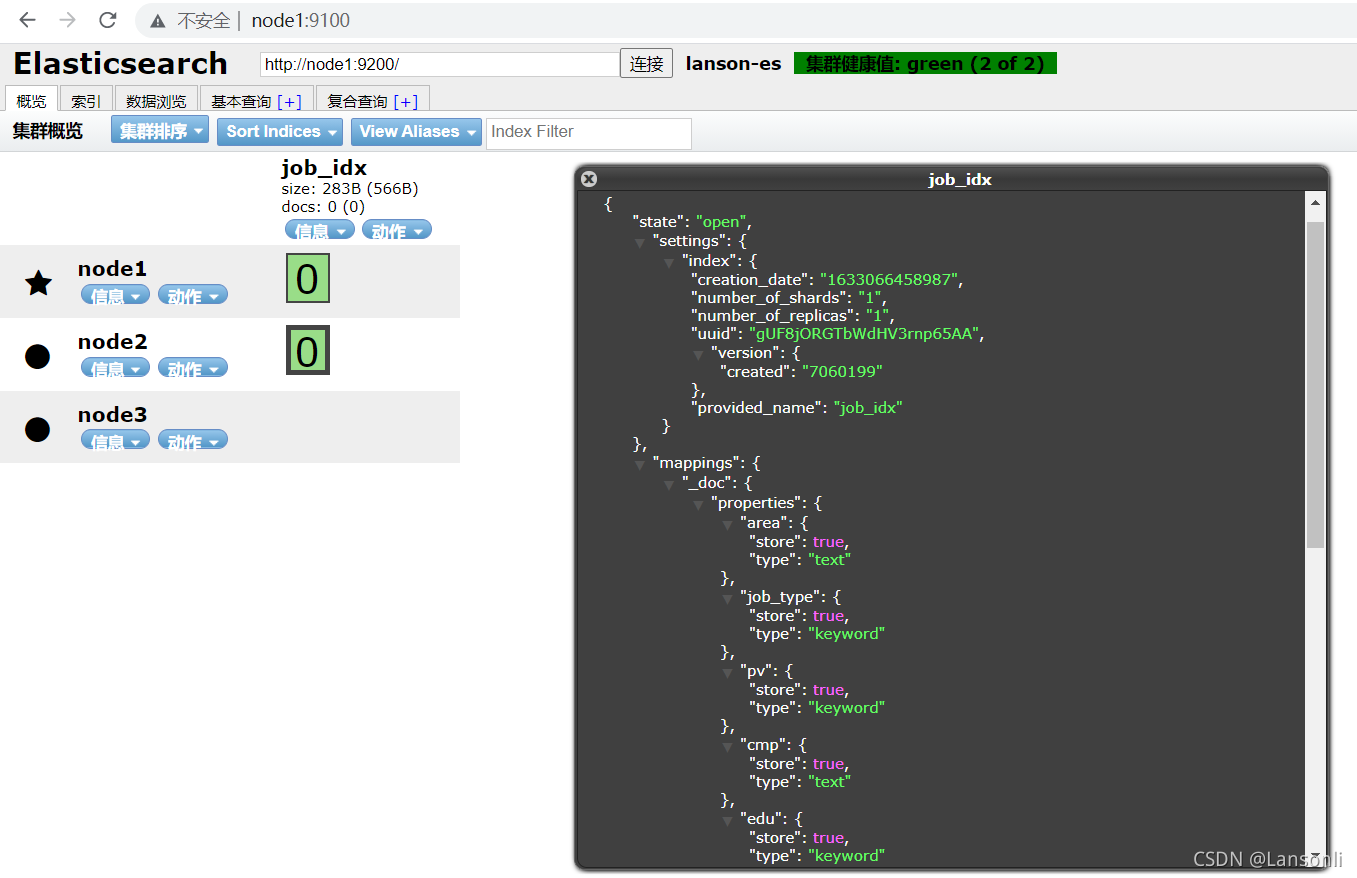
使用head插件也可以查看到索引映射信息
5、查看Elasticsearch中的所有索引
GET _cat/indices 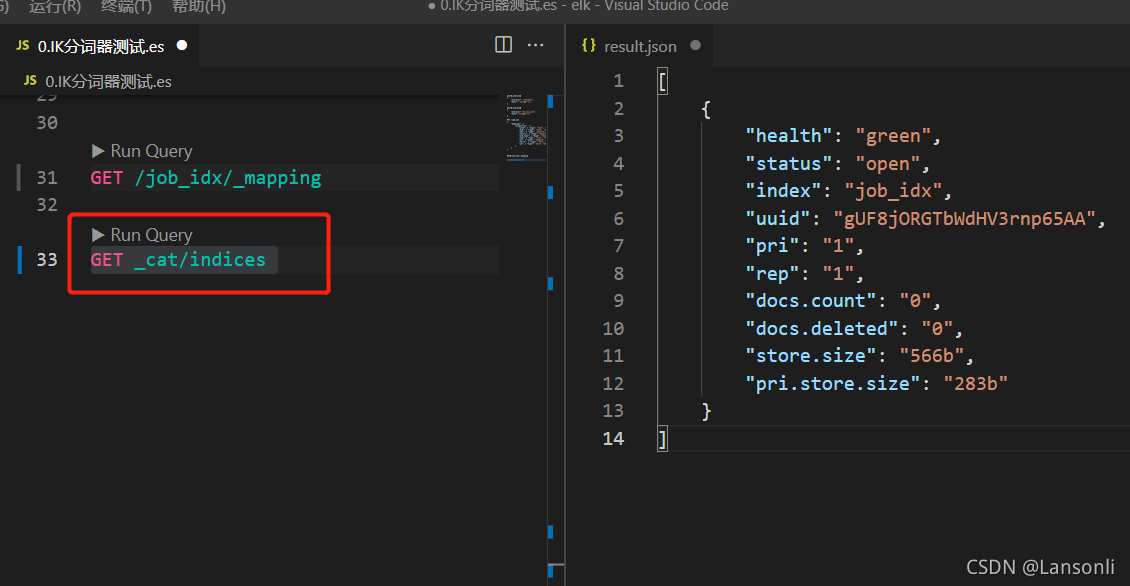
6、删除索引
delete /job_idx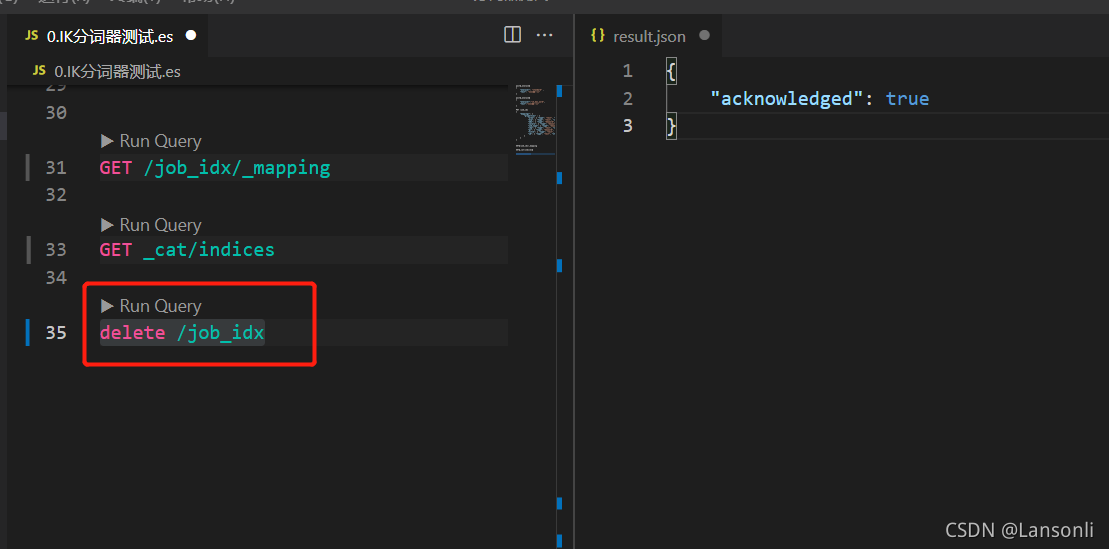
7、指定使用IK分词器
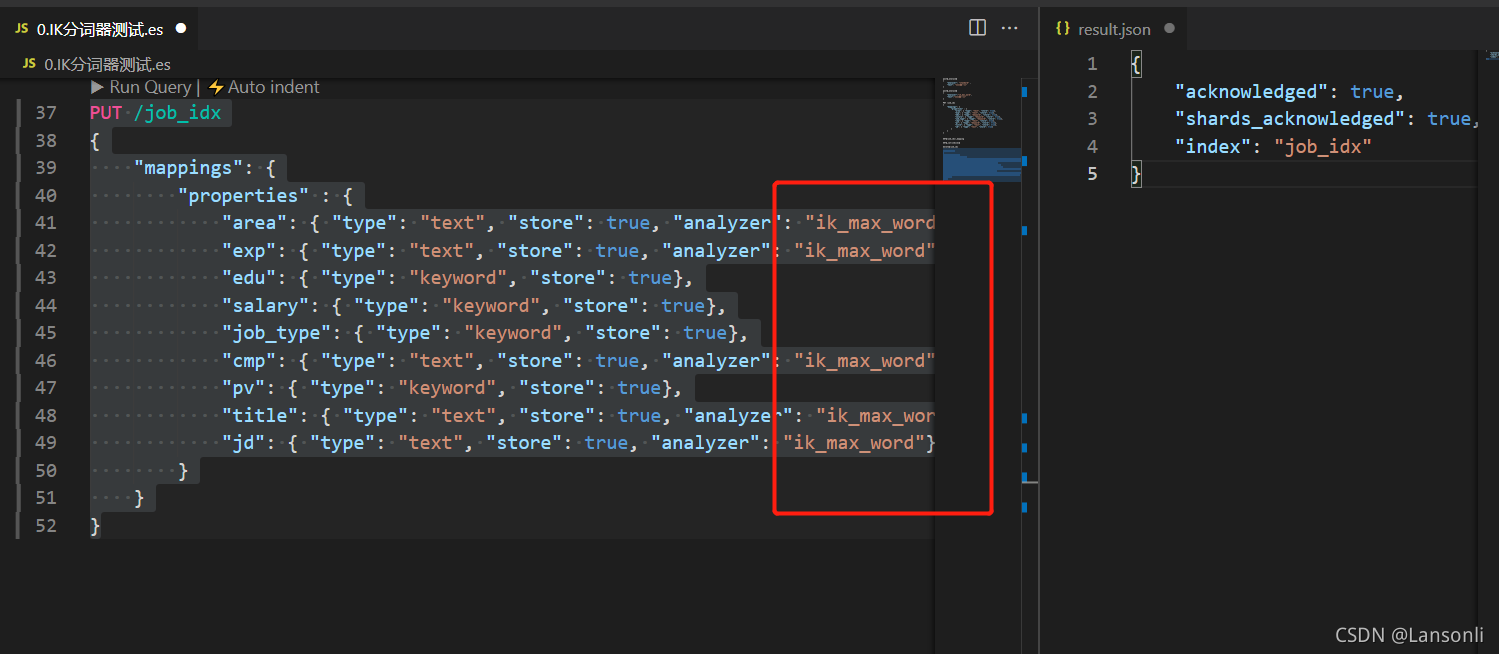
因为存放在索引库中的数据,是以中文的形式存储的。所以,为了有更好地分词效果,我们需要使用IK分词器来进行分词。这样,将来搜索的时候才会更准确。
PUT /job_idx
{
"mappings": {
"properties" : {
"area": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"exp": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"edu": { "type": "keyword", "store": true},
"salary": { "type": "keyword", "store": true},
"job_type": { "type": "keyword", "store": true},
"cmp": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"pv": { "type": "keyword", "store": true},
"title": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"jd": { "type": "text", "store": true, "analyzer": "ik_max_word"}
}
}
}
三、添加一个职位数据
1、需求
我们现在有一条职位数据,需要添加到Elasticsearch中,后续还需要能够在Elasticsearch中搜索这些数据。
| 29097, 工作地区:深圳-南山区, 1年经验, 大专以上, ¥ 6-8千/月, 实习, 乐有家, 61.6万人浏览过 / 14人评价 / 113人正在关注, 桃园 深大销售实习 岗前培训, 【薪酬待遇】 本科薪酬7500起 大专薪酬6800起 以上无业绩要求,同时享有业绩核算比例55%~80% 人均月收入超1.3万 【岗位职责】 1.爱学习,有耐心: 通过公司系统化培训熟悉房地产基本业务及相关法律、金融知识,不功利服务客户,耐心为客户在房产交易中遇到的各类问题; 2.会聆听,会提问: 详细了解客户的核心诉求,精准匹配合适的产品信息,具备和用户良好的沟通能力,有团队协作意识和服务意识; 3.爱琢磨,善思考: 热衷于用户心理研究,善于从用户数据中提炼用户需求,利用个性化、精细化运营手段,提升用户体验。 【岗位要求】 1.18-26周岁,自考大专以上学历; 2.具有良好的亲和力、理解能力、逻辑协调和沟通能力; 3.积极乐观开朗,为人诚实守信,工作积极主动,注重团队合作; 4.愿意服务于高端客户,并且通过与高端客户面对面沟通有意愿提升自己的综合能力; 5.愿意参加公益活动,具有爱心和感恩之心。 【培养路径】 1.上千堂课程;房产知识、营销知识、交易知识、法律法规、客户维护、目标管理、谈判技巧、心理学、经济学; 2.成长陪伴:一对一的师徒辅导 3.线上自主学习平台:乐有家学院,专业团队制作,每周大咖分享 4.储备及管理课堂: 干部训练营、月度/季度管理培训会 【晋升发展】 营销【精英】发展规划:A1置业顾问-A6资深置业专家 营销【管理】发展规划:(入职次月后就可竞聘) 置业顾问-置业经理-店长-营销副总经理-营销副总裁-营销总裁 内部【竞聘】公司职能岗位:如市场、渠道拓展中心、法务部、按揭经理等都是内部竞聘 【联系人】 小明主任15888888888(微信同号) |
2、PUT请求
前面我们已经创建了索引。接下来,我们就可以往索引库中添加一些文档了。可以通过PUT请求直接完成该操作。在Elasticsearch中,每一个文档都有唯一的ID。也是使用JSON格式来描述数据。例如:
PUT /customer/_doc/1
{
"name": "John Doe"
}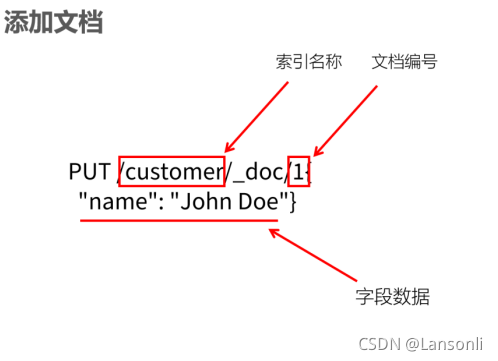
如果在customer中,不存在ID为1的文档,Elasticsearch会自动创建
3、添加职位信息请求
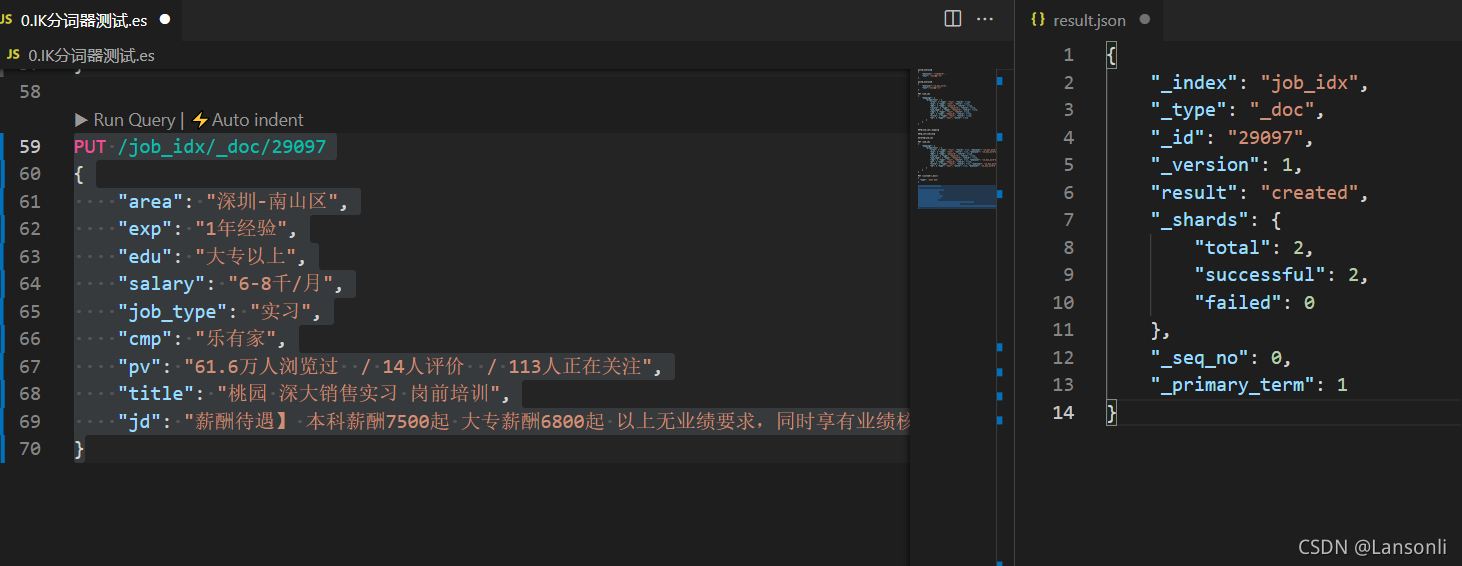
PUT /job_idx/_doc/29097
{
"area": "深圳-南山区",
"exp": "1年经验",
"edu": "大专以上",
"salary": "6-8千/月",
"job_type": "实习",
"cmp": "乐有家",
"pv": "61.6万人浏览过 / 14人评价 / 113人正在关注",
"title": "桃园 深大销售实习 岗前培训",
"jd": "薪酬待遇】 本科薪酬7500起 大专薪酬6800起 以上无业绩要求,同时享有业绩核算比例55%~80% 人均月收入超1.3万 【岗位职责】 1.爱学习,有耐心: 通过公司系统化培训熟悉房地产基本业务及相关法律、金融知识,不功利服务客户,耐心为客户在房产交易中遇到的各类问题; 2.会聆听,会提问: 详细了解客户的核心诉求,精准匹配合适的产品信息,具备和用户良好的沟通能力,有团队协作意识和服务意识; 3.爱琢磨,善思考: 热衷于用户心理研究,善于从用户数据中提炼用户需求,利用个性化、精细化运营手段,提升用户体验。 【岗位要求】 1.18-26周岁,自考大专以上学历; 2.具有良好的亲和力、理解能力、逻辑协调和沟通能力; 3.积极乐观开朗,为人诚实守信,工作积极主动,注重团队合作; 4.愿意服务于高端客户,并且通过与高端客户面对面沟通有意愿提升自己的综合能力; 5.愿意参加公益活动,具有爱心和感恩之心。 【培养路径】 1.上千堂课程;房产知识、营销知识、交易知识、法律法规、客户维护、目标管理、谈判技巧、心理学、经济学; 2.成长陪伴:一对一的师徒辅导 3.线上自主学习平台:乐有家学院,专业团队制作,每周大咖分享 4.储备及管理课堂: 干部训练营、月度/季度管理培训会 【晋升发展】 营销【精英】发展规划:A1置业顾问-A6资深置业专家 营销【管理】发展规划:(入职次月后就可竞聘) 置业顾问-置业经理-店长-营销副总经理-营销副总裁-营销总裁 内部【竞聘】公司职能岗位:如市场、渠道拓展中心、法务部、按揭经理等都是内部竞聘 【联系人】 小明主任15888888888(微信同号)"
}Elasticsearch响应结果:
{
"_index": "job_idx",
"_type": "_doc",
"_id": "29097",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
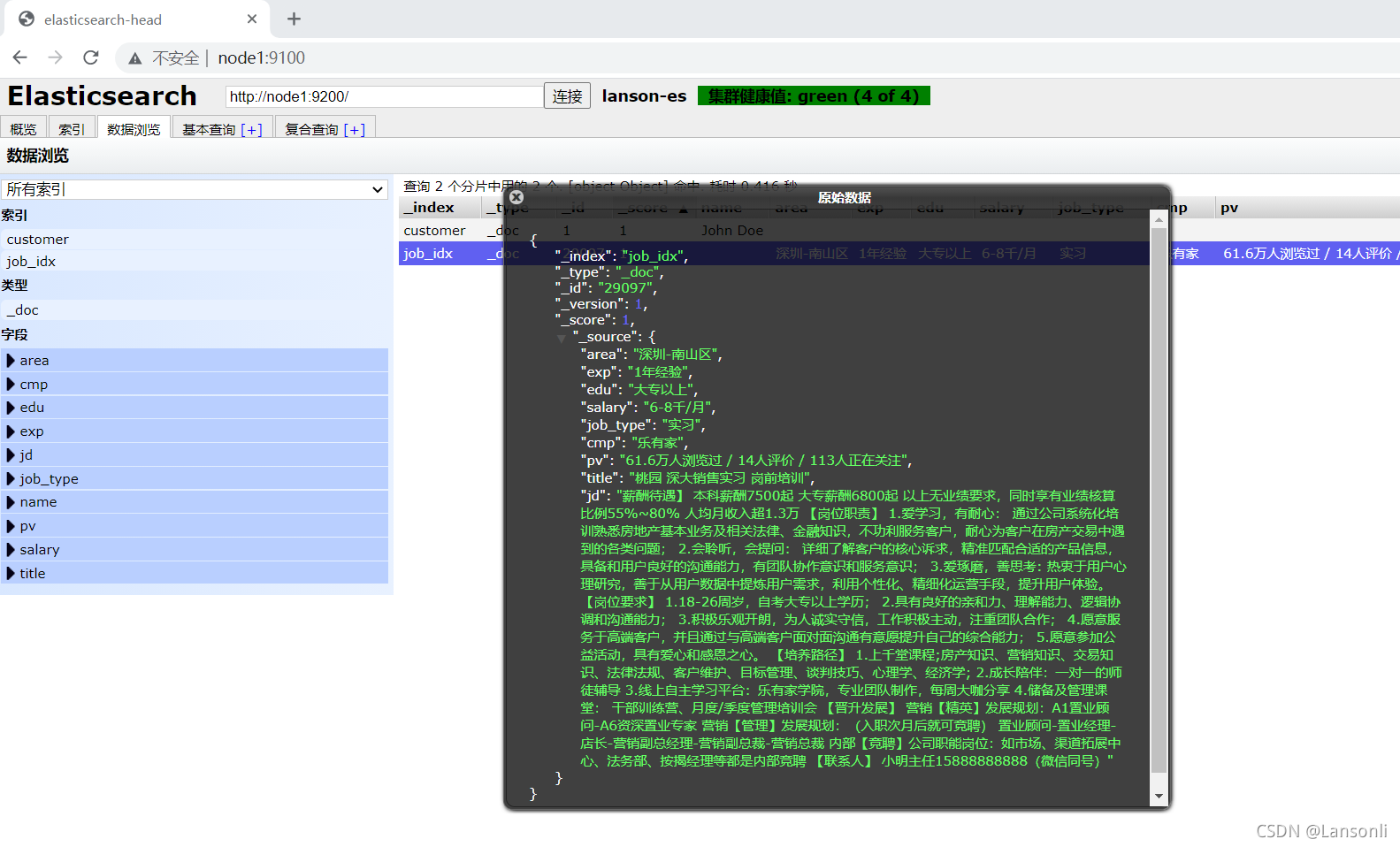
使用ES-head插件浏览数据:
四、修改职位薪资
1、需求
因为公司招不来人,需要将原有的薪资6-8千/月,修改为15-20千/月
2、执行update操作
POST /job_idx/_update/29097
{
"doc": {
"salary": "15-20k/月"
}
}
五、删除一个职位数据
1、需求
ID为29097的职位,已经被取消。所以,我们需要在索引库中也删除该岗位。
2、DELETE操作
DELETE /job_idx/_doc/29097
六、批量导入JSON数据
1、bulk导入
为了方便后面的测试,我们需要先提前导入一些测试数据到ES中。在资料文件夹中有一个job_info.json数据文件。我们可以使用Elasticsearch中自带的bulk接口来进行数据导入。
- 上传JSON数据文件到Linux
- 执行导入命令
curl -H "Content-Type: application/json" -XPOST "node1:9200/job_idx/_bulk?pretty&refresh" --data-binary "@job_info.json"
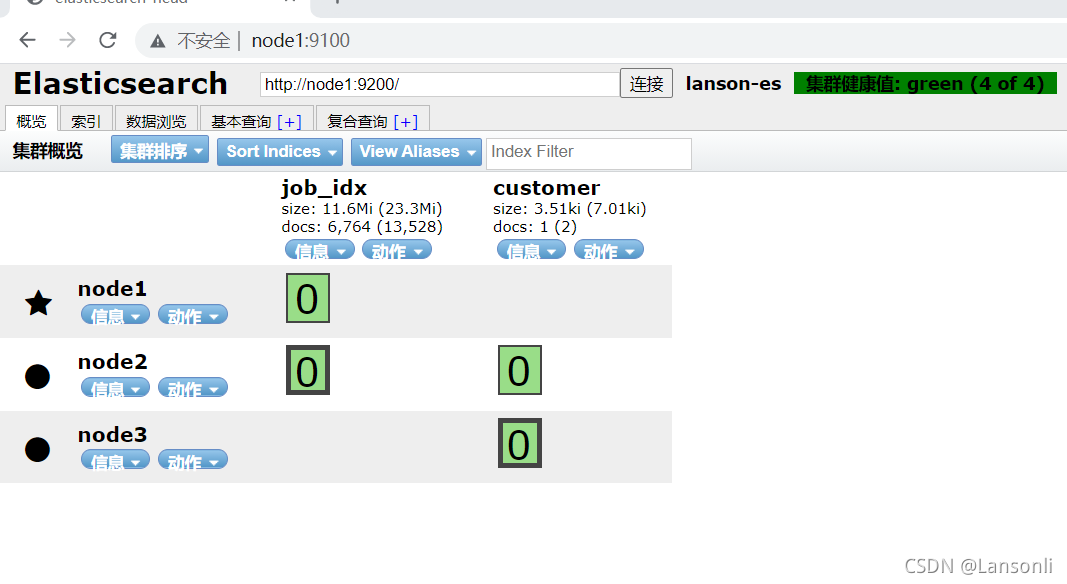
2、查看索引状态
GET _cat/indices?index=job_idx通过执行以上请求,Elasticsearch返回数据如下:
[
{
"health": "green",
"status": "open",
"index": "job_idx",
"uuid": "LS0fkOS3SWGlOCp5u28yIA",
"pri": "1",
"rep": "1",
"docs.count": "6764",
"docs.deleted": "0",
"store.size": "23.2mb",
"pri.store.size": "11.6mb"
}
]
七、根据ID检索指定职位数据
1、需求
用户提交一个文档ID,Elasticsearch将ID对应的文档直接返回给用户。
2、实现
在Elasticsearch中,可以通过发送GET请求来实现文档的查询。

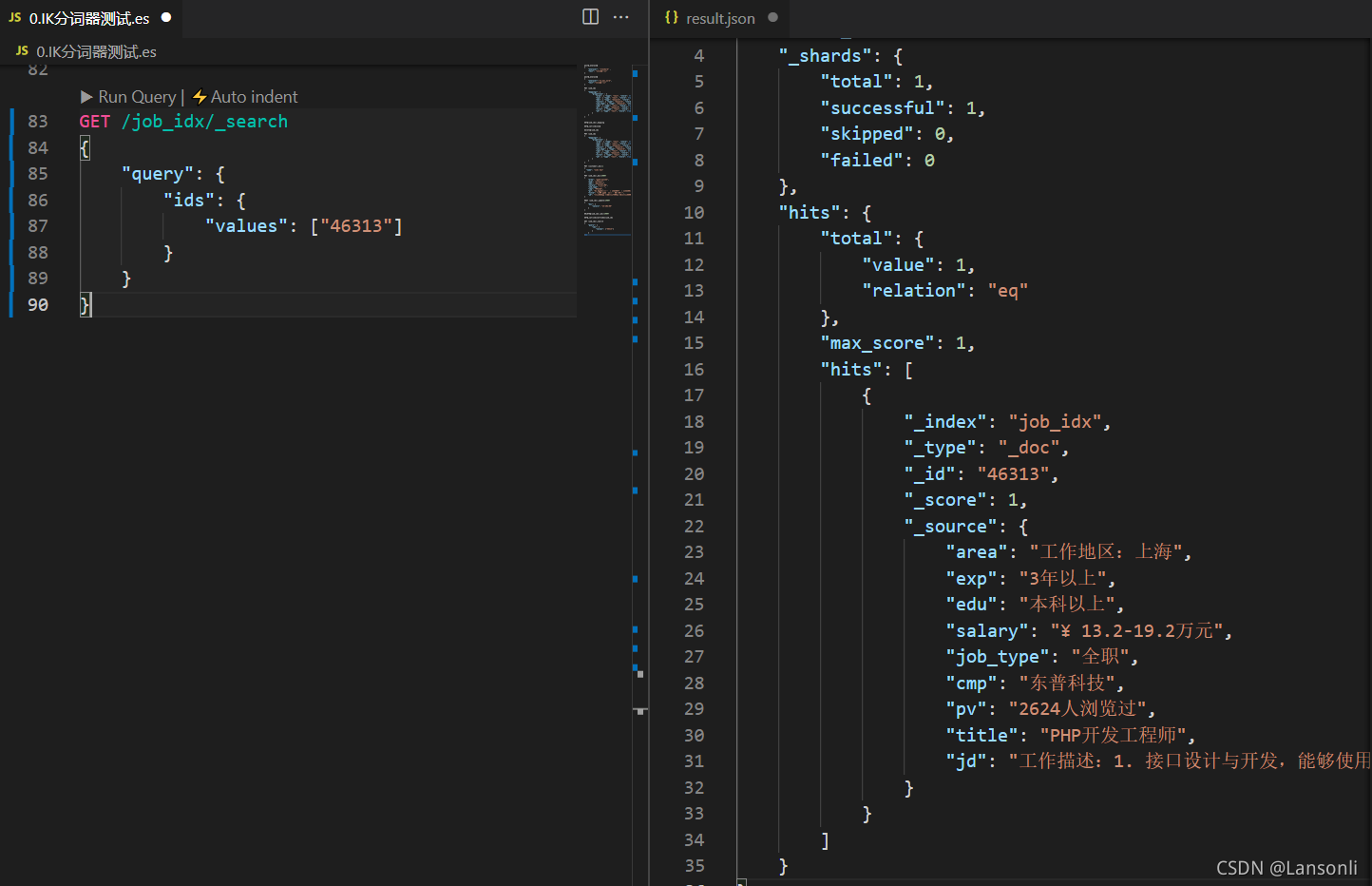
GET /job_idx/_search
{
"query": {
"ids": {
"values": ["46313"]
}
}
}
八、根据关键字搜索数据
1、需求
搜索职位中带有「销售」关键字的职位
2、实现
检索jd中销售相关的岗位
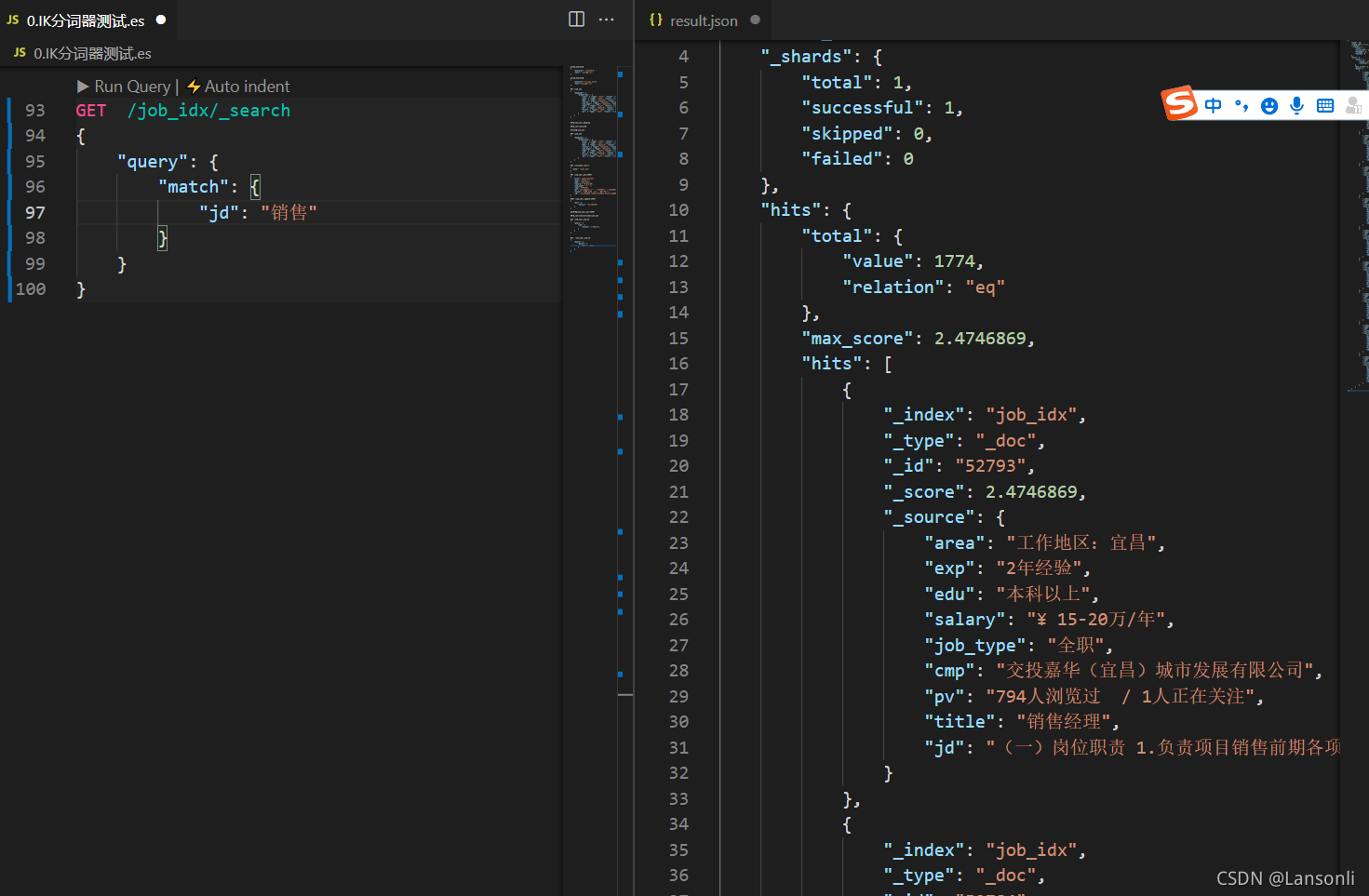
GET /job_idx/_search
{
"query": {
"match": {
"jd": "销售"
}
}
}
除了检索职位描述字段以外,我们还需要检索title中包含销售相关的职位,所以,我们需要进行多字段的组合查询。
GET /job_idx/_search
{
"query": {
"multi_match": {
"query": "销售前期各项资料统筹亚马逊",
"fields": [
"title",
"jd"
]
}
}
}更多地查询:
官方地址:开始使用 Elasticsearch | Elastic Videos
九、根据关键字分页搜索
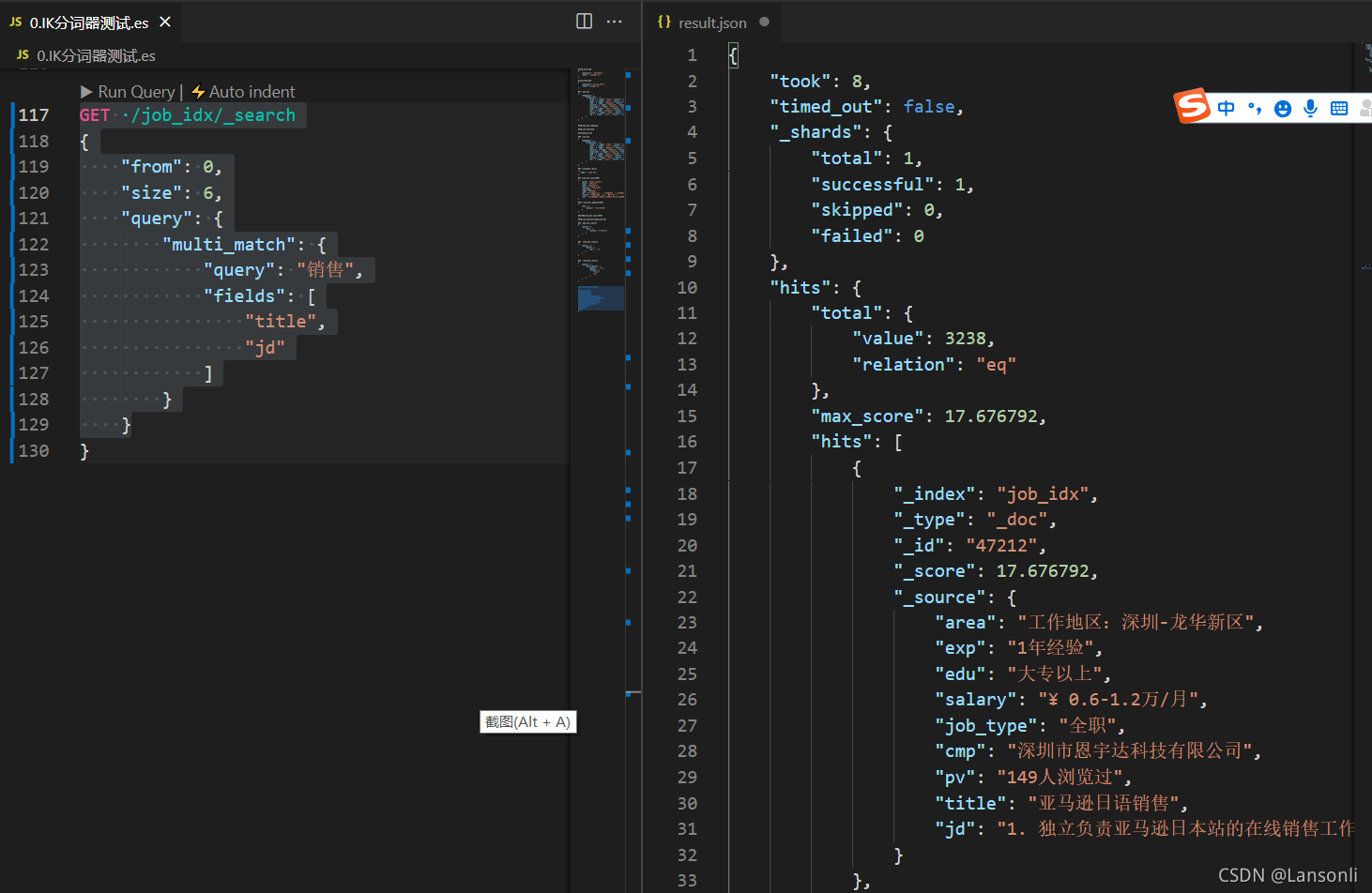
1、使用from和size来进行分页
在执行查询时,可以指定from(从第几条数据开始查起)和size(每页返回多少条)数据,就可以轻松完成分页。
from = (page – 1) * size
GET /job_idx/_search
{
"from": 0,
"size": 6,
"query": {
"multi_match": {
"query": "销售",
"fields": [
"title",
"jd"
]
}
}
2、使用scroll方式进行分页
前面使用from和size方式,查询在1W-5W条数据以内都是OK的,但如果数据比较多的时候,会出现性能问题。Elasticsearch做了一个限制,不允许查询的是10000条以后的数据。如果要查询1W条以后的数据,需要使用Elasticsearch中提供的scroll游标来查询。
在进行大量分页时,每次分页都需要将要查询的数据进行重新排序,这样非常浪费性能。使用scroll是将要用的数据一次性排序好,然后分批取出。性能要比from + size好得多。使用scroll查询后,排序后的数据会保持一定的时间,后续的分页查询都从该快照取数据即可。
1)第一次使用scroll分页查询
此处,我们让排序的数据保持1分钟,所以设置scroll为1m
GET /job_idx/_search?scroll=1m
{
"query": {
"multi_match": {
"query": "销售",
"fields": ["title", "jd"]
}
},
"size": 100
}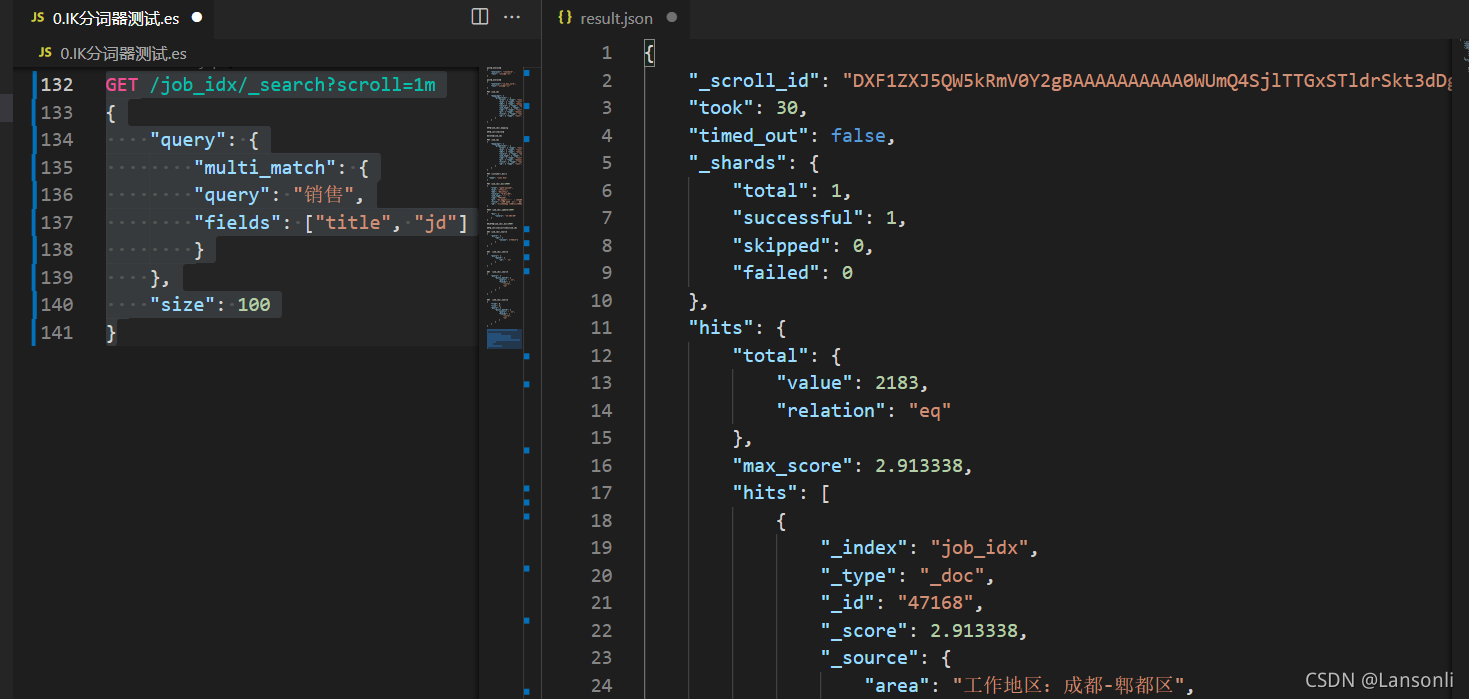
执行后,我们注意到,在响应结果中有一项:
"_scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAA0WUmQ4SjlTTGxSTldrSkt3dDg1eHRuQQ=="
后续,我们需要根据这个_scroll_id来进行查询
2)第二次直接使用scroll id进行查询
GET _search/scroll?scroll=1m
{
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAA4WUmQ4SjlTTGxSTldrSkt3dDg1eHRuQQ=="
}
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨