
开篇语:
我们在《一篇速学企业linux awk命令详解与应用(上篇)》中介绍了 awk 的基本用法,其实在awk 脚本程序中,还支持使用一些编程语言,比如变量、数组、分支结构(if-then-else)、循环结构(while)、函数等,本编文章将给大家做详细的讲解。
一、awk 数组的处理
关联数组跟数字数组不同之处在于它的索引值可以是任意文本字符串。不需要用连续的数字来标识数组中的数据元素。相反,关联数组用各种字符串来引用值。每个索引字符串都必须能够唯一地标识出赋给它的数据元素。如果熟悉其他编程语言的话,就知道这跟散列表和字典是同一个概念。
1.1 定义数组变量
语法格式:
var[index] = element其中 var 是变量名, index 是关联数组的索引值, element 是数据元素值。
capital["Illinois"] = "Springfield"
capital["Indiana"] = "Indianapolis"
capital["Ohio"] = "Columbus"a.在引用数组变量时,必须包含索引值来提取相应的数据元素值:

b.在引用数组变量时,会得到数据元素的值。数据元素值是数字值时也一样:

1.2 遍历数组变量
for (var in array)
{
statements
}这个 for 语句会在每次循环时将关联数组 array 的下一个索引值赋给变量 var ,然后执行一 次statements。注意:这个变量中存储的是索引值而不是数组元素值。可以将这个变量用作数组的索引,进而取出对应的数据元素值。
示例演示:
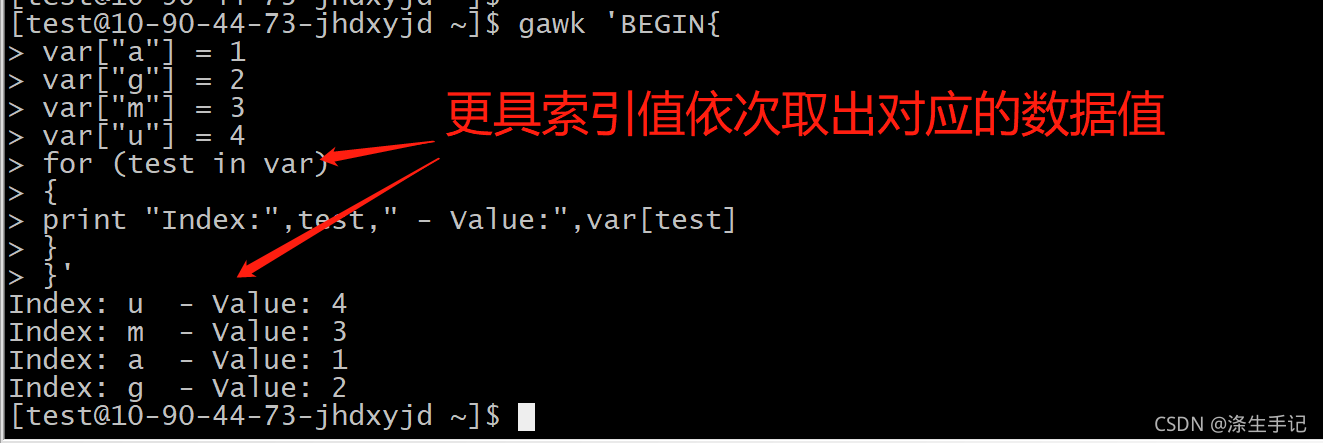
核心解说:
索引值不会按任何特定顺序返回,也就是说是无序的,返回的值不都是有固定的顺序的。但它们都能够指向对应的数据元素值,保证索引值和数据值是对应的。
1.3 删除数组变量
语法格式:
delete array [ index ]
注意:删除命令会从数组中删除关联索引值和相关的数据元素值。
操作演示:

二、awk 的使用模式
gawk程序支持多种类型的匹配模式来过滤数据记录,在上章节中我们介绍了 BEGIN 和 END 关键字是用来在读取数据流之前或之后执行命令的特殊模式。类似地,awk支持创建其他模式在数据流中出现匹配数据时执行一些命令,下面讲解gawk脚本中用匹配模式来限定程序脚本作用在哪些记录上。
2.1 正则表达式

正则表达式/6148/匹配了数据字段中含有字符串11的记录。
2.2 匹配操作符
匹配操作符(matching operator)允许将正则表达式限定在记录中的特定数据字段。匹配操 作符是波浪线(~)。可以指定匹配操作符、数据字段变量以及要匹配的正则表达式。
A:
$1 ~ /^data/
命令解说:
$1 变量代表记录中的第一个数据字段。这个表达式会过滤出第一个字段且以文本 data 开头的所有记录。

gawk程序脚本中经常用它在数据文件中搜索特定的数据元素,这个在工作中很常用的,希望大家练习掌握。

$1 !~ /expression/如果记录中没有找到匹配正则表达式的文本,程序脚本就会作用到记录数据。

2.3 数学表达式

上图显示所有属于root用户组(组ID为0)的系统用户。脚本会查看第四个数据字段含有值0的记录。在这个Linux系统中,有五个用户账户属于root用户组。
支持常见的数学比较表达式:
- x == y:值x等于y。
- x <= y:值x小于等于y。
- x < y:值x小于y。
- x >= y:值x大于等于y。
- x > y:值x大于y。

上图中我们可以看到,第一个测试没有匹配任何记录,因为第一个数据字段的值不在任何记录中。第二个测试用值3074匹配了一条记录。
核心总结:
对文本数据使用表达式时,表达式必须完全匹配。数据必须跟模式严格匹配。
三、awk 结构化命令
3.1 if 语句
gawk编程语言支持标准的if-then-else格式的if语句。你必须为if语句定义一个求值的 条件,并将其用圆括号括起来。如果条件求值为TRUE,紧跟在if语句后的语句会执行。如果 件求值为FALSE,这条语句就会被跳过。
if (condiion)statement1也可以将它放在一行上,像这样:if ( condition ) statement

如果需要在if语句中执行多条语句,就必须用花括号将它们括起来。如下示例:

gawk的if语句也支持else子句,允许在if语句条件不成立的情况下执行一条或多条语句。
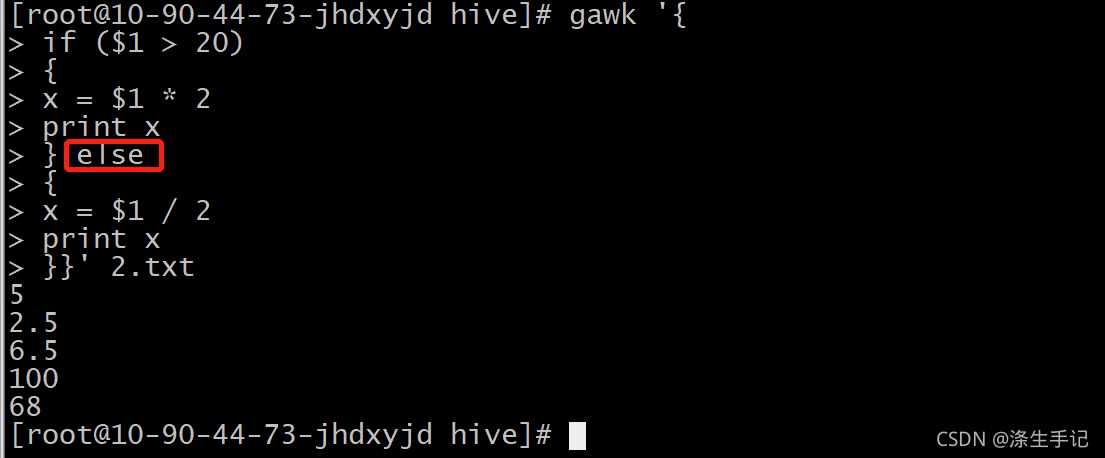
单行上使用else子句时,必须在if语句部分之后使用分号。
if ( condition ) statement1 ; else statement2

3.2 while 语句
while 语句为 gawk 程序提供了一个基本的循环功能。
语法格式:
while (condition)
{
statements
}
演示2:

脚本解说:
while 语句会遍历记录中的数据字段,将每个值都加到 total 变量上,并将计数器变量 i 增值。当计数器值等于 4 时, while 的条件变成了 FALSE ,循环结束,然后执行脚本中的下一条语句。 这条语句会计算并打印出平均值。这个过程会在数据文件中的每条记录上不断重复。
gawk编程语言也支持在while循环中使用break语句和continue语句,允许从循环中跳出。

脚本解说:
break语句用来在i变量的值为2时从while循环中跳出。
3.3 do-while 语句
do-while语句类似于 while语句,不同点时会在检查条件语句之前执行命令,保证了语句会在条件被求值之前至少执行一次。当需要在求值条件前执行语句时,可以用到这个功能。
do
{
statements
} while (condition) 示例演示:
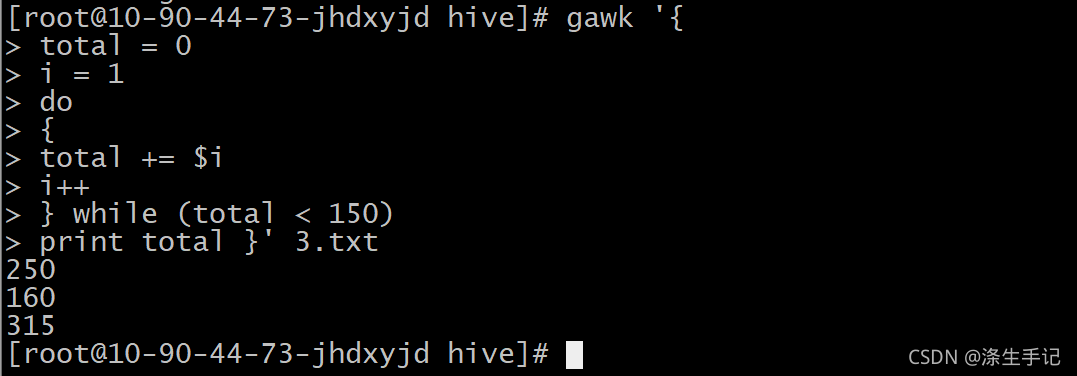
脚本解说:
这个脚本会读取每条记录的数据字段并将它们加在一起,直到累加结果达到 150 。如果第一个数据字段大于 150 (就像在第二条记录中看到的那样),则脚本会保证在条件被求值前至少读取第一个数据字段的内容。
3.4 for 语句
语法格式:
for (initialisation; condition; increment/decrement) action
for 语句首先执行初始化动作( initialisation ),然后再检查条件( condition )。如果条件为真,则执行动作( action ),然后执行递增( increment )或者递减( decrement )操作。只要条件为 true 循环就会一直执行。每次循环结束都会进条件检查,若条件为 false 则结束循环 。
演示1:

演示2:

四、awk 格式化输出
到目前为止,我们已经使用AWK的 print 和 printf 函数来显示在标准输出的数据。但 printf 比我们以前见过强大得多。这个函数是从C语言借来的,是非常有帮助的,同时产生格式化输出。
下面是 printf 语句的语法:
printf fmt, expr-list
在上面的语法fmt是格式规范和常量字符串。 expr-list是对应于格式说明符的参数列表。
4.1 结果换行输出

4.2 制表符(\t)分割输出

4.3 阶梯式输出

4.4 转换规范格式
a:【%c】
它打印一个字符。如果用于%c的参数是数字,它被视为一个字符和打印。否则,参数被假定为一个字符串,该字符串的唯一第一字符被打印。

b :【%d 和 %i】
打印整数部分:

c:【%f】
打印浮点数:

五、内建函数
gawk 编程语言提供了不少内置函数,可进行一些常见的数学、字符串以及时间函数运算。可以在gawk 程序中利用这些函数来减少脚本中的编码工作。下面将介绍一些少用的内建函数。
5.1 数学函数
- atan2(x, y) x/y的反正切,x和y以弧度为单位
- cos(x) x的余弦,x以弧度为单位
- exp(x) x的指数函数
- int(x) x的整数部分,取靠近零一侧的值
- log(x) x的自然对数
- rand( ) 比0大比1小的随机浮点值
- sin(x) x的正弦,x以弧度为单位
- sqrt(x) x的平方根
- srand(x) 为计算随机数指定一个种子值
x = int(10 * rand())
- and(v1, v2):执行值v1和v2的按位与运算。
- compl(val):执行val的补运算。
- lshift(val, count):将值val左移count位。
- or(v1, v2):执行值v1和v2的按位或运算。
- rshift(val, count):将值val右移count位。
- xor(v1, v2):执行值v1和v2的按位异或运算。
5.2 字符串函数
- asort(s [,d]) 将数组s按数据元素值排序。索引值会被替换成表示新的排序顺序的连续数字。另外,如果指定了d,则排序后的数组会存储在数组d中
- asorti(s [,d]) 将数组s按索引值排序。生成的数组会将索引值作为数据元素值,用连续数字索引来表明排序顺序。另外如果指定了d,排序后的数组会存储在数组d中
- gensub(r, s, h [, t]) 查找变量$0或目标字符串t(如果提供了的话)来匹配正则表达式r。如果h是一个以g 或G开头的字符串,就用s替换掉匹配的文本。如果h是一个数字,它表示要替换掉第h 处r匹配的地方
- gsub(r, s [,t]) 查找变量$0或目标字符串t(如果提供了的话)来匹配正则表达式r。如果找到了,就全部替换成字符串s
- index(s, t) 返回字符串t在字符串s中的索引值,如果没找到的话返回0
- length([s]) 返回字符串s的长度;如果没有指定的话,返回$0的长度
- match(s, r [,a]) 返回字符串s中正则表达式r出现位置的索引。如果指定了数组a,它会存储s中匹配正则表达式的那部分
- split(s, a [,r]) 将s用FS字符或正则表达式r(如果指定了的话)分开放到数组a中。返回字段的总数
- sprintf(format, variables) 用提供的format和variables返回一个类似于printf输出的字符串
- sub(r, s [,t]) 在变量$0或目标字符串t中查找正则表达式r的匹配。如果找到了,就用字符串s替换掉第一处匹配
- substr(s, i [,n]) 返回s中从索引值i开始的n个字符组成的子字符串。如果未提供n,则返回s剩下的部分
- tolower(s) 将s中的所有字符转换成小写
- toupper(s) 将s中的所有字符转换成大写

脚本解说:
上图脚本的含义是,取出文本的每行数据的第6个数值,并对此元素以'.'为分隔符进行分割,分割后的元素放在数组s中,打印s数组中第一位数据元素。
5.3 时间函数
常用时间函数列表:
- mktime(datespec) 将一个按YYYY MM DD HH MM SS [DST]格式指定的日期转换成时间戳值①
- strftime(format [,timestamp]) 将当前时间的时间戳或timestamp(如果提供了的话)转化格式化日期(采用shell 函数date()的格式)
- systime( ) 返回当前时间的时间戳
awk 'BEGIN{date = systime();day=strftime("%A,%B,%D",date);print day}'
该例用systime函数从系统获取当前的epoch时间戳,然后用strftime函数将它转换成用户可读的格式,转换过程中使用了shell命令date的日期格式化字符。
六、自定义函数
6.1 定义函数
function name([variables])
{
statements
}函数名必须能够唯一标识函数。可以在调用的gawk程序中传给这个函数一个或多个变量。
函数示例:
function printthird()
{
print $3
}return value
function myrand(limit)
{
return int(limit * rand())
}定义一个脚本文件,在里面编写自定义的函数(functions.awk):
# 返回最小值
function find_min(num1, num2)
{
if (num1 < num2)
return num1
return num2
}
# 返回最大值
function find_max(num1, num2)
{
if (num1 > num2)
return num1
return num2
}
# 主函数
function main(num1, num2)
{
# 查找最小值
result = find_min(10, 20)
print "Minimum =", result
# 查找最大值
result = find_max(10, 20)
print "Maximum =", result
}
# 脚本从这里开始执行
BEGIN {
main(10, 20)
}执行函数:awk -f functions.awk
最后分享一个处理实例:
[root@10-90-44-73-jhdxyjd hive]# cat scores.txt
Rich Blum,team1,100,115,95
Barbara Blum,team1,110,115,100
Christine Bresnahan,team2,120,115,118
Tim Bresnahan,team2,125,112,116[root@10-90-44-73-jhdxyjd hive]# cat bowling.sh
#!/bin/bash
for team in $(gawk –F, '{print $2}' scores.txt | uniq)
do
gawk –v team=$team 'BEGIN{FS=","; total=0}
{
if ($2==team)
{
total += $3 + $4 + $5;
}
}
END {
avg = total / 6;
print "Total for", team, "is", total, ",the average is",avg
}' scores.txt
done代码详解:
for循环中的第一条语句过滤出数据文件中的队名,然后使用uniq命令返回不重复的队名。for循环再对每个队进行迭代。for循环内部的gawk语句进行计算操作。对于每一条记录,首先确定队名是否和正在进行循环的队名相符。这是通过利用gawk的-v选项来实现的,该选项允许我们在gawk程序中传递shell变量。如果队名相符,代码会对数据记录中的三场比赛得分求和,然后将每条记录的值再相加, 只要数据记录属于同一队。
执行代码:

