线性表总结
文章目录
- 线性表总结
- 一,顺序表
- 1,头文件
- 2,C文件
- 3,测试菜单文件(menu)
- 4,顺序表的优缺点
- 二,单链表
- 1,头文件
- 2,C文件
- 3,测试文件
- 4,带头链表和不带头链表
- 三,双向链表
- 1,头文件
- 2,C文件
- 四,栈
- 1,栈的相关概念
- (1),定义
- (2),实现方式的选择
- 2,头文件
- 3,C文件
- 4,测试文件
- 五,队列
- 1,队列的相关概念
- (1),定义
- (2),实现方式的选择
- 1,头文件
- 2,C文件
- 3,测试文件
- 六,栈和队列的补充
- 七,二叉树
- 1,树的概念
- 2,前序,中序,后序遍历
- 3,二叉树的层序遍历
线性表:线性表是由n个数据特性相同的元素组成的有限序列。它是学习其他数据结构的基础。线性表在计算机中可以用顺序存储和链式存储两种存储结构来表示。其中,用顺序存储结构表示的是顺序表,用链式存储结构表示的是链表。(链表又有单链表,双向链表,循环链表之分)
一些前提知识:
1,因为以后可能会对代码进行改变,所以可以提前定义好一些后期可能会变的量。
比如:数组的大小,arr[100]。那么可以在开头#define N 100.
比如:数组的数据类型,int arr[10]。那么可以在开头typedef int SQDataType
这样以后要改的话,就直接在宏定义上进行修改就可以了。
(类型的定义就用typedef,变量的定义就用define)
2,对线性表进行增删改查的时候用的都是接口函数。
3,结构体的定义:
//关于结构体的定义,假设原先结构体的名字是seq,你想改成S
结构体的定义:
Struct seq
{
};
还有简便的是:
Typedef struct seq
{
}S;
Typedef struct seq S
{
};
这样都把原来的名字改成了自己想用的名字。
一,顺序表
顺序存储结构,是指用一段地址连续的存储单元依次存储线性表的数据元素。实际上我们是用数组来实现这种结构的。顺序表又分为静态顺序表和动态顺序表。静态顺序表的容量大小在开始时就是已经定义好了的。而动态顺序表的容量大小则是可以改变的。(本文中代码实现的是动态顺序表)
静态顺序表的缺点:容量必须在一开始定义好,如果定义少了不够用,如果定义多了用不完浪费,不能灵活控制。
1,头文件
可以先将头文件写好,这个头文件也就是起一个将条件准备完整的作用,
定义好简便的,可以及时修改的符号变量,(常变量是用const来修饰的)
定义好顺序表的结构体(类型名,数组的类型,大小)
定义好要等会要用的接口。然后在C文件中进行解释说明就行了。
代码实现:
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once//为了避免同一个头文件被包含(include)多次.
#include<assert.h>//因为C文件代码定义中使用了assert断言,引一下。
//常见的提前定义
//#define MAX_SIZE 10 如果是用静态数组实现的顺序表就可以用这个宏的定义,动态数组实现的顺序表就不需要定义最大值了。
#include<stdio.h>
#include<string.h>
#include<malloc.h>
#include<stdlib.h>
typedef int SQDataType;
//定义线性表
typedef struct SeqList
{
SQDataType* a;//数组
int size; //有效数据的个数
int capacity; //容量
}SL;
//增删改查等接口函数
void SeqListInit(SL* ps);//初始化
void SeqListPrint(SL* ps);//打印
void SeqListDestroy(SL* ps);//销毁空间
void SeqListPushFront(SL* ps, SQDataType x);//头插
void SeqListPushBack(SL* ps, SQDataType x);//尾插
void SeqListPopFront(SL* ps);//头删
void SeqListPopBack(SL* ps);//尾删
void SeqLisInsert(SL* ps, int pos, SQDataType x);//任意pos前插入数据
void SeqListErase(SL* ps, int pos);//删除pos位置数据
int SeqListFind(SL* ps,SQDataType x);//查找x数据
void SeqListModify(SL* ps, int pos, SQDataType x);//修改数据
void SeqListCheckCapacity(SL* ps);//检查储存空间并扩充储存空间
2,C文件
c文件中主要是h中的接口的定义。
代码实现:
#include "SeqList.h"//引一下刚才定义好的头文件
void SeqListInit(SL* ps)//初始化
{
ps->a = NULL;
ps->size = 0;
ps->capacity = 0;
//刚开始可以不给空间,也可以给一点点空间,这里选择不给空间了。
}
void SeqListCheckCapacity(SL* ps)//检查储存空间并扩充储存空间
{
if (ps->size >= ps->capacity)//如果存的数据大于等于数组的容量,这个时候有两种情况,一种就是原先的capacity就是空,那么无论存不存数据都会使这个条件成立。还有一种情况就是存储的数据真的超过了容量。这两种情况都需要扩容。
{
int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;//新建一个容量的数据,判断如果原先的数据是空,那么就直接分配4个数据,如果不是空,那么就把原来的数据变成扩两倍。
SQDataType* tmp = (SQDataType*)realloc(ps->a, newcapacity * sizeof(SQDataType));//使用realloc函数新建一个指定容量大小的空间。
if (tmp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
else
{
ps->a = tmp;//将建好的空间赋给数组。
ps->capacity = newcapacity;//将新容量赋给旧r
}
}
}
void SeqListPushBack(SL* ps, SQDataType x)//尾插
{
SeqListCheckCapacity(ps);
ps->a[ps->size] = x;
ps->size++;
//SeqListInsert(ps, ps->size, x);
}
void SeqListPrint(SL* ps)//打印
{
for (int i = 0; i < ps->size; i++)
{
printf("%d ", ps->a[i]);
//数组是这个结构体的,这个数组不是单独的个体,必须配合着ps结构体指针使用。
}
printf("\n");
}
void SeqListPushFront(SL* ps, SQDataType x)//头插
{
SeqListCheckCapacity(ps);
int end = ps->size - 1;
//循环三要素:
//1,初始条件,2,结束条件,3,迭代过程。
while (end >= 0)
{
ps->a[end + 1] = ps->a[end];
end--;
}
ps->a[0] = x;
ps->size++;
//用for也可以来实现:
/* SeqListCheckCapacity(ps);
for (int i = ps->size-1; i >= 0; i--)
{
ps->a[i+1] = ps->a[i];
}
ps->a[0] = x;
ps->size++;*/
//前面的可以都不用,直接
//SeqListInsert(ps,0,x);
}
void SeqListPopBack(SL* ps)//尾删
{
assert(ps->size > 0);
//这个断点的应用可以帮助找到在那一行出现的问题。
ps->size--;
//前面的可以都不用
//SeqListErase(ps,ps->size-1);
}
void SeqListPopFront(SL* ps)//头删
{
assert(ps->size > 0);
int start = 1;
while (start < ps->size)
{
ps->a[start - 1] = ps->a[start];
start++;
}
ps->size--;
/*这里也可以用for来实现
assert(ps->size > 0);
int i = 0;
for (i = 1; i <=ps->size; i++)
{
ps->a[i-1] = ps->a[i];
}
ps->size--;
*/
//SeqListErase(ps,0);
}
void SeqListInsert(SL* ps, int pos, SQDataType x)//从中间插入
{
assert(pos<ps->size);
SeqListCheckCapacity(ps);
int end = ps->size - 1;
while (pos <= end)
{
ps->a[end +1] = ps->a[end];
end--;
}
ps->a[pos] = x;
ps->size++;
}
void SeqListErase(SL* ps,int pos)//任意位置删除
{
assert(pos < ps->size);
int start = pos + 1;
while (start < ps->size)
{
ps->a[start - 1] = ps->a[start];
start++;
}
ps->size--;
}
void SeqListDestroy(SL* ps)//空间的销毁
{
free(ps->a);
ps->a = NULL;
ps->capacity = ps->size = 0;
}
int SeqListFind(SL* ps, SQDataType x)//查找
{
for (int i= 0; i < ps->size; i++)
{
if (ps->a[i] == x)
{
return i;
}
}
return -1;
}
void SeqListModify(SL* ps, int pos, SQDataType x)//修改
{
assert(pos < ps->size);
ps->a[pos] = x;
}
3,测试菜单文件(menu)
写了个相关的小菜单,实现了一点人机交互。
#define _CRT_SECURE_NO_WARNINGS 1
#include"SeqList.h";
void menu()
{
printf("************************************\n");
printf("1,尾插数据, 2,头插数据\n");
printf("3,尾删数据, 4,头删数据\n");
printf("5,在指定位置删数据, 6,在指定位置删除数据\n");
printf("7,查找数据, 8,打印数据\n");
printf("9,销毁表格, 0,修改表格\n");
printf(" -1,退出\n");
printf("请输入你的操作:\n");
printf("************************************\n");
}
int main()
{
SL sl;
SeqListInit(&sl);
int option = 0;
int x = 0;
while (option != -1)
{
menu();
scanf("%d", &option);
switch (option)
{
case 1:
printf("请输入你要在表头插入的数据,以-1结束\n");
do
{
scanf("%d", &x);
if (x != -1)
SeqListPushBack(&sl, x);
} while (x != -1);
printf("已插入******\n");
break;
case 2:
printf("请输入你要在表头插入的数据,以-1结束\n");
do
{
scanf("%d", &x);
if (x != -1)
{
SeqListPushFront(&sl, x);
}
} while (x != -1);
printf("已插入******\n");
break;
case 3:
printf("您确定要删除表尾的数据吗?1:确定||2:否定\n");
int num1 = 0;
scanf("%d", &num1);
if (num1 == 1)
{
SeqListPopBack(&sl);
printf("已经删除******\n");
break;
}
else
break;
case 4:
printf("您确定要删除表头的数据吗?1:确定||2:否定\n");
int num2 = 0;
scanf("%d", &num2);
if (num2 == 1)
{
SeqListPopFront(&sl);
printf("已经删除******\n");
break;
}
else
break;
break;
case 5:
printf("请输入您要插入元素的位置\n");
int num5 = 0;
scanf("%d", &num5);
printf("您要插入的数据是:\n");
SQDataType x;
scanf("%d", &x);
SeqListInsert(&sl, num5,x);
printf("已插入******\n");
break;
case 6:
printf("请输入您要删除元素的位置\n");
int num6 = 0;
scanf("%d", &num6);
SeqListErase(&sl, num6);
printf("已删除******\n");
break;
case 7:
printf("请输入你要查找的数据:\n");
int num3 = 0;
scanf("%d", &num3);
int num4 = SeqListFind(&sl, num3);
if (num4 != -1)
{
printf("表中确实存在该数据,它的下标是:%d\n", num4);
break;
}
else
printf("抱歉,表中不存在该数据\n");
break;
case 8:
SeqListPrint(&sl);
break;
case 9:
printf("您确定要销毁表格吗?1:确定||2:否定\n");
int num9 = 0;
scanf("%d", &num9);
if (num9 == 1)
{
SeqListDestroy(&sl);
printf("已销毁******");
break;
}
else
break;
case 0:
printf("请输入您要修改的数据的位置:\n");
int num0 = 0;
scanf("%d", &num0);
printf("您要修改为的数据是:");
SQDataType x1;
scanf("%d", &x1);
SeqListModify(&sl, num0, x1);
printf("修改完毕******");
break;
case -1:
break;
default:
break;
}
}
SeqListDestroy(&sl);
return 0;
}
4,顺序表的优缺点
优点:
1,无须为表示表中元素逻辑关系而增加额外的储存空间。
2,随机存取元素时可以达到O(1),效率高。
缺点:
1,插入和删除数据的时候需要移动大量的元素。
2,必须一开始就确定存储空间的容量。
3,如果空间不够了,增容。增容会付出一定性能的消耗,其次可能存在一定的空间浪费。(动态顺序表)
二,单链表
具体操作有:打印,尾插,头插,尾删,头删,在任意结点之前插入,删除任意结点,malloc一个新结点,在所给链表中查找数据x,并返回它的结点等。
标注的比较详细,可以借助注释食用哦。
分为三个项:(头文件,C文件,测试文件)
SList.h:包的引用和函数的声明
SList.c:各个操作的实现
Test.c:各个操作的实现
1,头文件
代码实现:
#pragma once//防止被重复包含
#include<stdio.h>
#include<stdlib.h>
typedef int SLTDataType;
struct SListNode
{
SLTDataType data; //链表的数据
struct SListNode* next; //链表的指针
};
typedef struct SListNode SLTNode;//改个名字
//实现一些接口
void SListPrint(SLTNode* phead);//打印
void SListPushBack(SLTNode** pphead,SLTDataType);//尾插
void SListPushFront(SLTNode** pphead, SLTDataType x);//头插
void SListPopBack(SLTNode** pphead);//尾删
void SListPopFront(SLTNode** pphead);//头删
void SListInsert(SLTNode** pphead, int pos, SLTDataType x);//在任意位置插入
void SListErase(SLTNode** pphead, int pos);//在任意位置删除
SLTNode* BuySListNode(SLTDataType x);//malloc一个结点
SLTNode* SListFind(SLTNode*phead, SLTDataType x);//在所给链表中查找数据x,并返回它的结点
2,C文件
代码实现:
#define _CRT_SECURE_NO_WARNINGS 1
#include"SList.h"//引一下头文件
void SListPrint(SLTNode* phead)//打印,这个就是边遍历边打印
{
SLTNode* cur = phead;//因为要通过指针遍历,所以就创建一个可移动的指针出来。
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");//最后可以手动的以NULL结尾。
}
SLTNode* BuySListNode(SLTDataType x)//malloc一个结点出来,申请一个新结点,然后进行初始化。
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->data = x;
newnode->next = NULL;
return newnode;
}
void SListPushFront(SLTNode** pphead, SLTDataType x)//头插
{
SLTNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
void SListPushBack(SLTNode** pphead, SLTDataType x)//尾插
{
SLTNode* newnode = BuySListNode(x);//创建一个新结点。
if (*pphead == NULL)
{
*pphead = newnode;
}
//这里判断一下传过来的这个头指针是不是指向NULL,如果是指向NULL的,说明单链表上还没有结点(因为头指针初始化为NULL),在这个状态下尾插,就可以直接让单链表的头指针指向这个新结点。
else
{
//定义一个找尾节点的指针,从头指针这里开始遍历。
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
//找到了尾节点直接在后面插入新创建的结点就行了。
}
}
void SListPopFront(SLTNode** pphead)//头删
{
SLTNode* next = (*pphead)->next;//创建一个指针变量将头结点的next指向的地址保留一下。
free(*pphead);
*pphead = next;
//还有个思路:其实也是道理也是一样的。
//SLTNode* tmp = *pphead;
//*pphead = tmp->next;
//free(tmp);
}
void SListPopBack(SLTNode** pphead)//后删;
{
//用双指针,一个指向尾巴的前一个结点,一个指向尾巴。
SLTNode* prev = NULL;
SLTNode* tail = *pphead;
if (*pphead == NULL)//这个是空链表的情况,直接返回。
{
return;
}
else if ((*pphead)->next==NULL)//这个是链表只有一个结点的情况。
{
free(*pphead);
*pphead = NULL;
}
else//这个是链表有两个及两个以上结点的情况。
{
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = NULL;
}
}
SLTNode* SListFind(SLTNode* phead, SLTDataType x)//查找
{
SLTNode* cur = phead;
while (cur != NULL)
{
if (cur->data == x)
return cur;
cur = cur->next;
}
return NULL;
}
void SListInsert(SLTNode** pphead,SLTNode* pos,SLTDataType x)//在pos前面的位置上插入x。
//因为需要上传结点参数,所以一般都与查找接口一齐使用。先查找返回对应的结点,然后进行插入。
{
SLTNode* newnode = BuySListNode(x);
if (*pphead == NULL)//空链表时候的插入情况
{
*pphead = newnode;
newnode->next = NULL;
}
else if (pos == *pphead)//头插情况
{
newnode->next = *pphead;
*pphead = newnode;
}
else
{
SLTNode* tmpt = *pphead;
while (tmpt->next != pos)//一直向后遍历
{
tmpt = tmpt->next;
}
tmpt->next = newnode;
newnode->next = pos;
}
}
void SListErase(SLTNode** pphead,SLTNode*pos)//删除pos位置上的值。
//因为需要上传结点参数,所以一般都与查找接口一齐使用。先查找返回对应的结点,然后进行插入。
{
SLTNode* cur = *pphead;
if (*pphead == NULL)//如果是空链表就直接返回。
{
return;
}
else if(pos==*pphead)//头删情况。
{
*pphead = cur->next;
free(cur);
cur = NULL;
}
else
{
while (cur->next != pos)
{
cur = cur->next;
}
cur->next = pos->next;//这样就直接将pos结点删除了。
free(pos);
}
}
3,测试文件
这个单链表可以进行测试测试。
#pragma once
#include"SList.h"//引一下头文件
test1()
{
SLTNode* phead = NULL;;
SListPushBack(&phead, 1);
SListPushBack(&phead, 2);
SListPushBack(&phead, 3);
SListPrint(phead);
//想在1前面插入0.
SLTNode* pos = SListFind(phead, 1);//先找到1
if (pos != NULL)
{
SListInsert(&phead, pos, 0);
SListPrint(phead);
}
else
printf("没有找到您要找的位置");
//想要删除链表中的2.
SLTNode* pos2 = SListFind(phead,2);//先找到2
if (pos2 != NULL)
{
SListErase(&phead, pos2);
SListPrint(phead);
}
else
{
printf("没有找到您要删除的元素");
}
}
int main()
{
test1();
return 0;
}
4,带头链表和不带头链表
上面的单链表是属于不带头的单链表。接下来讲一下带头的单链表。
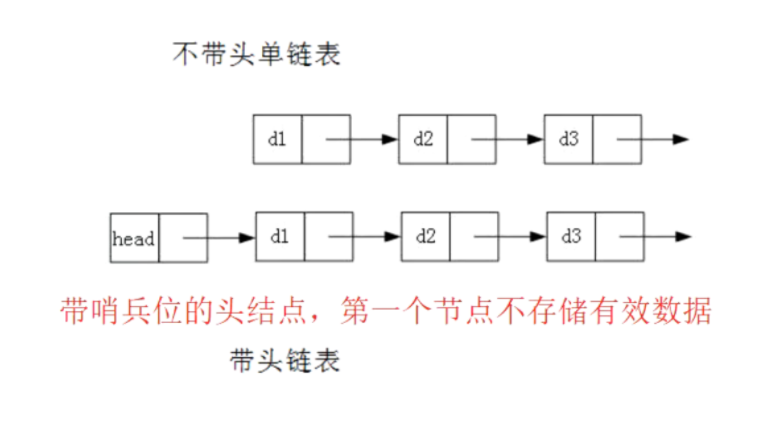
带头链表的好处:
尾插:还要判断首结点是不是空,如果是空,那么还得改变头指针的指向(原来是NULL,现在要指向这个newnode,修改了),所以这个就需要二级指针了。(如果要对原先的头指针进行修改,那么就需要使用二级指针。),而带头链表直接在head后面加就行了。不需要使用二级指针。尾插的判断会更简单。
头删:也是一样的,普通的单链表要找到d2,让头指针指向d2才行,这样也需要改变plist,使用二级指针。但是带头链表,指针直接找到d2了。(将d2的地址保存到head的next中)直接让head上的头指针指向d2就行了。这样实际上也没有改变头指针的地址。注意:头指针和带头结点是不一样的,头指针只有一个地址,没有next,而带头结点是有next的,这就可以放直接放地址,直接指向一个地方而不用改变自身的地址。而头指针改变指向的对象的话,就会改变自身的地址。
注意:头结点的head是不能存数值的(不能用头结点来存链表的长度)。这样是不规范的。链表中存的都是整数还好说,如果是其他的数据类型,例如char,double就尴尬了。
单链表的尾删,插入,删除的时间复杂度都是O(n),他们都是需要找到指定节点的前一个结点。
解决方案:双向链表(有后继,有前驱)
三,双向链表
用代码实现一下带头的双向循环链表。
1,头文件
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#pragma once
typedef int LTDataType;
typedef struct ListNode
{
struct ListNode* next;
struct ListNode* prev;
int data;
}ListNode;
//声明一下接口
ListNode* ListInit();//初始化。
void ListDestory(ListNode* plist);//销毁
void ListPushBack(ListNode* plist, LTDataType x);//尾插
ListNode* BuyListNode(LTDataType x);//创建新结点。
void ListPrint(ListNode* plist);//打印
void ListPushFront(ListNode* plist, LTDataType x);//前插
void ListPopFront(ListNode* plist);//前删
void ListPopBack(ListNode* plist);//尾删
ListNode* ListFind(ListNode* plist, LTDataType x);//查找
ListNode* ListInsert(ListNode* pos,LTDataType x);//在pos前面插入
ListNode* ListErase(ListNode* pos);//删除pos出的结点
void ListModify(ListNode* pos, int num);//在pos这里更改数据;
2,C文件
#define _CRT_SECURE_NO_WARNINGS 1
#include"List.h"
ListNode* BuyListNode(LTDataType x)//创建新结点
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
newnode->next = NULL;
newnode->data = x;
return newnode;
}
ListNode* ListInit()//初始化
{
ListNode* phead =BuyListNode(0);//这个时候phead就已经是头结点了
phead->next = phead;
phead->prev = phead;
return phead;
//使用举例:ListNode* phead = ListInit();创建哨兵位头结点。
}
void ListPushBack(ListNode* phead, LTDataType x)//后插
{
assert(phead);//这个链表最起码应该是带个head,所以肯定不能是空。
ListNode* newnode = (ListNode*)BuyListNode(x);
ListNode* tail = phead->prev;//先定义一下尾结点。
newnode->prev = tail;
newnode->next = phead;
tail->next = newnode;
phead->prev = newnode;
//这个进行的操作没有直接影响到指针(结点地址)本身,而改变的是next和prev,所以不用引二级指针。
}
void ListPrint(ListNode* phead)//打印
{
ListNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
void ListPushFront(ListNode* phead, LTDataType x)//前插
{
assert(phead);
ListNode* newnode = BuyListNode(x);
newnode->next = phead->next;
newnode->prev = phead;
phead->next->prev = newnode;
phead->next = newnode;
}
void ListPopFront(ListNode* phead)//前删
{
assert(phead);//判断确保不能链表不能为空。
assert(phead->next != phead);//判断确保链表不能只有头结点。(因为至少得有两个结点方法才能成立)
ListNode* first = phead->next;
ListNode* second = phead->next->next;
phead->next = second;
second->prev = phead;
free(first);
first = NULL;
}
void ListPopBack(ListNode* phead)//尾删
{
assert(phead);//判断确保不能链表不能为空。
assert(phead->next != phead);//判断确保链表不能只有头结点。(因为至少得有两个结点方法才能成立)
ListNode* tail = phead->prev;
ListNode* tailPrev = phead->prev->prev;
tailPrev->next = phead;
phead->prev = tailPrev;
free(tail);
tail = NULL;
}
ListNode* ListFind(ListNode* phead, LTDataType x)//查找,返回结点
{
assert(phead);
ListNode* cur = phead->next;
while (cur->data != x)//进行遍历。
{
cur = cur->next;
if (cur->next == phead)
return NULL;
}
return cur;
}
void ListModify(ListNode* pos, int num)//将pos这里的结点的data改成num
{
pos->data = num;
}
ListNode* ListInsert(ListNode* pos, int x)//在pos前面插入
{
assert(pos);
ListNode* prev = pos->prev;
ListNode* newnode = BuyListNode(x);
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = prev;
}
ListNode* ListErase(ListNode* pos)//删除pos出的结点
{
assert(pos);
ListNode* prev = pos->prev;
ListNode* next = pos->next;
prev->next = next;
next->prev = prev;
free(pos);
pos = NULL;
}
void ListDestory(ListNode* phead)//销毁
{
assert(phead);
ListNode* cur = phead->next;
while (cur != phead)//遍历,保存下一个,销毁前一个。
{
ListNode* next = cur->next;
free(cur);
cur = next;
}
free(phead);//最后销毁头结点
phead = NULL;
}
四,栈
1,栈的相关概念
(1),定义
栈是一种特殊的线性表,只允许在固定的一端进行插入和删除元素,进行数据插入和删除操作的一段称为栈顶,另一端称为栈底。
(2),实现方式的选择
用数组实现:
用数组实现栈可以完美的避开顺序表的缺点(避免在表头插入和删除需要移动大量的数据,因为如果用数组来实现栈的话,就是将顺序表的尾巴当作的栈顶,压栈和出栈对应着尾插和尾删,这就很方便)(而且数据扩容也不是特别的频繁。)
用链表实现:
1,双链表:链尾表示栈顶,如果要删除的话,必须要找到最后一个还有倒数第二个结点,也还可以。
2,单链表:链头表示栈顶,开始的时候,让栈顶和栈底都指向同一个,压栈就是头插,出栈就是头删。举个头删的例子:保存栈顶的后一个,然后将原先的栈顶销毁掉,让栈顶指向栈顶的后一个。这样出栈和入栈都是O(1)。
所以如果用链尾表示栈顶,那么就用双链表。
如果用链头表示栈顶,那么就用单链表。
这些方法都是可以的,你能写出来就行。
推荐:数组
1,(单链表增和删有些繁琐)
2,数组的cpu缓存的命中率要更高一点。(预加载)(因为数组的地址是连续的)
如果是连续的内存,cpu要访问的话要把他加载到寄存器。我会直接预加载一大块东西。第一个命中了,第二个命中的概率就会很多高了。链表就不会了,命中了第一个,由于内存不是连续的,所以想要预加载到第二个就会有些困难。
2,头文件
#pragma once//防止头文件重复引用
#include<stdio.h>
#include<stdbool.h>
#include<stdlib.h>
#include<assert.h>
typedef int STDataType;
typedef struct Stack
{
STDataType* a;//搞一个数组
int top;//栈顶的位置
int capacity;//栈的容量
}Stack;
void StackInit(Stack* ps);//初始化
void StackDestory(Stack* ps);//销毁单链表
void StackPop(Stack* ps);//删除
void StackPush(Stack* ps, STDataType x);//插入
STDataType StackTop(Stack* ps);//栈顶
int StackSize(Stack* ps);//输出大小
bool StackEmpty(Stack* ps);//是否为空
3,C文件
#include"Stack.h"//引一下头文件
void StackInit(Stack* ps)
{
assert(ps);
if (ps->a == NULL)
{
printf("malloc失败了");
exit(-1);
}
ps->a = (Stack*)malloc(sizeof(STDataType) * 4);//整个4个对应的数据类型的空间
if (ps->a == NULL)
{
printf("malloc失败了");
exit(-1);
}
ps->capacity = 4;
ps->top = 0;
//如果这里的栈顶top是赋值的0,那么栈顶指向的永远都是栈的最后一个数据的下一位置。
//因为一开始栈里面还没有数据的时候,top是0,在栈的第一个位置,有了数据之后,top就得指向第二个位置了。(用数组实现的)
//如果top给到-1,那么top指向的数值就是栈的最后一个数值。在这里代码给的是0.
}
void StackDestory(Stack* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
void StackPush(Stack* ps,STDataType x)//入栈
{
assert(ps);
//如果满了那么就需要扩容量
if (ps->top == ps->capacity)
{
STDataType* tmp = (STDataType*)realloc(ps->a, ps->capacity * 2 * sizeof(STDataType));
if (tmp == NULL)
{
printf("realloc失败了");
exit(-1);
}
else
{
ps->a = tmp;
ps->capacity = 2 * ps->capacity;
}
}
ps->a[ps->top] = x;
ps->top++;
}
void StackPop(Stack* ps)//出栈
{
assert(ps);
assert(ps->top > 0);//如果栈空了,那么就直接终止程序报错。
ps->top--;
}
STDataType StackTop(Stack* ps)//返回栈顶
{
assert(ps);
assert(ps->top > 0);//如果栈空了,就会访问到栈的前一个出界的随机元素了,肯定报错。
return ps->a[ps->top - 1];
}
int StackSize(Stack* ps)//输出大小
{
assert(ps);
return ps->top;
}
bool StackEmpty(Stack* ps)//是否为空
{
//assert(ps);
return ps->top == 0;
}
4,测试文件
#define _CRT_SECURE_NO_WARNINGS 1
#include"Stack.h"
int main()
{
Stack st;
StackInit(&st);
StackPush(&st, 1);
StackPush(&st, 2);
StackPush(&st, 3);
StackPush(&st, 4);
//遍历方法:(属于栈的)
while (!StackEmpty(&st))
{
printf("%d ", StackTop(&st));
StackPop(&st);
}
printf("\n");
StackDestory(&st);//只要有初始化,就得有销毁。
}
五,队列
1,队列的相关概念
(1),定义
队列定义:队列是只允许在一端插入数据,然后在另一端进行删除数据操作的特殊线性表。队列的特点就是先进先出。
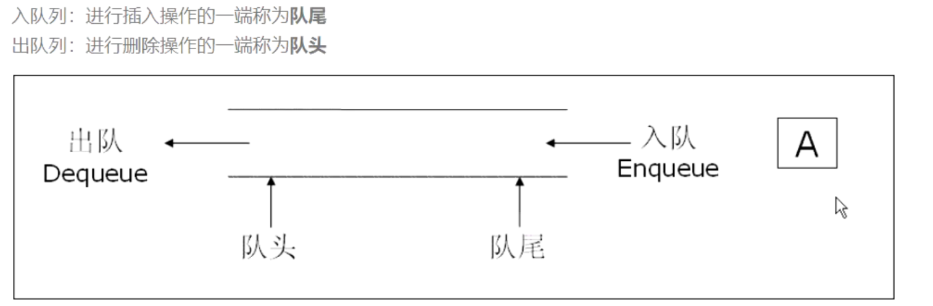
在队头出数据,在队尾进数据。
(2),实现方式的选择
实现方法:
数组:不太好,因为队头出数据的时候需要挪动了链表。
链表:操作就是头删和尾插。(完美的运用的单链表的优点,头删和尾插的效率都很高)。
下面的代码定义了一个(指针)结构体{head和tail},这样就不用二级指针了。
这里是不需要带头结点的,双向链表中的带头结点的目的是解决单链表中的二级指针的问题的,带头结点中的next和prev可以存取地址。头指针和带头结点是不一样的,头指针只有一个地址,没有next,而带头结点是有next的,这就可以放直接放地址,直接指向一个地方而不用改变自身的地址。而头指针改变指向的对象的话,就会改变自身的地址。(单链表和双向链表)
而队列:有指针结构体,在一个结构体存储着两个指针,一个是head还有一个是tail指针。有这两个指针也就不需要改变头结点的指针了,也就不需要二级指针了。
注意有两个结构体,一个结构体是关于指针的结构体,还有一个结构体是关于结点的结构体。如果向函数中传的参数是结点的话,那么就需要用二级指针,但是传的参数是指针的话,就只需要传指针就行了。
那为什么单链表的时候不用这个结构体来用tail呢?有tail之后尾插确实很简单,但是尾删还是很困难。单链表就是直接传的head,进行二级指针,这样就能改变指针的值。
1,头文件
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include<stdio.h>
#include<stdbool.h>
#include<stdlib.h>
#include<assert.h>
typedef int QDataType;
typedef struct QueueNode//这里是结点的结构体
{
struct QueueNode* next;
QDataType data;
}QNode;
typedef struct Queue//这里是指针的结构体。(有这个结构体就不需要二级指针了)
{
QNode* head;
QNode* tail;
}Queue;
void QueueInit(Queue* pq);//初始化
void QueueDestory(Queue* pq);//销毁单链表
void QueuePop(Queue* pq);//队头出
void QueuePush(Queue* pq, QDataType x);//队尾入
QDataType QueueFront(Queue* pq);//取队首的元素。
QDataType QueueBack(Queue* pq);//取队尾的元素。
int QueueSize(Queue* pq);//取队列的长度
bool QueueEmpty(Queue* pq);//判断队列是不是空
2,C文件
#include"Queue.h"//引一下头文件
void QueueInit(Queue* pq)//初始化
{
assert(pq);
pq->head = pq->tail = NULL;
}
void QueuePop(Queue* pq)//队头出
{
assert(pq);
assert(pq->head);//判断栈是否满了。
//删除之前要先保存下一个。
//为了防止后面的问题:
if (pq->head->next == NULL)//如果队列中就一个数据
{
free(pq->head);
pq->head = pq->tail = NULL;
}
else
{
QNode* next = pq->head->next;
free(pq->head);
pq->head = next;
}
//如果没有前面的if的话就会有一个问题,就是如果free掉最后一个。head和next都会指向NULL(这个是没有问题的,但是tail就会指向已经被释放掉的空间,成为了野指针)
}
void QueuePush(Queue* pq, QDataType x)//队尾入
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));//malloc一个新结点
if (newnode == NULL)
{
printf("mallco fail\n");
exit(-1);
}
newnode->next = NULL;
newnode->data = x;
if (pq->tail == NULL)//用tail和head比较都行。if(pq->head==NULL)
{
pq->tail = pq->head = newnode;
}
else
{
pq->tail->next = newnode;
pq->tail = newnode;
}
}
QDataType QueueFront(Queue* pq)//取队首的元素。
{
assert(pq);
assert(pq->head);//保证至少有一个元素。
return pq->head->data;
}
QDataType QueueBack(Queue* pq)//取队尾的元素。
{
assert(pq);
assert(pq->head);//保证至少有一个元素
return pq->tail->data;
}
int QueueSize(Queue* pq)//取队列的长度
{
int size = 0;
QNode* cur = pq->head;//定义一个指针。
while (cur)
{
size++;
cur = cur->next;
}
return size;
}
bool QueueEmpty(Queue* pq)//判断队列是不是空
{
assert(pq);
return pq->head == NULL;
}
void QueueDestory(Queue* pq)//销毁单链表
{
assert(pq);
QNode* cur = pq->head;
while (cur)
{
QNode* next = cur->next;//保存下一个结点
free(cur);
cur = next;
}
pq->head = pq->tail = NULL;
}
3,测试文件
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include"Queue.h"
#include"Queue.h"
int main()
{
Queue q;
QueueInit(&q);
QueuePush(&q, 1);
QueuePush(&q, 2);
QueuePush(&q, 3);
QueuePush(&q, 4);
QueuePop(&q);
//遍历(满足现进先出的特点)
while (!QueueEmpty(&q))
{
printf("%d ", QueueFront(&q));
QueuePop(&q);
}
printf("\n");
return 0;
}
六,栈和队列的补充
栈的实现:
底层可以用数组,也可以用链表,可以单链表,双链表,带头,不带头都可以。
如果用链表实现的话,推荐用单链表。
用链表的头这一端来做栈顶。这样录数据就相当于头插,出数据就相当头删。O(1)。
不要用链表的尾这一端来做栈顶,这样录数据好进入。但是出数据的时候就不容易删除了(要找到它的前一个,必须要遍历)O(n).
但是:
更推荐用数组来实现。录入数据就是直接将数据赋值过去,然后top下标向后移动就行了。出数据就直接top–,最后的数据就没有了(两个操作都是在数组的末尾进行的)可以用动态的数组,也可以用静态的数组。但是推荐用动态的,静态的给多了用不完,给少了不够用。
也就是在定义结构体的时候多一个capacity,然后不够用了就扩容。realloc。
队列的实现:
推荐还是用链表,
用数组的话就不太好:录入数据的时候还好说,但是出数据的时候出一个数据就需要将后面的数据整体的往前移动。效率就低了。
用链表:从链表的尾处入数据,在链表的头处出数据。(两个指针)都是O(1),把优点集合两个了。(三个方向都挺好的,在头上插,在头上删,在尾上插。但是在尾上删除就不好了O(n))。
七,二叉树
1,树的概念
结构:任何一棵二叉树都有三部分,根结点,左子树,右子树。
重点算法:分治算法:分而治之,大问题分成类似子问题,子问题再分成子问题。直到子问题不可再分割。
遍历方法:
前序(先根遍历):先访问根结点,然后左子树,最后右子树。
中序(中根遍历):先访问左子树,然后根结点,最后右子树。
后序(后根遍历):先访问左子树,然后右子树,最后根节点。
满二叉树:每一层都是满的。
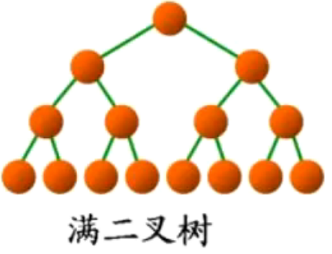
设总的结点数是N个,共h层。那么定满足2^h-1=N.
完全二叉树: 设树的高度是h,则h-1层都是满的,最后一层不是满的,但是最后一层从左到右都是连续的。
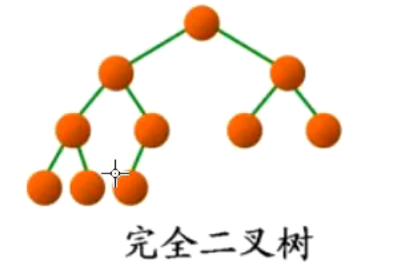
设最后一层还差x个结点才能构成满二叉树,那么满足2^h-1-x=N。
2,前序,中序,后序遍历
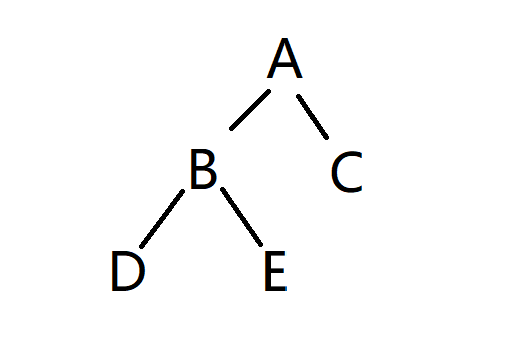
代码实现:(为了演示三种遍历顺序,在main函数中直接定义了一棵二叉树。(具体见下面main函数))
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
typedef char BTDataType;
typedef struct BinaryTreeNode//这个结点定义的是左子树,右子树,数据。
{
struct BinaryTreeNode* left;
struct BinaryTreeNode* right;
BTDataType data;
}BTNode;
void PrevOrder(BTNode* root)//前序
{
if (root == NULL)
{
printf("NULL ");
return;
}
printf("%c ", root->data);
PrevOrder(root->left);
PrevOrder(root->right);
}
void InOrder(BTNode* root)//中序
{
if (root == NULL)
{
printf("NULL ");
return;
}
InOrder(root->left);
printf("%c ", root->data);
InOrder(root->right);
}
void PostOrder(BTNode* root)//后序
{
if (root == NULL)
{
printf("NULL ");
return;
}
PostOrder(root->left);
PostOrder(root->right);
printf("%c ", root->data);
}
int main()//直接定义了一棵二叉树
{
BTNode* A = (BTNode*)malloc(sizeof(BTNode));
A->data = 'A';
A->left = NULL;
A->right = NULL;
BTNode* B = (BTNode*)malloc(sizeof(BTNode));
B->data = 'B';
B->left = NULL;
B->right = NULL;
BTNode* C = (BTNode*)malloc(sizeof(BTNode));
C->data = 'C';
C->left = NULL;
C->right = NULL;
BTNode* D = (BTNode*)malloc(sizeof(BTNode));
D->data = 'D';
D->left = NULL;
D->right = NULL;
BTNode* E = (BTNode*)malloc(sizeof(BTNode));
E->data = 'E';
E->left = NULL;
E->right = NULL;
A->left = B;
A->right = C;
B->left = D;
B->right = E;
//空的就不用处理了,上面已经整成空了。
PrevOrder(A);
printf("\n");
InOrder(A);
printf("\n");
PostOrder(A);
return 0;
}
输出结果:(前序,中序,后序)

3,二叉树的层序遍历
之前讲的都是递归的(前序,中序,后序。他们叫深度优先遍历),现在整个不是递归的。
这个层序遍历叫广度优先遍历。不用递归了,用队列(先进先出)。核心:上一层带下一层。
举个例子:
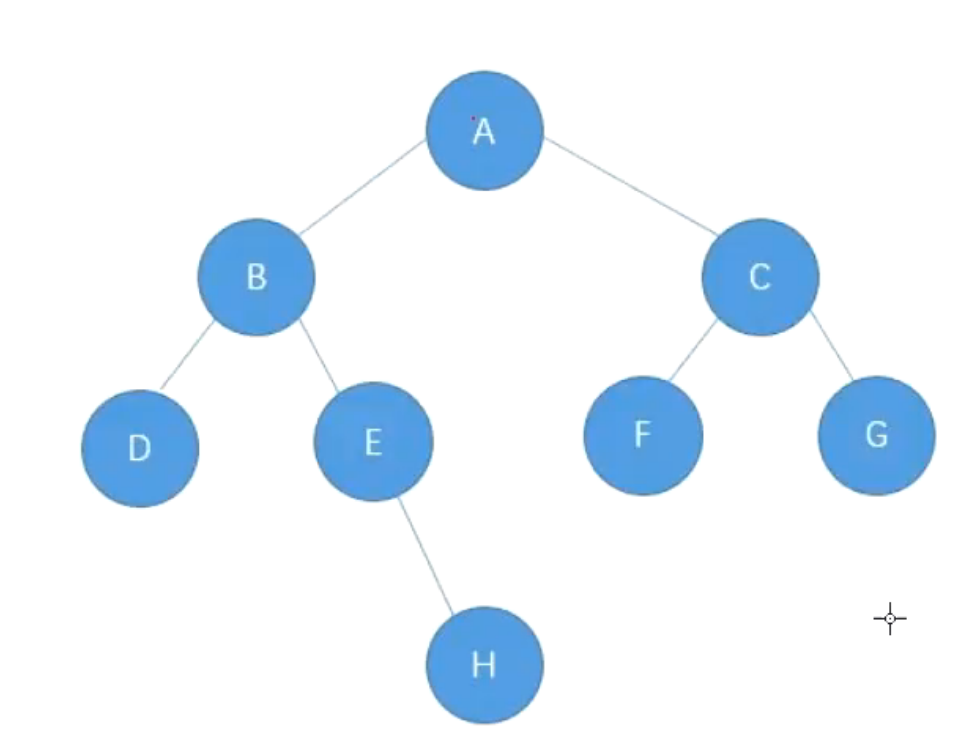
首先构建一个新的队列,一开始放A进队列,然后判断队列是不是空,队列不是空,然后将A拿出来然后将B,C放进去,队列不是空,拿B出来,然后将D,E放进去,队列不是空,拿C出来然后将F,G放进去,队列不是空,将D拿出来,不带。队列不是空,将E拿出来然后再将H放进去,然后将F拿出来,然后将G拿出来,最后将H拿出来,这个时候队列就是空了,然后就结束了。
觉得对自己有帮助的小伙伴可以点个赞哦