目录
8.1 人工智能概述
8.2 搭建“人工智能”开放平台
8.2.1 人脸检测后台搭建
8.2.2 本地脚本测试
8.2.3 前端说明页面
8.3 在线人脸检测
8.1 人工智能概述
人工智能出现至今已60余年,近几年深度学习全面爆发推动其走向一个更为兴盛的阶段。尤其是2016年谷歌的AIphaGo横扫棋坛,让人工智能在普罗大众中掀起一波关注热潮。时至今日,人工智能依然是最热门的研究领域之一。众多巨头企业、初创企业等纷纷入局人工智能领域,尝试寻找全新突破口。而人工智能想要改变社会,不能仅停留于理论和概念层面,更重要的是要实现商业化、场景化落地。
目前,很多科技企业均提供基于AI的开放平台,以Web的形式对外提供AI服务,例如人脸识别、OCR识别、语音识别等。以人脸检测为例,用户通过特定的api接口上传需要检测的照片,然后由Web服务器对照片进行人脸检测,并将检测结果返回给用户。实际的AI算法往往需要复杂的配置、较高的服务器性能才能进行算法推演,采用Web部署这种方式使得开发人员只需要配置和维护服务器环境即可,不需要再关注用户PC的配置和性能。另外,AI算法的更新也只需要在服务器上修改即可,使用Web架构适合生产环境下AI产品的快速部署和更新。
本节课程拟模仿上述流程,通过Django框架搭建一个人脸检测Web平台,以api接口形式提供对外服务。这里为了简化演示效果,降低读者的学习难度,只使用OpenCV提供的现成的人脸检测算法来进行检测,实际情况下可以根据服务器的CPU或GPU性能,采用更高级的人脸检测算法来提高检测精度,例如可以采用基于深度学习的人脸检测算法等。本节课程旨在为读者提供一个结合人工智能的Web开发方向,有兴趣转向人工智能方向的读者可以从本节内容出发,学习基本的AI算法推理和部署技巧,而更复杂的人脸识别或者AI算法研发则需要读者参考其它人工智能书籍或论文。
8.2 搭建“人工智能”开放平台
8.2.1 人脸检测后台搭建
本章采用OpenCV提供的人脸检测算法来搭建人脸检测后台。OpenCV是一个开放源代码的计算机视觉应用库,由英特尔企业下属研发中心俄罗斯团队发起该项目,开源免费,设计目标是实现实时高效的计算机视觉任务,是一个跨平台的计算机视觉库。从开发之日起就得到了迅猛发展,获得了众多企业和业界学者的鼎力支持与贡献。因为是BSD开源,因此可以免费应用在科研和商业应用领域。OpenCV中多数模块是基于C++实现,其中有少部分是基于C语言实现,算法经过高度优化,实现效率高,非常适合生产环境使用。当前OpenCV提供的SDK已经支持C++、Java、Python等语言的应用开发。
首先,下载并安装用于Python的OpenCV开发包:
pip install opencv_python接下来开发后台视图处理函数。由于需要开发基于api的接口,因此大部分功能代码都会在views.py文件中编写。当后台收到用户的请求以后,由指定的视图函数对用户上传的图片进行读取,然后调用OpenCV人脸检测算法进行检测,最后将检测结果以JSON字符串形式返回给用户。
打开serviceApp应用下的views.py文件,在头部导入一些Python库:
import numpy as np # 矩阵运算
import urllib # url解析
import json # json字符串使用
import cv2 # opencv包
import os # 执行操作系统命令
from django.views.decorators.csrf import csrf_exempt # 跨站点验证
from django.http import JsonResponse # json字符串响应为了能够进行人脸检测,需要使用特定的人脸检测器,一般情况下需要运用机器学习算法进行训练得到,而本书使用的OpenCV库自带高效的人脸检测器,无需再训练直接拿来使用即可。在OpenCV的安装目录中找到haarcascade_frontalface_default.xml文件(路径:Python安装目录+\Lib\site-packages\cv2\data)。该xml文件本质上是一个配置文件,用于保存训练好的人脸特征检测器模型参数,使用时只需要导入该文件即可进行人脸检测。为了方便项目使用,将该xml文件放置在项目serviceApp应用目录下。
继续编辑views.py文件,添加facedetect函数如下:
@csrf_exempt # 用于规避跨站点请求攻击
def facedetect(request):
result = {}
if request.method == "POST": # 规定客户端使用POST上传图片
if request.FILES.get("image", None) is not None: # 读取图像
img = read_image(stream=request.FILES["image"])
else:
result.update({
"#faceNum": -1,
})
return JsonResponse(result)
if img.shape[2] == 3:
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 彩色图像转灰度
#进行人脸检测
values = face_detector.detectMultiScale(img,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
# 将检测得到的人脸检测关键点坐标封装
values = [(int(a), int(b), int(a + c), int(b + d))
for (a, b, c, d) in values]
result.update({
"#faceNum": len(values),
"faces": values,
})
return JsonResponse(result)- 人脸检测配置文件导入:首先在外部引入配置文件路径,将路径存入变量face_detector_path中;然后使用cv2.CascadeClassifier创建人脸检测器face_detector,人脸检测器的创建需要通过传入人脸检测配置文件face_detector_path来实现;
- 人脸检测视图处理函数:首先在函数前导入@csrf_exempt装饰器,否则无法使用该api接口。result变量用于存放最终的返回结果。api接口规定客户端必须采用POST方式进行信息提交,视图处理函数从请求request的FILES中获取图像数据;
- 读取图像方式:该开放平台将图像封装于request.FILES中,并且以键“image”来标示;然后采用自定义的read_image函数进行图像读取,该函数的定义和详细代码将在后面给出;读取的图像数据存放于临时变量img中;
- 图像转化:由于OpenCV在检测人脸的过程中需要先将RGB彩色图像转化为灰度图像,因此使用OpenCV提供的cv2.cvtColor函数实现图像转化;
- 人脸检测:使用人脸检测器并调用对应的detectMultiScale方法对图像执行人脸检测,检测结果values存放每个检测到的人脸框的坐标值;
- JSON封装和返回:由于每个人脸检测返回的结果以左上角横、纵坐标以及检测框长、宽返回,为了能够方便后期绘图,将检测结果转换为左上角和右下角坐标;最终的检测结果封装成JSON字符串并使用JsonResponse函数返回结果;
下面给出自定义的图像读取函数read_image:
def read_image(stream=None):
if stream is not None:
data_temp = stream.read()
img = np.asarray(bytearray(data_temp), dtype="uint8")
img = cv2.imdecode(img, cv2.IMREAD_COLOR)
return imgread_image函数用于实现基于数据流的图像读取,默认上传图像为彩色图像,以二进制方式进行读取,然后通过cv2.imdecode函数解码为OpenCV的图像数据。
至此已在后端完成人脸检测视图处理函数,为了能够使用该处理函数执行人脸检测,需要为该函数定义对应的映射路由。打开serviceApp应用下的urls.py文件,在urlpatterns字段中添加路由:
path('facedetect/', views.facedetect, name='facedetect'), # 人脸检测api保存所有修改后运行项目。至此,人脸识别后台服务已经成功开启,下一小节将阐述如何从本地执行Python脚本来调用该api接口。
8.2.2 本地脚本测试
本小节通过本地Python脚本调用,实现基于Web Api的人脸检测功能。为了能够在本地使用Python发送HTTP请求,需要下载requests库并进行安装:
pip install requests这里为了项目集成方便将本地调用脚本放置在项目根目录下的test文件夹中,命名为faceDetectDemo.py,然后在文件同目录下放置一张测试图片face.jpg,用于进行人脸检测。编辑faceDetectDemo.py文件,添加代码如下:
import cv2, requests
url = "http://localhost:8000/serviceApp/facedetect/"
# 上传图像并检测
tracker = None
imgPath = "face.jpg" #图像路径
files = {
"image": ("filename2", open(imgPath, "rb"), "image/jpeg"),
}
req = requests.post(url, data=tracker, files=files).json()
print("获取信息: {}".format(req))
# 将检测结果框显示在图像上
img = cv2.imread(imgPath)
for (w, x, y, z) in req["faces"]:
cv2.rectangle(img, (w, x), (y, z), (0, 255, 0), 2)
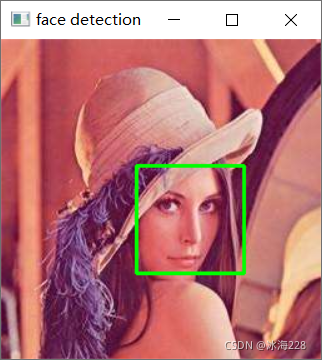
cv2.imshow("face detection", img)
cv2.waitKey(0)- 人脸检测api接口:开发阶段的后台服务器开启在http://localhost:8000,然后再根据url定义规则加上应用名serviceApp和对应的接口名facedetect即为最终的api接口;
- 发送数据:首先根据本地图像路径使用open函数读取图片内容并封装在files变量中,然后使用requests.post函数发送请求;返回的请求数据转化为JSON字符串,通过print函数打印查看字符串信息;
- 结果显示:为了显式的查看人脸检测效果,可以将获取到的人脸检测框输出在原图上。这里通过读取每一个人脸检测框然后使用OpenCV的rectangle函数在原图上绘制矩形框实现;
最终检测效果如下图所示:
在开发人脸识别开放平台时,有一点需要特别注意,由于每一个响应都需要主服务器进行人脸检测操作,而本身人脸检测算法相对其它类型的常规操作会更加耗时并且耗资源,当并发访问数过大时会导致网站奔溃,这也就是通常所说的访问量过载。访问量过载包含两个方面:一是超负荷访问,即后台主机性能有限,无法抗住过大的访问量;二是网站代码存在性能问题,将系统拖慢,导致网站服务奔溃。针对上述问题,通常有两种修复手段:
(1)为了快速访问网站,让用户迅速正常访问,最有效的手段就是限制访问。比如限制访问的频率,这个调整应该是动态的,比如说使用验证码等技术,放缓用户刷新次数。这样做可以确保服务的可用性,但也会牺牲部分用户的访问。正常情况下,服务器能支撑多大的访问量是需要技术人员在系统业务上线之前做好测试,提前做好数据支撑的;
(2)在时间允许的情况下,如果后端服务具有扩容条件,则可以对奔溃期间的访问数据进行分析,然后根据分析结果进行扩容服务,再逐步开放访问限制;
本节开发的人脸识别开放平台重点在于引导读者熟悉搭建人工智能Web接口的基本步骤,在实际的操作过程中需要结合服务器性能、用户群体、算法效率等综合考虑和设计Web架构,并且在上线前需要进行抗压测试,由于超出本课程内容,本节课不再对此进行深入阐述,有兴趣的读者可以自行查阅我的其他专栏中的博客。
8.2.3 前端说明页面
本小节将完善人工智能开放平台的前端页面,主要为用户提供一个说明页面用于向用户展示如何使用开放平台接口。接下来我们编辑serviceApp应用中templates文件夹下的platform.html文件,在前面开发企业门户网站时我们遗留了这部分内容没有开发,下面我们就来完善它。
参照示例网站所示效果可以看到,页面主体部分以说明文字为主,采用常规的HTML标签进行编写,主要对人脸检测开放平台的接口基本信息进行阐述,同时给出了基于Python的接口调用示例。可以看到,在演示代码部分,实现了适合Python格式的语法高亮功能,可以让用户方便的进行代码浏览和拷贝。为了实现该功能,这里通过集成CodeMirror插件来开发。CodeMirror是一款十分强大的代码编辑插件,提供了非常丰富的API,其核心基于JavaScript,可以实时在线代码高亮显示,值得指出的是该插件并不是某个富文本编辑器的附属产品,它本质上是一个在线代码编辑器的基础库。
本小节需要掌握在页面中高亮显示代码的方法。首先下载CodeMirror插件包,下载地址:https://codemirror.net/。插件包中包含各种代码的使用案例,由于本节课主要介绍基于Python语言的接口调用,因此介绍Python部分。用浏览器打开index.html文件,然后单击Python语言对应的示例即可跳转到Python示例页面,通过查看该页面源码即可进行开发。实际使用时只需要导入必要的js和css文件即可。
接下来进入具体的开发环节。首先需要从CodeMirror插件包中引入必要的js和css文件:
<link rel="stylesheet" href="{% static 'css/codemirror.css' %}">
<script src="{% static 'js/codemirror.js' %}"></script>
<script src="{% static 'js/python.js' %}"></script>
<style type="text/css">
.CodeMirror {
border-top: 1px solid black;
border-bottom: 1px solid black;
}
</style>其中codemirror.css、codemirror.js和python.js文件可以从CodeMirror插件包中找到,将其拷贝到hengDaProject项目static文件夹下的css和js子文件夹中即可实现调用。
使用时通过HTML标签<textarea>实现代码的显示和编辑:
<div><textarea id="code" name="code">
在此处写入Python代码
</textarea></div>最后,添加js代码:
<script>
var editor = CodeMirror.fromTextArea(document.getElementById("code"), {
mode: {
name: "python",
version: 3,
singleLineStringErrors: false
},
lineNumbers: true,
indentUnit: 4,
tabMode: "shift",
matchBrackets: true
});
</script>通过上述简单配置,可以使得页面显示的Python代码能够有效的进行高亮显示,方便用户浏览,效果如下图所示。完整代码请参考配套资源文件。
8.3 在线人脸检测
上一节阐述了人脸检测开放平台的搭建,通过服务器提供人脸检测服务,然后使用本地Python脚本实现接口调用。为了能够让用户更加方便的熟悉平台功能同时体验企业开发的AI产品特性,一种比较好的方式就是在上一节搭建的开放平台基础上提供一种在线检测功能。本节将阐述一种在线Web调用的方式,即用户在网页上上传一张照片,然后单击检测即可在网页上实现人脸检测并获取检测结果。这种方式可以方便的让用户无需编写任何脚本代码即可体验功能。下面阐述具体开发步骤。
首先来编写网页端功能。为了能够与当前的“人脸检测开放平台”说明页面区分开来,将通过使用Bootstrap提供的模式对话框来实现图片的在线检测。打开serviceApp应用下的platform.html文件,在主体部分<div class="model-details">中添加标题,并增加一个按钮用来弹出模式对话框,效果如下图所示:
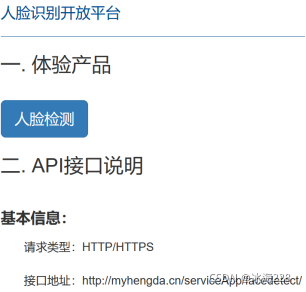

当在页面中单击“人脸检测”按钮时,弹出右侧所示对话框,此时背景页面会呈现灰色,只有在模式对话框关闭时页面才恢复正常。采用这种方式,可以方便的在页面中进行额外的界面操作而不影响页面原有布局。Bootstrap提供了现成的模式对话框组件,可以方便的直接使用。具体代码如下:
<h3>一. 体验产品</h3>
</br>
<!-- 按钮触发模态框 -->
<button class="btn btn-primary btn-lg" data-toggle="modal"
data-target="#myModal">人脸检测
</button>
<!-- 模态框(Modal) -->
<div class="modal fade" id="myModal" tabindex="-1" role="dialog"
aria-labelledby="myModalLabel" aria-hidden="true">
<div class="modal-dialog">
<div class="modal-content">
<div class="modal-header">
<button type="button" class="close" data-dismiss="modal"
aria-hidden="true">×
</button>
<h4 class="modal-title" id="myModalLabel">
在线人脸检测
</h4>
</div>
<div class="modal-body">
<img id="photoIn" src="{% static 'img/sample.png' %}"
class="img-responsive" style="max-width:250px">
<input type="file" id="photo" name="photo" />
</div>
<div class="modal-footer">
<button type="button" class="btn btn-default"
data-dismiss="modal">关闭
</button>
<button type="button" id="compute" class="btn btn-primary">
开始检测
</button>
</div>
</div><!-- /.modal-content -->
</div><!-- /.modal -->
</div>
<script>
$(function () {
$('#photo').on('change', function () {
var r = new FileReader();
f = document.getElementById('photo').files[0];
r.readAsDataURL(f);
r.onload = function (e) {
document.getElementById('photoIn').src = this.result;
};
});
});
</script>- 模式对话框触发:本节使用按钮来调用模式对话框,通过设定按钮的data-toggle参数为"modal"来申明当前按钮的触发方式为模式对话框,同时需要通过设定data-target 参数来具体确定当前哪个模式对话框需要被触发弹出,其属性值设定为模式对话框的id号;
- Bootstrap提供的模式对话框由三部分构成:头部(modal-header)、主体(modal-body)、尾部(modal-footer),每部分之间以一根灰色线进行分隔;
- 图像显示逻辑:模式对话框主体部分放置了两个组件,其中1个图片组件用于显示当前上传的图片,另1个文件上传组件用于选择本地图片进行上传。用户单击浏览按钮,选择1张图像,此时触发输入图片的change属性。根据编写的JS代码,当图片改变的时候,通过文件流读取当前上传的图片,并将图片内容赋值给图片组件的src属性用于显示图片;
接下来需要使用Ajax技术实现图片发送功能,将图片发送至服务器并且进行人脸检测,返回的结果也以图像的形式进行接收并显示。具体代码如下:
<script>
$('#compute').click(function () {
formdata = new FormData();
var file = $("#photo")[0].files[0];
formdata.append("image", file);
$.ajax({
url: '/serviceApp/facedetectDemo/', // 调用django服务器计算函数
type: 'POST', // 请求类型
data: formdata,
dataType: 'json', // 期望获得的响应类型为json
processData: false,
contentType: false,
success: ShowResult // 在请求成功之后调用该回调函数输出结果
})
})
</script>
<script>
function ShowResult(data) {
var v = data['img64'];
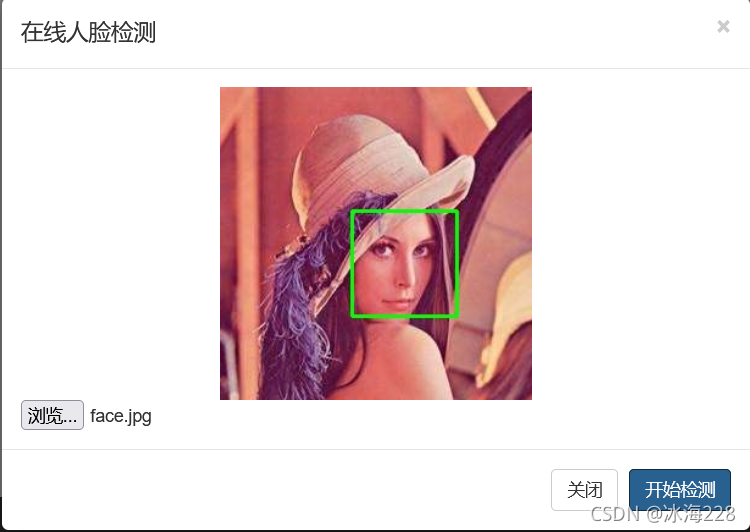
document.getElementById('photoIn').src = "data:image/jpeg;base64, " + v;
}
</script>- 基于Ajax的图像发送:发送图像数据需要采用一种FormData格式,即将上传的图片文件用formdata.append方式完成封装,最后只需要在Ajax的data属性中嵌入formdata变量即可;
- Ajax返回结果处理:Ajax返回结果使用额外的函数ShowResult进行实现,主要用于处理返回的图像数据,将图像进行显示。为了与本地调用接口区分,需要在后台额外的添加人脸处理函数,将检测框直接显示在图像上并将图像返回。此处定义新的url,其访问网址为'/serviceApp/facedetectDemo/',具体的后台实现后续会给出详细代码;
- 图像的base64显示:base64是网络上最常见的用于传输8Bit字节码的编码方式之一,base64就是一种基于64个可打印字符来表示二进制数据的方法。base64编码是从二进制转成字符的过程,可用于在HTTP环境下传递较长的标识信息。为了能够在网络上正常传输图像数据,这里采用base64进行图像的编解码。当前Ajax接收到的图像数据是由后台按照base64编码完成的。因此,需要将获取到的base64字符串按照特定格式传递给img组件并显示;
接下来开始开发后台视图处理程序。前面一节中开发的人脸视图处理函数返回了当前检测人脸的矩形框坐标值,此时可以继续使用该处理函数,但是需要在前端页面中根据返回的坐标值在画布Canvas中进行坐标换算和画框,页面逻辑较为复杂。为了简化实现过程,我们在后端检测完成后直接将显示框绘制在原图上。
具体的在views.py文件中添加facedetectDemo函数,详细代码如下:
import base64
@csrf_exempt
def facedetectDemo(request):
result = {}
if request.method == "POST":
if request.FILES.get('image') is not None: #
img = read_image(stream=request.FILES["image"])
else:
result["#faceNum"] = -1
return JsonResponse(result)
if img.shape[2] == 3:
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 彩色图像转灰度图像
else:
imgGray = img
#进行人脸检测
values = face_detector.detectMultiScale(imgGray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
#将检测得到的人脸检测关键点坐标封装
values = [(int(a), int(b), int(a + c), int(b + d))
for (a, b, c, d) in values]
# 将检测框显示在原图上
for (w, x, y, z) in values:
cv2.rectangle(img, (w, x), (y, z), (0, 255, 0), 2)
retval, buffer_img = cv2.imencode('.jpg', img) # 在内存中编码为jpg格式
img64 = base64.b64encode(buffer_img) # base64编码用于网络传输
img64 = str(img64, encoding='utf-8') # bytes转换为str类型
result["img64"] = img64 # json封装
return JsonResponse(result)- 实现逻辑:处理函数从POST请求中通过request.FILES.get('image')获取图像数据,然后根据定义的read_image函数读取图像;接下来使用cv2.cvtColor函数将彩色图像转灰度,然后调用OpenCV的人脸检测函数进行检测;接下来根据检测得到的矩形框使用cv2.rectangle函数绘制到每一个人脸上;最后对图像进行jpg以及base64转码实现图像数据的返回;
- 返回图像数据的格式:首先使用OpenCV提供的imencode函数在内存中对图像进行压缩编码,压缩格式为jpg格式;然后使用base64模块提供的b64encode函数对数据进行base64转码以方便网络传输,最后将得到的bytes数据转化为字符串类型并按照json格式进行封装;
最后为新添加的视图处理函数添加对应的路由,打开urls.py文件,添加路由如下:
urlpatterns = [
...其它路由...
path('facedetectDemo/', views.facedetectDemo, name='facedetectDemo'),
]保存所有修改后启动项目,上传照片并进行测试,效果如下图所示。
本节课通过搭建一个简单的基于Web的人工智能开放平台,利用Django框架在服务器端实现了人脸检测功能,同时提供有效的API接口供本地脚本调用,通过该平台的搭建旨在为读者拓宽思路和学习方向,熟悉当前人工智能的一种常见Web部署方案,为今后进一步的深入学习打下良好的基础。
到这里,本系列课程已全部结束,希望本课程能够给您学习道路上一些启发和帮助。
由于时间比较匆忙,这个系列博客教程还有很多需要完善的地方,我会尽可能的抽出时间不断的对其进行优化,使之更简洁、更实用。
本节课完整代码和数据下载地址如下:
百度网盘:https://pan.baidu.com/s/1CNniT0VSEz-PxDiapYhb8g
提取码:7tlr
课程介绍链接:Python Web企业门户网站—系列博客教程介绍_冰海的博客-CSDN博客_python web开发从入门到实战