超详细的一篇数据分析实战案例,模拟真实业务,建议收藏慢慢阅读!
目录
- 必看前言
- 1 行业背景
- 1.1 业务环境
- 1.2 发展现状
- 1.3 发展趋势
- 1.4 衡量指标
- 2 数据介绍
- 2.1 基本信息
- 2.2 家庭信息
- 2.3 家庭成员
- 2.4 疾病史
- 2.5 金融信息
- 2.6 个人习惯
- 2.7 家庭状况
- 2.8 居住城市
- 3 案例分析
- 3.1 分析流程
- 3.1.1 导入数据,观察数据
- 3.1.2 探索数据&数据可视化分析
- 3.1.2.1 处理列标签名异常
- 3.1.2.2 创建自定义翻译函数
- 3.1.2.3 探索用户基本信息
- 3.1.2.4 探索家庭成员字段信息
- 3.1.2.5 探索疾病相关字段
- 3.1.2.6 探索投资相关字段
- 3.1.2.7 探索生活习惯
- 3.1.2.8 探索家庭收入
- 3.1.2.9 探索所处地区情况
- 3.1.3 数据清洗
- 3.1.3.1 删除特征
- 3.1.3.2 删除重复值
- 3.1.3.3 划分训练集与测试集
- 3.1.3.4 填充缺失值
- 3.1.4 转码
- 3.1.4.1 0-1转码
- 3.1.4.2 哑变量转码
- 3.1.4.3 对测试集进行转码(总结)
- 3.1.5 数据建模与评估
- 3.1.5.1 初步建模
- 3.1.5.2 网格搜索找最优参数
- 3.1.5.3 模型评估
- 3.1.5.4 输出规则
- 3.1.6 输出结果的商业应用
- 3.1.6.1 第一类
- 3.1.6.2 第二类
- 3.1.6.3 了解客户需求
- 3.1.6.4 开发新的产品
- 结束语
必看前言
本次文章将会介绍一篇基于决策树模型的金融保险用户分类综合项目,我会从行业背景讲起,将整个项目包括代码全po上来,大家看目录就知道有多么详细啦。
1 行业背景
1.1 业务环境
- 宏观
中国是世界第二大保险市场,但在保险密度上与世界平均水平仍有明显差距。 - 业界
保险行业2018年保费规模为3.8万亿,同比增长不足4%,过去"短平快"的发展模式已经不能适应新时代的行业发展需求,行业及用户长期存在难以解决的痛点,限制了行业发展。 - 社会
互联网经济的发展,为保险行业带来了增量市场,同时随着网民规模的扩大,用户的行为习惯已发生转变,这些都需要互联网的方式进行触达。保险科技∶当前沿科技不断应用于保险行业,互联网保险的概念将会与保险科技概念高度融合。
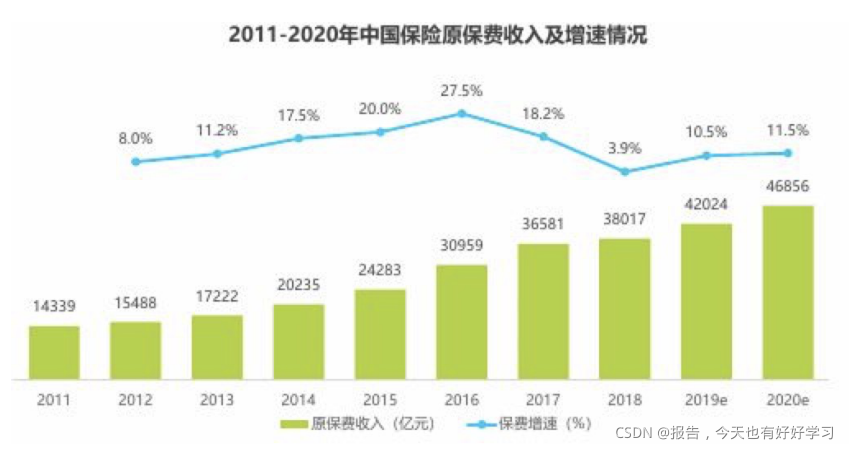
中国保险市场持续高速增长。根据保监会数据,2011~2018年,全国保费收入从1.4万亿增长至3.8万亿,年复合增长率17.2%。2014年,中国保费收入突破2万亿,成为全球仅次于美国、日本的第三大新兴保险市场市场;2016年,中国整体保费入突破3万亿,超过日本,成为全球第二大保险市场;2019年,中国保费收入突破4万亿。
1.2 发展现状
- 概览
受保险行业结构转型时期影响,互联网保险整体发展受阻,2018年行业保费收入为1889亿元,较17年持平,不同险种发展呈现分化格局,其中健康险增长迅猛,2018年同比增长108%,主要由短期医疗险驱动。 - 格局
供给端专业互联网保险公司增长迅速,但过高的固定成本及渠道费用使得其盈利问题凸显,加上发展现状强,自营渠道建设及科技输出是未来的破局方法,渠道端形成第三方平台为主,官网为辅的格局,第三方平台逐渐发展出B2C、B2A、B2B2C等多种创新业务模式。 - 模式
互联网保险不仅仅局限于渠道创新,其核心优势同样体现在产品设计的创新和服务体验的提升。
1.3 发展趋势
- 竞合格局
随着入局企业增多,流量争夺更加激烈,最终保险公司与第三方平台深度合作将成为常态。 - 保险科技
当前沿科技不断应用于保险行业,互联网保险的概念将会与保险科技概念高度融合。
1.4 衡量指标
2 数据介绍
- 数据来源
美国某保险公司,该公司的一款医疗产品准备上市。 - 商品介绍
这是一款针对65岁人群推出的医疗附加险,销售渠道是直邮。 - 商业目的
为该产品做用户画像,找到最具购买倾向的人群进行营销。
本次案例数据中共有76个字段,字段繁多,在处理数据时,需要先将数据按照类别进行划分,方便理解查看。
2.1 基本信息
| 变量名称 | 变量含义 | 备注 |
|---|---|---|
| KBM_INDY_ID | 用户ID | 无意义特征 |
| resp_flag | 用户是否购买保险 | 我们的目标变量 |
| age | 用户年龄 | 本产品为针对65岁以上的人群保险 |
| GEDN | 性别 | |
| c210mys | 学历 | 0-unknown; 1-初中; 2-高中不到; 3-高中毕业; 4-大学未毕业; 5-大专; 6-本科; 7-研究生; 8-专业院校毕业; 9-博士 |
| POC19 | 是否有小孩 | |
| CA[XX] | 小孩年龄 |
2.2 家庭信息
| 变量名称 | 变量含义 | 备注 |
|---|---|---|
| NOC19 | 家庭小孩个数 | |
| NAH19 | 家庭成年人个数 | |
| NPH19 | 家庭成员人数 | |
| POEP | 家庭是否为有老人 |
2.3 家庭成员
| 变量名称 | 变量含义 | 备注 |
|---|---|---|
| U18 | 是否有家庭成员小于18岁 | |
| N1819 | 是否有家庭成员在18-19岁之间 | |
| N2029 | 是否有家庭成员在20-29岁之间 | |
| N3039 | 是否有家庭成员在30-39岁之间 | |
| N4049 | 是否有家庭成员在40-49岁之间 | |
| N5059 | 是否有家庭成员在50-59岁之间 | |
| N6064 | 是否有家庭成员在60-64岁之间 | |
| N65P | 是否有家庭成员在65岁以上 |
2.4 疾病史
| 变量名称 | 变量含义 | 备注 |
|---|---|---|
| AART | 是否有关节炎 | |
| ADBT | 是否有糖尿病 | |
| ADEP | 是否有抑郁症 | |
| AHBP | 是否有高血压 | |
| AHCH | 胆固醇含量是否过高 | |
| ARES | 是否有呼吸疾病 | |
| … | … |
2.5 金融信息
| 变量名称 | 变量含义 | 备注 |
|---|---|---|
| BANK | 是否有过破产记录 | |
| FINI | 是否有过保险服务 | |
| INLI | 是否投资过寿险 | |
| INMEDI | 是否购买过医疗险 | |
| INVE | 是否有投资 | |
| … | … |
2.6 个人习惯
| 变量名称 | 变量含义 | 备注 |
|---|---|---|
| IOLP | 是否网上购买过产品 | |
| MOBPLUS | 是否通过快递买过东西 | M-通过多种快递渠道购买;P-或许通过多种快递渠道购买;S-单一快递渠道购买;U-不知道; |
| ONLA | 是否上网 | |
| SGFA | 是否喜欢美术 | |
| SGLL | 是否经常有奢侈消费 | |
| SGDE | 是否经常户外活动 | |
| SGSE | 是否喜欢运动 | |
| … | … |
2.7 家庭状况
| 变量名称 | 变量含义 | 备注 |
|---|---|---|
| LIVEWELL | 幸福指数 | 值越大,说明越幸福 |
| HOMSTAT | 是否有房子 | Y:有房子;P:可能有房子;R:租房;TU:不确定 |
| HINSUB | 是否有医保补贴 | A-C,补贴依次增加 |
| c210cip | 收入所处排名 | 值越大,说明收入越高 |
| c210ebi | 普查家庭有效购买收入 | 值越大,说明有效购买收入越高 |
| c210hmi | 家庭收入 | 值越大,说明家庭收入越高 |
| c210hva | 家庭房屋价值 | 值越大,说明房屋价值越高 |
| c210… | 家庭经济类数据 | 值越大,说明经济地位越高 |
2.8 居住城市
| 变量名称 | 变量含义 | 备注 |
|---|---|---|
| STATE_NAME | 是否网上购买过产品 | |
| c210apvt | 贫穷以上人的比例 | 值越大,说明比例越高 |
| c210b200 | 所处地区有多少居住小区在2000年后建立 | 值越大,说明比例越高 |
| c210blu | 所处地区蓝领所占百分比 | 值越大,说明比例越高 |
| c210bpvt | 贫穷以下人的比例 | 值越大,说明比例越高 |
| c210mob | 所处地区mobile home的比例 | 值越大,说明比例越高 |
| c210pdv | 离婚或者分局人群所占比例 | 值越大,说明比例越高 |
| … | 居住地统计数据 | 值越大,说明比例越高 |
3 案例分析
我们可以大概判别哪些特征很可能和用户是否购买保险会有相关关系。
也可以结合我们的业务经验,以及数据可视化,特征工程方法,先行探索一下,这些特征中哪些特征更重要一些。
可以在建模之后,再回顾我们这里认为比较重要或不重要的特征,看一下判断是否准确。
3.1 分析流程
- 导入数据,观察数据
- 探索数据 & 数据可视化分析(探索缺失值填充方案、转码方案、一些特殊字段的处理方案等)
- 空值填充
- 变量编码
- 数据建模
- 输出规则(决策树图)
#全部行都能输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 解决坐标轴刻度负号乱码
plt.rcParams['axes.unicode_minus'] = False
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Simhei']
3.1.1 导入数据,观察数据
data_00 = pd.read_csv('data/ma_resp_data_temp.csv')
feature_dict = pd.read_excel('保险案例数据字典.xlsx')
data_01 = data_00.copy()
3.1.2 探索数据&数据可视化分析
注意:在我们进行探索数据时,可以结合一下EXCEL,用EXCEL来记录数据后续需要进行的对应操作(可以分成删除、转换、填充三种情况),这样也方便我们后续进行数据清洗。
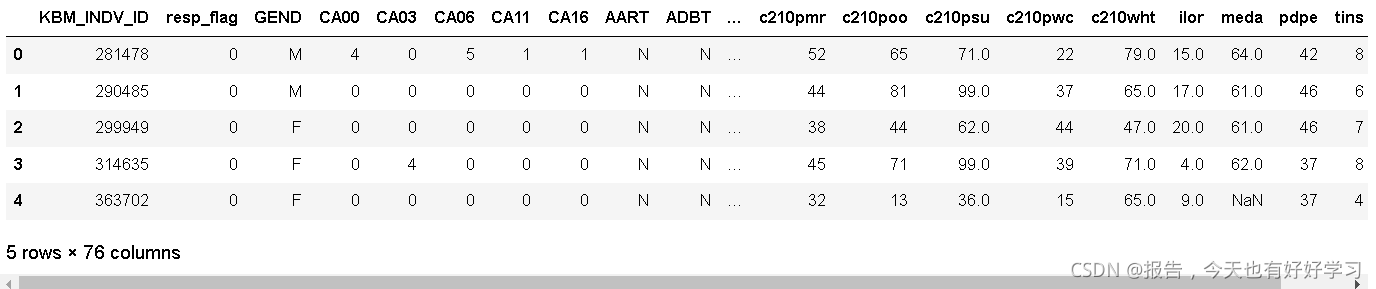
data_01.head()
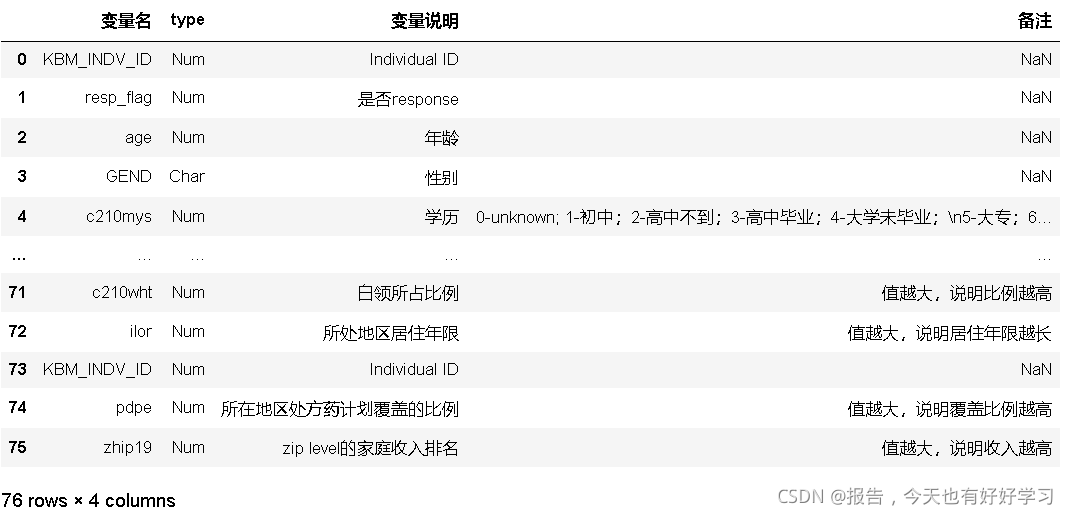
feature_dict
3.1.2.1 处理列标签名异常
表中的字段与数据字典不匹配。
判断data_01中的列标签名是否都出现在数据字典的变量名中。
data_01.columns

feature_dict.变量名

#求补集
np.setxor1d(data_01.columns,feature_dict.变量名)

'''
#数据表列标签
NY8Y9', 'N2N29', 'N3N39', 'N4N49', 'N5N59', 'N6N64'
#数据字典
'N1819', 'N2029','N3039','N4049', 'N5059','N6064'
meda # 这个莫名其妙,删掉
'''
# 删掉
data_01['meda'].nunique()
75
替换异常标签
a = ['NY8Y9', 'N2N29', 'N3N39', 'N4N49', 'N5N59', 'N6N64']
b = ['N1819', 'N2029','N3039','N4049', 'N5059','N6064']
# 要替换的列标签,做成映射字典
dic = dict(zip(a,b))
dic
#自定义要转化的向量化函数
def tran(x):
if x in dic:
return dic[x]
else:
return x
tran = np.vectorize(tran) #向量化
#使用向量化函数替换异常表头
data_01.columns = tran(data_01.columns)

3.1.2.2 创建自定义翻译函数
提高探索数据效率,创建自定义翻译函数,通过映射字典的方式,替换DataFrame列标签名为中文:
dic = {k:v for k,v in feature_dict[['变量名','变量说明']].values.reshape(-1,2)}
def chinese(x):
y = x.copy()
#将输入进来的字段名通过字典映射的方式去对应
y.columns = pd.Series(y.columns).map(dic)
return y
chinese(data_01).head()

3.1.2.3 探索用户基本信息
feature_dict.变量名[:5]

feature_dict.变量名[:5].tolist() #得到列表

data_01[feature_dict.变量名[:5].tolist()].head()

#将0_4列取出来并进行翻译
data0_4 = chinese(data_01[feature_dict.变量名[:5].tolist()])
data0_4.head()
下面来看一下数据的基本信息。
data0_4.info()
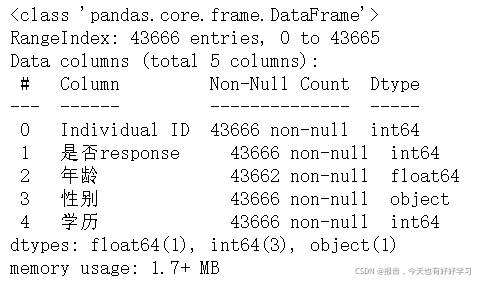
再看一下缺失值
data0_4.isnull().sum()

发现是有缺失的(后续要处理)。
同时,我们不难发现上面这些方法都是常用到的,可以考虑封装成函数,方便后续使用。
自定义探索特征频率函数
输入一个DataFrame,输出每个特征的频数分布:
def fre(x):
for i in x.columns:
print("字段名:",i)
print("----------")
print("字段数据类型:",x[i].dtype)
print("----------------------------")
print(x[i].value_counts()) #频数
print("----------------------------")
print("缺失值的个数:",x[i].isnull().sum())
print("------------------------------------------------\n\n")
fre(data0_4)
输出结果如下:
字段名: Individual ID
----------
字段数据类型: int64
----------------------------
142936063 1
68797618 1
193209817 1
172309160 1
171816124 1
..
172641155 1
76214763 1
228943803 1
185032198 1
1966080 1
Name: Individual ID, Length: 43666, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否response
----------
字段数据类型: int64
----------------------------
0 26177
1 17489
Name: 是否response, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 年龄
----------
字段数据类型: float64
----------------------------
66.0 3967
67.0 3670
65.0 3475
69.0 3449
68.0 3423
70.0 2948
71.0 2943
72.0 2909
74.0 2817
73.0 2814
75.0 2448
76.0 2220
78.0 2038
77.0 2012
79.0 1823
80.0 691
91.0 2
86.0 2
88.0 2
96.0 1
99.0 1
82.0 1
95.0 1
90.0 1
98.0 1
87.0 1
94.0 1
101.0 1
Name: 年龄, dtype: int64
----------------------------
缺失值的个数: 4
------------------------------------------------
字段名: 性别
----------
字段数据类型: object
----------------------------
F 25405
M 18261
Name: 性别, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 学历
----------
字段数据类型: int64
----------------------------
4 18597
3 12437
6 7493
5 4474
2 462
7 130
0 60
1 9
8 4
Name: 学历, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
- Individual ID是我们要删的(后面也有一个ID);
- 是否response则是我们的标签;
- 年龄则是有些缺失值(年龄有高有低,最高都101岁,可以考虑用中位数填充);
- 性别则是需要进行0-1编码;
- 学历需要转成哑变量(即one-hot编码)。
来看一下购买情况。
import seaborn as sns
#中文编码
sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']})
#sns.set()
plt.figure(1,figsize=(6,2))
sns.countplot(y='是否response',data=data0_4)
plt.show()
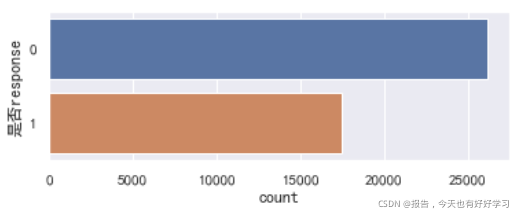
差别不是很大,后续使用class_weight参数与否也不重要。
#根据年龄 概率密度图
sns.kdeplot(data0_4.年龄[data0_4.是否response==1],label='购买')
sns.kdeplot(data0_4.年龄[data0_4.是否response==0],label='不购买')
sns.kdeplot(data0_4.年龄.dropna(),label='所有人')
plt.xlim([60,90])
plt.xlabel('Age')
plt.ylabel('Density')
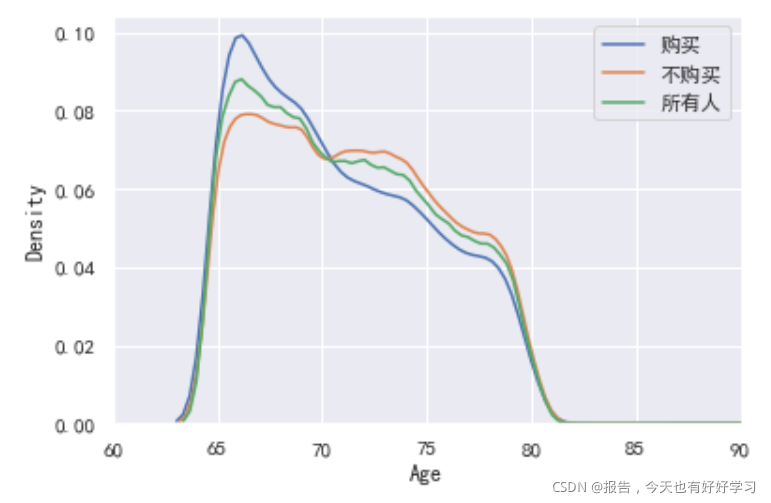
3.1.2.4 探索家庭成员字段信息
#将5_22列取出来并进行翻译
data5_22 = chinese(data_01[feature_dict.变量名[5:23].tolist()])
data5_22.head()
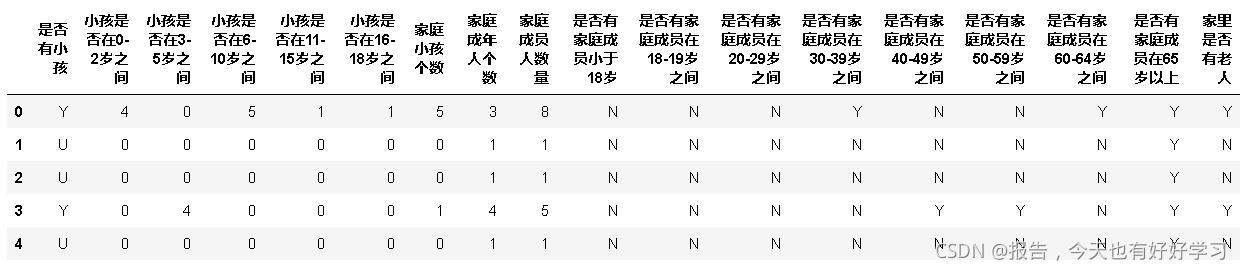
调用一下刚自定好的函数。
fre(data5_22)
输出结果为:
字段名: 是否有小孩
----------
字段数据类型: object
----------------------------
U 24500
Y 10225
P 8941
Name: 是否有小孩, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 小孩是否在0-2岁之间
----------
字段数据类型: int64
----------------------------
0 40677
4 2856
1 57
2 48
3 16
6 9
5 3
Name: 小孩是否在0-2岁之间, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 小孩是否在3-5岁之间
----------
字段数据类型: int64
----------------------------
0 41087
4 2068
1 204
2 202
3 45
5 30
6 29
7 1
Name: 小孩是否在3-5岁之间, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 小孩是否在6-10岁之间
----------
字段数据类型: int64
----------------------------
0 38969
4 2960
1 553
2 528
6 240
5 209
3 176
7 31
Name: 小孩是否在6-10岁之间, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 小孩是否在11-15岁之间
----------
字段数据类型: int64
----------------------------
0 39430
4 2281
1 757
2 651
3 211
5 176
6 140
7 20
Name: 小孩是否在11-15岁之间, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 小孩是否在16-18岁之间
----------
字段数据类型: int64
----------------------------
0 40243
4 1590
1 826
2 718
3 164
5 70
6 54
7 1
Name: 小孩是否在16-18岁之间, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 家庭小孩个数
----------
字段数据类型: int64
----------------------------
0 33441
1 5089
2 2365
3 1298
4 1008
5 290
6 116
7 30
8 26
9 3
Name: 家庭小孩个数, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 家庭成年人个数
----------
字段数据类型: int64
----------------------------
1 15792
2 13414
3 7633
4 3942
5 1292
0 1105
6 349
7 101
8 29
9 9
Name: 家庭成年人个数, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 家庭成员人数量
----------
字段数据类型: int64
----------------------------
1 14970
2 11148
3 6120
4 4123
5 2499
6 1547
0 1105
7 994
8 569
9 316
10 152
11 79
12 25
13 12
15 3
14 3
16 1
Name: 家庭成员人数量, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有家庭成员小于18岁
----------
字段数据类型: object
----------------------------
N 43665
Y 1
Name: 是否有家庭成员小于18岁, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有家庭成员在18-19岁之间
----------
字段数据类型: object
----------------------------
N 43579
Y 78
Name: 是否有家庭成员在18-19岁之间, dtype: int64
----------------------------
缺失值的个数: 9
------------------------------------------------
字段名: 是否有家庭成员在20-29岁之间
----------
字段数据类型: object
----------------------------
N 41318
Y 2348
Name: 是否有家庭成员在20-29岁之间, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有家庭成员在30-39岁之间
----------
字段数据类型: object
----------------------------
N 36624
Y 7042
Name: 是否有家庭成员在30-39岁之间, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有家庭成员在40-49岁之间
----------
字段数据类型: object
----------------------------
N 34740
Y 8926
Name: 是否有家庭成员在40-49岁之间, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有家庭成员在50-59岁之间
----------
字段数据类型: object
----------------------------
N 38345
Y 5321
Name: 是否有家庭成员在50-59岁之间, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有家庭成员在60-64岁之间
----------
字段数据类型: object
----------------------------
N 39544
Y 4121
0 1
Name: 是否有家庭成员在60-64岁之间, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有家庭成员在65岁以上
----------
字段数据类型: object
----------------------------
Y 42461
N 1205
Name: 是否有家庭成员在65岁以上, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 家里是否有老人
----------
字段数据类型: object
----------------------------
N 33522
Y 10136
Name: 家里是否有老人, dtype: int64
----------------------------
缺失值的个数: 8
------------------------------------------------
- 是否有小孩这个字段有三种值:U代表不知道,Y代表有,P表示可能有(美国老人和子女间的联系比较少,不知道自己有没有孙子孙女),后续转成哑变量;
- 小孩是否在0~2岁之间:我们发现有4个0~2岁的小孩的数量有2856,如果是子女的话很不科学,所以我们猜测是孙子孙女(所以上面的P才解释得通);
- 是否有家庭成员是小于18岁的:发现只有1个数据是有小于18岁的成员的,与上述数据完全不符,说明这个数据是有问题的,后续需要删掉;
- 是有有家庭成员在18~19岁之间:存在缺失值,考虑用众数填充;
- 是否有家庭成员在60~64岁之间:发现有个数据是0,怀疑可能原本是N弄成了0,后续可以将0替换成N;
- 家里是否有老人:我们统计的对象本来就是老人,但是数据却很多没有老人,推测可能存在对象觉得自己不算在其中的情况,我们可以考虑将这个字段删掉;
- 其他字段可以将N和P转成0和1;
3.1.2.5 探索疾病相关字段
老套路:
#将23_35列取出来并进行翻译
data23_35 = chinese(data_01[feature_dict.变量名[23:35].tolist()])
data23_35.head()

fre(data23_35)
字段名: 是否有关节炎
----------
字段数据类型: object
----------------------------
N 38369
Y 5297
Name: 是否有关节炎, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有糖尿病
----------
字段数据类型: object
----------------------------
N 40554
Y 3112
Name: 是否有糖尿病, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有抑郁症
----------
字段数据类型: object
----------------------------
N 41674
Y 1992
Name: 是否有抑郁症, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有高血压
----------
字段数据类型: object
----------------------------
N 38102
Y 5564
Name: 是否有高血压, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 胆固醇含量是否过高
----------
字段数据类型: object
----------------------------
N 37395
Y 6271
Name: 胆固醇含量是否过高, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有呼吸疾病
----------
字段数据类型: object
----------------------------
N 40900
Y 2766
Name: 是否有呼吸疾病, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有心脏病
----------
字段数据类型: object
----------------------------
N 41733
Y 1933
Name: 是否有心脏病, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有过敏性鼻炎
----------
字段数据类型: object
----------------------------
N 36824
Y 6832
Name: 是否有过敏性鼻炎, dtype: int64
----------------------------
缺失值的个数: 10
------------------------------------------------
字段名: 是否有消化不良
----------
字段数据类型: object
----------------------------
N 37381
Y 6285
Name: 是否有消化不良, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否耳聋
----------
字段数据类型: object
----------------------------
N 42082
Y 1584
Name: 是否耳聋, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有皮肤病
----------
字段数据类型: object
----------------------------
N 41161
Y 2497
Name: 是否有皮肤病, dtype: int64
----------------------------
缺失值的个数: 8
------------------------------------------------
字段名: 是否视力不好
----------
字段数据类型: object
----------------------------
N 38399
Y 5267
Name: 是否视力不好, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
- 是否有过敏性鼻炎:有10个缺失值,考虑用众数填充;
- 是否有皮肤病:有8个缺失值,考虑用众数填充;
- N和P转成0和1。
从常理性来讲,疾病之间很可能是存在相关性的,所以我们可以看看这些字段之间的相关性(画热力图),找到高度相关的字段并删除。
那我们得先将字段数据 转换成0-1编码:
#0 1 转码
def zero_one(x):
for i in x.columns:
if x[i].dtype == 'object':
dic = dict(zip(list(x[i].value_counts().index),range(x[i].nunique())))
x[i] = x[i].map(dic)
return x
zero_one(data23_35).corr()
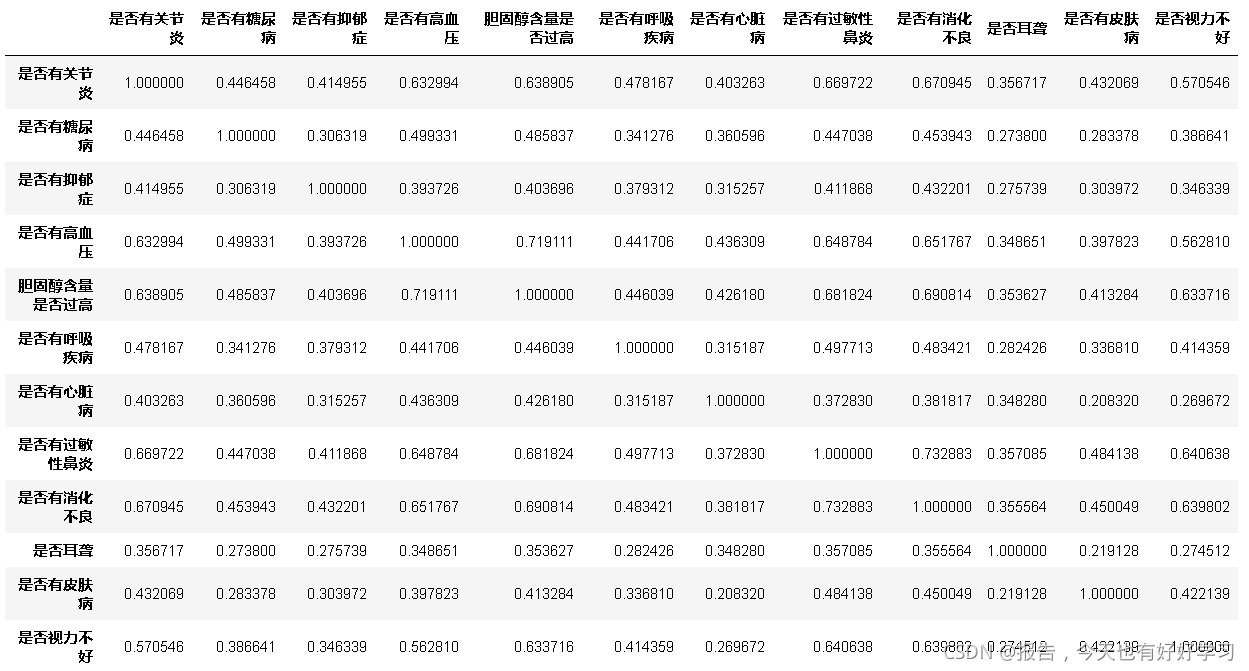
单看表可能比较头疼,下面我们画张热力图看看:
import matplotlib.pyplot as plt
import seaborn as sns
sns.heatmap(zero_one(data23_35).corr(),cmap='Blues')
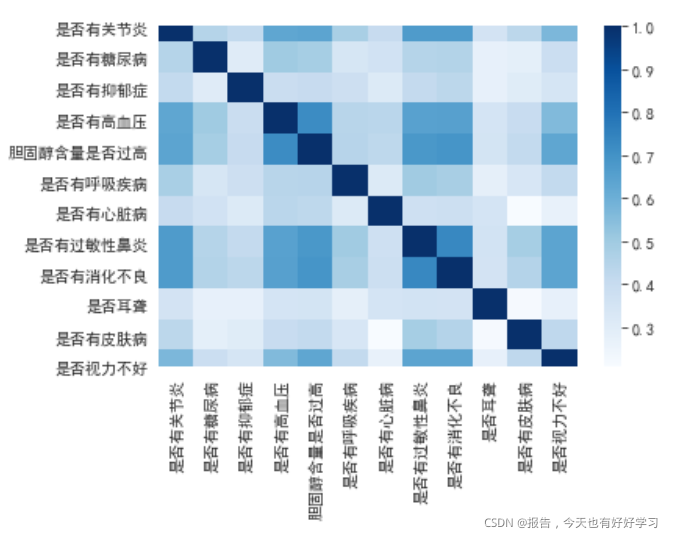
越蓝相关性越高。肉眼可以看出来相关性了,不过还是写个函数直接输出相关性高的字段更好,这里我们输出相关性高于0.65的字段(可以删,但不然删太多,对决策树的创建也不好)。
def higt_cor(x,y=0.65):
data_cor = (x.corr()>y)
a=[]
for i in data_cor.columns:
if data_cor[i].sum()>=2: # 有两个或两个以上的TRUE
a.append(i)
return a #这些是我们要考虑删除的
higt_cor(data23_35) #是否有关节炎 胆固醇含量是否过高 是否有过敏性鼻炎
[‘是否有关节炎’, ‘是否有高血压’, ‘胆固醇含量是否过高’, ‘是否有过敏性鼻炎’, ‘是否有消化不良’]
我们可以再结合一下图,考虑删除是否有关节炎 胆固醇含量是否过高 是否有过敏性鼻炎这三个字段。
3.1.2.6 探索投资相关字段
老套路:
#将35_41列取出来并进行翻译
data35_41 = chinese(data_01[feature_dict.变量名[35:41].tolist()])
data35_41.head()
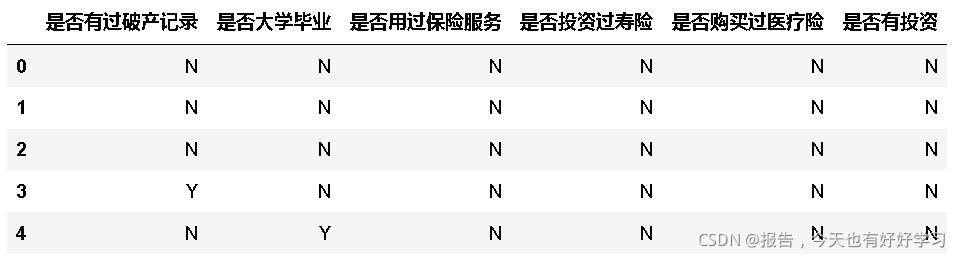
- 都是要改成0-1编码。
fre(data35_41)
字段名: 是否有过破产记录
----------
字段数据类型: object
----------------------------
N 40599
Y 3067
Name: 是否有过破产记录, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否大学毕业
----------
字段数据类型: object
----------------------------
N 39236
Y 4422
Name: 是否大学毕业, dtype: int64
----------------------------
缺失值的个数: 8
------------------------------------------------
字段名: 是否用过保险服务
----------
字段数据类型: object
----------------------------
N 42793
Y 873
Name: 是否用过保险服务, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否投资过寿险
----------
字段数据类型: object
----------------------------
N 35871
Y 7795
Name: 是否投资过寿险, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否购买过医疗险
----------
字段数据类型: object
----------------------------
N 40016
Y 3650
Name: 是否购买过医疗险, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否有投资
----------
字段数据类型: object
----------------------------
N 33896
Y 9770
Name: 是否有投资, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
- 是否大学毕业:存在缺失值,不过这个数据明显和之前的学历信息重复了,可以删掉。
接下来还是画图看一下属性间的相关性:
sns.heatmap(zero_one(data35_41).corr(),cmap='Blues')
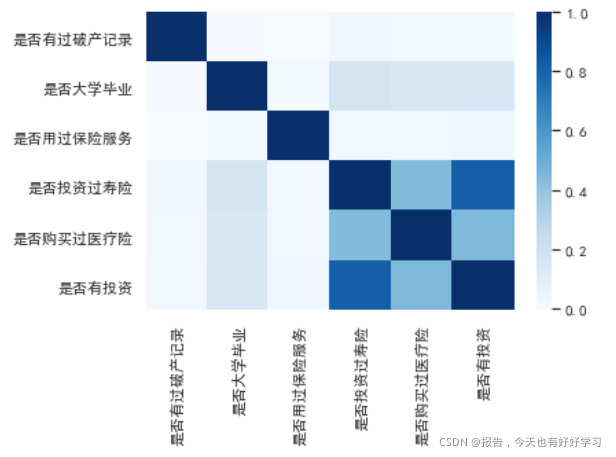
可以看到后下角颜色明显很深。
是否有过投资和是否投资过寿险明显相关,当然我们也可以再调用一下函数查看结果:
higt_cor(data35_41)
[‘是否投资过寿险’, ‘是否有投资’]
结果确实是这样,那我们这个时候要考虑删除其中哪一个?
我们结合一下我们的目的——推荐医疗附加险。是否投资过寿险感觉更贴合我们的目的,所以考虑删掉是否有投资这个字段。
3.1.2.7 探索生活习惯
老套路:
#将41_51列取出来并进行翻译
data41_51 = chinese(data_01[feature_dict.变量名[41:51].tolist()])
data41_51.head()

还是都要改成0-1编码。
我们接着在调用一下函数:
fre(data41_51)
字段名: 是否网上购买过产品
----------
字段数据类型: object
----------------------------
N 36197
Y 7469
Name: 是否网上购买过产品, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否通过快递买过东西
----------
字段数据类型: object
----------------------------
M 27450
S 9947
U 3912
P 2350
Name: 是否通过快递买过东西, dtype: int64
----------------------------
缺失值的个数: 7
------------------------------------------------
字段名: 所处的县的大小
----------
字段数据类型: object
----------------------------
A 26539
B 12687
C 3823
D 607
Name: 所处的县的大小, dtype: int64
----------------------------
缺失值的个数: 10
------------------------------------------------
字段名: 是否上网
----------
字段数据类型: object
----------------------------
Y 28473
N 15193
Name: 是否上网, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否喜欢美术
----------
字段数据类型: object
----------------------------
N 37029
Y 6637
Name: 是否喜欢美术, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否经常有奢侈消费
----------
字段数据类型: object
----------------------------
N 33801
Y 9865
Name: 是否经常有奢侈消费, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否经常户外活动
----------
字段数据类型: object
----------------------------
N 35728
Y 7938
Name: 是否经常户外活动, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否喜欢运动
----------
字段数据类型: object
----------------------------
N 31867
Y 11799
Name: 是否喜欢运动, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 是否热爱科技
----------
字段数据类型: object
----------------------------
N 31370
Y 12296
Name: 是否热爱科技, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 幸福指数
----------
字段数据类型: float64
----------------------------
4.0 16093
3.0 11975
1.0 8837
2.0 6395
6.0 361
Name: 幸福指数, dtype: int64
----------------------------
缺失值的个数: 5
------------------------------------------------
- 是否通过快递买过东西:转成哑变量,同时用众数填补缺失值;
- 所处的县的大小:转成哑变量,同时用众数填补缺失值;
- 其他字段则改成0-1编码。
我们也可以来看下县的大小和购买结果的关系:
sns.countplot(x='N2NCY',hue='resp_flag',data=data_01)
plt.xlabel('县的大小')
plt.ylabel('购买数量')

不难看出,县越大的购买人数就越多。跟我们的日常理解差不多。
3.1.2.8 探索家庭收入
老套路:
#将51_59列取出来并进行翻译
data51_59 = chinese(data_01[feature_dict.变量名[51:59].tolist()])
data51_59.head()
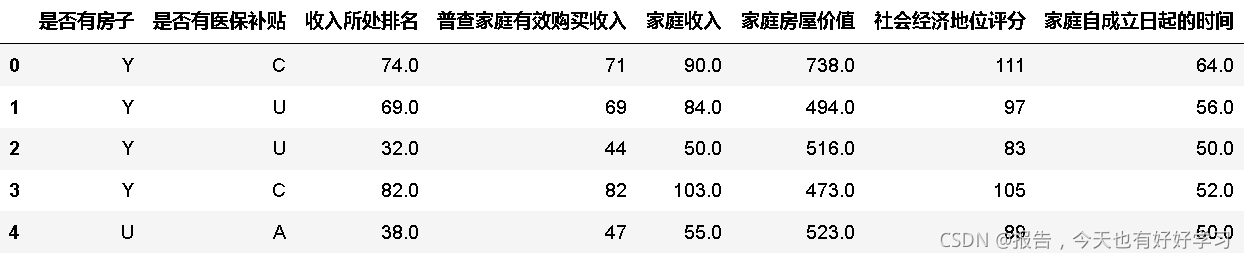
fre(data51_59)
输出结果:
字段名: 是否有房子
----------
字段数据类型: object
----------------------------
Y 31478
U 4747
P 4604
R 2623
T 204
Name: 是否有房子, dtype: int64
----------------------------
缺失值的个数: 10
------------------------------------------------
字段名: 是否有医保补贴
----------
字段数据类型: object
----------------------------
U 21612
C 8972
A 6765
B 6306
Name: 是否有医保补贴, dtype: int64
----------------------------
缺失值的个数: 11
------------------------------------------------
字段名: 收入所处排名
----------
字段数据类型: float64
----------------------------
79.0 713
61.0 648
55.0 647
82.0 636
88.0 607
...
25.0 258
46.0 254
17.0 246
23.0 225
42.0 162
Name: 收入所处排名, Length: 99, dtype: int64
----------------------------
缺失值的个数: 2
------------------------------------------------
字段名: 普查家庭有效购买收入
----------
字段数据类型: int64
----------------------------
48 1034
45 994
44 980
47 967
49 957
...
230 1
198 1
154 1
164 1
191 1
Name: 普查家庭有效购买收入, Length: 208, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 家庭收入
----------
字段数据类型: float64
----------------------------
49.0 746
46.0 713
63.0 710
59.0 687
60.0 683
...
246.0 1
221.0 1
218.0 1
207.0 1
241.0 1
Name: 家庭收入, Length: 224, dtype: int64
----------------------------
缺失值的个数: 7
------------------------------------------------
字段名: 家庭房屋价值
----------
字段数据类型: float64
----------------------------
999.0 1371
138.0 244
168.0 233
125.0 232
175.0 207
...
956.0 1
796.0 1
983.0 1
940.0 1
20.0 1
Name: 家庭房屋价值, Length: 983, dtype: int64
----------------------------
缺失值的个数: 15
------------------------------------------------
字段名: 社会经济地位评分
----------
字段数据类型: int64
----------------------------
77 1194
75 1153
78 1119
80 1119
79 1114
...
166 13
169 12
162 11
165 11
168 8
Name: 社会经济地位评分, Length: 111, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 家庭自成立日起的时间
----------
字段数据类型: float64
----------------------------
55.0 3257
56.0 3110
54.0 3034
53.0 2866
57.0 2826
...
28.0 3
25.0 2
26.0 1
81.0 1
20.0 1
Name: 家庭自成立日起的时间, Length: 64, dtype: int64
----------------------------
缺失值的个数: 15
------------------------------------------------
- 是否有房子:转成哑变量,同时用众数填补缺失值;
- 是否有医保补贴:转成哑变量,同时用众数填补缺失值;
- 收入所处排名:有缺失值,用中位数填补缺失值;
- 家庭收入:有缺失值,用中位数填补缺失值;
- 家庭自成立的时间:有缺失值,用中位数填补缺失值;
接下来我们同样来查看属性间的相关性,看看哪些是需要删除的。
sns.heatmap(zero_one(data51_59).corr(),cmap='Blues')
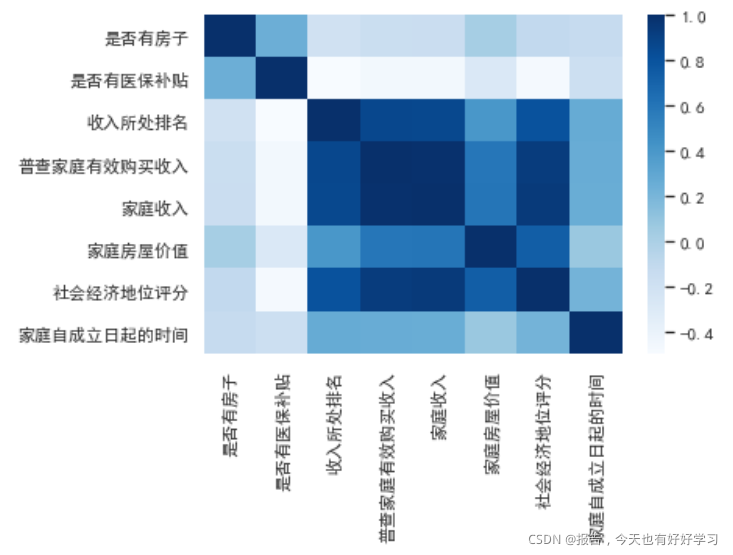
其实主要就是中间这一部分颜色特别深。
higt_cor(data51_59)
[‘收入所处排名’, ‘普查家庭有效购买收入’, ‘家庭收入’, ‘家庭房屋价值’, ‘社会经济地位评分’]
从我们的认知来讲,这些自然是存在高度相关性的,我们可以考虑保留普查家庭有效购买收入这一个属性。
3.1.2.9 探索所处地区情况
老套路:
#将59列之后取出来并进行翻译
data59 = chinese(data_01[feature_dict.变量名[59:].tolist()])
data59.head()
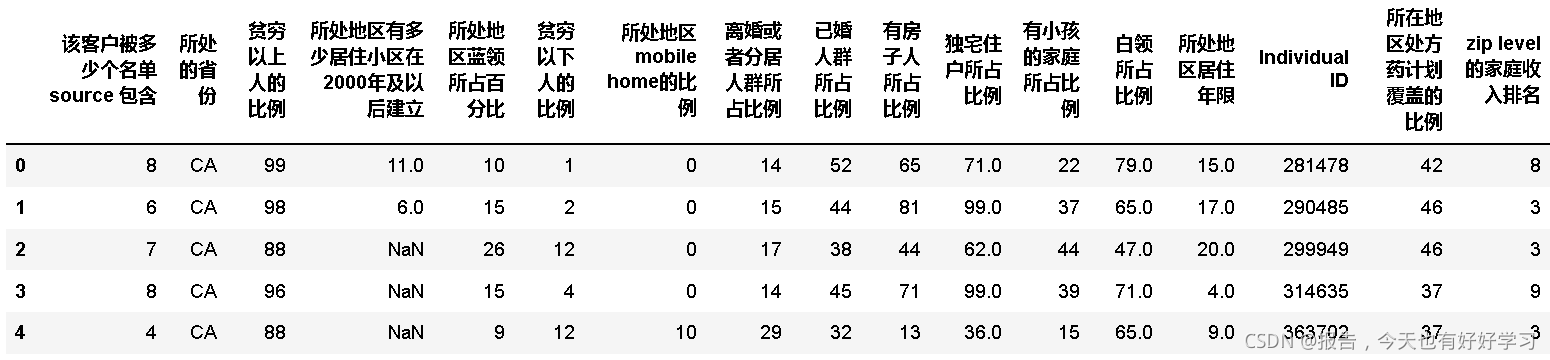
很明显,像这个贫穷以下人的比例和所处地区mobile home的比例这两个属性,我们一看就可以知道是相关性很高的,当然其他字段也是,我们还是用定义好的函数来看一下情况。
fre(data59)
输出结果为:
字段名: 该客户被多少个名单source 包含
----------
字段数据类型: int64
----------------------------
8 4168
9 4152
10 4131
7 3878
11 3735
6 3654
5 3400
4 3144
3 3044
12 3038
2 2229
13 2017
14 1243
1 728
15 630
16 310
17 104
18 48
19 13
Name: 该客户被多少个名单source 包含, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 所处的省份
----------
字段数据类型: object
----------------------------
CA 11700
OH 8959
NY 6481
IN 4954
CT 2873
MO 2202
WI 1884
GA 1687
KY 1375
NH 904
ME 647
Name: 所处的省份, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 贫穷以上人的比例
----------
字段数据类型: int64
----------------------------
99 4081
98 3624
97 3440
96 3307
95 2885
...
17 1
25 1
35 1
22 1
15 1
Name: 贫穷以上人的比例, Length: 81, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 所处地区有多少居住小区在2000年及以后建立
----------
字段数据类型: float64
----------------------------
4.0 2467
2.0 2401
3.0 2364
5.0 2317
1.0 2305
...
81.0 5
90.0 4
95.0 4
86.0 3
94.0 2
Name: 所处地区有多少居住小区在2000年及以后建立, Length: 100, dtype: int64
----------------------------
缺失值的个数: 5
------------------------------------------------
字段名: 所处地区蓝领所占百分比
----------
字段数据类型: int64
----------------------------
18 1717
16 1706
20 1696
17 1679
22 1670
...
61 3
64 2
63 2
67 1
58 1
Name: 所处地区蓝领所占百分比, Length: 66, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 贫穷以下人的比例
----------
字段数据类型: int64
----------------------------
2 3604
3 3464
4 3308
1 3082
5 2884
...
65 1
99 1
83 1
78 1
85 1
Name: 贫穷以下人的比例, Length: 82, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 所处地区mobile home的比例
----------
字段数据类型: int64
----------------------------
0 33478
1 1677
2 1442
3 906
4 658
...
85 2
66 2
73 1
99 1
78 1
Name: 所处地区mobile home的比例, Length: 96, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 离婚或者分居人群所占比例
----------
字段数据类型: int64
----------------------------
14 3288
15 3254
16 3162
13 3100
17 3073
12 2826
18 2805
11 2525
19 2345
10 2139
20 2055
9 1727
21 1724
22 1484
8 1228
23 1154
24 1050
7 999
25 656
26 517
6 500
27 414
5 282
28 266
29 199
30 175
31 135
4 130
32 106
0 62
33 56
3 45
34 39
36 38
2 22
35 21
37 13
38 12
42 7
39 6
41 5
1 5
50 4
40 4
55 3
44 2
48 1
47 1
46 1
43 1
Name: 离婚或者分居人群所占比例, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 已婚人群所占比例
----------
字段数据类型: int64
----------------------------
53 1221
52 1209
48 1164
51 1161
40 1157
...
81 4
79 2
80 2
78 1
82 1
Name: 已婚人群所占比例, Length: 83, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 有房子人所占比例
----------
字段数据类型: int64
----------------------------
85 972
89 913
88 890
81 877
86 856
...
7 120
3 116
97 69
98 9
99 8
Name: 有房子人所占比例, Length: 100, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 独宅住户所占比例
----------
字段数据类型: float64
----------------------------
99.0 6996
98.0 1213
0.0 1193
97.0 1043
95.0 994
...
14.0 142
19.0 139
17.0 138
27.0 123
24.0 122
Name: 独宅住户所占比例, Length: 100, dtype: int64
----------------------------
缺失值的个数: 23
------------------------------------------------
字段名: 有小孩的家庭所占比例
----------
字段数据类型: int64
----------------------------
32 1777
33 1754
34 1719
30 1704
31 1690
...
79 2
76 2
99 1
86 1
83 1
Name: 有小孩的家庭所占比例, Length: 86, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 白领所占比例
----------
字段数据类型: float64
----------------------------
61.0 1198
59.0 1098
63.0 1098
57.0 1072
64.0 1071
...
16.0 3
11.0 2
13.0 1
1.0 1
14.0 1
Name: 白领所占比例, Length: 91, dtype: int64
----------------------------
缺失值的个数: 14
------------------------------------------------
字段名: 所处地区居住年限
----------
字段数据类型: float64
----------------------------
19.0 6287
12.0 2756
1.0 2319
17.0 2125
7.0 2013
...
96.0 1
59.0 1
68.0 1
98.0 1
67.0 1
Name: 所处地区居住年限, Length: 70, dtype: int64
----------------------------
缺失值的个数: 6
------------------------------------------------
字段名: Individual ID
----------
字段数据类型: int64
----------------------------
142936063 1
68797618 1
193209817 1
172309160 1
171816124 1
..
172641155 1
76214763 1
228943803 1
185032198 1
1966080 1
Name: Individual ID, Length: 43666, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: 所在地区处方药计划覆盖的比例
----------
字段数据类型: int64
----------------------------
46 5765
65 2634
47 2518
61 2002
42 1782
...
86 1
88 1
27 1
93 1
95 1
Name: 所在地区处方药计划覆盖的比例, Length: 69, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
字段名: zip level的家庭收入排名
----------
字段数据类型: int64
----------------------------
0 6326
9 5119
8 4784
1 4657
7 4191
2 3998
6 3896
3 3611
5 3549
4 3535
Name: zip level的家庭收入排名, dtype: int64
----------------------------
缺失值的个数: 0
------------------------------------------------
-
所处地区有多少居住小区在2000年及以后建立:有5个缺失值,可以用中位数填充缺失值;
-
独宅住户所占比例:有23个缺失值,可以用中位数填充缺失值;
-
白领所占比例:有14个缺失值,可以用中位数填充缺失值;
-
所处地区居住年限:有6个缺失值,可以用中位数填充缺失值;
-
Individual ID:前面就说过啦,可以删掉这个无用数据;
-
所在地区处方药计划覆盖的比例:和是否有医疗补贴感觉也存在相关性,可以先mark一下;
-
所处的省份:转成哑变量。
可以看下省份之间跟购买结果的情况;
sns.countplot(x='STATE_NAME',hue='resp_flag',data=data_01)
plt.xlabel('所处的省份')
plt.ylabel('购买数量')
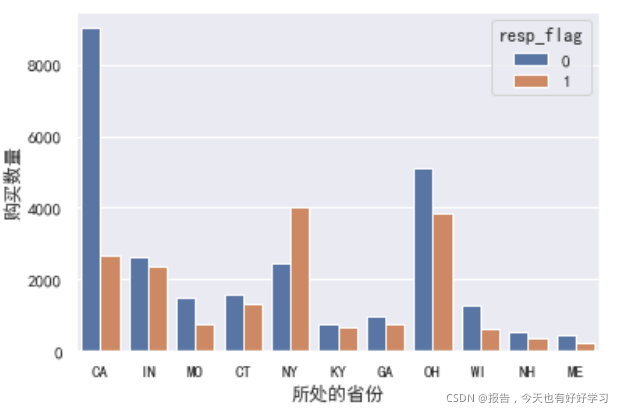
从图可以看出,我们后面营销时重点可以放在NY和OH这两个地方,特别是NY这个地方。
接着我们可以单独将与人群有关的数据拿出来看下彼此之间的相关性。
a = chinese(data_01[["c210apvt","c210blu","c210bpvt","c210mob","c210wht","zhip19"]])
sns.heatmap(a.corr(),cmap='Blues')
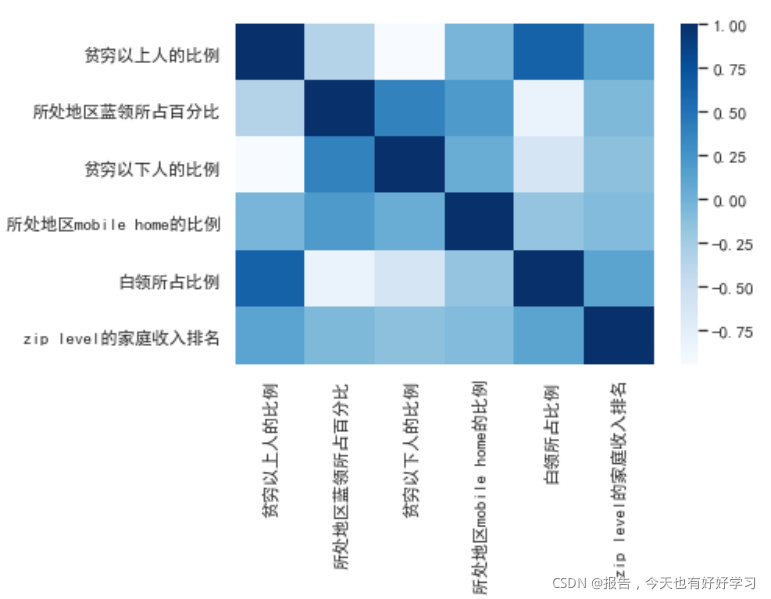
可以看到这里还会出现一些负的相关性,主要是因为我们的数据是比例数据。
从产品的目的来讲,我们的主要目标人群肯定是贫穷以上的人(穷人都这么穷了,应该不会再花钱购买保险了)
接着我们再调用一下方法看下那些相关性高的属性。
higt_cor(data59)
[‘贫穷以上人的比例’, ‘已婚人群所占比例’, ‘有房子人所占比例’, ‘独宅住户所占比例’]
但是这里确实不太适合用这种方法,因为数据主要是比例而不是0-1数据。
当然我们可以看一下所处地区情况的所有字段之间的相关性:
sns.heatmap(data59.corr(),cmap='brg')
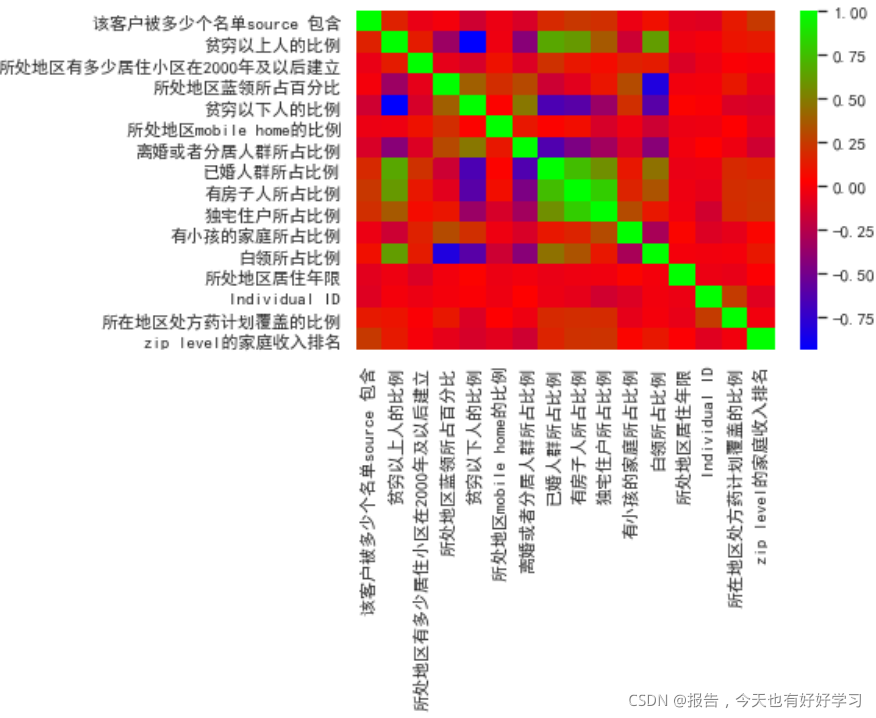
这里越绿相关性越好。
我们这里考虑删掉所处地区蓝领所占百分比、贫穷以下人的比例、有房子人所占比例这三个字段给删掉。
好,到这里,我们数据探索的过程就搞定了,接下来就是通过数据,将我们做好标记的(哪些是要转的、哪些是要删的、哪些是要填充的)数据进行处理。
3.1.3 数据清洗
这里我们还是先备份一下数据:
data_02 = data_01.copy()
data_02.shape
(43666, 76)
3.1.3.1 删除特征
我们从EXCEL找出要删除的字段,直接全部删掉,就不用一个个找啦。
del_col = ["KBM_INDV_ID","U18","POEP","AART","AHCH","AASN","COLLEGE",
"INVE","c210cip","c210hmi","c210hva","c210kses","c210blu","c210bpvt","c210poo","KBM_INDV_ID","meda"]
data_02 = data_02.drop(columns=del_col)
data_02.shape
(43666, 60)
3.1.3.2 删除重复值
我记得我们是没有发现重复值的,不过一般我们还是会进行这一环节的(而且也很简单)。
data_02.drop_duplicates().shape
(43666, 60)
果然,没有重复值。
3.1.3.3 划分训练集与测试集
一定要先划分数据集再填充、转码,别急!
from sklearn.model_selection import train_test_split
y = data_02.pop('resp_flag') #标签
X = data_02 #特征
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=100)
# 最好还是再备份一下,以防万一
Xtrain_01=Xtrain.copy()
Xtest_01=Xtest.copy()
Ytrain_01=Ytrain.copy()
Ytest_01=Ytest.copy()
3.1.3.4 填充缺失值
填充中位数
老规矩,我们打开EXCEL,找到我们标记了需要填充中位数的字段。
fil = ["age","c210mah","c210b200","c210psu","c210wht","ilor"]
Xtrain_01[fil].median()
输出结果为:
age 71.0
c210mah 53.0
c210b200 10.0
c210psu 77.0
c210wht 61.0
ilor 15.0
dtype: float64
dic = dict(zip(Xtrain_01[fil].median().index,Xtrain_01[fil].median()))
dic
输出结果为:
{'age': 71.0,
'c210mah': 53.0,
'c210b200': 10.0,
'c210psu': 77.0,
'c210wht': 61.0,
'ilor': 15.0}
#向训练集填充中位数
Xtrain_01 = Xtrain_01.fillna(dic)
填充众数
基本同样的操作:
mod = ["N1819","ASKN","MOBPLUS","N2NCY","LIVEWELL","HOMSTAT","HINSUB"]
dic_mod = dict(zip(Xtrain_01[mod].mode().columns,Xtrain_01[mod].iloc[0,:]))
Xtrain_01 = Xtrain_01.fillna(dic_mod)
替换填充
这里可不要忘了我们最开始发现的0换N。
Xtrain_01['N6064'] = Xtrain_01['N6064'].replace('0','N') #0 替换成 N
Xtrain_01.isnull().sum()[Xtrain_01.isnull().sum()!=0]
Series([], dtype: int64)
对测试集进行填充(总结)
这里测试集也是一样的方式:
# 需要填的字段
fil = ["age","c210mah","c210b200","c210psu","c210wht","ilor"]
#填充中位数--测试集
dic = dict(zip(Xtest_01[fil].median().index,Xtest_01[fil].median()))
Xtest_01 = Xtest_01.fillna(dic)
# #填充众数--测试集
mod = ["N1819","ASKN","MOBPLUS","N2NCY","LIVEWELL","HOMSTAT","HINSUB"]
dic_mod = dict(zip(Xtest_01[mod].mode().columns,Xtest_01[mod].iloc[0,:]))
Xtest_01 = Xtest_01.fillna(dic_mod)
# #替换填充
Xtest_01['N6064'] = Xtest_01['N6064'].replace('0','N')
Xtest_01.isnull().sum()[Xtest_01.isnull().sum() !=0]
3.1.4 转码
打开我们记录好的EXCEL文件,找到需要进行转码的数据。
不过我们可以发现确实是有点多,就不适合一个个复制出来啦,我们可以写一个方法,读取EXCEL文件,把变量名和转码的两列字段复制到另一个sheet里,方便读取。
encod_col = pd.read_excel('保险案例数据字典_清洗.xlsx',sheet_name=2)
encod_col.head()

# 查看Xtrain_01中object类型
object_tr =Xtrain_01.describe(include='O').columns
object_tr
输出结果为:
Index(['GEND', 'ADBT', 'ADEP', 'AHBP', 'ARES', 'AHRT', 'ADGS', 'AHRL', 'ASKN',
'AVIS', 'BANK', 'FINI', 'INLI', 'INMEDI', 'IOLP', 'MOBPLUS', 'N2NCY',
'N1819', 'N2029', 'N3039', 'N4049', 'N5059', 'N6064', 'N65P', 'ONLA',
'SGFA', 'SGLL', 'SGOE', 'SGSE', 'SGTC', 'POC19', 'HOMSTAT', 'HINSUB',
'STATE_NAME'],
dtype='object')
#检查一下转码的目标是否出现
np.setdiff1d(object_tr,encod_col['变量名'])
array([], dtype=object)
3.1.4.1 0-1转码
# 获取0-1 转码的变量名
z_0_list = encod_col[encod_col['转']=='0-1'].变量名
z_0_list.head()
输出结果为:
0 GEND
3 N1819
4 N2029
5 N3039
6 N4049
Name: 变量名, dtype: object
# 重新定义一个Xtrain_02,用于转码
Xtrain_02 = Xtrain_01[z_0_list]
Xtrain_02.head()

#sklearn的预处理模块
from sklearn.preprocessing import OrdinalEncoder
#fit_transform 直接转
new_arr = OrdinalEncoder().fit_transform(Xtrain_02)
new_arr

下面我们来做下合并。
# columns 设置表头为原来的 index 索引也是原来
Xtrain_02 = pd.DataFrame(data=new_arr,columns=Xtrain_02.columns,index=Xtrain_02.index)
Xtrain_02.head()
将转好的Xtrain_02 0-1编码变量 替换掉Xtrain_01:
Xtrain_01[z_0_list] = Xtrain_02
Xtrain_01.head()
3.1.4.2 哑变量转码
注意:哑变量转码有两种方法,一种是pandas中的get_dummies方法,另一种是sklearn中的onehot方法。区别主要在于pandas中的方法只能处理字符变量不能处理数值变量,而sklearn都可以,所以如果用get_dummies处理数值型数据的话得先将数值型数据转换成字符型数据。
下面我们用get_dummies来实现转码。
#获取哑变量---转码的变量名
o_h_list = encod_col[encod_col['转']=='哑变量'].变量名
o_h_list
输出结果为:
1 c210mys
2 POC19
24 MOBPLUS
25 N2NCY
32 LIVEWELL
33 HOMSTAT
34 HINSUB
35 STATE_NAME
Name: 变量名, dtype: object
Xtrain_01[o_h_list].head()

o_h_01 = ['c210mys','LIVEWELL'] #非字符型的变量
o_h_02 = [i for i in o_h_list if i not in o_h_01] #字符类型的变量
#先转o_h_02
Xtrain_02 = Xtrain_01.copy()
chinese(Xtrain_02[o_h_02]).head()

Xtrain_02 = pd.get_dummies(chinese(Xtrain_02[o_h_02]))
Xtrain_02.head()
#w我们再转 o_h_01
Xtrain_03 = Xtrain_01.copy()
#转成字符类型
Xtrain_03 = Xtrain_03[o_h_01].astype(str)
#转化覆盖
Xtrain_03 = pd.get_dummies(chinese(Xtrain_03[o_h_01]))
Xtrain_03.head()

Xtrain_02 Xtrain_03 是转好的 先删除原转码的字段再将转好的插入到数据集中。
# Xtrain_04 删除原转码的字段
Xtrain_04 = Xtrain_01.copy()
Xtrain_04 = chinese(Xtrain_04.drop(columns=o_h_01+o_h_02))
Xtrain_04.head()
Xtrain_04.shape
(30566, 51)
Xtrain_02.shape #字符的哑变量
(30566, 31)
Xtrain_03.shape #非字符的哑变量
(30566, 14)
#将 Xtrain_04 Xtrain_02 Xtrain_03 合并
Xtrain_05 = pd.concat([Xtrain_04,Xtrain_02,Xtrain_03],axis=1)
Xtrain_05.shape
(30566, 96)
Xtrain_05.head()
3.1.4.3 对测试集进行转码(总结)
0-1 转码总结:
#获取需要转码的字段
encod_col = pd.read_excel('保险案例数据字典_清洗.xlsx',sheet_name=2)
# 查看Xtest_01中object类型
object_tr =Xtest_01.describe(include='O').columns
#检查一下转码的目标是否出现
np.setdiff1d(object_tr,encod_col['变量名'])
#0-1 转码
# 获取0-1 转码的变量名
z_0_list = encod_col[encod_col['转']=='0-1'].变量名
Xtest_02 = Xtest_01[z_0_list]
#sklearn的预处理模块
from sklearn.preprocessing import OrdinalEncoder
#fit_transform 直接转
new_arr = OrdinalEncoder().fit_transform(Xtest_02)
# columns 设置表头为原来的 index 索引也是原来
Xtest_02 = pd.DataFrame(data=new_arr,columns=Xtest_02.columns,index=Xtest_02.index)
Xtest_01[z_0_list] = Xtest_02
Xtest_01.head()
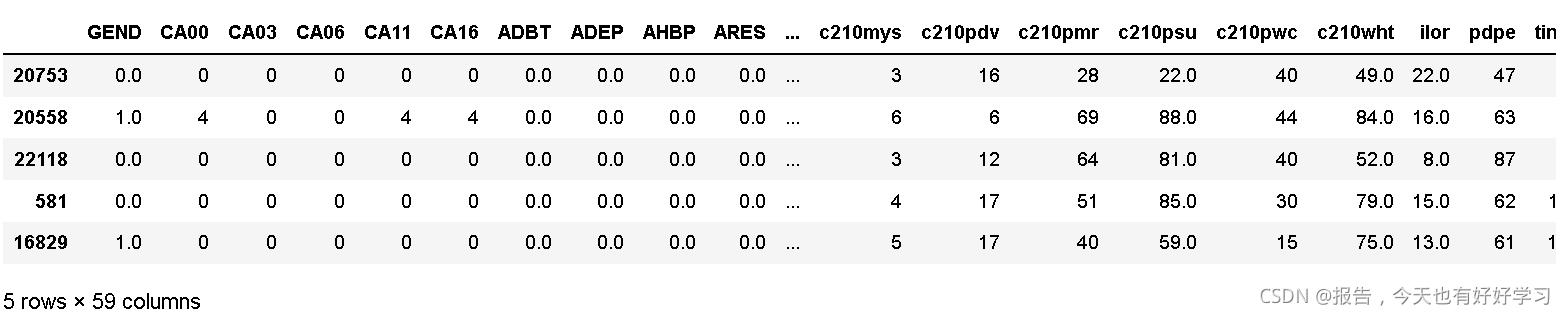
哑变量 总结
#获取哑变量转码的变量
o_h_list = encod_col[encod_col['转']=='哑变量'].变量名
o_h_01 = ['c210mys','LIVEWELL'] #非字符型的变量
o_h_02 = [i for i in o_h_list if i not in o_h_01] #字符类型的变量
#先转o_h_02 字符类型
Xtest_02 = Xtest_01.copy()
Xtest_02 = pd.get_dummies(chinese(Xtest_02[o_h_02]))
#w我们再转 o_h_01 非字符
Xtest_03 = Xtest_01.copy()
#转成字符类型
Xtest_03 = Xtest_03[o_h_01].astype(str)
#转化覆盖
Xtest_03 = pd.get_dummies(chinese(Xtest_03[o_h_01]))
# Xtrain_04 删除原转码的字段
Xtest_04 = Xtest_01.copy()
Xtest_04 = chinese(Xtest_04.drop(columns=o_h_01+o_h_02))
#将 Xtest_04 Xtest_02 Xtest_03 合并
Xtest_05 = pd.concat([Xtest_04,Xtest_02,Xtest_03],axis=1)
Xtest_05.shape
(13100, 96)
Xtest_05.head()
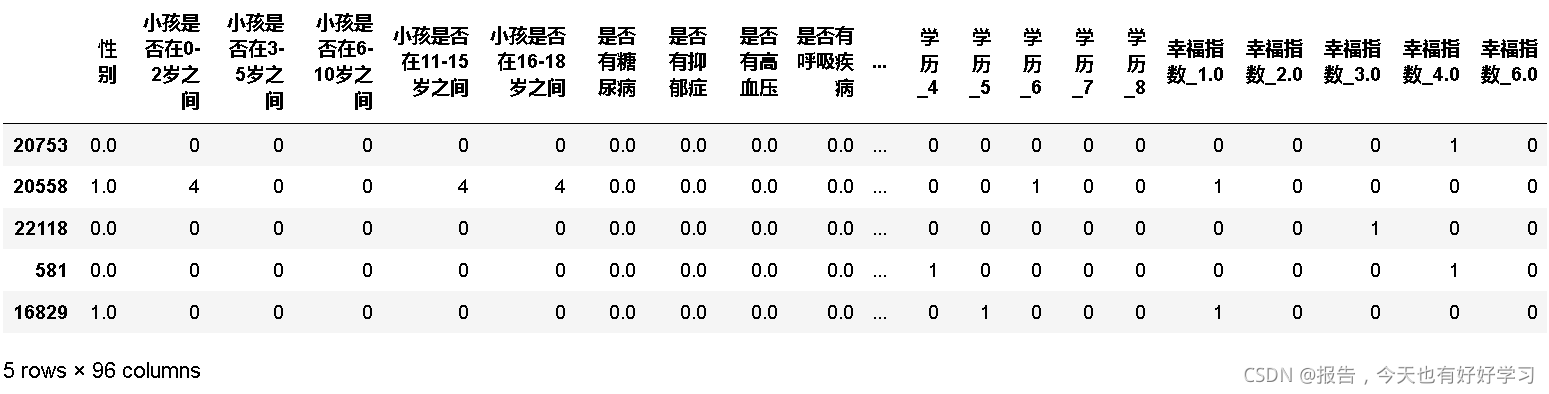
3.1.5 数据建模与评估
3.1.5.1 初步建模
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
clf = DecisionTreeClassifier(random_state=420,class_weight='balanced')
cvs =
cross_val_score(clf,Xtrain_05,Ytrain)
cvs.mean()
0.5993914576104883
3.1.5.2 网格搜索找最优参数
from sklearn.model_selection import GridSearchCV
#测试参数
param_test = {
'splitter':('best','random'),
'criterion':('gini','entropy'), #基尼 信息熵
'max_depth':range(3,15) #最大深度
#,min_samples_leaf:(1,50,5)
}
gsearch= GridSearchCV(estimator=clf, #对应模型
param_grid=param_test,#要找最优的参数
scoring='roc_auc',#准确度评估标准
n_jobs=-1,# 并行数 个数 -1:跟CPU核数一致
cv = 5,#交叉验证 5折
iid=False,# 默认是True 与各个样本的分布一致
verbose=2#输出训练过程
)
gsearch.fit(Xtrain_05,Ytrain_01)
输出结果如下:
GridSearchCV(cv=5,
estimator=DecisionTreeClassifier(class_weight='balanced',
random_state=420),
iid=False, n_jobs=-1,
param_grid={'criterion': ('gini', 'entropy'),
'max_depth': range(3, 15),
'splitter': ('best', 'random')},
scoring='roc_auc', verbose=2)
#优化期间观察到的最高评分
gsearch.best_score_
0.691856415170639
gsearch.best_params_
{‘criterion’: ‘entropy’, ‘max_depth’: 6, ‘splitter’: ‘best’}
3.1.5.3 模型评估
from sklearn.metrics import accuracy_score #准确率
from sklearn.metrics import precision_score #精准率
from sklearn.metrics import recall_score #召回率
from sklearn.metrics import roc_curve
y_pre = gsearch.predict(Xtest_05)
accuracy_score(y_pre,Ytest)
0.6090076335877863
precision_score(y_pre,Ytest)
0.748152359295054
recall_score(y_pre,Ytest)
0.5100116264048572
接下来我们来画图看一下ROC曲线:
fpr,tpr,thresholds = roc_curve(y_pre,Ytest) #roc参数
import matplotlib.pyplot as plt
plt.plot(fpr,tpr,c='b',label='roc曲线')
plt.plot(fpr,fpr,c='r',ls='--')
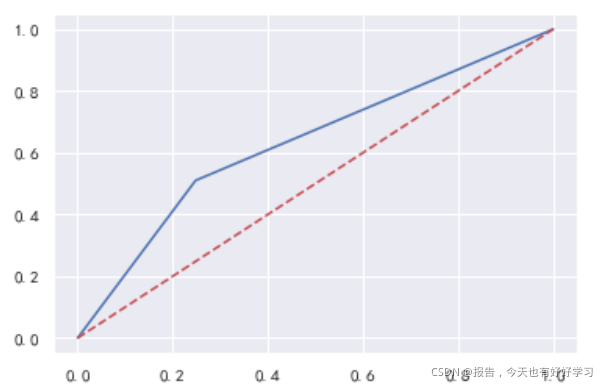
所以综上来看,我们的模型效果算是不好不坏吧。
3.1.5.4 输出规则
#最优参数
#{'criterion': 'entropy', 'max_depth': 6, 'splitter': 'best'}
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import graphviz
#将最优参数放到分类器
clf = DecisionTreeClassifier(criterion='entropy',max_depth=6,splitter='best')
clf = clf.fit(Xtrain_05,Ytrain)
features = Xtrain_05.columns
dot_data = tree.export_graphviz(clf,
feature_names=features,
class_names=['Not Buy','Buy'],
filled=True,
rounded=True,
leaves_parallel=False)
graph= graphviz.Source(dot_data)
graph
我们来看下图:

3.1.6 输出结果的商业应用
我们来看一下购买比例最高的两类客户的特征是什么?
结合上图,我们只要看蓝色的部分,可以得到以下结果。
3.1.6.1 第一类
- 处于医疗险覆盖率比例较低区域
- 居住年限小于7年
- 65-72岁群体
那么我们对业务人员进行建议的时候就是,建议他们在医疗险覆盖率比例较低的区域进行宣传推广,然后重点关注那些刚到该区域且年龄65岁以上的老人,向这些人群进行保险营销,成功率应该会更高。
3.1.6.2 第二类
- 处于医疗险覆盖率比例较低区域
- 居住年限大于7年(小于)年
- 居住房屋价值较高
这一类人群,是区域内常住的高端小区的用户。这些人群也同样是我们需要重点进行保险营销的对象。
除此之外,我们还可以做些什么?
3.1.6.3 了解客户需求
我们需要了解客户的需求,并根据客户的需求举行保险营销。PIOS数据∶向客户推荐产品,并利用个人的数据(个人特征)向客户推荐保险产品。旅行者∶根据他们自己的数据(家庭数据),生活阶段信息推荐的是财务保险、人寿保险、保险、旧保险和用户教育保险。外部数据、资产保险和人寿保险都提供给高层人士,利用外部数据,我们可以改进保险产品的管理,增加投资的收益。
3.1.6.4 开发新的产品
保险公司还应协助外部渠道开发适合不同商业环境的保险产品,例如新的保险类型,如飞行延误保险、旅行时间保险和电话盗窃保险。目的是提供其他保险产品,而不是从这些保险中受益,而是寻找潜在的客户。此外,保险公司将通过数据分析与客户联系,了解客户。外部因素将降低保险的营销成本,并直接提高投资回报率。
结束语
本次项目真的非常非常的详细,从这次项目我们也不难发现,数据探索和可视化这一部分是最花时间的,而这一部分也就是为了数据清洗来服务的(当然最终也可以结合可视化得到的结论),后续建模部分反而花的工夫不是很多。因为数据质量的好坏其实是决定最终效果的最大因素,如果我们不先了解清楚数据并进行清洗转换,后续工作也变得没有什么意义。
总之,过程虽然繁琐,但也饱含着乐趣,能从繁琐的数据中得到更多有用的结论,也显得那么的有意义。
CSDN@报告,今天也有好好学习