
目录
Scrapy概述:
安装Scrapy:
创建一个Scrapy爬虫项目:
1.使用scrapy创建一个工程:
2.创建爬虫文件:
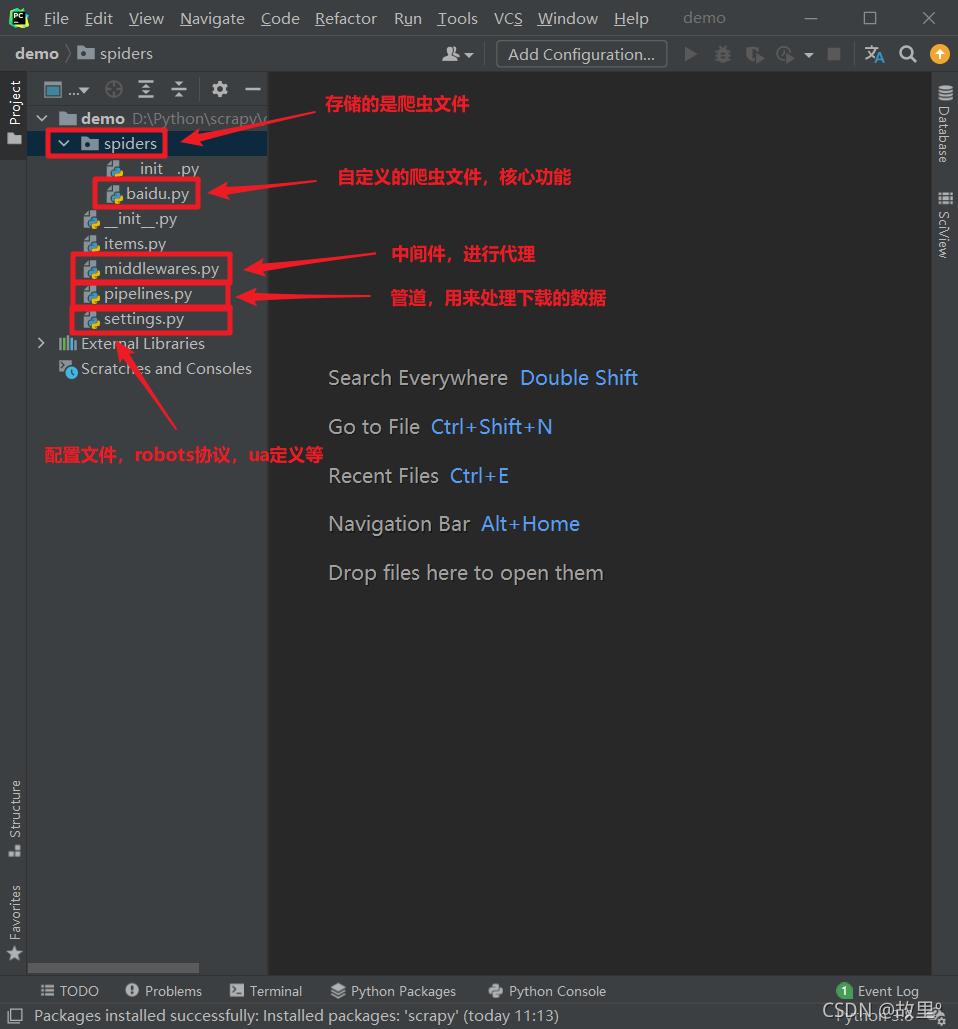
Scrapy项目结构:
response的属性和方法:
Scrapy架构组成:
Scrapy Shell:
安装:
应用:
Scrapy概述:
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
安装Scrapy:
pip install scrapy pip install -I cryptography创建一个Scrapy爬虫项目:
1.使用scrapy创建一个工程:
scrapy startproject scrapy项目名称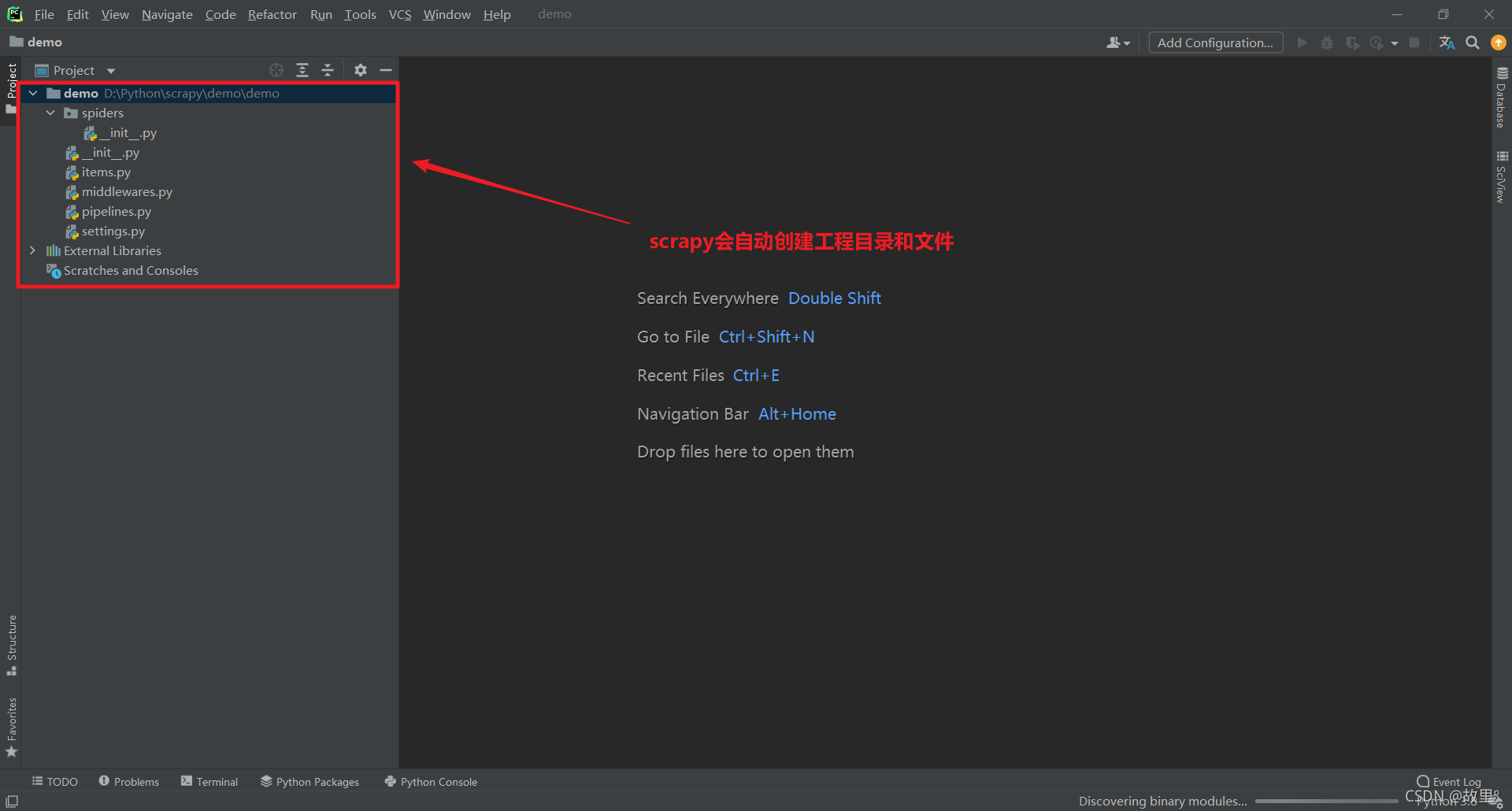
注意:项目的名称不允许使用数字开头,也不能包含中文!
2.创建爬虫文件:
注意:要在spiders文件夹中去创建爬虫文件!
cd 项目名称\项目名称\spiders修改君子协定:
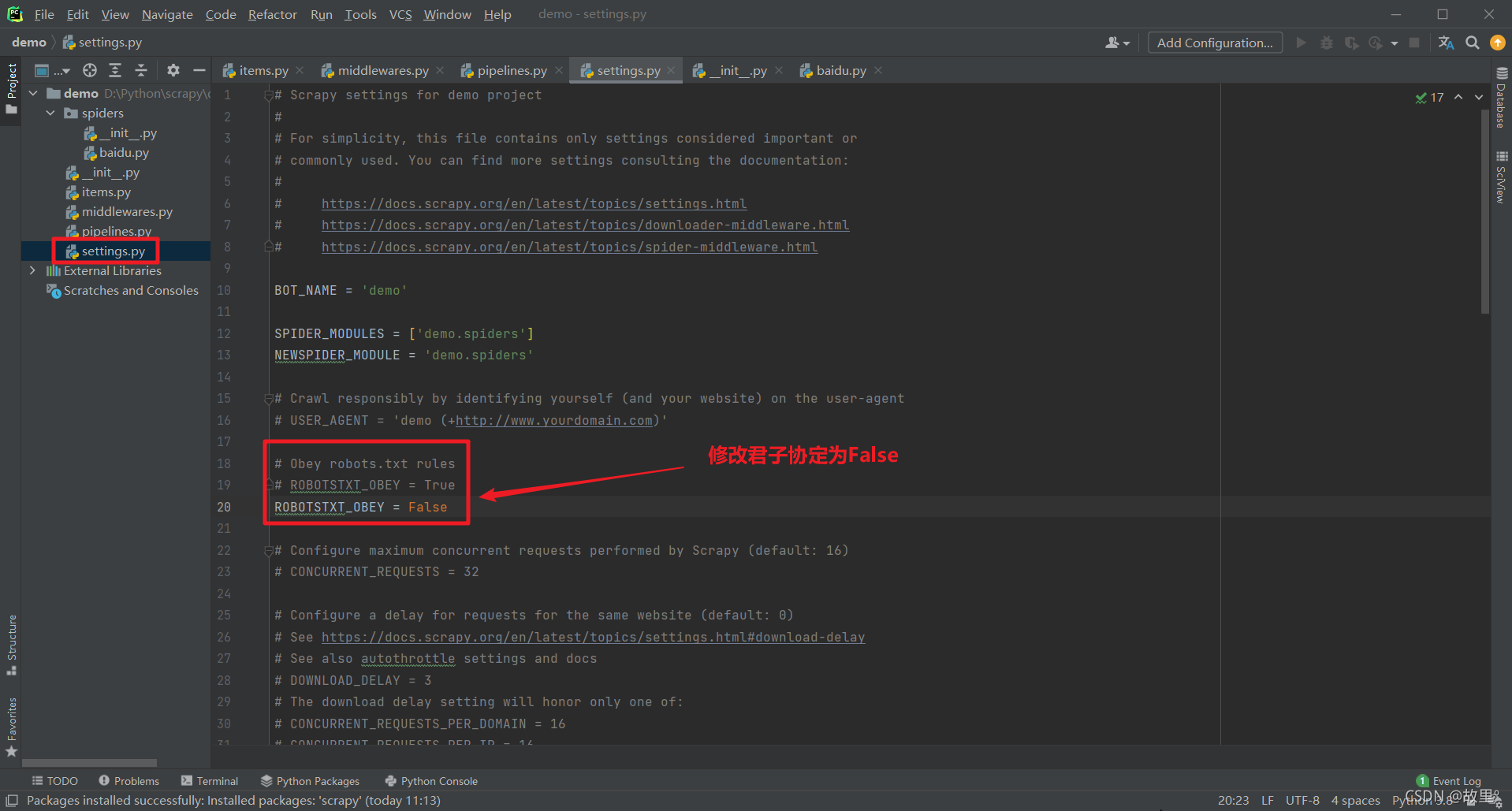
创建爬虫文件:
scrapy genspider 爬虫文件的名字 要爬取的网页import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候 url使用指:
name = 'baidu'
# 允许访问的域名:
allowed_domains = ['https://www.baidu.com']
# 起始的url地址 指的是第一次要访问的域名
# start_urls是在allowed_domains的前面添加一个http://,在allowed_domains后面添加一个/
start_urls = ['https://www.baidu.com/']
# 是执行了start_urls之后,执行的方法,方法中的response 就是返回的那个对象
# 相当于 response = urllib.request.urlopen()
# response = request.get()
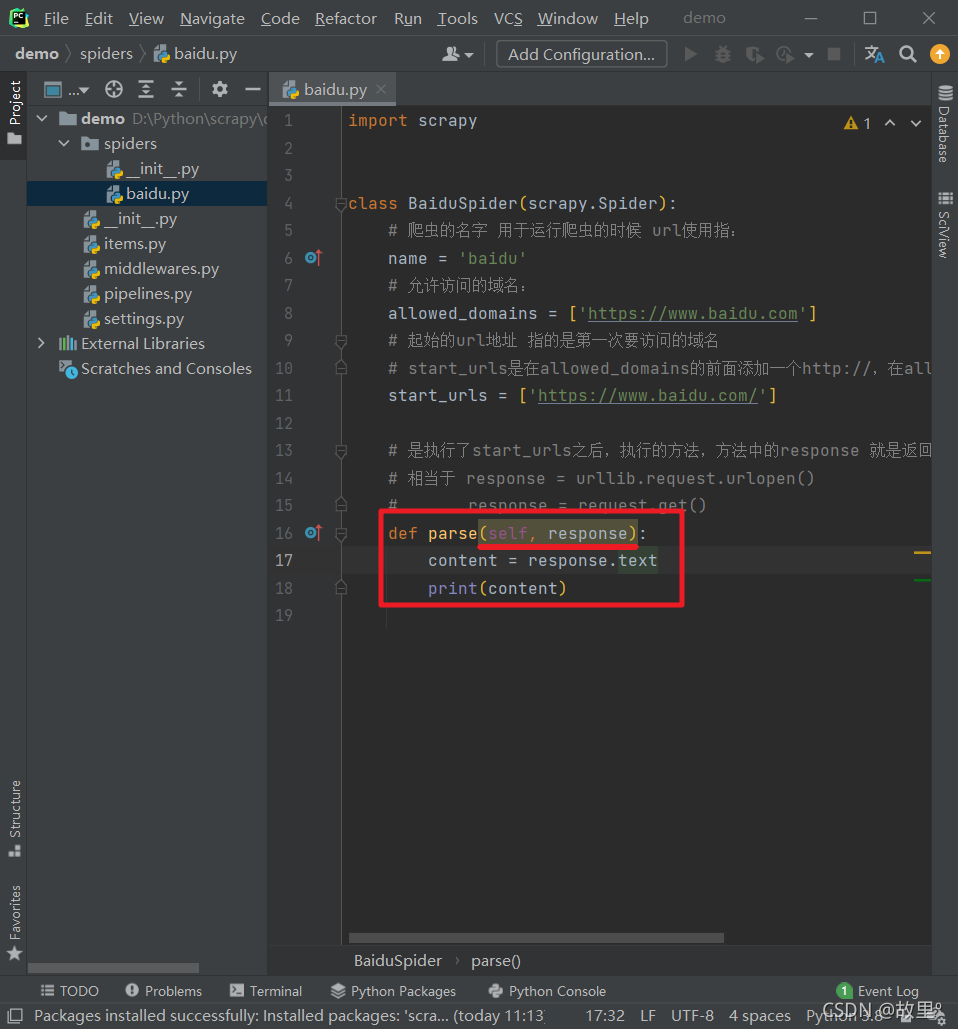
def parse(self, response):
print('------------------\n'
'------------------\n'
'------Hello-------\n'
'------World-------\n'
'------------------\n'
'------------------\n')
pass
执行爬虫文件:
scrapy crawl 爬虫文件文件名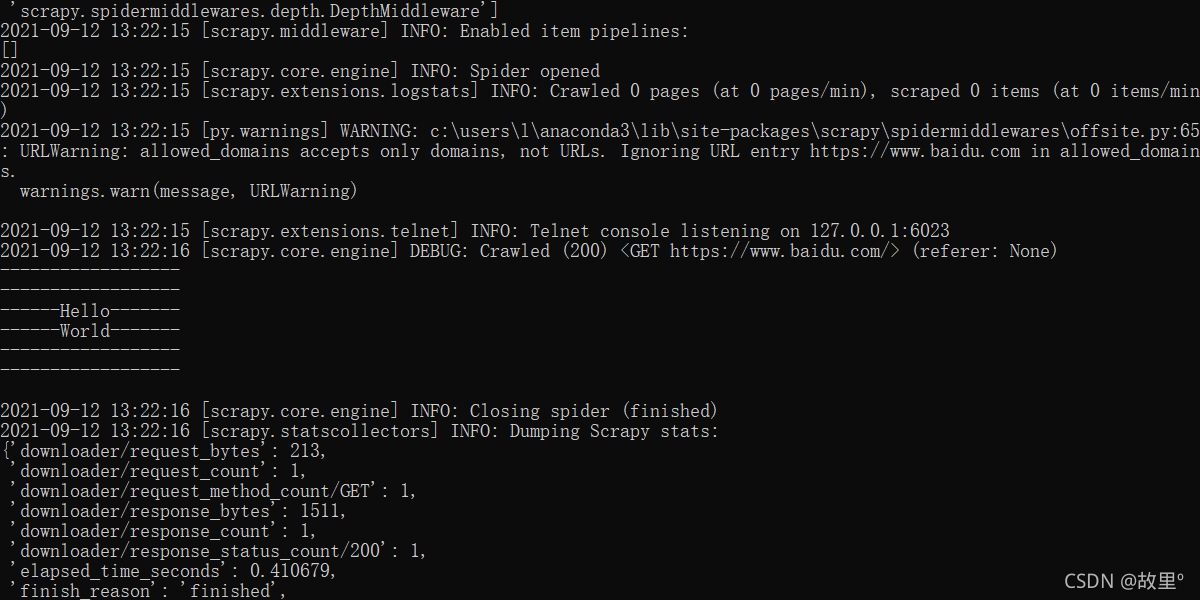
Scrapy项目结构:
response的属性和方法:
| response.text | 获取的是响应的字符串 |
| response.body | 获取的是二进制数据 |
| response.xpath | 可以直接是xpath方法来解析response中的内容 |
| response.extract() | 提取selector对象的data属性值 |
| response.extract_first() | 提取selector列表的第一个数据 |
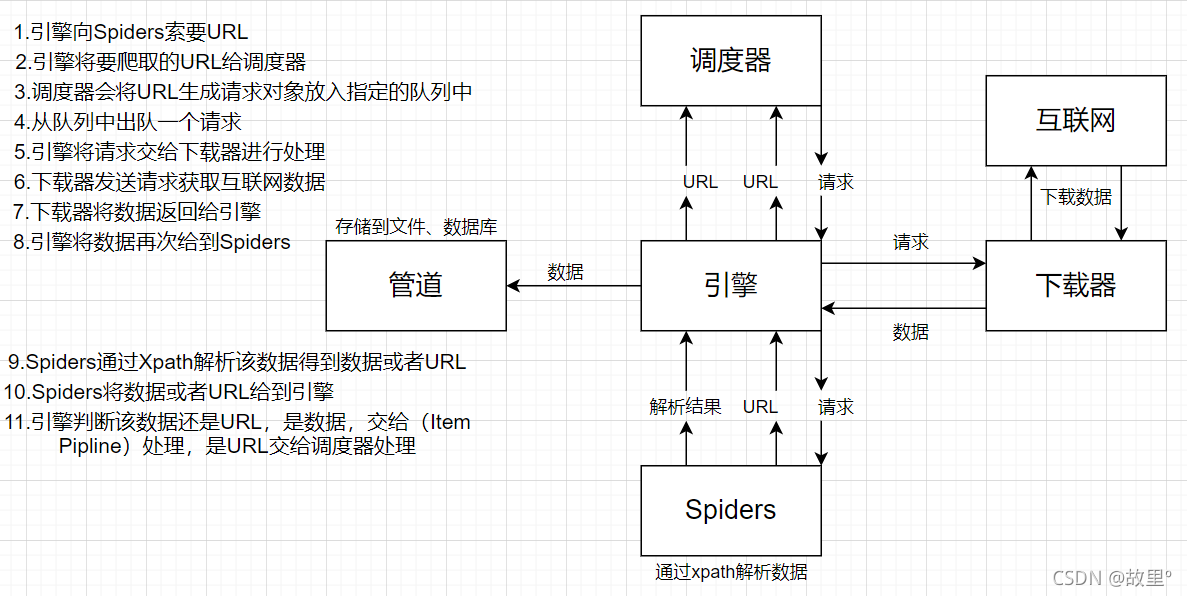
Scrapy架构组成:
- 引擎:自动运行,无需关注,会自动组织所有的请求对象,分发给下载器。
- 下载器:从引擎处获取请求对象后,请求数据。
- Spiders:Spider类定义了如何爬取某个(某些)网站,包括爬取的动作(例如:是否跟进连接)以及如何从网页的内容中提取结构化数据(爬取item)。Sprider就是定义爬取的动作及分析某个网页(或者有些网页)的地方。
- 调度器:有自己的调度规则,无需关注。
- 管道(Item pipeIine):最终处理数据的管道,会预留接口进行数据处理。当Item正在Spider中被收集之后,它将会被传递到Item Pipline,一些组件会按照一定的顺序执行对Item的处理。每个Item PipLine组件是实现了简单方法的Python类,他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipiline或者是丢弃不再进行处理。
以下是item pipline的一些典型应用:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取的结果保存到数据库中
Scrapy Shell:
Scrapy终端,是一个交互终端,可以在未启动Spider的情况下尝试及调试爬虫代码。其本意是用来测试和提取数据的代码,不过可以被作为正常的Python终端,在上面测试任何的Python代码。
该终端用来测试XPath或CSS表达式,查看他们的工作方式及从网页中提取数据。在编写您的Spider时,该终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行Spider的麻烦。
一旦熟悉Scrapy终端后,就能发现其在开发和调试Spider时发挥的巨大作用。
安装:
pip install ipython
如果安装了IPython,Scrapy终端将会使用IPython(代替标准Python终端),IPython终端与其他相比较更为强大,提供智能化的自动补全,高亮输出,及其他特性。
应用:
直接在CMD中启动后,会自动打开IPython终端:
scrapy shell URL地址(爬取指定目标地址)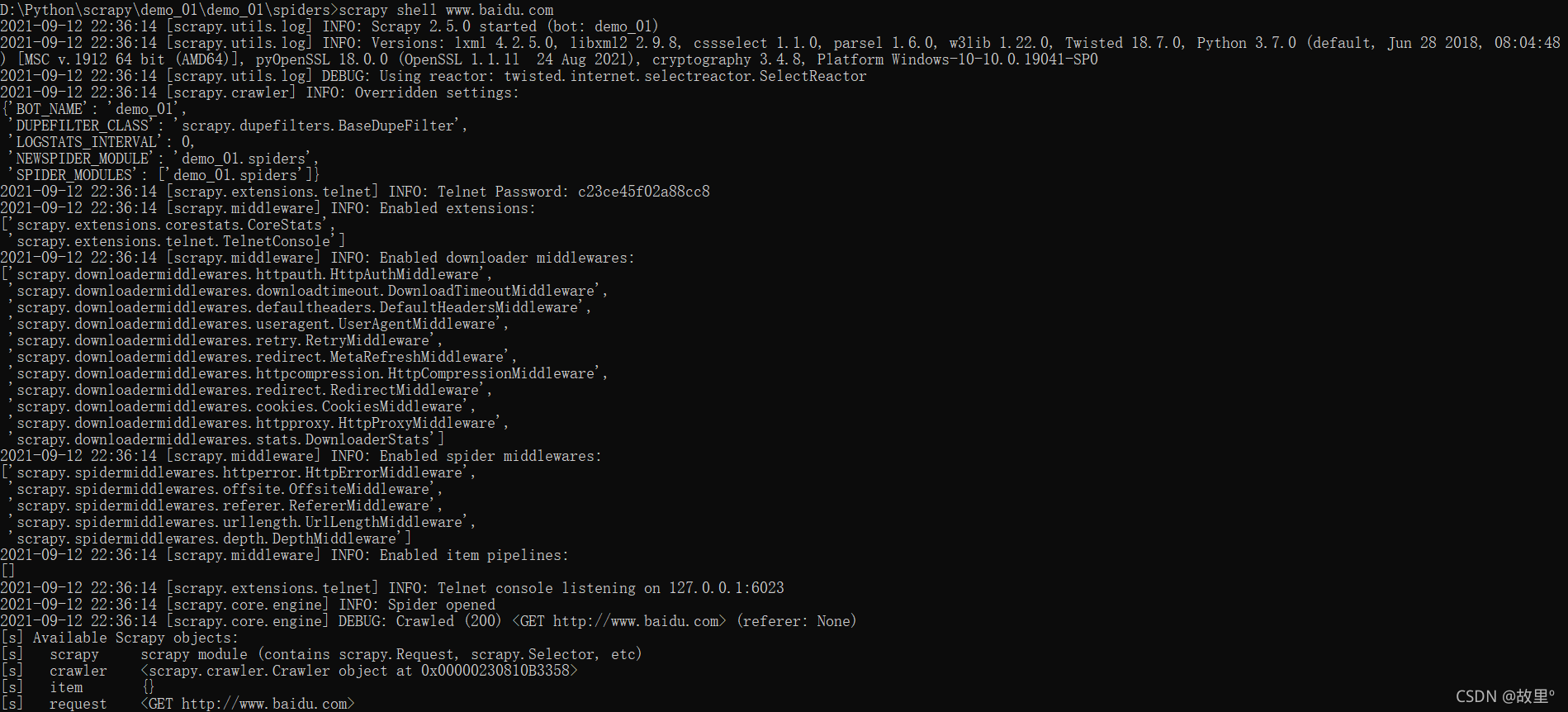

启动IPthon终端:

| scrapy shell www.daidu.com |
| scrapy shell https://www.baidu.com |
| scrapy shell "https://www.baidu.com" |
| scrapy shell "www.baidu.com" |