倘若有一天你去面试的时候,面试官问起了你HashMap的底层实现原理,你怎么办?是一脸懵逼支支吾吾吗?再让你自己通过代码实现你自己的HashMap的时候,难道完全破防?读完这篇文章,让我们对这个情况say no!

首先我们来通过下面的图看看JDK1.7时代的HashMap是如何通过数组+链表的形式进行值储存的。

由图中的描述可以清楚地看出来,当数组第一次被定义并且第一次被赋值的时候,这个时候的操作很简单,就是将这个值赋值到我们的table数组上面去。这个操作完成以后,然后我们进行二次put:
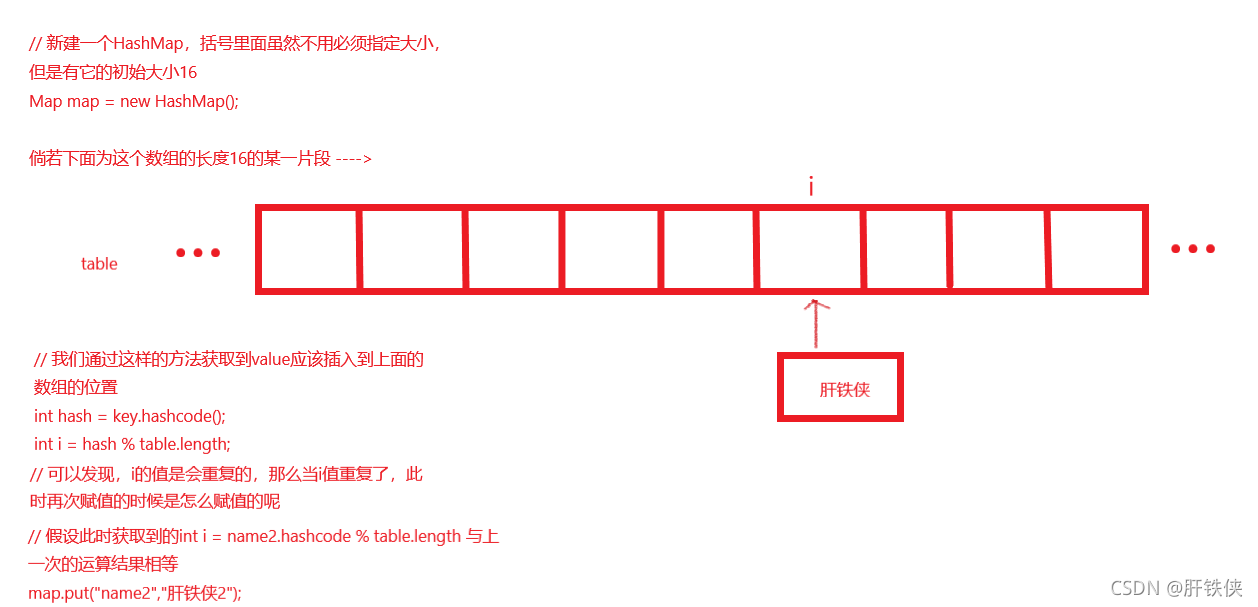
如图左下角描述所示的情况,当数组table下标出现了相等的情况的时候,此时此刻还是将肝铁侠2的值赋值给tablle[i]的,这里讲述的是JDK1.7版本下HashMap中插入的头插法,而JDK1.8版本中是用的尾插法。插入以后,我们要让数组指向链表的头部,那么链表的头部也就是头节点是不是就是table[i]的位置呀。

如上,最终插入完成以后的模型就是这样的:

那我们此时此刻是不是就可以大胆地猜测,在HashMap中,使用map.get(“name”)获取到它的value的时候,是不是就是通过int hash = “name”.hashcode,然后获取到对应table下的数组下标int i = hash % table.length获取到table[i]的具体位置的链表,然后再通过hash去对应table[i]上的链表中找到对应的值呢?
有了这个思维,我们再去看HashMap的源码就会轻松许多许多。下一期为大家带来HashMap的手动实现。
再顺带两个基本的关于HashMap的问题:
HashMap底层是怎么实现的呢?
在JDK1.7中是通过数组+链表实现的。JDK1.8中是通过数组+链表+树(红黑树)组成的。
为什么要用链表呢?
①HashMap数组元素为链表的时候,插入直接使用头插,插入复杂度O(1),即操作的数量为常数,与输入的数据的规模无关,效率是非常快的;当链表较短时候,查找数据时对性能并没有什么影响,但是如果链表一长,查找起来就很影响性能了。
②在Java8中,如果链表长度到达了8个,就会转化为红黑树,提高了查找的性能,但每次插入新的数据,都得维护红黑树的结构,复杂度为O(log n)。其实算是对查找和插入元素时性能的一个权衡,毕竟存入的效果就是用来查询的。
这个问题的答案不唯一,可以自行了解一下。