Redis(一) 核心数据结构 String hash list set zset 五种数据类型客户端的简单使用 各自的特点 使用场景_T_Antry
犹豫了好久,要不要跳过这些使用直接着重集群搭建的学习,因为我的工作还用不到,想着这些比较细的东西等我用到都忘光了吧。我想很多朋友在学习的时候也有这个困扰,最终我的想法是,其实也花不了多少时间,少打两把LOL是吧,不就搞定了。不为懒惰找理由好了,留个印象,再用之时得心应手。
文章目录
- 前言
- 一、Redis是什么?
- 二、安装
- 安装gcc
- 下载
- 解压
- 修改配置
- 需要注释掉bind
- 启动服务
- 验证启动是否成功
- 进入redis客户端
- 退出客户端
- 退出redis服务:
- 三、使用
- 查询最大连接数
- keys
- scan
- Info
- 字符串常规操作
- 原子加减
- Hash常用操作
- hash 结构的优缺点
- List
- Set常用操作
- Zset有序集合
前言
我对redis的初印象,存session信息。要说这么说错吧,好像能这么用,要说没错吧,难道就只能这么用?想当初面试官听我这么一回答,一脸懵逼。所以这回好好的找一些资料学习下,使用下。
一、Redis是什么?
按照国际惯例,先去官网看看,翻译一下,然后揪出几个关键字,浅浅地理解一下。下面就是软件翻译的结果。
Redis 是一个开源(BSD 许可)、内存数据结构存储库,用作数据库、缓存和消息中间商。Redis 提供数据结构,如字符串、哈希、列表、集、分拣集、范围查询、位图、超日志、地理空间索引和流。Redis 具有内置复制、Lua 脚本、LRU 驱逐、交易和不同级别的盘上持久性,并通过Redis 哨兵和与Redis 集群的自动分区提供高可用性。
您可以在这些类型上运行原子操作,如附加到字符串:在哈希中增加值:将元素推至列表;计算集交叉点、结合和差异:或让成员在排序集的最高排名。
为了实现最高性能,Redis 与内存数据集配合工作。根据您的使用案例,您可以通过定期将数据集倾倒到磁盘或将每个命令附加到基于磁盘的日志中来持续数据。如果您只需要一个功能丰富、网络化、内存存储的缓存,您也可以禁用持久性。
Redis 还支持异步复制,具有非常快的非阻塞式第一次同步、自动重新连接和网络拆分上的部分重新同步。
灰色部分咱暂且忽略,那么它就是可以用来做数据库和缓存使用,类型有那么些种,本次主要先介绍一下集中类型的使用。
redis的五种数据类型
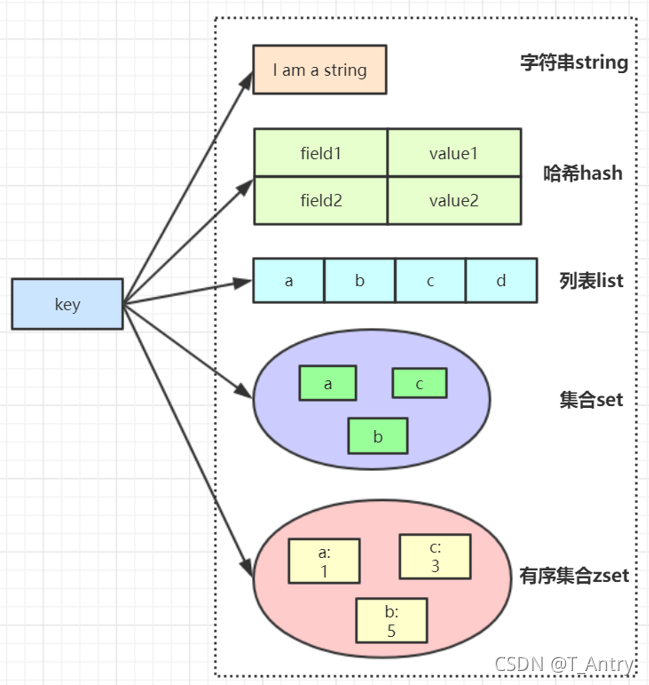
带过几个问题
Redis 的单线程主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外
提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,
是由额外的线程执行的。
为什么快?因为它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能损耗问题。正因为 Redis 是单线程,所以要小心使用 Redis 指令,对于那些耗时的指令(比如
keys),一定要谨慎使用,一不小心就可能会导致 Redis 卡顿。
Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到
文件事件分派器,事件分派器将事件分发给事件处理器
二、安装
安装gcc
yum install gcc
下载
下载地址:http://redis.io/download
或
wget http://download.redis.io/releases/redis‐5.0.3.tar.gz
解压
把下载好的redis‐5.0.3.tar.gz放在/usr/local文件夹下,并解压
tar xzf redis‐5.0.3.tar.gz
cd redis‐5.0.3
进入到解压好的redis‐5.0.3目录下,进行编译与安装
make
修改配置
daemonize yes #后台启动
protected‐mode no #关闭保护模式,开启的话,只有本机才可以访问redis
需要注释掉bind
##bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户
端通过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
启动服务
src/redis‐server redis.conf
验证启动是否成功
ps ‐ef | grep redis
进入redis客户端
src/redis‐cli
退出客户端
quit
退出redis服务:
(1)pkill redis‐server
(2)kill 进程号
(3)src/redis‐cli shutdown
三、使用
查询最大连接数
查看redis支持的最大连接数,在redis.conf文件中可修改,# maxclients 10000
127.0.0.1:6379> CONFIG GET maxclients
1) "maxclients"
2) "10000"
keys
全量遍历键,用来列出所有满足特定 正则字符串规则 的key
当redis数据量比较大时,性能比较差,要避免使用
现在是啥也没有,所以是空,后面有存储之后就有了
127.0.0.1:6379> keys *
(empty list or set)
scan
渐进式遍历键,可以理解为分页查询
SCAN cursor [MATCH pattern] [COUNT count]
scan 参数提供了三个参数
- 第一个是 cursor 整数值(hash桶的索引值)
- 第二个是 key 的正则模式
- 第三个是一次遍历的key的数量
第一次遍历时,cursor 值为 0,然后将返回结果中第一个整数值作为下一次遍历的 cursor。一直遍历到返回的 cursor 值为 0 时结束。
但是scan并非完美无瑕, 如果在scan的过程中如果有键的变化(增加、 删除、 修改) ,那么遍历效果可能会碰到如下问题: 新增的键可能没有遍历到, 遍历出了重复的键等情况, 也就是说scan并不能保证完整的遍历出来所有的键。
Info
查看redis服务运行信息
结果分为九大块:
| title | 信息 |
|---|---|
| Server | 服务器运行的环境参数 |
| Clients | 客户端相关信息 |
| Memory | 服务器运行内存统计数据 |
| Persistence | 持久化信息 |
| Stats | 通用统计数据 |
| Replication | 主从复制相关信息 |
| CPU | CPU 使用情况 |
| Cluster | 集群信息 |
| KeySpace | 键值对统计数量信息 |
字符串常规操作
存入字符串键值对
127.0.0.1:6379> set antry sun
OK
批量存储字符串键值对
存储对象 mset user:1:name antry user:1:age 18 user:1:sex girl
127.0.0.1:6379> mset antry1 1 antry2 2
OK
存入不存在字符串
如果已经存在则不会存入,用于获取锁,获取成功返回1,获取失败返回0
127.0.0.1:6379> setnx antry sun
(integer) 0
127.0.0.1:6379> setnx antry3 3
(integer) 1
获取一个字符串键值
127.0.0.1:6379> get antry
"sun"
批量获取键值
127.0.0.1:6379> mget antry1 antry2
1) "1"
2) "2"
删除键
127.0.0.1:6379> del antry
(integer) 1
设置一个键的过期时间,单位s
过期之后就取不到了
127.0.0.1:6379> expire antry1 1
(integer) 1
原子加减
key中存储的数值+1
可用作记录阅读量
127.0.0.1:6379> set count 0
OK
127.0.0.1:6379> incr count
(integer) 1
127.0.0.1:6379
key中存储的数值-1
127.0.0.1:6379> decr count
(integer) 6
127.0.0.1:6379> decr count
(integer) 5
key中存储的数值+指定数值
(integer) 5
127.0.0.1:6379> incrby count 5
(integer) 10
key中存储的数值-指定数值
(integer) 10
127.0.0.1:6379> decrby count 5
(integer) 5
Hash常用操作
存储一个hash表key的键值
127.0.0.1:6379> hset antry name kangkang
(integer) 1
存储一个不存在的hash表键值
127.0.0.1:6379> hsetnx antry age 18
(integer) 1
在一个哈希表key中存储多个键值对
127.0.0.1:6379> hmset antry name kangkang age 18 like girl sex boy
OK
获取hash表key对应的field键值
127.0.0.1:6379> hget antry like
"girl"
批量获取hash表key中多个field的键值
127.0.0.1:6379> hmget antry name age like sex
1) "kangkang"
2) "18"
3) "girl"
4) "boy"
可用于存储对象
删除hash表key中的field键值
127.0.0.1:6379> hdel antry like
(integer) 1
返回hash表key中的field的数量
127.0.0.1:6379> hlen antry
(integer) 3
返回hash表key中的所有键值
127.0.0.1:6379> hgetall antry
1) "name"
2) "kangkang"
3) "age"
4) "18"
5) "sex"
6) "boy"
为hash表中field键上的值+指定数值
127.0.0.1:6379> hincrby antry age 10
(integer) 28
hash 结构的优缺点
优点
- 同类数据归类整合存储,方便数据管理
- 相比String操作消耗内存和cpu更小
- 相比String存储更节省空间
缺点
- 过期功能不能用在field上,只能用在key上
- redis集群架构下不适合大规模使用
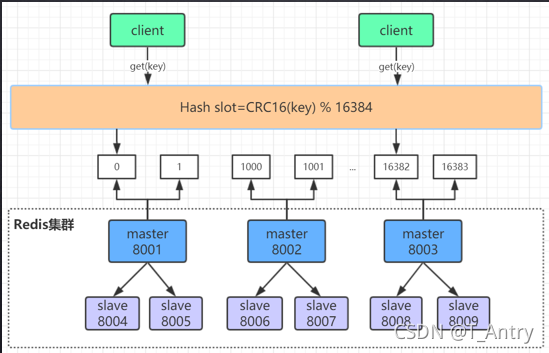
如果是使用的上面分布式集群方式(每个服务平分掉一部分key),在对key 进行hash时,所有数据只会落到某一个服务上。
List
将一个或多个值value插入到key列表的表头(最左边)
127.0.0.1:6379> lpush list 1 1 2 2 3 3 4 4 5 5 6 6
(integer) 12
将一个或多个值value插入到key列表的表尾(最右边)
127.0.0.1:6379> rpush list 1 2 3 4 5 6
(integer) 18
移除并返回key列表头部的元素
127.0.0.1:6379> lpop list
"6"
移除并返回key列表尾部的元素
127.0.0.1:6379> rpop list
"6"
返回列表key中指定区间内的元素,区间以偏移量start和stop指定
127.0.0.1:6379> lrange list 5 10
1) "3"
2) "3"
3) "2"
4) "2"
5) "1"
6) "1"
从key列表表头弹出一个元素,若表中没有元素,阻塞等待timeout秒,如果timeout=0则一直阻塞等待
127.0.0.1:6379> blpop list 0
1) "list"
2) "6"
从key列表表尾弹出一个元素,若表中没有元素,阻塞等待timeout秒,如果timeout=0则一直阻塞等待
127.0.0.1:6379> brpop list 0
1) "list"
2) "5"
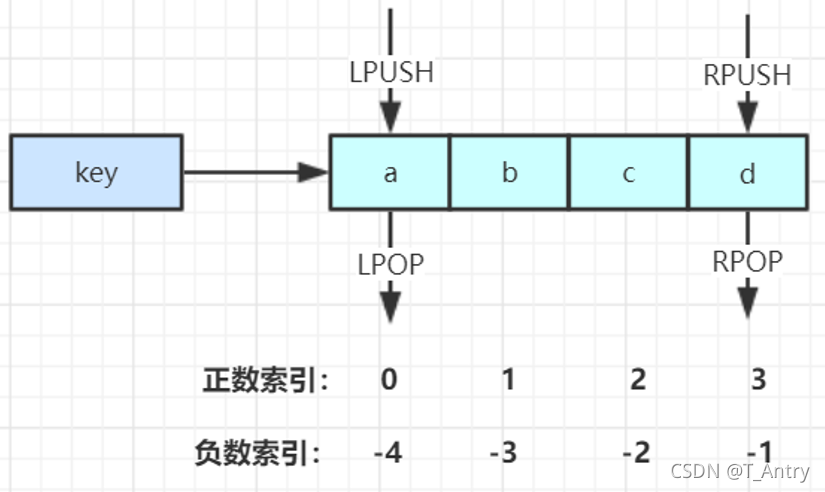
常用数据结构
- Stack(栈)= lpush + lpop
- Queue(队列)= lpush + rpop
- Blocking MQ(阻塞队列)= lpush + brpop
Set常用操作
往集合key中存入元素,元素存在则忽略,若可以不存在则新建
127.0.0.1:6379> sadd set member1 member2 member3 member4 member5 member6
(integer) 6
从集合key中删除元素
127.0.0.1:6379> srem set member1
(integer) 1
获取集合key中所有元素
127.0.0.1:6379> smembers set
1) "member5"
2) "member2"
3) "member3"
4) "member4"
5) "member6"
判断member元素是否存在于集合key中
127.0.0.1:6379> sismember set member3
(integer) 1
从集合key中选出count个元素,元素不从key中删除
127.0.0.1:6379> srandmember set 3
1) "member2"
2) "member3"
3) "member6"
从集合key中选出count个元素,元素从key中删除
127.0.0.1:6379> spop set 2
1) "member3"
2) "member5"
127.0.0.1:6379> spop set 2
1) "member6"
2) "member2"
获取集合key的元素个数
127.0.0.1:6379> scard set
(integer) 1
交集运算
127.0.0.1:6379> sadd set member1 member2 member3 member4 member5 member6
(integer) 5
127.0.0.1:6379> sadd set2 member2 memeber3
(integer) 2
127.0.0.1:6379> sinter set set2
1) "member2"
将交集结果存入新集合destination中
127.0.0.1:6379> sinterstore set3 set set2
(integer) 1
并集计算
127.0.0.1:6379> sunion set set2
1) "member5"
2) "member2"
3) "member1"
4) "member3"
5) "member4"
6) "member6"
7) "memeber3"
将并集结果存入新集合destination中
127.0.0.1:6379> sunionstore set4 set set2
(integer) 7
差集运算
127.0.0.1:6379> sdiff set set2
1) "member5"
2) "member3"
3) "member6"
4) "member1"
5) "member4"
将差集结果存入新集合destination中
127.0.0.1:6379> sdiffstore set5 set set2
(integer) 5
set集合可以对集合进行操作,显然可以用来做关注等关联。
Zset有序集合
往有序集合key中加入带分值元素
127.0.0.1:6379> zadd zset 1 a 2 b 3 c 4 d 5 e 6 f 7 g
(integer) 7
从有序集合key中删除元素
127.0.0.1:6379> zrem zset g
(integer) 1
返回有序集合key中元素member的分值
127.0.0.1:6379> zscore zset f
"6"
为有序集合key中元素member的分值加上increment
127.0.0.1:6379> zincrby zset 5 f
"11"
返回有序集合key中元素个数
127.0.0.1:6379> zcard zset
(integer) 6
正序获取有序集合key从start下标到stop下标的元素
127.0.0.1:6379> zrange zset 2 4
1) "c"
2) "d"
3) "e"
倒叙获取有序集合key从start下标到stop下标的元素
127.0.0.1:6379> zrevrange zset 1 2
1) "e"
2) "d"
并集计算
127.0.0.1:6379> zadd zset2 2 a 3 b 4 c 5 d 6 e 7 f 8 g
(integer) 7
127.0.0.1:6379> zunionstore zset3 2 zset zset2
(integer) 7
交集计算
127.0.0.1:6379> zinterstore zset4 2 zset zset2
(integer) 6
很显然地可以看到,zset多了score,且可以排序,因此就可以用来做排行榜。
登录后可发表评论
点击登录