?博客主页: 【小扳_-CSDN博客】
❤感谢大家点赞?收藏⭐评论✍


文章目录
1.0 索引库操作
1.1 Mapping 映射属性
1.2 索引库的 CRUD
1.2.1 创建索引和映射
1.2.2 查询索引库
1.2.3 修改索引库
1.2.4 删除索引库
2.0 文档操作
2.1 新增文档
2.2 查询文档
2.3 删除文档
2.4 修改文档
2.4.1 全量修改
2.4.2 局部修改
2.5 批处理
3.0 RestAPI
3.1 初始化 RestClient
3.2 创建索引库
3.3 删除索引库
3.4 判断索引库是否存在
4.0 RestClient 操作文档
4.1 新增文档
4.2 查询文档
4.3 删除文档
4.4 修改文档
4.5 批量导入文档
1.0 索引库操作
Index 就类似数据库表,Mapping 映射就类似表的结构。要向 es 中存储数据,必须先创建
Index 和 Mapping 。
1.1 Mapping 映射属性
Mapping 是对索引库中文档的约束,常见的 Mapping 属性包括:
type:字段数据类型,常见的简单类型有:
1)字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
数值:long、integer、short、byte、double、float
布尔:boolean
日期:date
对象:object
2)index:是否创建索引,默认为true
3)analyzer:使用哪种分词器
4)properties:该字段的子字段
1.2 索引库的 CRUD
由于 Elasticsearch 采用的是 Restful 风格的 API,因此其请求方式和路径相对都比较规范,
而且请求参数也都采用 JSON 风格。
直接基于 Kibana 的 DevTools 来编写请求做测试,由于有语法提示,会非常方便。
1.2.1 创建索引和映射
基本语法:
1)请求方式:PUT
2)请求路径:/ 索引库名,可以自定义
3)请求参数:mapping 映射
格式如下:
PUT /索引库名称{ "mappings": { "properties": { "字段名":{ "type": "text", "analyzer": "ik_smart" }, "字段名2":{ "type": "keyword", "index": "false" }, "字段名3":{ "properties": { "子字段": { "type": "keyword" } } }, // ...略 } }}举个例子:
PUT /xbs{ "mappings": { "properties": { "msg":{ "type": "text", "index": true, "analyzer": "ik_smart" }, "age":{ "type": "byte", "index": true }, "name":{ "type": "keyword", "index": true } } }}执行结果:
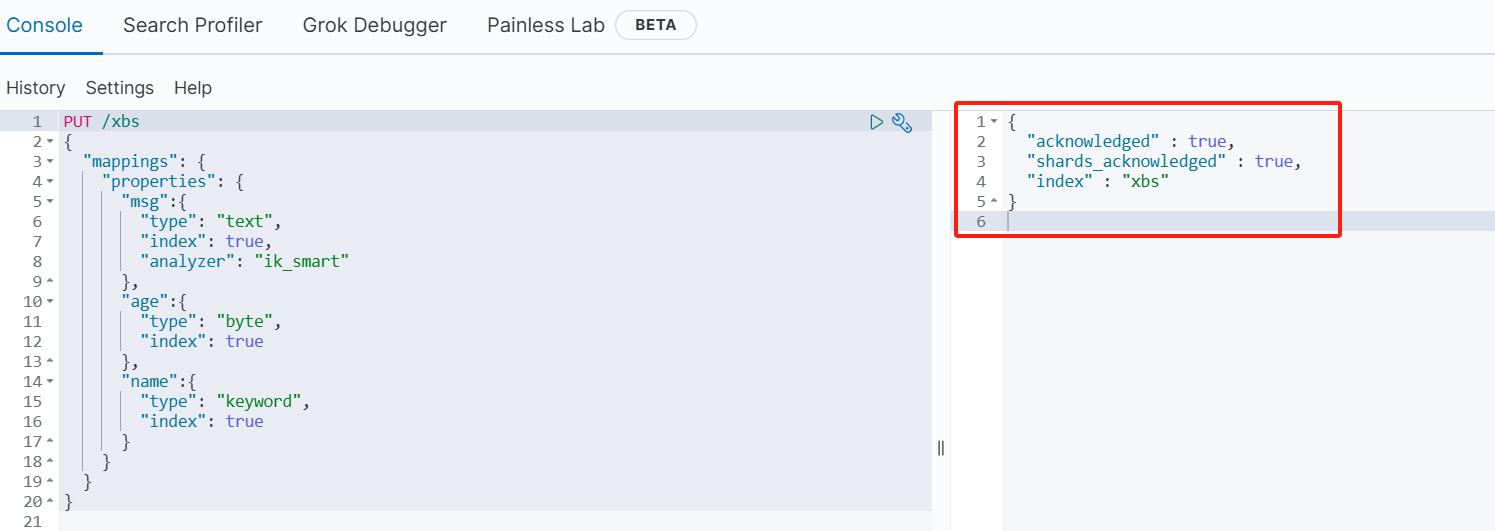
1.2.2 查询索引库
基本语法:
1)请求方式:GET
2)请求路径:/索引库名
3)请求参数:无
格式如下:
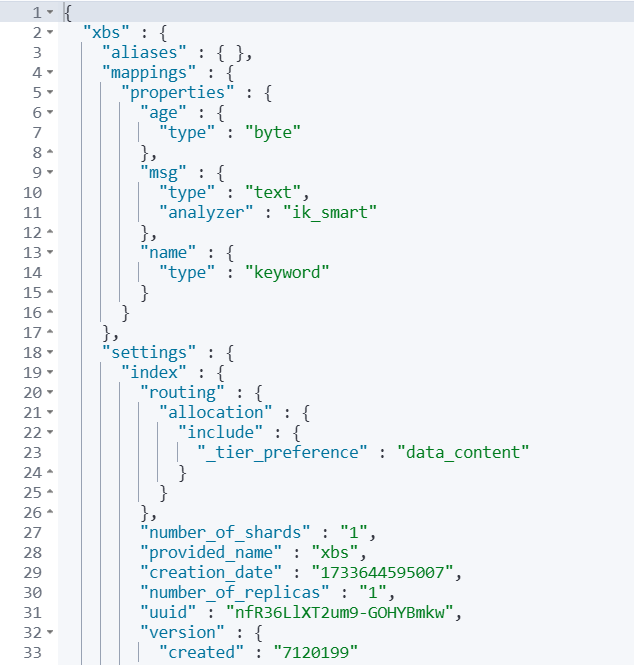
GET /索引库名举个例子:
GET /xbs执行结果:
1.2.3 修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建
倒排索引,这简直是灾难。因此索引库一旦创建,无法修改 mapping。
虽然无法修改 mapping 中已有的字段,但是却允许添加新的字段到 mapping 中,因为不会
对倒排索引产生影响。因此修改索引库能做的就是向索引库中添加新字段,或者更新索引库的基础
属性。
格式如下:
PUT /索引库名/_mapping{ "properties": { "新字段名":{ "type": "integer" } }}举个例子:
PUT /xbs/_mapping{ "properties": { "parent": { "type": "object", "properties": { "father": { "type": "keyword", "index": false }, "mother": { "type": "keyword", "index": false } } } }}执行结果:
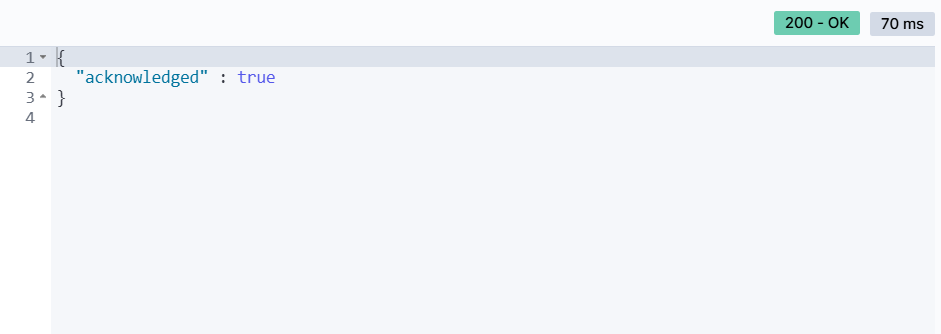
再来查询整体结构:
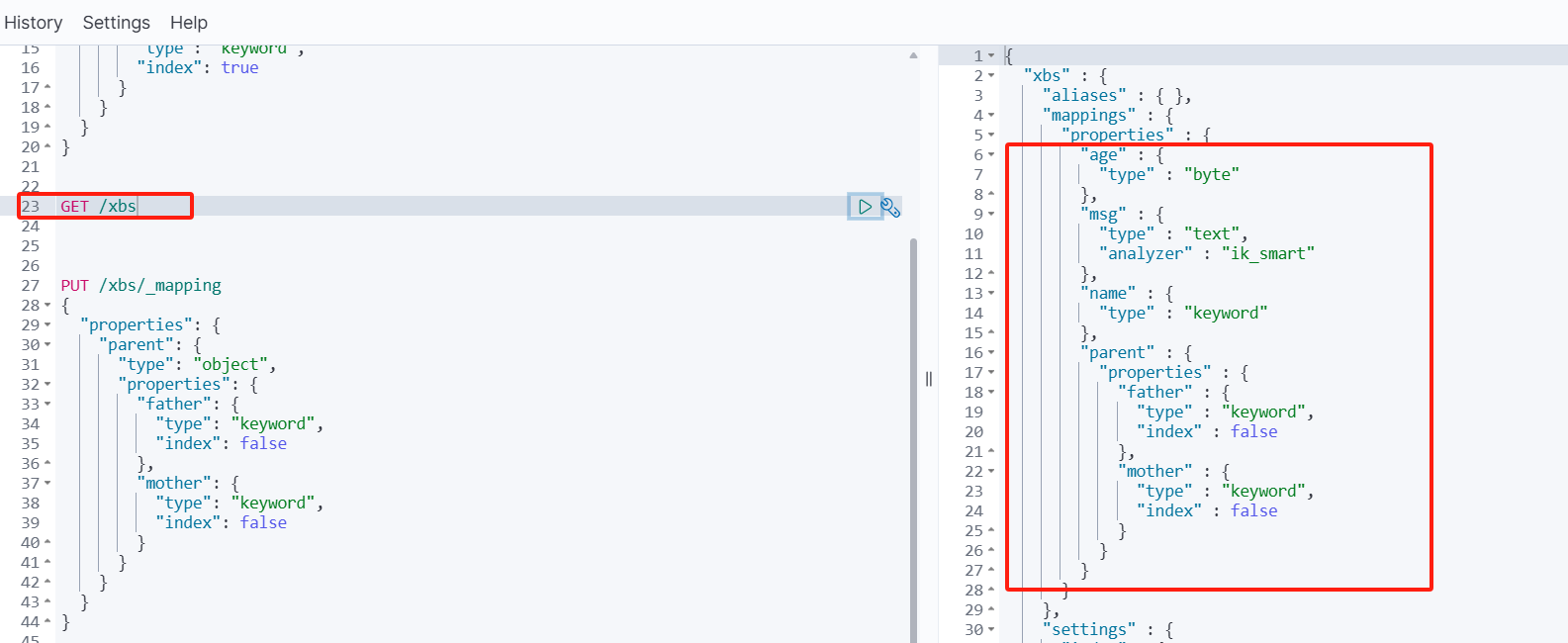
1.2.4 删除索引库
基本语法:
1)请求方式:DELETE
2)请求路径:/索引库名
3)请求参数:无
格式如下:
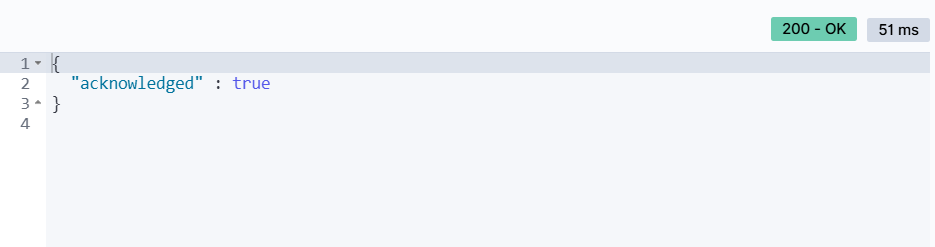
DELETE /索引库名举个例子:
DELETE /xbs输出结果:
2.0 文档操作
有了索引库,接下来就可以向索引库中添加数据了。
Elasticsearch 中的数据其实就是 JSON 风格的文档。操作文档自然保护增、删、改、查等
几种常见操作。
2.1 新增文档
语法:
POST /索引库名/_doc/文档id{ "字段1": "值1", "字段2": "值2", "字段3": { "子属性1": "值3", "子属性2": "值4" },}举个例子:
# 新增数据POST /xbs/_doc/1{ "id": 1, "age": 22, "msg": "我是小扳手", "name": "xbs", "parent": { "father": "螺丝刀", "mother": "锤子" }}
2.2 查询文档
根据 rest 风格,新增是 post,查询应该是 get,不过查询一般都需要条件,这里我们把文档
id 带上。
语法:
GET /{索引库名称}/_doc/{id}举个例子:
# 查看数据GET /xbs/_doc/1输出结果:

2.3 删除文档
删除使用 DELETE 请求,同样,需要根据 id 进行删除。
语法:
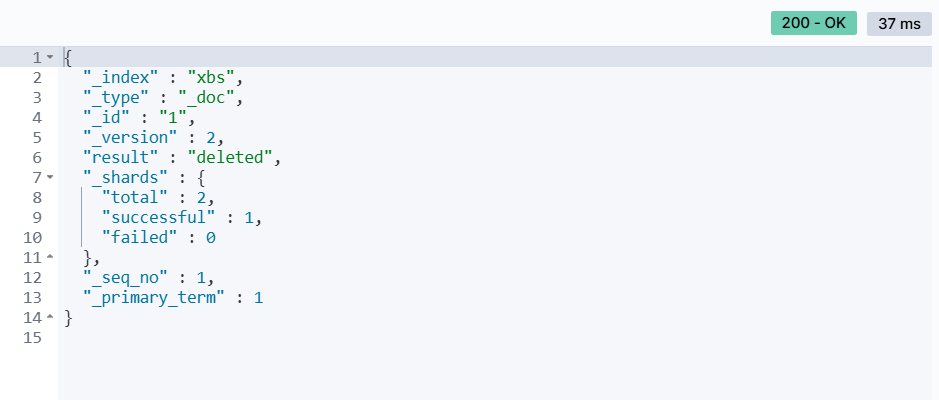
DELETE /{索引库名}/_doc/id值举个例子:
# 删除数据DELETE /xbs/_doc/1输出结果:
2.4 修改文档
修改有两种方式:
1)全量修改:直接覆盖原来的文档。
2)局部修改:修改文档中的部分字段。
2.4.1 全量修改
语法:
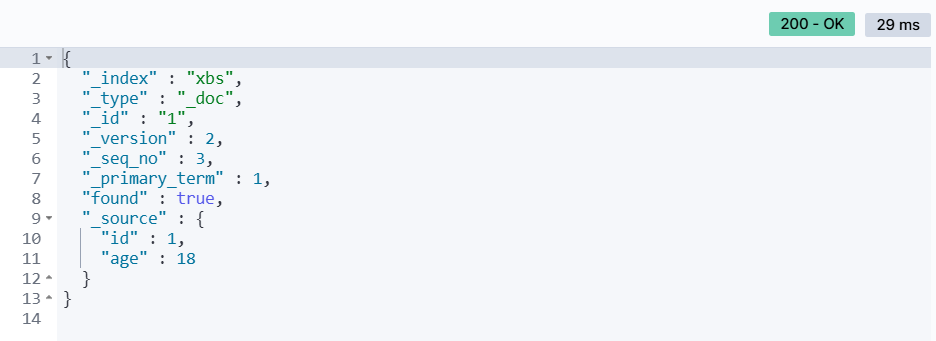
PUT /{索引库名}/_doc/文档id{ "字段1": "值1", "字段2": "值2", // ... 略}举个例子:
#全量修改数据PUT /xbs/_doc/1{ "id": 1, "age": 18}输出结果:
2.4.2 局部修改
局部修改是只修改指定 id 匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id{ "doc": { "字段名": "新的值", }}举个例子:
#局部修改数据POST /xbs/_update/1{ "doc": { "id": 1, "age": 18 }}查看数据:
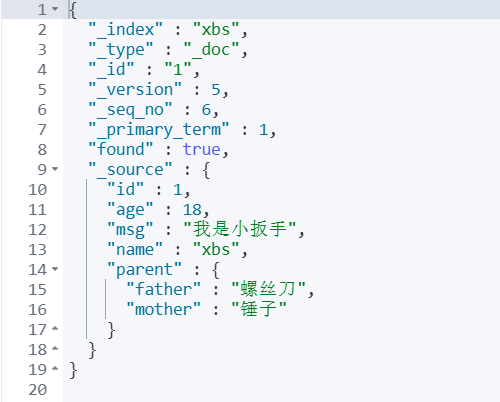
可以看到,只有 age 字段的信息修改了,其他字段的信息没有被修改。
2.5 批处理
批处理采用 POST 请求,基本语法如下:
POST _bulk{ "index" : { "_index" : "test", "_id" : "1" } }{ "field1" : "value1" }{ "delete" : { "_index" : "test", "_id" : "2" } }{ "create" : { "_index" : "test", "_id" : "3" } }{ "field1" : "value3" }{ "update" : {"_id" : "1", "_index" : "test"} }{ "doc" : {"field2" : "value2"} }其中:
1)index代表新增操作
_index:指定索引库名
_id指定要操作的文档id
{ "field1" : "value1" }:则是要新增的文档内容
2)delete代表删除操作
_index:指定索引库名
_id指定要操作的文档id
3)update代表更新操作
_index:指定索引库名
_id指定要操作的文档id
{ "doc" : {"field2" : "value2"} }:要更新的文档字段
举个例子:
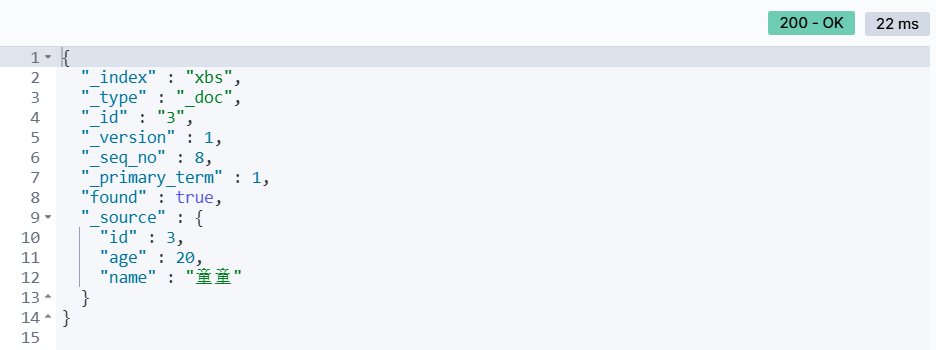
#批量新增数据PUT _bulk{"index":{"_index": "xbs","_id": 2}}{"id": 2,"age": 19,"name": "唐唐"}{"index": {"_index" : "xbs", "_id": 3}}{"id": 3,"age": 20,"name": "童童"}查看数据:

3.0 RestAPI
ES 官方提供了各种不同语言的客户端,用来操作 ES。这些客户端的本质就是组装 DSL 语
句,通过 http 请求发送给 ES 。
官方文档地址:Elasticsearch Clients | Elastic

3.1 初始化 RestClient
在 elasticsearch 提供的 API 中,与 elasticsearch 一切交互都封装在一个名为
RestHighLevelClient 的类中,必须先完成这个对象的初始化,建立与 elasticsearch 的连接。
1)在模块中引入 es 的 RestHighLevelClient 依赖:
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId></dependency>注意版本为:7.12.1
2)因为 SpringBoot 默认的 ES 版本是 7.17.10,所以需要覆盖默认的 ES 版本:
<properties> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> <elasticsearch.version>7.12.1</elasticsearch.version> </properties>3)初始化 RestHighLevelClient:
代码如下:
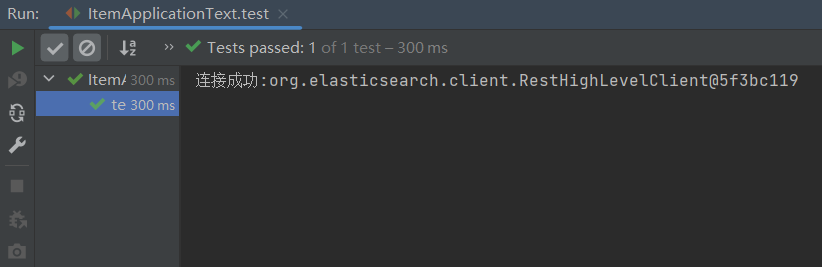
public class ItemApplicationText { private RestHighLevelClient client; @BeforeEach //先初始化,连接到es服务端 public void init() { this.client = new RestHighLevelClient( RestClient.builder(HttpHost.create("http://113.45.xxx.xxx:9200"))); } @Test public void test() throws Exception { if (client != null){ System.out.println("连接成功:" + client); }else { System.out.println("连接失败"); } } @AfterEach //程序结束后,关闭连接 public void close() throws Exception { this.client.close(); }}执行结果:
3.2 创建索引库
创建索引库的 API 如下:
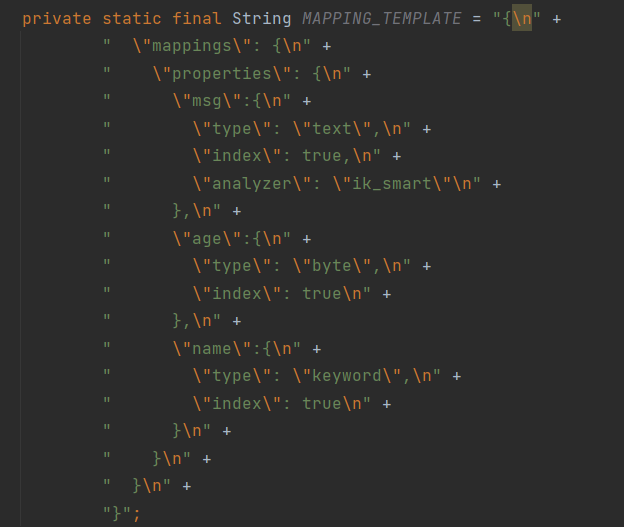
@Test public void build() throws Exception { //1.创建Request对象 CreateIndexRequest request = new CreateIndexRequest("xbs"); //2.准备请求参数,就是创建索引的请求参数JSON字符串 request.source(MAPPING_TEMPLATE, XContentType.JSON); //3.发送请求 client.indices().create(request, RequestOptions.DEFAULT); //该方法返回的对象中包含索引库操作的所有方法 }MAPPING_TEMPLATE 字符串常量:
创建索引库中的语句:
代码分为三步:
1)创建 Request 对象。
因为是创建索引库的操作,因此 Request 是 CreateIndexRequest 。
2)添加请求参数
其实就是 Json 格式的 Mapping 映射参数。因为 json 字符串很长,这里是定义了静态字符
串常量 MAPPING_TEMPLATE,让代码看起来更加优雅。
3)发送请求
client.indices() 方法的返回值是 IndicesClient 类型,封装了所有与索引库操作有关的方
法。例如创建索引、删除索引、判断索引是否存在等。
3.3 删除索引库
删除索引库的请求非常简单。
注意体现在 Request 对象上。流程如下:
1)创建 Request 对象。这次是 DeleteIndexRequest 对象。
2)准备参数。这里是无参,因此省略。
3)发送请求。改用 delete 方法。
具体代码如下:
@Test //删除索引库 public void deleteIndex() throws IOException { //1.创建Request对象 DeleteIndexRequest request = new DeleteIndexRequest("xbs"); //2.发送请求 client.indices().delete(request, RequestOptions.DEFAULT); }
3.4 判断索引库是否存在
判断索引库是否存在,本质就是查询,对应的请求语句是:
GET /xbs具体代码如下:
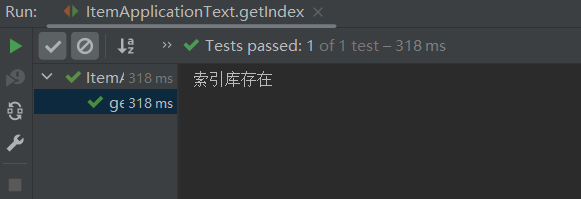
@Test //查询索引库 public void getIndex() throws IOException { //1.创建Request对象 GetIndexRequest request = new GetIndexRequest("xbs"); //2.发送请求 boolean exists = client.indices().exists(request, RequestOptions.DEFAULT); if (exists ){ System.out.println("索引库存在"); }else { System.out.println("索引库不存在"); } }执行结果:
4.0 RestClient 操作文档
索引库准备好以后,就可以操作文档了。
4.1 新增文档
新增文档的请求语法如下:
# 新增数据POST /xbs/_doc/1{ "id": 1, "age": 22, "msg": "我是小扳手", "name": "xbs", "parent": { "father": "螺丝刀", "mother": "锤子" }}对应的 JavaAPI 如下:
@Test //新增数据 public void addData() throws IOException { User user = new User(1, "我是小扳手", 18, "xbs", new Parent("father", "mother")); //1.创建Request对象 IndexRequest request = new IndexRequest("xbs").id("1"); //2.准备JSON文档 request.source(JSONUtil.toJsonStr(user), XContentType.JSON); //3.发送请求 client.index(request, RequestOptions.DEFAULT); }查看结果:

可以看到与索引库操作的 API 非常类似,同样是三步走:
1)创建 Request 对象,这里是 IndexRequest,因为添加文档就是创建倒排索引的过程。
2)准备请求参数,本例中就是 Json 文档。
3)发送请求。
变化的地方在于,这里直接使用 client.xxx() 的 API,不再需要 client.indices() 了。
4.2 查询文档
查询的请求语句如下:
GET /{索引库名}/_doc/{id}对应的 JavaAPI 如下:
@Test //查询数据 public void getData() throws IOException { //1.创建Request对象 GetRequest getRequest = new GetRequest("xbs","1"); //2.发送请求 GetResponse documentFields = client.get(getRequest, RequestOptions.DEFAULT); String sourceAsString = documentFields.getSourceAsString(); //查看结果 //将其转化为user对象 User bean = JSONUtil.toBean(sourceAsString, User.class); System.out.println(bean); }执行结果:
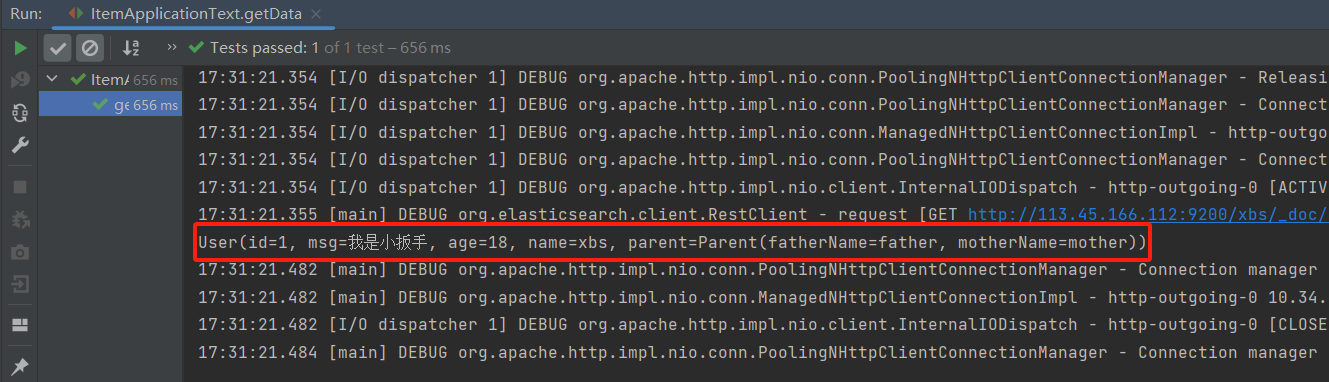
4.3 删除文档
删除的请求语句如下:
DELETE /hotel/_doc/{id}对应的 JavaAPI 如下:
@Test //删除数据 public void deleteData() throws IOException { //1.创建Request对象 DeleteRequest request = new DeleteRequest("xbs","1"); //2.发送请求 client.delete(request, RequestOptions.DEFAULT); }
4.4 修改文档
修改有两种方式:
1)全量修改:本质是先根据 id 删除,再新增。
2)局部修改:修改文档中的指定字段值。
在 RestClient 的 API 中,全量修改与新增的 API 完全一致,判断依据是 ID:
1)如果新增时,ID 已经存在,则修改。
2)如果新增时,ID 不存在,则新增。
这里不再赘述,主要关注局部修改的 API 即可。
具体代码如下:
@Test //修改数据 public void updateData() throws IOException { //1.创建Request对象 UpdateRequest request = new UpdateRequest("xbs","1"); //2.添加参数,每两个参数为一对,组成 key-value request.doc("name","唐唐"); //3.发送请求 client.update(request, RequestOptions.DEFAULT); }执行结果:
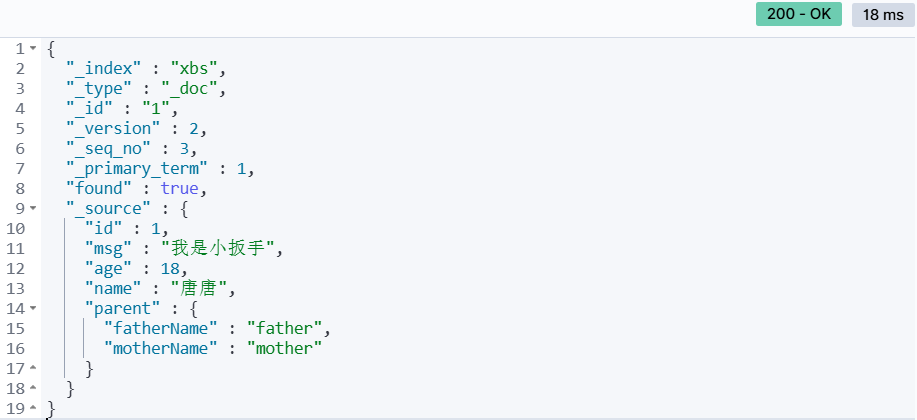
与之前类似,也是三步走:
1)准备 Request 对象。这次是修改,所以是 UpdateRequest 。
2)准备参数,也就是 JSON 文档,里面包含要修改的字段。
3)更新文档,这里调用 client.update() 方法。
4.5 批量导入文档
批处理与前面讲的文档的 CRUD 步骤基本一致:
1)创建 Request,但这次用的是 BulkRequest
2)准备请求参数
3)发送请求,这次要用到 client.bulk() 方法
BulkRequest 本身其实并没有请求参数,其本质就是将多个普通的 CRUD 请求组合在一起发
送。例如:
1)批量新增文档,就是给每个文档创建一个 IndexRequest 请求,然后封装到
BulkRequest 中,一起发出。
2)批量删除,就是创建 N 个 DeleteRequest 请求,然后封装到 BulkRequest,一起发出。
因此 BulkRequest 中提供了 add 方法,用以添加其它 CRUD 的请求:
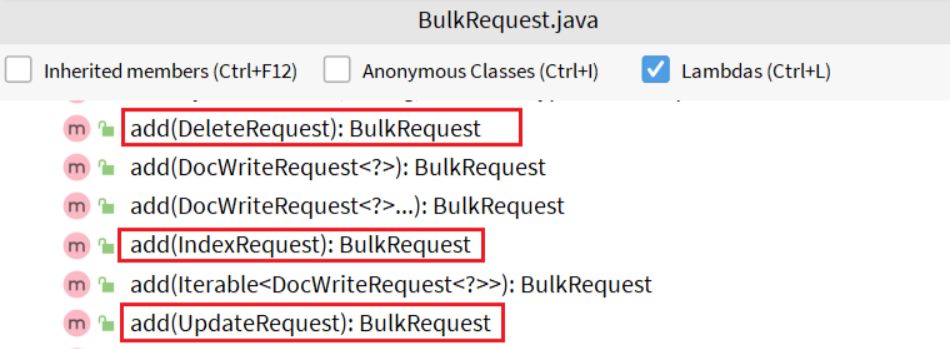
具体代码如下:
批量新增:
@Test //批量新增 public void bulk() throws IOException { //插入的数据 User user = new User(2, "有很多天才", 18, "天才1号", new Parent("老爹", "母亲")); User user2 = new User(3, "都喊我是天才", 22, "天才2号", new Parent("老豆", "老妈")); //1.创建Request对象 BulkRequest bulkRequest = new BulkRequest(); //2.准备参数 bulkRequest.add(new IndexRequest("xbs").id("2").source(JSONUtil.toJsonStr(user), XContentType.JSON)); bulkRequest.add(new IndexRequest("xbs").id("3").source(JSONUtil.toJsonStr(user2), XContentType.JSON)); //3.发送请求 client.bulk(bulkRequest, RequestOptions.DEFAULT); }执行结果:
id 为 "2":

id 为 "3":

批量删除:
具体代码如下:
@Test //批量删除 public void bulkDelete() throws IOException { //1.创建Request BulkRequest bulkRequest = new BulkRequest(); //2.准备参数 bulkRequest.add(new DeleteRequest("xbs", "2")); bulkRequest.add(new DeleteRequest("xbs", "3")); //3.发送请求 client.bulk(bulkRequest, RequestOptions.DEFAULT); }执行结果:
查询 id 为 2:

查询 id 为 3: