文章目录
awk基础结构说明与示例参数与内置变量常用参数内置变量其他参数内置变量 简单示例理解option简单参数NR与FNR-v ARGC ARGV参数 执行脚本if elsefor循环关联数组指定匹配pattern 使用正则指定分隔符理解pattern正则与逻辑算术 printfif else for whileBEGIN ENDnext(跳过行)重定向输出到文件字符串函数替换函数拆分与查找函数其他字符串函数字符串函数示例 算术函数其他函数系统调用(system)时间与格式化(mktime systime strftime)读取流数据,关闭流(getline close) 实例与ss、netstat结合使用,查看IP 端口统计tcp连接中状态数量统计访问日志中404的数量查看本机ip地址统计文件夹下文件大小
awk基础结构说明与示例
这个非常重要,只有理解了awk的基础结构,才能一眼看清awk在做什么,也便于记忆,不然过几天就忘了。
awk [option] [BEGIN{}] ‘[pattern]{action}’ [END{}] file1 file2…
awk是按行处理指定文件的文本:
option是选项,可以设置分隔符等,可选pattern是模式,匹配上才执行action,可选action是动作,例如输出等filename,表示要处理的文件BEGIN,awk开始之前执行1次END,awk结束之后执行1次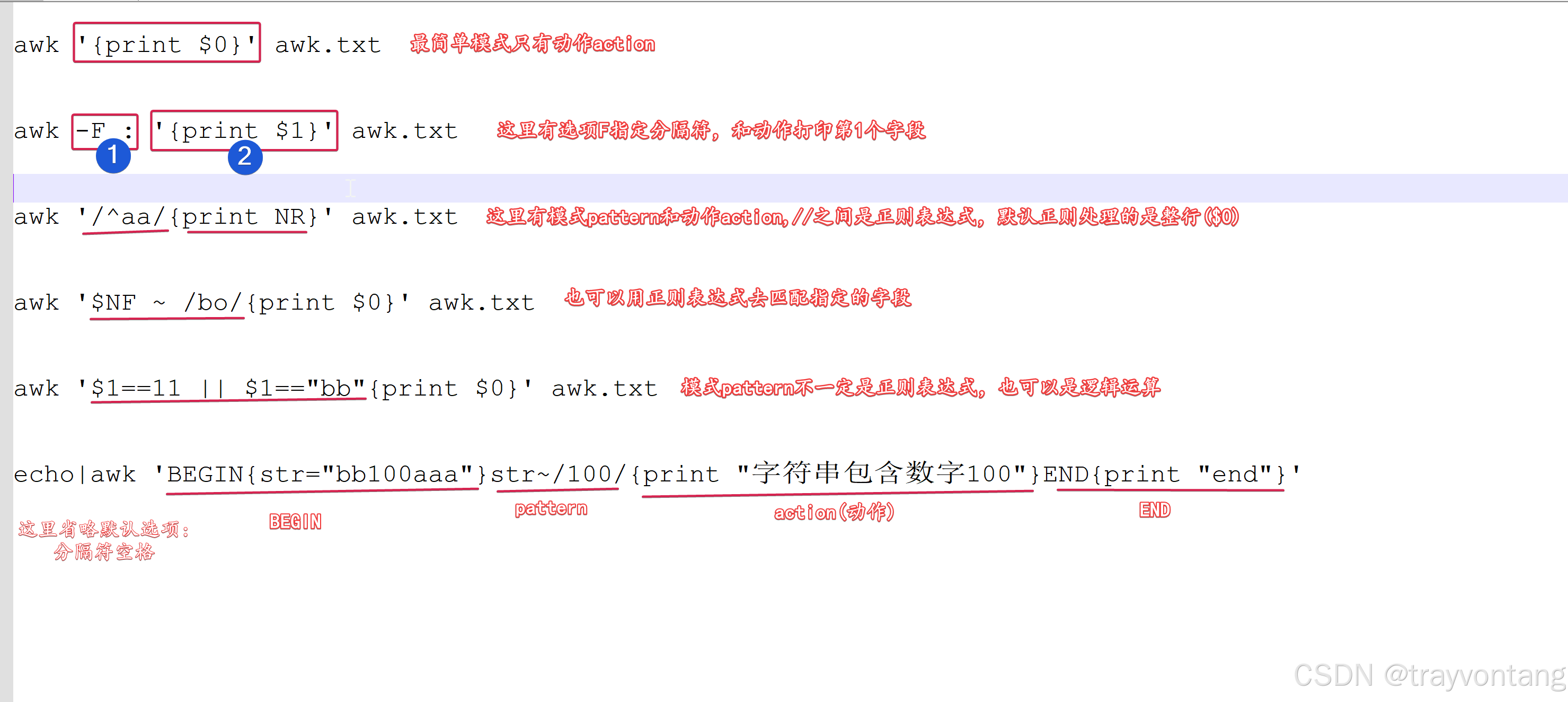
参数与内置变量

常用参数内置变量
| 符号变量 | 说明 |
|---|---|
| -F | 字段分隔符,默认空格 |
| $0 | 匹配到的当前行 |
| $n | n为1、2、3…表示记录分隔之后第n个字段 |
| NF | Number of Field,awk当前处理行的字段数,要取最后一个字段就是$NF |
| NR | Number of Record,awk当前处理的记录数(通常是行) |
| FNR | File Number of Record,awk当前处理的行在文件中的记录数(通常是行) |
| FS | Field Separator,字段分隔符,默认空格 |
| RS | Record Separator,记录(通常是行)分隔符,默认换行符 |
其他参数内置变量
| 符号变量 | 说明 |
|---|---|
| -f awk-script.awk | 指定awk脚本文件 |
| OFS | 输出字段的分隔符,默认空格,Output Field Separator |
| ORS | 输出行(记录)的分隔符,默认换行符,Output Record Separator |
| FILENAME | 处理的文件名称 |
| FIELDWIDTHS | 字段宽度 |
| -v k=v | 指定awk参数 |
| ARGC | awk参数个数 |
| ARGV | awk参数关联数组 |
| IGNORECASE | 是否忽略大小写 |
| OFMT | 数字的输出格式,默认%.6g |
简单示例理解option
我们先看一些简单的示例,来理解参数、变量
测试文件awk.txt
aa bb cc 11 dd 22 aabb cc aa11 22 33luck boy11 33 2211:22:33简单参数
# 使用$0,输出所有行awk '{print $0}' awk.txt# 使用空格做分隔符,输出第1个字段awk '{print $1}' awk.txt# 用:做分隔符,输出第1个字段awk -F : '{print $1}' awk.txt# 使用空格做分隔符,输出最后1个字段awk '{print $NF}' awk.txt# 使用空格做分隔符,输出每行字段总数awk '{print NF}' awk.txt# 打印第一个字段和最后一个字段释义---作为字段分隔符awk 'OFS="---" {print $1,$NF}' awk.txt# 释义ORS指定行分隔符awk 'ORS="行分隔符" {print $1,$NF}' awk.txt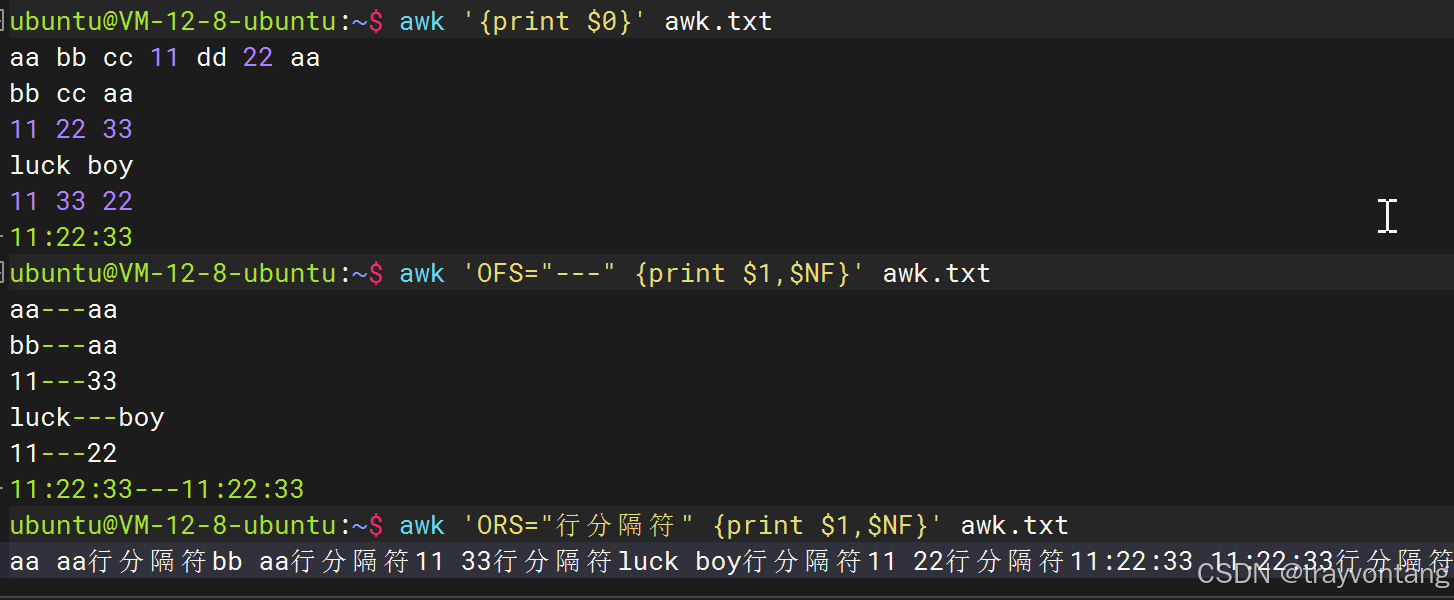
NR与FNR
NR和FNR主要区别体现在有多个文件的时候:
NR是awk处理的当前总行数FNR是awk处理的当前行在文件中的行数awk '{print "文件:"FILENAME,"NR:",NR,"FNR:",FNR}' a1.txt a2.txt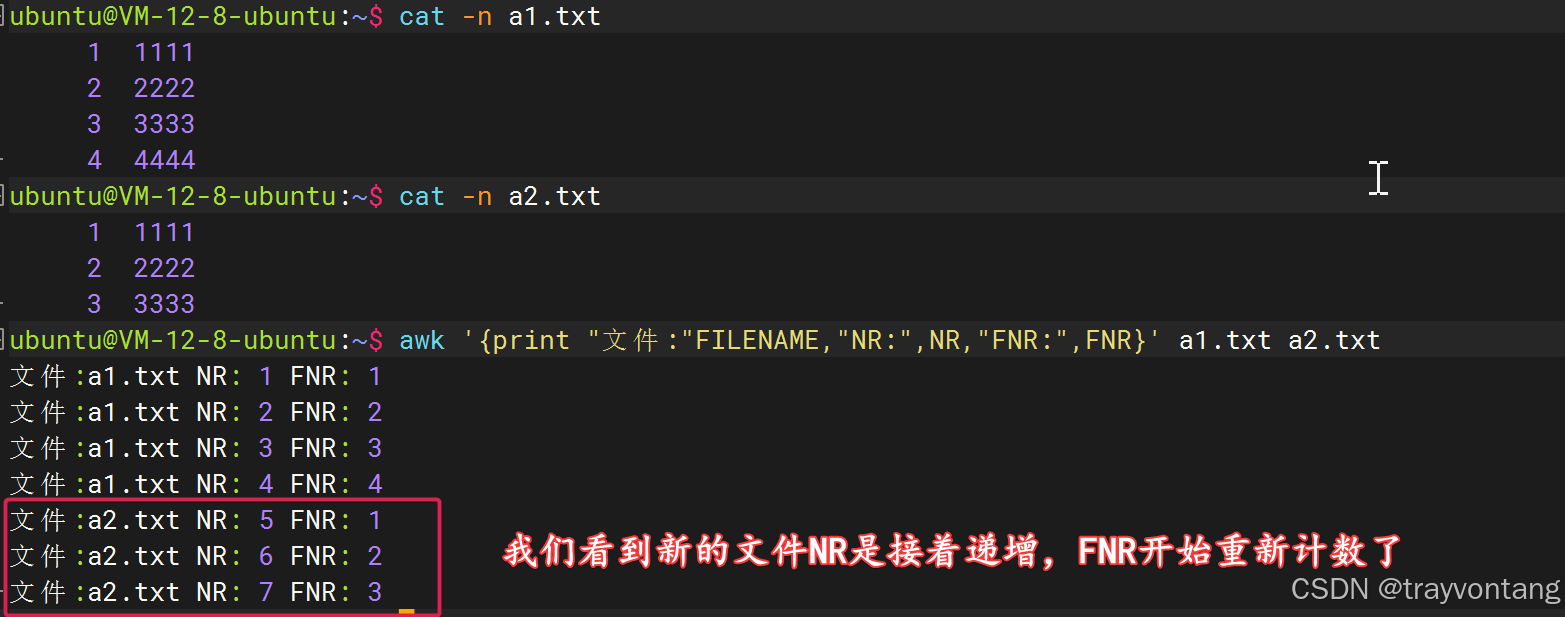
-v ARGC ARGV参数
echo | awk -v v1="参数1" -v v2="v2" 'BEGIN{print v1,v2,ARGC;for( a in ARGV){print a,ARGV[a]}}'
执行脚本
awk可以写非常复杂的命令,有时候写在1行之中不好看,可以将命令写作文件中,然后像sed一样通过-f参数来执行脚本。
awk -f awk-script.awk awk.txt#!/bin/awkBEGIN { print "脚本开始执行,设置选项" FS=" " RS="\n" ORS="\n\n"}{ print $1","$NF}END{ print "脚本执行完成"}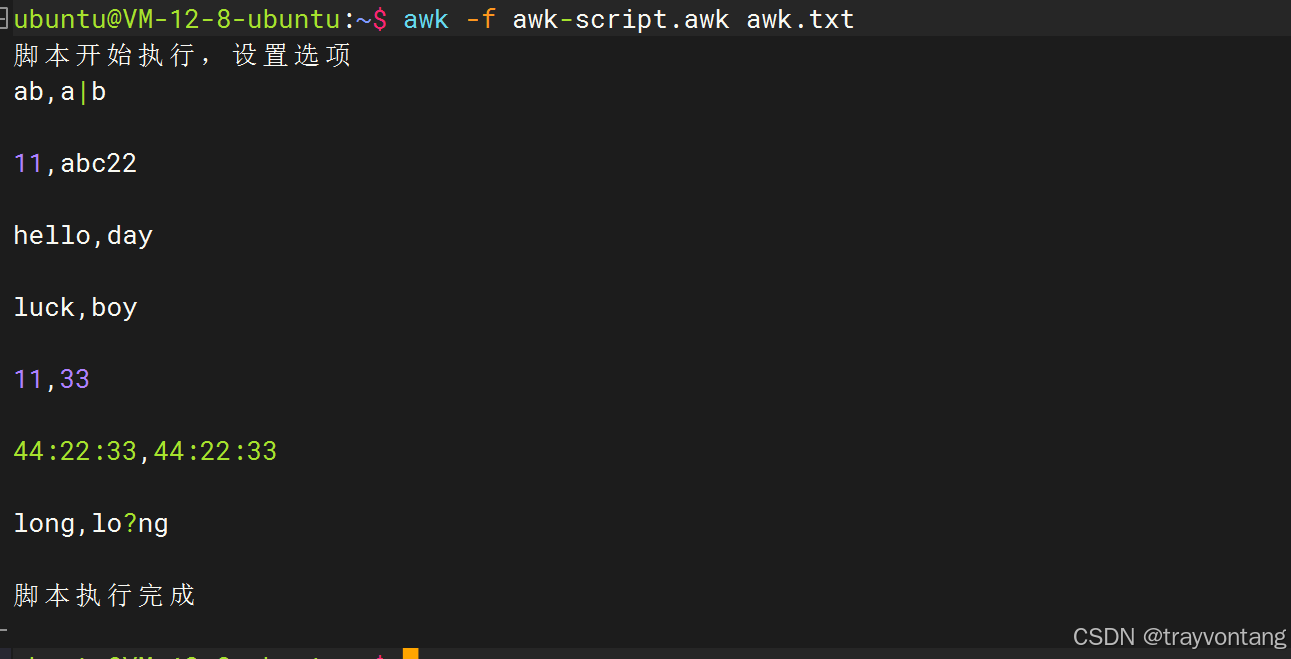
if else
{ if ($1==11) { print "匹配到11" } else if ($1=="luck") { print "匹配到第1个字段luck" } else { print "第一个字段为其他值" }}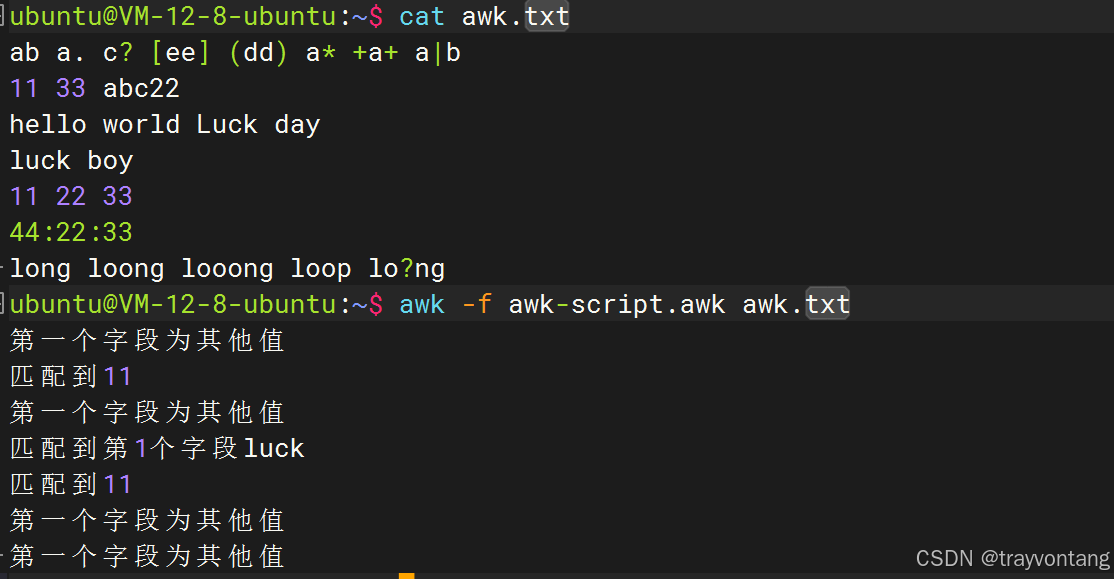
for循环
for循环:
{ for ( i=1;i<=5;i++ ) { print "第",i,"次for循环" }}关联数组
BEGIN { print "输出测试开始"}{ state["TIME-WAIT"]+=NF state["LISTEN"]+=NF*2}END{ print "输出测试结束打印结果" for( s in state) { print state[s] }}指定匹配pattern
BEGIN { print "输出测试开始"}/^11/{ state["TIME-WAIT"]+=NF state["LISTEN"]+=NF*2}END{ print "输出测试结束打印结果" for( s in state) { print s":",state[s] }}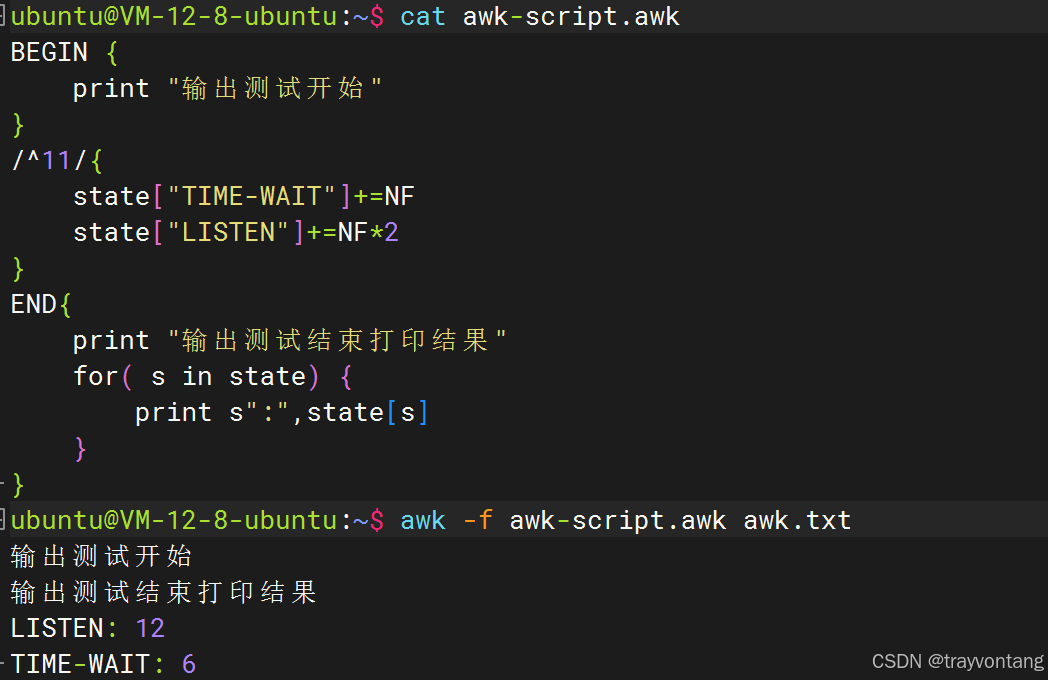
使用正则指定分隔符
例如,下面文件要如何分割其中的数字呢?
11,22,,33,,,4,511,,,22,,33,,,4,511 22,, 33 ,,, 4, 5# 使用正则[ ,]+作为分隔符awk -F '[ ,]+' '{print $1" "$NF}' split.txt# 使用1个或多个空白字符做分隔符awk -F [[:space:]+] '{print $1,$2}' sed.txt # 查看网卡eth0的ipv4、掩码、广播地址ifconfig eth0 | awk -F [" ":]+ 'NR==2{print "ip4:"$3,"掩码:"$5,"广播地址:"$7}'理解pattern
正则与逻辑
| 比较符号 | 说明 |
|---|---|
| > | 小于 |
| < | 大于 |
| >= | 小于等于 |
| <= | 大于等于 |
| && | 与 |
| ~ | 正则匹配(包含) |
| !~ | 正则匹配(不包含) |
# 使用空格做分隔符,匹配aa开头的行输出行号(匹配到新行的行号)awk '/^aa/{print NR}' awk.txt# 输出第2个字段大于第1个字段的行awk '$2 > $1{print $0}' awk.txt# 打印最后一个字段包含bo的行awk '$NF ~ /bo/{print $0}' awk.txt# 打印最后一个字段不包含bo的行awk '$NF !~ /bo/{print $0}' awk.txt# 打印字段数为3的行awk 'NR == 3{print $0}' awk.txt# 打印第1个字段是11或者bb的行,注意字符串类型加双引号awk '$1==11 || $1=="bb"{print $0}' awk.txt# 打印第1个字段是11并且第2个字段是22的行awk '$1==11 && $2==22{print $0}' awk.txt# 查看2到4行的第1个字段awk '{if(NR>=2 && NR<=5) print $1}' awk.txt算术
| 符号 | 说明 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| % | 求余 |
awk '$1 + $2 > 2{print $0}' awk.txtawk '$1 * $2 > 2{print $0}' awk.txt # 打印偶数行awk 'NR % 2 == 0{print $0}' awk.txt# 打印奇数行awk 'NR % 2 == 1{print $0}' awk.txtprintf
| 格式符号 | 说明 |
|---|---|
| %c | ASCII字符 |
| %d | 10进制整数,有符号 |
| %u | 10进制整数,无符号 |
| %e | 科学计数法 |
| %f | 浮点数 |
| %o | 八进制 |
| %c | 单字符 |
| %s | 字符串 |
| %x | 十六进制值 |
| %g | 自适应 |
| - | 左对齐修饰符 |
| # | 8进制加前缀0,16进制加前缀0x |
| + | 显示使用d 、e 、f和g转换的整数时,加上正负号+或- |
| 0 | 用0填充,默认空白字符,数字右对齐生效 |
echo "888888 16 55" | awk '{printf("科学:%e\n8进制:%o\n8进制:%#o\n16进制:%x\n16进制:%#x\n",$1,$2,$2,$3,$3)}'# printf的换行要自己加awk '{printf("文件名:%10s,行号:%s,列数:%s,内容:%s\n",FILENAME,NR,NF,$0)}' awk.txtawk '{ print "第1个字段: " $1 "\t\t最后一个字段:" $NF }' awk.txtawk '{printf "%10s\n",$1}' awk.txtawk '{printf "%-10s\n",$1}' awk.txtawk '{printf "%010d\n",$1}' awk.txt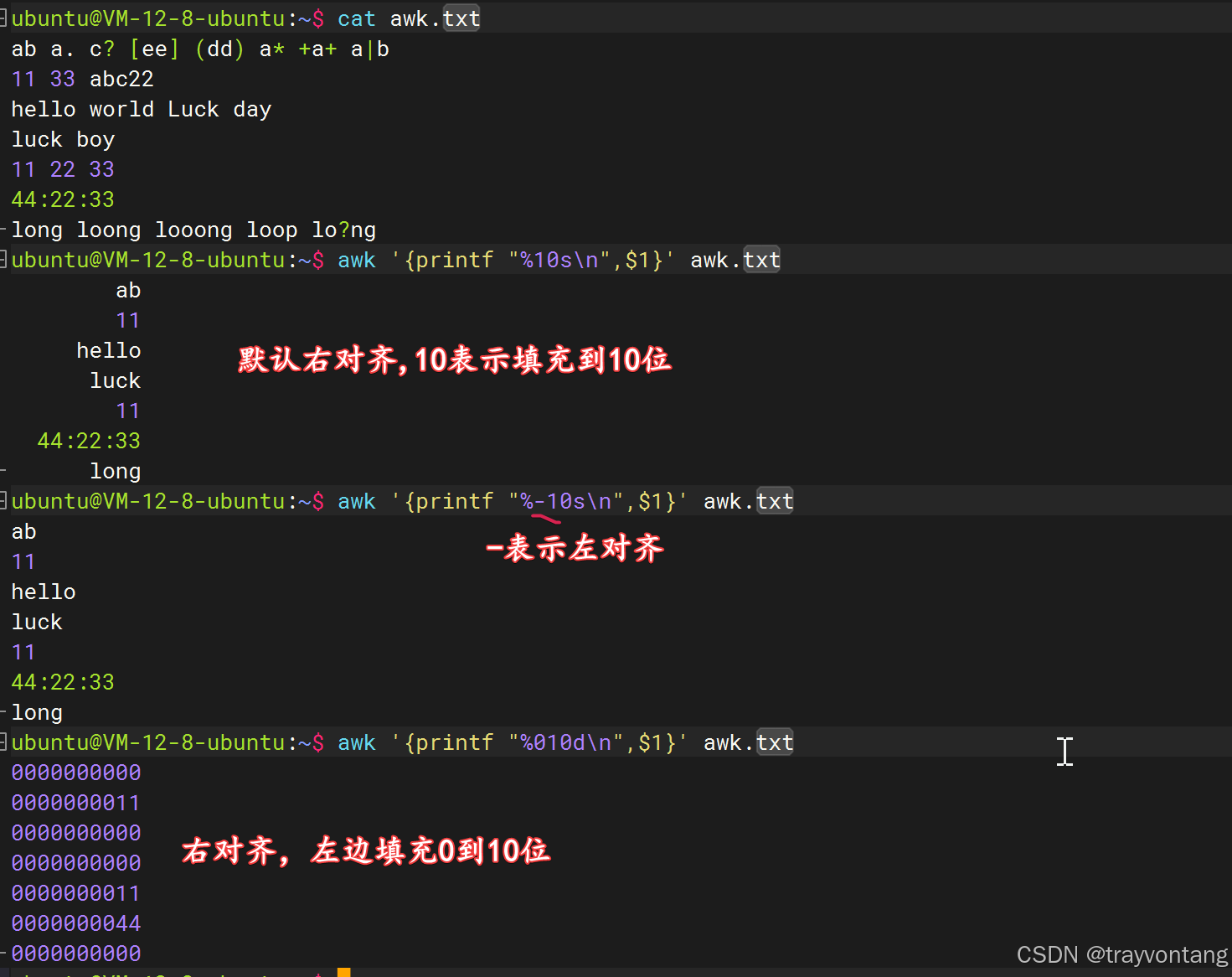
if else for while
# 语句用{}awk '{if($1>$2){print "大于"}else{print "小于或等于"}}' awk.txt# 打印所有字段awk '{for(i=1;i<=NF;i++){print $i}}' awk.txtawk '{i=1; while(i<NF){print $i;i++}}' awk.txtawk '{if(NR%2==0){print "-----"}print $0}' awk.txt# 输出文件2到5行awk '{if(NR>=2 && NR<=5) print $0}' awk.txt BEGIN END
注意是大写的BEGIN END
# BEGIN最先执行,END最后执行awk 'BEGIN {print "执行begin语句"} {print $1","$NF} END {print "执行end语句"}' awk.txt# 多条语句;分割awk 'BEGIN{num=0;a+=5;print a}'# 支持正则awk 'BEGIN{str="aa100bbcc";if(str~/100/) {print "字符串包含数字100"}}'# echo不能省略,因为awk默认需要文件,这里echo没有输入,使用begin中初始化的变量echo|awk 'BEGIN{str="bb100aaa"}str~/100/{print "字符串包含数字100"}END{print "end"}'# 支持三目运算符awk 'BEGIN{num=200;print num==200?"状态码正常":"状态码错误"}'# 可以通过FS变量来指定分隔符awk 'BEGIN{FS=":"}{print NF}' awk.txtawk 'BEGIN{FS=":";OFS="#"}{print $1,$2}' awk.txt # 统计第1个字段等于11的行数awk 'BEGIN {count=0;} {if($1==11){count=count+1};print $0} END{print "第1个字段是11行数:",count}' awk.txtnext(跳过行)
next表示跳过行
# 打印偶数行,跳过奇数行awk 'NR%2==1{next}{print NR,$0;}' awk.txt# 将11开头的行缓存拼接到后面行的前面awk '/^11/{cache=$0;next;}{print cache"####"$0;}' awk.txt# 只拼接到下1行awk '/^11/{cache=$0"####";next;}{print cache$0;cache=""}' awk.txt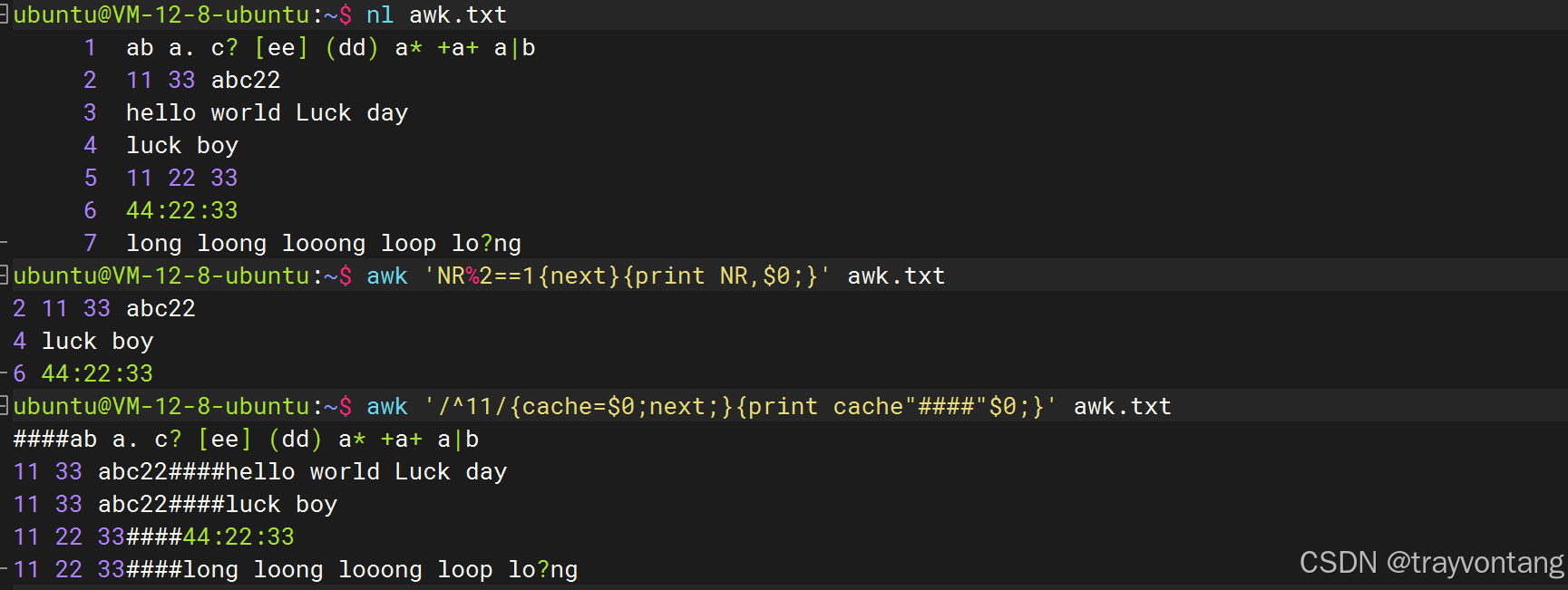
重定向输出到文件
# 覆盖原文件echo | awk '{printf("hello word!\n啊哈\n") > "awk-data.txt"}'# 在原文件上追加内容echo | awk '{printf("hello word\n娘子\n") >> "awk-data.txt"}'字符串函数
替换函数
| 函数 | 说明 |
|---|---|
| gsub(r,s) | 在整个$0中用s代替r |
| gsub(r,s,t) | 在整个t中用s替代r |
| sub(r,s) | 用$0中最左边最长的子串代替s |
| substr(s,p) | 返回字符串s中从p开始的后缀部分 |
| substr(s,p,n) | 返回字符串s中从p开始长度为n的后缀部分 |
拆分与查找函数
| 函数 | 说明 |
|---|---|
| index(s,t) | 返回s中字符串t的第1个位置,索引从1开始,如果没有找到返回0 |
| match(s,r) | 测试s是否包含匹配r的字符串,返回第1个匹配位置,没有匹配则为0 |
| split(s,a,fs) | 在fs上将s分成序列a |
| sprint(fmt,exp) | 经fmt格式化后的exp |
其他字符串函数
| 函数 | 说明 |
|---|---|
| length(s) | 返回s字符长度 |
| blength(s) | 返回s字节长度 |
| tolower(s) | 转换为小写字母 |
| toupper(s) | 转换为大写字母 |
字符串函数示例
# 打印长度和匹配aa的位置awk '{print length($0),match($0,"aa")}' awk.txt# 将aa替换为aa-aaawk '{gsub("aa","aa-aa");print $0}' awk.txt# 用[0-9]+在content匹配,并用####替换awk 'BEGIN{content="what are word 99 啊哈 100 娘子 88";gsub(/[0-9]+/,"####",content);print content}'# 索引位置从1开始awk 'BEGIN{content="what are word 99 啊哈 100 娘子 88";print index(content,"what")}'# 返回的是第1个位置awk 'BEGIN{content="what are word 99 啊哈 100 娘子 88";print index(content,"are")}'# 没找到返回0awk 'BEGIN{content="what are word 99 啊哈 100 娘子 88";print index(content,"where")}'# 索引位置从1开始awk 'BEGIN{content="what are word 99 啊哈 100 娘子 88";print match(content,"what")}'# 返回的是第1个位置awk 'BEGIN{content="what are word 99 啊哈 100 娘子 88";print match(content,"are")}'# 没找到返回0awk 'BEGIN{content="what are word 99 啊哈 100 娘子 88";print match(content,"where")}'# 从第5个字符开始,截取6个字符awk 'BEGIN{content="what are word 99 啊哈 100 娘子 88";print substr(content,5,6);}'# 用空格拆分content,然后打印数组长度和数组awk 'BEGIN{content="what are word 99 啊哈 100 娘子 88";split(content,resultArray," ");print length(resultArray);for(k in resultArray){print k,resultArray[k];}}'# 默认就是使用空格拆分,所以可以省略第3个参数awk 'BEGIN{content="what are word 99 啊哈 100 娘子 88";split(content,resultArray);print length(resultArray);for(k in resultArray){print k,resultArray[k];}}'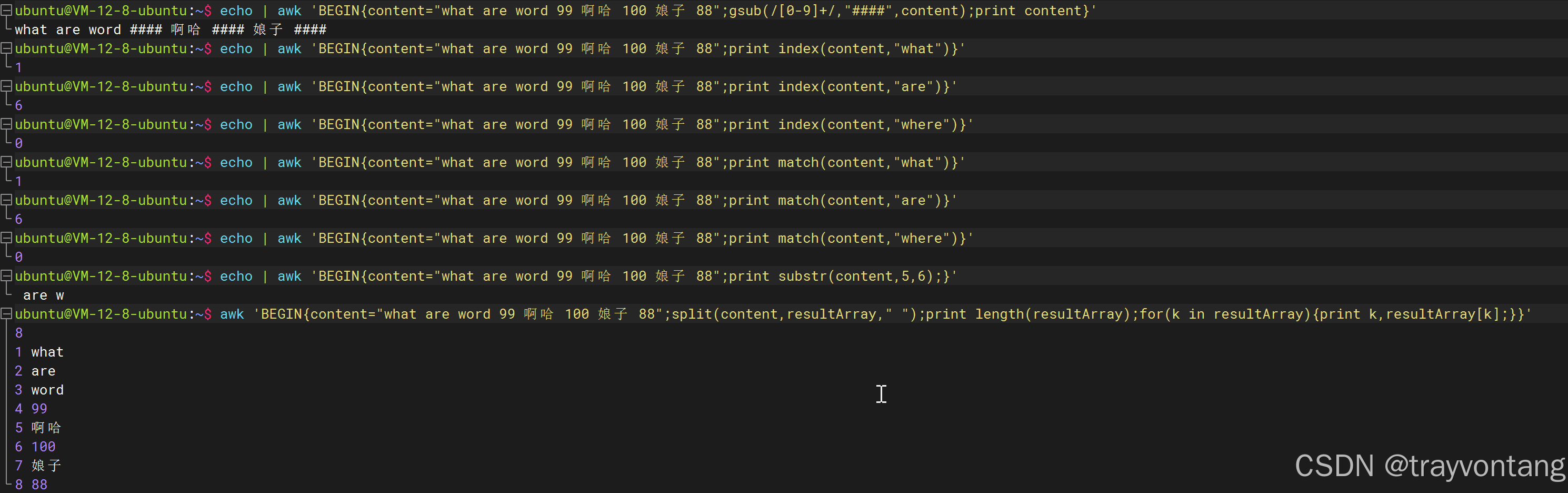
算术函数
| 函数 | 说明 |
|---|---|
| atan2(y,x) | y/x的反正切 |
| cos(x) | x的余弦;x 是弧度 |
| sin(x) | x的正弦;x 是弧度 |
| exp(x) | x幂函数 |
| log(x) | x的自然对数 |
| sqrt(x) | x平方根 |
| int(x) | x取整 |
| rand() | 生成随机数n,0 <= n < 1 |
awk 'BEGIN{srand();num=100*rand();print num}'awk 'BEGIN{srand();num=int(100*rand());print num}'awk 'BEGIN{srand();num=sqrt(16);print num}'其他函数
| 函数 | 说明 |
|---|---|
| system() | 调用系统命令 |
| mktime() | 生成时间 |
| strftime() | 格式化时间输出,将时间戳转为时间字符串 |
| systime() | 得到时间戳,秒 |
| close() | 关闭流,通常和getline结合使用 |
| getline | 从标准输入、重定向、管道、文件等输入流获取数据 |
系统调用(system)
awk中可以使用system()来调用系统命令
# 创建第1个字段为文件名的txt文件awk '{system("touch "$1".txt")}' awk.txt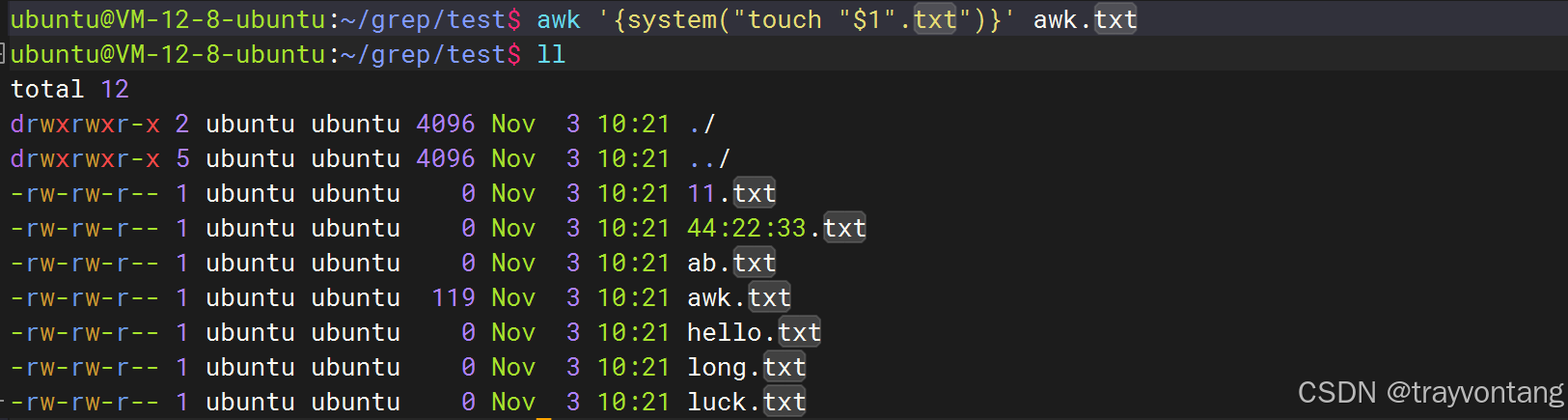
用awk命令来执行文件中的所有awk命令:
awk 'BEGIN{print "脚本命令执行开始"}/^awk/{print "执行命令:"$0;system($0)}END{print "\n脚本命令执行结束"}' awk-sh.txt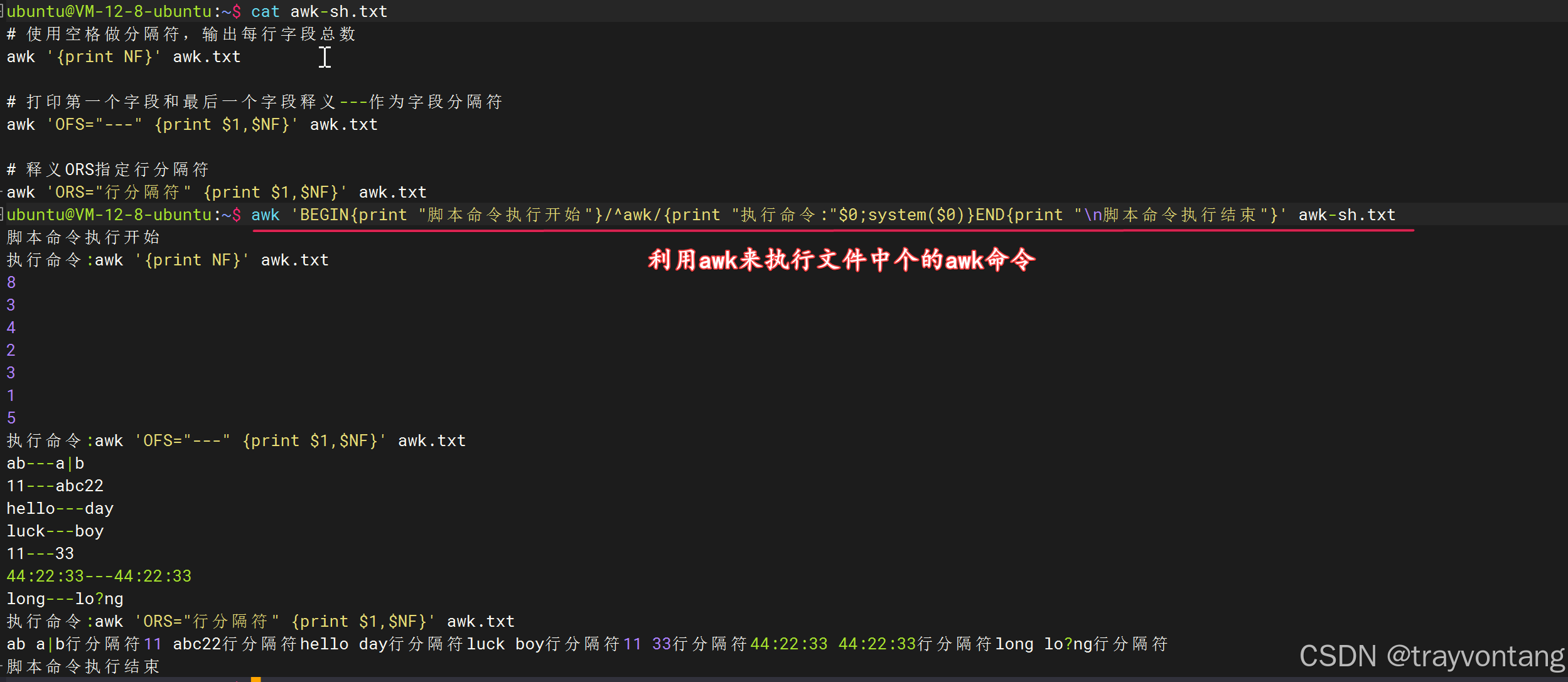
时间与格式化(mktime systime strftime)
更符合中国习惯格式:
| 格式 | 说明 |
|---|---|
| %Y | 4位年(2024) |
| %y | 2位年(24) |
| %m | 数字月份 |
| %d | 几号,03表示3号 |
| %e | 几号,3表示3号 |
| %H | 24小时,16表示下午4点 |
| %M | 分钟 |
| %S | 秒 |
| %D | 月/日/年,11/03/24 |
| %y | 2位年(24) |
西方格式习惯:
| 格式 | 说明 |
|---|---|
| %c | 本地日期和时间,Wed 01 Jan 2025 11:59:59 PM CST |
| %I | 12小时,04,可能是早上4点,也可能是下午4点 |
| %p | 12小时表示法(AM/PM) |
| %b | 月缩写(Nov) |
| %B | 月(November) |
| %j | 从1月1日起一年中的第几天 |
| %w | 星期几数字(星期天是0) |
| %A | 星期几(Sunday) |
| %U | 年中的第几个星期(星期天作为一个星期的开始) |
| %W | 年中的第几个星期(星期一作为一个星期的开始) |
| %x | 重新设置本地日期 |
| %X | 重新设置本地时间 |
| %Z | 时区 |
| %% | 百分号(%) |
# 打印当前时间戳,10位、秒awk 'BEGIN{now=systime();print now}'# 根据时间创建时间戳:年月日时分秒 yyyy MM dd HH mm ssawk 'BEGIN{time=mktime("2025 01 01 23 59 59");print time}'# 时间戳不好看,格式化一下awk 'BEGIN{time=mktime("2025 01 01 23 59 59");print strftime("%c",time)}'# 还不好看,在简化一下awk 'BEGIN{time=mktime("2025 01 01 23 59 59");print strftime("%D",time)}'# 还不好看,自定义一下awk 'BEGIN{time=systime();print strftime("%Y-%m-%d %H:%M:%S",time)}'# 计算一下到元旦还有多少天awk 'BEGIN{time1=mktime("2025 01 01 00 00 00");time2=systime();print int((time1-time2)/(24 * 3600))}'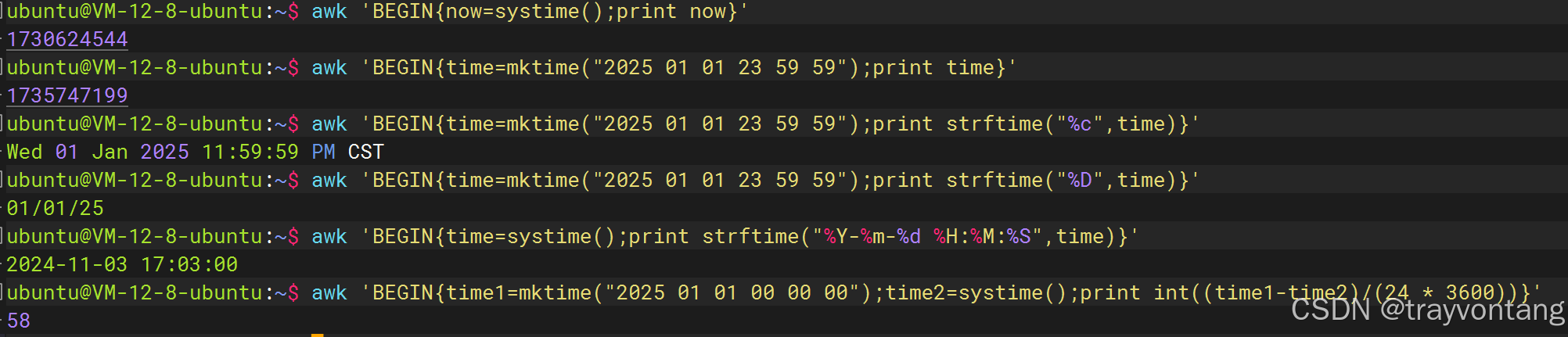
读取流数据,关闭流(getline close)
awk 'BEGIN{ "date" | getline time; print time }'awk 'BEGIN{ "date" | getline time; split(time,times); for(t in times){print t,times[t]}}'# getline 没有参数默认赋值个$0,print没有变量,默认输出$0awk 'BEGIN{ while( "ls" | getline) print}'awk 'BEGIN{ while( "ls" | getline) print $0}'# NF也会被赋值,注意不能使用别名如llawk 'BEGIN{ while( "ls -l" | getline) print NF,NR,FNR}'# 管道方式awk 'BEGIN{while("cat /home/ubuntu/awk.txt"|getline){print NF,NR,FNR};close("/home/ubuntu/awk.txt");}'# 重定向方式awk 'BEGIN{while(getline < "/home/ubuntu/awk.txt"){print NF,NR,FNR};close("/home/ubuntu/awk.txt");}'# 从标准输入获取awk 'BEGIN{print "标准输入值:";getline value;print value;}'实例
与ss、netstat结合使用,查看IP 端口
# 当前tcp连接的打印ip端口netstat -an | awk '/tcp/{print $4}'# 只打印端口netstat -an | awk '/tcp/{print $4}' | awk -F: '{print $NF}'# 去重之前要先排序,因为uniq只去相邻重复的数据netstat -an | awk '/tcp/{print $4}' | awk -F: '{print $NF}' | sort -n | uniq# 打印本地监听的ip和端口ss -tunl | awk '/tcp/{print $5}'# 本地ip都是localhost,我们通常只关心端口ss -tunl | awk '/tcp/{print $5}' | awk -F: '{print $NF}'# 查看所有tcp的本地连接与远程连接ss | awk '/tcp/{print $5,$6}'统计tcp连接中状态数量
# 查看TIME-WAIT数量ss -a | awk 'BEGIN {count=0;} $1=="tcp" && $2=="TIME-WAIT"{count++}END{print "TIME-WAIT数量:",count}'# 利用数组查看不同状态的数量ss -a|awk '/^tcp/{++s[$2]}END{for(a in s)print a,s[a]}'统计访问日志中404的数量
# 先看一下是否匹配正确head server_access_log | awk '{print $9}'awk 'BEGIN {count=0;} $9==404{count++}END{print "404数量:",count}' server_access_log查看本机ip地址
ifconfig | grep inet | awk '{print $2}'统计文件夹下文件大小
# 统计某个文件夹下的文件占用的字节数ll | awk 'BEGIN {size=0;} {size=size+$5;} END{print "文件夹下文件总大小:",size}'# M单位换算ll | awk 'BEGIN{size=0;} {size=size+$5;} END{print "文件夹下文件总大小:",size/1024/1024,"M"}'