文章目录
3.C语言过渡到C++(中)3.1 函数重载3.1.1 函数重载的多种情况3.1.2 函数重载的辨别3.1.3 函数重载原理——名字修饰 3.2 引用3.2.1 引用的概念3.2.2 引用的特性3.2.3 常引用3.2.3.1 权限问题3.2.3.2 类型转换 3.2.4 引用的使用3.2.4 传值、传引用效率比较 3.3 内联函数3.3.1 非内联函数与内联函数比较3.3.2 内联函数的特性 希望读者们多多三连支持小编会继续更新你们的鼓励就是我前进的动力!接上一篇C++入门学习,本篇将重点学习函数重载,引用,内联函数的内容,尤其引用是重中之重?
3.C语言过渡到C++(中)
3.1 函数重载
是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这
些同名函数的形参列表不同在于参数个数 或 类型 或 类型顺序
常用来处理实现功能类似数据类型不同的问题
3.1.1 函数重载的多种情况
?参数类型不同
int Add(int left, int right){ cout << "int Add(int left, int right)" << endl; return left + right;}double Add(double left, double right){ cout << "double Add(double left, double right)" << endl; return left + right;}一个函数类型为 int ,一个函数类型为 double ,构成函数重载
?参数个数不同
void f(){ cout << "f()" << endl;}void f(int a){ cout << "f(int a)" << endl;}一个函数含有不含参数,一个函数有一个参数,构成函数重载
?参数类型顺序不同
void f(int a, char b){ cout << "f(int a,char b)" << endl;}void f(char b, int a){ cout << "f(char b, int a)" << endl;}一个函数先传 int 再传 char,一个函数先传 char 再传 int
?值得注意的是:函数的返回值不构成重载
3.1.2 函数重载的辨别
?参数类型顺序混淆
void f(int a, char b){ cout << "f(int a,char b)" << endl;}void f(int b, char a){ cout << "f(int b, char a)" << endl;}这是一种典型错误的函数重载,函数参数顺序的重载针对的是类型
这里只是把参数名调换了顺序,这会导致传参的时候出现歧义,不知道要调用哪一个函数,所以参数顺序重载和参数名顺序无关,只和参数类型顺序有关
?无参与缺省参数混淆
void f(){ cout << "f()" << endl;}void f(int a = 0){ cout << "f(int a = 0)" << endl;}这也是一种典型错误的函数重载,无参和只有一个缺省参数其实是同一种情况,这里函数调用的时候编译器不知道要不要传入缺省值,导致产生歧义
3.1.3 函数重载原理——名字修饰
根据 C 语言的学习,我们知道一个程序执行的过程分为预处理、编译、链接
在链接阶段,链接器会根据编译器生成的经过名字修饰后的函数名称,将调用和函数定义进行正确的连接
⌨️由于Windows下vs的修饰规则过于复杂,而Linux下g++的修饰规则简单易懂,下面我们使用了g++演示了这个修饰后的名字
?C语言环境下
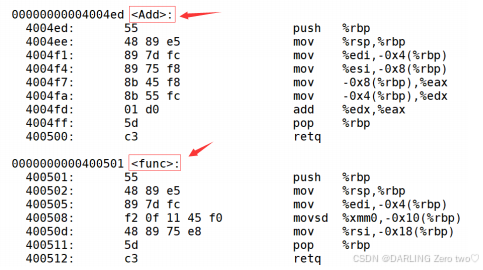
• C 语言的函数调用通常是比较直接的过程,在编译阶段,编译器会将函数调用翻译成机器指令,这些指令会在运行时按照调用约定将参数传递到栈上或者寄存器中,然后跳转到函数的入口地址执行函数体
• 在链接过程中,C 语言的函数名在目标文件中一般是简单的符号形式,例如,对于函数int func(int a),在目标文件中函数名可能就是 func ,当链接器链接多个目标文件时,它会根据函数名来匹配函数的调用和定义
?C++环境下
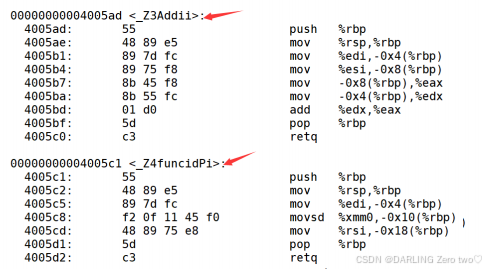
⌨️根据反汇编代码可以知道函数在 C++ 环境下进行了函数名修饰,i 是整型,d 是双精度浮点数,Pi 是整型指针,这里 “Z” 是名字修饰后的标识部分,“4” “3”可能与函数名 “func” 的长度有关
• C++ 由于有函数重载、命名空间、类等特性,其函数调用过程相对复杂。在编译阶段,除了传递参数等常规操作外,编译器还需要进行名字修饰来区分不同的函数
• 在链接阶段,C++ 的函数名经过名字修饰后,链接器才能正确地将函数调用和函数定义进行匹配。例如,对于函数int func(int a),在不同的编译器和编译选项下,可能会被修饰成类似 _Z4funcidPi 这样复杂的名字,以区别于其他可能存在的同名函数(如不同参数类型的重载函数)
3.2 引用
3.2.1 引用的概念
引用是一种别名机制,它允许你为一个已经存在的变量创建一个新的名字,这个新名字和原来的变量共享相同的内存地址,对引用的操作实际上就是对被引用变量的操作
int a = 0;int& b = a; // b 是 a 的别名?值得注意的是:引用与指针类似,他与指向的变量共享一块内存,引用本身不占据内存,他是指向变量的别名,引用本质上是绑定到指向变量的地址上
3.2.2 引用的特性
?定义时必须初始化
int a = 1;int& b = a;//正确int& b;//错误指针在创建的时候可以不绑定变量地址,但是引用必须绑定指向变量
?一个变量可以有多个引用
int a = 1;int& b = a;int& c = a;a 的别名可以是多个,b 和 c 都是 a 的别名
?引用只能绑定一个变量
int a = 1;int& b = a;int x = 2;int& b = x;这里 b 已经绑定了 a ,就不能再绑定 x 了,举个有趣的例子,a 已经和 b 结婚了,就不能再去找小三了?
?值得注意的是:
• 没有 NULL 引用,但有 NULL 指针
• 有多级指针,但是没有多级引用
• 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
• 引用比指针使用起来相对更安全
3.2.3 常引用
3.2.3.1 权限问题
⌨️只有左边引用的值改变会影响右边的值时候,才涉及权限的放大与缩小,权限可以平移或缩小,但是不能放大,普通赋值就不涉及权限的问题
?权限的放大
const int a = 10; int& ra = a; a 与 ra 的类型不匹配,需要在 int& 前加一个 const,这里是权限的放大
?权限的平移和缩小
int a = 0;int& b = a;const int& c = a;第二行是权限的平移,等号两边都是 int 类型,是权限的平移;第三行是权限的缩小,左边是 const int ,右边是 int ,是权限的缩小
?普通赋值不涉及权限
const int a = 0;int b = a;a 拷贝给 b,没有放大权限,因为这里 b 的改变不影响 a,和权限没有关系
3.2.3.2 类型转换
⌨️在介绍常引用之前,我们要回顾一下算术转换
double a = 1.11;int b = a;这里 int 向上转化为 double ,难道是直接进行转化吗?不是的,a 在传递给 b 的过程中产生了一个 int 的临时变量,临时变量具有常性,但这里是普通赋值,不涉及权限问题,所以直接赋给 b
?那么就可以迁移到常引用类型转换
double d = 1.11;int& r = d;这里 d 先转化成 int 的临时变量,临时变量具有常性(常性就是类似于加了 const不可修改),左边的值没加 const ,所以这里是权限的放大,转换失败
3.2.4 引用的使用
?引用做参数
void Swap(int& left, int& right){ int temp = left; left = right; right = temp;}实参给形参传值时,如果想要调用函数时,能够改变实参的值,通常我们会使用传址调用的方式,也就是把实参的地址传给指针形参,但这样未免太麻烦了,那么用引用代替指针未免不是一个好办法,修改引用的值就是修改原来的实参
?引用做返回值
int& Count(){ static int n = 0; n++; // ... return n;}int main(){ int ret = Count() cout << ret << endl;}首先我们要知道什么是浅拷贝,什么是深拷贝?
⌨️ 浅拷贝:
浅拷贝会创建一个新的东西,这个新东西的基本内容是把原来的东西复制了一份。但是如果碰到比较复杂的内容,像一组东西,新的和旧的就都指向这同一组东西,会互相影响的
⌨️ 深拷贝:
与浅拷贝不同的是他不仅会把原来的东西全部复制过去,他会重新创建一份自己的地址,不会互相影响
?如果没有引用返回和 static 的话:
那么他是创建一个中间变量把 n 复制过去,然后再把中间变量赋值给 ret,为什么要这么做?因为出了作用域 n 传给 ret 的值是不确定的
• 如果 Count 函数结束,栈帧销毁,没有清理栈帧,那么 ret 的结果侥幸是正确的
• 如果 Count 函数结束,栈帧销毁,清理栈帧,那么 ret 的结果是随机的
?如果没有 static 的话:
局部变量是在函数的栈帧上分配内存的,当函数执行完毕后,其栈帧会被销毁,局部变量所占用的内存也随之被释放。在 Count 函数中,n 是一个局部变量,当 Count 函数执行完 return n; 这一步并返回后,n 所占用的内存已经被释放了,此时返回的引用实际上指向了一块已经被释放的内存区域
所以想要使用引用返回的话就要保证返回的值是没有被销毁的,或者要在返回的值前加上 static 关键字
3.2.4 传值、传引用效率比较
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。当一个函数返回引用时,它返回的是对象在内存中的地址,而不是对象的副本,有利于提高效率
3.3 内联函数
3.3.1 非内联函数与内联函数比较
⌨️以 inline 修饰的函数叫做内联函数,编译时 C++ 编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。假如有 1000 行代码调用非内联函数(3行),那么一共有 1000 + 3 行;假如有 1000 行代码调用内联函数(3行),那么一共有 1000 * 3 行
?非内联函数
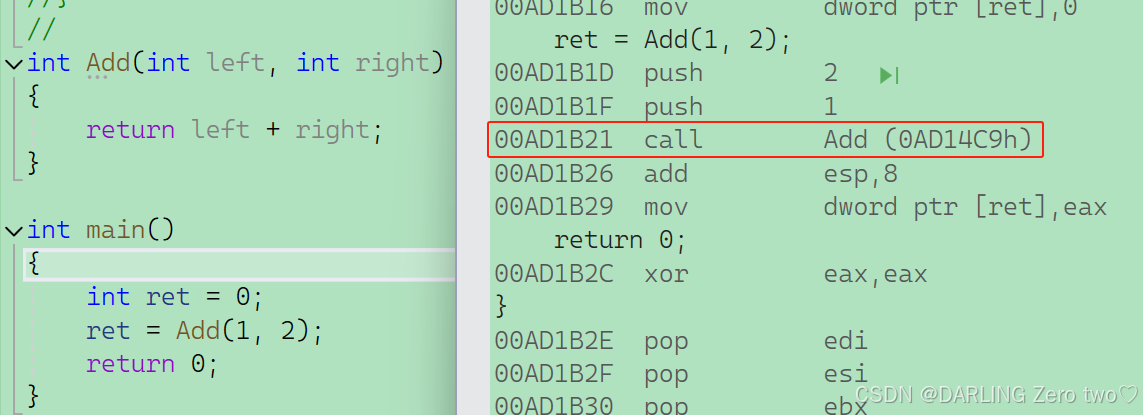
一个简单的加和函数,转到反汇编,是有 call 指令的,也就是调用函数
?内联函数
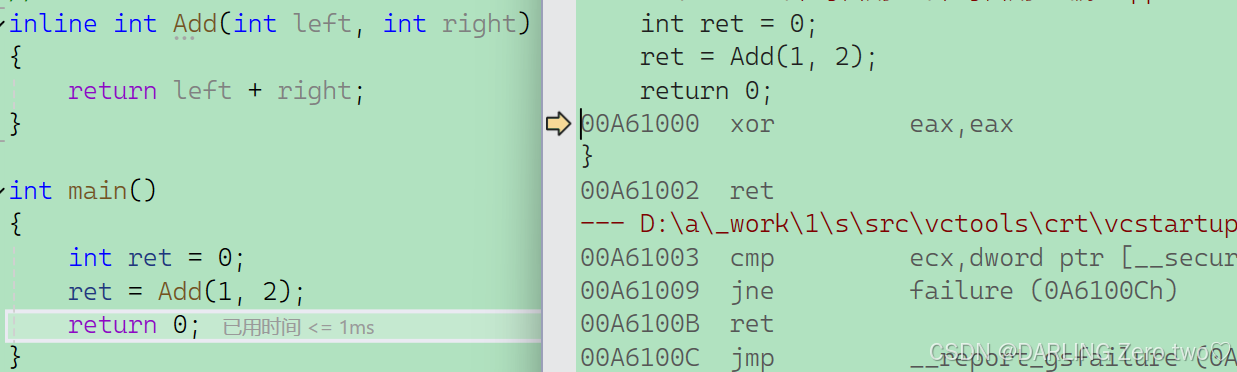
转到反汇编可以发现已经没有 call 指令的生成了,说明内联函数不是调用的,而是在原来要使用的地方展开的,总的来说内联函数是一种用空间换时间的函数
内联函数查看方法:在 debug 模式下,需要对编译器进行设置,否则不会展开,因为debug 模式下,编译器默认不会对代码进行优化,要方便调试,所以要在 release 模式下运行
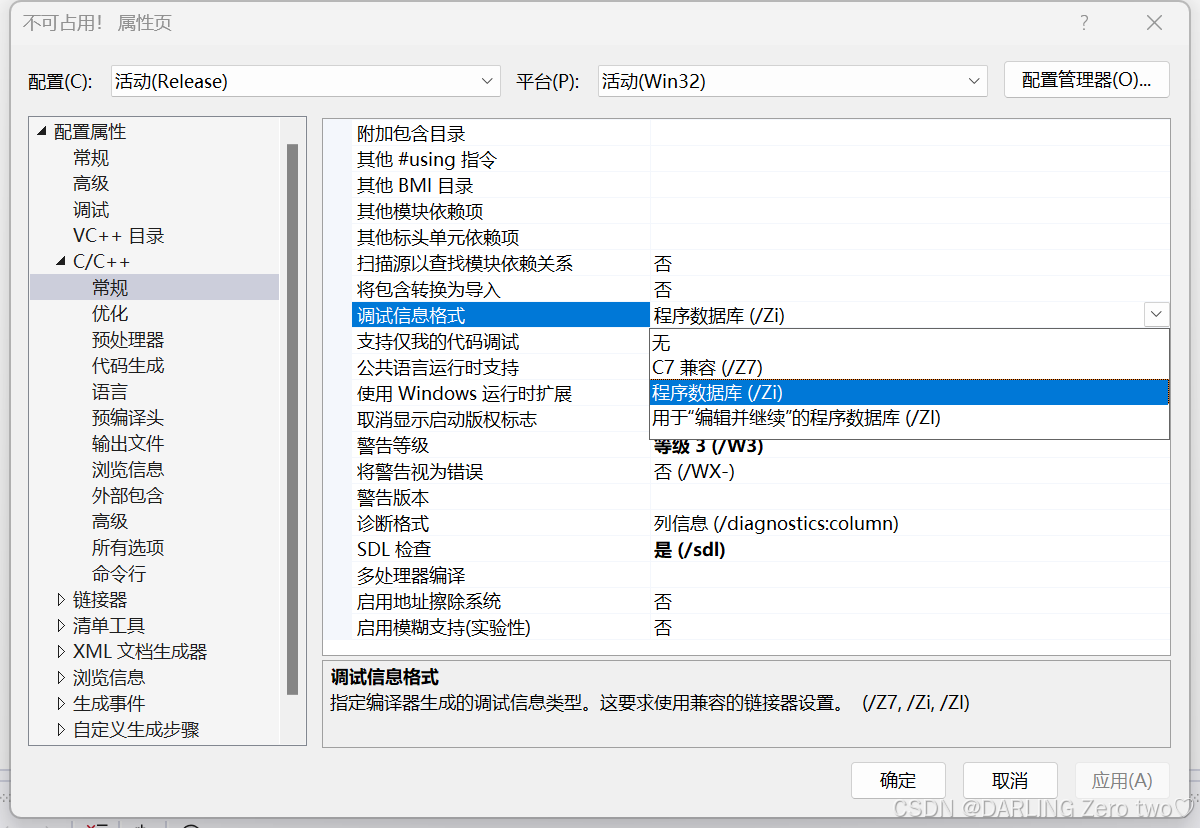
打开项目属性界面,调试信息格式中选用程序数据库
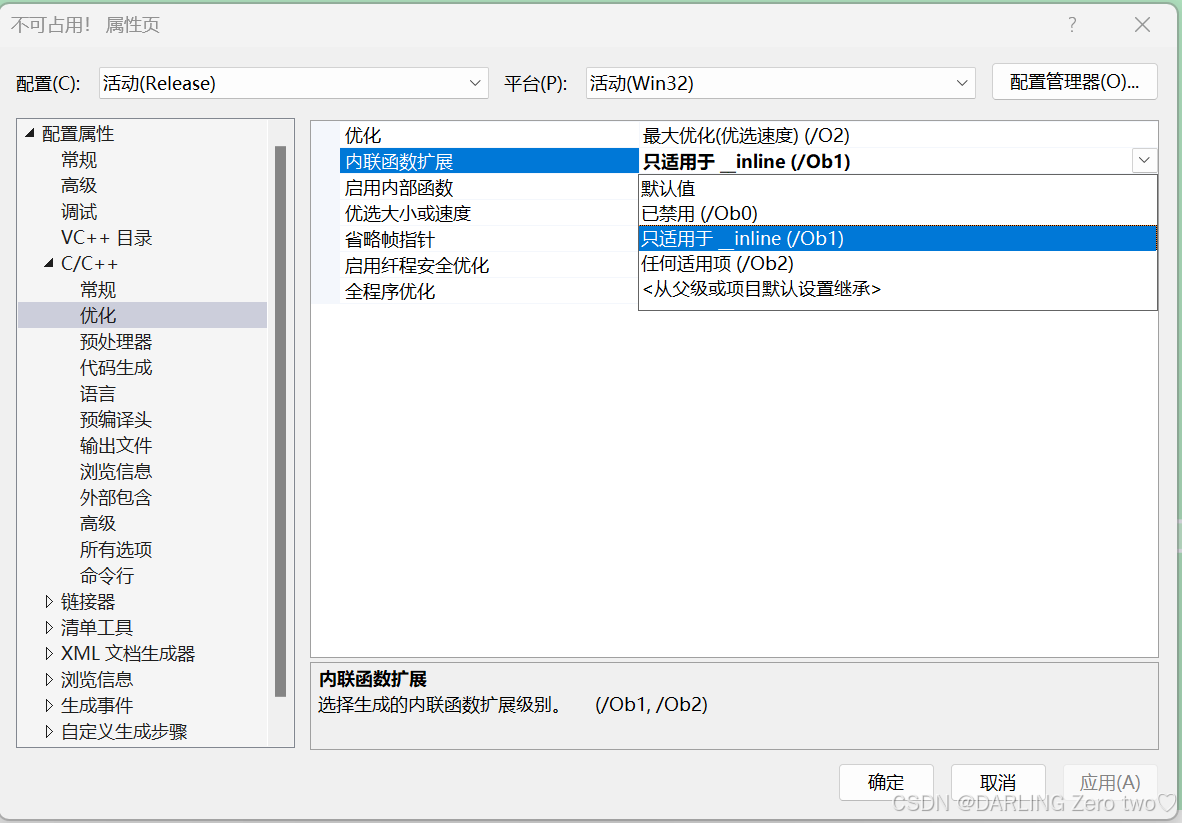
内联函数扩展选用只适用于 _inline(/Ob1),再选择应用就行了
3.3.2 内联函数的特性
?1. 内联函数适用于短小且频繁调用的函数
?2. inline 对于编译器只是个建议,最终是否成为内联函数,编译器自己决定
?3. 比较长的函数、递归函数等类似的函数即使加了 inline 也会被编译器否决
?4. inline 不建议声明和定义分离,分离会导致链接错误,因为 inline 被展开,就没有函数地址了,链接就会找不到
?5. 内联函数可以替换宏的短小函数定义
希望读者们多多三连支持
小编会继续更新
你们的鼓励就是我前进的动力!
