文章目录
R语言预备知识获取工作目录设置工作目录注释变量名的命名赋值变量的显示查看与清除变量函数帮助文档查询函数安装R包文件的读取文件的输出软件的退出与保存 R语言语法向量向量的创建向量的索引(向量元素的提取、删除、添加)向量长度的获取向量的注意要点向量的计算向量的相关函数(部分)NA与NULL值向量元素的筛选向量相等数据结构的查看控制语句 矩阵矩阵的创建矩阵的索引矩阵相关操作及相关函数(部分)apply()函数数据结构的查看 列表列表的创建声明列表标签或者对象名的命名删除标签列表元素的索引列表元素的增减获取标签解除列表列表相关函数(部分) 数据框数据框的创建数据框的索引数据框行列名的获取与更改数据框元素的增减数据框相关函数 因子和表因子的创建因子的索引因子的修改因子常用函数表 字符串字符串操作的常见函数正则表达式 数学运算与模拟R语言画图plot函数1.图片的保存2.par()函数图布局3.main :设置主标题,sub:副标题4.type,指线的类型5.pch : 指定绘制点时使用的符号6.`cex : 指定符号的大小,(默认是1)7.lty:指定绘制线条时的类型,lwd:指定线条粗细8.坐标轴标签9.坐标轴范围10.字体设置11.title()函数12.abline()函数添加线13.lines()函数在现有图形上添加线14.layout()函数图布局15.添加图例16.在图上添加文字17.R的撤销图片操作**`*****`****`*****`**
本文为生信初学者在学习完R语言后,整理的知识点及学习方法与个人观点,方便需要的同志学习,使用生信或其他医学相关专业,欢迎各位大佬进行指点批评,有错误或者有不同观点可在评论区留言。 更新时间2023年3月21号
声明:本文仅为学习笔记,和实例记录,可供参考。
本文知乎地址:R语言基础入门(学习笔记通俗易懂版)
建议使用CSDN,因为代码有高亮
软件工具:R与Rstudio,先安装R再安装Rstudio。软件工具不过多介绍,安装方法可以参考在CSDN上各大佬的方法。本文代码为Rstudio中R软件框中的(Rstudio左下角框的,如下图),代码与结果便于直观展示。(建议使用电脑浏览本文代码,因为部分代码好长)
R语言预备知识
获取工作目录
使用getwd()函数获取当前工作目录,作用是查看当前工作目录在哪一个具体位置,C盘或者是其他,第一次使用可能会出现警告,但是也可以看到工作目录,你可以在运行一次代码,如下:
> getwd()[1] "C:/Users/橙/Documents"Warning message:In normalizePath(path.expand(path), winslash, mustWork) : path[1]="C:/Users/?/Documents": 文件名、目录名或卷标语法不正确。> getwd()[1] "C:/Users/橙/Documents"设置工作目录
使用setwd()函数更改当前目录,把工作目录更改到你存放你需要使用的数据包的那个位置,更便于直接重工作目录中读取,否者需要使用全路径。在使用函数是需要几点注意,请看以下代码:
> setwd("F:\R.cx")#工作目录的地址需要用双引号括起来,注意斜杠,这种单斜杠会报错Error: '\R' is an unrecognized escape in character string starting ""F:\R"> setwd("F:/R.cx")#这种单斜杠可以,能运行> setwd("F://R.cx")#这行与下一行的双斜杠都行> setwd("F:\\R.cx")> 注释
R语言的注释使用#号,写代码一定要常写注释,不然时间久了会忘记某代码的作用,便于后续操作。在Rstudio中可以使用Ctrl+shift+C经行多行注释。
变量名的命名
与其他语言的变量名命名差不多,主要要注意:数字不能开头;%号是非法字符,不可以用来命名;.号后面不可以跟数字;不可以下划线开头。变量名可以为与你操作相关的名字命名,如我要对一行身高的数据求均值:
higth<-c(175,169,179,175,180,183)higth_mean<-mean(higth)#对身高求均值赋值
R语言的赋值方式与其他语言有点区别,有三种,分别是左箭头<-(<键+-键(等号左边的那个,不要按Shift)),等号=,右箭头->,如:
> a<-2> b=3> c->4 #注意右箭头使用方法,被赋值的应该在右边,简单点说,就是某某赋值给谁,箭头就指向谁Error in 4 <- c : invalid (do_set) left-hand side to assignment> 4->c> a #键盘敲出变量名,回车后就会显示结果[1] 2> b[1] 3> c[1] 4> 变量的显示
1.命令行直接输入变量名
2.利用print()函数,如下
> a<-2> a #命令行直接输入变量名[1] 2> print(a) #利用print()函数[1] 2查看与清除变量
查看变量:ls()
清除指定变量:rm()
清除所有变量:rm(list=ls()) 如下:
> ls() #查看变量,这个函数是查看所有已定义的变量,输出所有变量名[1] "a" "b" "c"> rm(a) #清除变量a> rm(list=ls()) #清除所有变量函数帮助文档查询
当遇到一个函数不会用时,可以使用帮助文档查询,结果会在Rstudio的右下角框里显示,方法有三种:
1.?+要查询的函数
2.使用help()函数查询
3.使用example()函数查询
我以求和函数sum()为例:
> ?sum> help(sum)> example(sum)函数
R中含有大量的函数,比如求和函数sum(),求均值mean()等直接可以拿来使用的函数,但是往往在实际操作过程中,因为需求不同需要自己写函数,就是自定义函数,类似于C或C++中的自定义函数,我们来看一下R中如何自定义函数,请看如下代码:
> #函数名<-function(){·······}> f<-function(a,b) #写一个求和函数,function()是固定格式+ {+ k<-a+b+ return(k) #返回结果为k,如果没有设置返回值,则函数会返回最后一行执行的结果+ }> f(3,4)#使用函数名加一个括号调用函数[1] 7注:函数可以套函数使用
输出函数
print()函数,输出,与C语言中的printf()函数作用一样
> print(5)[1] 5安装R包
安装R包需要使用install.packages()或者BiocManager::install()函数安装,library()函数调用,以安装openxlsx为例,如下:
#安装R包代码如下
install.packages(“openxlsx”)
#或BiocManager::install(“openxlsx”)
library(openxlsx)
文件的读取
有多个函数可以读取文件,一下介绍几种常用的
scan()函数 scan(file = “”, what = double(), nmax = -1, n = -1, sep = “ ”),file=" " 的双引号里写文件地址,what写读入的数据类型,如果文件有好几种类型,可以啥也不写(what=" "),sep表示文件中数据的分隔符。举例如下
> #我桌面上有一个txt文件,数字、字符都有,元素间隔为空格> scan(file="C://Users//橙//Desktop//juli.txt",what=" ",sep=" ")Read 6 items[1] "1" "2" "2" "3" "你干嘛" [6] "!哎呦~"readline()函数 从键盘中读入一行数据,举例如下:
> duru2<-readline() Hello Worl> duru2[1] "Hello Worl"> duru3<-readline("请输入:") #请输入是提示语,可以自定义请输入:"喝,为什么不喝,他奈奈滴"> duru3[1] "\"喝,为什么不喝,他奈奈滴\""readLines()函数 可以一次性读取整个文件,可以限制读取的行数,举例如下:
> #返回结果会出现警告,原因是读取的文件每一行后(包括最后一行)必须包括换行符,我这个文件无> readLines("C://Users//橙//Desktop//juli.txt")[1] "1 2 2 3 你干嘛 !哎呦~" "我滴任务完成啦!" [3] "你坤哥厉不厉害!" Warning message:In readLines("C://Users//橙//Desktop//juli.txt") : incomplete final line found on 'C://Users//橙//Desktop//juli.txt'> #n=2表示读取前两行,因为第二行有换行符,所以不会出警告> readLines("C://Users//橙//Desktop//juli.txt",n=2)[1] "1 2 2 3 你干嘛 !哎呦~" "我滴任务完成啦!" read.table()函数 这个函数对于医学专业学生来讲,十分重要,主要用于读取矩阵数据框文件(可以读取.xlsx格式文件),
read.table(file, header = FALSE, sep = “”, quote = “”'",dec = “.”, numerals = c(“allow.loss”, “warn.loss”, “no.loss”),row.names, col.names, as.is = !stringsAsFactors,na.strings = “NA”, colClasses = NA, nrows = -1,skip = 0, check.names = TRUE, fill = !blank.lines.skip,strip.white = FALSE, blank.lines.skip = TRUE,comment.char = “#”,allowEscapes = FALSE, flush = FALSE,stringsAsFactors = FALSE,fileEncoding = “”, encoding = “unknown”, text, skipNul = FALSE)
| file | 文件名(包在" "内,或使用一个字符型变量),可能需要全部路径(注意即使是在Windows下,符号\也不允许包含在内,必须使用/替换),或者一个URL链接(http://···)(用UPL对文件远程访问) |
|---|---|
| header | 一个逻辑值(FALSE,TRUE),用来反映这个文件的第一行是否包含变量名 |
| sep | 文件中的字段分离符,例如对用制表符的文件使用sep=“\t” |
| quote | 指定用于包围字符型数据的字符 |
| dec | 用来表示小数点的字符 |
| row.names | 保存着行名的向量,或文件中的一个变量的序号或名字,缺省时行号取为1,2,3···· |
| col.names | 指定列名的字符型的向量(缺省值是:v1,v2,v3····) |
| as.is | 控制字符型向量是否转化为因子型变量(如果值为FALSE),或者仍将其保留为字符型(TRUE)。as.is可以是逻辑值,数值型或者字符型向量,用来判断变量是否保留为字符 |
| na.strings | 代表缺失数据的值(转化为NA) |
| colClasses | 指定各列的数据类型的一个字符型向量 |
| nrows | 可以读取的最大行数(忽略负值) |
| skip | 在读取行数据前跳过的行数 |
| check.names | 如果为TRUE,则检查变量名是否在R中有效 |
| fill | 如果为TRUE,且非所有的行中变量数目相同,则用空白补齐 |
| ··· | ··· |
read.xlsx()函数 读入.xlsx文件,使用该函数需要安装"openxlsx包"。
文件的输出
write.table()函数,参数与read.table()对应, > write("Hello,wrold","C://Users//橙//Desktop//juli.txt")> cat("hello wrold",file="C://Users//橙//Desktop//juli.txt",append=T)#追加写入,(里面有内容)> cat("hello wrold",file="C://Users//橙//Desktop//juli1.txt") #覆盖写入,里面的内容被覆盖了软件的退出与保存
1.可以直接输入q()函数;也可以右上角直接叉掉,后根据提示操作
2.当写完一个文件时,可以点击保存按钮,根据提示选择保存位置,文件后缀有多种,看你保存哪种文件,有.R、.Rdata等后缀,.R一般是保存代码的,.Rdata是保存处理后的数据的。
保存数据
可以使用**save()**函数,可以保存多种格式的文件
> save(b,file="xxx.Rdata") #保存b,文件是xxx,格式为.Rdata> save(b,c,file="xxx.Rdata") #保存b,c,文件是xxx,格式为.Rdata> save.image("xxx.Rdata") #保存所有(你定义的所有变量及数据),文件是xxx,格式为.RdataR语言语法
向量
向量(vector)是R语言的最基本的数据类型、R语言的核心、R语言中的战斗机 ,向量是用于存储数值型、字符型或逻辑型数据的一维结构。
向量的创建
1.可以使用c()创建一个向量,如:
> a<-c(1,2,3,4,5) #存储的数据是数值型,直接用逗号隔开> a<-c(1:5) #与第一行代码意思是一样的,因为是连续的,所以用1:5表示1到5的五个数> b<-c("R","Rstudio") #储存的是字符型数据,字符型的数据要加双引号> c<-c(TRUE,FALSE,T,F) #储存的数据是逻辑型的,TRUE与T是一样的,T是TRUE的简写,F是FALSE的简写2.可以用vector()函数建立一个空向量,如:
> d<-vector(length=10) #建立了一个名字为d的空向量,长度为10> d #我们看一下d里的内容,发现全部为FALSE,可以理解为空向量里值都为FALSE [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [9] FALSE FALSE向量的索引(向量元素的提取、删除、添加)
我们有一个向量后,我想知道里面第几个第几个的内容,我们可以使用中括号[]进行索引。如:
> a<-c(1,2,3,4,5) #我这里有一个向量a> a[2] #我查看a中第2个元素,返回结果为2[1] 2> a[4] #我查看a中第4个元素,返回结果是4[1] 4> a[c(1,3)] #我查看a中第1和第3个元素,可以使用向量的方式一次查看多个[1] 1 3> c<-c(TRUE,FALSE,T,F,F) #当然还有骚操作,这里有一个逻辑型向量c,我们试试用a索引它> a[c] #结果可以看到,返回的是TRUE对应位置的元素,这个操作我不知道教材上有没有,这是我意外摸索出来的[1] 1 3以上讲的是查看某元素,在实际中会遇到更改或删除某些元素
1.向量中元素的更改,直接进行索引赋值,如下
> a<-c(1,2,3,4,5) #这里有一个向量a,没错又是它,它又来了,这个阿婆主真没技术含量(叹气)> a[2]<-4 #a中第二个元素改为4> a #看一下a中的元素,唉~~,没错它变了(窃喜)[1] 1 4 3 4 5> a[c(1,5)]<-7 #我把a中的第1和第5改为7> a #再次看一下[1] 7 4 3 4 72.向量中元素的删除
上面讲到索引是用[],里面写上元素位置,位置是数字,正的!!!那么是负的会怎样呢???嗯!没错,负数
索引是查看删除那个位置后的结果,注意单纯的负索引出来的结果是没有改变原向量的,我们需要重新赋值,给它一个新的变量名(不用新的也行,但会把原来的覆盖掉),废话不多说,直接看如下代码:
> a #没错,又用了上面个那个向量a,up真没创意(梆梆给阿婆主两拳)[1] 7 4 3 4 7>> a[-2] #我负索引以下第2个位置,返回的结果与a的区别是,把第2位删掉了[1] 7 3 4 7> a #我们在看一下a,返回结果尽然没有把第2为删掉,那怎么办??那就给他一个新的名字吧![1] 7 4 3 4 7>> e<-a[-2] #既然a[-2]返回的结果是我需要的,那么直接给他一个新名字吧,让一个东西去接收它> e #上面我们用了e去接受我们需要的,我们看一下是否赋值到了,运行这行代码后发现结果是我想要的[1] 7 3 4 7>> a<-a[-2] #为啥要重新弄个新的变量名呢?用a不可以吗?肯定可以呀!俺敲着这行代码试一下(自信)> a #查看一下a,对的是我想要的(满意)······(十分钟后)我原本的a呢?啊~~,救命,被我覆盖掉了(螺旋升天)[1] 7 3 4 7 #所以不要轻易覆盖掉原来的变量,万一后面要用到呢?>> #升级以下,看看能不能用向量一次性多删几个> a<-c(1,2,3,4,5) #这里我又用了原向量a,上面的向量a太短了> f1<-a[c(-1,-3)] > f1 #结果是可以的[1] 2 4 5> f2<-a[-c(1,3)] #上面f1是把负号放在向量里面,放外面其实也是可以的耶!> f2[1] 2 4 5>> #突发奇想,如果a[],中括号里面的向量里面与外面都有负号呢?试一试!> f3<-a[-c(-1,-3)] > f3 #f3的结果显示第1位与第3位的元素,嗯~~,那就可以理解为负负得正,直接把a中的第1和3位赋值给f3[1] 1 3> f4<-a[-c(-1,3)] #脑子抽风了,这种行不行呢?哈!!!!它报错,对的报错了,那就不可以咯!Error in a[-c(-1, 3)] : only 0's may be mixed with negative subscripts3.向量元素的添加
上面我们提到了向量元素的索引与元素的删除,那能不能加元素进去呢??答案肯定是能得,那么如何加入元素呢?这就要用到向量的素引了,看如下代码与注释:
> a<-1:5 #这里有一个向量a,我想在第2与第3个位置上加上一个元素6,如下> g1<-c(a[1:2],6,a[3:5]) #这中方法结果是可行的,可以理解为,把a分为两部分,中间插一个6> g1[1] 1 2 6 3 4 5> g2<-c(a[1:2],7,9,10,a[3:5]) #多插如几个都是可以的> g2[1] 1 2 7 9 10 3 4 5> #当然比较短的向量就可以重新写一个,但是如果有几万个,上面的方法是很不错的向量长度的获取
我有一个非常长的向量,我并不知道它的长度,我们可以使用length()函数获取向量长度,如下代码:
> a1<-99:10058 > length(a1) #运行函数后返回了向量a1的长度[1] 9960向量的注意要点
向量在使用之前需要进行声明,声明主要有两种:
1.变量名<-c(········);变量名与向量元素同时确定,如:
a<-c(1,2,4,5,7,8) #使用了c(····)的形式,a就默认为一个向量2.直接创建一个空向量,后赋值,如:
> b<-vector(length=5) #建立一个名字为b,长度为5的空向量> b[3]<-6 #第3位元素赋值为6> b #查看结果,可以看到第三位是6,其他为0,因为之前提到过,空向量里的值都为FALSE[1] 0 0 6 0 0 #当里面出现数值时,其他位置的FALSE变为数字0还需注意向量元素的类型
如何判断一个变量类型呢?我们可以使用mode()函数查看变量类型,或者使用typeof()函数
1.当向量元素同时含有数值与字符型时,返回的结果为字符型,数值型转变为了字符型,在后续处理数据时需要注意,只要出现了字符型元素,则此向量应当作字符型向量处理,如下:
> c<-c(1,3,"ABC") > mode(c) #查看一下c是什么类型的数据,返回结果是字符型[1] "character"> c [1] "1" "3" "ABC"2.当向量元素同时含有数值型与逻辑型时,返回结果为数值型,逻辑性转变为数值型,其中FALSE转变为0,TRUE转变为1。如:
> c1<-c(1,5,FALSE,TRUE)> mode(c1) #查看一下c是什么类型的数据,返回结果是数值型[1] "numeric"> c1[1] 1 5 0 13.当向量同时含有数值型、逻辑型与字符型时,全部转变为字符型,如:
> c2<-c(1,5,FALSE,TRUE,"ABC")> mode(c2) #查看一下c2是什么类型的数据,返回结果是字符型[1] "character"> c2[1] "1" "5" "FALSE" "TRUE" "ABC" 总结:逻辑性可以转化为数值型与字符型,数值型可以转化为字符型,注意:字符型不可以转换为逻辑与数值型, as.数据类型()可以进行强制转换,如下
> c1<-c(1,5,FALSE,TRUE)> as.character(c1) #将c1强制转换为字符型[1] "1" "5" "0" "1"> as.numeric(c1) #将c1强制转换为数值型[1] 1 5 0 1向量的计算
1.向量的循环补齐,使用向量相加的例子举例,(相加与相减类似)如:
> c(3,4)+c(8,9) #8+3=11,9+4=13,这是两个向量长度相同的[1] 11 13> c(2,4)+c(2,3,4,5,6) #2+2,3+4,4+2,5+4,6+2,能算,但长度不相同的会出现警告[1] 4 7 6 9 8Warning message:In c(2, 4) + c(2, 3, 4, 5, 6) : longer object length is not a multiple of shorter object length2.向量相乘,使用*号。长度相同时,两向量对应元素相乘,但长度不同时会出现警告,会使用向量循环补齐的方式计算,如下:
> c(1,3)*c(3,5) #长度相同,对应元素相乘,3×1,5×3[1] 3 15> c(1,3,5)*c(2,4,7,8,10) #长度不同,补齐方式计算,2×1,4×3,7×5,8×1,10×3[1] 2 12 35 8 30Warning message:In c(1, 3, 5) * c(2, 4, 7, 8,10) : longer object length is not a multiple of shorter object length3.向量取余使用%%,长度相同时,对应元素取余,长度不同时,出现警告,循环补齐式取余,请看如下代码:
> c(1,3)%%c(5,9) #1÷5余1,3÷9余3,长度相同,对应元素取余[1] 1 3> c(5,9)%%c(1,3) #5÷1余0,9÷3余0,长度相同,对应元素取余[1] 0 0> c(1,3,10)%%c(2,4,5,8,3) #长度不同,1÷2余1,3÷4余3,10÷5余0,1÷8余1,3÷3余0[1] 1 3 0 1 0Warning message:In c(1, 3, 10)%%c(2, 4, 5, 8, 3) : longer object length is not a multiple of shorter object length向量的相关函数(部分)
与向量相关的函数有很多,不一一介绍,介绍几个比较简单常用的
1.seq()函数
seq(from,to,by=), 从什么到什么,间隔(by)为多少,(等差数列,公差就是by的值)
seq(from,to,length.out=),从什么到什么,长度为多少;详情看如下代码:
> seq(from=3,to=12,by=3) #从3到12,间隔(公差)为3[1] 3 6 9 12> seq(3,12,3) #from,to by 可以不写,默认[1] 3 6 9 12> seq(from=3,to=12,length.out=6) #从3到12,长度为6[1] 3.0 4.8 6.6 8.4 10.2 12.02.rep() 函数
rep(x,time),x重复time次,rep是重复repeat的简写
rep(x,each),每个连续重复each次,详情如下:
> x<-c(1,3) > rep(x,time=2) #重复两次整体x[1] 1 3 1 3> rep(x,each=2) #x里的元素每一个重复两次[1] 1 1 3 3> rep(x,2) #既不写time也不写each,默认为time[1] 1 3 1 33.all()、any() 与match()函数
all(),判断元素是否都符合条件,返回逻辑值 ,只要有一个不满足,返回FALSE,看如下代码:
ang(),判断是否有元素满足条件,返回逻辑值,只要有一个满足,返回TRUE,如下代码:
> a #我用向量a举例子[1] 1 2 3 4 5> all(a>0) #判断a里的元素是否都大于0,返回了TRUE[1] TRUE> all(a>3) #判断a里的元素是否都大于3,返回了FALSE[1] FALSE> any(a>4) #判断a中是否有大于4的元素,返回了TRUE[1] TRUE> any(a>6) #判断a中是否有大于6的元素,返回了FALSE[1] FALSEmatch(),意为匹配的意思,例如:match(A,B),判断向量A的元素在向量B里是否有,若有则返回在B中的位置,若没有,则返回NA;两向量长度不等时,循环补齐时判断,要注意时哪一个向量要循环,请看如下代码:
> match(c(1,4,5),c(2,4,3)) #两向量长度相同,第二个是相同的,返回相同的位置,其他返回NA[1] NA 2 NA> match(c(1,4,5),c(2,4)) #长度不等,1与2判断,4与4判断,5与2判断[1] NA 2 NA> match(c(1,4),c(2,4,3)) #长度不等,1与2判断,4与4判断,第一个元素都判断完了,直接结束,返回结果[1] NA 2> match(c(1,4,5,6,2,4),c(2,4)) [1] NA 2 NA NA 1 2NA与NULL值
NA表示存在但未知的数,NULL代表不存在的数
当数据中存在NA值是,要么删掉,但可能会让结果有偏差(尤其是在做科研时处理较大的数据时慎重考虑),要么给它一个这组数据的平均数或者是其他,看你处理什么数据与看你的需求。
NULL还有其他用法,比如在循环中创建一个向量,便于存数据。
举例如下:
> mean(c(3,5,7,9,NA)) #存在NA值,无法确定NA值的大小,返回结果也未知[1] NA> mean(c(3,5,7,9,NA),na.rm=T) #把NA值删掉[1] 6> mean(c(3,5,7,9,NULL)) #NULL值根本不存在,不影响结果[1] 6向量元素的筛选
以下举例几个常用函数
1.which()函数
which() 返回满足条件元素的位置,注意是返回位置,如:
> a<-c(1,5,7,4,9)> which(a==4) #返回a等于4的元素的位置,位置为4[1] 4> which(a>5) #返回a大于5的元素的位置,第3与第5是大于5的[1] 3 52.subset()函数
subset() 函数是返回符合条件的元素,但会忽略NA值。注意:条件应为逻辑值,否则会报错,详情看如下代码:
> x<-c(1,3,7,NA,10) #一个含有NA值的向量> x[x>6] #用向量的索引查看一下x>6的元素[1] 7 NA 10> subset(x,x>6) #筛选x>6的元素,可以注意到它忽略了NA值,x>6可以理解为一个逻辑向量[1] 7 103.ifelse()函数
ifelse(x,a,b) 函数判断元素x是否符合条件,如符合,返回a,若不符合,返回b。其中x为逻辑值, 如:
> X<-1:10 > Y<-ifelse(X%%2==0,1,0) #如果为偶数,返回1,奇数,返回0> Y [1] 0 1 0 1 0 1 0 1 0 1进阶
> temp0<-sample(c(5,6),50,replace=T) #我用sample函数随机生成一个长度为50,元素只有5与6,随机生成> temp0 #看一下temp0 [1] 6 5 6 5 6 5 5 6 6 6 5 6 5 5 5 6 5 6 6 6 5 6 5 6 5[26] 6 6 6 6 5 5 5 6 5 6 5 6 5 5 6 5 5 6 6 6 6 5 6 5 5> #我想计算一下temp0中数字5出现的次数,有多种方法> #方法一> temp1<-ifelse(temp0==5,1,0) #我让为5的等于1,不为5的等于0,> sum(temp1) #求和一下,结果就为temp0中5的个数[1] 24>> #方法二> temp2<-temp0 #temp2等于temp0,防止temp0数据被更改> temp2[temp2==5]<-1 #让元素为5的等于1> temp2[temp2==6]<-0 #让元素为6的等于0> sum(temp2) #求和,就是5的个数[1] 24>> #方法三> temp3<-which(temp0==5) #找向量temp0中为5的位置,并用一个向量接受它> length(temp3) #在算temp3的长度[1] 24> length(which(temp0==5)) #还能简化一下上两行的代码,直接出向量temp0中为5的元素个数[1] 24>> #方法多种多样,只要能出正确结果的方法都能,只是代码复杂度的问题,我不再一一列举,各位有兴趣可以自行探索向量相等
有多种方法可以判断两向量是否相等
1.all()函数 ,返回逻辑值
2.identical()函数,判断两向量是否相等,返回逻辑值
3.自定义函数,(自己写一个函数判断)
all()函数与identical()使用及两者区别直接请看如下代码:
> d1<-c(1,5,7,9)> d2<-c(1,5,7,9)> d3<-c(2,4,7,9)> d4<-1:5> d5<-c(1,2,3,4,5)> all(d1,d2) #判断d1与d2是否相等,返回了TRUE,但是出现了警告[1] TRUEWarning messages:1: In all(d1, d2) : coercing argument of type 'double' to logical2: In all(d1, d2) : coercing argument of type 'double' to logical> all(d1,d3) #判断d1与d3是否相等,返回了TRUE,但是出现了警告[1] TRUEWarning messages:1: In all(d1, d3) : coercing argument of type 'double' to logical2: In all(d1, d3) : coercing argument of type 'double' to logical> identical(d1,d2) #判断d1与d2是否相等,返回了TRUE[1] TRUE> identical(d1,d3) #判断d1与d3是否相等,返回了FALSE[1] FALSE> all(d4,d5) #判断d4与d5是否相等,返回了TRUE,但是出现了警告[1] TRUEWarning message:In all(d4, d5) : coercing argument of type 'double' to logical> identical(d4,d5) #判断d4与d5是否相等,返回了FALSE[1] FALSE>> #在对比d4与d5时,all与identical出现了不同的结果,虽然内容相同,但是定义向量的方式不同,有区别,> #这是all与identcal的主要区别。数据结构的查看
上面一部分,我们了解了R含有向量的数据结构,当然还有其他数据结构,比如矩阵、数据框、列表等,我们可以使用class(),
控制语句
ifelse()函数,iflese(x,a,b),如果x为TRUE,则执行a,否者执行b
for(i in x){·········},i在循环会取遍x中的值,例如:
> for(i in c(1,5,7)) # i 在1,5,7中从左到右依次取+ {+ print(i^2)+ }[1] 1[1] 25[1] 49next与break
next在for中表示继续循环,break表示跳出循环,例如:
> for(i in c(1,5,7))+ {+ ifelse(i<=5,print(i^2),next)+ }[1] 1[1] 25> for(i in c(1,5,7,8))+ {+ ifelse(i<=7,print(i^2),break)+ }[1] 1[1] 25[1] 49while()函数 和C语言用法一样,当括号里条件为TRUE时,执行语句
> a<-3> while(a==3)+ {+ print(a+1)+ a<-FALSE+ }[1] 4repeat()函数 意为重复,搭配if、break使用,不用break跳出程序将陷入死循环
repeat{ a<-a+1 if(a>7) { break }}if(···){···}else{···}语句 特别注意else必须跟在第一个大括号后面,否则报错,举例如下:
> for(i in c(1,2,3,4,5))+ {+ if(i<=3)+ {+ print(i^2)+ }else #else必须跟在第一个大括号后面+ {+ print(i^3)+ }+ }[1] 1[1] 4[1] 9[1] 64[1] 125逻辑运算符 和C语言差不多,&&表示与,||表示或,!表示非
函数返回值 1.利用return返回结果
2.如果没有return则返回语句最后一行执行的结果,举例如下:
> F<-function(a)+ {+ k<-a+ return(k)+ }> F(3) #利用return返回结果[1] 3> F1<-function(a,b)+ {+ d<-a-b+ c<-a+b+ c+ }> F1(5,2) #返回最后执行的语句值[1] 7如果学过C语言好理解;如果没学过,可以把全局变量理解为在函数内部无法改变的变量,局部变量就是在函数内部的变量,具有临时性。如:
> b<-5 #全局变量> f3<-function(x)+ {+ b<-7 #这个并没有改变外面那个b+ b1<-x #局部变量,在函数外访问不到,函数返回结果后被删除+ b2<-b+b1+ return(b2)+ }> f3(9)[1] 16> b #b没有发生变化[1] 5> b1 #在函数中是局部变量,函数返回结果后被删除,所以无法找到Error: object 'b1' not found矩阵
矩阵(matrix) 是一种特殊的向量,包含两个附加的属性:行数和列数,R生存矩阵时按列存储。
注意向量不能看成只有1列或1行的矩阵
矩阵的创建
1.利用函数matrix()函数
matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE,dimnames = NULL);其中data表示要处理的数据(向量),nrow表示行,ncol表示列,byrow表示是否按行排列,默认是列排,dimnames表示行与列的名字,默认是没有,要使用列表设置。如下代码:
> mydata<-matrix(c(1,2,3,4,5,6),nrow=2,ncol=3) #两行三列,默认按列排> mydata [,1] [,2] [,3][1,] 1 3 5[2,] 2 4 6> mydata1<-matrix(c(1,2,3,4,5,6),nrow=2,ncol=3,byrow=T) #两行三列,按行排> mydata1 [,1] [,2] [,3][1,] 1 2 3[2,] 4 5 6> mydata3<—matrix(c(1,2,3,4,5,6),nrow=2,ncol=3,dimnames=list(c("r1","r2"),c("c1","c2","c3")))> mydata3 #设置了名字,名字要用列表list形式,如上一行代码 c1 c2 c3r1 1 3 5r2 2 4 62.利用函数将向量接起来,函数有rbind()按行接起来、cbind()按列接起来,例子代码如下:
> mydata5<-rbind(c(1,2,3),c(4,5,6)) #按行将两个向量接起来,形成矩阵> mydata5 [,1] [,2] [,3][1,] 1 2 3[2,] 4 5 6> mydata6<-cbind(c(1,2,3),c(4,5,6)) #按列将两个向量接起来,形成矩阵> mydata6 [,1] [,2][1,] 1 4[2,] 2 5[3,] 3 63.强制转换为矩阵
利用as.matrix()函数强制转换为矩阵,如:
> a<-c(1,2,3,4,5,6,7,8)> a1<-as.matrix(a) #强制转换为矩阵,但是只有一列> a1 [,1][1,] 1[2,] 2[3,] 3[4,] 4[5,] 5[6,] 6[7,] 7[8,] 84.建立一个空矩阵
直接写行列大小,如下:
> d<-matrix(nrow=3,ncol=2) #建立一个3行2列的空矩阵,内容为NA,存在但未知> d [,1] [,2][1,] NA NA[2,] NA NA[3,] NA NA注意事项
当两个向量长度不相等时,会出现警告,长度不等的那个向量会用循环补齐的形式填补,如下:
> mydata7<-cbind(c(1,2,3,4,5),c(4,5)) #后一个向量短,出现警告,后面循环补上Warning message:In cbind(c(1, 2, 3, 4, 5), c(4, 5)) : number of rows of result is not a multiple of vector length (arg 2)> mydata7 [,1] [,2][1,] 1 4[2,] 2 5[3,] 3 4[4,] 4 5[5,] 5 4> mydata8<-cbind(c(1,2),c(4,5,6,7,8)) #前面一个短,出现警告,前一个循环补齐Warning message:In cbind(c(1, 2), c(4, 5, 6, 7, 8)) : number of rows of result is not a multiple of vector length (arg 1)> mydata8 [,1] [,2][1,] 1 4[2,] 2 5[3,] 1 6[4,] 2 7[5,] 1 8当向量中含有不同类型的数据时,会改变元素类型后转变为矩阵,如下:
> mydata10<-matrix(c(2,5,FALSE,TRUE),2,2) #向量含有逻辑与数值型,逻辑转为数值,2行2列按列排> mydata10 [,1] [,2][1,] 2 0[2,] 5 1> #向量含有逻辑,字符与数值型,全部转为字符,2行3列按列排> mydata9<-matrix(c(1,3,FALSE,TRUE,"ABC","babiQ"),2,3) > mydata9 [,1] [,2] [,3] [1,] "1" "FALSE" "ABC" [2,] "3" "TRUE" "babiQ"矩阵的索引
使用下标和中括号来选择矩阵中的行或列或元素,矩阵名+中括号,中括号里面写需要的行与列
我有一个矩阵,名字为mymatrix,5行5列,如下:
> mymatrix<-matrix(c(1:25),5,5)> mymatrix [,1] [,2] [,3] [,4] [,5][1,] 1 6 11 16 21[2,] 2 7 12 17 22[3,] 3 8 13 18 23[4,] 4 9 14 19 24[5,] 5 10 15 20 25矩阵每一行前或列首都有一个中括号括起来的,可以理解为这一行或列
1.mymartix[i,],返回矩阵mymatrix中第i行元素,如:
> mymatrix[3,] #返回第三行元素[1] 3 8 13 18 232.mymartix[,j],返回矩阵mymatrix中第j列元素,如:
> mymatrix[,5] #返回第5列元素[1] 21 22 23 24 253.mymartix[i,j],返回矩阵mymatrix中第i行第j列元素,如:
> mymatrix[2,2] #返回第2行第2列元素 [1] 74.mymatrix[i,-j],返回第i行,但排除第j列元素,如:
> mymatrix[2,-3] #返回第2行,但排除第3列元素[1] 2 7 17 225.mymatrix[-i,j],返回第j列,但排除第i行元素,如:
> mymatrix[-3,2] #返回第2列,但排除第3行元素[1] 6 7 9 106.mymatrix[c(m,n),c(p,k)],返回第m和n行,第p和k列元素,如:
> mymatrix[c(1,3),c(3,5)] #返回第1和3行,第3和5列元素 [,1] [,2][1,] 11 21[2,] 13 237.mymatrix[-c(m,n),c(p,k)],返回第p和k列,但排除第m和n行元素,如:
> mymatrix[-c(1,3),c(3,5)] #返回第3和5列,但排除第1和3行元素 [,1] [,2][1,] 12 22[2,] 14 24[3,] 15 258.当矩阵有行列名时,可以通过行与列名进行提取元素,如:
> mymatrix3#这里有一个矩阵 c1 c2 c3 c4 c5 行均值 r1 1 6 11 16 21 11r2 2 7 12 17 22 12r3 3 8 13 18 23 13r4 4 9 14 19 24 14r5 5 10 15 20 25 15列均值 3 8 13 18 23 NA> mymatrix3["r1","c2"]#返回列名c2,行名为r1的元素[1] 6> mymatrix3[c("r2","r4"),c("c3","c5")]#返回行名为r2与r4,列名为c3与c5的元素 c3 c5r2 12 22r4 14 24drop处理意外降维
上面矩阵的引用1~5条,从一个矩阵中提取的结果都为向量,如果说,我取一行或一列后返回结果要求是矩阵,虽然说可以先取后转变为矩阵,但相对还是麻烦了,我们可以加入drop防止降维,如:
> mymatrix<-matrix(c(1:25),5,5)> mymatrix[2,] #直接取就会降维为向量[1] 2 7 12 17 22> mymatrix[2,,drop=F] #如果要求取出是矩阵,则加入drop=F [,1] [,2] [,3] [,4] [,5][1,] 2 7 12 17 22矩阵相关操作及相关函数(部分)
1.转置,函数t(),如:
> mymatrix<-matrix(c(1:25),5,5) #我这里有一个矩阵> mymatrix [,1] [,2] [,3] [,4] [,5][1,] 1 6 11 16 21[2,] 2 7 12 17 22[3,] 3 8 13 18 23[4,] 4 9 14 19 24[5,] 5 10 15 20 25> mymatrix1<-t(mymatrix) #对函数进行转置,返回结果如下> mymatrix1 [,1] [,2] [,3] [,4] [,5][1,] 1 2 3 4 5[2,] 6 7 8 9 10[3,] 11 12 13 14 15[4,] 16 17 18 19 20[5,] 21 22 23 24 252.横向或纵向合并矩阵
cbind()函数横向合并矩阵
rbind()函数纵向合并矩阵,举例如下:
> M<-matrix(c(1,2,3,4),2,2) > N<-matrix(c(5,6,7,8),2,2) #建立了两个矩阵M,N,如下> M [,1] [,2][1,] 1 3[2,] 2 4> N [,1] [,2][1,] 5 7[2,] 6 8> cbind(M,N)#横向合并矩阵M,N [,1] [,2] [,3] [,4][1,] 1 3 5 7[2,] 2 4 6 8> rbind(M,N)#纵向合并矩阵M,N [,1] [,2][1,] 1 3[2,] 2 4[3,] 5 7[4,] 6 83.对各列或行求和或求均值
colSums()对各列求和,rowSums()对各行求和
colMeans()对各列求均值,rowMeans()对各行求均值,举例如下:
> mymatrix#以这个矩阵举例 [,1] [,2] [,3] [,4] [,5][1,] 1 6 11 16 21[2,] 2 7 12 17 22[3,] 3 8 13 18 23[4,] 4 9 14 19 24[5,] 5 10 15 20 25> colSums(mymatrix)#对各列求和[1] 15 40 65 90 115> rowSums(mymatrix)#对各行求和[1] 55 60 65 70 75> colMeans(mymatrix)#对各列求均值[1] 3 8 13 18 23> rowMeans(mymatrix)#对各行求均值[1] 11 12 13 14 154.计算行列式
det()函数,计算行列式,举例如下:
> M [,1] [,2][1,] 1 3[2,] 2 4> det(M)[1] -25.矩阵相乘
使用%*%进行矩阵相乘,举例如下:
> M [,1] [,2][1,] 1 3[2,] 2 4> N [,1] [,2][1,] 5 7[2,] 6 8> K<-M%*%N#两矩阵相乘> K [,1] [,2][1,] 23 31[2,] 34 466.设置行列名
设置行列名有三种以上方式,这里介绍三种常用的
在创建矩阵时设置行列名,如 > #使用dimnames,以列表的形式设置行列名 > fa<-matrix(c(2,3,4,5),2,2,dimnames =list(c("第一行","第二行"),c("第一列","第二列"))) > fa 第一列 第二列 第一行 2 4 第二行 3 5dimnames()函数设置行列名 > fa1<-matrix(c(6,7,8,9),2,2) #矩阵原先未设置行列名 > a<-c("第一行","第二行") > b<-c("第一列","第二列") > dimnames(fa1)<-list(a,b) #使用dimnames函数设置行列名 > fa1 第一列 第二列 第一行 6 8 第二行 7 9rownames()设置行名,使用colnames()设置列名 > fa2<-matrix(c(1,3,5,7),2,2) #行列未命名的矩阵> rownames(fa2)<-c("A1","A2") #对行命名> colnames(fa2)<-c("B1","B2")#对列命名> fa2 B1 B2A1 1 5A2 3 7apply()函数
apply(m,dimcode,f,fargs) 允许用户在各行各列调用函数
m 矩阵,dimcode 1代表行, 2代表列,f函数,frags可选参数,函数大于一个参考时使用用“,”隔开。
> mymatrix<-matrix(c(1:25),5,5)#建立了一个矩阵> mymatrix [,1] [,2] [,3] [,4] [,5][1,] 1 6 11 16 21[2,] 2 7 12 17 22[3,] 3 8 13 18 23[4,] 4 9 14 19 24[5,] 5 10 15 20 25> > mymatrix_rowmean<-apply(mymatrix,1,mean) #对行求均值> mymatrix_colmean<-apply(mymatrix,2,mean) #队列求均值> mymatrix_rowmean1<-matrix(mymatrix_rowmean,length(mymatrix_rowmean),1) #转换为一列的矩阵> mymatrix_colmean1<-matrix(mymatrix_colmean,1,length(mymatrix_colmean)) #转换为一行的矩阵> mymatrix_colmean1[6]<-NA #矩阵右下角有个空,用NA值填一下,方便连接> mymatrix2<-cbind(mymatrix,mymatrix_rowmean1) #按列把两个矩阵接起来> mymatrix3<-rbind(mymatrix2,mymatrix_colmean1) #按列把两个矩阵接起来> a<-c("r1","r2","r3","r4","r5","列均值")> b<-c("c1","c2","c3","c4","c5","行均值")> dimnames(mymatrix3)<-list(a,b) #设置行列名> mymatrix3#展示结果 c1 c2 c3 c4 c5 行均值r1 1 6 11 16 21 11r2 2 7 12 17 22 12r3 3 8 13 18 23 13r4 4 9 14 19 24 14r5 5 10 15 20 25 15列均值 3 8 13 18 23 NA数据结构的查看
上面一部分,我们了解了R含有向量,矩阵数据结构,当然还有其他数据结构,比如数据框、列表等,我们可以使用class(),如:
> mymatrix<-matrix(c(1:25),5,5) > class(mymatrix)[1] "matrix" "array" > a<-c(1,2)> class(a)[1] "numeric"判断对象是否是矩阵
1.使用attributes()函数,若是矩阵返回一个维度,若不是,返回NULL值,如下:
> mymatrix<-matrix(c(1:25),5,5)> attributes(mymatrix) #返回维度,5行5列$dim[1] 5 5> attributes(mymatrix[2,]) #向量无维度,返回NULL值NULL2.使用is.matrix()函数,如:
> mymatrix<-matrix(c(1:25),5,5)> is.matrix(mymatrix) #判断mymatrix是不是一个矩阵,若是返回TRUE,不是返回FALSE[1] TRUE> is.vector(mymatrix[2,])#判断mymatrix[2,]是不是向量,是返回TRUE,不是返回FALSE[1] TRUE列表
列表(list) 是R的数据类型中最为复杂的一种。一般来说,列表就是一些对象(或成分,component)的有序集合。列表允许整合若干(可能无关的)对象到单个对象名下。
列表允许以一种简单的方式组织和重新调用不相干的信息。
许多R函数的运行结果都是以列表的形式返回的。函数需要返回两个以上变量时需采用list形式返回。
列表的创建
使用list(·····)创建列表,list(object1,object2······)其中的object可以是到目前为止提到的任何数据类型,比如:向量,矩阵,列表等。下面举个例子,如:
> d<-"our one list " #单个字符> d1<-c(1,2,4,7,9) #向量> d2<-matrix(c(2,4,6,8),2,2,byrow=T) #矩阵> ourlist<-list(d,d1,d2) #建立列表> ourlist #查看列表[[1]][1] "our one list "[[2]][1] 1 2 4 7 9[[3]] [,1] [,2][1,] 2 4[2,] 6 8声明列表
之前提过如何建立一个空向量,现在建立(声明)一个空列表也差不多,如下:
> ourlist2<-list() #建立或声明一个空向量> mode(ourlist2) #查看一下类型,返回结果是列表[1] "list"标签或者对象名的命名
每一个列表组件都可设置标签,就像向量的变量名或矩阵的行列名一样,标签会显示在$的后面。命名的方式很简单直接在建立列表时直接命名,如
> d<-"our one list "> d1<-c(1,2,4,7,9)> d2<-matrix(c(2,4,6,8),2,2,byrow=T)> d3<-list(c(1,2),c(3,4)) #列表> ourlist3<-list("字符"=d,d1=d1,juzhen=d2,d3) #注意我这里列表里嵌套了一个列表> #第一个组件名字是“字符”,第二个是d1,第三个是juzhen>> ourlist3 #$符号的后面是标签(组件名),如果没有标签的那个,$号会变成[[数字]],如第4个$字符[1] "our one list "$d1[1] 1 2 4 7 9$juzhen [,1] [,2][1,] 2 4[2,] 6 8[[4]][[4]][[1]][1] 1 2[[4]][[2]][1] 3 4删除标签
这里讲的删除标签是删除列表中的所有标签,有两个函数可以使用
使用unname()函数去掉标签,如: > listxx<-list(d3=c(2,4,6,8),d4=c(1,3,5,7))> listxx$d3[1] 2 4 6 8$d4[1] 1 3 5 7> unname(listxx) #去掉标签[[1]][1] 2 4 6 8[[2]][1] 1 3 5 7> listxx1<-list(d5=c(2,4,6,8),d6=c(1,3,5,7))> listxx1 #这个列表是有标签的$d5[1] 2 4 6 8$d6[1] 1 3 5 7> names(listxx1)<-NULL#给标签一个NULL值> listxx1#列表标签被删除[[1]][1] 2 4 6 8[[2]][1] 1 3 5 7鬼点子
既然我们上面看到了使用names()<-NULL,可以删掉标签,那么如果把NULL值换成向量是不是可以更换列表标签呢?(这是我写这篇文章的时候突发奇想的,之前并不知道),我直接试了一下,如下:
> listxx2<-list(D1=c(2,4,6,8),D2=c(1,3,5,7))> listxx2#兄弟们,这是可以的$D1 ##### #####[1] 2 4 6 8 ### ### ### ###$D2[1] 1 3 5 7 ## ## ## ##> names(listxx2)<-c("f1","f2") ## ##> listxx2##########$f1[1] 2 4 6 8$f2[1] 1 3 5 7列表元素的索引
列表元素的索引有多种,一是索引列表某组件,二是索引列表中某组件里的内容
一、索引列表某组件
1.如果有标签,可以通过标签索引一个组件整体,方法与向量,矩阵的访问差不多,如,我们用上面例子,ourlist3举例:
> ourlist3["字符"] #中括号里写标签,注意要用双引号$字符[1] "our one list "> ourlist3[1] #直接中括号里一个数字,这个数字代表的是列表里第几个组件$字符[1] "our one list "2.无论有无标签,都可以直接用组件序号索引,如
> ourlist4<-list(c(1,2),c(3,5)) #有一个列表,没有给组件设置标签> ourlist4[2] #直接可以中括号里写组件序号索引一整个组件[[1]][1] 3 5> class(ourlist4[2])#class一下,ourlist4[2]是一个列表[1] "list"二、索引列表某组件中的内容
1.如果有标签,有两种方式索引组件内容
使用$符号索引组件内容,变量名+$+标签 ,如: > ourlist5<-list(a=c(1,2),b=c(3,5),c(5,6)) #这里有一个列表,两个有标签 > ourlist5 #查看一下,是我预期结果 $a [1] 1 2 $b [1] 3 5 [[3]] [1] 5 6 > ourlist5$a #使用$符号加标签索引 [1] 1 2 > ourlist5$b [1] 3 5 > class(ourlist5$a) #class一下ourlist5$4,它是数值型内容 [1] "numeric" > ourlist5<-list(a=c(1,2),b=c(3,5),c(5,6)) > ourlist5[["a"]] #两个中括号,中括号里写标签,标签要用双引号 [1] 1 2 > ourlist5[["b"]] [1] 3 52.无论有无标签,都可用两个中括号,中括号里写组件序号索引组件内容 ,如
> ourlist5<-list(a=c(1,2),b=c(3,5),c(5,6))> ourlist5[[1]] #两个中括号,中括号里写组件序号访问[1] 1 2> ourlist5[[3]][1] 5 6列表元素的增减
1.增加元素
当我有一个列表,已经创建完毕,但还需加入元素时,可以直接通过索引的方式赋值,如:
方法一,通过两个中括号的方式,本来没有第三个的,直接加一个进去,R灰常银杏话(nice) > ourlist6<-list(a=c(1,2),b=c(3,5)+ )> ourlist6[[3]]<-TRUE#第三个给它一个TRUE> ourlist6$a[1] 1 2$b[1] 3 5[[3]][1] TRUE$符号,直接标签与内容一次性直接加进去。 > ourlist7<-list(a=c("很好","非常好"),b=c("good","nice"))> ourlist7$c<-"好极了"#> ourlist7$a[1] "很好" "非常好"$b[1] "good" "nice"$c[1] "好极了"2.减元素
把你不需要的,直接赋值为NULL,之前提过NULL表示啥也没有,请直接看代码,如;
> ourlist7#我这里有一个列表,他有三个元素$a[1] "很好" "非常好"$b[1] "good" "nice"$c[1] "好极了"> ourlist7$b=NULL #现在把第二个删掉,赋给它一个NULL值,看如下结果> ourlist7$a[1] "很好" "非常好"$c[1] "好极了"当然仿照向量使用负索引也是可以的,如:
> ourlist8<-list(a=c("很好","非常好"),b=c("good","nice"))> #这里使用另一个变量ourlist9来接受它,因为和向量一样,负索引不会对原来的有影响> ourlist9<-ourlist8[-2]> ourlist9$a[1] "很好" "非常好">>> ourlist8#ourlist8是没有改变的,ourlist9是ourlist8删了第二项后的$a[1] "很好" "非常好"$b[1] "good" "nice"获取标签
直接使用names()函数获取列表所有标签,如:
> ourlist8<-list(a=c("很好","非常好"),b=c("good","nice"))> names(ourlist8)#返回结果是列表所有标签,如果列表好多标签,可以选择你需要的标签索引元素[1] "a" "b"解除列表
直接使用unlist()函数解除列表,(可以理解为一个列表让它散架)
> ourlist8<-list(a=c("很好","非常好"),b=c("good","nice"))> unlist(ourlist8)#返回结果是字符型向量,标签会各自显示在上方 a1 a2 b1 b2 "很好" "非常好" "good" "nice" > class(unlist(ourlist8))[1] "character"列表相关函数(部分)
1.lapply()函数
lapply()-list apply 给每个组件执行给定函数,返回列表,和矩阵apply()类似,同属于apply家族
使用方法:lapply(目标列表,函数),举例如下 :
> listaa1<-list(a1=c(1,3,5,7,9),a2=c(2,4,6,8,10))> lapply(listaa1,mean) #对每一个组件执行求均值$a1[1] 5$a2[1] 6> lapply(listaa1,max) #返回组件内容中的最大值$a1[1] 9$a2[1] 102.sapply()函数
与lapply()一样,只是返回的结果类型是向量,举例如下
> listaa1<-list(a1=c(1,3,5,7,9),a2=c(2,4,6,8,10))> sapply(listaa1,mean) #返回结果是向量,标签与返回值竖一一对应a1 a2 5 6 > class(sapply(listaa1,mean))[1] "numeric"数据框
数据框的创建
数据框类似矩阵,有行列两个维度。数据框允许不同的列可以包含不同类型的数据。注意:数据框可以看成每个组件长度相同的列表。。个人见解:数据框就像excel表格一样,比矩阵高级一点。很多东西都可以参考矩阵。
x<-data.frame(col1, col2, col3,……) 其中的列向量col1, col2, col3,… 可为任何类型(如字符型、数值型或逻辑型)。数据框可以看成每个组件长度相同的列表,数据框类似矩阵,有行列两个维度。建议数据框在Rstudio的左上角框里查看。数据框的创建举例如下:
> mydata1<-data.frame(name=c("李华","张三","李怡"),"性别"=c("男","女","女"),age=c(18,19,20))> #name,性别,age 是列名> mydata1 name 性别 age1 李华 男 182 张三 女 193 李怡 女 20数据框的索引
数据框的索引与矩阵的索引差不多
1.索引一整各组件
使用一个中括号索引,中括号里写第几列序号,如:> mydata1<-data.frame(name=c("李华","张三","李怡"),"性别"=c("男","女","女"),age=c(18,19,20))> mydata1[3]#索引第三列的age元素 age1 182 193 20> class(mydata1[3])#索引的结果是一个数据框[1] "data.frame"> mydata1<-data.frame(name=c("李华","张三","李怡"),"性别"=c("男","女","女"),age=c(18,19,20))> mydata1["name"] #列名索引 name1 李华2 张三3 李怡> mydata1[c("age","name")]#这里使用了向量索引了两列 age name1 18 李华2 19 张三3 20 李怡> class(mydata1["name"])#索引的结果是一个数据框[1] "data.frame"> #当然还可以像矩阵一样索引多列多行,如:> mydata1[,c(1,3)]#索引1,3列 name age1 李华 182 张三 193 李怡 20> mydata1[,c("name","age")] #使用列名索引1,3列 name age1 李华 182 张三 193 李怡 20> mydata1[c(1,2),c("name","age")]#索引特定的行列 name age1 李华 182 张三 192.索引组件里的元素,和列表相同,如:
使用两个中括号,中括号里写列的序号或者是列名(列名要引号),如> mydata1<-data.frame(name=c("李华","张三","李怡"),"性别"=c("男","女","女"),age=c(18,19,20))> mydata1[[2]]#中括号里写所需的列序号[1] "男" "女" "女"> mydata1[["性别"]]#中括号写列名,列名要加引号,因为它是字符型[1] "男" "女" "女"> class(mydata1[["性别"]])#索引后返回结果是字符型向量[1] "character"$符号索引,与列表相同 > mydata1<-data.frame(name=c("李华","张三","李怡"),"性别"=c("男","女","女"),age=c(18,19,20))> mydata1$性别[1] "男" "女" "女"> class(mydata1$性别)#索引后返回结果是字符型向量[1] "character"数据框有两个维度,可以返回多行多列的结果,具体操作方式与矩阵 相同,这里不过多阐述(怕读者读了睡觉)
数据框行列名的获取与更改
数据框行列名的读取与编辑有多种方式,这里介绍两种常用的
数据框列名的读取与更改
1.可以通过colnames(<数据框>)来读取并编辑列名称。 这种方式很银杏话(dog),既可以单个读取或更改,也可以大量读取或更改,请看如下代码:
列名读取,colnames(数据框)[···]或者colnames(数据框)> mydata1<-data.frame(name=c("李华","张三","李怡"),"性别"=c("男","女","女"),age=c(18,19,20))> colnames(mydata1)[1]#读取第一列列名,读取哪个中括号里就写几[1] "name"> colnames(mydata1)[c(1,2)] #我使用向量读取了两个[1] "name" "性别"> colnames(mydata1) #读取数据框所有列名[1] "name" "性别" "age" > mydata1<-data.frame(name=c("李华","张三","李怡"),"性别"=c("男","女","女"),age=c(18,19,20))> colnames(mydata1)[1]<-"a"#更改第一列列名,要改第几个中括号里就写几> mydata1 a 性别 age1 李华 男 182 张三 女 193 李怡 女 20> colnames(mydata1)[3]<-"c"#更改第三列列名> mydata1 a 性别 c1 李华 男 182 张三 女 193 李怡 女 20> colnames(mydata1)<-c("a1","b","c1") #注意没有中括号了,我使用一个向量全部改了> mydata1 a1 b c11 李华 男 182 张三 女 193 李怡 女 20数据框行名的读取与更改
可以通过row.names(<数据框>)来读取并更改行名称
行名读取,row.names(数据框)[···]或row.names(数据框),举例如下:> mydata1<-data.frame(name=c("李华","张三","李怡"),"性别"=c("男","女","女"),age=c(18,19,20))> #读取所有行名,因为我没有设置行名,所以系统帮你默认了数字(可以在Rstudio左上角框里看到> row.names(mydata1) [1] "1" "2" "3"> row.names(mydata1)[2]#还可以查看第几个第几个你想看的行名[1] "2"> row.names(mydata1)[c(2,3)]#多行中括号里就用向量[1] "2" "3"> mydata1<-data.frame(name=c("李华","张三","李怡"),"性别"=c("男","女","女"),age=c(18,19,20))> mydata1 name 性别 age1 李华 男 182 张三 女 193 李怡 女 20> #从上面的结果看到,我没有设置行名,系统默认了一个,往往按大部分需求是要改的> row.names(mydata1)<-c("r1","r2","r3") #更改行名,结果如下:> mydata1 name 性别 ager1 李华 男 18r2 张三 女 19r3 李怡 女 20数据框元素的增减
1.数据框元素的增加
和矩阵一样,也可以使用rbind()与cbind()函数添加行列,但需注意数据框使用rbind()时添加的行是数据框或列表。
> mydata2<-data.frame(name=c("李小华","张大三","李佳怡"),"性别"=c("男","男","女"),age=c(18,19,20)) #这里有一个数据框> mydata2 name 性别 age1 李小华 男 182 张大三 男 193 李佳怡 女 20> higth<-c(175,173,167) #这里创建了一个身高的向量> mydata3<-cbind(mydata2,higth) #按列合并,返回结果如下> mydata3 name 性别 age higth1 李小华 男 18 1752 张大三 男 19 1733 李佳怡 女 20 167注意数据框使用rbind时添加的行是数据框或列表。举例如下: > #这里直接沿用上面的例子> mydata3 name 性别 age higth1 李小华 男 18 1752 张大三 男 19 1733 李佳怡 女 20 167> a<-data.frame(name="陈永鸿","性别"="男",age=21,higth=177) #要加入的新数据框> a#看一下是不是我需要的 name 性别 age higth1 陈永鸿 男 21 177> rbind(mydata3,a)#按行合并数据框 name 性别 age higth1 李小华 男 18 1752 张大三 男 19 1733 李佳怡 女 20 1674 陈永鸿 男 21 1772.数据框元素的删除
数据框元素的删除有多种方式,但方法与矩阵的差不多 ,直接看代码,如下:
使用负索引> mydata2<-data.frame(name=c("李小华","张大三","李佳怡"),"性别"=c("男","男","女"),age=c(18,19,20))> mydata2 name 性别 age1 李小华 男 182 张大三 男 193 李佳怡 女 20> #负索引的形式,但也要覆盖或这建立新数据框储存> mydata4<-mydata2[-2,] #删掉第二行> mydata4 name 性别 age1 李小华 男 183 李佳怡 女 20> mydata5<-mydata2[-3,-3] #删除第三行第三列> mydata5 name 性别1 李小华 男2 张大三 男> mydata2 name 性别 age1 李小华 男 182 张大三 男 193 李佳怡 女 20> mydata6<-mydata2> #好像不可以使用NULL值取删除行,如果有同志会操作的可以在评论区留言> mydata6[2,]<-NULLError in x[[jj]][iseq] <- vjj : replacement has length zero> mydata6[,2]<-NULL #给第二列一个NULL值> mydata6#查看mydata6,与删除前对比就是删除了第三列 name age1 李小华 182 张大三 193 李佳怡 20> mydata7<-mydata2> mydata7[,"age"]<-NULL #使用列名也是可以的(呕心沥血)> mydata7 name 性别1 李小华 男2 张大三 男3 李佳怡 女数据框相关函数
基本以矩阵一致,好多函数都可以用,这里我举例apply 与lapply(),如:
apply() > mydata9<-data.frame("c1"=c(1,2,3),"c2"=c(6,7,8),"c3"=c(11,12,13),"c4"=c(4,5,6))> mydata9 c1 c2 c3 c41 1 6 11 42 2 7 12 53 3 8 13 6> r_mean<-apply(mydata9,1,mean) #对行求均值> da<-cbind(mydata9,r_mean)#按列合并> da c1 c2 c3 c4 r_mean1 1 6 11 4 5.52 2 7 12 5 6.53 3 8 13 6 7.5> r<-apply(da,2,mean) #求列均值> mydata10<-rbind(da,r)#合并行> mydata10[4,5]<-NA#不需要右下角的那个值> mydata10 c1 c2 c3 c4 r_mean1 1 6 11 4 5.52 2 7 12 5 6.53 3 8 13 6 7.54 2 7 12 5 NA> rownames(mydata10)<-c("r1","r2","r3","c_mean") #改一下行名> mydata10 c1 c2 c3 c4 r_meanr1 1 6 11 4 5.5r2 2 7 12 5 6.5r3 3 8 13 6 7.5c_mean 2 7 12 5 NAlapply(),注意此函数操作对象是列表,即在数据框中默认对列操作 > mydata9 c1 c2 c3 c41 1 6 11 42 2 7 12 53 3 8 13 6> mydata11<-lapply(mydata9,sum) #lappya()函数> mydata11 #对列操作$c1[1] 6$c2[1] 21$c3[1] 36$c4[1] 15有时候,数据框会转换成矩阵操作,此时可以使用as.matrix()函数操作,这里不进行举例(太简单了)
因子和表
因子(factor) 是R语言中许多强大运算的基础,因子的设计思想来着统计学中的名义变量(分类变量),因子可以简单的看做一个附加了更多信息的向量。使用方法:factor(x = character(), levels, labels = levels, exclude = NA, ordered = is.ordered(x), nmax = NA)
因子的创建
不像向量、矩阵与数据框比较直观,很好理解,因子不太好使用语言描述,但是代码很直观,能很直观的返回对象有多少水平。直接看例子吧!
> myvector<-c("T","F","T","T","F","T") #这里有一个向量> myfactor<-factor(myvector) #这是因子的用法> myfactor#查看一下[1] T F T T F TLevels: F T>#注意返回值第二行有一个水平,指的是myvector只有F与T,只有这两个水平。>#第一行可以理解为myvector转换为因子后的结果。>因子的索引
因子的索引与向量的操作差不多,但是返回的是原因子水平,不过多介绍,简单举例如下:
> myvector<-c("T","F","T","T","F","T")> myfactor[1] T F T T F TLevels: F T> myfactor[c(1,2)]#取1,2个,水平不变[1] T FLevels: F T> myfactor[c(3,4)]#取3,4个,返回两个T,水平注意是原因子的水平[1] T TLevels: F T因子的修改
与向量也差不多,最简单的方法是赋值,如:
> myvector<-c("T","F","T","T","F","T")> myfactor<-factor(myvector)> myfactor[3]<-"F"#把第三个改为F> myfactor[1] T F F T F TLevels: F T当然还有其他操作,差不多都可以参照向量,特别说明:因子不是向量,他们只是像,因子的类型是因子型,与向量不同
因子常用函数
1.tapply()函数
tapply(x,f,g): x向量,f因子或因子列表,g函数。tapply执行操作,将x分组,每组对应一个因子水平(多因子情况下对应一组水平的组合,然后向量应用于函数g),注意:f中每个因子需要与x具有相同的长度,返回值是向量或矩阵。x必须是向量
举例如下:
> data1#这里有一个数据框 name 性别 age higth1 李小华 男 18 1752 张大三 男 19 1733 李佳怡 女 20 1674 黎晓鸿 男 21 177> class(data1)[1] "data.frame"> #如下:对性别进行分组后,对身高进行求均值,返回男的身高平均值,女的身高平均值> tapply(data1$higth,data1$性别,mean) 男 女 175 167 >> #如果想用分多组,就用因子列表,如 ;> tapply(data1$higth,list(data1$性别,data1$name),mean) 黎晓鸿 李佳怡 李小华 张大三男 177 NA 175 173女 NA 167 NA NA> #如上结果开始有点有别扭,那是因为你的数据量不够大> #如果有几个人同时同名,就可以算出这些人在分男女的情况下的身高均值,我不在举例,大伙可以去试试2.spilt()函数
和tapply(x,f,g)不同split(x,f)只分组,x可为数据框或向量,返回值是列表。
举例如下:
> #沿用上面的数据框> split(data1$name,data1$性别) #对name按照性别进行分组,结果返回列表,标签是分组水平$男[1] "李小华" "张大三" "黎晓鸿"$女[1] "李佳怡"3.by()函数
by(x, f, function), x 向量或矩阵,注意by应用于对象,f 是因子,function 是函数。
举例如下:
> #继续沿用上面的数据框> by(data1$higth,data1$性别,mean) data1$性别: 男[1] 175----------------------------------------- data1$性别: 女[1] 1674.aggregate()函数
aggregate(x,list,f),其中x为向量/数据框/矩阵,第二个参数必须为一个列表,f是函数。该函数可以按照要求把数据打组聚合,然后对聚合以后的数据进行加和、求平均等各种操作。
举例如下:
> data1#这里还是用了这个数据框 name 性别 age higth1 李小华 男 18 1752 张大三 男 19 1733 李佳怡 女 20 1674 黎晓鸿 男 21 177> aggregate(data1[,c(3,4)],list(data1$性别),mean) #按性别聚合后,对age与higth进行求期望 Group.1 age higth1 男 19.33333 1752 女 20.00000 167表
R中表指的是列联表,至于什么意思,我这里直接给你看代码!表有多个函数,我们举两个例子
1.table()函数
常用于统计向量频数,举例如下:
> a<-c(1,2,3,4,2,3,1,1,1,3,3,3,2,4)> table(a)a1 2 3 4 4 3 5 2 > #解释:1有4个,2有3个,3有5个,4有2个注意:表表可以如同矩阵一样访问
如:
> a<-c(1,2,3,4,2,3,1,1,1,3,3,3,2,4)> table(a)[3] #看第三个3 5 > list1<-list(c(2,2,2,3,4,5,5),c(6,6,7,7,7,8,8))> table(list1) list1.2list1.1 6 7 8 2 2 1 0 3 0 1 0 4 0 1 0 5 0 0 2> table(list1)[3,] 6 7 8 0 1 0 2.cut()函数
cut(x,b,labels=FALSE)是生成因子的一种常用方法,常用于表操作。这个函数用法很复杂,我这里举一个非常简单的,如:
> a<-cut(data1$higth,breaks=c(-Inf,160,170,175,180,Inf),labels=c("不评价","还行","很好","喜欢","哇!哇!"))> a<-cut(data1$higth,breaks=c(-Inf,160,170,175,180,Inf),labels=c("不评价","身高还行","身高很好","喜欢这身高","哇!哇!"))> data1<-cbind(data1,a)> data1#对身高的一个估测 name 性别 age higth a1 李小华 男 18 175 身高很好2 张大三 男 19 173 身高很好3 李佳怡 女 20 167 身高还行4 黎晓鸿 男 21 177 喜欢这身高个人评价:cut()这个函数用于基因表达的上调与下调好像很简便。(我没有用过,各位读者可以去试试,评论区可以告诉我结果行不行)
字符串
字符串比较简单,基本上就一些函数,如果学过C语言的,应该就知道字符串是啥,这里不在介绍。
字符串在文本挖掘中很重要,使用正则表达式很方便。
字符串操作的常见函数
1.字符串长度
使用nchar()函数求字符串长度。举例如:
> a1<-c("我是某某,喜只因") #自己可以数一数,什么也要算长度(狗头)> nchar(a1)[1] 82.字符串合并
使用paste()合并字符串。paste(str1,str2,sep),举例如下:
> a2<-"我是坤"> a3<-"绰号只因"> a4<-paste(a2,a3,sep="-坤粉说-") #使用“"-坤粉说-"”进行连接a2与a3> a4[1] "我是坤-坤粉说-绰号只因"3.字符串的分割
使用strsplit()函数分割字符串,返回的是列表,举例如下:
> a5<-"你~干~嘛~!"> strsplit(a5,"~") #分割a5,分割位置是~[[1]][1] "你" "干" "嘛" "!"4.读取字符串
使用substr()读取字符串,substr(x, start, stop),举例如下:
> a6<-"读取字符串"> substr(a6,3,5) #读取3到5个字符[1] "字符串"> substr(a6,5,5) #还能都一个“串”字哦!晚上看到它的同志饿吗?[1] "串"5.字符串的替换
使用chartr()函数替换元素,chartr(old, new, x),把x里的old换成new的,举例如下:
> a7<-"字符串的替换"> chartr("替换","更改",a7)[1] "字符串的更改"注意:替换时,两个长度要相同,不然出问题
6.多个组件合成一个字符串
使用sprintf()函数,先给各位举个例子,学过C语言的应该秒懂它是干啥的。
> a9<-666> hh<-sprintf("你真%d",a9) #对的a9里的数字替换了%d> hh[1] "你真666"具体举例如下:
> a10<-"哎呦"> a11<-6> h1<-sprintf("你干嘛!%s,%d",a10,a11) #%s是接受字符串型的数据> h1[1] "你干嘛!哎呦,6"正则表达式
正则表达式说它难吧,感觉又不难,它的内容很多,建议有兴趣读者去搜索R正则表达式,这里介绍几个常用的函数,(简单来说,正则表达式就是找相同的,作用范围非常广)
1.grep() 函数
grep(pattern, x, ignore.case = FALSE, perl = FALSE, value = FALSE,fixed = FALSE, useBytes = FALSE, invert = FALSE),在向量x中搜索给定的子字符串pattern,返回结果是匹配项的下标
x向量(这里介绍简单的,后面一串参数比较复杂)。
> grep("A",c("a","A","B","b")) #在向量中搜索A,返回在向量中的位置。[1] 2当然还可以进行其他操作,查找对应元素位置,例如:
> a<-c("en","english","glish") #这里有一个向量> grep("[an]",a) #返回有an的元素的位置[1] 1 2> grep("l.s",a) #查找l与s,中间有一个随便的元素,返回2,3[1] 2 3> grep("e..l",a) #查找e至l,中间有两个元素[1] 2grep() 函数还有其他用法,各位感兴趣可以自行百度
2.sub(old,new,x)函数 ,gsub()函数
sub(old,new,x),在x将old换成new,只对查找到的第一个内容进行替换。举例入下:
> a<-c("a","c","d") > sub("c","hh",a)#把c换成hh[1] "a" "hh" "d" gsub(old,new,x),在x将所有的old换成new,对查找到的所有内容进行替换,举例如下:
> a1<-c("aac","hhc","sss","cdd")> gsub("c","b",a1) #将所有的c换成b[1] "aab" "hhb" "sss" "bdd"3.regexpr(pattern,text)、gregexpr(pattern, text)函数
regexpr(pattern, text, ignore.case = FALSE, perl = FALSE,fixed = FALSE, useBytes = FALSE),返回一个与给出第一个匹配的起始位置的文本长度相同的整数向量,如果没有则返回-1。举例如下:
> a2<-c("asdasdv","wertsdasv","sdvasd")> regexpr("sdas",a2) #返回结果,第一个第二个元素有相同的,返回2,第二个第五个开始,第三个无[1] 2 5 -1attr(,"match.length")[1] 4 4 -1attr(,"index.type")[1] "chars"attr(,"useBytes")[1] TRUEgregexpr(pattern, text, ignore.case = FALSE, perl = FALSE,fixed = FALSE, useBytes = FALSE),返回一个与文本长度相同的列表,每个元素的格式与regexpr的返回值相同,除了给出了每个(不相交)匹配的起始位置。举例如下
> a2<-c("asdasdv","wertsdasv","sdvasd")> gregexpr("sdas",a2)[[1]][1] 2attr(,"match.length")[1] 4attr(,"index.type")[1] "chars"attr(,"useBytes")[] TRUE[[2]][1] 5attr(,"match.length")[1] 4attr(,"index.type")[1] "chars"attr(,"useBytes")[1] TRUE[[3]][1] -1attr(,"match.length")[1] -1attr(,"index.type")[1] "chars"attr(,"useBytes")[1] TRUE注:正则表达式有很多使用场景,多用于处理文本,比较复杂,各位感兴趣可自行百度,CSDN上有许多优秀资源
数学运算与模拟
这部分介绍部分常用与数学计算与模拟的函数
1.sum()函数,求和函数
> a<-c(1:5)> sum(a) #对a中的元素求和[1] 152.prod()函数,求连乘
> a<-c(1:5)> prod(a)[1] 1204.factorial()函数,求阶乘
> factorial(6)[1] 7205.max()函数,求最大值,min()函数求最小值,range()函数,同时返回最小值与最大值
> a[1] 1 2 3 4 5> max(a)[1] 5> min(a)[1] 1> range(a)#同时返回最小值与最大值[1] 1 5> c(min(a),max(a))#同时返回最小值与最大值[1] 1 56.which.max()函数返回最大元素的位置,which.min()函数返回最小元素的位置
> a1<-c(3,5,1,8)> which.max(a1) #最大元素位置是4[1] 4> which.min(a1) #最大元素位置是3[1] 37.median()函数,求中位数
> a[1] 1 2 3 4 5> median(a)[1] 38.var()函数,计算方差
> a[1] 1 2 3 4 5> var(a)[1] 2.59.rev()函数,对元素去逆序列
> a[1] 1 2 3 4 5> a<-rev(a)> a[1] 5 4 3 2 110.sort()函数,将元素按升序排列,order()函数,从小的到大的返回他们各自的位置
> a[1] 5 4 3 2 1> a<-sort(a)> a[1] 1 2 3 4 5> a5<-c(11,50,23,37,44)> order(a5) #11最小的,位置是1,23第二小,位置是3,第三小37,位置为4·····[1] 1 3 4 5 211.cumsum()函数,累计和,第n个元素是1加到n的和
> a[1] 1 2 3 4 5> a<-cumsum(a)> a[1] 1 3 6 10 1512.pmax(a,b)函数返回一个向量,第i个元素是a[i]与b[i]中的最大值、pmin()函数返回一个向量,第i个元素是a[i]与b[i]中的最小值,如:
> a2<-c(1,2,3,4)> a3<-c(2,4,3,6)> pmax(a2,a3) #结果第一个元素是a2[1]与a3[1]两个中的最大值,其他类推[1] 2 4 3 6> pmin(a2,a3)[1] 1 2 3 413.match(x,y)函数,返回一个和x的长度相同的向量,表示x中与y中元素相同的元素在y中的位置(没有则返回NA),如:
> a2<-c(1,2,3,4)> a3<-c(2,4,3,6)> match(a2,a3)[1] NA 1 3 2> #解析:a2中的第一个元素在a3中没有,返回NA,a2中的第二个元素在a3中的第1个有,返回1,以此类推14.choose(n,k),求组合数,从n个中选出k,
> choose(5,3) #5×4×3÷3÷2÷1=10[1] 1015.unique(x),如果x是一个向量或者数据框,则返回一个类似的对象但是去掉所有重复的元素,对于重复的元素只取一个,举例如下:
> a4<-c(1,2,4,5,6,7,7,7,7,4,4,4,2,2,2)> unique(a4) #对重复的对象只取一次[1] 1 2 4 5 6 716.union(x,y)函数求x,y并集,intersect(x,y)函数求x,y交集,setdiff(x,y)函数相当于先求x,y交集在求差集,举例如下:
> a5<-c(1,2,3,4,5,6)> a6<-c(4,5,6,7,8,9)> union(a5,a6)[1] 1 2 3 4 5 6 7 8 9> intersect(a5,a6)[1] 4 5 6> setdiff(a5,a6)[1] 1 2 3> setdiff(a6,a5)[1] 7 8 917.x%in%y判断x,y向量元素是否相同,相同的返回TRUE,setequal(x,y)函数判断x,y向量是否完全相同,返回逻辑值,举例如下:
> a5<-c(1,2,3,4,5,6)> a6<-c(4,2,6,4,8,9)> a5%in%a6[1] FALSE TRUE FALSE TRUE FALSE TRUE> setequal(a5,a6)[1] FALSE> setequal(c(1,2,3),c(1,2,3))[1] TRUER语言画图
此部分只了解两个内容,一是R自带的plot函数画图,二是ggplot2函数
plot函数
R自带的画图工具,R绘图基础图形系统的核心 plot()函数,plot 是一个泛型函数,使用plot 时真正被调用的时函数依赖于对象所属的类。
plot(x, y = NULL, type = "p", xlim = NULL, ylim = NULL,log = "", main = NULL, sub = NULL, xlab = NULL, ylab = NULL,ann = par("ann"), axes = TRUE, frame.plot = axes,panel.first = NULL, panel.last = NULL, asp = NA, ...)
plot函数中有许多的参数,我这里解释基础的部分。
其中x,y指横纵坐标对应的参数
1.图片的保存
保存图片使用下列函数保存PDF文件,PDF文件可以放大后不会模糊。
pdf("文件名.pdf")#作图语句dev.off() #作图完成后关闭,返回结果1.什么参数都不设置(最简单的散点图),如
> a<-c(10,15,20,25,30,35)> b<-c(12,23,27,44,56,63)> plot(a,b)结果如下:
2.par()函数图布局
就是Rstudio右下角画图区域,可以设置一个页面多少张图,可以进行布局,默认一张,使用par参数进行设置图布局,par(mfrow=c(行,列)按行排列,par(mfcol=c(行,列)按列排列。
R绘图区域界面公共分为三个部分:outer margins、figure region、plot region。一般情况下,R绘图区域没有out margin区域;标签、轴名称和标题在figure region区域;画的线条之类的都在plot region区域。
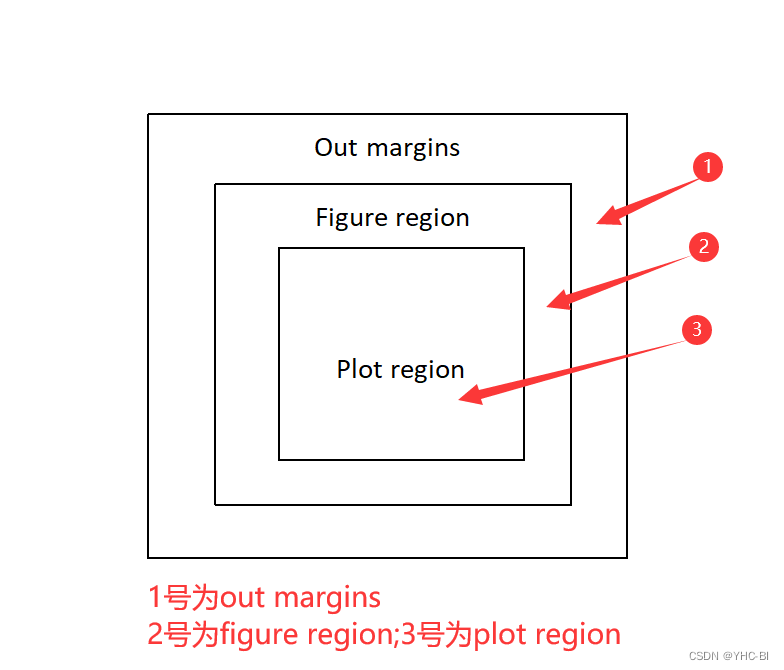
这里我直接用代码展示区域,我使用box()函数描绘各区域边框,部分参数如下:
| 参数 | 作用 |
|---|---|
| which | 在当前图形上绘制边框,参数可以选择 plo他、figure、inner、outer。 |
| col | 边框颜色 |
| lwd | 边框大小 |
| ···· | ···· |
> par(oma=c(3,3,3,3)) #请把注意里放在par函数与box函数上,其他函数后面会提及> lines1<-plot61<-plot(a,b,type="b",pch=23,col="blue",col.axis=2,xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="红色框里的为plot区域",sub="plot61")> lines2<-lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("topleft",inset=0.05,cex=0.8,title="lines",c("lines1","lines2"),pch=c(23,21),text.col=2)> text(27,60,"lines1",col="blue")> text(35,45,"lines2",col="red")> box(which="plot",col="red",lwd=2)> box(which="inner",col="black",lwd=4)> box(which="figure",col="blue",lwd=3)> box(which="outer",col="green",lwd=5)红色框内为plot区域,蓝色内部为plot area区域,蓝色与红色之间为margin区域,绿色与蓝色之间为out margin area区域,结果如下:
par有许多参数,其中与plot部分一样,比如:col;lwd;lty;font;cex等,常用参数如下:
| 参数 | 作用、 |
|---|---|
| mfcol | 分割画图区域,一个大图分割成几个子图,按列绘制子图 |
| mfrow | 分割画图区域,一个大图分割成几个子图,按行绘制子图 |
| mgp | 设置标题、坐标轴名称、坐标轴距离图形边框的距离,默认是标题为3;坐标轴名称为1;坐标轴为0 |
| oma | 设置外边界,oma=c(下,左,上,右),例如:oma=c(2,3,4,3),下边距2,左边距3,上边距4,右边距3。 |
#这里看不懂的跳过,后面回来看,这是后面一点的代码,其中参数后面会提及,我这里只举例par函数的用法> par(oma=c(2,1,2,0.5),col="blue",mgp=c(2,1,0),bg="black")> lines1<-plot51<-plot(a,b,type="b",pch=23,col="blue",col.axis=2,xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="背景为黑",sub="plot51")> lines2<-lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("topleft",inset=0.05,cex=0.8,title="lines",c("lines1","lines2"),pch=c(23,21),text.col=2)> text(27,60,"lines1",col="blue")> text(35,45,"lines2",col="red")
如果嫌弃Rstudio画图区域太小,还可使用dev.new()函数在外部建一个画图区域(个人感觉这种方式更模糊一点)
3.main :设置主标题,sub:副标题
> plot(a,b,main="主标题位置",sub="副标题位置")结果如下:
4.type,指线的类型
| tybe参数可选值 | 线条类型 |
|---|---|
| tybe=“p” | 点图 |
| tybe=“l” | 线图 |
| tybe=“b” | 同时绘制点和线 |
| tybe=“c” | 仅绘制参数b所示的线 |
| tybe=“o” | 同时绘制点和线,且线穿过点 |
| tybe=“h” | 绘制出点到横坐标轴的垂直线 |
| tybe=“s” | 阶梯图,先横后纵 |
| tybe=“S” | 阶梯图,先纵后横 |
| tybe=“n” | 空图 |
举例如下?:
> par(mfrow=c(2,2)) #表示画图的布是两行两列的,只能最多画四个图> plot2<-plot(a,b,type="p",main="点图",sub="plot2")> plot3<-plot(a,b,type="l",main="线图",sub="plot3")> plot4<-plot(a,b,type="b",main="点线图",sub="plot4")> plot5<-plot(a,b,type="c",main="点线图去掉点",sub="plot5")结果如下:
> par(mfrow=c(2,2))> plot6<-plot(a,b,type="o",main="同时绘制点和线,线穿过点",sub="plot6")> plot7<-plot(a,b,type="h",main="绘制出点到横坐标轴的垂直线",sub="plot7")> plot8<-plot(a,b,type="s",main="阶梯图,先横后纵",sub="plot8")> plot9<-plot(a,b,type="S",main="阶梯图,先纵后横",sub="plot9")结果如下:
5.pch : 指定绘制点时使用的符号

21~24号可以指定点的边界颜色(col=)和点的填充色(bg=)
这里举几个例子
> > par(mfrow=c(2,1))> p1<-plot(a,b,type="b",pch=5,main="例1")> p2<-plot(a,b,type="b",pch=23,col="red",bg=9,main="例2")结果如下:
还可以自定义pch,(有些形状不行)
> plot(a,b,type="b",pch="6",col="red",bg=6)结果如下:
6.`cex : 指定符号的大小,(默认是1)
指定点的大小,如
> plot(a,b,type="b",pch="*",cex=2)结果如下:
cex家族还可以指定其他部位的大小
| 参数 | 作用 |
|---|---|
| cex.axis | 坐标轴大小 |
| cex.lab | 坐标轴标签的大小 |
| cex.main | 主标题大小 |
| cex.sub | 副标题大小 |
| 举一个例子,如 |
> plot(a,b,type="b",pch="*",cex.axis=2,cex.lab=2)结果如下:
绘图时,为了美观,尽量不要改变更改默认值,除非不美观,这里的图为了直观展示,所以画的不太好看
7.lty:指定绘制线条时的类型,lwd:指定线条粗细
线条类型> a1<-c(12,22,32,42,52,62)> b1<-c(12,22,32,42,52,62)> par(mfrow=c(3,2))> plot(a1,b1,type="b",pch="*",lty=1,main="lty=1 实线")> plot(a1,b1,type="b",pch="*",lty=2,main="lty=2 虚线")> plot(a1,b1,type="b",pch="*",lty=3,main="lty=3 点线")> plot(a1,b1,type="b",pch="*",lty=4,main="lty=4 点+短虚线")> plot(a1,b1,type="b",pch="*",lty=5,main="lty=5 长虚线")> plot(a1,b1,type="b",pch="*",lty=6,main="lty=6 点+长虚线")结果如下:
线条粗细使用
lwd 参数,直接用数字表示粗细,如 > par(mfrow=c(2,1))> plot(a1,b1,type="b",pch="*",lty=1,main="lty=1 lwd=1 实线",lwd=1)> plot(a1,b1,type="b",pch="*",lty=1,main="lty=1 lwd=2 实线",lwd=2)结果如下:
使用
col设置线条颜色 | 参数 | 作用 |
|---|---|
| col | 默认的绘图颜色(有些函数可以有不同操作)比如:某些函数可以接受一个含有颜色的向量,并自动循环,使用col=c(“blue”,“white”)绘制三条线时,第一条为蓝色,第二条为白色,第三条为蓝色 |
| col.axis | 坐标轴刻度文字颜色 |
| col.lab | 坐标轴标签的颜色 |
| col.main | 标题颜色 |
| col.sub | 副标题颜色 |
| fg | 图形的前景色 |
| bg | 图形的背景色 |
设置颜色有多种方式,比如通过颜色下标,颜色名称,十六进制颜色值等,
使用colors()函数可以返回查看R中可使用的657中颜色名称.
如:
使用举例如下:
> par(mfrow=c(2,1))> plot(a1,b1,type="b",pch="*",lty=1,main="线条颜色为blue",col="blue",lwd=1.5)> plot(a1,b1,type="b",pch="*",lty=1,main="线条颜色为粉红色",col=2,lwd=2)结果如下:
col参数(部分)举例如下:
> par(mfrow=c(3,2))> plot11<-plot(a,b,type="b",pch="*",col.axis=2,main="坐标轴刻度颜色为红",sub="plot11")> plot12<-plot(a,b,type="b",pch="*",col.lab=2,main="坐标轴标签颜色为红",sub="plot12")> plot13<-plot(a,b,type="b",pch="*",col.main=2,main="标题颜色为红",sub="plot13")> plot14<-plot(a,b,type="b",pch="*",col.sub=2,main="副标题颜色为红",sub="plot14")> plot15<-plot(a,b,type="b",pch="*",fg=2,main="图形的前景色为红",sub="plot15")> plot16<-plot(a,b,type="b",pch=23,bg=2,main="点的类型23,背景色为红",sub="plot16")结果如下:
8.坐标轴标签
使用xlab与ylab参数设置横纵坐标标签,举例如下:
> par(mfrow=c(2,1))> plot17<-plot(a,b,type="b",pch="*",xlab="横坐标标签",col.main=2,main="设置横坐标标签举例",sub="plot15")> plot18<-plot(a,b,type="b",pch="*",ylab="纵坐标标签",col.main=2,main="设置横坐标标签举例",sub="plot16")结果如下:
9.坐标轴范围
使用xlim与ylim参数设置坐标轴范围,举例如下:
> par(mfrow=c(3,1))> plot19<-plot(a,b,type="b",pch="*",xlim=c(0,40),col.main=2,main="设置横坐标范围后图例",sub="plot19")> plot20<-plot(a,b,type="b",pch="*",ylim=c(5,65),col.main=2,main="设置横坐标范围后图例",sub="plot20")> plot21<-plot(a,b,type="b",pch="*",xlim=c(0,40),ylim=c(5,65),col.main=2,main="设置横纵坐标范围后图例",sub="plot21")结果如下:
注:我的屏幕太小了,一次画三个图无法展示全纵坐标数值,现提出一个,更直观展示,上面第三个图如下
10.字体设置
使用font参数设置字体。font=1 表示常规字体,2 表示粗体,3 表示斜体,4 表示粗斜体,5 表示符号字体
| 字体参数 | 作用 |
|---|---|
| font.axis | 坐标轴字体 |
| font.lab | 坐标轴标签字体 |
| font.main | 主标题字体 |
| font.sub | 副标题字体 |
| family | 字体家族:“serif”表示衬线,“sans”表示无衬线,“mono”表示等宽 |
举例如下:
> a2<-c(1,2,3,4,5)> b2<-c(1,2,3,4,5)> plot22<-plot(a2,b2,type="b",pch="*",font.axis=4,xlab="横坐标a2",ylab="纵坐标b2",main="坐标轴字体",sub="plot22")> plot23<-plot(a2,b2,type="b",pch="*",font.lab=4,xlab="横坐标a2",ylab="纵坐标b2",main="坐标轴标签字体",sub="plot23")> plot24<-plot(a2,b2,type="b",pch="*",font.main=4,xlab="横坐标a2",ylab="纵坐标b2",main="主标题字体",sub="plot24")结果如下:
> par(mfrow=c(2,2))> plot25<-plot(a2,b2,type="b",pch="*",font.sub=4,xlab="横坐标a2",ylab="纵坐标b2",main="副标题字体",sub="plot25")> plot26<-plot(a2,b2,type="b",pch="*",family="serif",xlab="横坐标a2",ylab="纵坐标b2",main="有衬线",sub="plot26")> plot27<-plot(a2,b2,type="b",pch="*",family="sans",xlab="横坐标a2",ylab="纵坐标b2",main="无衬线",sub="plot27")> plot28<-plot(a2,b2,type="b",pch="*",family="mono",xlab="横坐标a2",ylab="纵坐标b2",main="等宽",sub="plot28")结果如下:
11.title()函数
title()函数为图形添加标题和坐标轴标签。举例如下:
注意事项:添加标题与标签是在原基础上添加,如果原先有标题或者标签,则新加入的会与之重叠(下面第二个图),所以在要加入新的标签或标题,要把原先的删掉,我这里直接把原来的赋予空值
> par(mfrow=c(3,1))> a2<-c(1,2,3,4,5)> b2<-c(1,2,3,4,5)> plot29<-plot(a2,b2,type="b",pch="*")> plot29<-plot(a2,b2,type="b",pch="*")> title(main="这是标题",sub="这是副标题",xlab="标签1",ylab="标签2")> plot30<-plot(a2,b2,type="b",pch="*",xlab="",ylab="")> title(main="这是标题",sub="这是副标题",xlab="标签1",ylab="标签2")结果如下:
12.abline()函数添加线
在原有图的基础上添加线,可以使用abline()函数abline(a,b,h=x,v=x),其中 a 表示截距,b 表示斜率, h 表示与横坐标平行的线,v 表示与纵坐标平行的线,如:
> a<-c(10,15,20,25,30,35)> b<-c(12,23,27,44,56,63)> par(mfrow=c(2,1))> plot31<-plot(a,b,type="l",pch="*",col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="水平线",sub="plot31")> abline(h=c(20,35,55),v=c(15,25),col="red")> plot32<-plot(a,b,type="l",pch="*",col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="截距为20,斜率为1",sub="plot32")> abline(a=20,b=1,col="red") #截距为20,斜率为1结果如下:
13.lines()函数在现有图形上添加线
在现有图形上添加线可以使用lines函数lines(x, y = NULL, type = “l”, …),举例如下:
> a<-c(10,15,20,25,30,35)> b<-c(12,23,27,44,56,63)> plot33<-plot(a,b,type="l",pch="*",col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="添加线",sub="plot33")> lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",col="red")结果如下:
14.layout()函数图布局
使用layout()函数划分绘图页面,将一张绘图页面类似于矩阵划分为多个区域,可设置某图形的特定行高与列宽
layout(mat, widths = rep.int(1, ncol(mat)),heights = rep.int(1, nrow(mat))····)
layout.show(n = 1)
lcm(x)
mat为矩阵,用于划分绘图窗口,矩阵里0表示此位置不画图,非零元素从1开始,必须为整数值,非0元素的大小就是绘图顺序,比如1,3,2。先画1,后2位置,后画3位;widths设置上列的宽度,绝对宽度用lcm()指定,相对宽度用数值设置。heights设置行高度,用法与widths一样;n指要绘制图形的数量。
具体举例可以看下面代码例子里
> layout(matrix(c(1,1,2,1,1,3),2,3,byrow=T)) #设置画图区域及顺序> > lines1<-plot51<-plot(a,b,type="b",pch=23,col="blue",col.axis=2,xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="添加文字",sub="plot51")> lines2<-lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("topleft",inset=0.05,cex=0.8,title="lines",c("lines1","lines2"),pch=c(23,21),text.col=2)> text(27,60,"lines1",col="blue")> text(35,45,"lines2",col="red")> > plot49<-plot(a,b,type="l",pch=23,col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="关键字为center图9",sub="plot49")> lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("center",inset=0.05,cex=0.4,title="图例",c("线1","线2"),pch=c(23,21 ),text.col=2)> > plot50<-plot(a,b,type="l",pch=23,col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="添加线",sub="plot33")> lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("bottomleft",inset=0.05,cex=0.4,title="图例",c("线1","线2"),pch=c(23,21 ),text.col=2)> 结果如下:
15.添加图例
使用legend()函数添加图例
legend(x, y = NULL, legend, col = par(“col”), border = “black”, lty, lwd, pch,text.width = NULL, text.col = par(“col”),text.font = NULL, plot =TRUE,inset = 0, title.col = text.col[1]······· )
这里只介绍简单的图例,参数很多很多,可以自行摸索。
图例有许多的关键字,可以设置关键字放置图例位置,还可以直接点击移动图例(手动设置位置),关键字如:bottom、bottomleft、left、topleft、top、topright、right、bottomright、center。如果用了关键字还可以使用inset参数设置图例向图形内测移动的大小,用绘图取余大小的分数表示。cex设置图例字体大小。
以下举例用于展示使用了关键字,图例显示位置以及展示layout函数使用。
> layout(matrix(c(1,2,3,4),2,2))#列排,按矩阵排法画图,2行2列> plot41<-plot(a,b,type="l",pch=23,col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="关键字bottom,图1",sub="plot41") > lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("bottom",inset=0.05,cex=0.4,title="图例",c("线1","线2"),pch=c(23,21 ),text.col=2)> > plot42<-plot(a,b,type="l",pch=23,col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="关键字bottomleft,图2",sub="plot42")> lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("bottomleft",cex=0.4,inset=0.05,title="图例",c("线1","线2"),pch=c(23,21 ),text.col=2)> > plot43<-plot(a,b,type="l",pch=23,col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="关键字left,图3",sub="plot43")> lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("left",inset=0.05,cex=0.4,title="图例",c("线1","线2"),pch=c(23,21 ),text.col=2)> > plot44<-plot(a,b,type="l",pch=23,col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="关键字topleft,图4",sub="plot44")> lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("topleft",inset=0.05,cex=0.4,title="图例",c("线1","线2"),pch=c(23,21 ),text.col=2)结果如下:
> layout(matrix(c(1,2,3,4,5,0),2,3,byrow=T)) #按行排列绘图> plot45<-plot(a,b,type="l",pch=23,col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="关键字top,图5",sub="plot45")> lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("top",inset=0.05,cex=0.4,title="图例",c("线1","线2"),pch=c(23,21 ),text.col=2)> > plot46<-plot(a,b,type="l",pch=23,col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="关键字topright,图6",sub="plot46")> lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("topright",inset=0.05,cex=0.4,title="图例",c("线1","线2"),pch=c(23,21 ),text.col=2)> > plot47<-plot(a,b,type="l",pch=23,col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="关键字为rigth,图7",sub="plot47")> lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("right",inset=0.05,cex=0.4,title="图例",c("线1","线2"),pch=c(23,21 ),text.col=2)> > plot48<-plot(a,b,type="l",pch=23,col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="关键字为bottomright,图8",sub="plot48")> lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("bottomright",inset=0.05,cex=0.4,title="图例",c("线1","线2"),pch=c(23,21 ),text.col=2)> > plot49<-plot(a,b,type="l",pch=23,col="blue",xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="关键字为center图9",sub="plot49")> lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("center",inset=0.05,cex=0.4,title="图例",c("线1","线2"),pch=c(23,21 ),text.col=2)结果如下:
16.在图上添加文字
使用text()函数可在图形任意位置添加文字。
在图片上标上线条名称,举例如下:
> lines1<-plot51<-plot(a,b,type="b",pch=23,col="blue",col.axis=2,xlim=c(0,40),ylim=c(5,65),col.main=2,col.sub="blue",main="添加文字",sub="plot51")> lines2<-lines(c(5,10,20,25,32,35),c(5,25,35,45,50,55),type="b",pch=21,col="red")> legend("topleft",inset=0.05,cex=0.8,title="lines",c("lines1","lines2"),pch=c(23,21),text.col=2)> text(27,60,"lines1",col="blue")> text(35,45,"lines2",col="red")结果如下:
在无法准确获取图片坐标的情况下可以使用函数locator()获取精确坐标,只需运行下面代码,后再图片上点击你想获取坐标的位置,会返回坐标结果。
> locator(1) #直接回车,点击图片上想获取坐标的位置17.R的撤销图片操作
使用recordplot()与replayplot()函数保存与撤销操作,解释如下:
> #plot1<-plot(·······)> chetu<-recordplot() #记录plot1绘制的图,chetu 这个东西是随便设哈!> text(········) #加上文字,不一定是text,还可以其他函数,只要再图上 > #(接上行)进一步操作(plot1)都可以撤回> replayplot(chetu) #撤回上一步操作到这里,R自带的plot函数部分参数介绍到这里,自带的画图函数还是具有局限性,建议使用ggplot2包画图,可以画多种多样的图,美观漂亮,个人感觉ggplot2难一点,参数用法多,这里我就不介绍了(太难讲了,细节太多)。
*****
个人感觉R代码深入学习后具有强烈的创造性,在面对实际应用分析不同数据时具有很高的灵活性。
*****
致读者:本篇文章所有代码为原所创,内容为学完R后的个人总结,文章中的大部分函数因为参数复杂丰富,没有一一举例,所以如果文章内容或代码有问题,欢迎各位大佬评论区留言批评指正,同志们加油!!。