找往期文章包括但不限于本期文章中不懂的知识点:
个人主页:我要学编程(ಥ_ಥ)-CSDN博客
所属专栏: Python
目录
元组
相关概念
元组的创建与删除
元组的遍历
元组生成式
字典
相关概念
字典的创建与删除
字典的遍历与访问
字典的相关操作方法
字典生成式
元组
相关概念
元组是Python中内置的不可变序列,与上次我们学习的列表不同,因此元组中不存在增加、删除、修改元素的相关操作。
在Python中使用 () 定义元组,元素与元素之间使用英文的逗号分隔。
同样元组也是属于序列的,因此操作序列的一系列方法也是可以给元组使用的。
元组的创建与删除
语法:
# 使用()的方式创建元组元组名 = (element1, element2, ..., elementN)# 使用内置函数tuple()创建元组元组名 = tuple(序列)代码演示:
# 创建元组# 使用()创建元组t1 = (1,'Hello',[1,2,3])print(t1) # 输出为 (1, 'Hello', [1, 2, 3])# 使用内置函数tuple创建元组t2 = tuple('Hello') # 字符串是序列print(t2) # 输出为 ('H', 'e', 'l', 'l', 'o')t3 = tuple([10,'Hello']) # 列表是序列print(t3) # 输出为 (10, 'Hello')从上面的输出结果,我们可以得出一个结论:使用内置函数去创建元组时,序列中的基础元素会被拆解开来,而使用 () 去创建元组,最终的结果就是 () 内部的一个一个的元素。
注意:当创建的元组中只有一个元素时,"逗号"是不能省略的。
代码演示:
t = (3)print(type(t)) # 输出为 <class 'int'> ——> 整型t = (3,)print(type(t)) # 输出为 <class 'tuple'> ——> 元组类型元组的删除和列表是一样的,也是使用 关键字 del。
语法:
del 元组名元组的遍历
与列表一样,有三种常见的遍历方式:
1、使用for循环:
t = ('Hello', 'Python',123)for item in t: print(item, end=' ') # 输出为 Hello Python 1232、使用for循环+range索引:
t = ('Hello', 'Python',123)for i in range(0,len(t)): print(t[i],end=' ') # 输出为 Hello Python 1233、使用 enumerate 函数:
语法结构:
for index, item in enumerate(t): print(index, item) # index 是序号,不是索引。序号可以手动设置起始位置,索引是不变的# item 是列表的元素代码演示:
t = ('Hello', 'Python',123)for index,item in enumerate(t, 1): print(index,item)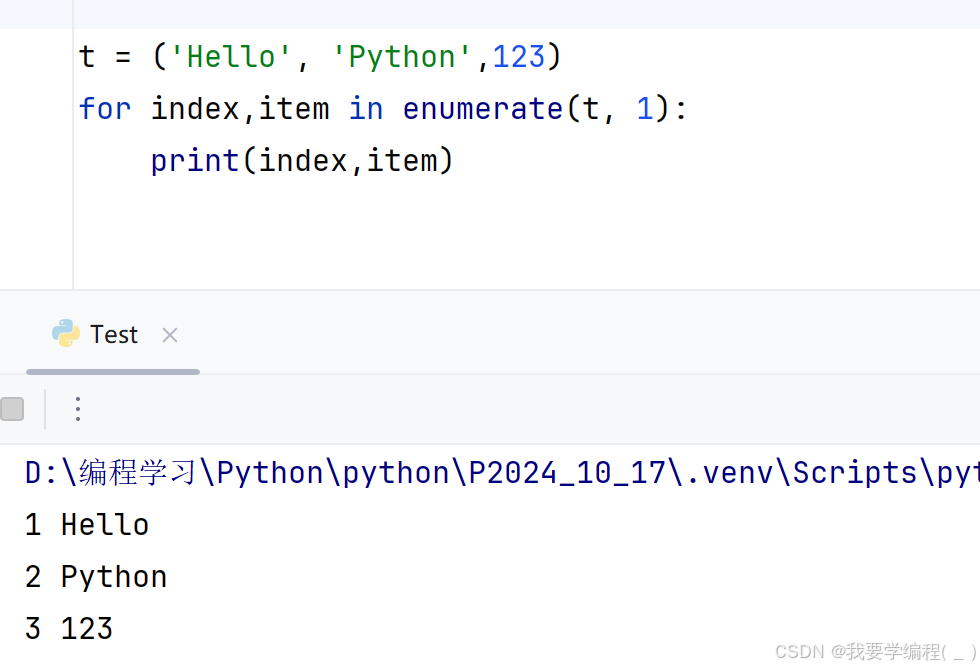
元组生成式
元组生成式与列表生成式有些不同,列表生成式是直接生成了一个列表对象,而元组生成式是生成了一个生成器对象,需要我们手动地去转换为元组或者列表才行。
代码演示:
# 元组生成式t = (i for i in range(1,4))print(t)# 转换为列表l = list(t)print(l)# 转换为元组t = tuple(t)print(t)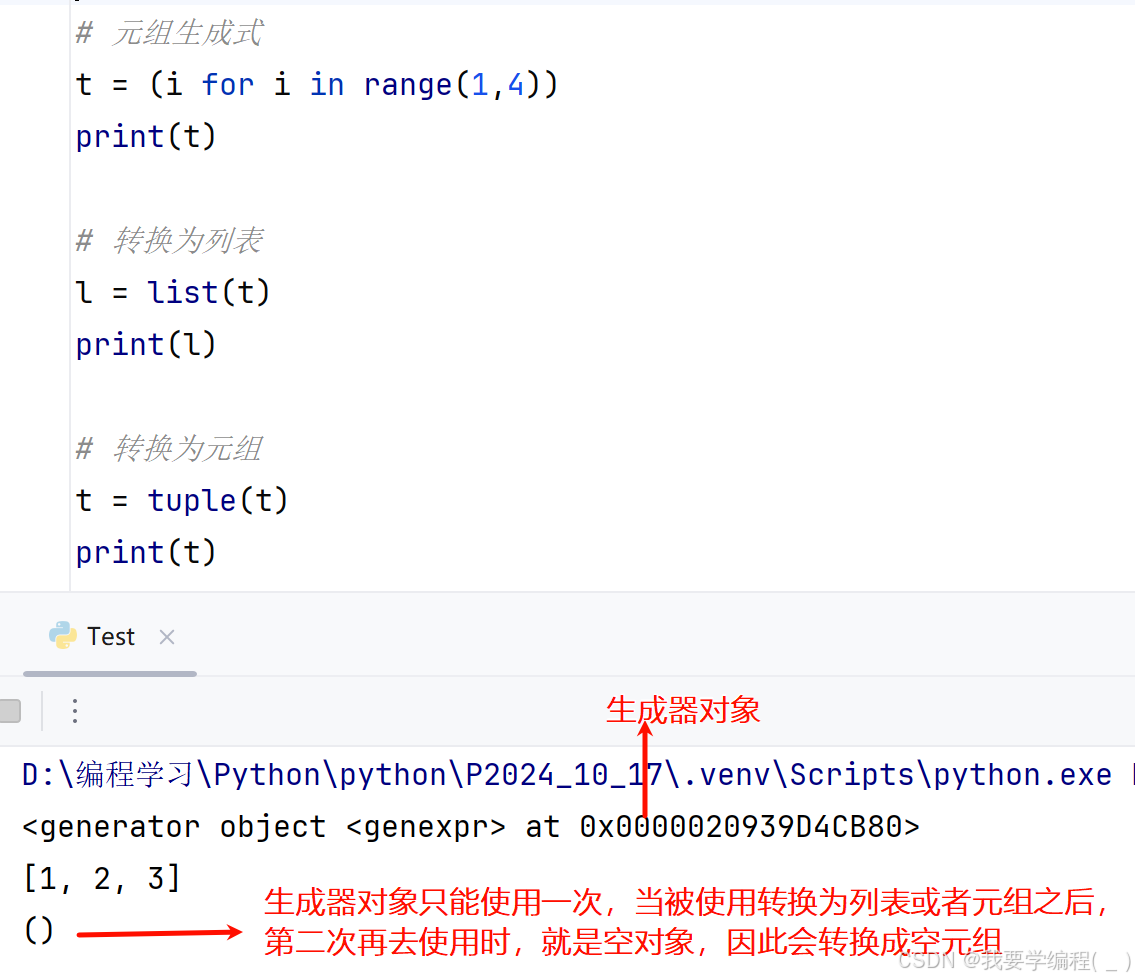
当然,除了转换为列表或者元组之外,还可以直接使用for循环和"__next__方法"去遍历生成器对象。
代码演示:
for循环:
t = (i for i in range(1,4))for item in t: print(item,end=' ') # 输出为 1 2 3 __next__方法:这个next前后都是有两个下划线的。
t = (i for i in range(1,4))print(t.__next__()) # 输出为 1print(t.__next__()) # 输出为 2print(t.__next__()) # 输出为 3# __next__方法是每次从生成器对象中取出一个值# 因此我们都是把这个方法和for循环配合使用注意:只要这个生成器对象被遍历过一遍之后,这个生成器对象里面的内容就为空了,我们再去遍历就获取不到任何的元素了。
以上就是元组的全部内容了,下面我们来学习字典。
字典
相关概念
字典类型是根据一个信息查找另一个信息的方式构成了“键值对”,它表示索引用的键和对应的值构成的成对关系。如果学过数据结构的小伙伴,应该对这个概念很熟悉,哈希表就是通过哈希函数的映射方式实现了键值对的时间复杂度为O(1)的查找,而字典就是在数据结构中所学的哈希表。
字典和列表一样是可变的数据类型,具有增删改查的相关操作。在 Python 3.6 及以后的版本中,字典的键在插入顺序上是保持有序的。而在之前的版本中,字典中的键通常被认为是无序的。因为其底层的实现方式就是哈希函数的映射。 虽然现在字典中的键是在插入的顺序上保持有序的,但是我们仍然认为字典的键是无序的。
即字典本身的键是无序的,之所以在输出时,看起来处于有序的状态,是因为Python解释器的处理。
字典中的键要求是不可变的数据类型,且键是不能重复的,但是值是可以重复的。
字典也是序列,因此操作序列的方法也是可以用来操作字典的。
字典的创建与删除
语法结构:
# 使用{}直接创建字典d = {key1:value1, key2:value2,......}# 使用内置函数创建字典# 1、通过映射函数zip创建字典# lst1、lst2一定要是可迭代的对象zip(lst1, lst2) # lst1对应着键,lst2对应着值(两者的数量要一一对应)# 2、通过dict()创建字典d = dict(key1=value1, key2=value2,......)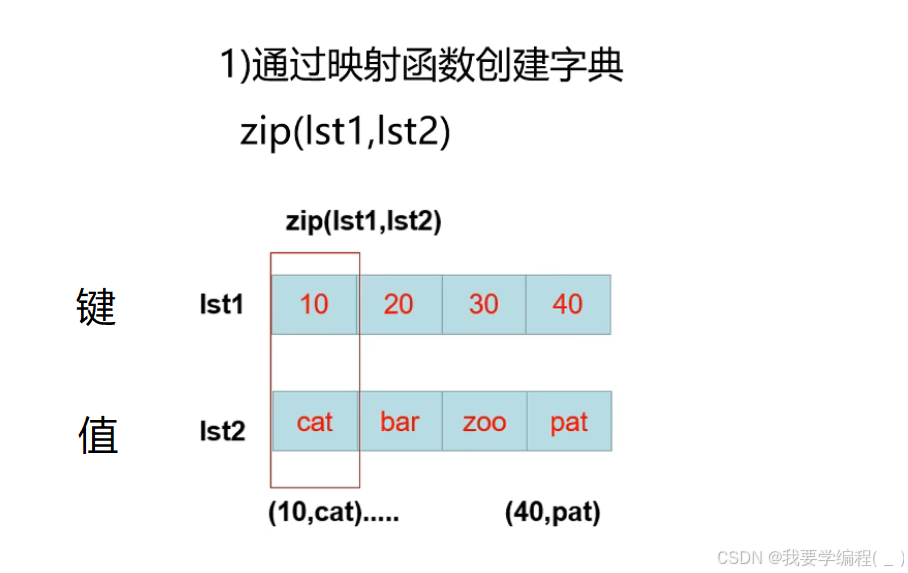
代码演示:
# 1、使用{}方式创建d = {1:'Hello',2:'World',3:'Python'}print(d) # 输出为 {1: 'Hello', 2: 'World', 3: 'Python'}# 当键冲突时,前面的值会被覆盖d = {1:'Hello',2:'World',3:'Python',3:'Java'}print(d) # 输出为 {1: 'Hello', 2: 'World', 3: 'Java'}# 2、使用dict()创建d = dict(Hello=1,Python=2) # 这里的Hello会被当作字符串,作为键print(d) # 输出为 {'Hello': 1, 'Python': 2}# 不能直接将数字字面值作为键# d = dict(1=Hello,2=Python) ——> error# 3、使用zip函数创建字典z = zip([1,2,3],['Hello','Python','Java'])print(z) # 这里也是生成的zip对象# zip对象需要转换为列表、元组、字典才行,同样只能这个对象只能使用一次# print(list(z)) # 输出为[(1, 'Hello'), (2, 'Python'), (3, 'Java')]# print(tuple(z)) # 输出为 ((1, 'Hello'), (2, 'Python'), (3, 'Java'))print(dict(z)) # 输出为 {1: 'Hello', 2: 'Python', 3: 'Java'}注意:使用zip函数去创建zip对象时,lst1的元素必须是不可变类型。例如,lst1本身可以是不可变类型,但是其内不能嵌套列表,因为列表是可变的数据类型,不能作为键。
z = zip(([1,2],[3,4]),('Hello','World'))print(dict(z)) # 这里会报错但是如果我们将 zip对象 转换为元组或者列表的话,是可以成功的,因为元组和列表没有规定。
1、转换为列表:
z = zip(([1,2],[3,4]),('Hello','World'))print(list(z)) # 输出为 [([1, 2], 'Hello'), ([3, 4], 'World')]2、转换为元组:
z = zip(([1,2],[3,4]),('Hello','World'))print(tuple(z)) # 输出为 (([1, 2], 'Hello'), ([3, 4], 'World'))删除的字典的语法:
del 字典名字典的遍历与访问
字典的访问与元组和列表的访问有所不同,其有两种访问方式:
1、通过 d[key] 去访问对应的值:
2、通过 d.get(key) 去访问对应的值:
代码演示:
d = {1:'Hello',2:'World',3:'Python'}print(d[1]) # 输出为 Helloprint(d.get(3)) # 输出为 Python注意:当 键 不存在时,d[key]的方式会报错,而d.get(key)会返回一个默认值:None,当然也可以指定返回默认值。
d = {1:'Hello',2:'World',3:'Python'}print(d.get('Java',2)) # 输出为 2这个默认值,可以随便是什么类型的数据。可以字符串、整型、列表等。
字典的遍历语法:
# 1、遍历key与value的元组for element in d.items(): print(element)# 2、分别遍历key和valuefor key,value in d.items(): print(key,value)代码演示:
1、遍历key与value的元组:
d = {1:'Hello',2:'World',3:'Python'}for element in d.items(): print(element,end=' ') # 输出为 (1, 'Hello') (2, 'World') (3, 'Python')2、分别遍历key与value:
for key,value in d.items(): print(key,'-->',value)# 输出为# 1 --> Hello# 2 --> World# 3 --> Python字典的相关操作方法
字典有一系列相关的操作方法:
| 字典的方法 | 描述说明 |
| d.keys() | 获取所有的key数据 |
| d.values() | 获取所有的value数据 |
| d.pop(key, default) | key存在获取相应的value,同时删除key-value对,否则获取默认值 |
| d.popitem() | 随机从字典中取出一个key-value对,结果为元组类型,同时将该key-value从字典中删除 |
| d.clear() | 清空字典中所有的key-value对 |
下面我们就来演示:
d = {1:'Hello',2:'World',3:'Python'}print(d) # {1: 'Hello', 2: 'World', 3: 'Python'}# 增加元素,直接可以赋值d[4] = 'Java'print(d) # {1: 'Hello', 2: 'World', 3: 'Python', 4: 'Java'}# 获取所有的keykeys = d.keys()print(keys) # dict_keys([1, 2, 3, 4])print(list(keys)) # [1, 2, 3, 4]print(tuple(keys)) # (1, 2, 3, 4)# 获取所有的valuevalues = d.values()print(values) # dict_values(['Hello', 'World', 'Python', 'Java'])print(list(values)) # ['Hello', 'World', 'Python', 'Java']print(tuple(values)) # ('Hello', 'World', 'Python', 'Java')# 将字典的元素转为 key-value的形式,以元组的形式进行展现z = d.items()print(z) # dict_items([(1, 'Hello'), (2, 'World'), (3, 'Python'), (4, 'Java')])print(list(z)) # [(1, 'Hello'), (2, 'World'), (3, 'Python'), (4, 'Java')]print(tuple(z)) # ((1, 'Hello'), (2, 'World'), (3, 'Python'), (4, 'Java'))print(dict(z)) # {1: 'Hello', 2: 'World', 3: 'Python', 4: 'Java'}# 找到对应key的value,并从字典中删除print(d.pop(1)) # Helloprint(d) # {2: 'World', 3: 'Python', 4: 'Java'}print(d.pop(5,"没找到")) # 如果不设置默认值,那么找不到就会报错# 随机找到一对key-value,并从字典中删除print(d.popitem()) # (4, 'Java')-->这是随机删除的print(d) # {2: 'World', 3: 'Python'}# 清空字典d.clear()print(d) # {}注意:
1、在字典中添加元素是直接使用 d[key] = value 的方式。
2、使用 d.keys() 和 d.values() 得到的结果是与我们之前学习的列表生成式、元组生成式不一样。虽然两者都是迭代器,但是前者是可以循环遍历的,也就是可以转换多次,而后者只能使用一次。
字典生成式
语法格式:
# 第一种方式:d = {key:value for item in range}# 第二种方式:d = {key:value for key,value in zip(lst1,lst2)}代码演示:
# 第一种方式:# 0-2作为键、1-100之间的数作为值d = {item:random.randint(1,100) for item in range(3)}print(d) # {0: 22, 1: 65, 2: 52} -> 随机的值# 第二种方式:lst1 = [1,2,3]lst2 = ['张三','李四','王五']d = {key:value for key,value in zip(lst1,lst2)}print(d) # {1: '张三', 2: '李四', 3: '王五'}以上就是字典的全部内容了。
我们现在学习的三种数据类型:列表、元组、字典都是属于序列的一种。
好啦!本期 初始Python篇(4)—— 元组、字典 的学习之旅到此结束啦!我们下一期再一起学习吧!