
文章目录
一、文件的随机读取函数1.fseek函数2.ftell函数3.rewind函数 二、文件读取结束的判断1.被错误使用的feof2.判断文件读取结束的方法3.判断文件结束的原因feofferror判断文件读取结束原因示例 三、文件缓冲区
一、文件的随机读取函数
在上一篇的文章中,我们讲到了文件顺序读取的各种函数,顺序读取也就是从开头读到结尾,没有选择,我们今天要讲的就是文件的随机读取
也就是我们不必按照文件的顺序进行读写,可以通过一些函数更改读写的位置,从而实现我们所说的随机读写,接下来我们就来学习这些函数
1.fseek函数
fseek函数用来定位文件内容的光标,光标默认在开头,如果读取了一个字符,那么光标就会往后面移动一位,而fseek函数可以通过偏移量来定位光标,然后我们就可以从定位的位置进行读写,我们来看看fseek的原型:
int fseek ( FILE * stream, long int offset, int origin ); 如果函数定位成功,那么就会返回0,定位失败就会返回一个非0值
它的第一个参数是我们要定位光标的流,第二个参数就是我们的偏移量,是一个长整型,它要根据我们的第三个参数来定,第三个参数origin可以是三个常量值,如下图:

当它取SEEK_SET时表示,光标的偏移量要从文件开头开始计算,当它取SEEK_CUR时,光标的偏移量要从当前光标位置开始计算,当取SEEK_END时,光标的偏移量要从文件尾开始计算,我们来举一个例子说明:
假设有一个文件中存储着abcde,现在光标的位置在a后面,如:
a | bcde我们想要获取字符d,那么就要把光标移动到d的前面,如下:
abc | de 那么这时我们就要计算偏移量,偏移量是针对第三个参数origin的不同取值的,当origin取SEEK_SET时,我们光标的偏移量要从文件开头开始计算,那么此时我们要把光标移动到d前面,偏移量就是3
当origin取SEEK_CUR时,光标的偏移量就要从当前光标位置开始计算,那么此时我们要把光标移动到d前面,偏移量就是2
当origin取SEEK_END时,光标的偏移量要从文件尾开始计算,那么此时我们要把光标移动到d前面,偏移量就是-2
所以偏移量不是绝对的,要看fseek第三个参数的取值
接下来我们就来看一段代码,尝试分析代码运行的结果:
#include <stdio.h>int main(){FILE* pf = fopen("test.txt", "w");if (pf == NULL){perror("fopen");return 1;}fputs("This is an apple.", pf);fseek(pf, 9, SEEK_SET);fputs(" orange", pf);fclose(pf);pf = NULL;return 0;}首先程序以写的方式打开了当前目录下的文本文件test.txt,然后写入了一句英文:
This is an apple.然后对文件里的光标位置做了更改,它的含义就是将光标移动到从文件开头计算,偏移量为9的位置,我们经过计算,应该在以下这个位置:
This is a|n apple.光标在a和n的中间,那么这时我们又进行了写入,写入了如下字符串:
book要注意的是,book的前面有一个空格,所以我们写入时不要把这个空格忘记了,使用w写的时候,会覆盖之前的数据,所以空格会覆盖n,book会覆盖 app,所以写入之后,应该是这个样子的字符串:
This is a bookle. 我们来运行一下这个程序,然后去看看我们的test.txt的内容和我们的预期是否相同,如下:

可以看到代码的结果正如我们所料,但是我们还是有一些疑问,我们难道每一次都去数偏移量吗?有没有什么办法可以计算偏移量呢?就要看我们接下来要学习的函数:ftell了
2.ftell函数
ftell函数的作用就是返回当前文件光标到文件开头的偏移量,我们来看看它的原型:
long int ftell ( FILE * stream ); 它的原型看起来也很好理解,参数就是我们要操作的流,返回值是长整型,返回的就是当前文件光标到文件开头的偏移量
接下来我们直接来看例子,看看代码运行会发生什么:
代码的前提是,当前目录下有一个test.txt文件,里面的内容是hello world!
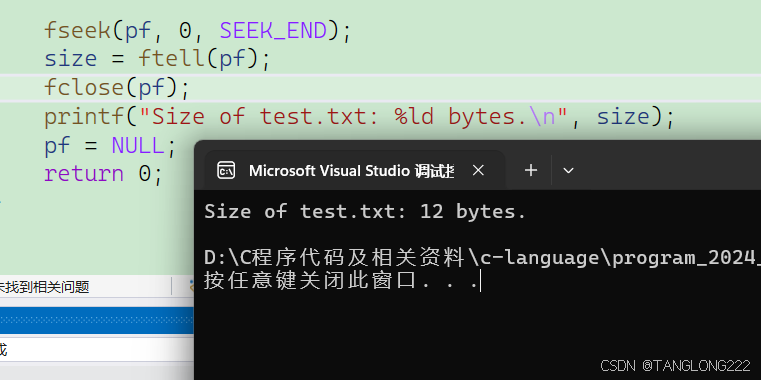
#include <stdio.h>int main(){long size;FILE* pf = fopen("test.txt", "r");if (pf == NULL){perror("fopen");return 1;}fseek(pf, 0, SEEK_END); size = ftell(pf);fclose(pf);printf("Size of test.txt: %ld bytes.\n", size);pf = NULL;return 0;} 首先程序打开了文件test.txt,创建了一个长整型变量size,随后使用了fseek函数,我们要看得懂这句代码是什么意思,它的意思就是,将文件光标移动到离文件结尾偏移量为0的地方,实际上就是把光标移动到了文件末尾
然后此时我们使用ftell函数算出文件开头到光标的偏移量,也就是文件开头到文件末尾的偏移量,那么算出来的将会是我们字符的个数,而一个字符占用一个字节,所以我们就间接算出来了文件内容的大小
我们来看看代码运行结果:
3.rewind函数
rewind函数的作用就比较简单了,就是把文件中的指针位置重置到文件开头,我们来看看它的原型:
void rewind ( FILE * stream ); 它的参数就是我们要操作的流,没有返回值,从原型看就可以发现它应该是一个很简单的函数,它的作用就是将文件光标移动到开头,然后我们可以重新在开头对文件进行读写
接下来我们直接上案例,来看看代码运行结果:
#include <stdio.h>int main(){int i;char buffer[27];FILE* pf = fopen("test.txt", "w+");if (pf == NULL){perror("fopen");return 1;}for (i = 'A'; i <= 'Z'; i++){fputc(n, pf);}rewind(pf);fread(buffer, 1, 26, pf);fclose(pf);pf = NULL;buffer[26] = '\0';printf(buffer);return 0;} 首先,程序以读写的方式打开了当前目录下的test.txt文件,然后将大写字母A到Z的字符写入到了我们的test.txt文件中,随后就到了我们的rewind函数,它直接就将我们的光标移动到了开头
然后我们就又使用了fread函数将pf中的数据读了出来,然后关闭文件,打印了读出的数据
现在唯一的问题是,我们之前讲的fread是对二进制文件进行操作,那么它能不能对普通文本文件进行操作呢?我们来看看代码的运行结果:
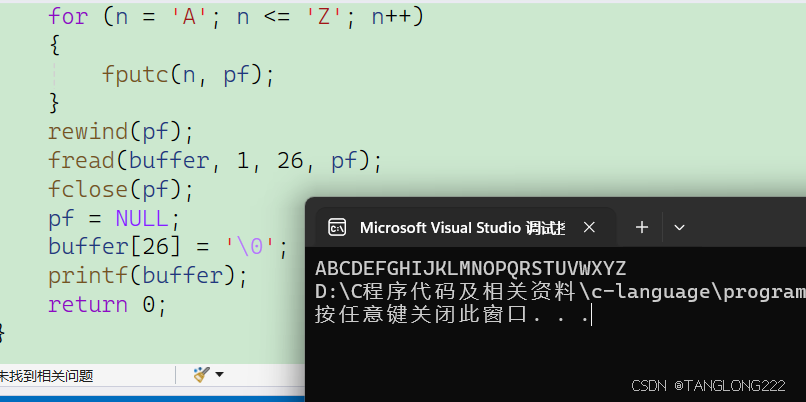
可以看到代码成功把文件中的内容读出来了,说明fread既可以读取二进制文件和文本文件,这是为什么呢?我们可以在cplusplus.com这个链接下搜索这个函数,看看这个函数是如何解释的:
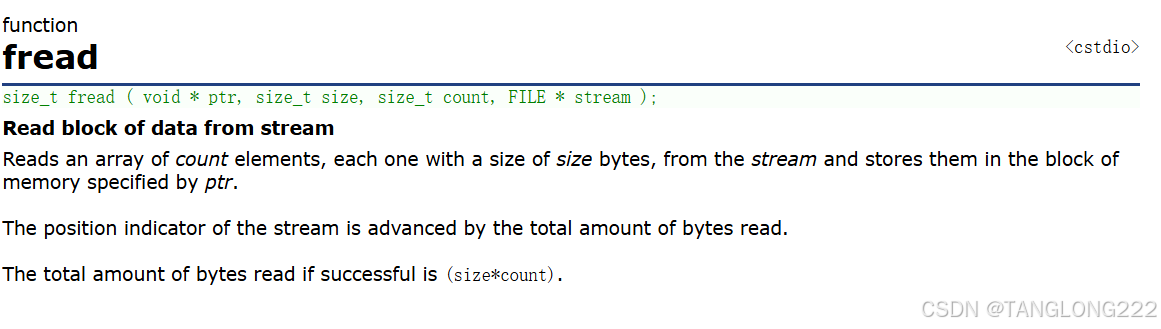
可以看到fread是一个函数,它的原型我们也解释过,这里不多说了,我们可以看下一行加粗的字体,翻译过来就是,从流中读取数据块,看到这个解释我们就知道了,它读取时不是 只能读取二进制,而是可以读取数据块
所以在传参时我们才要传元素个数和元素大小,而读取数据块就不会分它是文本文件还是二进制文件,函数也没有明确说只能读取二进制文件,只是它可以读取二进制文件而已
而另一个函数fwrite和函数fread也是一样的,它既可以写入文本数据又可以写入二进制数据,因为它写入的时候也是按照数据块进行写入
二、文件读取结束的判断
1.被错误使用的feof
牢记:在⽂件读取过程中,不能⽤feof函数的返回值直接来判断⽂件的读取是否结束,feof 的作⽤是:当⽂件读取结束的时候,判断是读取结束的原因是否是:遇到⽂件尾结束
再通俗一点的说,feof使用的前提就是文件的读取已经结束了,它的作用就是在文件读取结束后判断文件是不是读到末尾结束,如果我们用它去判断文件读取是否结束,很明显是错误的
2.判断文件读取结束的方法
所以我们对不同的文件,提供了不同的判断方法,如下:
(1)文本文件是否读取结束
根据我们的读取函数的返回值来确定,在上一篇文章中我们就学过了文件读取函数,这里我们就不再多赘述,如果忘记可以翻看上一篇文章:【C语言】文件操作(1)(文件打开关闭和顺序读写函数的万字笔记)
(2)二进制文件是否读取结束
fread判断返回值是否⼩于实际要读的个数3.判断文件结束的原因
刚刚我们学习了如何判断文件读取结束,那么文件读取结束了不一定就是正常的全部读取成功了,所以又会有正常读取结束和错误读取结束两种区别,正常读取结束就是文件读取到了文件末尾,错误读取就是因为某种原因读取出现错误了,没有读到文件末尾
那么我们怎么判断文件是正常读取结束还是错误读取结束了呢?一般是使用feof函数和ferror函数来进行判断
feof
feof函数我们在上面已经做了基本介绍,它的作用就是,在文件读取结束后,判断文件读取结束的原因是不是碰到了文件尾,我们来看看它的原型:
int feof ( FILE * stream );函数的参数是要操作的流,当文件是正常读取结束,也就是文件是因为读到末尾了而结束,就返回一个非0值,非正常读取结束就返回0
ferror
ferror函数就是在文件读取结束后,用来判断文件是否是错误读取结束,和feof有点相似,只是判断的内容不同,我们来看看它的原型:
int ferror ( FILE * stream );它的参数也是要操作的流,如果文件是错误读取结束,那么就返回非0值,如果没有错误读取结束,也就是正常读取结束了,就返回0
判断文件读取结束原因示例
我们刚刚学习了feof和ferror函数,现在我们就来使用它们来判断文件结束的原因,要注意一个前提:当前目录下有一个文件test.txt,里面的内容是hello world!,接下来我们来看看怎么把这两个函数运用在实战上:
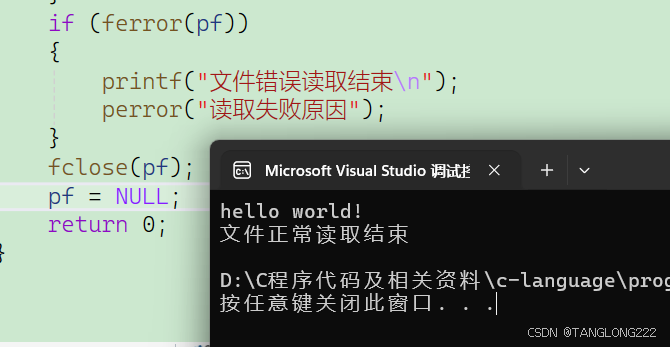
#include <stdio.h>int main(){char arr[20];FILE* pf = fopen("test.txt", "r");if (pf == NULL){perror("fopen");return 1;}fgets(arr, 20, pf);printf("%s\n", arr);if (feof(pf)){printf("文件正常读取结束\n");}if (ferror(pf)){printf("文件错误读取结束\n");perror("读取失败原因");}fclose(pf);pf = NULL;return 0;} 我们将读取到的字符串放在了arr中,然后我们来判断文件是否正常读取结束,如果正常读取结束就打印一下这句话,如果错误读取结束,那么就使用perror来打印一下读取失败的原因,最后我们来看看代码运行结果:
三、文件缓冲区
当我们对文件写入数据后,如果程序还在进行,并且没有关闭文件,那么我们会发现,我们写入的内容居然没有立刻就出现在文件中,而一旦关闭文件后写入的内容才出现在文件中,这是为什么呢?
这时我们就要引入文件缓冲区的概念了,ANSIC 标准采⽤“缓冲⽂件系统” 处理的数据⽂件的,所谓缓冲⽂件系统是指系统⾃动地在内存中为程序中每⼀个正在使⽤的⽂件开辟⼀块“⽂件缓冲区”
从内存向磁盘输出数据会先送到内存中的缓冲区,装满缓冲区后才⼀起送到磁盘上。如果从磁盘向计算机读⼊数据,则从磁盘⽂件中读取数据输⼊到内存缓冲区,充满缓冲区后再从缓冲区逐个地将数据送到程序数据区(程序变量等)
在文件中,有多种情况可以刷新缓冲区,将缓冲区的数据写入文件,我们这里就讲一下常用的三种情况
那么缓冲区具体有多大呢?这个是不确定的,要看编译器的具体实现
今天的内容就分享到这里啦,也是终于把文件操作写完了,文件操作还是挺难的,所以如果有什么问题欢迎在评论区留言或者私信我
bye~