YOLO V5模型 0 基础使用教程?
一. 官方工程文件解读?
以下是YOLO v5官方工程文件的一级目录结构:
.
├── benchmarks.py(py文件,Python脚本,用于评估YOLOv5模型的性能,比如检测速度和精度)
├── classify(文件夹,可能包含用于图像分类的代码)
├── CONTRIBUTING.md(markdown文件,贡献指南,说明如何为项目贡献代码或文档)
├── data(文件夹,通常包含用于训练和测试的数据集以模型训练对应的配置文件,包括图像文件和标注信息)
├── detect.py(py文件,用于执行目标检测任务,可以加载预训练模型并进行推理)
├── export.py(py文件, 用于将训练好的模型转换为其他格式,例如ONNX,以便于在不同平台上部署)
├── hubconf.py(py文件,可能与PyTorch Hub集成有关,用于发布和分享模型)
├── LICENSE(项目许可证文件,说明项目使用和分发的法律条款)
├── models(文件夹,包含模型定义的代码以及官方提供的权重文件,比如YOLOv5的网络结构)
├── README.md(markdown文件,项目的自述文件,通常包含项目简介、安装指南和使用说明。)
├── requirements.txt(txt文件,列出项目所需的依赖库,通常用 pip指令安装)
├── segment(文件夹,包含用于图像分割的代码和配置文件)
├── setup.cfg(cfg配置文件,用于设置Python包的安装选项)
├── train.py(py文件,用于训练YOLOv5模型,可能包含数据加载、模型定义、训练循环和验证步骤。)
├── tutorial.ipynb(Jupyter Notebook教程,用于指导用户如何使用YOLOv5)
├── utils(文件夹,包含一些辅助函数或工具,比如数据增强、日志记录等。)
└── val.py(py文件,用于模型的验证过程,评估训练过程中模型的性能)
这些文件是官方提供给我们的基础文件,通过这些文件我们就可以训练模型了。虽然凭借以上文件就可以训练模型了,但是训练出来的模型不是我们想要的。
要想训练出我们自己想要的模型离不开以下三样东西:
自己的数据集(训练集、测试集)配置文件(与数据集信息相匹配的配置文件)官方提供的工程文件(官方预训练的权重文件)二. 用自己的数据集训练模型?
1. 创建自己的数据集yaml配置文件
在 data 目录下,新建.yaml文件,名字自己取,我这里是traffic_data.yaml
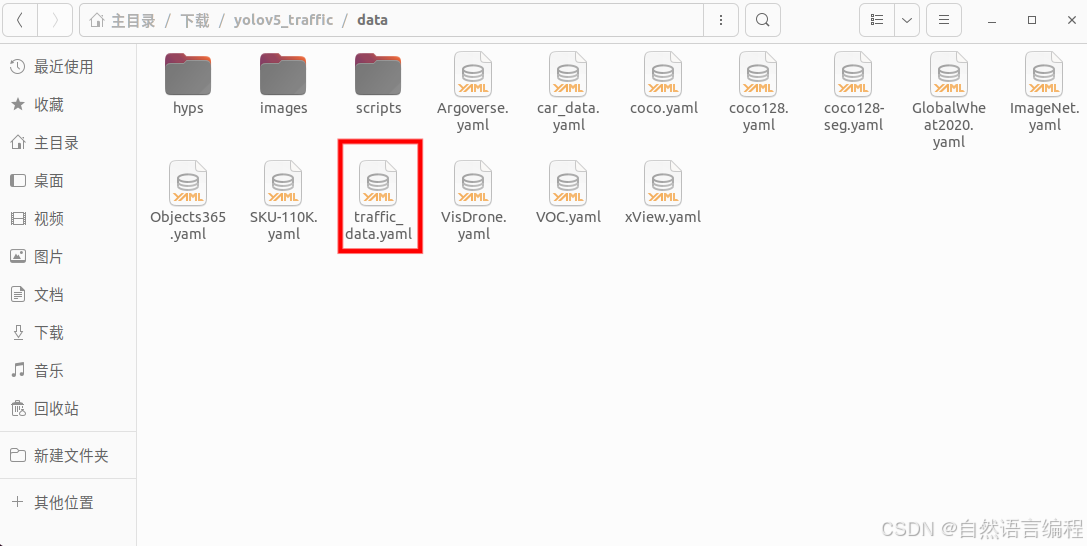
2. 对数据集进行划分
结构如下所示,其dataset放在yolov5-master文件夹第一层就好,或者随便放都行,推荐放yolov5-master文件夹第一层。训练集和验证集自己划分比例,一般都是30%作为验证集合,需要注意的是,文件夹命名按着下面的一样。
dataset/
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── …
│ ├── labels/
│ │ ├── image1.txt
│ │ ├── image2.txt
│ │ └── …
│ └── …
└── text
├──images/
│ ├── image101.jpg
│ ├── image102.jpg
│ └── …
├── labels/
│ ├── image101.txt
│ ├── image102.txt
│ └── …
└── …
3. 填写创建的yaml配置文件里的信息
将我们数据信息写入yaml文件,path写dataset的路径,train直接按着下面就行
path: ./dataset
train: train/images/
val: text/images/
Classes
names:
0: Speed limit (5km)
1: Speed limit (15km)
2: Speed limit (20km)
3: Speed limit (30km)
4: Speed limit (40km)
5: Speed limit (50km)
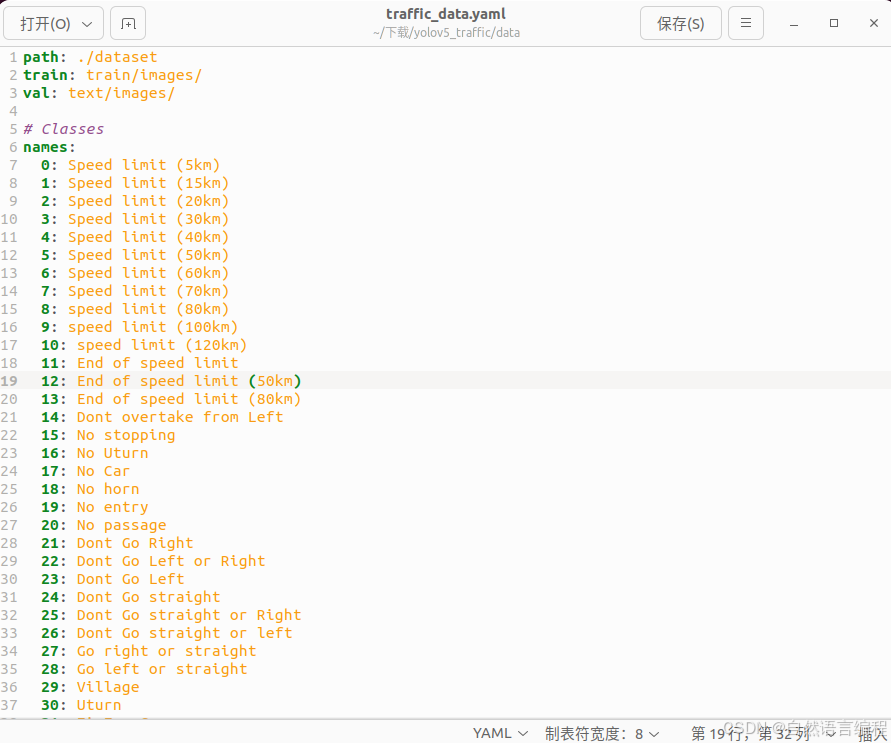
4. 修改代码
train.py中找到如下代码,按着图中的要求修改代码。
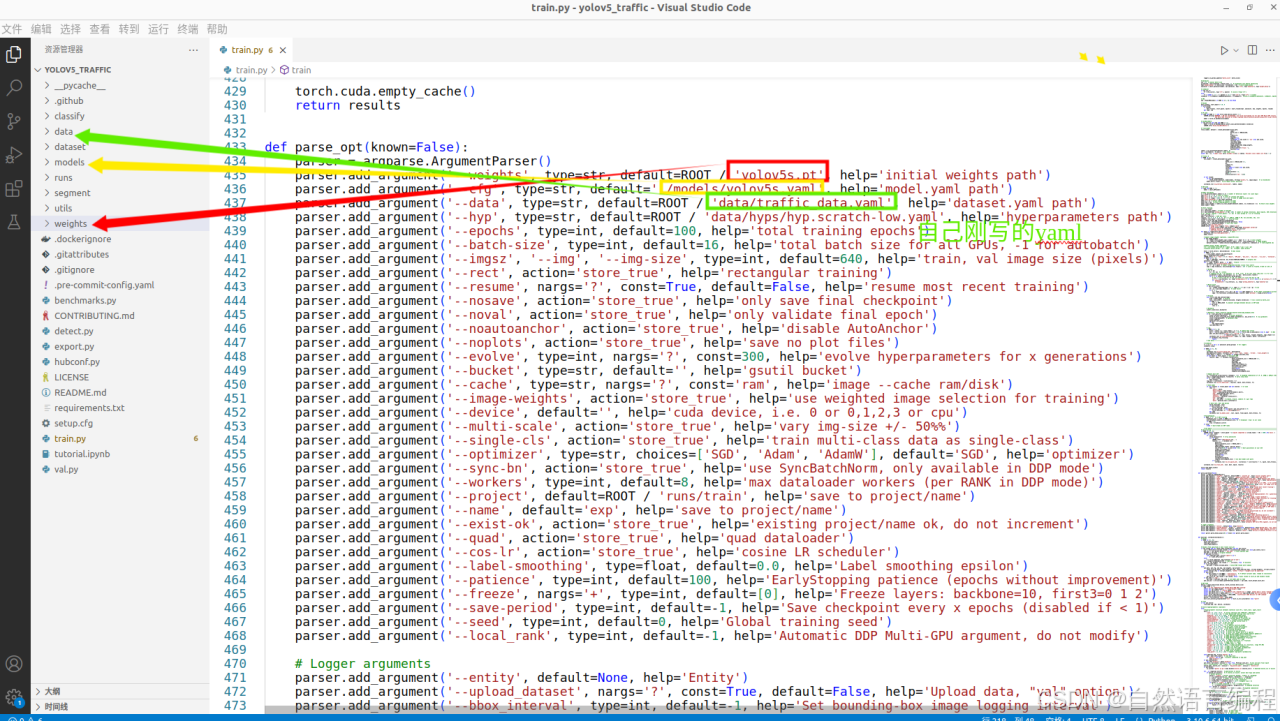
修改完之后保存即可。
5. 训练模型
python train.py --img 640 --batch 32 --epoch 101 --data data/traffic_data.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --device 0python train.py: 执行的Python脚本的名称。train.py是用于启动训练过程的脚本。--img 640: 指定输入图像的尺寸,这里是640 * 640像素。--batch 32: 设置一个批次(batch)的大小,即每次训练迭代中同时处理的图像数量,这里是32张图像。--epoch 101: 指定训练过程中要进行的迭代次数,称为"epoch"。每个epoch代表整个数据集被完整地遍历一次。这里是101个epoch。--data data/traffic_data.yaml: 指定数据配置文件的路径,data/traffic_data.yaml文件含训练数据的路径、类别信息等。--cfg models/yolov5s.yaml: 指定模型配置文件的路径,models/yolov5s.yaml这个文件定义了模型的架构,例如YOLOv5s模型。--weights weights/yolov5s.pt: 指定预训练模型权重的路径,weights/yolov5s.pt用于在训练开始时加载预训练的权重,以便更快地收敛或提高模型的性能。--device 0: 指定要使用的计算设备,这里是0。在多GPU环境中,可以通过指定不同的数字来选择不同的GPU设备。 当我们看到如下信息时,就说明模型已经训练完成:
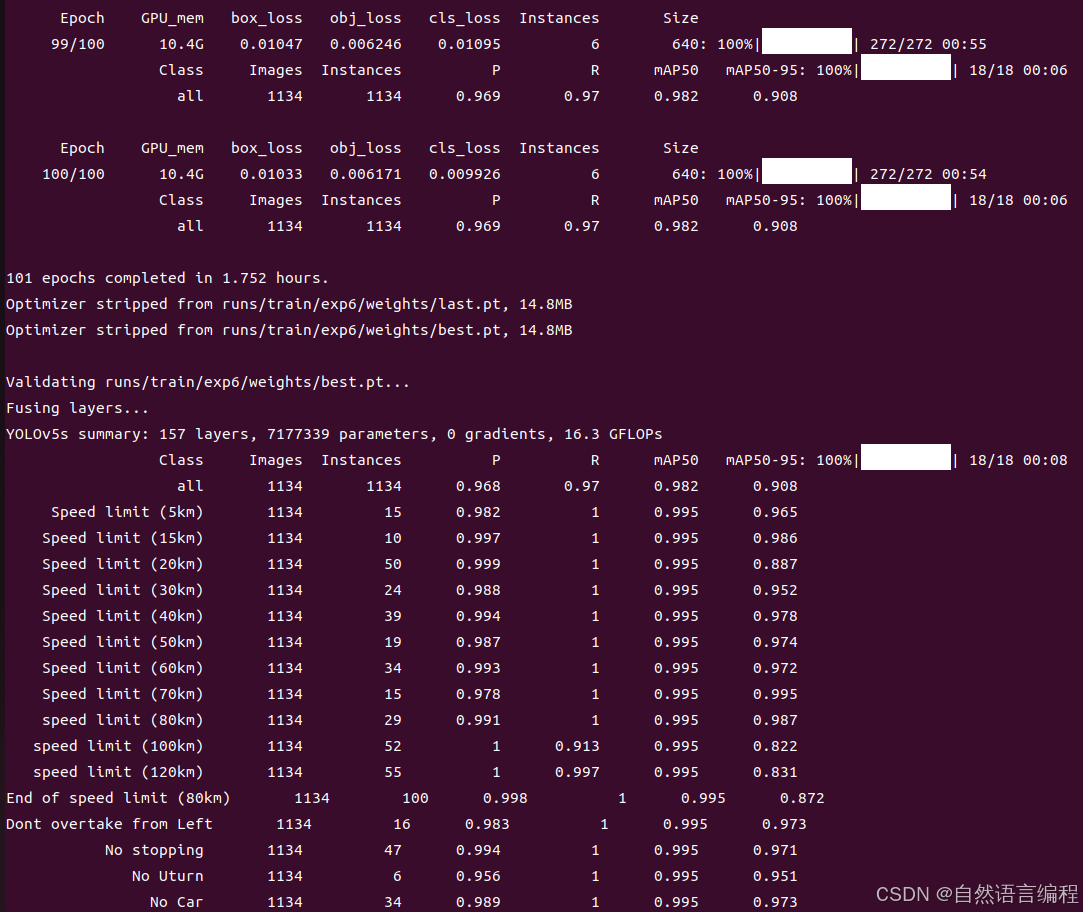
通过以上信息,我们可以大致判断出我们模型的训练效果。接下来,我们看看每一行信息的具体含义。
101 epochs completed in 1.752 hours. # 训练周期和时间:模型训练完成了101个epoch,在1.752小时内完成。Optimizer stripped from runs/train/exp6/weights/last.pt, 14.8MB # 代表最后一个epoch训练后的权重文件Optimizer stripped from runs/train/exp6/weights/best.pt, 14.8MB # 代表验证过程中表现最好的权重文件Validating runs/train/exp6/weights/best.pt... # 正在验证best.pt权重文件的性能。Fusing layers... YOLOv5s summary: 157 layers, 7177339 parameters, 0 gradients, 16.3 GFLOPs# 模型有157层。# 总共有7,177,339个参数。# 在验证过程中没有梯度计算(是因为在验证阶段不进行反向传播)。# 模型的浮点运算次数为16.3 GFLOPs(每秒浮点运算次数的十亿次)。同时在runs/train/exp6/也会生成本次模型训练结果的所有文件,我们可以在这个文件夹下看到模型训练的结果
上面显示可以让我们对模型有一个大概的判断,但是在实际中我们更关注下面这些信息:
class:类别。这是指在目标检测任务中需要识别的对象类别
Images:图像数量。这表示用于评估模型性能的图像总数(也就是测试集的图片数量)
Instances:实例数量。这表示所有测试集图像中,特定类别的对象出现的次数
P (Precision):精度。这是针对每个类别计算的,表示模型正确识别的正例占模型识别为正例的总数量的比例。(范围 0-1,数值越大越好)
R (Recall):召回率。也称为真正例率或灵敏度,表示模型正确识别的正例占实际正例总数的比例。(范围 0-1,数值越大越好)
mAP50:平均精度在50%交并比下。(数值越大越好)
mAP50-95:平均精度在50%到95%交并比范围内。(数值越大越好)
Epoch:训练周期。每个周期中模型都会遍历一次完整的数据集。一般设置在100左右,设置数值太小,模型可能捕获的特征不够,训练的效果不好;设置数值太大,模型容易过拟合,同样也会造成训练效果不好。
GPU_mem:GPU内存使用量。训练过程中使用的GPU内存大小
box_loss:边界框损失。这是评估模型预测的边界框与真实边界框之间差异的损失值,数值越小表示预测越准确。
obj_loss:目标损失。这是评估模型是否正确识别出图像中存在目标的损失值。
cls_loss:分类损失。这是评估模型对目标类别分类准确性的损失值。
Instances:实例数量。这表示在当前的训练批次(batch)中有多少个目标实例。
Size:图像尺寸。这表示训练使用的图像分辨率是640 * 640像素。
需要注意的是,我们在训练模型的时候,--img 应该设置成跟训练集测试集图片大小尺寸一样,这样训练出来的模型效果才比较好。
三. 利用训练好的模型,借助labelImg自动标注?
工程目录下打开文件detect.py文件,找到类sar_opt(),如下图:
差不多在200多行,会有一个**‘–save-txt’, action=‘store_false’, help=‘save results to *.txt’)**,这里需要改成store_false,原本是store_true。这样在推理的时候就可以生成txt文件。
四. 模型转换?
模型文件转换指令:
python export.py --weights runs/train/exp4/weights/best.pt --opset 11 --include onnx --batch 1 --img 720export.py: 这是执行转换操作的Python脚本文件。--weights: 此参数后面跟的是模型权重文件的路径。在这个例子中,runs/train/exp4/weights/best.pt是模型训练过程中保存的最佳权重文件的路径。--opset: 此参数后面跟的是ONNX操作集的版本。操作集版本决定了ONNX模型的兼容性和特性。在这个例子中,版本被设置为11。--include: 此参数用于指定导出的文件格式。onnx表示生成ONNX格式的文件。--batch: 此参数定义了导出模型的batch大小。在这个例子中,batch大小被设置为1,意味着模型将被导出为处理单个图像的版本。重文件的路径。
--opset: 此参数后面跟的是ONNX操作集的版本。操作集版本决定了ONNX模型的兼容性和特性。在这个例子中,版本被设置为11。--include: 此参数用于指定导出的文件格式。onnx表示生成ONNX格式的文件。--batch: 此参数定义了导出模型的batch大小。在这个例子中,batch大小被设置为1,意味着模型将被导出为处理单个图像的版本。--img: 此参数用于指定模型输入图像的尺寸。