YOLO V8目标检测
在之前的文章中讲述了在win11系统中如何部署并使用YOLO V8项目进行预测和训练,经过一段时间的目标检测源代码的学习来讲述YOLO v8网络模型的构建、预测、匹配、训练等一下几个方法来讲述YOLO v8网络。
YOLO v8网络结构
v8网络整体概述
YOLO V8在网络结构上的改进点主要体现在了一下几个方面:
在backbone主干网络中主要包括了
YOLOv8 继续采用 CSP (Cross Stage Partial networks)的设计理念,可以提高梯度流动并减少参数数量。YOLOv5中的C3模块在YOLOv8中被C2f模块所替代,这个变化是为了进一步的轻量化。C2f 模块融合了ELAN的设计思想head部分主要包括了(PAN+FPN)
YOLOv8 保留了PAN 的思想,这是一种特征融合策略,用于结合不同层次的特征以改善性能。检测头的部分:使用了解耦头的思想
YOLOv8 采用了 Decoupled-Head 的设计,这是一种将分类和定位任务分离的头部架构。YOLOv8 放弃了传统的 Anchor-Base 方法,转而采用了 Anchor-Free 的思想
损失函数部分:包括了定位和分类损失
YOLOv8 使用 BCE LOSS 作为分类损失, 并结合 DFL LOSS 与 CIOU LOSS 来作为定位损失。样本匹配(Sample Matching) :
在样本分配上,YOLOv8 抛弃了以往的IOU 匹配或单边比例分配方式,转而使用了Task-Aligned Assigner匹配方式,这可能有助于改善模型对于不同任务的适应性和整体性能。YOLO v8网络定义的基础模块都基础在moudle模块下的nn模块中
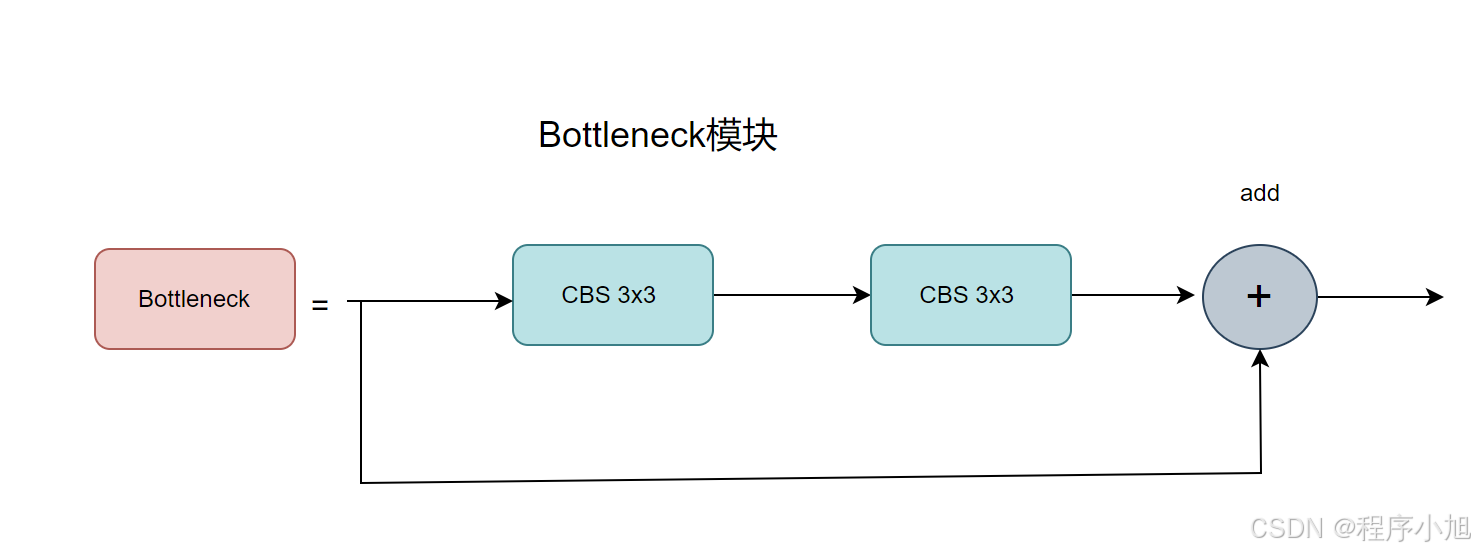
CBS模块
CBS模块是最基本的一个网络模块可以说是Yolo v7中的基础卷积模块 。CBS模块由三个部分拼接组成。在最后通过画图软件给出CBS模块的直观表示。
CONV:卷积层BN:批量归一化层SiLU:SiLU激活函数层CBS模块也就是三个拼接层的缩写,在ultralytics/nn/modules/conv.py的路径下面,该文件定义了所有的卷积结构。和网络的起始结构等。
class Conv(nn.Module): """Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation).""" default_act = nn.SiLU() # default activation # 使用卷积模块时候的构造函数 #c1 :输入通道的数量。c2 :输出通道的数量。k :卷积核的大小。s :卷积的步长。p :填充的大小,如果为 None ,则使用 autopad 函数自动计算。 #g :卷积的分组数量。d :卷积的扩张系数。act :激活函数,如果为 True ,使用默认的 SiLU 激活函数;如果是 nn.Module 类型的实例,则使用该激活函数;否则使用恒等激活函数 nn.Identity def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True): """Initialize Conv layer with given arguments including activation.""" super().__init__() self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False) self.bn = nn.BatchNorm2d(c2) self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity() def forward(self, x): """Apply convolution, batch normalization and activation to input tensor.""" return self.act(self.bn(self.conv(x)))同时,它也支持不同的激活函数选项,使得这个类在神经网络设计中非常通用。
此外,额外的 forward_fuse 方法提供了一种在不使用批量归一化的情况下应用卷积和激活函数的方式,增加了额外的灵活性。
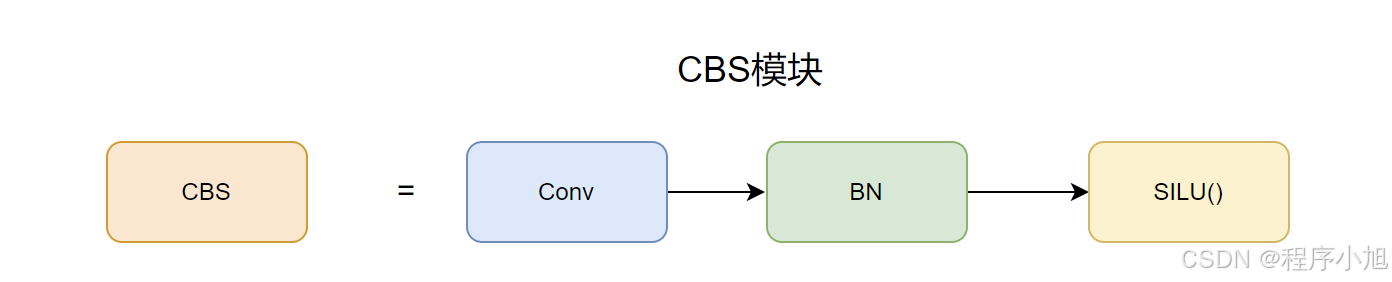
Bottleneck模块
Bottleneck 类定义了一个标准的瓶颈模块。这是深度神经网络中常见的架构组件,特别是在设计用于图像分类、目标检测等任务的模型。
ultralytics/nn/modules/block.py
构造函数设置了以下层:
c_ :根据 c2 和扩展因子 e 计算隐藏通道的数量。self.cv1 :一个将通道数从 c1 减少到 c_ 的卷积层,使用 k 中的第一个核大小。self.cv2 :另一个从 c_ 到 c2 的卷积层,使用 k 中的第二个核大小。如果 g 大于 1,该层还包括分组卷积。如果启用了快捷方式并且输入和输出通道大小相同,则将 self.add 属性设置为 True# Bottleneck模块class Bottleneck(nn.Module): """Standard bottleneck.""" def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): """Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and expansion. """ super().__init__() c_ = int(c2 * e) # hidden channels(中间隐藏层的通道数) self.cv1 = Conv(c1, c_, k[0], 1) self.cv2 = Conv(c_, c2, k[1], 1, g=g) self.add = shortcut and c1 == c2 def forward(self, x): """'forward()' applies the YOLO FPN to input data.""" return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))在backbone部分使用残差连接的方式,在head部分不使用残差连接的方式。
总结:Bottleneck 模块通过先减少通道数,然后再增加回原始通道数的方式来处理输入张量。
C2f模块
经过c2f模块并不改变通道数目,C2代表的是两个conv结构。C2f 类定义了一个更快的 CSP(Cross Stage Partial)瓶颈层实现,该层只使用了两个卷积层。
self.c :隐藏通道的数量,为 int(c2 * e) 。self.cv1 :一个将通道数从 c1 增加到 2 * self.c 的卷积层。self.cv2 :一个将通道数从 (2 + n) * self.c 减少到 c2 的卷积层。self.m :一个包含若干个 Bottleneck 模块的 ModuleList 。# C2f模块class C2f(nn.Module): """Faster Implementation of CSP Bottleneck with 2 convolutions.""" def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): """Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups, expansion. """ super().__init__() self.c = int(c2 * e) # hidden channels self.cv1 = Conv(c1, 2 * self.c, 1, 1) self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2) self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n)) def forward(self, x): """Forward pass through C2f layer.""" y = list(self.cv1(x).chunk(2, 1)) # 经过chunk操作分为两部分y0 y1 y.extend(m(y[-1]) for m in self.m) # 将y1送入bottleneck进行处理 extend拓展两个bottleneck部分 return self.cv2(torch.cat(y, 1)) def forward_split(self, x): """Forward pass using split() instead of chunk().""" y = list(self.cv1(x).split((self.c, self.c), 1)) y.extend(m(y[-1]) for m in self.m) return self.cv2(torch.cat(y, 1))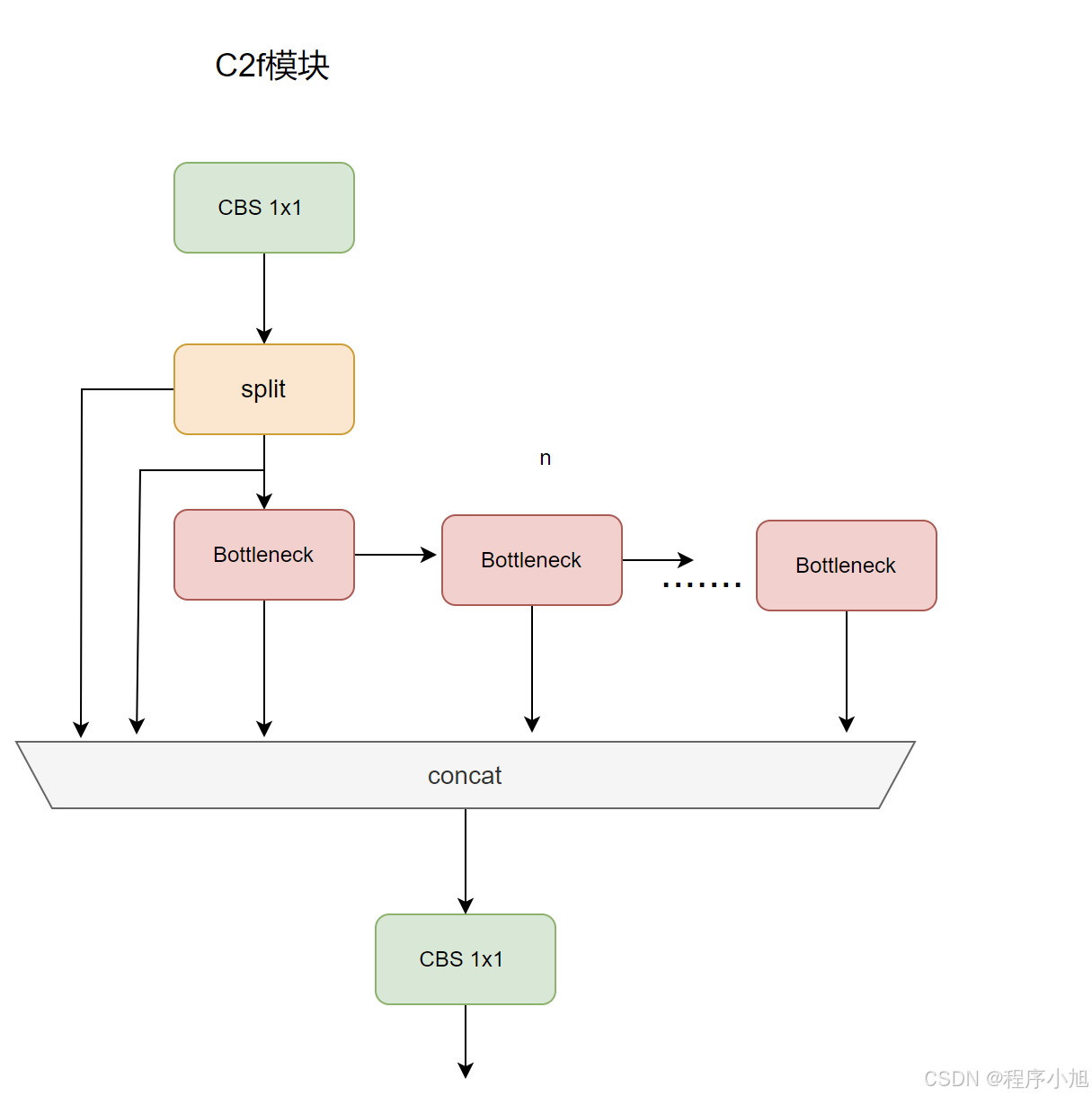
SPPF模块
快速-空间金字塔池化 (SPPF)层是backbone的最后一个模块,也可以看作是neck模块。
使用1 * 1的CBL和maxpooling,对输入进行特征提取和特征融合与SPP不同之处在于增加特征由浅入深的提取过程。
Spp部分主要使用在yolo v3+spp的部分中和yolo v4的网络中。
SPP全称为空间金字塔池化结构,主要是为了解决两个问题
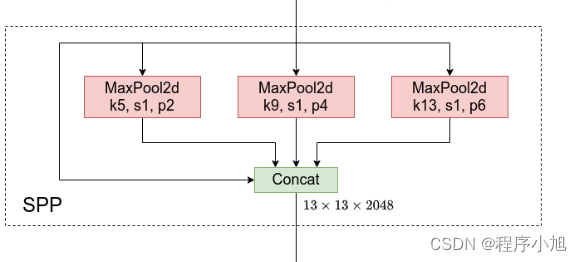
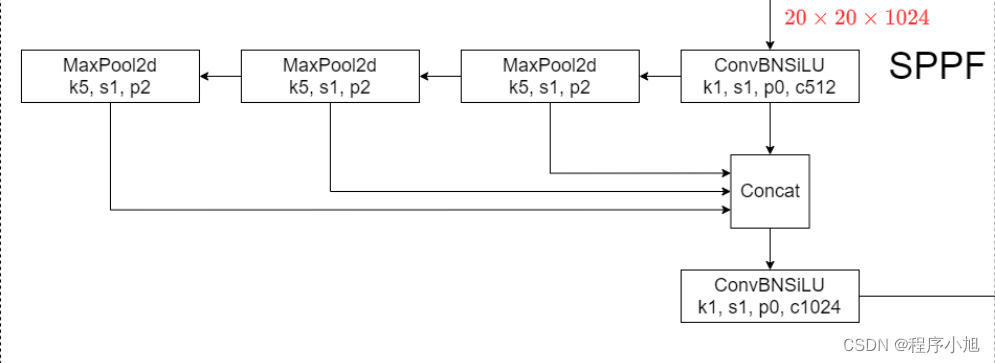
SPPF的三个maxpooling之间使用了串联的连接方式,在进行连接之后再次进入CBL模块中进行使用。
class SPPF(nn.Module): """Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher.""" def __init__(self, c1, c2, k=5): # k:池化和大小为5 """ Initializes the SPPF layer with given input/output channels and kernel size. This module is equivalent to SPP(k=(5, 9, 13)). """ super().__init__() c_ = c1 // 2 # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_ * 4, c2, 1, 1) self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) def forward(self, x): """Forward pass through Ghost Convolution block.""" y = [self.cv1(x)] y.extend(self.m(y[-1]) for _ in range(3)) return self.cv2(torch.cat(y, 1))特点:经过maxpooling不改变特征图的大小。
Detect模块
Detect 类是 YOLOv8 模型中的关键部分,负责将特征图转换为最终的检测输出,包括边界框和类别概率。这个类通过多个卷积层和自定义层处理输入特征图,最终生成用于目标检测的输出。
Detect模块中包括了推理解码等许多部分,这里只对模型结构的部分来进行说明。
class Detect(nn.Module): """YOLOv8 Detect head for detection models.""" dynamic = False # force grid reconstruction export = False # export mode end2end = False # end2end max_det = 300 # max_det shape = None anchors = torch.empty(0) # init strides = torch.empty(0) # init def __init__(self, nc=80, ch=()): # nc :类别数量。ch :每个检测层的通道数。 """Initializes the YOLOv8 detection layer with specified number of classes and channels.""" super().__init__() self.nc = nc # number of classes self.nl = len(ch) # number of detection layers 检测层的数量 self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x) DFL(Distribution Focal Loss)通道数 self.no = nc + self.reg_max * 4 # number of outputs per anchor self.stride = torch.zeros(self.nl) # strides computed during build c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channels self.cv2 = nn.ModuleList( #解耦头的上部分操作dfi + ciou nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch ) # 解耦头的下部分bce self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch) self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity() #dfl输入16 if self.end2end: self.one2one_cv2 = copy.deepcopy(self.cv2) self.one2one_cv3 = copy.deepcopy(self.cv3) def forward(self, x): """Concatenates and returns predicted bounding boxes and class probabilities.""" if self.end2end: return self.forward_end2end(x) # 循环遍历 self.nl (检测层的数量)。 # 对于每个特征图,通过两个卷积层( self.cv2[i] 和 self.cv3[i] )处理,然后将结果沿着通道维度拼接。 for i in range(self.nl): # 三个尺度每个尺度做拼接操作 x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1) if self.training: # Training path return x # 训练模式直接返回 y = self._inference(x) # 预测模式执行后面的推理操作 return y if self.export else (y, x)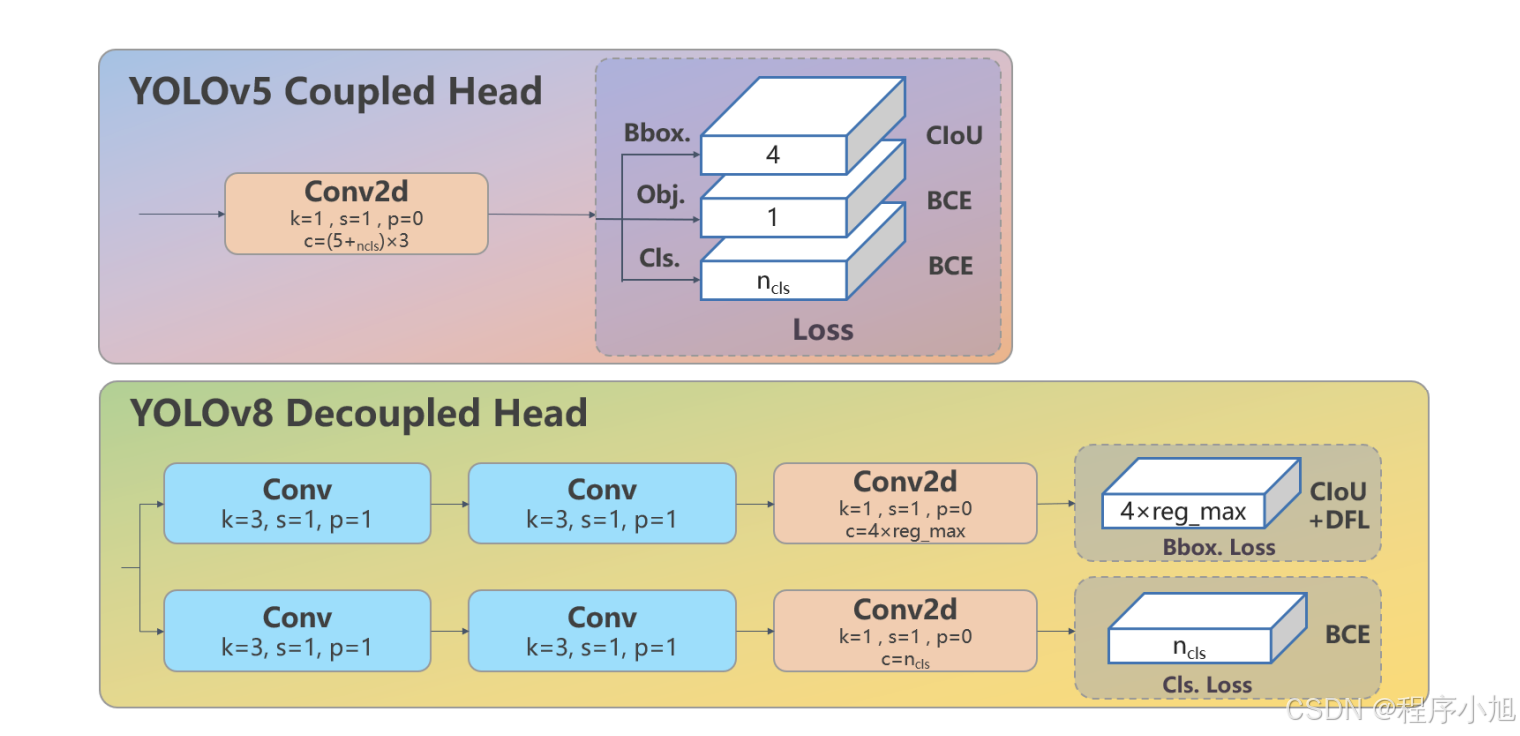
V8网络架构
# Ultralytics YOLO ?, AGPL-3.0 license# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parametersnc: 80 # number of classesscales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n' # [depth, width, max_channels] n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbonebackbone: # [from, repeats, module, args] - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 - [-1, 3, C2f, [128, True]] - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 - [-1, 6, C2f, [256, True]] - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 - [-1, 6, C2f, [512, True]] - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 - [-1, 3, C2f, [1024, True]] - [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n headhead: - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 6], 1, Concat, [1]] # cat backbone P4 - [-1, 3, C2f, [512]] # 12 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 4], 1, Concat, [1]] # cat backbone P3 - [-1, 3, C2f, [256]] # 15 (P3/8-small) - [-1, 1, Conv, [256, 3, 2]] - [[-1, 12], 1, Concat, [1]] # cat head P4 - [-1, 3, C2f, [512]] # 18 (P4/16-medium) - [-1, 1, Conv, [512, 3, 2]] - [[-1, 9], 1, Concat, [1]] # cat head P5 - [-1, 3, C2f, [1024]] # 21 (P5/32-large) - [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)结合官方论文中给出的配置文件的信息和mmDetection中给出的结构图为参考进行学习。

源码的网络构建流程
首先先要对tasks.py文件和moudule下面的文件对象继承关系进行了解。
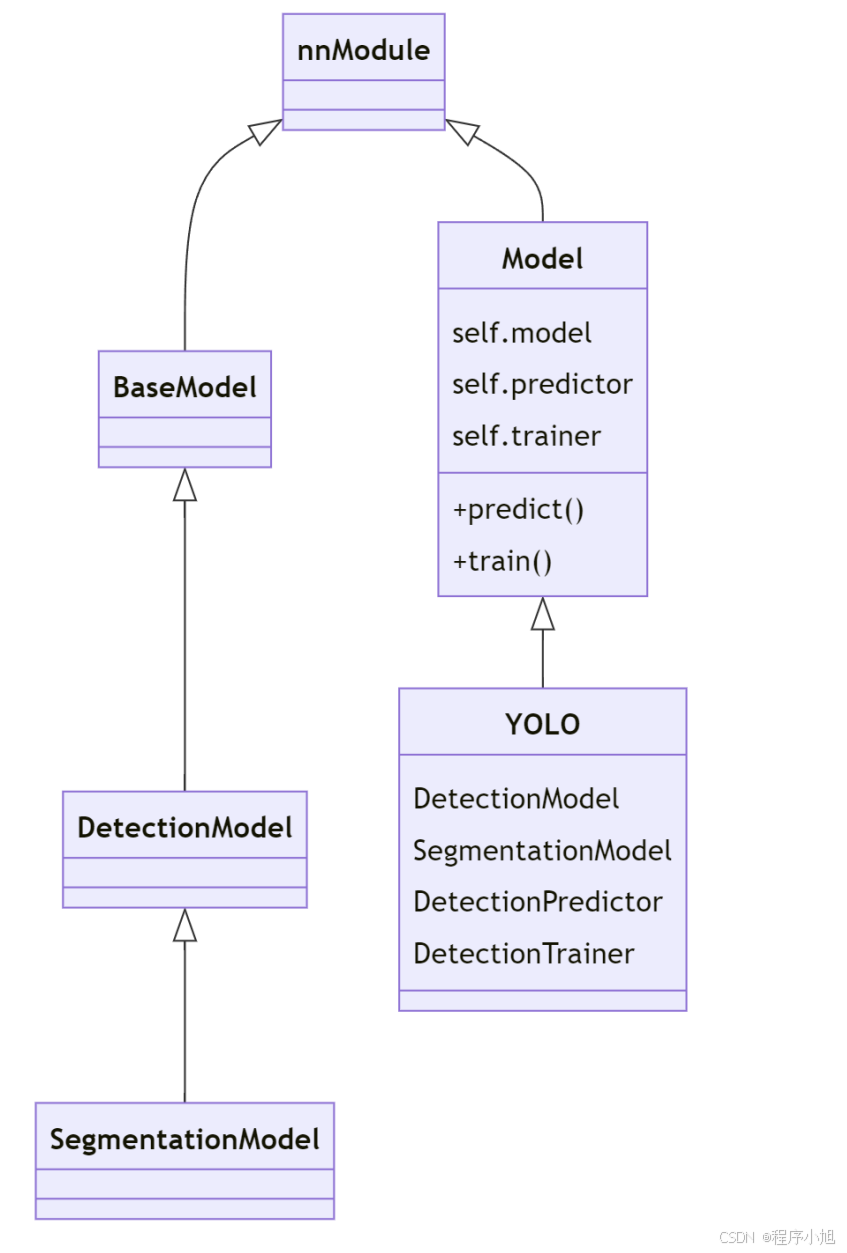
代码的执行在官网文档中给出了两种运行的方式:首先先说明使用命令行cli方式执行时代码的执行流程。
cli方式代码是如何跑起来的
当你能够直接在命令行中使用:
yolo train {task} model={model}.yamldata={data} imgsz=32 epochs=1 device=0
这样的命令,并不一定是因为 yolo 命令被添加到了系统的 PATH 环境变量。在 Python 包中,这通常是通过在包的 pyproject.toml 配置文件中配置 entry_points 来实现的。
动态调用下面的方法执行。 动态调用 model 对象上名为 mode 的方法,并传递一个字典 overrides 作为关键字参数。
if __name__ == "__main__": # Example: entrypoint(debug='yolo predict model=yolov8n.pt') entrypoint(debug="") getattr(model, mode)(**overrides) # default args from model之后就是根据相应的命令行输入的命令格式,在model的创建中使用def task_map(self)函数来将不同的任务映射到相应的模型、训练器、验证器和预测器类上,完成程序的执行过程。
return { "classify": { "model": ClassificationModel, "trainer": yolo.classify.ClassificationTrainer, "validator": yolo.classify.ClassificationValidator, "predictor": yolo.classify.ClassificationPredictor, }, "detect": { "model": DetectionModel, "trainer": yolo.detect.DetectionTrainer, "validator": yolo.detect.DetectionValidator, "predictor": yolo.detect.DetectionPredictor, }, "segment": { "model": SegmentationModel, "trainer": yolo.segment.SegmentationTrainer, "validator": yolo.segment.SegmentationValidator, "predictor": yolo.segment.SegmentationPredictor, }, "pose": { "model": PoseModel, "trainer": yolo.pose.PoseTrainer, "validator": yolo.pose.PoseValidator, "predictor": yolo.pose.PosePredictor, }, "obb": { "model": OBBModel, "trainer": yolo.obb.OBBTrainer, "validator": yolo.obb.OBBValidator, "predictor": yolo.obb.OBBPredictor, }, }使用程序调用的方式断点调试
参考官方文档给出调用的程序在model = YOLO(‘yolov8s.pt’)处打断点,进行调试,分析源码中模型构建的执行过程。
from PIL import Imagefrom ultralytics import YOLO# if __name__ =='__main__':# model = YOLO('yolov8n.yaml')# Load a pretrained YOLOv8 modelmodel = YOLO('yolov8s.pt')# Run inference on 'zidane.jpg'# results = model('D:/ultralytics/ultralytics/assets/zidane.jpg', imgsz=640, conf=0.5) # results listresults = model("ultralytics/assets") # predict on an image# Show the resultsfor r in results: im_array = r.plot() # plot a BGR numpy array of predictions im = Image.fromarray(im_array[..., ::-1]) # RGB PIL image im.show() # show image im.save('results.jpg') # save image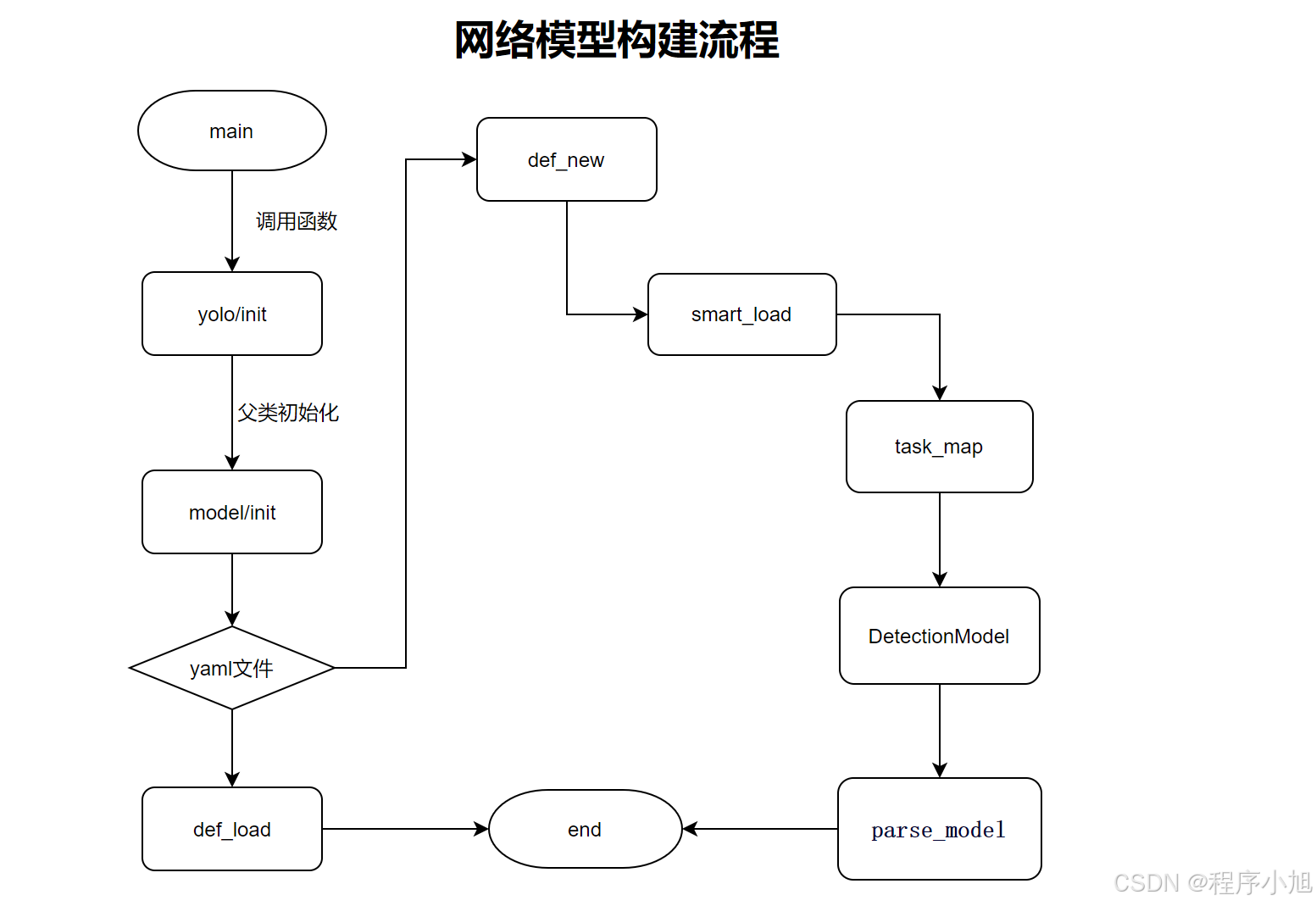
主要分析的是通过yaml文件进行模型初始化的执行过程。
对于代码部分的断点调试和代码部分注释可以私信联系,这么方便起见不在具体的书写。