C++之 string

string类对象的容量操作
resize
将有效字符的个数该成n个,多出的空间用字符c填充
虽然在string里用的不多,但是在vector里面常见
这里有三种情况:
1)resize小于当前的size
2)resize大于当前的size,小于capacity
3)大于capacity
1)resize小于当前的size
本质上就是删除数据
代码如下:
#include <iostream>#include <string>using namespace std;int main(){//初始情况string s1("111111");cout << s1.size() << endl;cout << s1.capacity() << endl;return 0;}初始情况:

再来看下面的代码:
#include <iostream>#include <string>using namespace std;int main(){//初始情况string s1("111111");cout << s1.size() << endl;cout << s1.capacity() << endl;//小于sizes1.resize(3);cout << s1 << endl;return 0;}
2)resize大于当前的size,小于capacity
本质是插入
using namespace std;int main(){//初始情况string s1("111111");cout << s1.size() << endl;cout << s1.capacity() << endl;//小于sizes1.resize(3);cout << s1 << endl;//resize大于当前的size,小于capacitys1.resize(7,'6'); //这里相当于给字符串插入字符,如果不给也不会报错,编译器会自己赋初始值cout << s1 << endl;return 0;}
3)大于capacity
using namespace std;int main(){//初始情况string s1("111111");cout << s1.size() << endl;cout << s1.capacity() << endl;//小于sizes1.resize(3);cout << s1 << endl;//resize大于当前的size,小于capacitys1.resize(7,'6');cout << s1 << endl;//大于capacitys1.resize(16, '3');return 0;}
本质也是插入,大于也不会报错
总结:
resize小于当前的size本质是删除,resize大于当前的size,小于capacity和大于capacity是插入
注意点:
resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不 同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数 增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
string类对象的修改操作
insert
C++是一个极度追求效率的语言,不希望过多的使用头插,头插会使时间复杂度变大,所以就用insert间接替代
代码示例如下:
#include <iostream>#include <string>using namespace std;int main(){string s1("hello world");s1.insert(5, "xxx");cout << s1 << endl;return 0;}打印结果:

当然最好也是少用,因为影响效率
erase
消除字符串
代码示例如下:
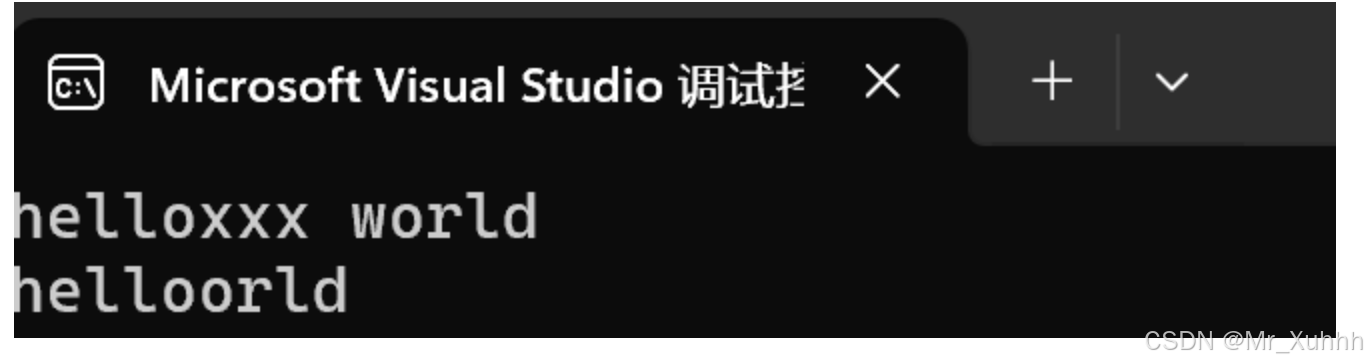
#include <iostream>#include <string>using namespace std;int main(){string s1("hello world");s1.insert(5, "xxx");cout << s1 << endl;s1.erase(5, 5);//前一个表示要从第几个开始删除,第二个参数表示删除几个cout << s1 << endl;return 0;}打印结果:
注意点:
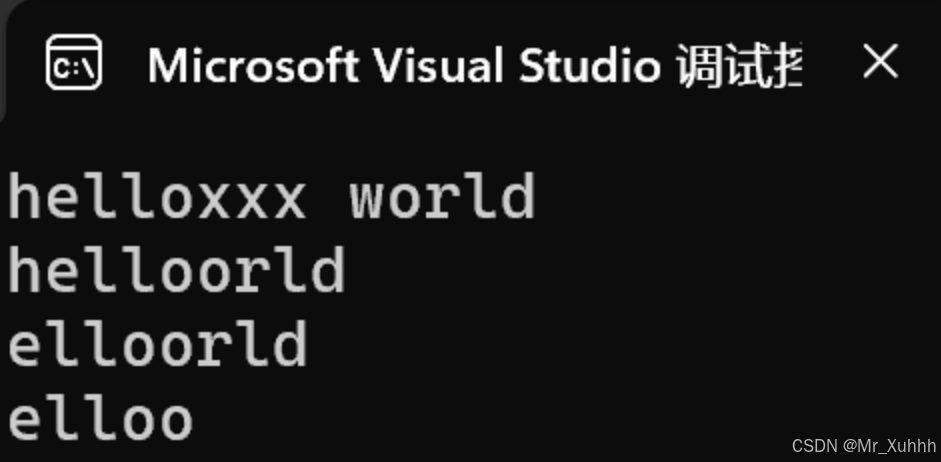
s1.erase(0, 1);//可以删开头cout << s1 << endl;s1.erase(5);//不给删除到第几个,直接后面全删掉cout << s1 << endl;打印结果:
还要注意的是开头的第一个参数不可以越界,会抛异常
s1.erase(55);replace
只有平替的效率才会高,其余情况不建议使用
示例代码如下:
s1.replace(5, 1, "%%");cout << s1 << endl;运行结果如下:

不推荐的原因在于它会改变位置,影响运行的效率
find
从字符串pos位置开始往后找字符c,返回该字符在字符串中的 位置
代码示例如下:
size_t i = s1.find(" ");while (i != string::npos){s1.replace(i, 1, "%%");i = s1.find(" ");}cout << s1 << endl;打印结果:

结合之前的范围for,还有更简便的写法:
string s2;for (auto ch : s1){if (ch != ' '){s2 += ch;}else{s2 += "%%";}}cout << s2 << endl;得到的也是同样的结果。
c_str
返回C格式字符串
示例代码如下:
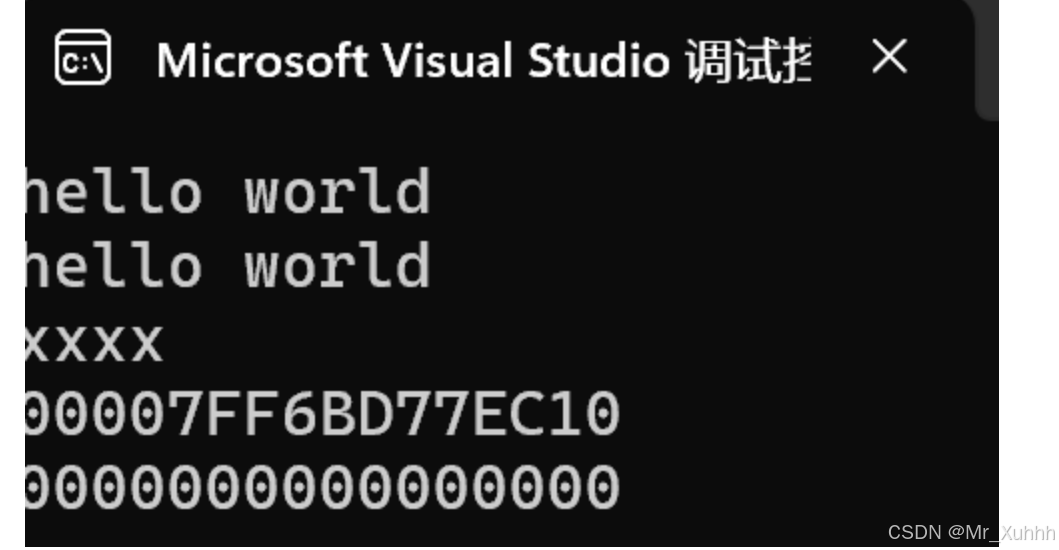
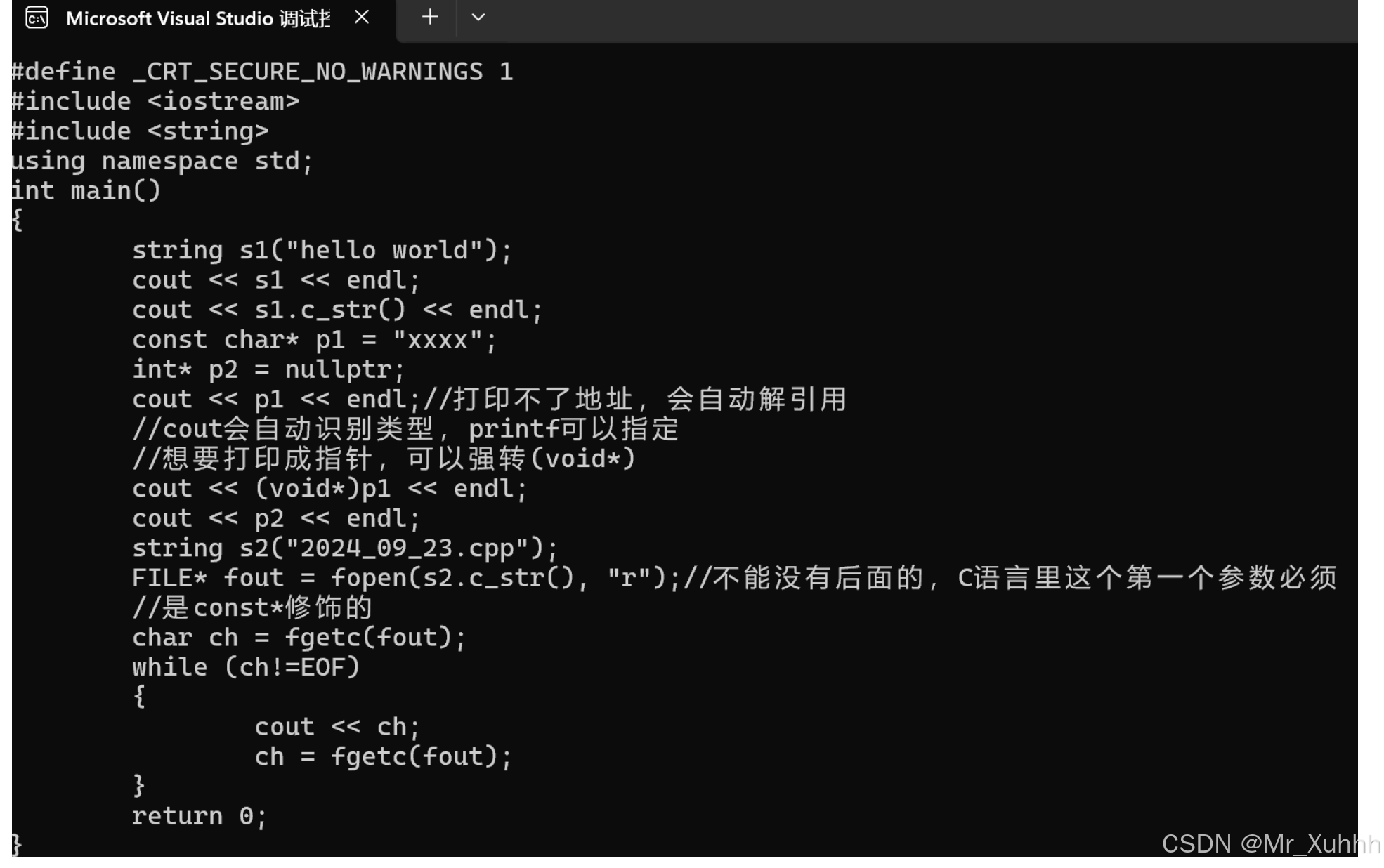
#include <iostream>#include <string>using namespace std;int main(){string s1("hello world");cout << s1 << endl;cout << s1.c_str() << endl;const char* p1 = "xxxx";int* p2 = nullptr;cout << p1 << endl;//打印不了地址,会自动解引用//cout会自动识别类型,printf可以指定//想要打印成指针,可以强转(void*)cout << (void*)p1 << endl;cout << p2 << endl;return 0;}打印结果:
因为C++也是兼容C语言的,但是它有的不会接收C++的接口,所以要用到c_str,如文件的读:
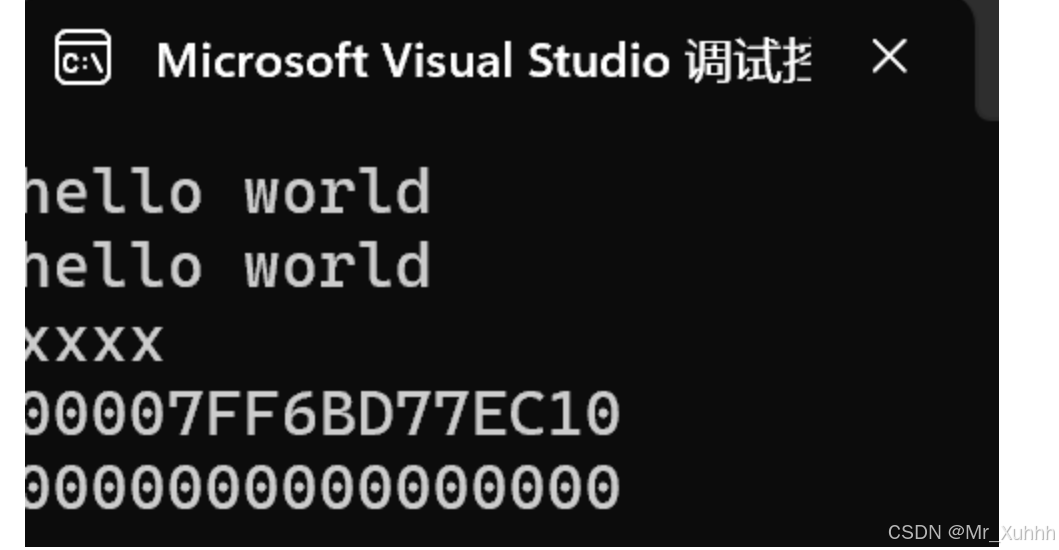
#include <iostream>#include <string>using namespace std;int main(){string s1("hello world");cout << s1 << endl;cout << s1.c_str() << endl;const char* p1 = "xxxx";int* p2 = nullptr;cout << p1 << endl;//打印不了地址,会自动解引用//cout会自动识别类型,printf可以指定//想要打印成指针,可以强转(void*)cout << (void*)p1 << endl;cout << p2 << endl;string s2("2024_09_23.cpp");FILE* fout = fopen(s2.c_str(), "r");//不能没有后面的,C语言里这个第一个参数必须//是const*修饰的char ch = fgetc(fout);while (ch!=EOF){cout << ch; ch = fgetc(fout);}return 0;}打印结果:
rfind
从字符串pos位置开始往前找字符c,返回该字符在字符串中的 位置
应用场景如:找文件名后缀
string s3("test.cpp.zip");size_t pos = s3.rfind('.');if (pos != string::npos){string sub = s3.substr(pos);cout << sub << endl;}打印结果:
注意点在于我这里也用了个新接口
substr
在str中从pos位置开始,截取n个字符,然后将其返回
find_first_of
代码示例如下:
// string::find_first_of#include <iostream> // std::cout#include <string> // std::string#include <cstddef> // std::size_tint main(){std::string str("Please, replace the vowels in this sentence by asterisks.");std::size_t found = str.find_first_of("aeiou");while (found != std::string::npos){str[found] = '*';found = str.find_first_of("aeiou", found + 1);}std::cout << str << '\n';return 0;}
任意一个在里面的值用*替换
not的话就是相当于它的补集关系,其实叫any更好,任意的意思
总的来说:需要重点掌握的接口有以下,以一张思维导图的形式表现:
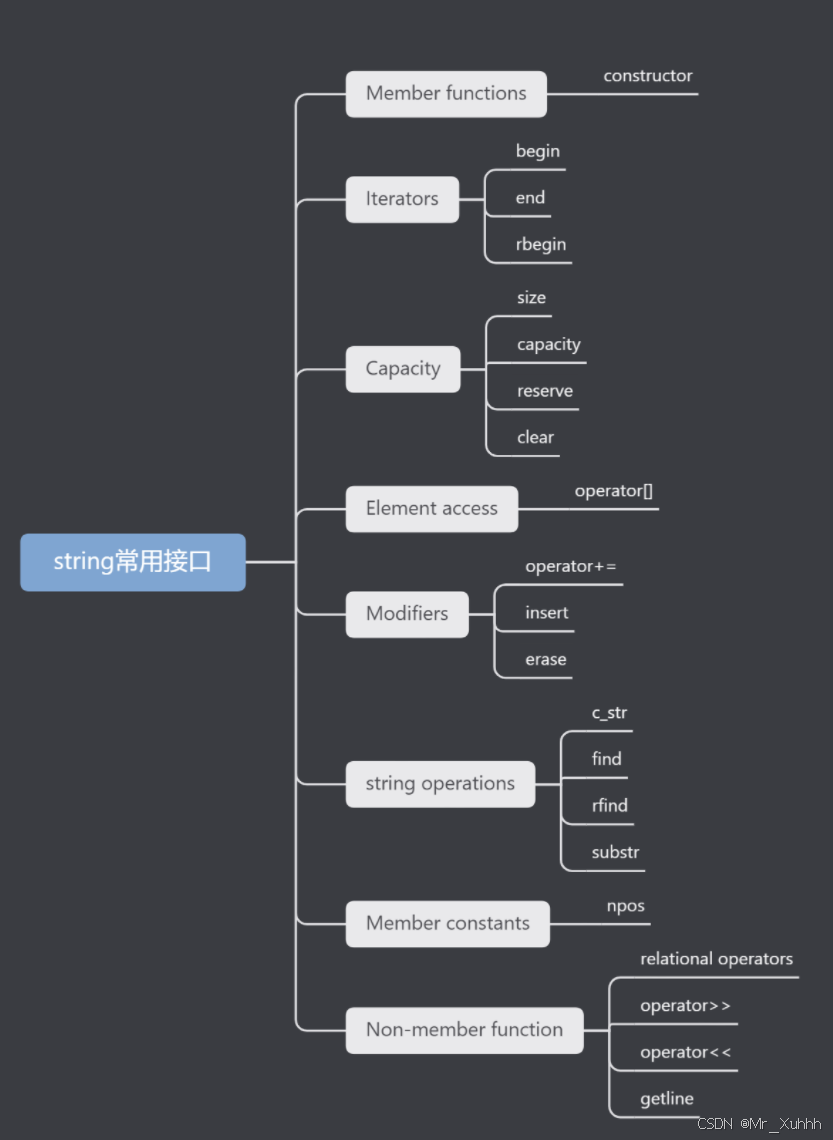
上面这些属于不看文档都必须要知道其基本用法的。
一道OJ题:字符串中的第一个唯一字符
给定一个字符串 s ,找到 它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1 。
示例 1:
输入: s = "leetcode"输出: 0示例 2:
输入: s = "loveleetcode"输出: 2示例 3:
输入: s = "aabb"输出: -1提示:
1 <= s.length <= 105s 只包含小写字母 代码:
class Solution {public: int firstUniqChar(string s) { int count[26]={0}; //统计次数 for(auto ch:s) { //间接映射 count[ch-'a']++; } //再遍历索引(下标) for(size_t i=0;i<s.size();++i) { if(count[s[i]-'a']==1) { return i; } } return -1; }};一道OJ题:字符串最后一个单词的长度
描述
计算字符串最后一个单词的长度,单词以空格隔开,字符串长度小于5000。(注:字符串末尾不以空格为结尾)
输入描述:
输入一行,代表要计算的字符串,非空,长度小于5000。
输出描述:
输出一个整数,表示输入字符串最后一个单词的长度。
示例1
输入:hello nowcoder输出:8说明:最后一个单词为nowcoder,长度为8代码:
#include <iostream>using namespace std;#include<string>int main() { string str;// 不要使用cin>>line,因为会它遇到空格就结束了// while(cin>>line) getline(cin,str); size_t pos=str.rfind(' '); cout<<str.size()-(pos+1)<<endl; //左闭右开,减出来才是个数 return 0; }这里我们需要来介绍一个接口:getline
获取一行字符串
遇到换行的时候会自动结束
像我们之前遇到的scanf,cin都是连续地从流中提取数据,因为它会把数据放到缓冲区里,默认空格,换行是分割,因为一个一个字符地区提取效率会很低
来看下面代码示例:
#include <iostream>#include <string>using namespace std;int main(){string s1, s2;cin >> s1 >> s2;cout << s1 << endl;cout << s2 << endl;return 0;}打印结果:

另外一种情况:
string str;getline(cin, str, '#');//指定字符,遇到这个字符就会停止流输入
一道OJ题:验证回文串
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。
字母和数字都属于字母数字字符。
给你一个字符串 s,如果它是 回文串 ,返回 true ;否则,返回 false 。
示例 1:
输入: s = "A man, a plan, a canal: Panama"输出:true解释:"amanaplanacanalpanama" 是回文串。示例 2:
输入:s = "race a car"输出:false解释:"raceacar" 不是回文串。示例 3:
输入:s = " "输出:true解释:在移除非字母数字字符之后,s 是一个空字符串 "" 。由于空字符串正着反着读都一样,所以是回文串。提示:
1 <= s.length <= 2 * 105s 仅由可打印的 ASCII 字符组成 代码如下:
class Solution {public: bool isLetterOrNumber(char ch) { return (ch>='0'&&ch<='9') ||(ch>='a'&&ch<='z') ||(ch>='A'&&ch<'Z'); } bool isPalindrome(string s) { for(auto&ch:s) { if(ch>='a'&&ch<='z') ch-=32; } int begin=0,end=s.size()-1; while(begin<end) { while(begin<end&&!isLetterOrNumber(s[begin])) ++begin; while(begin<end&&!isLetterOrNumber(s[end])) --end; if(s[begin]!=s[end]) { return false; } else { ++begin; --end; } } return true; }};string类的模拟实现
在面试中,面试官总喜欢让 学生自己来模拟实现string类,最主要是实现string类的构造、拷贝构造、赋值运算符重载以及析 构函数。
下面是关于构造,析构,迭代器,尾插的模拟实现
string.h
#pragma once#include <iostream>#include <assert.h>#include <string>using namespace std;namespace Tzuyu{class string{public:string(const char* str = " ");~string();void reserve(size_t n);void push_back(char ch);void append(const char* str);string& operator+=(char ch);//不建议过多使用,因为是全局变量string& operator+=(const char* str);char& operator[](size_t i){assert(i < _size);return _str[i];}const char& operator[](size_t i) const{assert(i < _size);return _str[i];}using iterator = char*;using const_iterator = const char*;iterator begin()//范围for底层是迭代器,必须要规范,如这里的begin,如果是Begin就不行,范围for会报错{return _str;}iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}size_t size() const{return _size;}const char* c_str() const{return _str;}private :char* _str;size_t _size;size_t _capacity;};}string.cpp
#include "string.h"namespace Tzuyu{string::string(const char* str):_size(strlen(str)){_capacity = _size;_str = new char[_size + 1];strcpy(_str, str);}string::~string(){delete[]_str;_str = nullptr;_size = 0;_capacity = 0;}void string::push_back(char ch){if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size] = ch;_size++;}void string::append(const char* str){size_t len = strlen(str);if (_size + len > _capacity){size_t newCapacity = 2 * _capacity;//扩2倍不够,则需多少扩多少if (newCapacity < _size + len)newCapacity = _size + len;reserve(newCapacity);}strcpy(_str + _size, str);_size += len;}void string::reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];//预留一个空间,因为reserve是内外都好用strcpy(tmp, _str);delete[]_str;_str = tmp;_capacity = n;}}string&string:: operator+=(char ch){push_back(ch);return*this;}string& string:: operator+=(const char* str){append(str);return*this;}}test.cpp
#define _CRT_SECURE_NO_WARNINGS 1#include "string.h"int main(){Tzuyu::string s2;cout << s2.c_str() << endl;Tzuyu::string s1("hello world");cout << s1.c_str() << endl;s1[0] = 'x';cout << s1.c_str() << endl;Tzuyu::string::iterator it1 = s1.begin();while (it1 != s1.end()){(*it1)--;++it1;}cout << endl;it1 = s1.begin();while (it1 != s1.end()){cout << *it1 << " ";++it1;}cout << endl;for (auto& ch : s1){ch++;}for (auto ch : s1) {cout << ch << " ";}cout << endl;const string s3("xxxxxxxx");for(auto& ch : s3){//ch++;//不可以这样进行操作,因为auto自动推导的时候发现的是const修饰的,不能修改cout << s3 << " ";}cout << endl;return 0;}