Linux——基础IO
一.文件理解
我们要进行文件操作,前提是我们的程序跑起来了,文件的打开和关闭,是CPU在执行代码。
打开一个文件,本质上是进程打开文件。
文件没有被打开时,会在磁盘中存在。
进程能够打开很多文件,很多情况下,在OS内部,一定存在大量被打开的文件。
每打开一个文件,在OS内部,一定要存在对应的描述文件属性的结构体,类似PCB。
“>”符号,即输出重定向,也是文件操作,可以用来新建文件,清空文件,与用“w”方式打开文件一样。
“>>”符号,为追加重定向,与用“a”方式打开文件一样。
文件->磁盘->外设->硬件->向文件中写入,本质是向硬件中写入->用户没有权利直接写入->OS是硬件的管理者->通过OS写入->OS必须给我们提供系统调用(OS不相信任何人)->fopen/fwrite/fread/fprintf/fscanf/scanf/printf/cin/cout...->我们用的C/C++等语言,都是对系统调用接口的封装。
二.系统调用文件操作
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
//文件打开
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
#include<unistd.h>
//文件关闭
int close(int fd);
#include<unistd.h>
//文件写入
ssize_t write(int fd,const void *buf,size_t count);(文件描述符,缓冲区,缓冲区大小)
#include<unistd.h>
//文件读取
ssize_t read(int fd, void *buf, size_t count);(文件描述符,缓冲区,缓冲区大小)
open是OS系统下调用文件操作接口,其中第一个用于操作已有的文件,第二个用于操作新文件。
1.参数
open:
pathname:文件名
flags:文件操作方式
mode:设置文件权限(二进制方式)
由open创建的新文件都必须给出文件的权限。
但是我们默认创建的权限会与系统默认的权限掩码umask其冲突, 可以使用umask函数更改权限掩码。
flags为文件操作方式,可以有多个同时使用,使用“|”隔开:
O_WRONLY:只写O_CREAT:不存在就创建O_TRUNC:清空文件内容O_ADDEND:从末尾追加内容O_RDONLY:只读2.返回值
open函数的返回值称为文件描述符fd,其本质为内核的进程与文件映射关系的数组的下标。
在操作系统中,每一个被操作的文件,都会链入类型为struct file的文件执行链表中,文件的属性存放在结构体中,文件的内容则存放在内核级缓存中。
在进程task_struct内部,还有一个struct file_struct *files类型的指针,指向类型为struct file_struct的文件描述符表,该结构体中存在一个类型为struct file* fd_array[N]的指针数组,指针指向文件执行链表中的每个文件的地址,数组每个元素的下标即为文件描述符fd。
当open函数打开错误时,返回 -1。
打开正确时,会返回文件映射关系的数组的下标。
该下标默认从3开始,每新建一个文件则加1。为什么不从0开始?
原因是0、1、2三个下标被占用,分别是:
0:标准输入 键盘1:标准输出 显示器2:标准错误 显示器在OS内部,系统访问文件的时候,只认文件描述符!
文件描述符的分配规则:
进程查自己的文件描述符表,从0开始分配最小的没有被使用的fd下标给新文件。
3.open的实际作用
创建struct file;开辟文件缓冲区的空间,加载文件数据(延后);查进程的文件描述符表;获取file地址,填入对应的表下标中;返回下标。三.重定向
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
//获取文件的属性
int stat(const char *pathname, struct stat *statbuf);(路径,文件属性结构体)
int fstat(int fd, struct stat *statbuf);(文件描述符,文件属性结构体)
int lstat(const char *pathname, struct stat *statbuf);(路径,文件属性结构体)
在内核中改变文件描述符表特定下标的内容,从而使一个特定的文件描述符成为目标文件的下标,和上层无关。
例如我们先关闭标准输出stdout文件,随后再打开一个新的文件,那么标准输出stdout的文件描述符1就会给到新的文件。
#include <unistd.h>
int dup2(int oldfd,int newfd);
重定向函数,其参数为文件描述符,作用是让newfd成为oldfd的副本。从而使文件描述符newfd成为oldfd所指向的文件的下标。本质是文件描述符下标所对应的内容的拷贝。
思考一下,标准输出和标准错误都是向显示器打印,那么两者有什么区别呢???
两者有不同的文件描述符,这样就使得我们可以通过重定向将正常的输出信息和错误信息分开,以便我们去寻找错误,常用的perror函数就是向标准错误打印信息。
四.缓冲区
在struct FILE内部,存在语言级别的文件缓冲区,printf,fprintf等语言级系统调用获取到数据后,先会放入文件缓冲区中,然后通过文件描述符,将数据冲刷进内核的文件缓冲区,最后在冲刷进磁盘空间。
缓冲区是一段内存空间,给上层提供高效的IO体验,间接提升整体的效率。
每一个文件都有一个自己的缓冲区。
C语言为什么要在FILE中提供用户级缓冲区:为了减少底层调用系统调用的次数,让使用C语言IO函数(printf,fprintf)效率更高。
函数会将数据先放入缓冲区,最后执行一次性刷新。
1.如何工作(用户级)
(1)刷新策略
立即刷新。fflush(stdout)(语言层)、int fsync(int fd)(系统层)行刷新。显示器全缓冲。缓冲区写满才刷新,普通文件。(2)特殊情况
进程退出,系统自动刷新。强制刷新五.文件系统
在系统中存在很多的文件,但是被打开的文件只是很少的一部分。
没有被打开的文件则存放在磁盘中,称为磁盘文件。
想要打开一个文件,就需要通过文件路径+文件名找到该文件,进而从磁盘中将其打开。
1.磁盘的存储结构
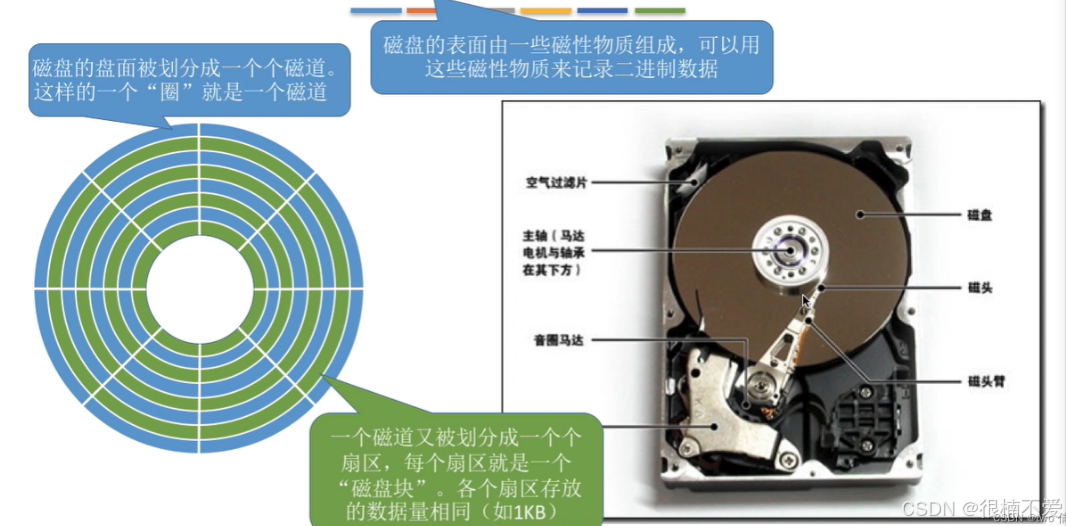
磁盘读写的基本单位是扇区:512字节,4KB。
如何找到一个指定位置的扇区?
找到指定的磁头。Header找到指定的磁道(柱面)。Cylinder找到指定的扇区。Sector该方法称为CHS定址法。
文件其实就是在磁盘中占用几个扇区的问题。
2.逻辑抽象磁盘存储
文件由很多个块构成,块从0开始记号,每个块由8个连续的扇区构成。我们只需文件的起始地址,以及磁盘的总大小,那么有多少块,每个块的块号,进而转换到对应的多个CHS地址就都可以得到了。每个块对应的地址称为LBA :逻辑区块地址。
一整个磁盘会先分为若干个区,即我们电脑中常见的C盘、D盘等,每个区又会分为若干个组,管理好一组,就可以管理好一个分区,进而管理好好整个磁盘,这种思想称为分治。
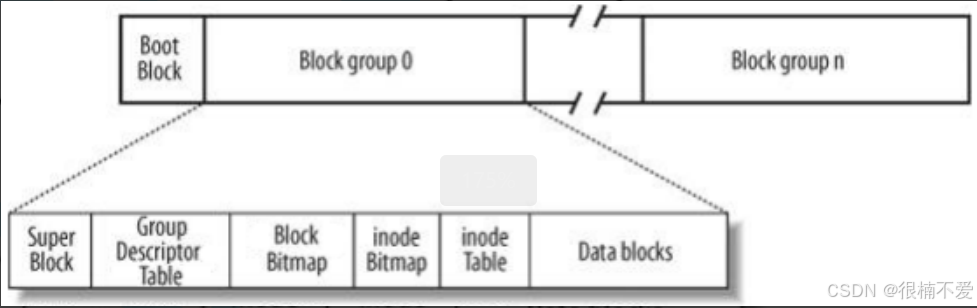
如图所示即为区的一个分组,下面我们来看一个组中的各种构成。
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Bloc的信息被破坏,可以说整个文件系统结构就被破坏了。 GDT,Group Descriptor Table:块组描述符,描述块组属性信息。 inode Bitmap:每个bit表示一个inode是否空闲可用。 Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用。 inode table:存放文件属性如文件大小,所有者,最近修改时间。 Data blocks:存放文件内容。linux文件系统特定:文件内容和文件属性分开存储。
linux中文件的属性是一个大小固定的集合体,即struct inode,128个字节。
内核层面上,每一个文件属性结构体中都要有inode number,我们通过inode号标识一个文件。
使用指令:ll -li便可以看到当前目录下的文件的inode number。
inode编号是以整个分区为单位进行划分的,一个分区内不可能存在相同的inode编号,不同的分区则可能存在。
目录本身也是一个文件,目录 = 文件属性 + 文件内容,目录的内容即:文件名和inode编号的映射关系。
由此我们能够得出一下结论:
一个目录下不能建立同名文件。查找文件的顺序:文件名->inode编号。目录的r权限,本质是是否允许我们读取目录的内容即,文件名:inode的映射关系。目录的w权限,新建文件,最后一定要向当前所处目录内容中写入:文件名和inode的映射关系。想要找到一个文件,就需要找到其所在的目录,但是目录也是一个文件,我们该如何找到这个目录呢?目录通常是由谁提供的呢?
你或者你的进程早就已经提供了。内核文件系统提前写入并组织好,然后我们提供的。
Linux内核再被使用时,一定存在大量的解析完毕的路径,系统同样需要对这些路径进行管理。
通过struct dentry{}结构体,保存路径解析的信息,一个文件对应一个该结构体,所有的结构体通过链表管理。
但是得到inode,更前提得是,我的文件在哪一个分区中,如何寻找分区呢?
分区->写入文件系统(格式化)->挂载到指定的目录下->进入该目录->在指定的分区进行文件操作。
这样一来,只要我们知道文件在哪个目录下,就同样可以知道它在哪个分区中。
六.软硬链接
软链接指令:ln -s + 目标文件 + 链接文件名(后缀.link)
硬链接指令:ln + 目标文件 + 链接文件名(后缀.link)
1.特征
软链接是一个独立的文件,因为有独立的inode number。硬链接不是一个独立的文件,因为没有独立的inode number,用的是目标文件的inode。文件属性中的有一列数字即为硬链接数,即文件的磁盘级引用计数:有多少个文件名字符串通过inode number指向inode。软连接的内容:目标文件对应的路径字符串,即windows中的快捷方式。
硬链接就是一个文件名和inode的映射关系,建立硬链接,就是在指定的目录下,添加一个新的文件名和inode number的映射关系。
硬链接的作用:
构建linux的路径结构,让我们可以使用"."和".."来进行路径定位。用做文件备份。七.动静态库
所谓的库文件,本质就是把.o文件打包。
1.静态库
静态库创建:
ar -rc + 库名(前缀lib,后缀.a) + 要打包的文件
使用静态库:
使用静态库有多种方式:
一是库、头文件以及main文件在同一目录下,直接使用:
gcc + main文件 + 库
二是将头文件添加到系统的头文件目录下,同时将库文件也添加到系统的库文件目录下:
gcc + main文件 + -l库名
但是我们不推荐将第三方库添加到系统的库文件下,所以当头文件和库文件在其他路径下时,还有第三种方法:
gcc + main文件 + -I(大i) + 指定头文件所在路径 + -L + 指定库文件所在路径 + -l第三方库名
2.动态库
动态库创建:
gcc -shared + 要打包的.o文件 + -o + 库名(后缀.so)
我们平时使用gcc进行编译时,如果不使用static选项时,默认自动连接的为动态库。
动态库在程序运行时,需要找到动态库并加载运行,所以使用动态库有以下几种方法:
将动态库安装到系统的动态库目录中(/lib64)。在系统动态库目录中建立软连接。将动态库所在路径导入环境变量(LD_LIBRARY_PATH)。修改.bashrc配置文件,让环境变量永久生效在/etc/ld.so.conf.d路径下新增动态库搜索的配置文件(.conf后缀),将动态库的绝对路径写入配置文件中,再通过ldconflg指令进行更新。3.动态库VS静态库
系统默认链接的为动态库。
如果没有使用-static,并且只提供了当前的.a库,其他库正常动态链接。
-static的意义?
必须强制将我们的程序进行静态链接,这就要求我们链接的任何库都必须提供对应的静态版本。
4.动态库加载
动态库以文件形式存放在磁盘中,当程序运行需要加载动态库时,动态库先要被加载到内存中,动态库在内存中也要被OS通过链表管理在一起,随后通过页表映射到程序地址空间的堆栈共享区中。
八.可执行程序理解
我们的可执行程序,编译成功,没有加载运行时,依然具有地址。
可执行程序编译后,会形成很多行汇编语句,每条汇编语句都有它的地址,即虚拟地址。
进程创建阶段,会初始化自己的地址空间,让CPU知道main函数的入口地址。
pcb创建需要从elf和加载器拿虚拟地址和mian函数入口地址,pc指针先存着入口地址等后面OS根据页表运行;把可执行程序加载入物理内存,得到物理地址,同时在虚拟地址空间拥有虚拟地址,所以这时候就有虚拟地址和物理地址,根据这两个地址就可以构造页表印射关系,OS运行找pc指针印射物理地址执行代码,pc指针顺便存下一跳地址,然后OS和pc指针继续这种操作,代码就运行起来了。
登录后可发表评论
点击登录