2016 年,百度 PaddlePaddle 打响了国产深度学习框架开源的第一枪。
2019 年 4 月,在 Wave Summit 深度学习开发者峰会上,首次发布了PaddlePaddle 的中文名“飞桨”,开始强调自己更适合中国开发者,以及更加专注于深度学习模型的产业实践。与此同时,飞桨的发展开始提速。
时间来到 2020 年,这一年是国产深度学习框架的高光时刻,作为国产领头羊的飞桨动作频频,不断更新升级。
2021 年 3 月,百度正式推出飞桨框架 2.0 正式版,实现了一次跨时代的升级。如今,在 GitHub 上,飞桨已收获Star数量达到了14.6k,被越来越多的开发者所使用。
从开发、训练到部署:飞桨框架 2.0 从“更新升级”到“全面换代”
飞桨作为我国首个开源开放的深度学习平台,想要保持自己的地位,必须要有自己独特的优势。经过多年的更新迭代,飞桨已经集开发便捷的核心框架、超大规模深度学习模型训练、多端多平台部署的高性能推理引擎和覆盖多领域的产业级模型库四大核心技术于一体,始终保持技术领先与功能完备。如今飞桨已凝聚 265 万开发者,服务 10万多家企业,创建了超过 34 万个模型,帮助越来越多的行业完成AI赋能,实现产业智能化升级。

与之前的版本迭代相比,此次 2.0 版本的发布对于飞桨来说,不仅仅是一次常规升级,而是一次“基础设施”的全面更新换代!这一次,百度从产业实践的全流程出发,对 深度学习模型的开发、训练、部署进行了整体优化,进一步加速 AI 应用的大规模落地。
| AI Workflow | 更新/升级 | 功能 |
| AI 模型开发 | 成熟完备的动态图模式 | 1、默认的开发模式升级为命令式编程模式(动态图)。 2、支持查看变量的输入、输出,灵活调试。 3、全面完备的动转静支持。 |
| API 体系全新升级 | 1、体系化:重新梳理和优化了 API 的体系结构,新增 API 217 个,优化修改 API 195 个。 2、简洁化:经典的网络模型结构都被封装成了高层 API,在编程过程中可以同时使用高层 API 与基础 API。 | |
| AI 模型训练 | 分布式训练能力的提升 | 新增支持混合并行模式,即数据并行、模型并行、流水线并行这三种并行模式可以相互组合使用,实现对千亿参数规模的模型训练。 |
| 业内首个通用异构参数服务器技术 | 支持同时使用不同的硬件进行混合异构训练,解决了搜索推荐领域大规模稀疏特征模型训练场景下,IO 占比过高导致的计算资源利用率过低的问题。 | |
| AI 模型部署 | 硬件适配升级 | 硬件生态持续繁荣,已经适配和正在适配的芯片或 IP达到 29款。 |
一、更高效地开发 AI 模型
1、成熟完备的动态图模式
由于命令式编程模式(动态图)对开发者的友好性,飞桨于 2019 年初也在推进动态图功能。此次升级,飞桨将默认的开发模式升级为动态图,这标志着飞桨的动态图功能已经成熟完备。据了解,飞桨 框架2.0 支持用户使用动态图完成深度学习相关领域全类别的模型算法开发。动态图模式下,开发者可以随时查看变量的输入、输出,方便快捷的调试程序,带来更好的开发体验。
为了解决动态图的部署问题,飞桨提供了全面完备的动转静支持,在 Python 语法支持覆盖度上达到领先水平。开发者在动态图编程调试的过程中,仅需添加一个装饰器,即可无缝平滑地自动实现静态图训练或模型保存。同时飞桨框架 2.0 还做到了模型存储和加载的接口统一,保证动转静之后保存的模型文件能够被纯动态图加载和使用。
在飞桨框架 2.0 版本上,官方支持的动态图算法数量达到了 270+,涵盖计算机视觉、自然语言处理、语音、推荐等多个领域,并且在动态图的训练效率和部署效率方面都有所提升。2.0版本的动态图支持了自动混合精度和量化训练功能,实现了比静态图更简洁灵活的混合精度训练接口,达到媲美静态图的混合精度和量化训练效果。
同时,为了推进各个主流场景的产业级应用,飞桨的系列开发套件也随飞桨框架 2.0 完成了升级,全面支持动态图开发模式。
2、API体系全新升级
API 是用户使用深度学习框架的直接入口,对开发者使用体验起着至关重要的作用。飞桨框架 2.0 对 API 体系进行了全新升级,包括体系化的梳理以及简洁化的处理,而且飞桨框架 2.0的 新API 体系完全兼容历史版本,同时飞桨提供了升级工具,帮助开发者降低升级迁移成本。
- 体系化:飞桨重新梳理和优化了 API 的体系结构,使其更加清晰、科学,让广大开发者可以更容易地根据开发使用场景找到想要的 API。此外可以通过 class 和 functional 两种形式的 API 来模块化的组织代码和搭建网络,提高开发效率。同时,API 的丰富度有了极大的提升,共计新增 API 217 个,优化修改 API 195 个。
- 简洁化:提供更适合低代码编程的高层 API。像数据增强、建立数据流水线、循环批量训练等可以标准化的工作流程,以及一些经典的网络模型结构,在飞桨框架2.0中,都被封装成了高层 API。基于飞桨高层 API,开发者只需10行左右代码就可以编写完成训练部分的程序。最为重要的是,高层 API 与基础 API 采用一体化设计,即在编程过程中可以同时使用高层 API 与基础 API,让用户在简捷开发与精细化调优之间自由定制。
| API目录 | 功能 |
| paddle.tensor | tensor操作相关的API,如:创建zeros、矩阵运算matmul、变换concat、计算add、查找argmax等。 |
| paddle.nn | 组网相关的API,如:Linear、卷积、LSTM、损失函数、激活函数等。 |
| paddle.framework | 框架通用API和动态图模式的API,如:to_tensor、no_grad等。 |
| paddle.optimizer | 优化算法相关API,如:SGD、Adagrad、Adam等。 |
| paddle.optimizer.lr_scheduler | 学习率衰减相关API。 |
| paddle.metric | 评估指标计算相关的API,如:Accuracy、Auc等。 |
| paddle.io | 数据输入输出相关API,如:Dataset、DataLoader、Sampler等。 |
| paddle.device | 设备管理相关API,如:CPUPlace、CUDAPlace等。 |
| paddle.distributed | 分布式相关基础API。 |
| paddle.distributed.fleet | 分布式相关高层API。 |
| paddle.vision | 视觉领域API,如:数据集、数据处理、常用基础网络结构(如ResNet)等。 |
| paddle.text | NLP领域API, 例如数据集、数据处理、常用基础网络结构(如Transformer)等。 |
| paddle.static.nn | 静态图组网专用API,如:输入占位符data、全连接层fc、控制流while_loop/cond等。 |
| paddle.static | 静态图下基础框架相关API,如:Variable、Program、Executor等。 |
二、更高效地训练AI模型
1、训练更大规模的模型
飞桨的英文名 Paddle 其实就是并行分布式训练学习的缩写,因此分布式训练可以说是飞桨与生俱来的特性。飞桨支持包括数据并行、模型并行、流水线并行在内的广泛并行模式和多种加速策略。在飞桨框架2.0 版本中,新增支持了混合并行模式,即数据并行、模型并行、流水线并行这三种并行模式可以相互组合使用,更高效地将模型的各网络层甚至某一层的参数切分到多张 GPU 卡上进行训练,从而实现支持训练千亿参数规模的模型。
2、业内首个通用异构参数服务器架构
飞桨框架2.0推出了业内首个通用异构参数服务器技术,解除了传统参数服务器模式必须严格使用同一种硬件型号Trainer节点的枷锁,使训练任务对硬件型号不敏感,即可以同时使用不同的硬件进行混合异构训练,如CPU、GPU(也包括例如V100、P40、K40的混合)、AI 专用加速硬件如昆仑芯片等,同时解决了搜索推荐领域大规模稀疏特征模型训练场景下,IO 占比过高导致的计算资源利用率过低的问题。通过异构参数服务器架构,用户可以在硬件异构集群中部署分布式训练任务,实现对不同算力的芯片高效利用,为用户提供更高吞吐,更低资源消耗的训练能力。
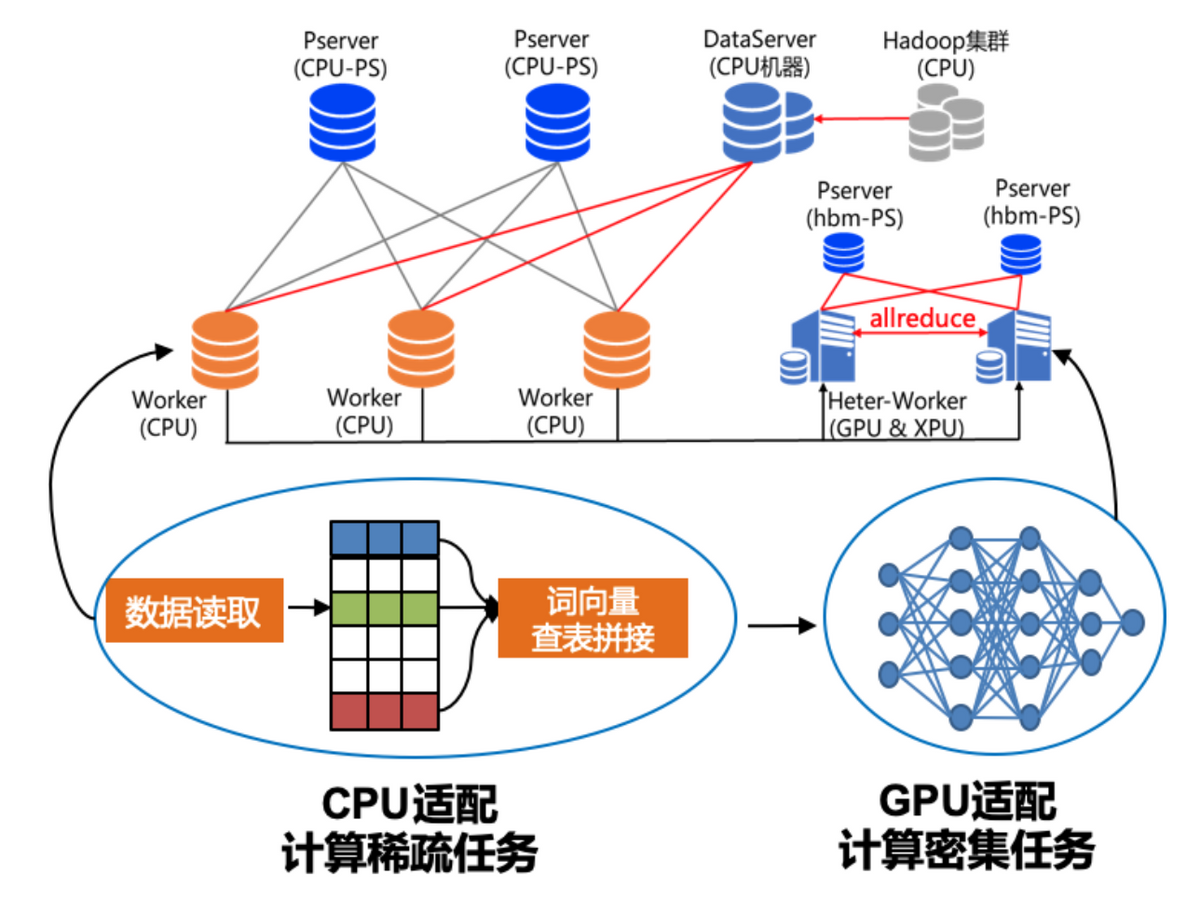
通用异构参数服务器架构之所以被称之为通用,主要在于其兼容支持三种训练模式:
- 可兼容全部由CPU机器组成的传统参数服务器架构所支持的训练任务。
- 可兼容全部由GPU或其他AI加速芯片对应机器组成的参数服务器,充分利用机器内部的异构设备。
- 支持通过CPU机器和GPU或其他AI加速芯片对应机器的混布,组成机器间异构参数服务器架构。
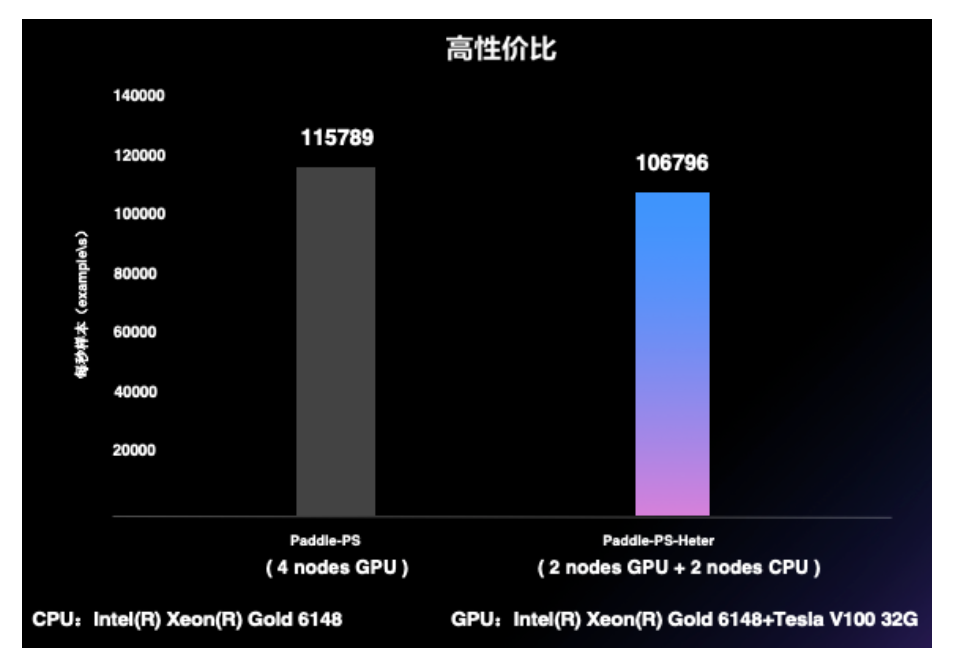
异构参数服务器拥有非常高的性价比,如下图所示,仅用两个CPU机器加两个GPU机器就可以达到与4个GPU机器相仿的训练速度,而成本至少可以节约35%。
三、更广泛地部署AI模型到各种硬件
AI产业的广泛应用离不开各种各样的人工智能硬件的繁荣,当前包括英特尔、英伟达、ARM等诸多芯片厂商纷纷开展对飞桨的支持。飞桨还跟飞腾、海光、鲲鹏、龙芯、申威等 CPU 进行深入适配,并结合麒麟、统信、普华操作系统,以及百度昆仑、海光 DCU、寒武纪、比特大陆、瑞芯微、高通、英伟达等 AI 芯片深度融合,与浪潮、中科曙光等服务器厂商合作形成软硬一体的全栈AI基础设施。当前飞桨已经适配和正在适配的芯片或 IP达到 29款,处于业界领先地位。
自主可控的必要性:TensorFlow、PyTorch 并不完美
很多人对国产深度学习框架的发展抱有怀疑态度,认为这些工作只不过是在拾人牙慧,重复造轮子,而且 AI 开源框架的搭建是一项费时费力的庞大工程。如果没有超越现有主流框架的想法,去重复造一套没有技术创新的轮子,“性价比”似乎不高,对技术人员来说吸引力也不大。
然而 AI 的大规模落地仍然处在起步阶段,深度学习技术依然在不断发展,复杂程度也在不断提高,而 TensorFlow、PyTorch 等国外框架并非没有提升的空间,因此飞桨等国产框架依然有很大的机会。
业内的一位算法工程师表示,TensorFlow 对稀疏模型的处理能力,大规模分布式计算能力,以及在 Embedding 内存利用率上,仍然有提升空间,而且 TensorFlow 2.0 API 混乱的问题也亟待解决;PyTorch 也是类似,主要关注解决密集模型,对稀疏模型的关注度欠缺。
此外,飞桨免费开放了很多预训练模型,可以直接在产业界落地,因此对于小型企业来说更有利,成本更低,同时也能取得不错的效果。由于 AI 正在从云端走向边缘端,而飞桨对多芯片平台的适配和支持,也带了很大的部署优势。
与此同时,百度也在加大构建飞桨社区的扶持,因此中国开发者也可以获得更及时、更个性化的支持。
今年 3 月美国国家人工智能安全委员会(NSCAI)发布的一份报告,提出了对于总统拜登、国会及企业和机构的数十项建议,以期压制中国 AI 的发展。这也说明了构建中国自主可控核心技术栈的重要性和必要性。
新加坡工程院院士、IEEE Fellow 颜水成在CSDN《2020-2021 中国开发者调查报告》中点评道“以飞桨为代表的国产框架已经在快速崛起,其市场占有率已经不可忽视。”
2021 年,基于飞桨的企业级的开发工具库数量越来越多,内容越来越丰富,加入飞桨生态社区的用户越来越多。有着先发优势的百度,如今在 AI 基础设施这一领域已经走得更远,也将走得更稳。