大家好,我是一哥,周末有读者私聊我咨询了一些问题,遂想起了之前看过的一些关于数据湖的知识,下面是基于之前的所见和自己的思考而成文。
数据湖
数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
这是AWS给出的解释。
看了很多数据湖的介绍文章,笔者认为数据湖和我们常说的ODS数据很类似,也就是原始数据的保存区域,存储来自各业务系统(消息队列)的原始数据。比如电商网站的访问日志(埋点的时候是以JSON存储),物联网终端设备实时发送的数据等原始数据直接存储在数据仓库的ODS层。
数据湖为什么火了
做数据仓库已经有ODS数据了,那么怎么突然大家都在提数据湖了?
真正的原因在于数据分析和机器学习这两年成为了主流,可以看看现在的招聘网站,很多招聘数据分析师和算法工程师的岗位,笔者所在城市尤为明显。15年的时候大家都在建立各自的大数据平台,那时候你懂点Hadoop,已经很了不起了。现在各个大数据平台已经建设成熟,逐步为业务服务,越来越多的公司需要利用大数据服务于业务,提升变现能力。
基于大数据建设的数据仓库往往是各个维度的聚合数据,大多服务于传统的报表分析。而机器学习往往需要使用到原始数据,另外很多机器学习用到的也不至于格式化数据,用户的评论,图像等都可以应用到机器学习中。
为什么要有数据湖
可以看下上面的这个组织架构图。数据湖的存在更多的是改变部门的组织架构,毕竟现在大部分公司都更注重业务分析的价值。
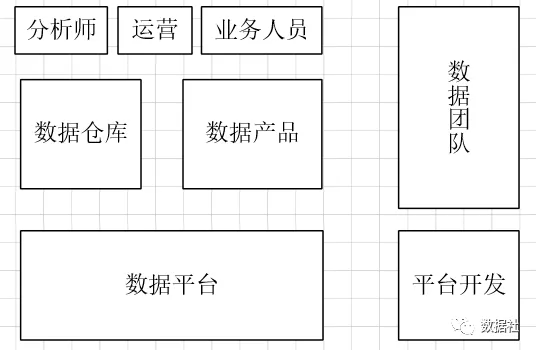
传统企业的数据团队被当做IT体系,整天要求提数。现在,数据团队只需要负责提供简单易用的工具,业务部门直接进行数据的使用。这也就是人人具备数据分析能力(人人都是数据分析师,真的很难)。
数据湖 vs 数据仓库
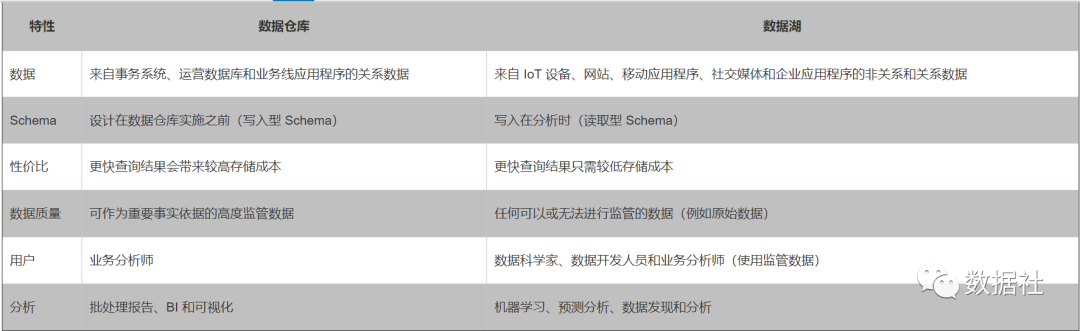
这是AWS给出的对比,还是比较中肯的。
传统的数据仓库工作方式是集中式的:业务人员给需求到数据团队,数据团队根据要求加工、开发成维度表,供业务团队通过BI报表工具查询或者业务分析系统展示。
数据湖是开放、自助式的:开放数据给所有人使用,数据团队更多是提供工具、环境供各业务团队使用,业务团队进行开发、分析。
和数据仓库不同的是,以前数据仓库都是先设计schema,然后灌入数据。数据湖的schema是随用随生成,随着分析场景不同而不同。关于数据湖的技术实现方面可以了解下 delta lake这个项目(我司的平台部分功能在delta lake这个项目出来之前已经实现了一些功能)。
数据湖对于数据分析师来说对数据的操控性更强,但是要求也更高,不光懂业务,懂sql,懂数据,还要懂大数据处理技术,每个人都在处理自己需要的数据,会造成很多冗余数据存储和计算资源浪费,无法形成共性的可复用的数据层,这方面数仓是有益的补充。
数据湖并不是为了颠覆数据仓库,是为了满足数仓无法满足的数据需求,二者是互补的(目前来看)。
ELT
你没看错,是ELT,不是ETL!
周末有读者私聊一哥,看了一篇ETL和ELT的文章,知道了概念,但是不知道具体在什么场景下实施?
很多时候,我们只讲概念,很晦涩。先上一张图:
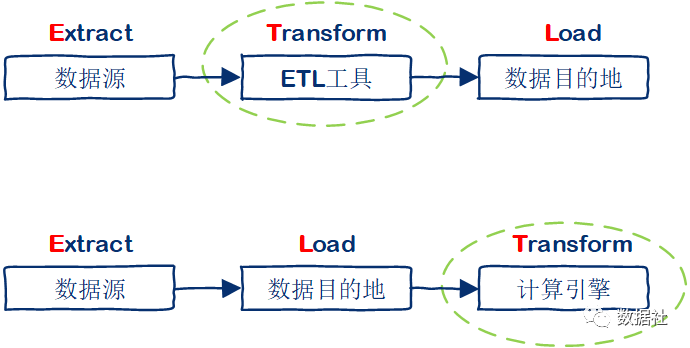
数据集成包含三个基本的环节:Extract(抽取)、Transform(转换)、Load(加载)。
ETL:抽取是将数据从已有的数据源中提取出来;转换是对原始数据进行处理,例如使用ETL工具(Informatica、Kettle等)进行过滤空值,指标计算等;加载是将数据写入目的地,一般是关系型数据库。
ELT:在抽取后将结果先写入目的地,比如Hive中,然后由下游应用利用外部计算框架进行指标加工、建模,例如 Spark 来完成转换的步骤。
可以说现在大数据环境下,很多已经是ELT架构了,数据湖就非常适合作为ELT架构中的“数据存储目的地”。
数据湖的未来
3月初和一个好友饭后闲聊,聊到数仓的建设。首先,我们思考一下数仓为什么会出现?其实是数据量的飞速增长,以至于当时的数据存储计算引擎,不能很好的满足分析需求;于是数仓概念和经典的理论出现了,很好的解决了当时的问题,用“规范+存储”来解决了当时的问题。
那么现在大数据时代,随着技术的不断发展,很多新技术出现了,大批量的存储和计算不再是那么难了,那么我们放弃数仓那一套是否可行呢?从一哥现在处理的业务看,如果你的业务系统相对较单一,没有几十个业务系统每天往数仓里灌数据,那么数据湖可以满足你的需求,并且对于“数据驱动”更“敏捷”。如果一线的业务系统较复杂,那么现在使用数据湖也会一不小心会变成“数据沼泽”。
所以,下一个方向也许就是数据湖的数据治理,当数据湖的治理明确后,也就是它大放异彩的时刻了!