系列篇章?
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
目录
系列篇章?前言一、数据准备1、通用文本数据2、专业文本数据 二、数据质量过滤1、基于启发式规则2、基于分类器方法 三、数据去重过滤1、模糊去重2、精确去重 四、数据敏感过滤1、过滤有毒内容2、过滤隐私内容 五、数据影响分析1、数据数量的影响2、数据质量的影响 六、简单实践样例1、质量过滤2、去重过滤3、隐私过滤 总结
前言
随着人工智能技术的不断发展,大语言模型在自然语言处理、机器翻译、文本生成等领域取得了显著的成果。然而,训练一个高性能的大语言模型需要大量的高质量预训练数据。本文将详细介绍大语言模型预训练数据准备的各个环节,包括数据来源、质量过滤、去重过滤、敏感过滤以及数据影响分析等。希望通过本文的介绍,能够帮助读者更好地理解和应用大语言模型预训练数据的准备过程。
一、数据准备
大语言模型训练所需的数据来源大体上可以分为通用数据和专业数据两大类。通用数据包括网页、图书、新闻、对话文本等内容。通用数据具有规模大、多样性和易获取等特点,因此可以支持大语言模型的构建语言建模和泛化能力。专业数据包括多语言数据、科学数据、代码以及领域特有资料等数据。通过在预训练阶段引入专业数据可以有效提供大语言模型的任务解决能力。
不同的大语言模型在训练类型分布上的差距很大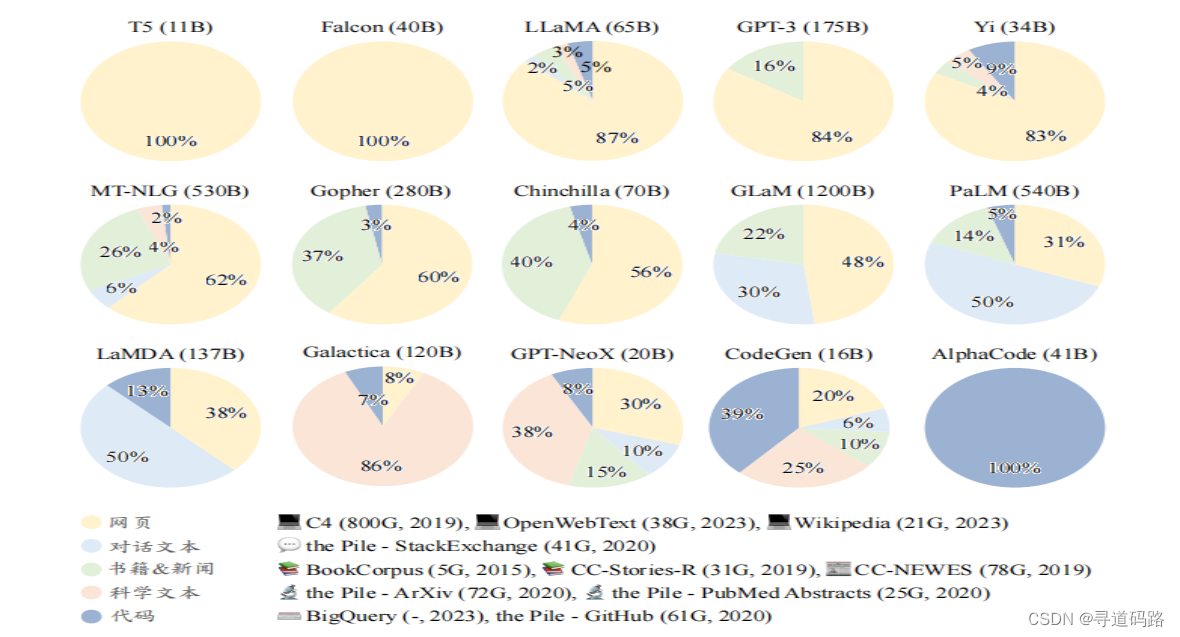
国内常用的数据集网站:悟道数据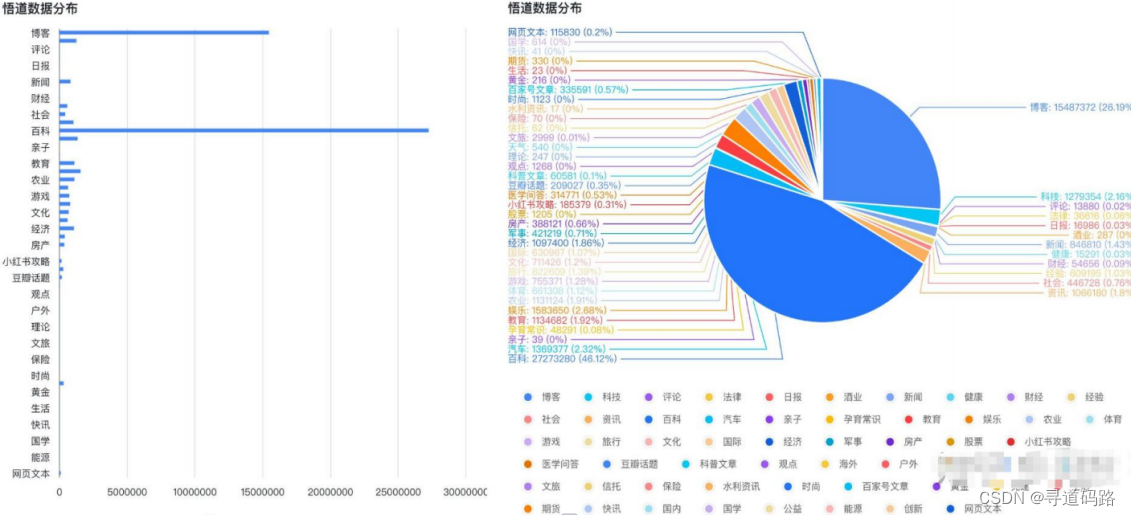
1、通用文本数据
通用数据在大模型训练数据中占比通常非常高,主要包括网页、书籍、对话文本等类型,为 大模型提供了大规模且多样的训练数据。
• 网页:是通用数据中数量最大的一类。随着互联网的大规模普及,人们通过网站、 论坛、博客、APP 等各种类型网站和应用,创造了海量的数据。网页数据所包含的海量内容,使得语言模型能够获得多样化的语言知识并增强其泛化能力。 同样包含很多低质量文本,需要进行过滤处理
• 对话数据:对话数据是指包含两个或更多参与者之间交流的文本内容。对话数据包含书面形式的对话、聊天记录、论坛帖子、社交媒体评论等。当前的一些研究也表明,对话数据可以有效增强语言模型的对话能力,并潜在地提高其在多种问答任务上的表现。
• 书籍:书籍可以丰富语言模型的知识库。书籍通常包含广泛的词汇,包括专业术语、文学表达以及各种主题词汇。利用书籍数据进行训练,语言模型可以接触到多样化的词汇,从而提高其对不同领域和主题的理解能力。相较于其他语料库,书籍也是最重要的,甚至是唯一的长文本书面语的数据来源。书籍提供了完整的句子和段落,使得语言模型可以学习到上下文之间的联系。这对于模型理解句子中的复杂结构、逻辑关系和语义连贯性非常重要。
2、专业文本数据
专业数据在通用大语言模型中所占比例通常较低,但是专业数据对于改进大语言模型在下游任务上的特定能力有着非常重要的作用。专业数据有非常多的种类,当前大语言模型使用的三类专业数据,包括多语言数据、科学文本以及代码。
• 多语言数据:对于增强大语言模型语言理解和生成多语言能力具有至关重要的作用。当前的大语言模型训练除了需要目标语言中的文本之外,通常还要整合多语言语料库。
• 科学文本:包括教材、论文、百科以及其他相关资源。这些数据对于提升大型语言模型在理解科学知识方面具有重要作用。科学文本数据的来源主要包括 arXiv 论文、 PubMed 论文、教材、课件和教学网页等。由于科学领域涉及众多专业领域且数据形式复杂,通常还需要对公式、化学式、蛋白质序列等采用特定的符号标记进行预处理。使得语言模型更好地处理和分析科学文本数据。
• 代码:代码是进行程序生成任务所必须的训练数据。通过在大量代码上进行预训练,大语言模型可以有效提升代码生成的效果。代码是一种格式化语言,它对应着长程依赖和准确的执行逻辑。可以提升语言模型的逻辑推理能力。
二、数据质量过滤
直接收集到的文本数据往往掺杂了很多低质量的数据。例如,从网页抓取的数据中可能包含由机器自动生成的广告网页。为了优化模型学习的性能,需要去除语料库中的低质量数据。目前主要使用以下两种数据清洗方法:基于启发式规则的方法,和基于分类器的方法。
1、基于启发式规则
基于启发式的方法则通过一组精心设计的规则来消除低质量文本,启发式规则主要包括:
• 语言过滤:如果一个大语言模型仅关注一种或者几种语言,那么就可以大幅度的过滤掉数据
中其他语言的文本。
• 指标过滤:利用评测指标也可以过滤低质量文本。例如,可以使用语言模型对于给定文本的困惑度(Perplexity)进行计算,利用该值可以过滤掉非自然的句子。
• 统计特征过滤:针对文本内容可以计算包括标点符号分布、符号字比(Symbol-to-Word Ratio)、句子长度等等在内的统计特征,利用这些特征过滤低质量数据。
• 关键词过滤:根据特定的关键词集,可以识别和删除文本中的噪声或无用元素,例如,HTML标签、超链接以及冒犯性词语等。
2、基于分类器方法
基于分类器的方法目标是训练文本质量判断模型,并利用该模型识别并过滤低质量数据。GPT-3、PALM 以及 GLam模型在训练数据构造时都使用了基于分类器的方法。
目前常用来实现分类器的方法包括轻量级模型(如 FastText 等)、可微调的预训练语言模型(如 BERT、BART 或者 LLaMA 等)以及闭源大语言模型 API(如 GPT-4、Claude 3)。
三、数据去重过滤
对预训练数据进行去重处理是一个重要步骤。由于大语言模型具有较强的数据拟合与记忆能力,很容易习得训练数据中的重复模式,可能导致对于这些模式的过度学习。预训练语料中出现的重复低质量数据可能诱导
模型在生成时频繁输出类似数据,进而影响模型的性能。
1、模糊去重
可以采用SimHash,MinHash算法删除相似的文档:对于每个文档,计算其与其他文档的近似相似性,并删除高重叠的文档对。
通过更改哈希算法的参数,可以调整去重的比例。
2、精确去重
一般采用精确子字符串去重,是序列级去重。通过使用后缀数组查找字符串之间的精确匹配,删除重复超过给定阈值的连续token的段落。
假设我们有两篇文章如下:
文章1: “我喜欢吃苹果,苹果是我最喜欢的水果。”
文章2: “我喜欢吃苹果,因为苹果很好吃。”
在这两篇文章中,“我喜欢吃苹果,”是重复的部分。因此,通过使用精确去重的方法,我们将在两篇文档中只保留一个“我喜欢吃苹果,”。
所以,处理过后的文章可能就变成了:
文章1: “我喜欢吃苹果,苹果是我最喜欢的水果。”
文章2: “因为苹果很好吃。”
实现中可以综合考虑去重效率和去重效果之间的权衡。例如,在文档层面采用了开销较小的近似匹配模糊去重来实现去重,而在句子层面则采用了精确匹配算法来确保去重的准确性。
四、数据敏感过滤
收集到的数据可能包括有毒内容或隐私信息,需要进一步进行更为细致的过滤和处理。与质量过滤类似,不同类型的数据内容往往需要采用特定的过滤规则。
1、过滤有毒内容
为了精确过滤含有有毒内容的文本,可以采用基于分类器的过滤方法。通过设置合理的阈值,训练完成的分类器将能够有效识别并过滤掉含有有毒内容的信息。在进行分类阈值设置时,需要在精确度和召回率之间寻求平衡,避免过多或者过少去除候选数据。
2、过滤隐私内容
预训练文本数据大多来自互联网,其中可能包括用户生成的敏感信息或可识别的个人信息,如姓名、地址和电话号码等。这些信息如果不加处理,将增加隐私泄露的潜在风险。因此,在预处理
阶段,需要去除这些可识别的个人信息。一种直接且有效的方法是使用启发式方法,如关键字识别,来检测和删除这些私人信息。
五、数据影响分析
在训练大语言模型的过程中,预训练数据的质量对模型能力的影响至关重要。基于含有噪音、有毒和重复数据的低质量语料库进行预训练,会严重损害模型性能。在下面的内容中,我们从三个角度简要阐述数据对预训练效果的影响。
1、数据数量的影响
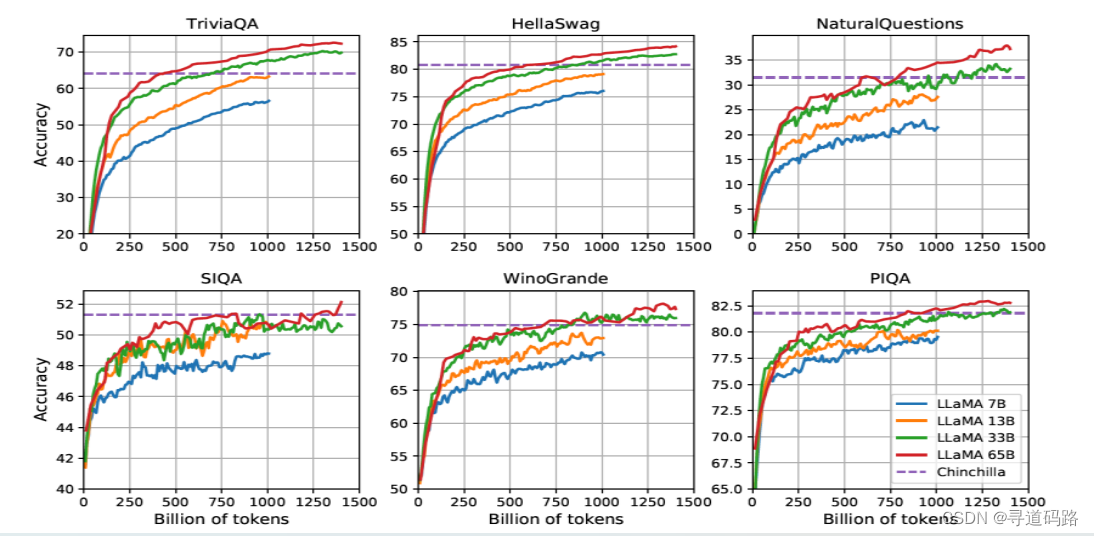
整体上,语言模型的性能会随着训练数据数量的增加而提升,符合扩展法则。然而,早期的研究工作(扩展法则)认为增加模型参数更为重要,数据量的增长对模型性能的提升非常大。数据量的扩展性本质上来源于 Transformer 模型的可扩展性,这也是大语言模型能够取得成功最为关键的基础要素。
如图:随着训练数据量的不断提升,模型在分属两类任务的 6 个数据集上的性能都在稳步提高
2、数据质量的影响
在获取充足数量的预训练数据后,数据质量直接决定了模型的实际性能。通 过显著提升数据质量,使得语言模型在参数、数据、算力更加节约的情况下就能 展现出与更大规模模型相匹敌甚至更为优异的性能。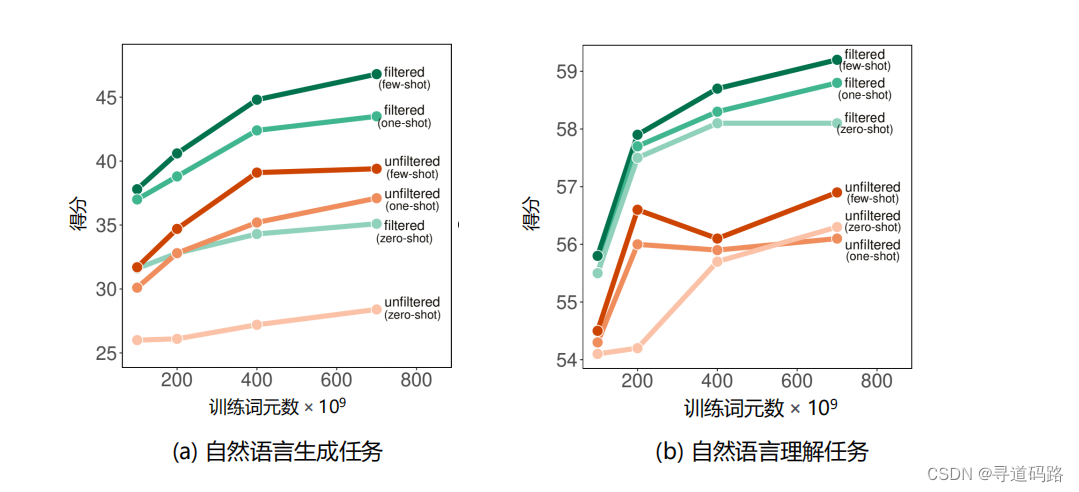
• 整体影响:在很多模型的探索研究过程中,发现在高质量数据上训练的模型都能取得更为出色的表现。此外,大语言模型所掌握的知识信息也来源于预 训练数据,这意味着如果模型在包含事实性错误的、过时的数据上进行训练,那 么它在处理相关主题时可能会产生不准确或虚假的信息,这种现象被称为“幻象” 。
• 重复数据. 很研究表面,重复数据会降低大语言模型利用上下文中信息的能力。会削弱模型在上下文学习中的泛化能力,使其难以适应各种复杂的语言环境和任务需求。因此,通常的建议是对于预训练数据进行精细的去重操作。
• 有偏、有毒、隐私内容.数据是大语言模型掌握知识与建立能力的基础,而语言模型是对于训练数据语义的压缩。一旦数据中包含有偏、有毒、隐私的内容,将会对于模型造成严重的不良影响。在有偏内容上训练可能会导致语言模型学习并复制这些偏见,进而在其生成的文本中表现出对诸如种族、性别和年龄的偏好或歧视。进一步,如果训练数据中包含有毒内容,模型则可能会产生侮辱性、攻 击性或其他有害的输出;而在含有隐私内容的数据上训练可能会导致模型在输出中无意中泄露或利用个人数据。这些问题对于大语言模型的对齐带来了很大挑战。
六、简单实践样例
1、质量过滤
在质量过滤阶段,包含过滤和清洗两个主要流程。在过滤阶段,被判断为低质量的数据会被直接丢弃;而在清洗阶段,经过清洗后的高质量文本会替换原始文本。质量过滤阶段的实现可以依赖于启发式规则(如数据集统计特征、正则表达式匹配等)、预训练模型度量(如模型困惑度等)和语言标签判别(如语言分类器打分)等。下面以使用 FastText 的语言过滤模块为例来展示实现细节。首先,加载预训练好的 FastText 语言分类器,为每个输入文本生成一个语言标签,不符合配置文件中语言类别的文本将被过滤。
import refrom fasttext import load_model# 加载预训练好的 FastText 语言分类器language_classifier = load_model("language_classifier.bin")def filter_and_clean_data(input_texts, language_config): filtered_texts = [] for text in input_texts: # 生成语言标签 language_label = language_classifier.predict(text)[0][0] # 判断语言是否符合配置文件中的语言类别 if language_label not in language_config: continue # 清洗文本 cleaned_text = clean_text(text) # 添加到过滤后的文本列表 filtered_texts.append(cleaned_text) return filtered_textsdef clean_text(text): # 使用正则表达式去除特殊字符和数字 cleaned_text = re.sub('[^a-zA-Z\s]', '', text) # 去除多余的空格 cleaned_text = re.sub('\s+', ' ', cleaned_text).strip() return cleaned_text# 示例输入文本列表input_texts = ["This is a sample English sentence.", "这是一个中文句子。", "Ceci est une phrase française."]# 配置文件中的语言类别language_config = {"__label__en", "__label__zh", "__label__fr"}# 过滤和清洗数据filtered_texts = filter_and_clean_data(input_texts, language_config)print(filtered_texts)2、去重过滤
在去重阶段,集成了句子级和文档级去重方法,分别基于句子间元组的相似性与 MinHashLSH 算法实现。下面以句子级去重为例来展示实现细节。首先,对文本包含的所有句子(每行对应一个句子)计算n元组,对于相邻的句子之间 n元组的 Jaccard 相似度超过设定阈值的都将会被过滤。
import refrom gensim.models import Word2Vecfrom gensim.similarities import SoftCosineSimilarity, SparseTermSimilarityMatrixfrom gensim.similarities import MinHashLSHdef sentence_level_deduplication(text, threshold=0.8): # 将文本分割成句子 sentences = re.split('[。!?]', text) # 计算n元组 ngrams = [sentence.split() for sentence in sentences] # 计算Jaccard相似度 similarity_matrix = [[jaccard_similarity(ngrams[i], ngrams[j]) for j in range(len(sentences))] for i in range(len(sentences))] # 根据阈值过滤相似度高于阈值的句子 filtered_sentences = [] for i in range(len(sentences)): if not any(similarity_matrix[i][j] > threshold for j in range(i)): filtered_sentences.append(sentences[i]) return ' '.join(filtered_sentences)def jaccard_similarity(set1, set2): intersection = len(set(set1).intersection(set(set2))) union = len(set(set1).union(set(set2))) return intersection / union# 示例文本text = "今天天气真好,我们去公园玩吧。天气不错,适合户外运动。"# 句子级去重filtered_text = sentence_level_deduplication(text)print(filtered_text)3、隐私过滤
在隐私过滤阶段,去除了个人身份信息,包括邮件名、身份证号、电话号码、网址与 IP 地址。我们以去除身份证号为例,对每个输入的文本,下面使用正则替换的方式将匹配到的身份证号替换为特定字符串。
import redef filter_privacy(text): # 匹配身份证号的正则表达式 id_card_pattern = r'\d{18}|\d{17}[Xx]' # 将匹配到的身份证号替换为特定字符串 filtered_text = re.sub(id_card_pattern, '[IDENTITY_REMOVED]', text) return filtered_text# 示例文本text = "我的身份证号是123456789012345678,请保密。"# 隐私过滤filtered_text = filter_privacy(text)print(filtered_text)总结
大语言模型预训练数据准备是实现高性能模型的关键步骤。本文从数据来源、质量过滤、去重过滤、敏感过滤以及数据影响分析等多个方面进行了详细的介绍。通过对这些环节的深入理解,可以帮助我们更好地为大语言模型的训练提供高质量的预训练数据,从而提升模型的性能和效果。在未来的研究中,我们可以进一步探索如何利用更多的高质量数据来训练大语言模型,以实现更加强大的自然语言处理能力。

??更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!