1 机器学习基础
1.1 机器学习是什么
机器学习是计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的学科。
机器学习要做的就是根据已有的训练数据得到模型,并根据模型实现对未知的数据的最优预测。
机器学习涉及统计学、概率论、逼近论、凸分析、算法复杂度理论等多门学科。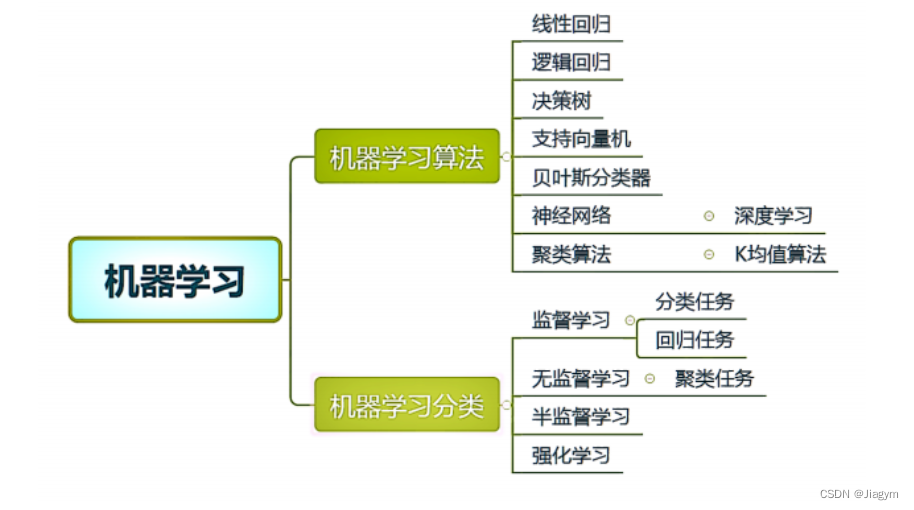

1.2 机器学习
机器学习主要包括:
监督学习(Supervised Learning): 在监督学习中,模型从带有标签的训练数据中学习,目标是预测新的、未标记数据的标签。典型的任务包括分类和回归。 无监督学习(Unsupervised Learning): 无监督学习中,模型在没有标签的数据上学习。常见的任务包括聚类(将相似的数据分组) 半监督学习(Semi-Supervised Learning): 半监督学习结合了监督和无监督学习的元素,其中模型使用带有标签和没有标签的数据进行训练。这对于标注数据较为昂贵或稀缺的情况下是有用的。 强化学习(Reinforcement Learning): 强化学习涉及智能体(agent)从与环境的交互中学习,通过执行动作来最大化某种奖励信号。这在涉及决策和序列学习的任务中很有用,如游戏和机器人控制。2 模型预测
2.1 问题类型
根据输出类型的不同,预测问题主要分为:
分类问题:输出变量为有限个离散变量,当个数为 2 时即为最简单的二分类问题 回归问题:输入变量和输出变量均为连续变量2.2 机器学习的上限和逼近
数据和标签决定了机器学习的上限。
数据的质量: 机器学习模型的性能很大程度上取决于用于训练和测试的数据的质量。如果数据包含错误或者不代表真实场景,模型就很难学到有用的特征。高质量、多样性的数据集有助于训练出泛化
能力更强的模型。
泛化性能关注模型在未知数据上的表现,它不仅仅在训练数据上表现好,还能够推广到新的、未曾见过的数据上。
标签的准确性:标签是指训练数据中每个样本对应的正确输出或目标值。如果标签不准确,那么模型就会学到错误的关系,从而影响其在新数据上的表现。准确的标签是确保机器学习模型有效性的关键。
算法和模型只能趋近于这个上限。
由于实际情况中很难获取完美的数据,也可能存在标签的不准
确性或噪声,因此模型很难达到性能的上限。算法和模型的作用就是
通过学习数据中的特征和规律,尽可能地逼近这个性能上限。
3 机器学习实现步骤
3.1 选择模型
当前主要是了解你要解决的问题是分类、还是回归问题。不同类型的问题需要不同的模型。
3.2 模型训练
数据准备: 将数据集划分,确保模型在未见过的数据上能够泛化良好。 特征缩放: 对数据进行特征缩放,确保不同特征的尺度一致,有助于模型的训练。 模型初始化:根据选择的模型,初始化模型的参数。有些模型可能需要更复杂的初始化过程。 损失函数: 确定模型的损失函数,它衡量模型预测和实际值之间的差异。 优化算法: 选择适当的优化算法,通过迭代调整模型参数,选择合适的损失函数。 训练迭代: 多次迭代训练模型,直到模型收敛或达到预定的训练轮数。3.3 输出最优结果
模型评估: 使用测试集对训练好的模型进行评估,了解模型在未见过的数据上的性能。 性能指标:使用合适的性能指标量化模型的表现。 优化模型:根据评估结果,考虑进一步优化模型,可能包括调整模型参数、增加特征等。 实际部署:将训练好的模型部署到实际应用中,以便进行实时预测或决策。4 深度学习是什么
4.1 深度学习概念
深度学习(DL:Deep Learning)是一种机器学习方法,其灵感来源于人类大脑的结构和工作原理。通俗地说,深度学习模仿人脑的神经网络,通过层层堆叠的神经元(类似人脑中的神经元)来学习和理解复杂的模式和特征。
神经网络就像搭积木: 想象一下,你有一堆不同形状和颜色的积木,每个积木都代表一个神经元。你可以把这些积木按照一定的规则和顺序堆叠在一起,形成一个复杂的结构,这就是一个神经网络。每一层积木都负责处理某些特征,最终组成一个完整的模型。
深度学习是端到端的学习:
有时候,我们不需要手动设计特征提取器,深度学习模型可以端到端地从原始数据中学习特征,使得整个学习过程更加自动化。
举个通俗的例子:
假设你要训练一个计算机程序来识别车辆照片。
在传统的方式中,你可能需要进行一系列手动的步骤:
手动提取特征: 需要手动提取特征(轮廓以及面积大小),然后编写代码去提取这些特征。 设计分类器: 之后,你可能需要设计一个分类器,告诉程序如何利用这些手动提取的特征来判断一张照片是否包含车辆。 调整参数: 你可能还需要不断调整这些特征提取的参数,以提高准确性。而在端到端的深度学习中,情况就不同了:
输入和输出: 你只需告诉程序:“这是一堆车的照片,这是对应的标签(有车或没车)。” 神经网络学习: 使用深度学习模型,这个模型会自动学习从输入(车的照片)到输出(有车或没车)的映射关系。程序会自发学习车的特征,不需要你手动去告诉它。 端到端训练: 整个过程就像一个黑盒子,你只需要关心输入和输出,而深度学习模型会自动调整内部的参数,使得整个系统能够尽可能地正确分类车。端到端学习的核心思想:不再需要手动设计特征提取器,而是直接通过大量的数据告诉模型应该如何完成任务。
4.2 深度学习与机器学习的区别与联系
首先,深度学习是机器学习的一个分支:
模型复杂度:机器学习: 通常涉及手动选择和设计特征提取器,然后使用相对简单的模型(例如线性模型、KNN等)进行学习。
深度学习: 使用深度神经网络,这是一种由多层神经元组成的复杂模型。深度学习模型可以学习更高层次的抽象特征,而无需手动设计特征提取器。 特征表示:
机器学习: 通常需要手动选择和提取特征,这可能涉及较复杂的知识和经验。
深度学习: 模型可以端到端地学习特征表示,不需要手动提取特征。深度学习模型通过多层神经网络逐渐学习数据的抽象特征。 任务适用性:
机器学习: 在处理一些传统的机器学习问题上表现良好,如分类、回归和聚类。
深度学习: 在处理大规模、高维度的数据以及复杂任务,如图像识别、自然语言处理和语音识别方面表现出色。 数据量需求:
机器学习: 对于相对较小的数据集,机器学习算法可能仍然能够取得良好的结果。
深度学习: 通常需要大量的标记数据进行训练,因为深度学习模型的参数数量较大,需要足够的样本来泛化。 计算资源:
机器学习: 相对较轻量,通常可以在较普通的计算机上运行。
深度学习: 对于训练深度神经网络,通常需要更强大的计算资源,例如GPU或TPU,以加速训练过程。(TPU 是谷歌公司设计的专用硬件加速器,用于高效地执行深度学习中的张量计算。TPU 是 Tensor Processing Unit 的缩写)
总体而言,深度学习是机器学习的一个分支,它使用深度神经网络来自动学习特征。在处理大规模和复杂数据时,深度学习通常表现更出色。
深度神经网络的复杂性导致它们的决策过程不太容易解释,这被称为深度学习模型的“黑盒”性质。
想象你在纸上画了一些点、线和颜色。这些就像图像中的像素、边缘和颜色。就像画一样,图像也由基本的元素构成。这些元素是图像的基础,但我们可能无法准确识别它们代表的是什么。
中层特征比喻为图案和形状的组合:你用这些点和线条画出了一个人脸的眼睛、嘴巴等局部轮廓。中层特征是基本元素的组合,通过这些组合,能够识别一些简单的形状和局部结构。
高层特征比喻为整体对象或场景:最后,你用这些形状和结构画出了一个完整的人脸。高层特征是对图像中整体对象的理解,它们让我们能够识别出人脸,提供了更高级别的语义信息(语义信息就是让计算机能够理解图像或文本的“意思”,而不仅仅是看到图像的像素)
4.3 常见的深度学习框架
PyTorch:Facebook出品,语法和 python 相同,操作类似于numpy
TensorFlow:Google出品
MindSpore:华为推出的新一代AI框架
百度: paddlepaddle
5 神经网络(深度学习)的起源的算法
5.1 感知机
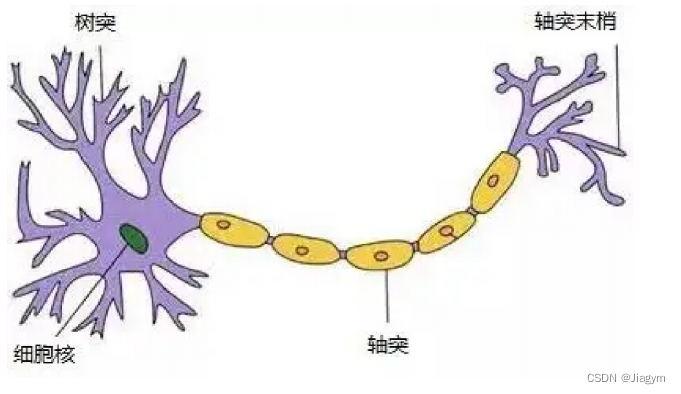
对于神经元的研究由来已久,1904年生物学家就已经知晓了神经元的组成结构。
一个神经元通常具有多个树突,主要用来接受传入信息;而轴突只有一条,轴突尾端有许多轴突末梢可以给其他多个神经元传递信息。轴突末梢跟其他神经元的树突产生连接,从而传递信号。这个连接的位置在生物学上叫做“突触”。细胞核包含遗传信息,决定了神经元的特性。
1943年,心理学家McCulloch和数学家Pitts参考了生物神经元的结构,发表了抽象的神经元模型MP(根据两个作者的名字起的)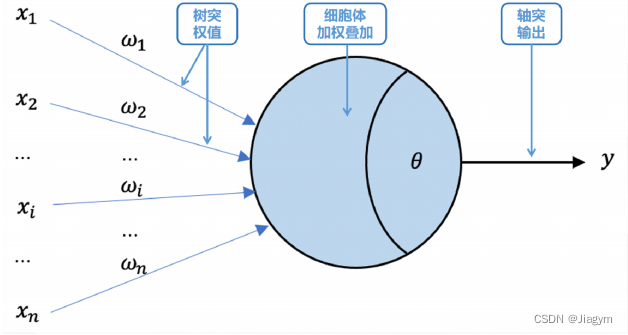
感知机模型是神经元的建模,是将输入值映射到输出值的一个数学函数。有n个输入值,分别是x1, x2, x3 … xn,对应的是权重是w1, w2, w3 … wn,输出值为y。
例如:
f(x) = w * x + b
x:输入 w:斜率(权重) b:截距(权重) y:输出
def perceptron(x, w):x = torch.tensor(x, dtype=torch.float32)w = torch.tensor(w, dtype=torch.float32)b = 0.5return torch.dot(w, x) + bx = [0, 10, 20, 30, 40, 50, 60, 70, 90]w = [0.1, 0.2, 0.3, 0.1, 0.2, 0.3, 0.1, 0.2, 0.3]y = perceptron(x, w)print(y.item())如何让这个感知机学习起来?
让感知机学习起来涉及到许多关键概念。以下是与感知机学习相关的一些重要概念:
5.4 感知机模型能够解决的问题
单层感知机只能解决线性问题,不能解决非线性问题。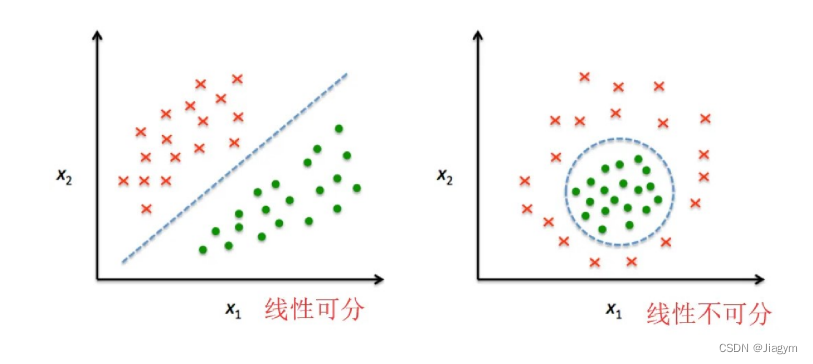
5.5 单层神经网络
单层神经网络:感知机模型 + 激活函数输出
激活函数:把神经网络模型的线性输出变成非线性输出。如果没有激活函数,神经网络的每一层都相当于矩阵相乘,叠加了若干层之后,其结果还是矩阵相乘(线性工具)
这是因为如果使用线性激活函数,多层神经网络将等同于单层网络。
如下图所示: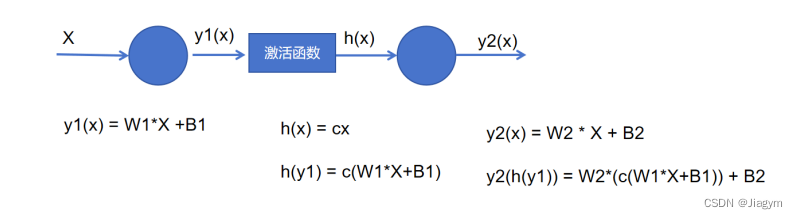
5.6 激活函数 Sigmoid
Sigmoid激活函数被称为S型函数,定义域为[-∞, +∞],值域(0,1),因此被用于计算概率。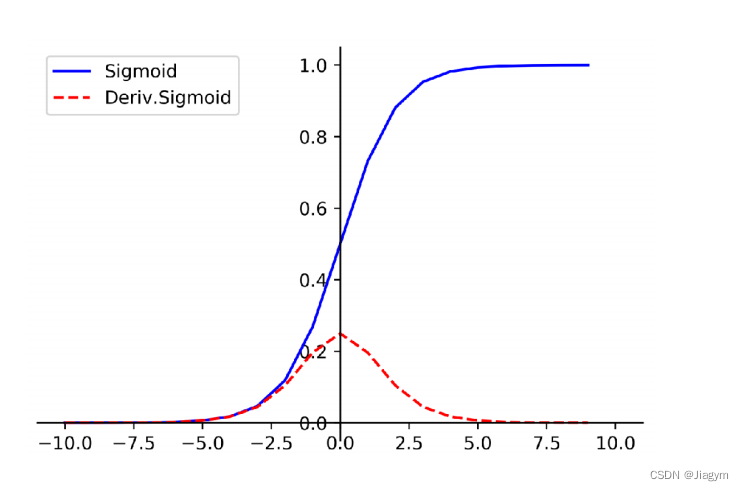
优点:
缺点:
当输入非常大或非常小的时候,输出基本为常数,即变化非常小,进而导致梯度接近于0(容易造成梯度消失问题); 梯度可能会过早消失,进而导致收敛速度较慢;("收敛速度"是指训练神经网络时模型的参数如何逐渐接近最优解或理想值的速度。)5.7 激活函数:ReLu(线性整流函数)
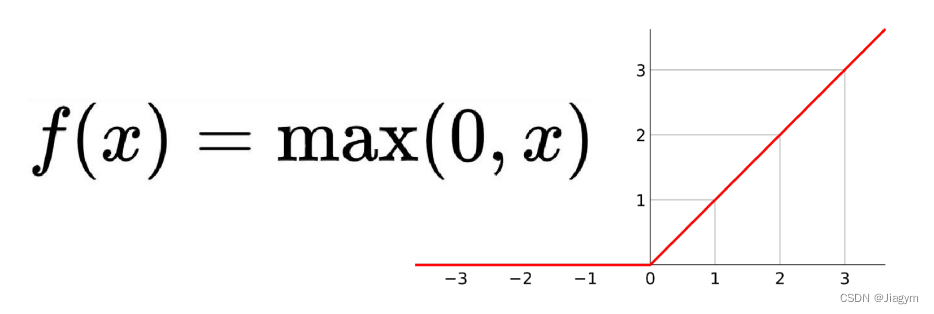
线性整流函数(Rectified Linear Unit, ReLU),在输入大于0时,直接输出该值;在输入小于等于 0时,输出 0。其作用在于增加神经网络各层之间的非线性关系。
优点:
相较于sigmoid函数以及Tanh函数来看,在输入为正时,Relu函数不存在饱和问题。(即解决了梯度消失问题,使得深层网络可训练); 即解决了梯度消失问题,使得深层网络可训练:0.99^365 计算速度非常快,只需要判断输入是否大于0值; 收敛速度远快于sigmoid以及Tanh函数;(备注:"收敛速度"是指训练神经网络时模型的参数如何逐渐接近最优解或理想值的速度) 当输入为正值,导数为1,在“链式反应”中,不会出现梯度消失缺点:
存在Dead Relu Problem,即某些神经元可能永远不会被激活(输出永远是零),进而导致相应参数一直得不到更新; Relu函数的输出不是以0为均值的函数; 可能导致模型收敛速度慢(当所有输入的权重都是正数或负数时,梯度在训练过程中始终指向同一个方向导致收敛速度较慢)x = np.arange(-10, 10, 0.1)# 用于逐位比较取最大值y = np.maximum(0, x)plt.plot(x, y)plt.show()5.8 激活函数:tanh(双曲正切)
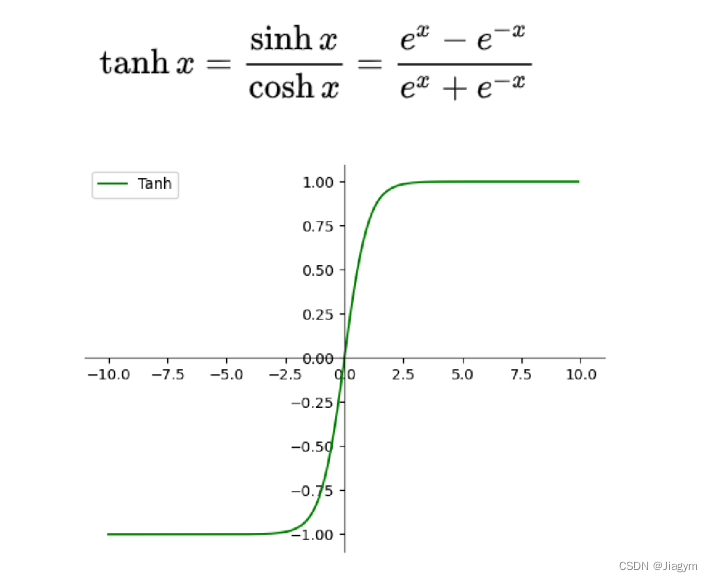
双曲函数,tanh为双曲正切,由双曲正弦和双曲余弦这两种基本双曲函数推导而来。
优点:
解决了的Sigmoid函数输出不是0均值的问题; tanh 的输出范围在 [-1, 1] 之间,相对于 sigmoid 来说,输出的动态范围更大; 在原点附近,tanh函数与y=x函数形式相近,使得当激活值较低时,训练相对容易; tanh 函数的输出范围在 −1到1 之间,且在原点附近的斜率较大,使得它在输入值接近零的地方变化更为敏感。这使得网络在这个区域的权重调整更为明显,有助于梯度的传播。相比之下,sigmoid 函数在原点附近的梯度较小,可能导致梯度消失的问题。零中心化有助于缓解梯度消失问题,使得权重更新更为稳定。缺点:
与Sigmoid函数类似,梯度消失问题仍然存在;5.9 数据预处理
分析一下以下代码:
a