1. 链表的分类
链表的种类很多,主要由三个要素决定:是否带头,单向还是双向,是否循环。
根据这三个要素的组合,共可得到8(2*2*2)种链表
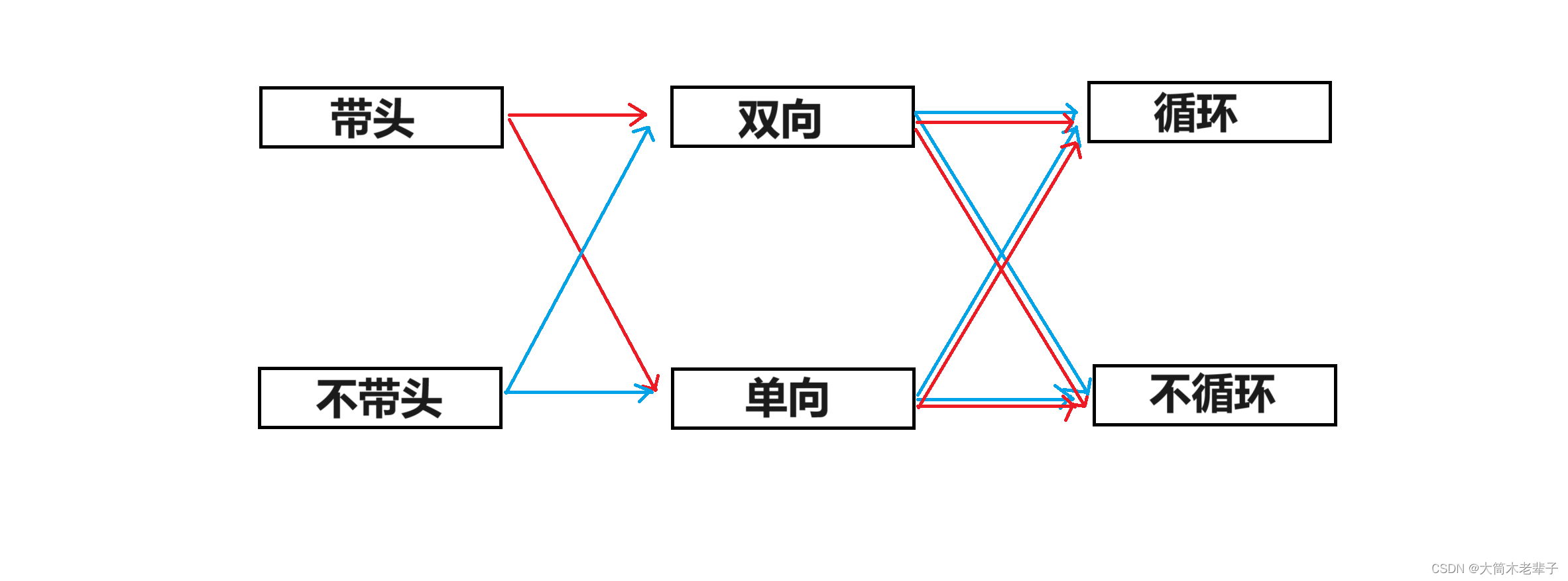
而我们常用的链表有两种:
1. 单链表:不带头单向不循环链表。
2. 双向链表:带头双向循环链表。
之前我们已经实现过单链表C语言单链表-CSDN博客
单链表在三个元素的选择中,选择的都是较为简单的选项,结构简单那就意味着我们在对其进行操作时所能用的现成条件较少,操作函数的实现就较为复杂。
双向链表作为单链表的另一个极端,每个元素都选择了较为复杂的那个,而将结构设计的复杂的目的,就是为了解决一些操作实现起来很麻烦的问题。
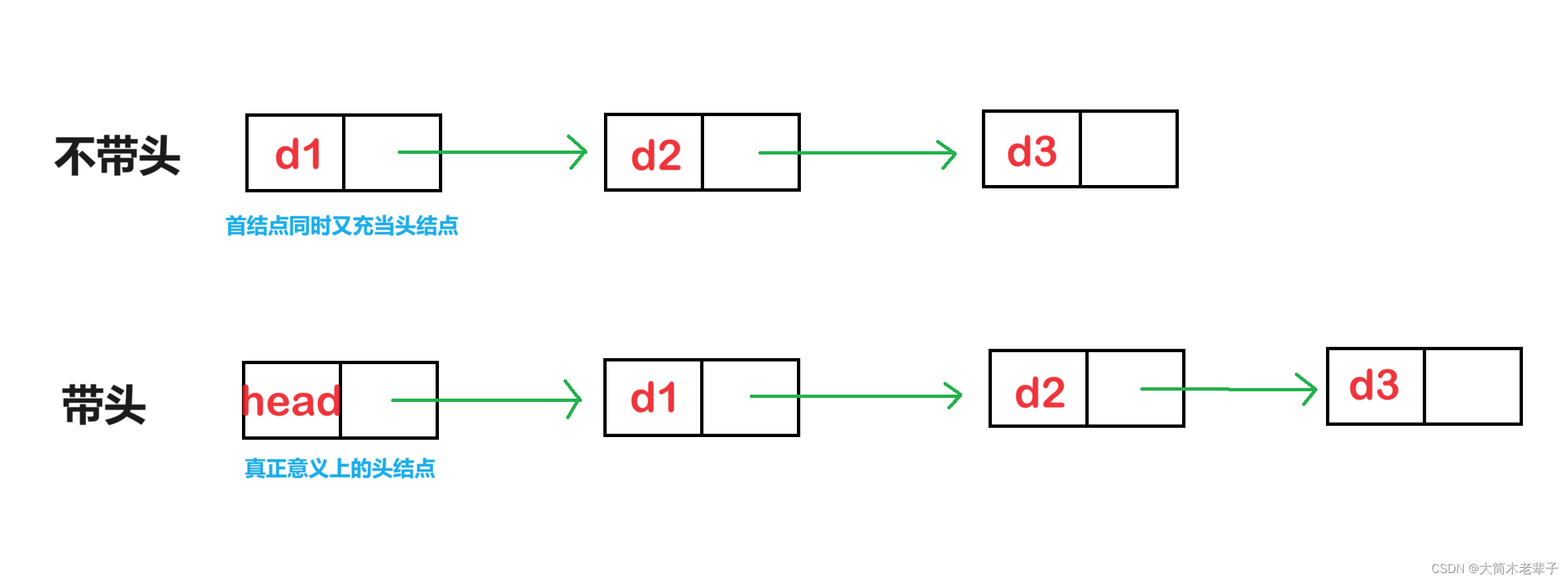
带头的作用
在单链表的实现中,当链表为空时,我们常常要对其进行单独的处理。
例如单链表的尾插和尾删:
//尾插void SLTPushBack(SLTNode** pphead, SLTDataType x){assert(pphead);SLTNode* newnode = SLTBuyNode(x);if (*pphead == NULL){*pphead = newnode;}else{SLTNode* ptail = *pphead;while (ptail->next != NULL){ptail = ptail->next;}ptail->next = newnode;}}//尾删void SLTPopBack(SLTNode** pphead){assert(pphead && *pphead);if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}else{SLTNode* ptail = *pphead;while (ptail->next->next != NULL){ptail = ptail->next;}free(ptail->next);ptail->next = NULL;}}应对这种情况常常需要对头结点进行修改,所以我们仅仅为了这么一种单独的情况,写了一种应对方法并将函数的参数改为了"SLTNode**"类型的指针。
带头,即使得链表自带一个没有意义的结点,始终保持链表中有结点。
这样一来,else部分的代码就对所有情况适用了。
使链表带头很简单,只需要在初始化链表时为其申请一个存储无意义数据的结点即可。
在之后对链表的操作中,要确保不访问这个头结点的数据。
这个头结点通常也被叫做是哨兵位。
//初始化LTNode* LTInit(){LTNode* phead = LTBuyNode(-1);return phead;}双向的作用
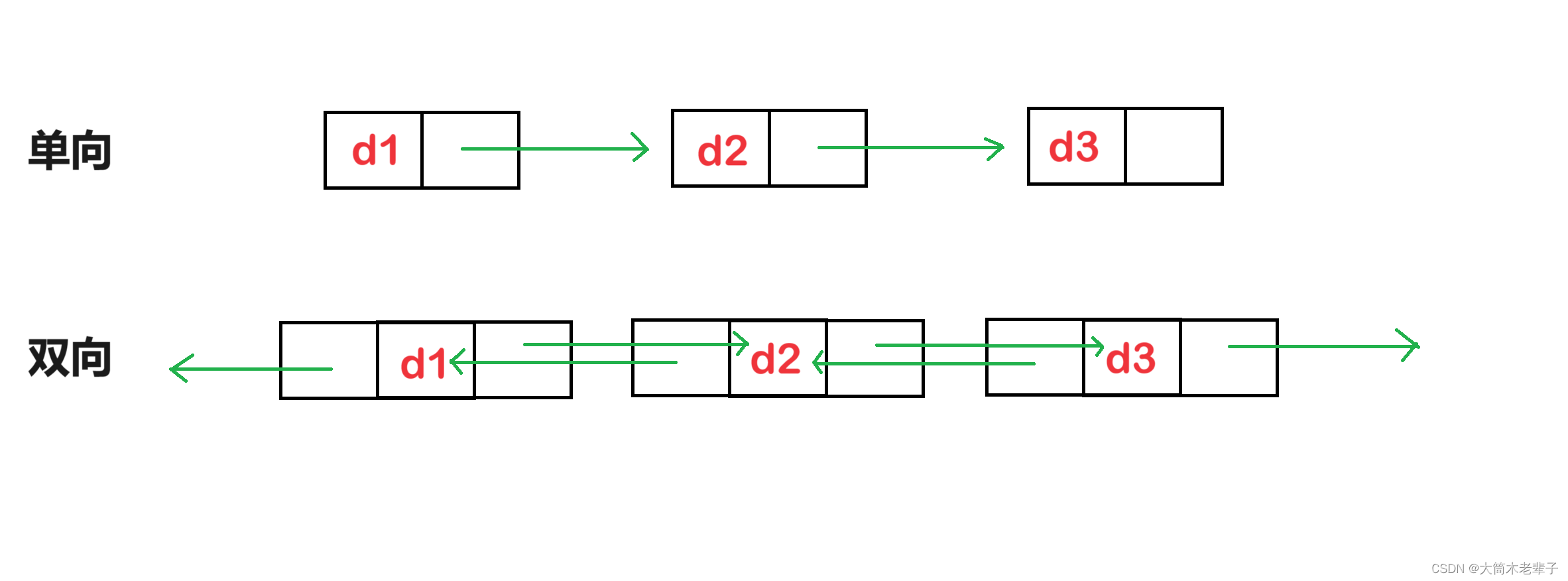
由于单链表只能单向遍历,我们在遇到很多问题时不得不多次遍历链表(查找链表的倒数第k个结点),或者定义一个参数(prev)来存储前一个结点的地址。
例如在指定位置之前插入数据:
//指定位置之前插入void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x){assert(pphead && *pphead);assert(pos);if (pos == *pphead){SLTPushFront(pphead, x);return;}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}SLTNode* newnode = SLTBuyNode(x);newnode->data = x;newnode->next = prev->next;prev->next = newnode;}}这样会极大的降低我们程序运行的效率。
双向,即每个结点不仅包含了指向后一个数据的指针,还包含了指向前一个数据的指针。
//双向链表typedef struct ListNode{LTDataType data;struct ListNode* next;struct ListNode* prev;}LTNode;这样,我们就可以更加自由地去查找结点,提高运行效率。
当然,运行效率的提升一般都是靠空间的消耗来换取的。
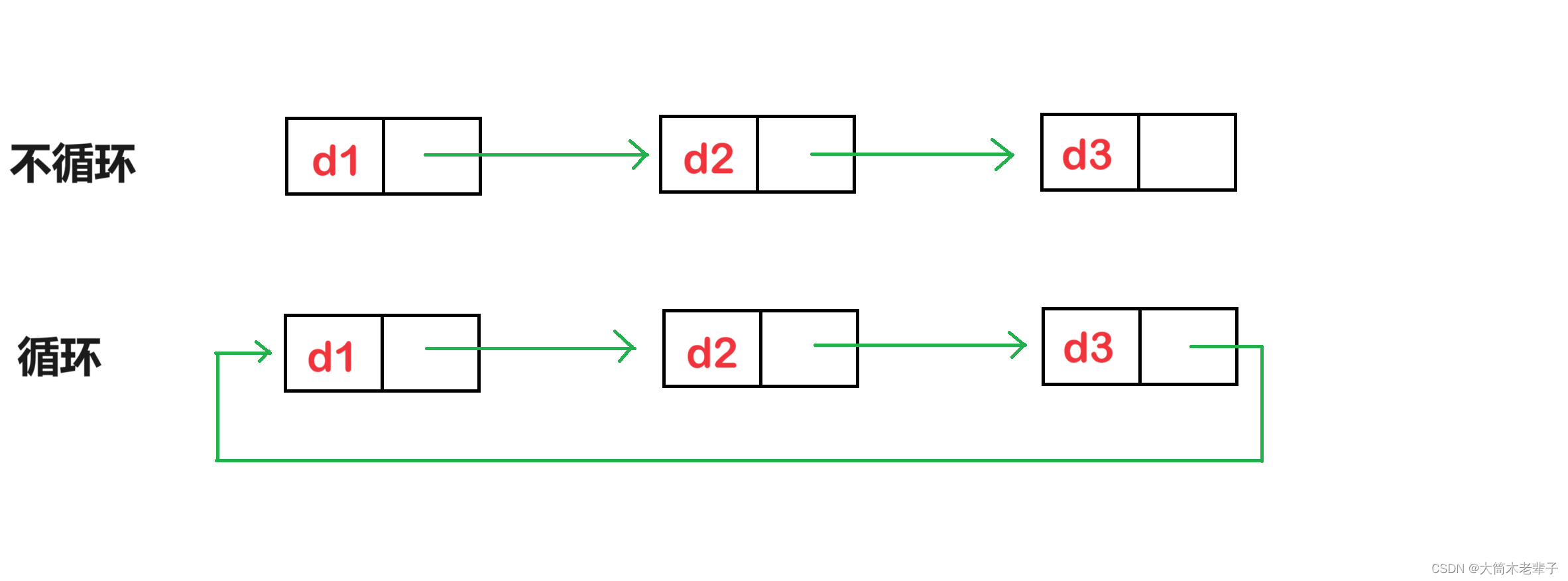
循环的作用
在单链表中,我们常常会为了寻找到尾结点而大动干戈地遍历整个链表。
就例如上面给出的尾插和尾删的代码。
循环,即使得尾结点的next指针指向头结点,并让头结点的prev指针指向尾结点,将整个链首尾相连形成一个环。
这样一来,只需要通过头结点的prev指针就可以查找到尾结点,通过尾结点的next指针就可以找到头结点。
将两个本来相隔最远的结点链接在一起,就使得某些算法的复杂度大幅下降。
双向链表的结构
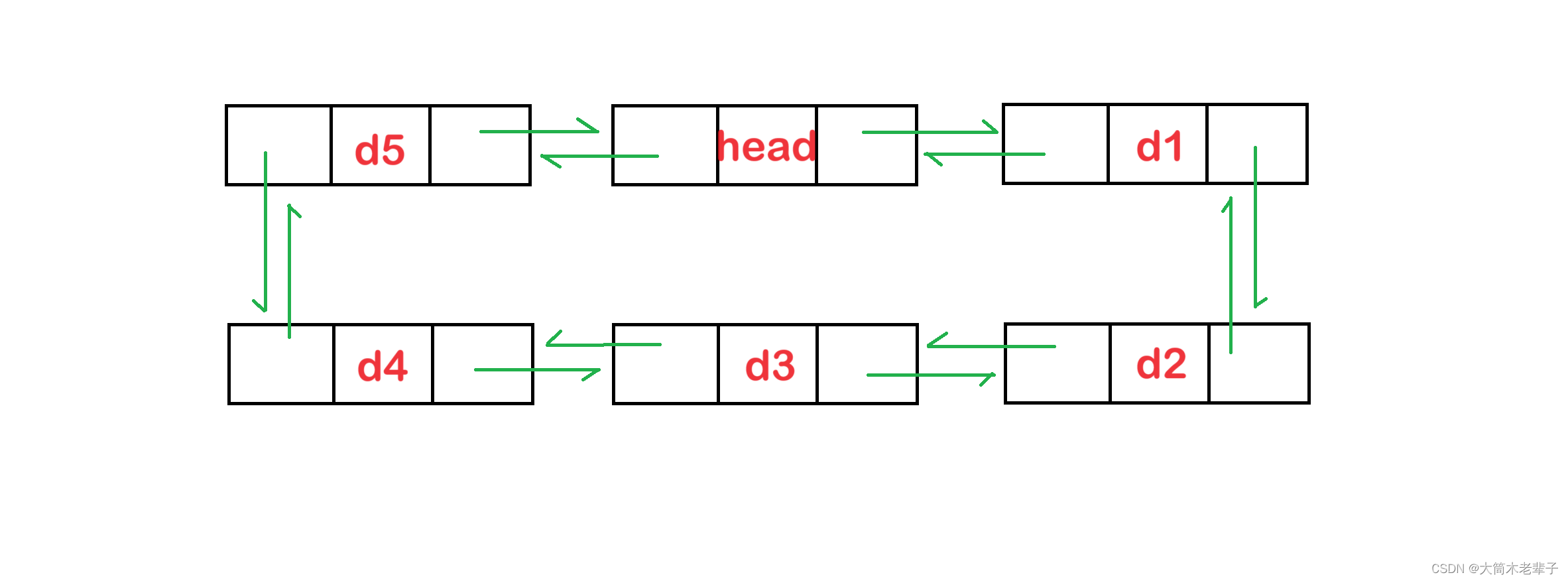
2. 双向链表的实现
2.1 头文件
#pragma once#include <stdio.h>#include <stdlib.h>#include <assert.h>typedef int LTDataType;//双向链表typedef struct ListNode{LTDataType data;struct ListNode* next;struct ListNode* prev;}LTNode;//初始化LTNode* LTInit();//销毁void LTDestroy(LTNode* phead);//尾插void LTPushBack(LTNode* phead, LTDataType x);//头插void LTPushFront(LTNode* phead, LTDataType x);//尾删void LTPopBack(LTNode* phead);//头删void LTPopFront(LTNode* phead);//打印void LTPrint(LTNode* phead);//在pos位置之后插入数据void LTInsert(LTNode* pos, LTDataType x);//查找LTNode* LTFind(LTNode* phead, LTDataType x);//删除pos结点void LTErase(LTNode* pos);//LTErase和LTDestroy为了保持接口一致性而传入一级指针,未将pos或phead置为空2.2 源文件
#define _CRT_SECURE_NO_WARNINGS#include "List.h"LTNode* LTBuyNode(LTDataType x){LTNode* node = (LTNode*)malloc(sizeof(LTNode));if (node == NULL){perror("malloc fail");exit(-1);}node->data = x;node->next = node->prev = node;return node;}//初始化LTNode* LTInit(){LTNode* phead = LTBuyNode(-1);return phead;}//销毁void LTDestroy(LTNode* phead){assert(phead);LTNode* pcur = phead->next;while (pcur != phead){LTNode* next = pcur->next;free(pcur);pcur = next;}free(phead);phead = NULL;}//尾插void LTPushBack(LTNode* phead, LTDataType x){assert(phead);LTNode* newnode = LTBuyNode(x);newnode->prev = phead->prev;newnode->next = phead;phead->prev->next = newnode;phead->prev = newnode;}//头插void LTPushFront(LTNode* phead, LTDataType x){assert(phead);LTNode* newnode = LTBuyNode(x);newnode->next = phead->next;newnode->prev = phead;phead->next->prev = newnode;phead->next = newnode;}//尾删void LTPopBack(LTNode* phead){assert(phead && phead->prev != phead);LTNode* del = phead->prev;phead->prev->prev->next = phead;phead->prev = phead->prev->prev;free(del);del = NULL;}//头删void LTPopFront(LTNode* phead){assert(phead && phead->next != phead);LTNode* del = phead->next;phead->next->next->prev = phead;phead->next = phead->next->next;free(del);del = NULL;}//打印void LTPrint(LTNode* phead){assert(phead);LTNode* pcur = phead->next;while (pcur != phead){printf("%d->", pcur->data);pcur = pcur->next;}printf("head\n");}//查找LTNode* LTFind(LTNode* phead, LTDataType x){LTNode* pcur = phead->next;while (pcur != phead){if (pcur->data == x){return pcur;}pcur = pcur->next;}return NULL;}//在pos位置之后插入数据void LTInsert(LTNode* pos, LTDataType x){assert(pos);LTNode* newnode = LTBuyNode(x);newnode->prev = pos;newnode->next = pos->next;pos->next->prev = newnode;pos->next = newnode;}//删除pos结点void LTErase(LTNode* pos){//pos理论上来说不能是哨兵位assert(pos);pos->prev->next = pos->next;pos->next->prev = pos->prev;free(pos);pos = NULL;}可见,对双向链表进行操作的各种函数要比对单链表进行操作的各种函数简单的多。
但是相对的,双向链表会占用更多的空间。