LLaMA Factory+ModelScope实战——使用 Web UI 进行监督微调
文章原始地址:https://onlyar.site/2024/01/14/NLP-LLaMA-Factory-web-tuning/
引言
大语言模型微调一直都是一个棘手的问题,不仅因为需要大量的计算资源,而且微调的方法也很多。在尝试每种方法过程中,配置环境和第三方库也颇为麻烦。。而 LLaMA Factory1 是一个高效的大语言模型训练和推理的框架,不仅集成多种高效训练方法,而且能持续适配国内外各种开源大模型。该框架还提供了能够一站式实现大模型预训练、监督微调、评估、推理的 Web UI 界面,使用户能够直观地看到训练选项、模型数据集选项、训练进度等重要信息。
为方便国内用户使用,该框架支持了魔搭社区(ModelScope)的模型和数据集资源,训练前可自动下载并缓存资源。
而 Yi 系列大模型2是李开复博士创办的“零一万物”公司研发的首款开源大模型。参数规模有 6B 和 34B。其中的 Yi-34B 不仅支持 200K tokens 的超长窗口,更是在众多性能评测榜单上取得领先成绩。
本次我们基于 LLaMA Factory 框架,在一张 V100 显卡上使用 ModelScope 上支持的在线数据集对 Yi-6B 模型进行监督微调,使其获得对话能力。
环境准备
LLaMA Factory框架目前托管在 github 上,所以,我们要先使用 git 来安装 LLaMA Factory 开源框架:
git clone https://github.com/hiyouga/LLaMA-Factory.git等待仓库下载完毕,进入仓库并安装所需依赖:
cd LLaMA-Factorypip install -r requirements.txt注意:截至文章编辑时(2024 年 1 月 22 日),该框架在使用最新版本的 torch 库时,会出现无法正常推理的情况。请根据您的硬件环境选择合适的 torch 版本进行安装,版本范围为 torch>=1.13.1,<=2.0.1。
Web UI 的使用
服务的启动
首先我们要在命令行里设置一个环境变量 USE_MODELSCOPE_HUB=1,框架程序在运行时会读取这个环境变量,当 USE_MODELSCOPE_HUB 的值为 1 时框架才会使用 ModelScope 在线资源。在 Windows 和 Linux 操作系统上,设置环境变量的命令是不同的,请二选其一:
export USE_MODELSCOPE_HUB=1 # Linux 上使用的命令set USE_MODELSCOPE_HUB=1 # Windows 上使用的命令接着使用以下命令启动 Web UI:
CUDA_VISIBLE_DEVICES=0 python src/train_web.py # 指定一块 GPU 启动网页服务LLaMA Factory 的 Web UI 目前只支持单卡训练/推理,当你的机器有多张显卡时请使用 CUDA_VISIBLE_DEVICES 指定一张显卡启动程序。
我们在浏览器地址栏中输入 http://localhost:7860 进入 Web 界面,接着可以在“语言/Language”选项中,将界面的语言修改为“中文/zh”,然后在模型名称中选择“Yi-6B”,在模型路径中选择“01ai/Yi-6B”。
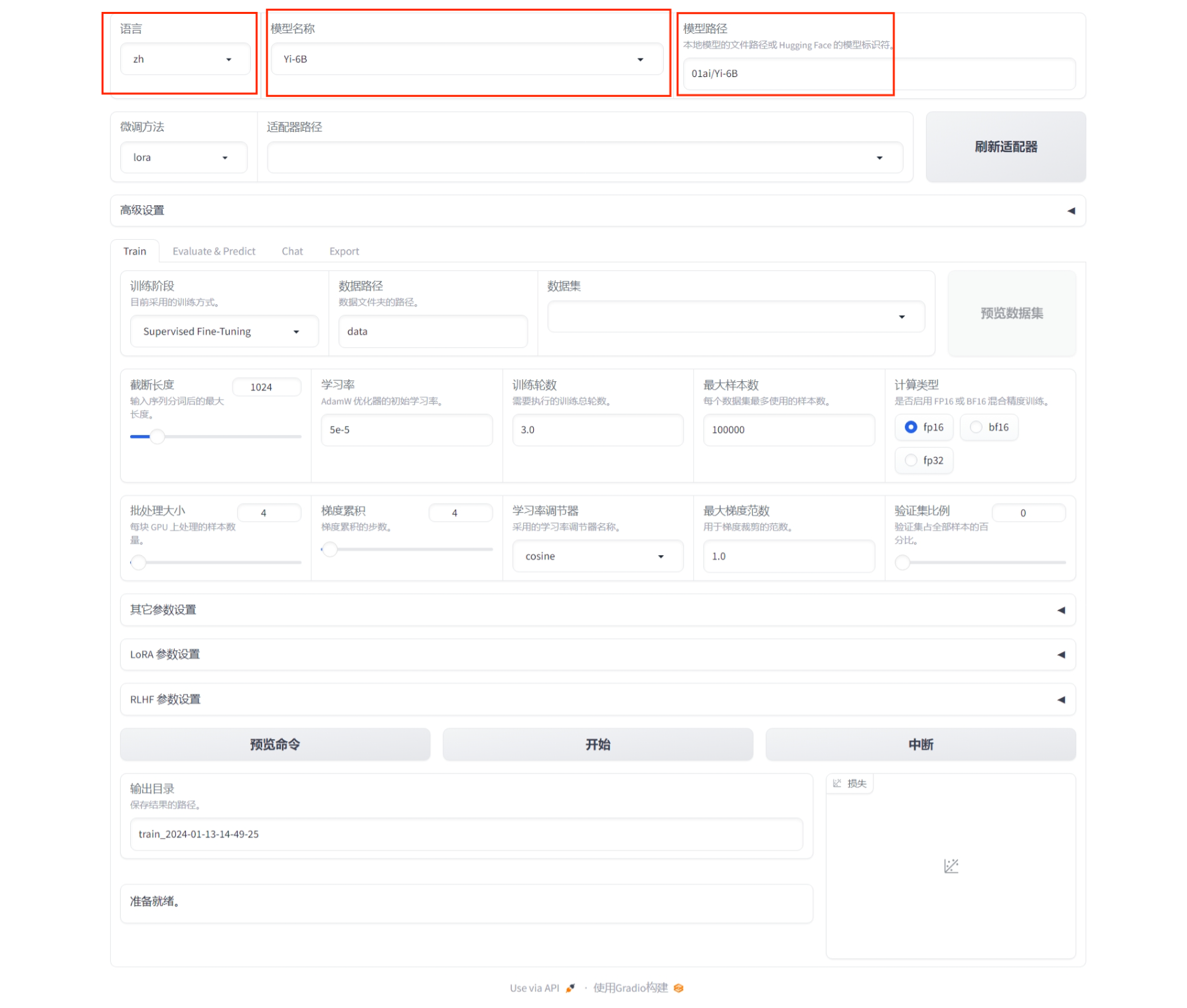
监督微调
第二行中的微调方法,我们保持 “lora” 不变,适配器路径使用默认的空值。
“微调方法”有三个可选项:
full:全参数微调,对模型的所有参数进行训练,这种方法需要大量的计算资源和时间;freeze:参数冻结,即对模型的大部分参数进行冻结操作,仅训练少数参数,以便于在有限资源下对大模型进行微调;lora:Low-Rank Adaptation3,是一种参数高效性微调方法,不仅让微调的成本显著下降,还能获得和全参数微调类似的效果。适配器指的是 lora 微调的输出结果,可以理解为将预训练模型的输出转换为目标形式的组件,需要搭配预训练模型一起使用。在模型的推理和合并阶段中,才需要指定“适配器路径”作为输入,而在微调过程中则不需要指定这个参数。
打开“高级设置”,本次演示中量化等级保持 none,提示模板使用 xverse,RoPE 插值方法和加速方式均为 none。

QLoRA4是一种能够减少显存占用的大模型高效微调方法,当模型过大导致显存不够时可以考虑使用 4bit / 8bit QLoRA。
提示模板在微调时为大模型指示人类输入和机器输出的模板,除了 default 以外也可以根据仓库中Supported Models的说明选择合适的模板进行实验。
RoPE5插值可以扩展 LLaMA 模型的上下文长度,如果使用了 linear 参数微调模型推理时也要设置为 linear,如果微调时使用 none,推理时可以选择 none 或 dynamic。
框架支持 FlashAttention-26 (RTX4090、A100 或 H100 GPU)和 unsloth(LLaMA、Mistral 和 Yi 模型)的加速方式,均需要额外安装。
接下来我们来到训练参数设置面板:
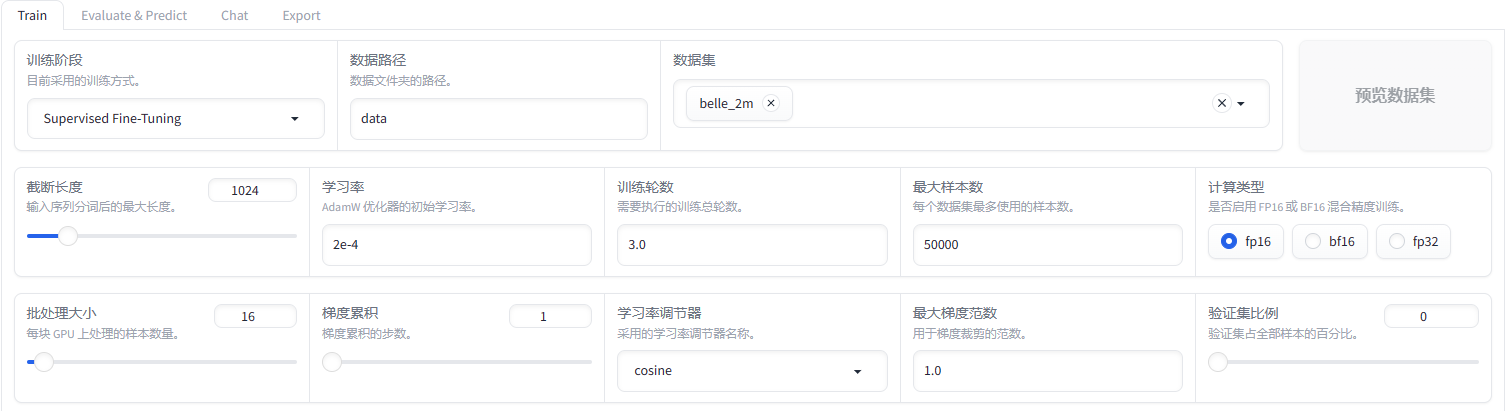
训练阶段选择 Supervised Fine-Tuning(监督微调),数据路径保持 data 不变,数据集我们使用 ModelScope 社区提供的 belle_2m 数据集。其他参数的介绍如下:
打开其它参数设置面板,我们对其中的参数进行一些修改:
注意,在模型的微调过程中,使用较小的保存间隔可能会在训练的过程中保存大量的检查点(checkpoint),占用大量的磁盘空间。在实际微调时可以根据训练的总步数适当调大保存间隔。
预热步数:指的是学习率预热过程中加到正常学习率的步数,可选参数,本次实验设为 50;NEFTune7 噪声参数:在训练过程中适量添加噪声,可选参数,本次实验设为 5;序列打包8:将多组数据打包到一起进行训练,能够提高模型的上下文能力和训练速度。因为本次实验使用的数据集长度较小,所以可以使用序列打包技术提高模型在较长上下文的表现。这也决定了我们的学习率参数应该稍大些;缩放归一化层:可以提高训练过程中的稳定性,本次实验中不勾选。下面打开 LoRA 参数设置面板:

最后设置输出目录(输出结果为 LoRA 适配器),点击“预览命令”,可以看到实际的所有的命令行参数,点击“开始”,在下面可以看到打印出来的日志。等待模型和数据集加载完毕,就会显示训练过程的进度条,以及已用时间和剩余时间。等训练结束,面板会显示“训练完成”,没训练完也可以点击“中断”,程序会根据最后一个检查点(checkpoint)生成训练结果文件夹。
推理对话
当模型结束以后,同样可以使用 LLaMA Factory 的 Web UI 跟训练好的模型进行对话。
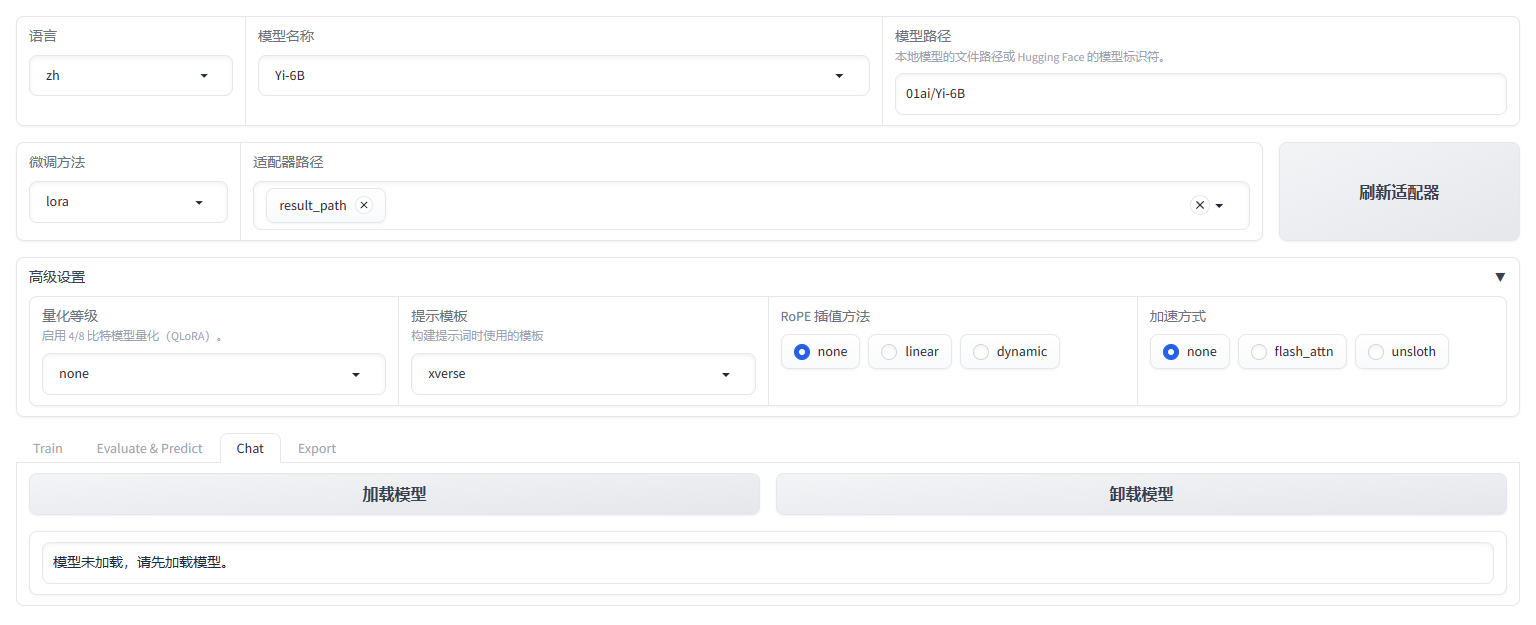
首先刷新适配器路径列表,在下拉列表中选择刚刚训练好的结果。然后在提示模板中选择刚刚微调时采用的 xverse,RoPE 插值使用 none。
最后点击“加载模型”:
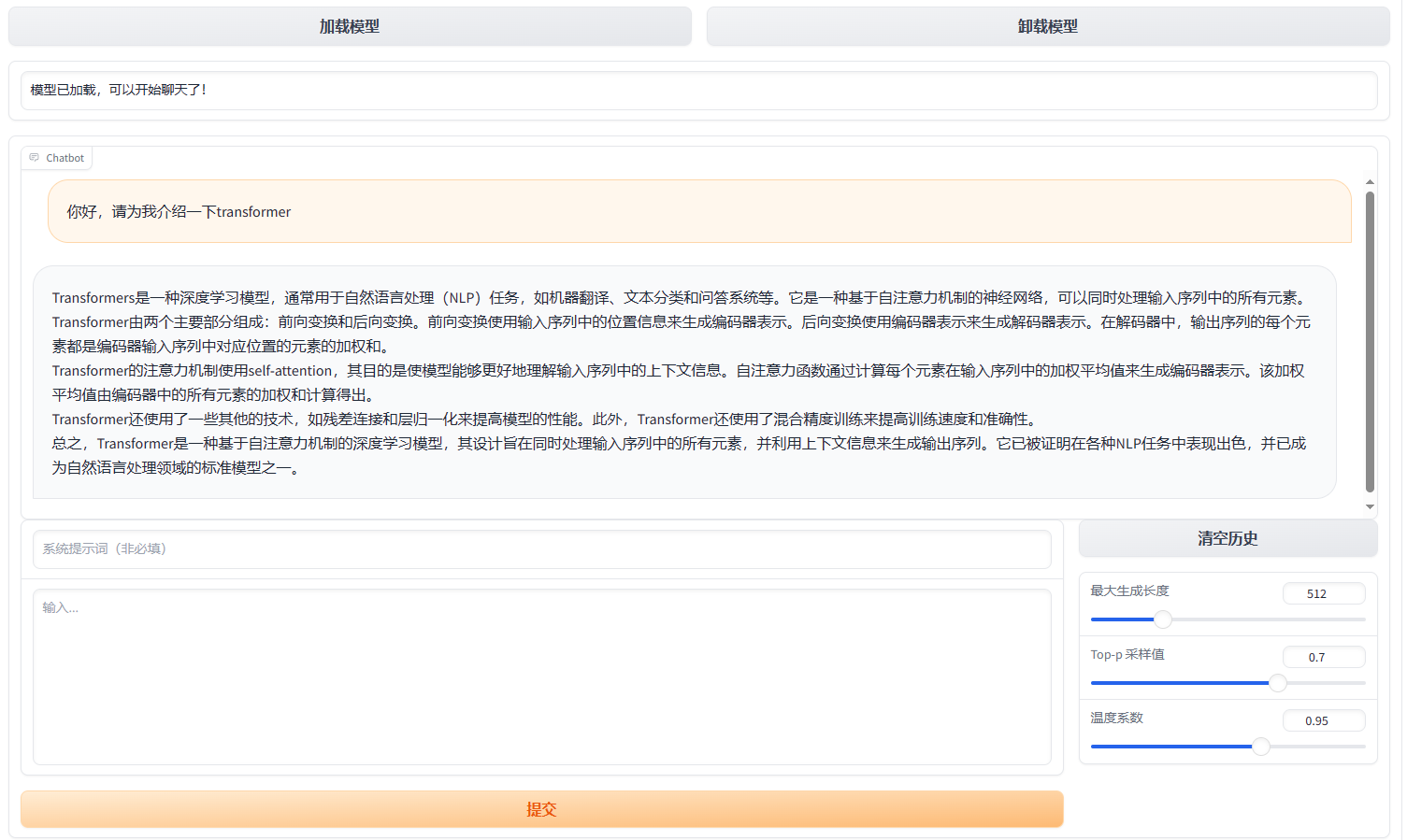
在对话过程中,在输入框内撰写内容,并可以添加系统提示词。点击“提交”后会调用大模型生成回答。“清空历史”可以清除对话积累的上下文。右侧的最大生成长度、Top-p 和温度系数都是可以自己调整的。
对话结束后,如果想更换模型或适配器,需要点击“卸载模型”,卸载后才能重新加载模型。
模型合并
当我们使用 LoRA 训练结束以后,获得的实际上是一个适配器。单独的适配器需要和模型一起使用,我们也可以使用 LLaMA Factory 的模型合并功能将适配器和模型基座组装成一个完整的模型。
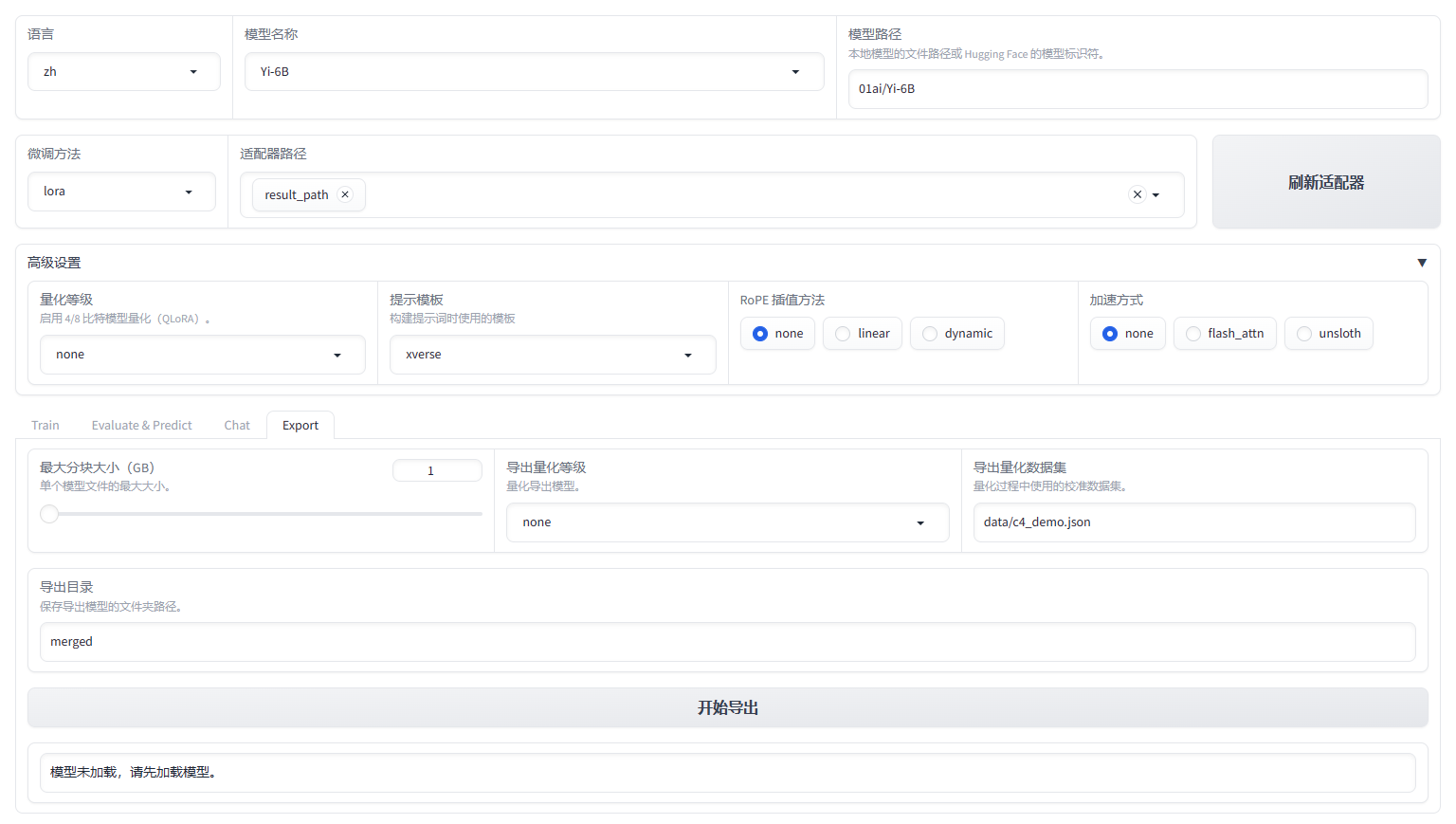
适配器路径、提示模板、RoPE 插值方法的选择应与上述模型推理和对话过程中的选择保持一致。然后在下面点击 Export 面板,最大分块大小、导出量化等级、导出量化数据集均不需要修改,只需要指定导出目录。点击开始导出,等待导出完毕即可。
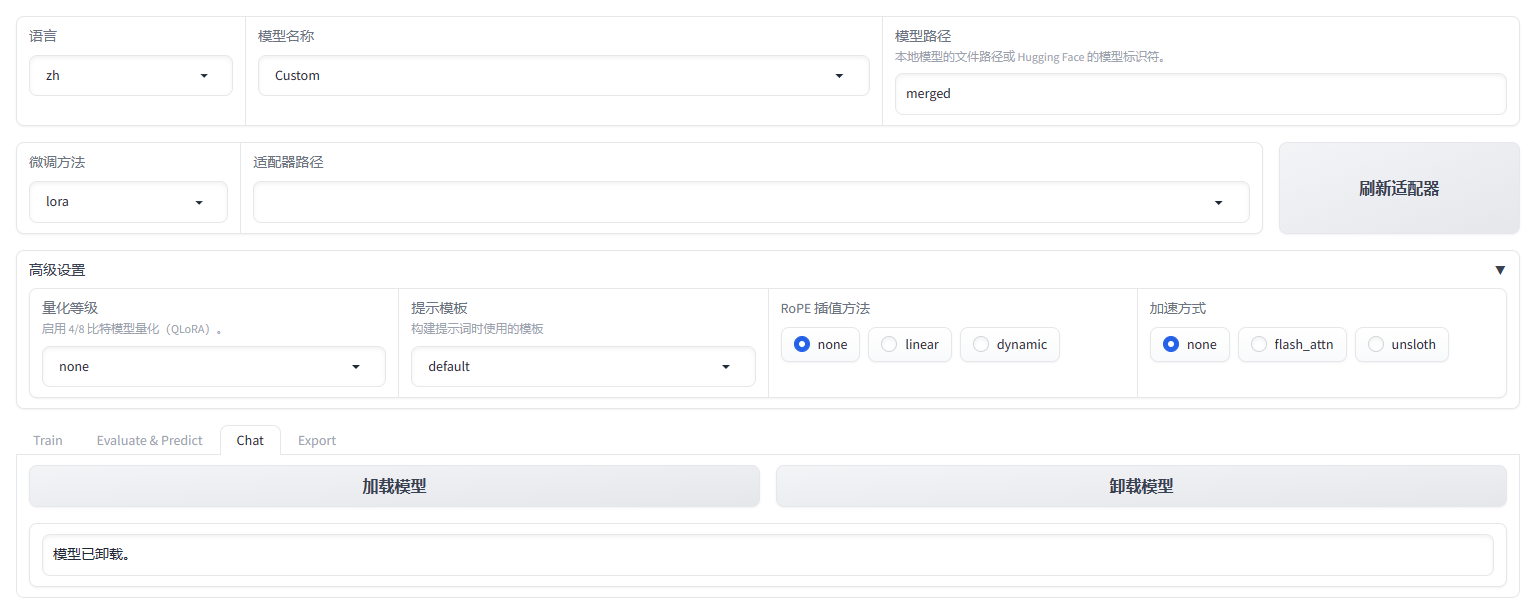
当我们使用导出后的模型进行推理时,需要将模型名称改为 Custom、模型路径设为导出后的模型的相对/绝对路径即可。
hiyouga/LLaMA-Factory: Easy-to-use LLM fine-tuning framework (github.com) ↩︎
01-ai/Yi: A series of large language models trained from scratch by developers @01-ai (github.com) ↩︎
LoRA: Low-Rank Adaptation of Large Language Models (arxiv.org) ↩︎
QLoRA: Efficient Finetuning of Quantized LLMs (arxiv.org) ↩︎
RoFormer: Enhanced Transformer with Rotary Position Embedding (arxiv.org) ↩︎
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning (arxiv.org) ↩︎
neelsjain/NEFTune: Official repository of NEFTune: Noisy Embeddings Improves Instruction Finetuning (github.com) ↩︎
Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance (arxiv.org) ↩︎