AIGC(AI内容生成)技术的快速发展确实为创作者提供了高效生产力工具,但同时也引发了一些问题和挑战。这些技术可以生成以假乱真的图像、视频换脸等,给不法分子提供了滥用的机会。其中,一些不法分子可能利用AIGC技术制造虚假新闻、违反版权、绕过活体身份验证、散布谣言和诽谤他人、进行敲诈勒索等非法活动,以谋取不当利益。这些行为给社会造成了严重的负面影响,破坏了信息的真实性和可信度。
因此,我们需要认识到AIGC技术的潜在风险,并采取相应的措施来应对。这包括加强法律法规的制定和执行,建立有效的监管机制,加强技术的安全性和可追溯性,提高公众的科技素养和警惕性,以及加强教育和宣传,提高人们对虚假信息的辨别能力。只有在合理监管和有效管理的前提下,AIGC技术才能更好地为创作者和社会带来益处,推动科技和艺术的进步。
如果有效地利用深度学习技术对AI生成式人脸图像进行辨别,成为近些年来的热点研究领域,越来越引起工业界和研究机构的重视和关注。本文选择公开的iFakeFaceDB数据集和ResNet-50深度学习模型来搭建一个基于深度学习的AI生成式人脸图像辨别系统。
数据集
iFakeFaceDB数据集是一个用于人脸图像合成和欺骗检测的数据集。它包含了真实的人脸图像以及通过人工合成生成的虚假人脸图像。该数据集的目的是帮助研究人员开发和评估人脸合成技术以及欺骗检测算法。iFakeFaceDB数据集的使用可以帮助提高人脸合成和欺骗检测的准确性和鲁棒性。与先前数据库相比且为了防止伪检测器,iFakeFaceDB在保持非常逼真的外观的同时,**通过一种称为GANprintR(GAN指纹移除)的方法去除了GAN体系结构产生的指纹。**作为GANprintR步骤的结果,与其他数据库相比,iFakeFaceDB对高级伪检测器提出了更高的挑战。
深度学习模型
ResNet-50是一种深度卷积神经网络模型,由微软研究院的Kaiming He等人在2015年提出。它是ResNet(Residual Network)系列模型中的一员,被广泛用于图像分类、目标检测和图像分割等计算机视觉任务中。
ResNet-50的主要特点是引入了残差连接(residual connection),通过跨层直接连接来解决深层网络中的梯度消失和表达能力退化问题。这种连接方式允许信息在网络中直接跳过一些层,使得网络可以更轻松地学习到更深层次的特征表示。
ResNet-50由50个卷积层组成,包括多个残差块(residual block)。每个残差块由两个3x3的卷积层和一个跳跃连接组成。在网络的开头和结尾,还有一个卷积层和一个全连接层,用于适应特定的任务。
在训练过程中,ResNet-50通常使用预训练的权重,这些权重是在大规模图像数据集上预先训练得到的。这样做可以加快模型的收敛速度,并提高模型的泛化能力。
鉴于此,本文选择ResNet-50作为首选模型,也可以方便地更换为其他分类模型如shufflenet,MobileNet、EfficientNet等。
训练代码
导入所需的库:
import torchimport torchvisionimport torchvision.transforms as transformsimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import Dataset, DataLoaderfrom sklearn.model_selection import train_test_splitimport os设置数据集路径:
dataset_path = "~/data/iFakeFaceDB"定义自定义数据集类:
class iFakeFaceDataset(Dataset): def __init__(self, root_dir, transform=None): self.root_dir = root_dir self.transform = transform self.images, self.labels = self.load_dataset() def __len__(self): return len(self.images) def __getitem__(self, idx): image = self.images[idx] label = self.labels[idx] if self.transform: image = self.transform(image) return image, label def load_dataset(self): images = [] labels = [] for idx, folder_name in enumerate(os.listdir(self.root_dir)): folder_path = os.path.join(self.root_dir, folder_name) if os.path.isdir(folder_path): for image_name in os.listdir(folder_path): image_path = os.path.join(folder_path, image_name) image = Image.open(image_path) images.append(image) labels.append(idx) return images, labels数据预处理:
transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])加载数据集并划分训练集和测试集:
dataset = iFakeFaceDataset(dataset_path, transform=transform)train_dataset, test_dataset = train_test_split(dataset, test_size=0.2, random_state=42)创建数据加载器:
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)构建ResNet-50模型:
model = torchvision.models.resnet50(pretrained=True)num_features = model.fc.in_featuresmodel.fc = nn.Linear(num_features, 2)定义损失函数和优化器:
criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)训练模型:
num_epochs = 100device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.to(device)best_accuracy = 0.0for epoch in range(num_epochs): print(f"Epoch {epoch + 1}/{num_epochs}") print("-" * 10) model.train() running_loss = 0.0 for images, labels in train_loader: images = images.to(device) labels = labels.to(device) optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() * images.size(0) epoch_loss = running_loss / len(train_dataset) print(f"Train Loss: {epoch_loss:.4f}") model.eval() correct = 0 total = 0 with torch.no_grad(): for images, labels in test_loader: images = images.to(device) labels = labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() accuracy = 100 * correct / total print(f"Test Accuracy: {accuracy:.2f}%") print() if accuracy > best_accuracy: best_accuracy = accuracy best_model_wts = copy.deepcopy(model.state_dict())保存模型:
model.load_state_dict(best_model_wts)torch.save(model.state_dict(), "resnet50_model.pth")print(f"Best Accuracy: {best_accuracy:.2f}%")训练结果如下:
Epoch 100/100----------Best val Acc: 99.50%推理代码
import torchimport torch.nn as nnimport torchvision.transforms as transformsfrom PIL import Imagefrom torchvision.models import resnet50import time# 加载预训练的ResNet-50模型model = resnet50(pretrained=True)num_features = model.fc.in_featuresmodel.fc = nn.Linear(num_features, 2)model.load_state_dict(torch.load('resnet50_model.pth'), strict=False)model.eval()# 定义图像预处理的转换preprocess = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 加载图像并进行预处理image_path = '~/data/iFakeFaceDB/TPDNE/0000011.jpg' # 替换为实际图像的路径image = Image.open(image_path)since = time.time()input_tensor = preprocess(image)input_batch = input_tensor.unsqueeze(0)# 使用GPU进行推理(如果有可用的GPU)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")input_batch = input_batch.to(device)model = model.to(device)# 进行推理with torch.no_grad(): output = model(input_batch)# 获取预测结果的索引和概率_, predicted_idx = torch.max(output, 1)predicted_prob = torch.nn.functional.softmax(output, dim=1)[0] * 100time_elapsed = time.time() - sinceprint("FPS:", 1/ time_elapsed) # 打印预测结果print("预测结果:", predicted_idx.item())print(f"概率: {predicted_prob[predicted_idx.item()].item():.2f}%")预测结果如下:
预测结果: 1概率: 99.92%部署到AlxBoard

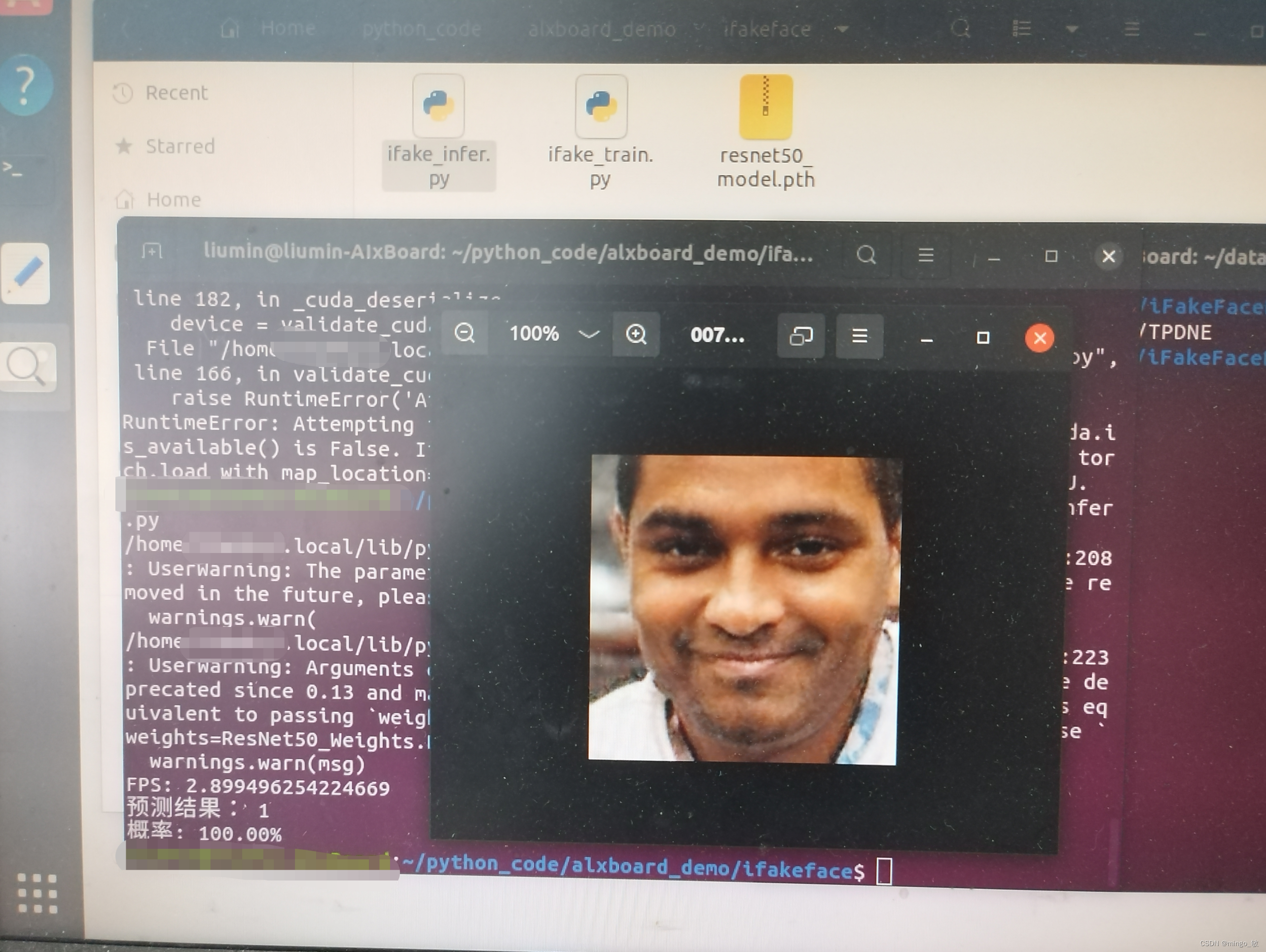
后记
基于深度学习的AI生成式人脸图像辨别系统可以应用于多个领域,如社交媒体平台的人脸识别、虚假信息的辨别和防范等。但是,需要注意的是,这种系统仍然存在一定的误判率和局限性,因此在实际应用中需要综合考虑其他因素,如人工审核和其他辅助技术,以提高准确性和可靠性。