浏览器:Edge
系统:Ubuntu 18.04
服务器远程连接工具:mobaxterm(这个不一样无所谓)
1、打开nuScenes官网的下载链接
https://www.nuscenes.org/nuscenes#download
2、注册并登陆账号,登陆后自动跳转下方界面
3、选择需要的数据集
根据需要找到所需的数据集。
关于完整数据集下载:
网页向下翻到Full Dataset部分
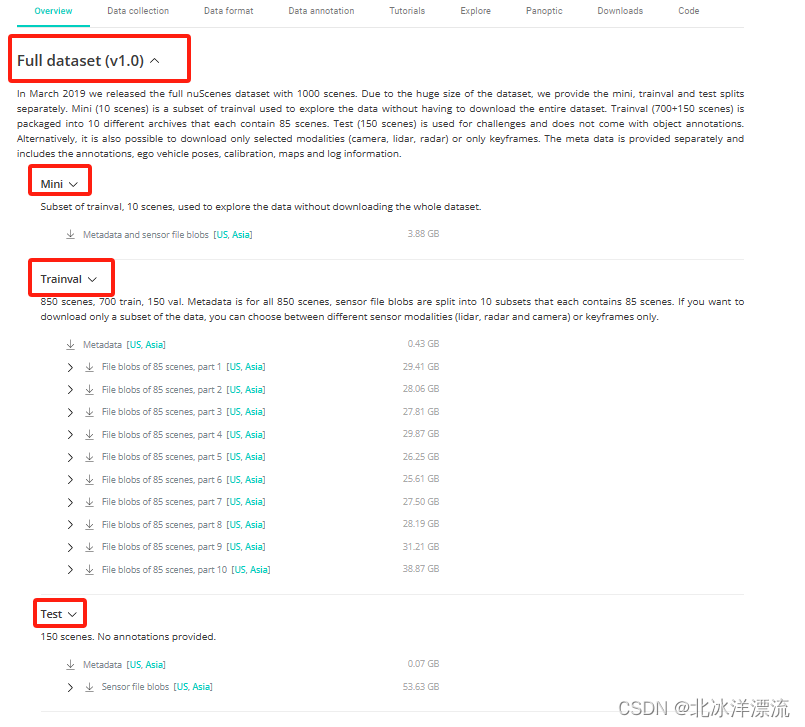
Mini:(10个场景)是trainval的一个子集,用于在不下载整个数据集的情况下探索数据。如果空间不够,可以只下载这个小数据集试试代码能不能跑通,训练的模型评估结果一般不会很好。要下完整数据集,就下载下面两个:
Trainval:(700+150个场景)被打包成10个不同的压缩包,每个包含85个场景。
Test:(150个场景)用于挑战,不附带对象注释。
可以根据下面教程完整下载,也可根据需要点开>,单独下载Lidar、Radar或Camera数据的某几种。
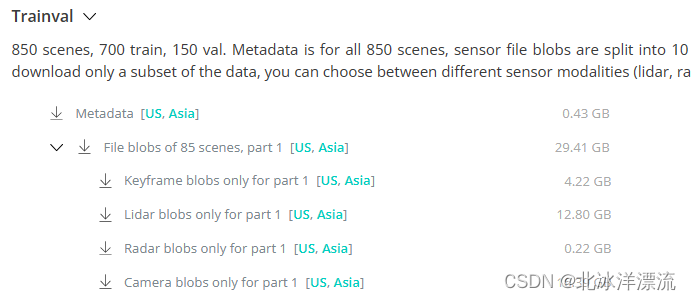
4、下载准备
点击Asia,浏览器过一会弹出下载框,右键空白区域选择“复制下载链接”
在服务器合适位置,新建download.sh文件,也可以新建text文件改名为download.sh
打开后粘贴下载链接
https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-test_blobs.tgz修改命令格式为:wget -c -O 文件名 "下载链接"
例如:
wget -c -O v1.0-test_blobs.tgz "https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-test_blobs.tgz"文件名就是链接最后一个斜杠后面的内容。
-c 选项(或 --continue)用于继续下载已经存在的文件。如果你中断了之前的下载过程,使用 -c 选项可以从中断处继续下载,而不是重新开始下载整个文件。这对于大型文件或断网后需要恢复下载的文件非常有用。
-O 选项(或 --output-document)用于指定保存下载文件的名称。你可以在 -O 选项后面提供文件名或路径来命名保存的文件。如果不指定该选项,wget 将使用远程服务器上的文件名来保存文件。
两条命令中间加&符号可以让多条命令并行执行。如果不加,就会逐条执行,下完一个再下下一个。
命令中间尽量不要空一行,windows和linux换行符不一样,脚本执行会出问题
完整download.sh内容,注意链接会过期,根据自己情况替换下载链接
wget -c -O v1.0-trainval_meta.tgz "https://d36yt3mvayqw5m.cloudfront.net/public/v1.0/v1.0-trainval_meta.tgz"&wget -c -O v1.0-trainval01_blobs.tgz "https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval01_blobs.tgz"&wget -c -O v1.0-trainval02_blobs.tgz "https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval02_blobs.tgz"&wget -c -O v1.0-trainval03_blobs.tgz "https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval03_blobs.tgz"&wget -c -O v1.0-trainval04_blobs.tgz "https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval04_blobs.tgz"&wget -c -O v1.0-trainval05_blobs.tgz "https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval05_blobs.tgz"&wget -c -O v1.0-trainval06_blobs.tgz "https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval06_blobs.tgz"&wget -c -O v1.0-trainval07_blobs.tgz "https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval07_blobs.tgz"&wget -c -O v1.0-trainval08_blobs.tgz "https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval08_blobs.tgz"&wget -c -O v1.0-trainval09_blobs.tgz "https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval09_blobs.tgz"&wget -c -O v1.0-trainval10_blobs.tgz "https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-trainval10_blobs.tgz"&wget -c -O v1.0-test_meta.tgz "https://d36yt3mvayqw5m.cloudfront.net/public/v1.0/v1.0-test_meta.tgz"&wget -c -O v1.0-test_blobs.tgz "https://motional-nuscenes.s3.amazonaws.com/public/v1.0/v1.0-test_blobs.tgz"如果报错404 nofound,可能是有防盗链,可以改成wget -c -O -U "username" 文件名 "URL"
我也遇到过这个报错,但吃个饭回来重新运行脚本,莫名其妙又好了
5、下载数据集
打开命令行,导航到包含该.sh文件目录
cd /path/to/scripts授予脚本执行权限
chmod +x download.sh执行脚本
bash downloaad.sh执行脚本后,wget命令将开始下载文件,等待下载完成即可。
解压可以使用tar命令,逐条解压即可。
tar -xvf v1.0-trainval_meta.tgz使用脚本批量解压:
Linux服务器脚本自动解压nuScenes数据集tar tgz https://blog.csdn.net/qq_49415623/article/details/136428235
https://blog.csdn.net/qq_49415623/article/details/136428235