Python进行情感分析
情感分析概述
情感分析是自然语言处理中的一个重要任务,它主要是通过对文本进行分析来确定文本中的情感倾向,包括正面、负面和中性等。Python是一种功能强大的编程语言,它提供了许多工具和库来实现情感分析。本文将介绍Python中常用的情感分析库,并提供一些示例代码,以帮助您开始进行情感分析。
情感分析步骤
下面是进行情感分析的基本步骤:
数据收集:收集需要进行情感分析的文本数据,例如评论、文章、推文等。数据清洗:清洗文本数据,去除特殊符号、停用词等。特征提取:将文本转换为可以被机器学习算法处理的特征向量。常用的特征提取方法包括词袋模型和TF-IDF模型。模型训练:选择适合的机器学习算法,使用标注好情感的数据训练模型。模型评估:评估训练好的模型的性能,例如准确率、精确率、召回率等。模型应用:将训练好的模型应用于新的文本数据,进行情感分析。情感分析库
Python中常用的情感分析库包括:
TextBlobNLTKVader SentimentPatternStanford CoreNLPFastText这些库提供了各种不同的情感分析技术和算法,包括基于规则的方法、基于机器学习的方法和深度学习方法。在本文中,我们将着重介绍前三个库。
使用TextBlob进行情感分析
TextBlob是一个Python库,用于处理文本数据。它可以用于分析文本中的情感,对文本进行标记,提取名词和动词等。以下是使用TextBlob进行情感分析的代码示例:
from textblob import TextBlob# 创建一个TextBlob对象text = TextBlob("I love this product, it's amazing!")# 分析情感sentiment = text.sentiment.polarity# 输出情感分析结果if sentiment > 0: print("Positive")elif sentiment == 0: print("Neutral")else: print("Negative")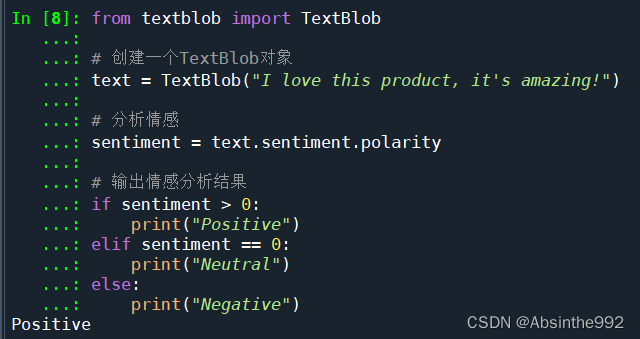
上述代码中,首先构建了一段文本,然后使用TextBlob对其进行情感分析,计算情感得分。情感得分为一个浮点数,表示文本的情感倾向,其取值范围为-1到1。如果得分大于0,则认为文本是正面情感;如果得分小于0,则认为文本是负面情感;如果得分等于0,则认为文本是中性情感。最后根据情感得分输出文本情感分类结果。在这个例子中,输出结果为“Positive”。
需要注意的是,TextBlob进行情感分析的方法比较简单,可能无法处理一些复杂的情感表达。在实际应用中,需要根据具体需求选择合适的情感分析方法。
使用NLTK进行情感分析
NLTK是一种常用的自然语言处理库,它包含了许多工具和数据集,可以用于情感分析、文本分类、词性标注等。以下是使用NLTK进行情感分析的代码示例:
import nltkfrom nltk.sentiment import SentimentIntensityAnalyzer# 创建一个SentimentIntensityAnalyzer对象sia = SentimentIntensityAnalyzer()# 分析情感text = "I love this product, it's amazing!"sentiment = sia.polarity_scores(text)# 输出情感分析结果if sentiment['compound'] > 0: print("Positive")elif sentiment['compound'] == 0: print("Neutral")else: print("Negative")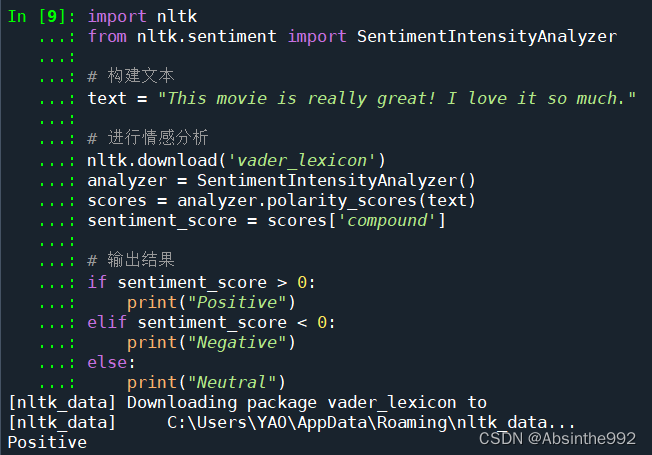
在上面的代码中,我们首先导入了NLTK库,并从中导入了SentimentIntensityAnalyzer类。然后,我们创建了一个SentimentIntensityAnalyzer对象,并使用polarity_scores()方法来获取情感极性分数。与TextBlob不同,NLTK返回的情感分数是一个包含了四个值的字典,其中compound值表示情感极性分数,它在-1到1之间。最后,我们根据情感极性分数输出情感分析结果。
总结
本文介绍了使用TextBlob和NLTK库进行情感分析的方法,并附上了相应的代码和文字说明。这些库是进行情感分析的常用工具,对于分析文本中的情感非常有用。通过学习本文,读者将能够了解如何使用Python进行情感分析。