1、环境准备及安装
1.1、linux环境
# 首先,已经预先安装好了anaconda,在这里新建一个环境conda create -n sdwebui python=3.10# 安装完毕后,激活该环境conda activate sdwebui# 安装# 下载stable-diffusion-webui代码apt install wget git python3 python3-venv libgl1 libglib2.0-0git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitcd stable-diffusion-webui bash webui.sh -f2、运行
安装完成前期的环境准备之后,之后每次运行只需要:
conda activate sdwebuicd stable-diffusion-webuibash webui.sh -f# 或者按照如下方式,将sd放在后台执行nohup bash webui.sh -f >> nohup.log 2>&1 &该种方式会将进程运行在本地,可以通过ip+port的方式直接在网页上访问。 也可以通过如下方式进行简单的改造:
# 编辑webui-user.sh脚本vim webui-user.sh# 在终端中输入“i”进入编辑模式,移动到 COMMANDLINE_ARGS,并将其修改为:export COMMANDLINE_ARGS="--listen --share --enable-insecure-extension-access"参数说明:
--listen:将本地连接从127.0.0.1修改为0.0.0.0,即可通过服务器 IP:7861进行访问--share:生成可供外网访问 Gradio 网址。--enable-insecure-extension-access:使用--listen时,webui出于安全考虑会禁止用户在UI页面添加插件,添加该参数可允许用户添加插件。--mdevram或 --lowvarm:降低显存消耗
PS:windows下的同理,在webui-user.bat中修改即可
成功页面:
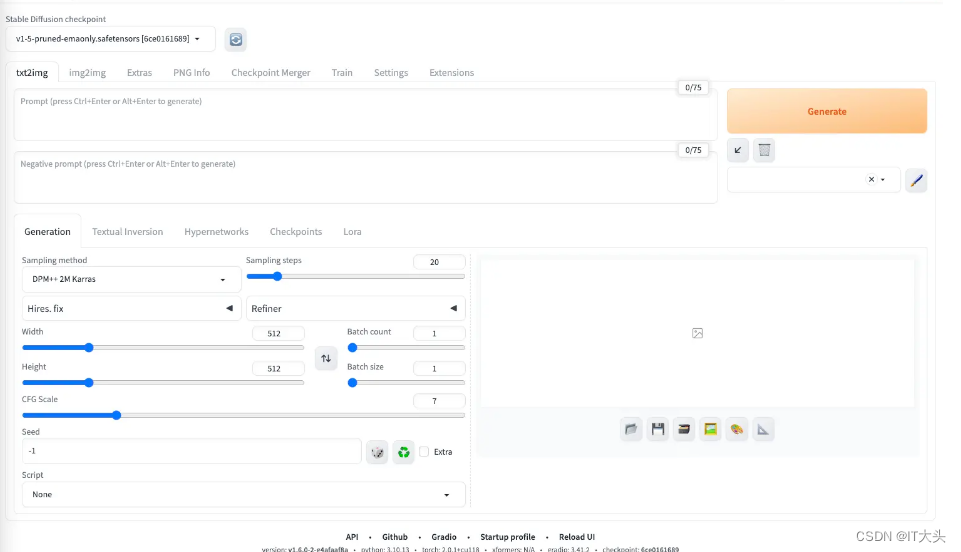
3、自定义模型
初步安装完成后,打开webui,可以看到左上角自带的模型。
模型的分类大概有如下几种:
CheckPointCheckpoint 是 Stable Diffusion 中最重要的模型,也是主模型,几乎所有的操作都要依托于主模型进行。所有的主模型都是基于 Stable Diffusion 模型训练而来.
主模型后缀一般为 .ckpt 或者 .safetensors,并且体积比较庞大,一般在 2G - 7G 之间。放置在 webUI 目录下的 `models/Stable-diffusion` 目录下。LoRA/LyCORIS
LoRA 是除了主模型外最常用的模型。LoRA 和 LyCORIS 都属于微调模型,一般用于控制画风、控制生成的角色、控制角色的姿势等等。
LoRA 和 LyCORIS 的后缀均为 .safetensors,体积较主模型要小得多,一般在 4M - 300M 之间。一般使用 LoRA 模型较多,而 LyCORIS 与 LoRA 相比可调节范围更大,但是需要额外的扩展才可使用。放置在 `models/LoRA` 目录下。Textual Inversion
Textual Inversion 是文本编码器模型,用于改变文字向量。可以将其理解为一组 Prompt。
Textual Inversion 后缀为 .pt 或者 .safetensors,体积非常小,一般只有几 kb。放置在 `embeddings` 目录下。Hypernetworks
Hypernetworks 模型用于调整模型神经网络权重,进行风格的微调。
Hypernetworks 的后缀为 .pt 或者 .safetensors,体积一般在 20M - 200M 之间。放置在 `models/hypernetworks` 目录下。ControlNet
ControlNet 是一个及其强大的控制模型,它可以做到画面控制、动作控制、色深控制、色彩控制等等。使用时需要安装相应的扩展才可。
ControlNet 类模型的后缀为 .safetensors。放置在 `models/ControlNet` 目录下。
使用时我们需要先去 Extensions 页面搜索 ControlNet 扩展,然后 Install 并 Reload UI。然后便可以在 txt2img 和 img2img 菜单下找到。VAE
VAE全称是变分自动编码器 (Variational Auto-Encoder),是机器学习中的一种人工神经网络结构。VAE在sd模型中负责微调,类似我们熟知的滤镜,调整生成图片的饱和度。
默认的sd-webui页面并没有VAE的设置,需要进入:Settings->User interface->Quick settings list,在输入框中添加sd_vae。然后依次点击Apply settings和Reload UI。随后就会在webui中看到对应区域。
下载好上述模型之后,可以在页面上直接通过标签进入选中,可以直接prompt使用: