?♂️ 个人主页:@艾派森的个人主页
✍?作者简介:Python学习者
? 希望大家多多支持,我们一起进步!?
如果文章对你有帮助的话,
欢迎评论 ?点赞?? 收藏 ?加关注+
目录
一、获取数据
1.技术工具
2.爬取目标
3.字段信息
二、数据预处理
1.加载数据
2.异常值处理
3.字段处理
三、数据可视化
四、总结
文末福利
一、获取数据
1.技术工具
IDE编辑器:vscode
发送请求:requests
解析工具:xpath
def Get_Detail(Details_Url): Detail_Url = Base_Url + Details_Url One_Detail = requests.get(url=Detail_Url, headers=Headers) One_Detail_Html = One_Detail.content.decode('gbk') Detail_Html = etree.HTML(One_Detail_Html) Detail_Content = Detail_Html.xpath("//div[@id='Zoom']//text()") Video_Name_CN,Video_Name,Video_Address,Video_Type,Video_language,Video_Date,Video_Number,Video_Time,Video_Daoyan,Video_Yanyuan_list = None,None,None,None,None,None,None,None,None,None for index, info in enumerate(Detail_Content): if info.startswith('◎译 名'): Video_Name_CN = info.replace('◎译 名', '').strip() if info.startswith('◎片 名'): Video_Name = info.replace('◎片 名', '').strip() if info.startswith('◎产 地'): Video_Address = info.replace('◎产 地', '').strip() if info.startswith('◎类 别'): Video_Type = info.replace('◎类 别', '').strip() if info.startswith('◎语 言'): Video_language = info.replace('◎语 言', '').strip() if info.startswith('◎上映日期'): Video_Date = info.replace('◎上映日期', '').strip() if info.startswith('◎豆瓣评分'): Video_Number = info.replace('◎豆瓣评分', '').strip() if info.startswith('◎片 长'): Video_Time = info.replace('◎片 长', '').strip() if info.startswith('◎导 演'): Video_Daoyan = info.replace('◎导 演', '').strip() if info.startswith('◎主 演'): Video_Yanyuan_list = [] Video_Yanyuan = info.replace('◎主 演', '').strip() Video_Yanyuan_list.append(Video_Yanyuan) for x in range(index + 1, len(Detail_Content)): actor = Detail_Content[x].strip() if actor.startswith("◎"): break Video_Yanyuan_list.append(actor) print(Video_Name_CN,Video_Date,Video_Time) f.flush() try: csvwriter.writerow((Video_Name_CN,Video_Name,Video_Address,Video_Type,Video_language,Video_Date,Video_Number,Video_Time,Video_Daoyan,Video_Yanyuan_list)) except: pass保存数据:csv
if __name__ == '__main__': with open('movies.csv','a',encoding='utf-8',newline='')as f: csvwriter = csv.writer(f) csvwriter.writerow(('Video_Name_CN','Video_Name','Video_Address','Video_Type','Video_language','Video_Date','Video_Number','Video_Time','Video_Daoyan','Video_Yanyuan_list')) spider(117)2.爬取目标
本次爬取的目标网站是阳光电影网https://www.ygdy8.net,用到技术为requests+xpath。主要获取的目标是2016年-2023年之间的电影数据。
3.字段信息
获取的字段信息有电影译名、片名、产地、类别、语言、上映时间、豆瓣评分、片长、导演、主演等,具体说明如下:
| 字段名 | 含义 |
| Video_Name_CN | 电影译名 |
| Video_Name | 电影片名 |
| Video_Address | 电影产地 |
| Video_Type | 电影类别 |
| Video_language | 电影语言 |
| Video_Date | 上映时间 |
| Video_Number | 电影评分 |
| Video_Time | 片长 |
| Video_Daoyan | 导演 |
| Video_Yanyuan_list | 主演列表 |

二、数据预处理
技术工具:jupyter notebook
1.加载数据
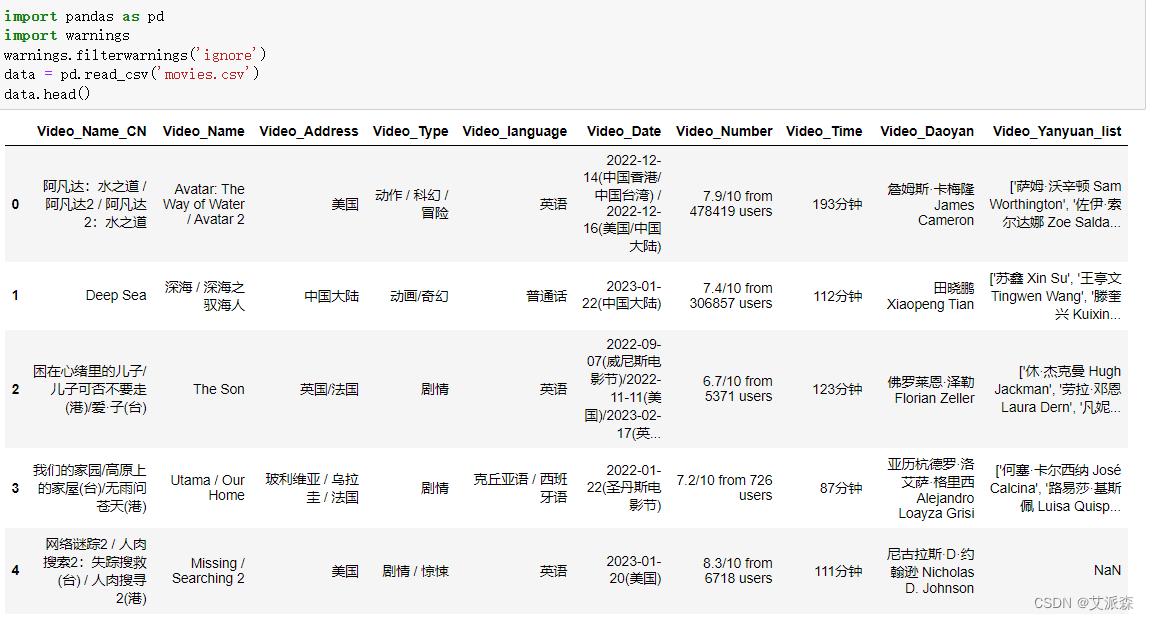
首先使用pandas读取刚用爬虫获取的电影数据
2.异常值处理
这里处理的异常值包括缺失值和重复值
首先查看原数据各字段的缺失情况

从结果中可以发现缺失数据还蛮多的,这里就为了方便统一删除处理,同时也对重复数据进行删除
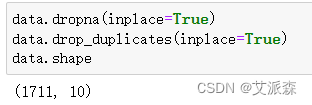
可以发现经过处理后的数据还剩1711条。
3.字段处理
由于爬取的原始数据中各个字段信息都很乱,出现很多“/”“,”之类的,这里统一进行处理,主要使用到pandas中的apply()函数,同时由于我们分析的数2016-2023年的电影数据,除此之外的进行删除处理
# 数据预处理data['Video_Name_CN'] = data['Video_Name_CN'].apply(lambda x:x.split('/')[0]) # 处理Video_Name_CNdata['Video_Name'] = data['Video_Name'].apply(lambda x:x.split('/')[0]) # 处理Video_Namedata['Video_Address'] = data['Video_Address'].apply(lambda x:x.split('/')[0]) # 处理Video_Addressdata['Video_Address'] = data['Video_Address'].apply(lambda x:x.split(',')[0].strip())data['Video_language'] = data['Video_language'].apply(lambda x:x.split('/')[0])data['Video_language'] = data['Video_language'].apply(lambda x:x.split(',')[0])data['Video_Date'] = data['Video_Date'].apply(lambda x:x.split('(')[0].strip())data['year'] = data['Video_Date'].apply(lambda x:x.split('-')[0])data['Video_Number'] = data['Video_Number'].apply(lambda x:x.split('/')[0].strip())data['Video_Number'] = pd.to_numeric(data['Video_Number'],errors='coerce')data['Video_Time'] = data['Video_Time'].apply(lambda x:x.split('分钟')[0])data['Video_Time'] = pd.to_numeric(data['Video_Time'],errors='coerce')data['Video_Daoyan'] = data['Video_Daoyan'].apply(lambda x:x.split()[0])data.drop(index=data[data['year']=='2013'].index,inplace=True)data.drop(index=data[data['year']=='2014'].index,inplace=True)data.drop(index=data[data['year']=='2015'].index,inplace=True)data.dropna(inplace=True)data.head()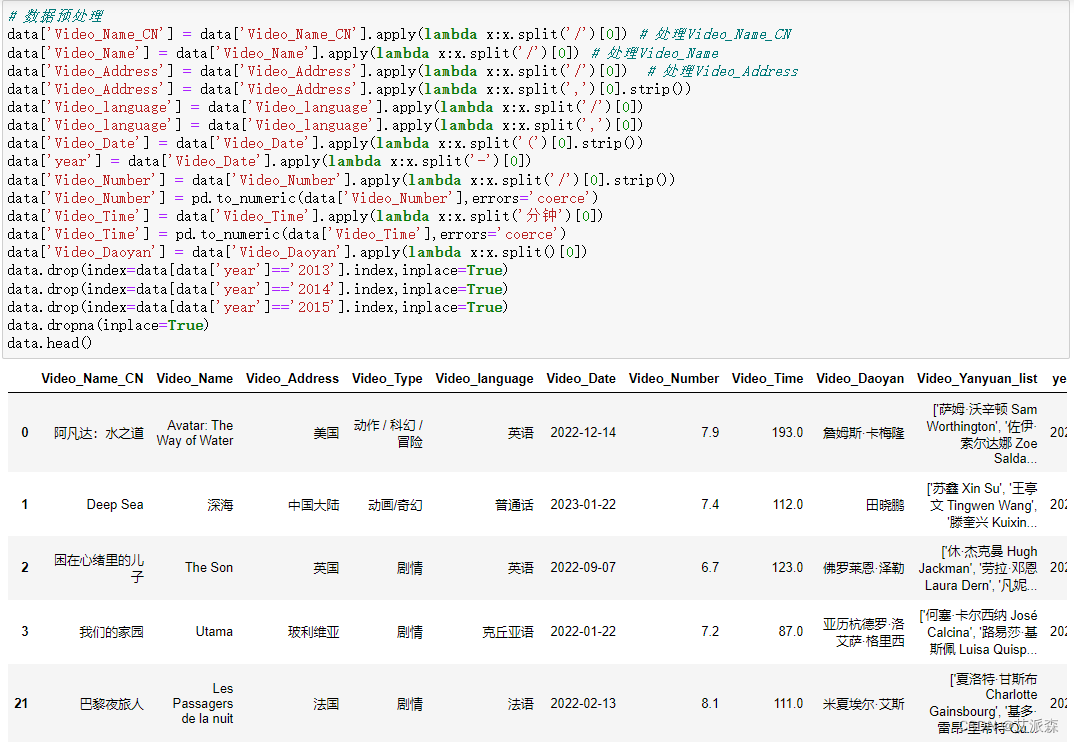
三、数据可视化
1.导入可视化库
本次可视化主要用到matplotlib、seaborn、pyecharts等第三方库
import matplotlib.pylab as pltimport seaborn as snsfrom pyecharts.charts import *from pyecharts.faker import Fakerfrom pyecharts import options as opts from pyecharts.globals import ThemeTypeplt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示2.分析各个国家发布的电影数量占比
# 分析各个国家发布的电影数量占比df2 = data.groupby('Video_Address').size().sort_values(ascending=False).head(10)a1 = Pie(init_opts=opts.InitOpts(theme = ThemeType.LIGHT))a1.add(series_name='电影数量', data_pair=[list(z) for z in zip(df2.index.tolist(),df2.values.tolist())], radius='70%', )a1.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item'))a1.render_notebook()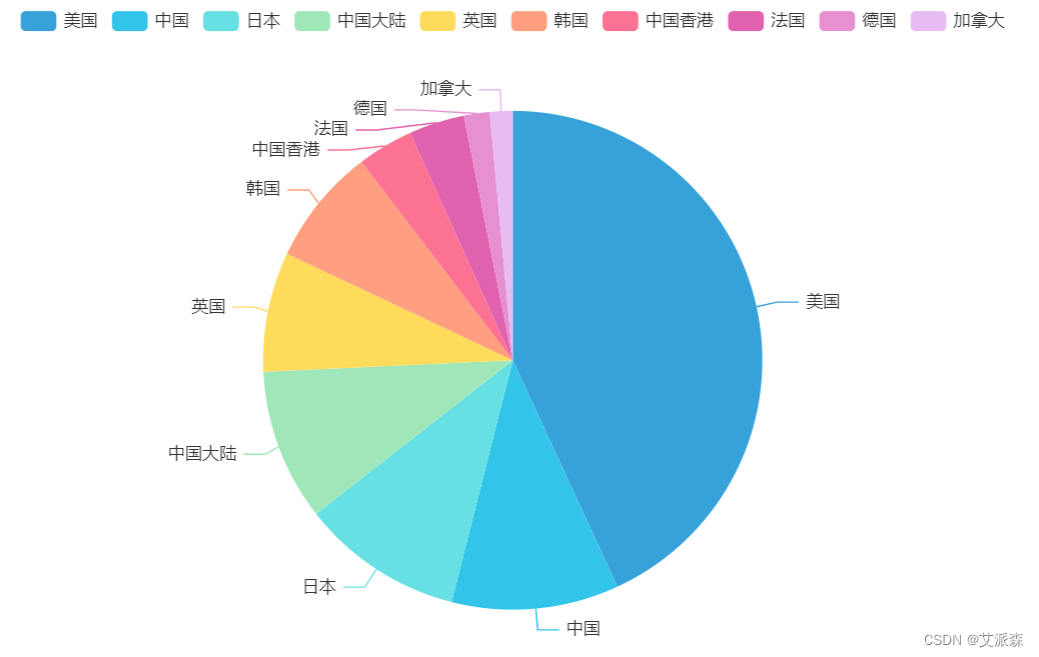
3.发布电影数量最高Top5导演
# 发布电影数量最高Top5导演a2 = Bar(init_opts=opts.InitOpts(theme = ThemeType.DARK))a2.add_xaxis(data['Video_Daoyan'].value_counts().head().index.tolist())a2.add_yaxis('电影数量',data['Video_Daoyan'].value_counts().head().values.tolist())a2.set_series_opts(itemstyle_opts=opts.ItemStyleOpts(color='#B87333'))a2.set_series_opts(label_opts=opts.LabelOpts(position="top"))a2.render_notebook()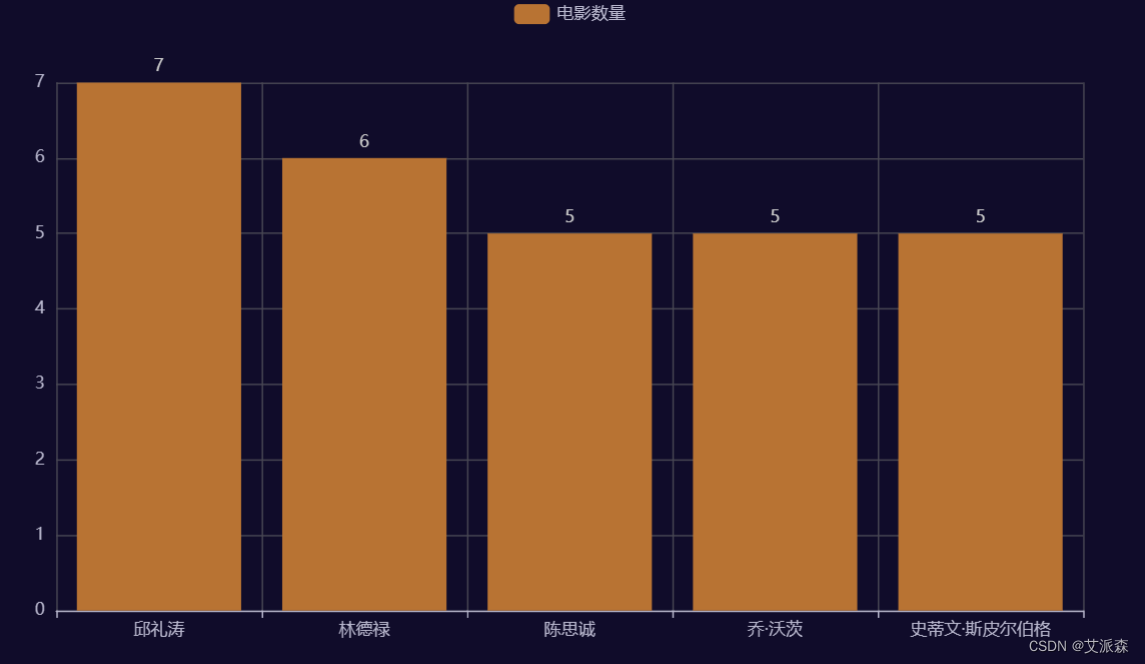
4.分析电影平均评分最高的前十名国家
# 分析电影平均评分最高的前十名国家data.groupby('Video_Address').mean()['Video_Number'].sort_values(ascending=False).head(10).plot(kind='barh')plt.show()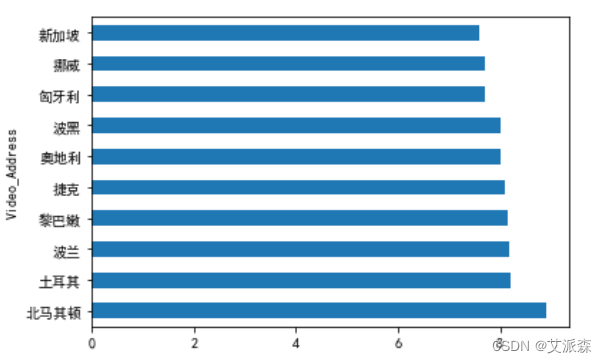
5.分析哪种语言最受欢迎
# 分析哪种语言最受欢迎from pyecharts.charts import WordCloudimport collectionsresult_list = []for i in data['Video_language'].values: word_list = str(i).split('/') for j in word_list: result_list.append(j)result_listword_counts = collections.Counter(result_list)# 词频统计:获取前100最高频的词word_counts_top = word_counts.most_common(100)wc = WordCloud()wc.add('',word_counts_top)wc.render_notebook()
6.分析哪种类型电影最受欢迎
# 分析哪种类型电影最受欢迎from pyecharts.charts import WordCloudimport collectionsresult_list = []for i in data['Video_Type'].values: word_list = str(i).split('/') for j in word_list: result_list.append(j)result_listword_counts = collections.Counter(result_list)# 词频统计:获取前100最高频的词word_counts_top = word_counts.most_common(100)wc = WordCloud()wc.add('',word_counts_top)wc.render_notebook()
7.分析各种类型电影的比例
# 分析各种类型电影的比例word_counts_top = word_counts.most_common(10)a3 = Pie(init_opts=opts.InitOpts(theme = ThemeType.MACARONS))a3.add(series_name='类型', data_pair=word_counts_top, rosetype='radius', radius='60%', )a3.set_global_opts(title_opts=opts.TitleOpts(title="各种类型电影的比例", pos_left='center', pos_top=50))a3.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter='{a} <br/>{b}:{c} ({d}%)'))a3.render_notebook()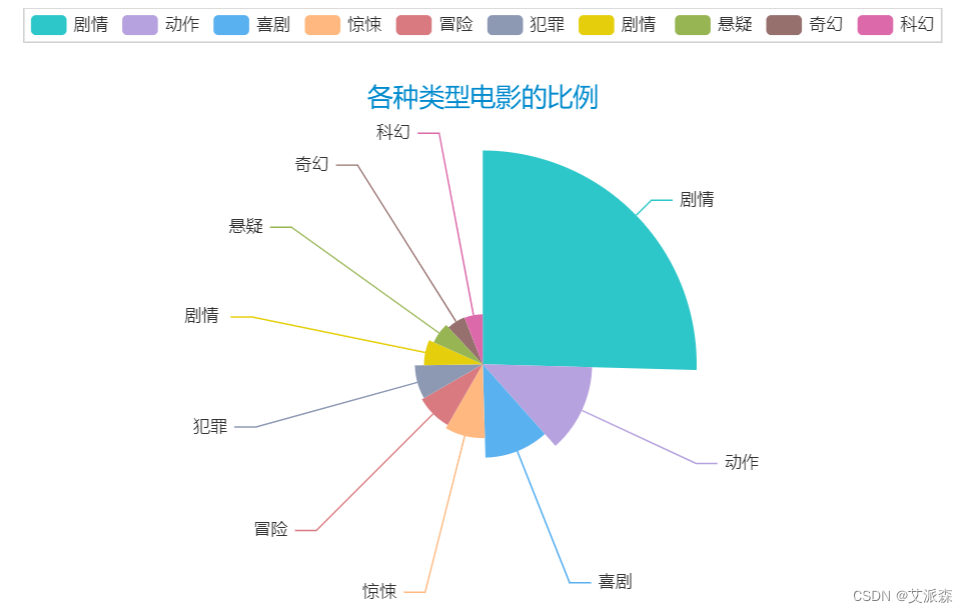
8.分析电影片长的分布
# 分析电影片长的分布sns.displot(data['Video_Time'],kde=True)plt.show()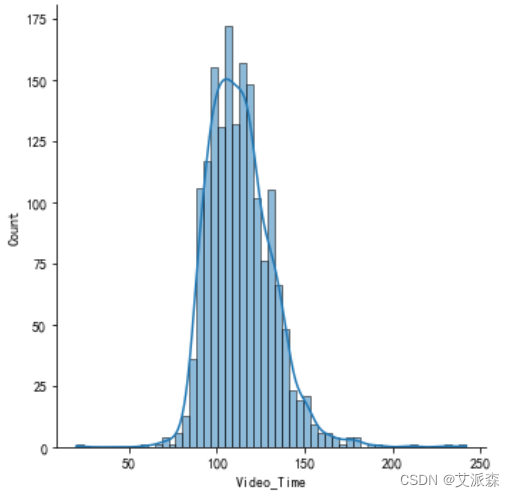
9.分析片长和评分的关系
# 分析片长和评分的关系plt.scatter(data['Video_Time'],data['Video_Number'])plt.title('片长和评分的关系',fontsize=15)plt.xlabel('片长',fontsize=15)plt.ylabel('评分',fontsize=15)plt.show()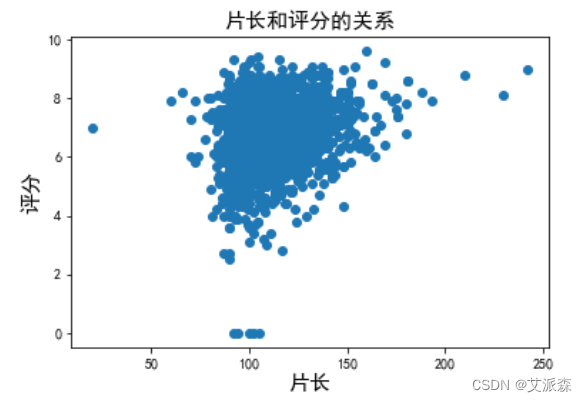
10.统计 2016 年到至今的产出的电影总数量
# 统计 2016 年到至今的产出的电影总数量df1 = data.groupby('year').size()line = Line()line.add_xaxis(xaxis_data=df1.index.to_list())line.add_yaxis('',y_axis=df1.values.tolist(),is_smooth = True) line.set_global_opts(xaxis_opts=opts.AxisOpts(splitline_opts = opts.SplitLineOpts(is_show=True)))line.render_notebook()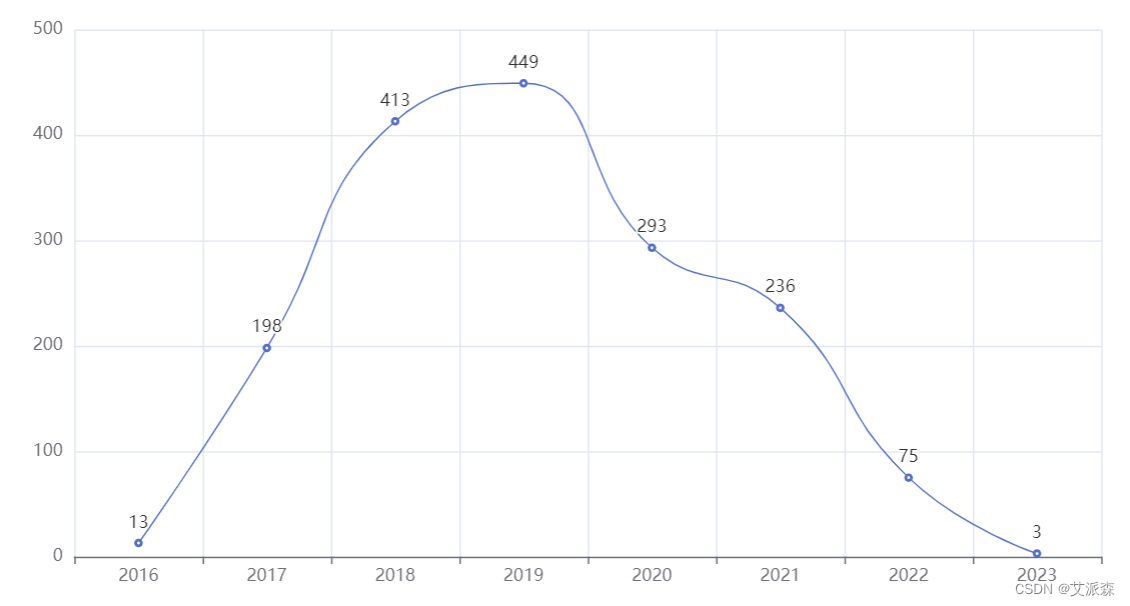
四、总结
本次实验通过使用爬虫获取2016年-2023年的电影数据,并可视化分析的得出以下结论:
1.2016年-2019年电影数量逐渐增大,2019年达到最大值,从2020年开始迅速逐年下降。
2.发布电影数量最多的国家是中国和美国。
3.电影类型最多的剧情片。
4.电影片长呈正态分布,且片长和评分呈正相关关系。
文末福利
《MySQL数据库基础与实战应用》免费送出!

内容简介:
MySQL 数据库性能优越,功能强大,是深受读者欢迎的开源数据库之一。本书由浅入深、循序渐进、系统地介绍了MySQL 的相关知识及其在数据库开发中的实际应用,并通过具体案例,帮助读者巩固所学知识,以便更好地开发实践。
全书共分为13 章,内容涵盖了认识与理解数据库、安装与配置MySQL 数据库、数据库与数据表的基本操作、数据查询、索引的创建与管理、视图的创建与管理、触发器、事务、事件、存储过程与存储函数、访问控制与安全管理、数据库的备份与恢复,以及综合的实践教学项目—图书管理系统数据库设计。
本书结合全国计算机等级考试二级MySQL 考试大纲编写,章节后面配有习题,适当融入思政元素,并配备了相应的教案与课件。本书内容丰富,讲解深入,适合初级、中级MySQL 用户,既可以作为各类高等职业技术院校与职业本科院校相关专业的课程教材,也可以作为广大MySQL 爱好者的实用参考书。
参与福利
抽奖方式:评论区随机抽取2位小伙伴免费送出!参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,我用Python!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)活动截止时间:2023-04-13 20:00:00 京东自营购买链接:https://item.jd.com/13663131.html名单公布时间:2023-04-13 21:00:00