博主介绍:✌全网粉丝100W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
?由于篇幅限制,想要获取完整文章或者源码,或者代做,可以给我留言或者找我聊天。?
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
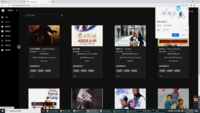
文章包含:项目选题 + 项目展示图片 (必看)
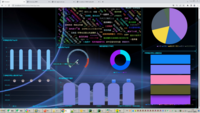
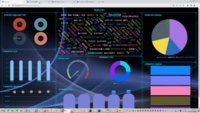
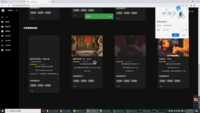
技术栈:使用request爬取豆瓣+1905多路数据源电影数据集 , hive分析百万海量数据 , sqoop导入mysql flask做后台+前端echarts加登录页面做的可视化





| 题 目 | 基于机器学习的喜剧电影推荐系统的设计与实现 | ||||
| 学 院 专 业 | 数据科学与大数据技术 | 年 级 | 2020级 | 开题日期 | 2023.12.2 |
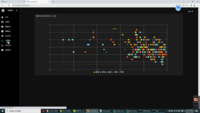
| 一、选题的目的、意义、研究现状,本选题研究的基本内容、拟解决的主要问题 (一)目的、意义 随着科技的迅猛发展,互联网和大数据技术为我们提供了前所未有的便利和机会。在众多网络视频平台中,电影市场规模不断扩大,喜剧电影受众广泛,用户可以享受到丰富多样的电影内容。然而,这也带来了一个问题,即面对巨大的电影库,用户往往会感到困惑和无法选择。 对于用户来说,他们需要一个能够提供准确、个性化喜剧电影推荐的系统,以便在海量的电影资源中快速找到符合自己口味和兴趣的喜剧电影。这样的系统应该能够根据用户的历史行为、偏好和当前情境等因素进行分析,为其推荐适合的喜剧电影,从而使用户能够享受到更加便捷和愉悦的观影体验。 对于在线视频平台和电影院线来说,他们也需要一个能够提供准确喜剧电影推荐的系统。这样的系统能够帮助他们吸引更多的用户,增加平台的流量和收入。同时,通过提供个性化的喜剧电影推荐服务,平台能够更好地满足用户的需求,使用户的观影体验得到显著提升,从而增强用户的忠诚度和满意度。 随着互联网和移动设备的普及,用户对于娱乐的需求越来越高。喜剧电影作为一种广受欢迎的娱乐形式,能够带给人们欢乐和放松。然而,面对海量的电影资源,如何选择适合自己的喜剧电影却成为了一个难题。基于此背景,设计一个基于用户行为和电影特征的喜剧电影推荐系统。 (二)研究现状 推荐系统的发展可以追溯到20世纪90年代,当时电子商务和在线零售业开始兴起,企业需要一种能够根据用户的历史购买行为和偏好来推荐产品的系统。随着社会的不断进步,推荐系统的应用领域不断扩展,从最初的电子商务和在线零售业,发展到现在的在线视频、音乐、新闻等多个领域。随着技术的不断进步和数据的持续增长,推荐系统的准确性和个性化程度也不断提高,为用户带来更加优质的体验。 在当前的在线视频推荐系统中,机器学习算法已经被广泛应用。这些系统主要基于用户的历史行为数据,如观影历史、评分等,来预测用户可能感兴趣的电影。 然而,现有的推荐系统仍然存在一些问题。例如,它们往往不能很好地处理新用户或者新电影的推荐问题。此外,由于数据的稀疏性,协同过滤方法往往不能很好地处理冷启动问题。此外,现有的推荐系统往往不能很好地处理用户的个性化需求和兴趣的变化。因此,本研究旨在开发一种基于机器学习的喜剧电影推荐系统,以解决这些问题。 (三)基本内容 本课题以开发一个基于机器学习的喜剧电影推荐系统为目标,主要研究内容包括以下几部分: 1.数据收集与预处理:从各大在线视频平台和电影院线收集大量的用户行为数据和喜剧电影数据,如用户的观影历史、评分、评论等,以及电影的标题、描述、分类等信息,利用大数据处理技术Spark对大量数据进行预处理、特征提取和模型训练,使用大数据存储技术,分布式文件系统Hadoop HDFS以及MySQL数据库,存储大量的用户行为数据和喜剧内容数据。 2.数据挖掘与特征提取:在收集到的用户行为数据和电影数据中,提取出对喜剧电影推荐有用的特征,如用户的观影频率、评分偏好,电影的类型、导演、演员等信息。使用K-means聚类算法,设定聚类数目即K值,对用户数据进行聚类。然后对每个类别计算聚类中心,这代表了该类别的用户观影偏好的平均值。对于每个用户,根据其观影偏好与每个类别的聚类中心的相似度,确定其所属的类别。根据该用户所属的类别,推荐该类别中最受欢迎的喜剧电影。 3.模型构建与优化:将采用机器学习算法构建推荐模型。模型将根据用户的行为数据和电影的特征来预测用户可能感兴趣的电影。通过实验和用户反馈来不断优化模型,提高推荐准确率。 4.系统设计与实现:把推荐模型放到在线视频平台的后端系统中,实现一个喜剧电影推荐系统。系统将提供个性化的喜剧电影推荐服务,使用户的观影体验得到显著提升。 5.数据可视化:利用Hue大数据可视化技术,将分析结果以图表、图形等形式展示给用户,帮助用户更好地理解数据和内容。
本课题的研究内容主要包括以上几个方面。通过本研究,将开发出一个基于机器学习的喜剧电影推荐系统,能够准确预测用户的观影喜好,提高平台的流量和收入。同时,本研究还将提供个性化的喜剧电影推荐服务,使用户的观影体验得到显著提升。 拟解决的主要问题 1.用户喜好的预测:基于机器学习的推荐系统需要准确地预测用户的观影喜好,以便为他们提供个性化的喜剧电影推荐服务。这可能需要对用户的观影历史、浏览行为等进行深入分析,以提取有效的特征并构建模型。 2.系统评估与优化问题:在现有的推荐系统中,对于系统的评估和优化往往缺乏科学的方法和手段。本研究将通过实验和用户反馈来评估系统的性能和效果,并根据评估结果对系统进行优化和改进,提高系统的稳定性和可靠性。 | |||||
| 二、选题研究步骤、研究方法及措施: (一)研究步骤 1、课题调研 对现状需求进行分析,调研该课题的背景、目的及意义。 2、对目前电影个性化推荐系统进行研究和分析。使用机器学习算法K-means聚类,对数据进行K-means聚类,将用户分成若干个类别。每个类别中的用户具有相似的观影偏好,然后就可以推荐相应的喜剧电影。 3、系统设计 根据需求分析的结果,按照其功能进行模块划分,编写各个模块:数据采集模块;数据清洗模块;数据分析模块;数据可视化模块。 4、编程实现 根据系统设计,按照编程规范和编码风格,进行编程实现。采用Python编程语言实现整个系统。具体使用爬虫技术实现数据采集模块;使用Pandas库实现数据清洗模块;使用scikit-learn库实现数据分析模块;使用matplotlib库实现数据可视化模块并且采用分布式计算框架Spark和Hadoop来实现数据分析模块。 5、撰写论文 归纳总结,参考文献,对分析结果进行整理,撰写论文。 (二)研究方法 1、文献法 通过对期刊、网络、图书等文献进行调研,了解该课题研究现状,找出不足,力求能够避免或者进行改进。 2、案例法 通过对有关成功案例进行搜集和分析,借鉴其成功的部分,根据现有的研究项目进行分析与设计,理论与实践的相结合,使理论有理有据,设计更合理,并提出自己的看法,在此基础上创新。 (三)研究措施 通过相关图书,学习相应的有关知识,进行网上搜索相关内容,阅读相关的项目报告,及时做笔录,对该课题有帮助的部分进行整理与分析,开拓思维,由此作为该课题的理论基础。 | |||||
| 三、选题研究工作进度: | |||||
| 起讫日期 | 主要工作内容 | ||||
| 2023.10.01-2023.10.30 | 选题、调研、收集资料 | ||||
| 2023.11.01-2023.12.02 | 论证、开题、撰写开题报告 | ||||
| 2023.12.03-2024.01.31 | 实践研究、资料搜集过程 | ||||
| 2024.02.01-2024.05.17 | 论文写作 | ||||
| 2024.03.14-2024.03.21 | 中期检查 | ||||
| 2024.05.18-2024.05.25 | 论文答辩 | ||||
| 四、主要参考文献: [1] 张廉月. 基于Flink的电影推荐系统的研究与实现[D]. 电子科技大学, 2020. [2]王茜子. 基于混合算法的电影推荐系统的研究与设计[D]. 电子科技大学, 2020. [3]张坤. 基于 Spark 机器学习的电影推荐系统的设计与实现[D]. 南京邮电大学,2022. [4]梁肇敏,梁婷婷.基于深度学习的电影推荐系统设计与实现[J].现代电子技术,2022,12(10):157-162. [5]张鹏飞.基于数据挖掘的个性化电影推荐系统设计与实现[D].杭州电子科技大学, 2022. [6] 武玲梅,李秋萍,黄秀芳,张立强,董力量,罗芳琼.基于Django框架的电影推荐系统的设计与实现[J].2023,19(4):56-61 | |||||
| 五、指导教师意见:
指导教师(签名): 年 月 日 | |||||
| 六、开题审查小组审查意见: 选题是否合适: 选题能否实现: 组长(签名): 年 月 日 |
说明:1、开题报告应在教师指导下由学生独立撰写,并交指导教师审阅。
2、开题报告一般不少于1500字。
3、研究方法按规范名称填写,不得少于两种。主要研究方法包括: 问卷法、访谈法、实验法、文献法、案例法等。
import numpy as np# 创建一个电影评分矩阵,每行代表一个用户,每列代表一个电影ratings = np.array([ [5, 4, 0, 5, 0, 0], [0, 0, 4, 0, 4, 0], [4, 0, 5, 0, 0, 0], [0, 0, 4, 3, 0, 2]])# 计算电影之间的相似度(使用余弦相似度)def similarity_matrix(ratings): norm = np.linalg.norm(ratings, axis=1, keepdims=True) normalized_ratings = ratings / norm similarity = np.dot(normalized_ratings, normalized_ratings.T) return similarity# 预测用户对未看过的电影的评分def predict_ratings(ratings, similarity): mean_ratings = np.mean(ratings, axis=1, keepdims=True) normalized_ratings = ratings - mean_ratings predicted_ratings = np.dot(similarity, normalized_ratings) / np.sum(np.abs(similarity), axis=1, keepdims=True) predicted_ratings += mean_ratings return predicted_ratings# 根据预测评分推荐电影def recommend_movies(predicted_ratings, user_id, num_recommendations=3): user_ratings = predicted_ratings[user_id] sorted_indices = np.argsort(user_ratings)[::-1] top_movies = sorted_indices[:num_recommendations] return top_movies# 计算相似度矩阵similarity = similarity_matrix(ratings)# 预测评分predicted_ratings = predict_ratings(ratings, similarity)# 用户ID为0的用户推荐电影recommended_movies = recommend_movies(predicted_ratings, 0)print("推荐的电影:")for movie_id in recommended_movies: print("电影ID:", movie_id)