
目录
使用类注解
前置工作
Bean命名规则
五大类的实现
JavaEE标准分层
之前我们存储Bean时,是在spring-config.xml文件中添加bean注册内容来实现的
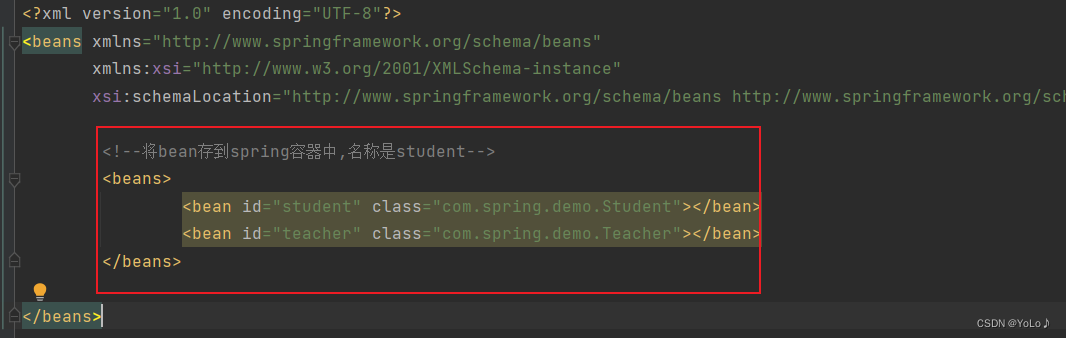
通过"注解"我们可以替代这一项工作
更加简单的存储方式:
使用类注解
五大类注解:
@Controller(控制器):用来控制前端提交的请求,验证用户请求的数据的正确性(安保系统)
@Service(服务):编排和调度具体的执行方法
@Repository:持久层,和数据库交互=DAO(Data Access Object)数据访问层
@Component:组件,存放工具类
@Configuration:配置项,项目中的配置
前置工作
创建好Spring项目后,进行前置工作:配置扫描路径
要将对象存储到Spring中,需要配置一下存储对象的扫描路径, 只有配置的包下的所有类,添加了注解才会正确的被识别并保存到Spring
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:content="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd"> <content:component-scan base-package="com.aaa.service"></content:component-scan></beans> 创建.xml配置文件,将上述代码粘贴到这里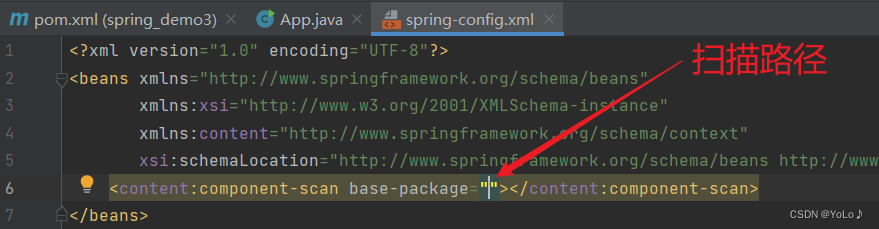

<content:component-scan base-package="com.java.demo"></content:component-scan>只有这个包下的类,才会扫描是否有五大类注解的.如果这个类没加注解,也不会被加入Spring
但是,如果加了五大类注解,却没在这个包下的类,也不会被存储到Spring中
Bean命名规则
新建类,然后使用注解添加类到Spring中
package com.java.demo;import org.springframework.stereotype.Controller;@Controller//将当前类存储到Spring中public class StudentController { public void say(){ System.out.println("student-hello"); }}import com.java.demo.StudentController;import org.springframework.context.ApplicationContext;import org.springframework.context.support.ClassPathXmlApplicationContext;public class App { public static void main(String[] args) { ApplicationContext context = new ClassPathXmlApplicationContext("spring-config.xml"); StudentController studentController = context.getBean("StudentController",StudentController.class); studentController.say(); }}我们使用上文所说,第三种类型+名称的方式获取Bean
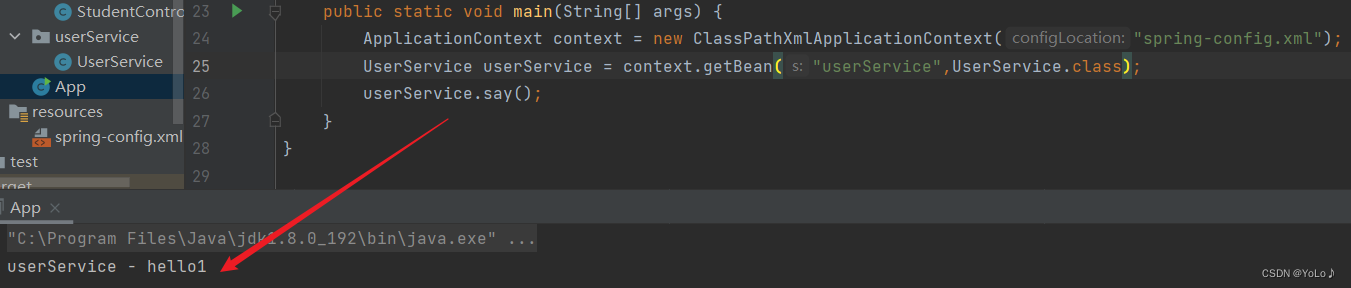
名称先用类名试一试,报错了

使用原类名首字母小写的形式试试,成功了

那么名称是需要使用原类名首字母小写的形式,这是个spring的约定
那如果是这种形式的类名呢?
package com.java.demo;public class SController { public void say(){ System.out.println("SController-hello"); }}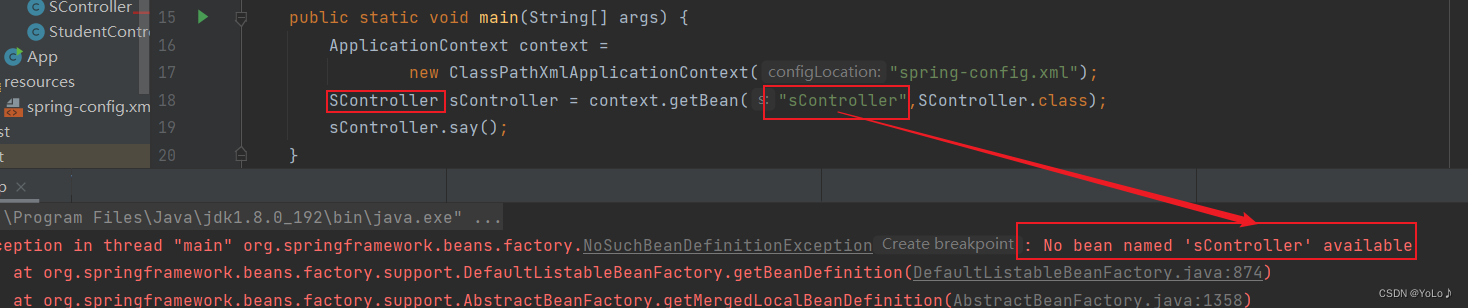
通过原类名首字母小写的形式,获取不到bean
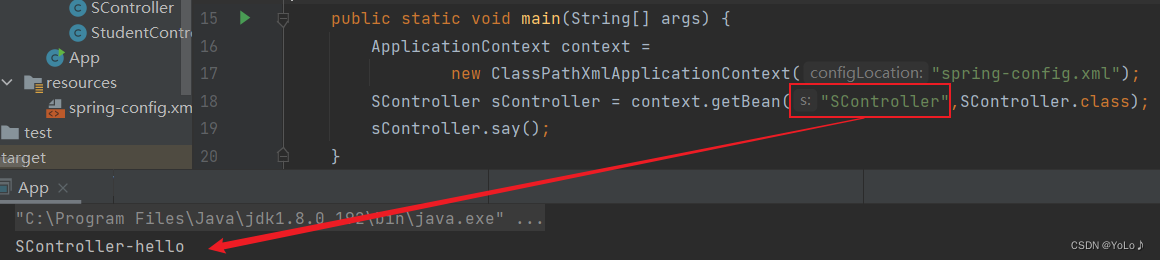
规则:
如果类名是第一个字母大写,第二个字母小写,就可以原类名首字母小写形式去访问
如果类名是第一个字母大写,第二个字母也是大写,就只能用原类名形式访问
我们从源码角度分析,为什么是这样的规则

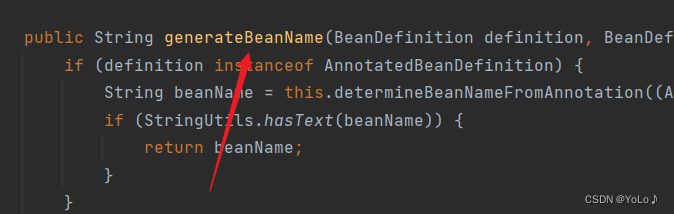


看这段代码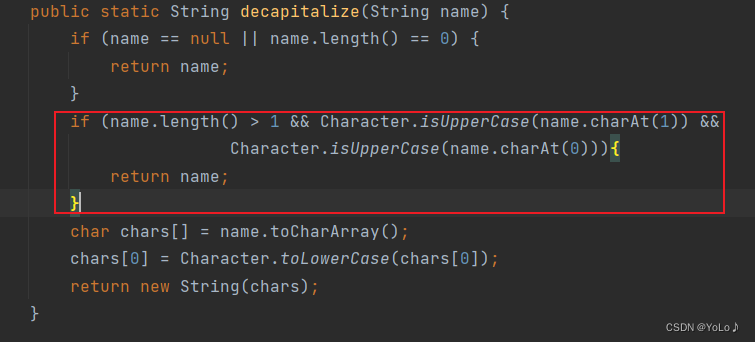
如过name.length()大于1并且下标为1的字符是大写并且第0个字符也为大写写,那么就返回name
对应的是第二条规则
否则,将第0个字符转换成小写并返回
对应的是第一条规则
Bean,命名规则:默认情况下是首字母小写,如果类名首字母和第二个字母都为大写,Bean名称为原类名
我们使用这个方法测试一下不同的名称
import java.beans.Introspector;public class BeanNameTest { public static void main(String[] args) { String name1 = "USer"; String name2 = "User"; System.out.println("name1 => "+Introspector.decapitalize(name1)); System.out.println("name2 => "+Introspector.decapitalize(name2)); }}与我们分析的相同

五大类的实现
@Controller实现了对Bean的存取

将注解替换为@Service
效果:也能获取到Bean并使用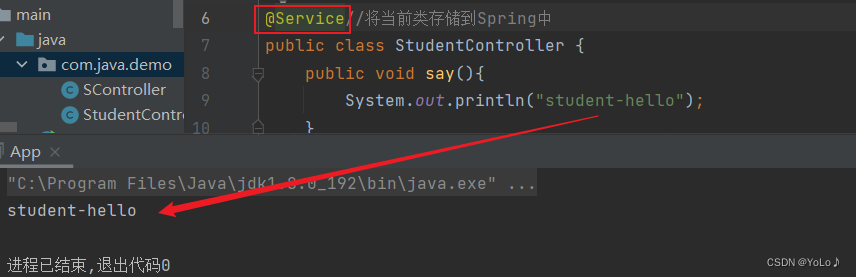
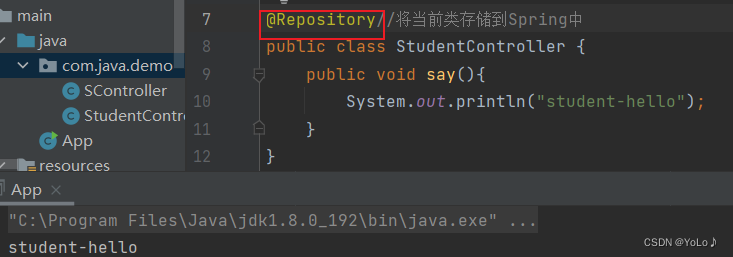
换成@Repository也能成功
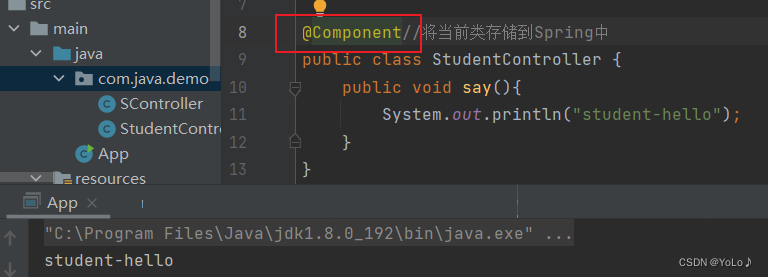
换成@Component也能成功
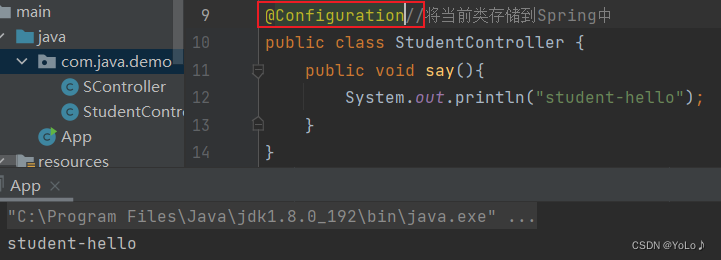
换成@Configuration,也可以
这五大类注解,都都更加简单的存储获取Bean
<bean>标签能否可以和content-scan一起使用呢?新建一个包创建类试试

使用bean标签
 成功执行了,说明<bean>标签和 content-scan是可以一起使用的.
成功执行了,说明<bean>标签和 content-scan是可以一起使用的.
这种场景是在这个类不合适放在content-scan扫描的包下的,但是有需要这个类,就将它用bean标签配置,相当于对content-scan的补充
如果 去掉 bean标签,再加上注解,能获取到userService吗?
也就是,如果没在content-scan扫描路径下的类,加了五大类注解能不能存取Bean?
看结果:代码虽然没有报错,但是结果 是找不到userService这个bean的
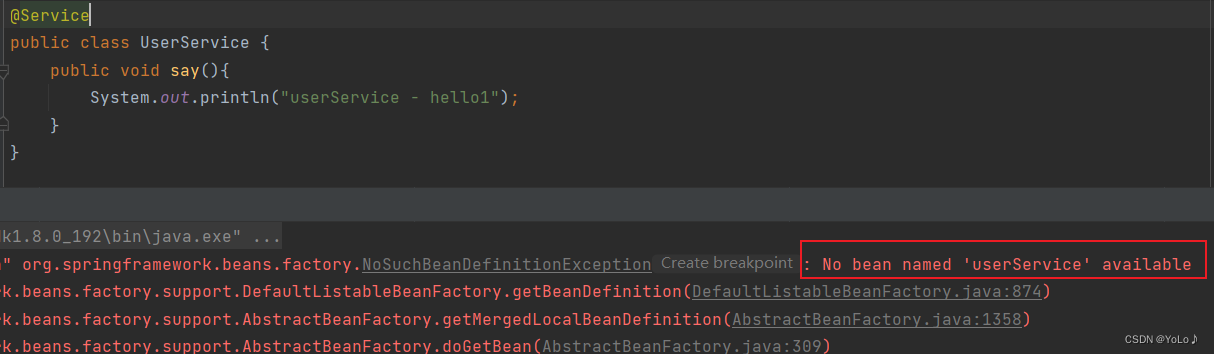
所以答案是不可以!
如果不再扫描路径下,就不会被扫描
那要是在扫描路径下,没加五大类注解呢?
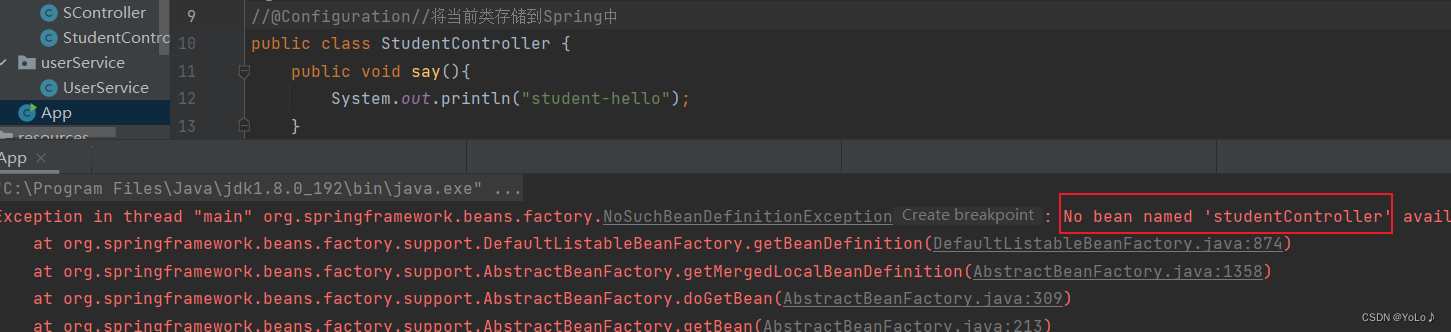
也是不行的,即使在扫描路径下,没有五大类注解,也是不能被存储到Spring中的
还有个结论:如果在content-scan下的所有子包下的类,只要加了五大类注解,都能被存储到Spring中
建议:不要有重名的类,导包很可能导错,如果报错了,可以加别名来区分
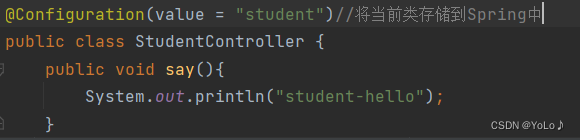
五大类注解既然都能进行存储Bean对象,那么为啥要设置五个类注解?
先看看每个注解的实现
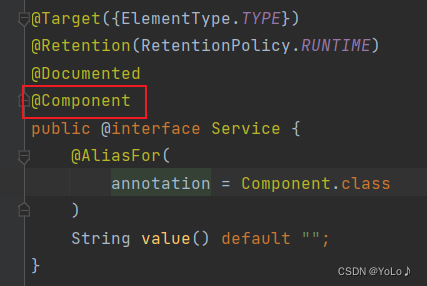

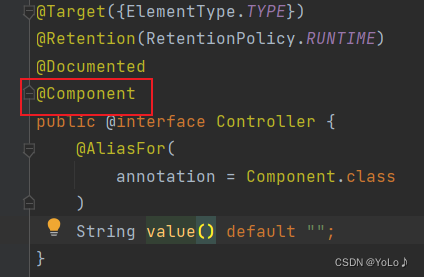
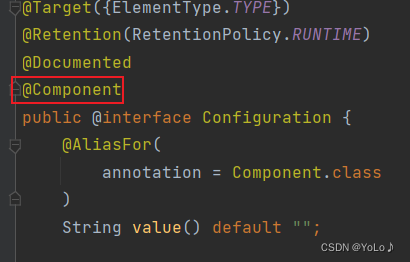
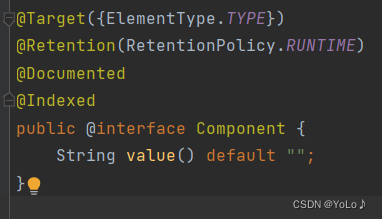
可以看到,这四个注解都是基于Component实现的,都是它的一个子类,是针对于它的功能的扩展
回到问题,为什么需要五大类注解呢?
JavaEE标准分层
需要先学习JavaEE标准分层
为什么要分层?
高内聚:分层的设计可以简化系统设计,让不同的层专注做某一模块的事
低耦合:层与层之间通过接口或API来交互,依赖方不用知道被依赖方的细节
复用:分层之后可以做到很高的复用
扩展性:分层架构可以让我们更容易做横向扩展
如果系统没有分层,当业务规模增加或流量增大时我们只能针对整体系统来做扩展。分层之后可以很方便的把一些模块抽离出来,独立成一个系统
JavaEE标准分层至少三层(后端三层架构)
1.请求处理层(验证参数):业务逻辑层
2.业务逻辑层(服务调度)
3.数据持久层(直接操作数据库)DAO层
这个分层是我们做项目的基础
这是阿里的分层标准
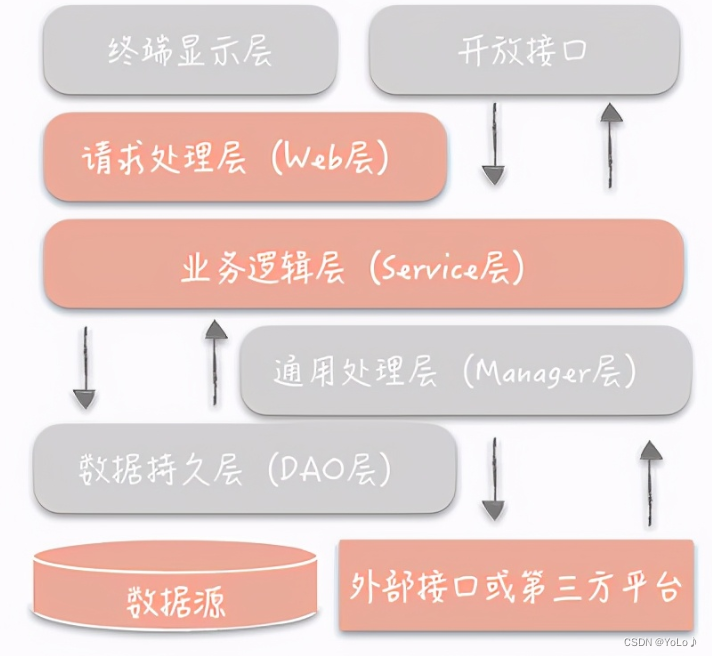
细化了原来的三层架构,添加了Manager 通用业务处理层
mannger层作用
一、可以将原先 Service 层的一些通用能力下沉到这一层,比如与缓存和存储交互策略,中间件的接入;二、也可以在这一层封装对第三方接口的调用,比如调用支付服务,调用审核服务等RPC接口。
优点:相比于三层方式,添加了通用处理层对接外部平台。 上下游对接划分的比较清晰
缺点:核心业务逻辑层没有划分
适应场景:业务逻辑不复杂的常用业务
回到问题,为什么要设置五大类 注解?
设置五大类注解的作用就很明了了,为了方便程序员使用,看到某个注解时,就知道是什么层面的代码,这些注解底层都是Component,功能都是相同的,目的就是为了让程序员看到注解就能知道当前类的作用!
方法注解也可以存储bean:@Bean
下文再介绍