Latent Diffusion Models / Stable Diffusion
High-Resolution Image Synthesis with Latent Diffusion Models(CVPR 2022)
https://arxiv.org/abs/2112.10752
latent-diffusion
stable-diffusion
引言
AI作画近期取得如此巨大进展的原因个人认为有很大的功劳归属于Stable Diffusion的开源。Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。Stable Diffusion在LAION-5B的一个子集上训练了一个Latent Diffusion Models,该模型专门用于文图生成。
Latent Diffusion Models通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像,让文图生成能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛,也带来了文图生成领域的大火。所以,如果你想了解Stable Diffusion的背后原理,可以跟我一起深入解读一下其背后的论文High-Resolution Image Synthesis with Latent Diffusion Models(Latent Diffusion Models),同时这篇文章后续也会针对相关代码进行讲解。
Stable Diffusion
再解读论文之前,首先让我深入了解一下Stable Diffusion。
Stable Diffusion基于Latent Diffusion Models,专门用于文图生成任务。目前,Stable Diffusion发布了v1版本,即Stable Diffusion v1,它是Latent Diffusion Models的一个具体实现,具体来说,它特指这样的一个模型架构设置:自编码器下采样因子为8,UNet大小为860M,文本编码器为CLIP ViT-L/14。官方目前提供了以下权重:
sd-v1-1.ckpt: 237k steps at resolution 256x256 on laion2B-en. 194k steps at resolution 512x512 on laion-high-resolution (170M examples from LAION-5B with resolution >= 1024x1024).sd-v1-2.ckpt: Resumed from sd-v1-1.ckpt. 515k steps at resolution 512x512 on laion-aesthetics v2 5+ (a subset of laion2B-en with estimated aesthetics score > 5.0, and additionally filtered to images with an original size >= 512x512, and an estimated watermark probability < 0.5. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using the LAION-Aesthetics Predictor V2).sd-v1-3.ckpt: Resumed from sd-v1-2.ckpt. 195k steps at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning to improve classifier-free guidance sampling.sd-v1-4.ckpt: Resumed from sd-v1-2.ckpt. 225k steps at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning to improve classifier-free guidance sampling.论文贡献
Diffusion model相比GAN可以取得更好的图片生成效果,然而该模型是一种自回归模型,需要反复迭代计算,因此训练和推理代价都很高。论文提出一种在潜在表示空间(latent space)上进行diffusion过程的方法,从而能够大大减少计算复杂度,同时也能达到十分不错的图片生成效果。相比于其它空间压缩方法,论文提出的方法可以生成更细致的图像,并且在高分辨率图片生成任务(如风景图生成,百万像素图像)上表现得也很好。论文将该模型在无条件图片生成(unconditional image synthesis), 图片修复(inpainting),图片超分(super-resolution)任务上进行了实验,都取得了不错的效果。论文还提出了cross-attention的方法来实现多模态训练,使得条件图片生成任务也可以实现。论文中提到的条件图片生成任务包括类别条件图片生成(class-condition), 文图生成(text-to-image), 布局条件图片生成(layout-to-image)。这也为日后Stable Diffusion的开发奠定了基础。方法
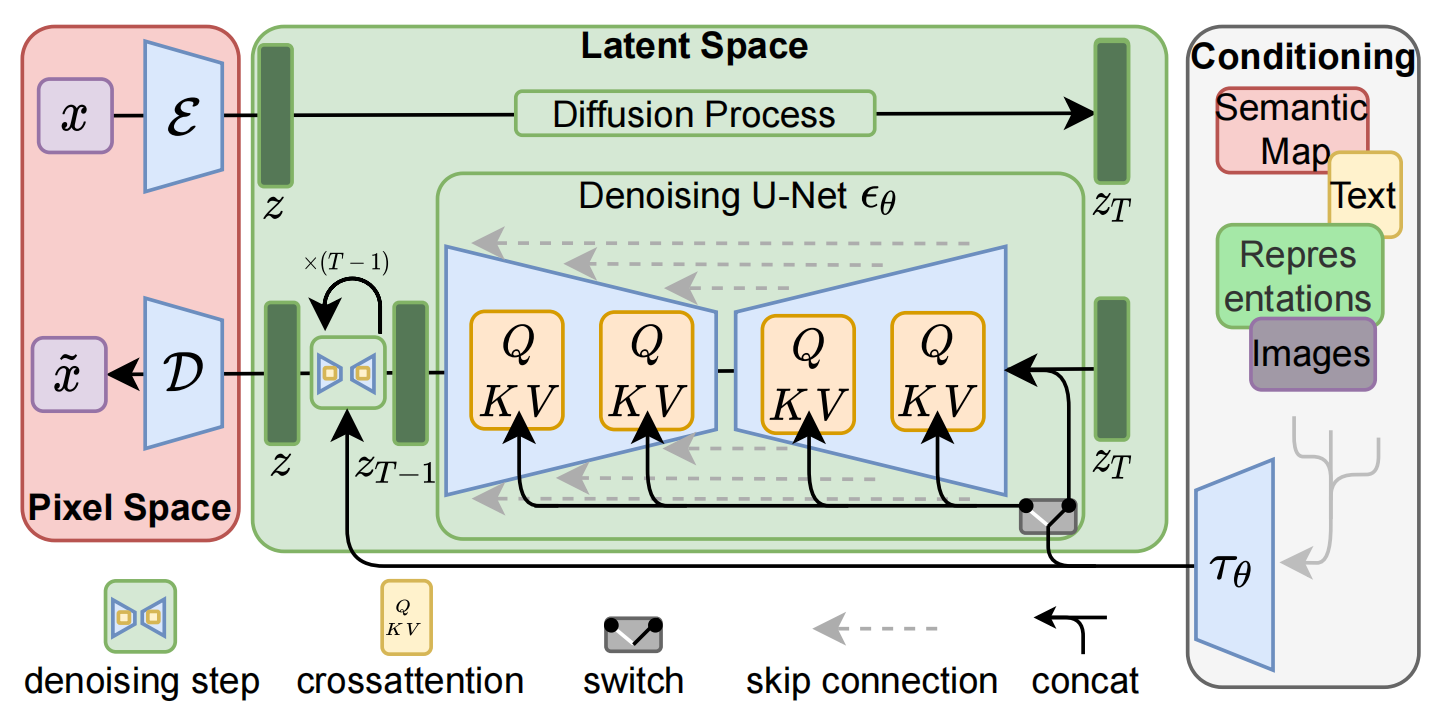
基本思路:【论文将这个方法称之为感知压缩(Perceptual Compression)】:在AutoEncoder的编码器 E \mathcal{E} E 对图片进行压缩 ==> 然后在潜在表示空间上做diffusion操作 ==> 最后再用解码器 D D D 恢复到原始像素空间
自编码器的方法有几个优点:
通过离开高维图像空间,获得计算效率高得多的diffusion models,因为采样是在低维空间上进行的。利用了从其UNet架构[71]继承而来的diffusion models的归纳偏差,这使它们对具有空间结构的数据特别有效,从而减轻了对之前方法所要求的激进的、降低质量的压缩水平的需求。得到了通用的压缩模型,其潜空间可用于训练多个生成模型,也可用于其他下游应用,如单图像片段引导的合成。Latent Diffusion Models整体框架如上图,首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器 E \mathcal{E} E 和一个解码器 D D D )。这样一来,我们就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可,论文将这个方法称之为感知压缩(Perceptual Compression)。个人认为这种将高维特征压缩到低维,然后在低维空间上进行操作的方法具有普适性,可以很容易推广到文本、音频、视频等领域。
在潜在表示空间上做diffusion操作其主要过程和标准的扩散模型没有太大的区别,所用到的扩散模型的具体实现为 time-conditional UNet。但是有一个重要的地方是论文为diffusion操作引入了条件机制(Conditioning Mechanisms),通过cross-attention的方式来实现多模态训练,使得条件图片生成任务也可以实现。
下面我们针对感知压缩、扩散模型、条件机制的具体细节进行展开。
1)★★★图片感知压缩(Perceptual Image Compression)
感知压缩本质上是一种tradeoff【权衡】,之前的很多扩散模型没有使用这个技巧也可以进行,但原有的非感知压缩的扩散模型有一个很大的问题在于,由于在像素空间上训练模型,如果我们希望生成一张分辨率很高的图片,这就意味着我们训练的空间也是一个很高维的空间。引入感知压缩就是说通过VAE这类自编码模型对原图片进行处理,忽略掉图片中的高频信息,只保留重要、基础的一些特征。这种方法带来的的好处就像引文部分说的一样,能够大幅降低训练和采样阶段的计算复杂度,让文图生成等任务能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛。
感知压缩主要利用一个预训练的自编码模型,该模型能够学习到一个在感知上等同于图像空间的潜在表示空间。这种方法的一个优势是只需要训练一个通用的自编码模型,就可以用于不同的扩散模型的训练,在不同的任务上使用。这样一来,感知压缩的方法除了应用在标准的无条件图片生成外,也可以十分方便的拓展到各种图像到图像(inpainting,super-resolution)和文本到图像(text-to-image)任务上。
由此可知,基于感知压缩的扩散模型的训练本质上是一个两阶段训练的过程,第一阶段需要训练一个自编码器,第二阶段才需要训练扩散模型本身。在第一阶段训练自编码器时,为了避免潜在表示空间出现高度的异化,作者使用了两种正则化方法,一种是KL-reg,另一种是VQ-reg,因此在官方发布的一阶段预训练模型中,会看到KL和VQ两种实现。在Stable Diffusion中主要采用AutoencoderKL这种实现。
具体来说,给定图像 x ∈ R H × W × 3 x \in \mathbb{R}^{H \times W \times 3} x∈RH×W×3 ,我们可以先利用一个编码器 E \mathcal{E} E 来将图像编码到潜在表示空间 ,其中 z ∈ R H × W × 3 z \in \mathbb{R}^{H \times W \times 3} z∈RH×W×3,然后再用解码器从潜在表示空间重建图片 x ~ = D ( z ) = D ( E ( x ) ) \tilde{x}=\mathcal{D}(z)=\mathcal{D}(\mathcal{E}(x)) x~=D(z)=D(E(x)) 。在感知压缩压缩的过程中,下采样因子的大小为 f = H / h = W / w f=H/h=W/w f=H/h=W/w ,它是2的次方,即 f = 2 m f=2^m f=2m 。
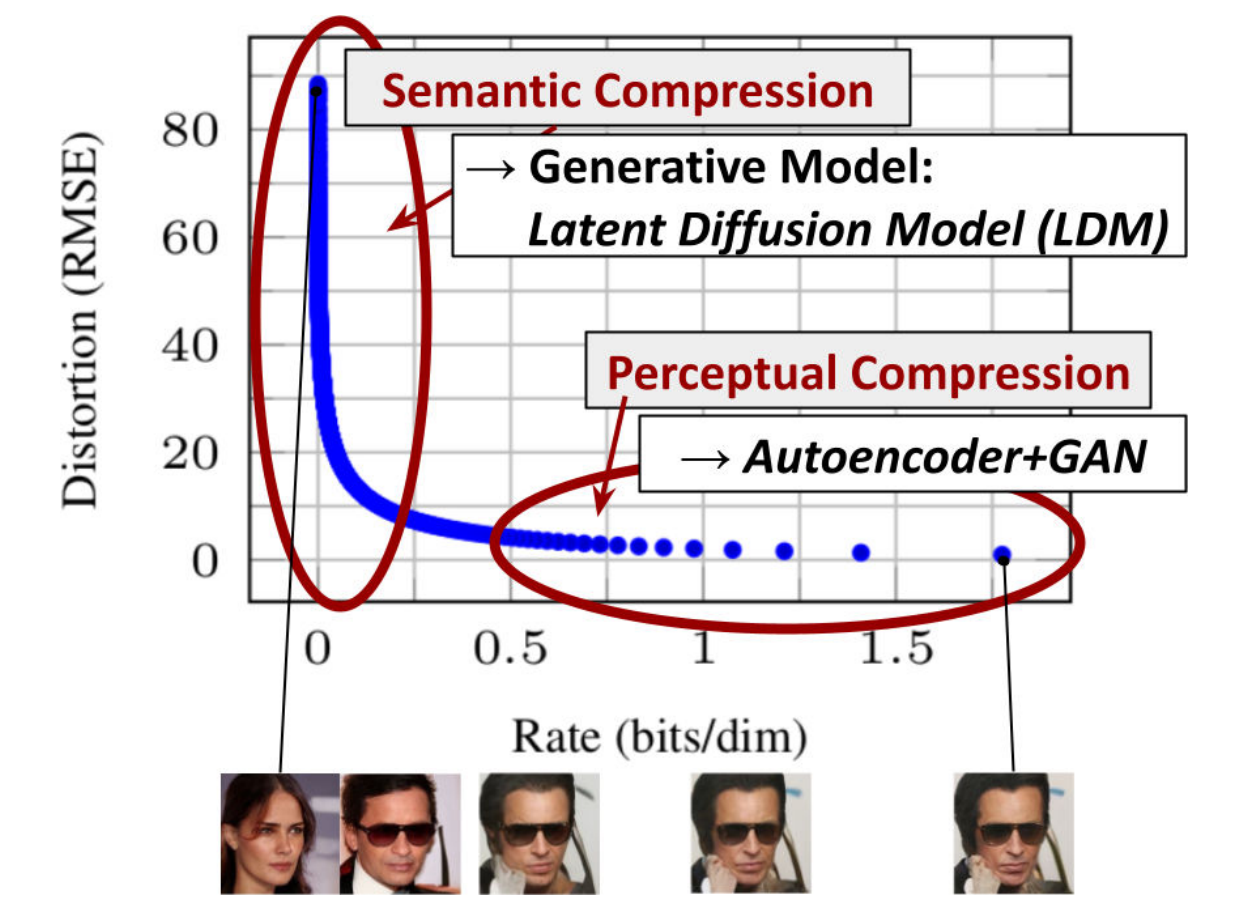
如下图所示:横轴是隐变量每个维度压缩的bit率,纵坐标是模型的损失。模型在学习的过程中,随着压缩率变大,刚开始模型的损失下降很快,后面下降很慢,但仍然在优化。模型首先学习到的是semantic部分的压缩/转换(轮廓部分),然后学习到的是perceptual部分的压缩/转换,这是细节处的转变。
2)潜在扩散模型(Latent Diffusion Models)
首先简要介绍一下普通的扩散模型(DM),扩散模型可以解释为一个时序去噪自编码器(equally weighted sequence of denoising autoencoders) ϵ θ ( x t , t ) ; t = 1 … T \epsilon_{\theta}\left(x_{t}, t\right) ; t=1 \ldots T ϵθ(xt,t);t=1…T ,其目标是根据输入 x t x_t xt 去预测一个对应去噪后的变体,或者说预测噪音,其中 x t x_t xt 是输入 x x x 的噪音版本。相应的目标函数可以写成如下形式:
L D M = E x , ϵ ∼ N ( 0 , 1 ) , t [ ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 2 ] L_{D M}=\mathbb{E}_{x, \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_{\theta}\left(x_{t}, t\right)\right\|_{2}^{2}\right] LDM=Ex,ϵ∼N(0,1),t[∥ϵ−ϵθ(xt,t)∥22]
其中 t t t 从 { 1 , … , T } \{1, \ldots, T\} {1,…,T} 中均匀采样获得。
而在潜在扩散模型中,引入了预训练的感知压缩模型,它包括一个编码器 E \mathcal{E} E 和一个解码器 D D D 。这样就可以利用在训练时就可以利用编码器得到 z t z_t zt,从而让模型在潜在表示空间中学习,相应的目标函数可以写成如下形式:
L L D M : = E E ( x ) , ϵ ∼ N ( 0 , 1 ) , t [ ∥ ϵ − ϵ θ ( z t , t ) ∥ 2 2 ] L_{L D M}:=\mathbb{E}_{\mathcal{E}(x), \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_{\theta}\left(z_{t}, t\right)\right\|_{2}^{2}\right] LLDM:=EE(x),ϵ∼N(0,1),t[∥ϵ−ϵθ(zt,t)∥22]
3)条件机制(Conditioning Mechanisms)
除了无条件图片生成外,我们也可以进行条件图片生成,这主要是通过拓展得到一个条件时序去噪自编码器(conditional denoising autoencoder) ϵ θ ( z t , t , y ) \epsilon_{\theta}\left(z_{t}, t, y\right) ϵθ(zt,t,y) 来实现的,这样一来我们就可通过 y y y 来控制图片合成的过程。具体来说,论文通过在UNet主干网络上增加cross-attention机制来实现 ϵ θ ( z t , t , y ) \epsilon_{\theta}\left(z_{t}, t, y\right) ϵθ(zt,t,y)。为了能够从多个不同的模态预处理 y y y ,论文引入了一个领域专用编码器(domain specific encoder) T θ \mathcal{T}_{\theta} Tθ ,它用来将 y y y 映射为一个中间表示 τ θ ( y ) ∈ R M × d τ \tau_{\theta}(y) \in \mathbb{R}^{M \times d_{\tau}} τθ(y)∈RM×dτ ,这样我们就可以很方便的引入各种形态的条件(文本、类别、layout等等)。最终模型就可以通过一个cross-attention层映射将控制信息融入到UNet的中间层,cross-attention层的实现如下:
A t t e n t i o n ( Q , K , V ) = softmax ( Q K T d ) ⋅ V Attention (Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d}}\right) \cdot V Attention(Q,K,V)=softmax(d QKT)⋅V
Q = W Q ( i ) ⋅ φ i ( z t ) , K = W K ( i ) ⋅ τ θ ( y ) , V = W V ( i ) ⋅ τ θ ( y ) Q=W_{Q}^{(i)} \cdot \varphi_{i}\left(z_{t}\right), K=W_{K}^{(i)} \cdot \tau_{\theta}(y), V=W_{V}^{(i)} \cdot \tau_{\theta}(y) Q=WQ(i)⋅φi(zt),K=WK(i)⋅τθ(y),V=WV(i)⋅τθ(y)
其中 φ i ( z t ) ∈ R N × d ϵ i \varphi_{i}\left(z_{t}\right) \in \mathbb{R}^{N \times d_{\epsilon}^{i}} φi(zt)∈RN×dϵi 是UNet的一个中间表征。相应的目标函数可以写成如下形式:
L L D M : = E E ( x ) , y , ϵ ∼ N ( 0 , 1 ) , t [ ∥ ϵ − ϵ θ ( z t , t , τ θ ( y ) ) ∥ 2 2 ] L_{L D M}:=\mathbb{E}_{\mathcal{E}(x), y, \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_{\theta}\left(z_{t}, t, \tau_{\theta}(y)\right)\right\|_{2}^{2}\right] LLDM:=EE(x),y,ϵ∼N(0,1),t[∥ϵ−ϵθ(zt,t,τθ(y))∥22]
实验
论文的所用到的模型为LDMs,在无条件图片生成任务上用到的数据集为LSUN、FFHQ以及CelebA-HQ,在类别条件图片生成用到的数据集为ImageNet,在文图生成任务上用到的数据集为Conceptual Captions、LAION。论文设计了大量的对比实验,并分别对感知压缩权衡(下采样因子)、LDM生成效果对比进行了分析验证。并且还在其他任务上进行了实验,包括Super-Resolution、Inpainting、layout-condition在内的多种图片生成等任务,这说明说明LDMs中的学习到的潜在表示空间确实具备很强的分布拟合能力,能够够适配各种下游任务。
感知压缩权衡(Perceptual Compression Tradeoffs)
前面提到过下采样因子 f f f 的大小为 f = H / h = W / w f=H/h=W/w f=H/h=W/w,如果 f = 1 f=1 f=1 那就等于没有对输入的像素空间进行压缩,如果 f f f 越大,则信息压缩越严重,可能会噪声图片失真,但是训练资源占用的也越少。论文对比了 f f f 在分别 {1,2,4,8,16,32} 下的效果,发现 f f f 在 {4-16} 之间可以比较好的平衡压缩效率与视觉感知效果。作者重点推荐了LDM-4和LDM-8。
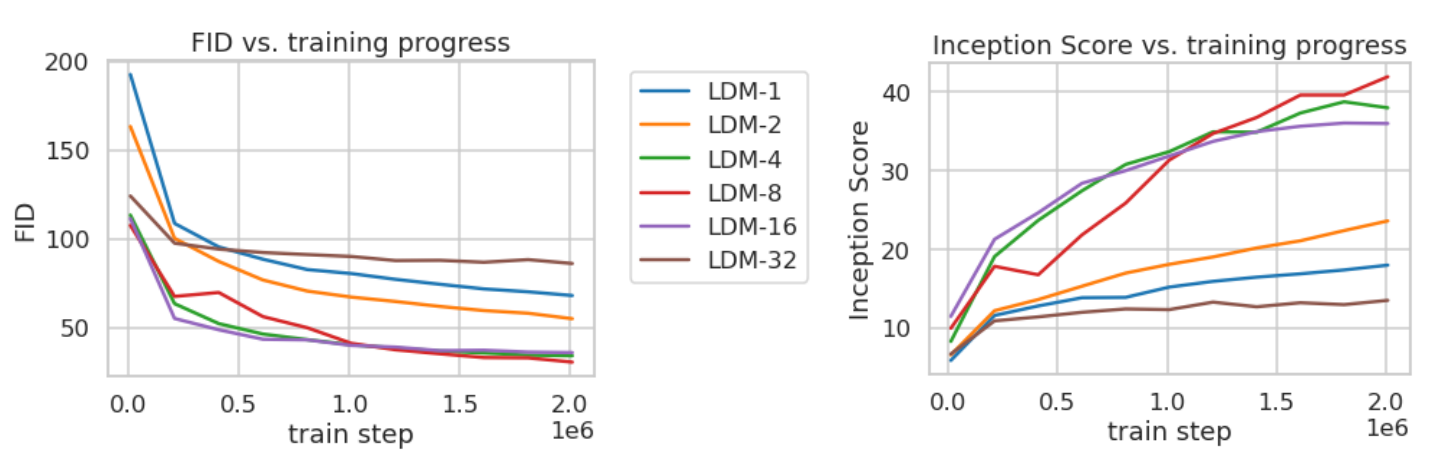
下采样因子对比实验,横坐标train step,左纵坐标FID,右纵坐标Inception Score
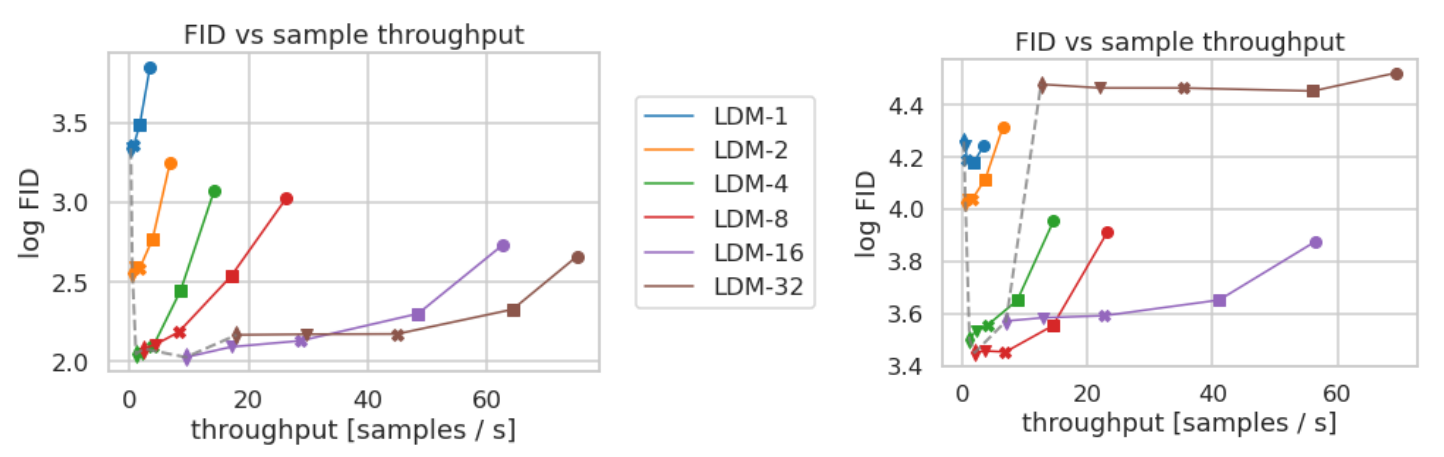
下采样因子对比实验(Inference speed VS sample quality),横坐标throughtput【吞吐率/采样速度】,纵坐标log FID,左CelebA-HQ数据集,右ImageNet数据集
LDM生成效果(Image Generation with Latent Diffusion)
论文从FID和Precision-and-Recall两方面对比LDM的样本生成能力,实验数据集为CelebA-HQ、FFHQ和LSUN-Churches/Bedrooms,实验结果如下: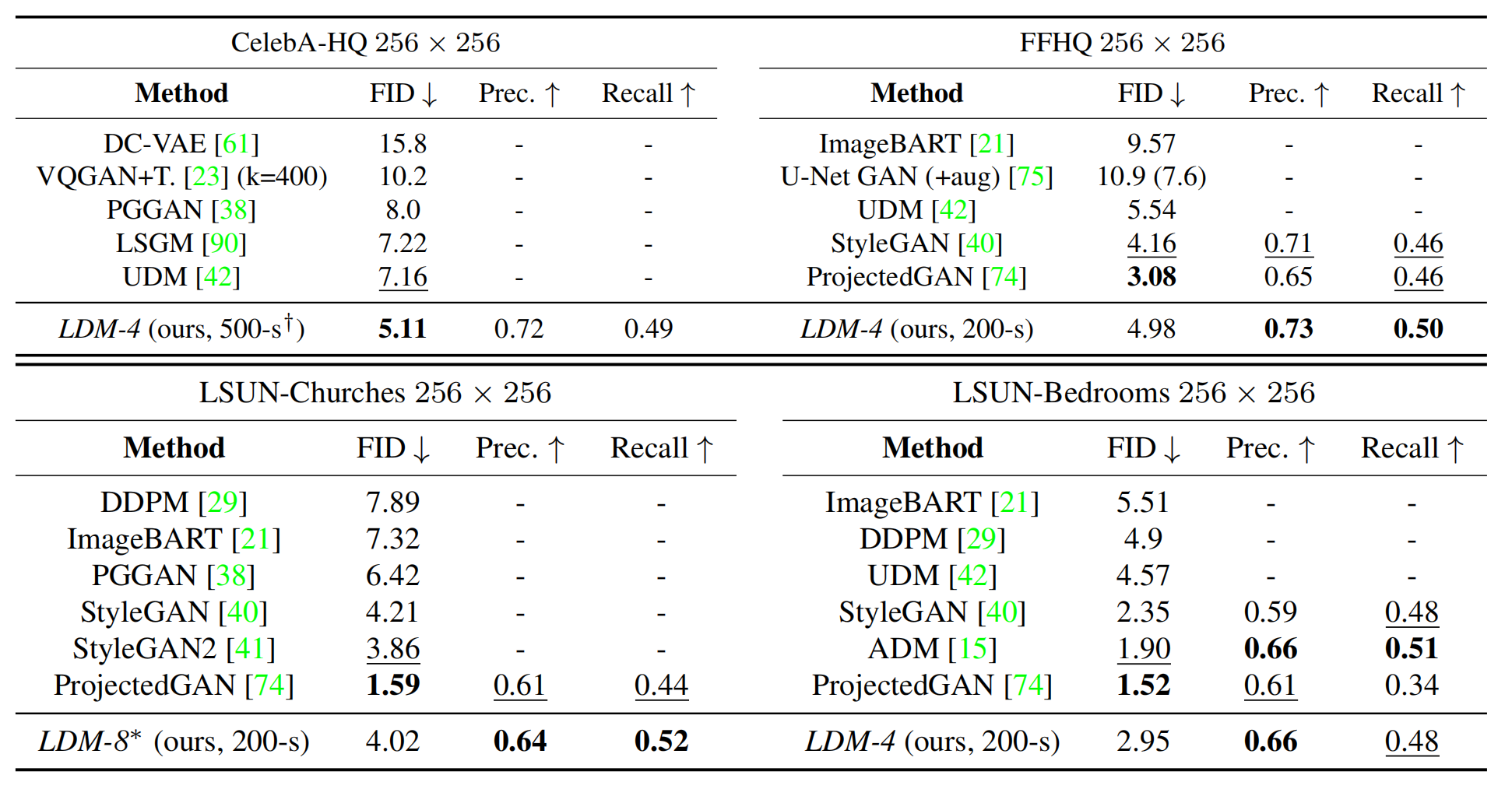
其效果超过了GANs和LSGM,并且超过同为扩散模型的DDPM。
参考:https://zhuanlan.zhihu.com/p/582693939
登录后可发表评论
点击登录