深度学习中的算法学习与记忆,利用故事联想帮助大家记忆,每个人都会
大家好,我是微学AI,大家看过我的文章,想必是对深度学习有了一定的了解了,但是对于初学者来说,深度学习中有很多名词和数学知识、原理还是不太清楚,记忆的不牢固,用起来不熟练,今天就给大家讲一个故事,让大家记忆得更清楚:
故事开始:
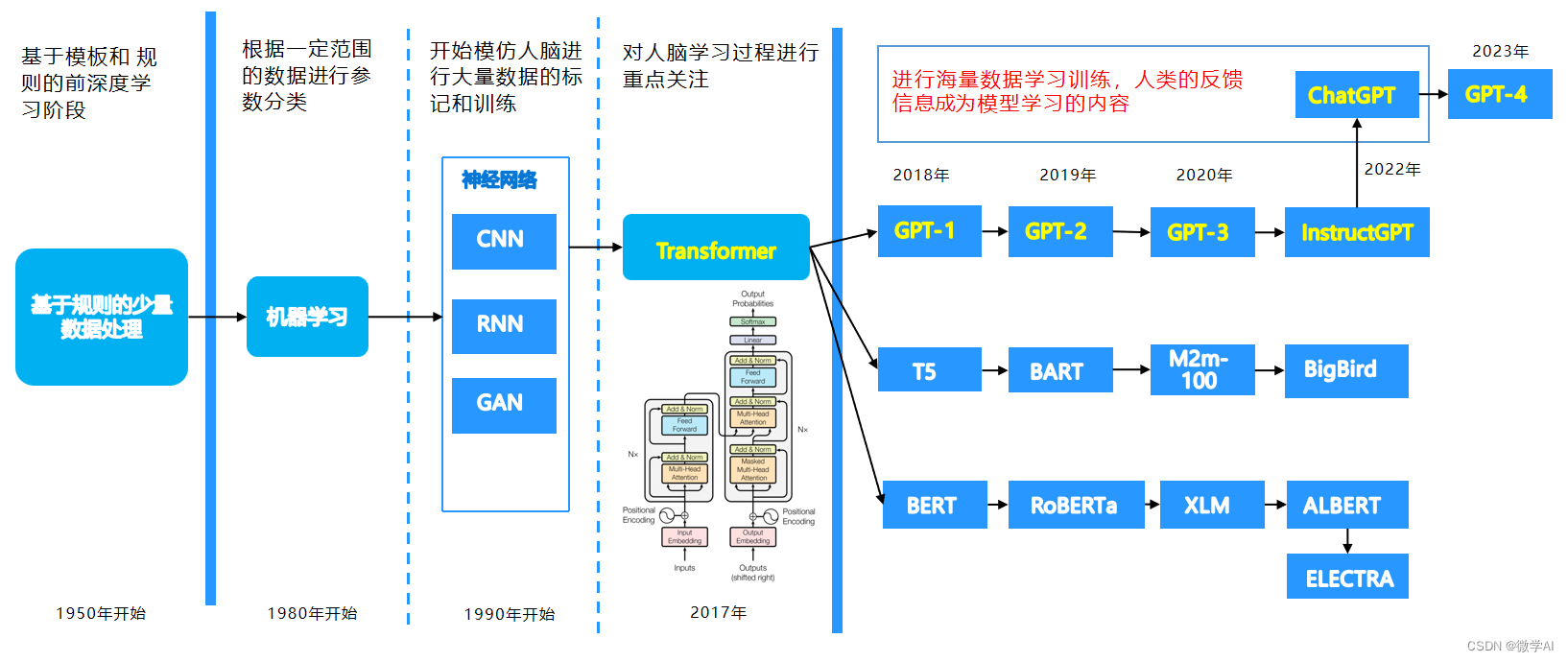
有一位名叫小微的数学科学家,他有一个目标:要用计算机让机器具备类似于人类的智能。为了实现这个目标,他研究了很多算法,其中包括神经网络、卷积神经网络和循环神经网络、以及很多算法模型。
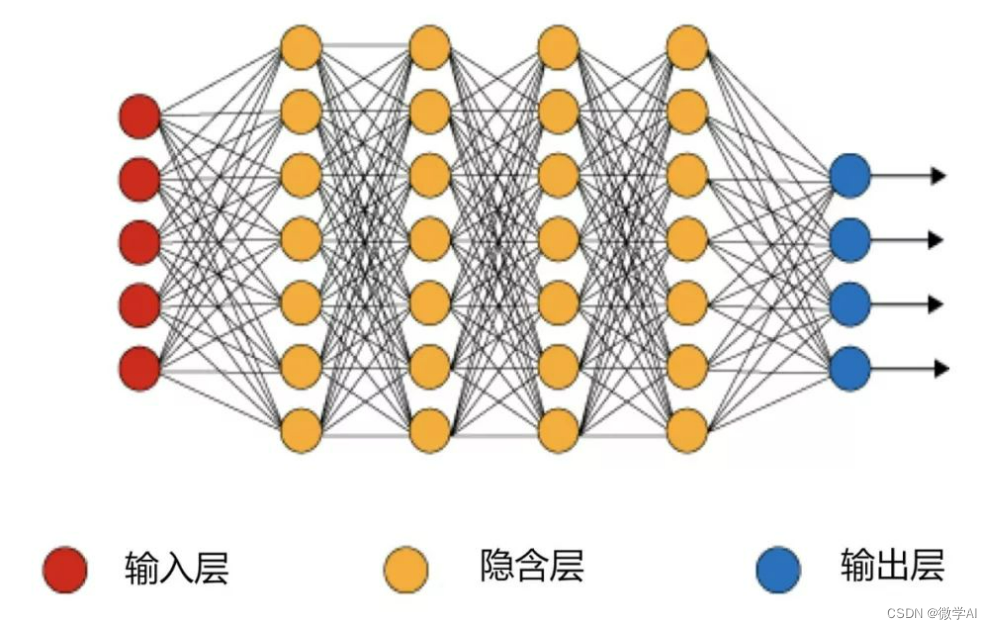
首先,小微深入研究了神经网络。他发现神经网络的结构类似于人脑。它由输入、隐藏和输出三个层次组成,每个层次由一些神经元组成。神经元接收输入信号,并把信号通过激活函数输出到下一层次。通过反向传播算法,小微总结出寻找最优解的方法,也就是不停地去调整神经元之间的连接权重,直到得到最佳计算结果。这个方法被称为梯度下降算法。
接着,小微觉得之前神经网络输入是一维特征向量,如果是二维的图像输入会是什么样的呢?于是他探索了卷积神经网络。他发现这种网络结构在处理图像和视频等数据上非常有效。卷积神经网络由卷积层、池化层和全连接层三个部分组成。卷积层通过滤波器捕捉输入数据中的特征,池化层用于对数据进行下采样,全连接层将汇总的数据映射到最终的输出。小微深入研究了卷积神经网络的训练过程,并利用反向传播算法的技术,可以通过不断地反馈误差信号来优化网络的参数,从而提高网络的性能。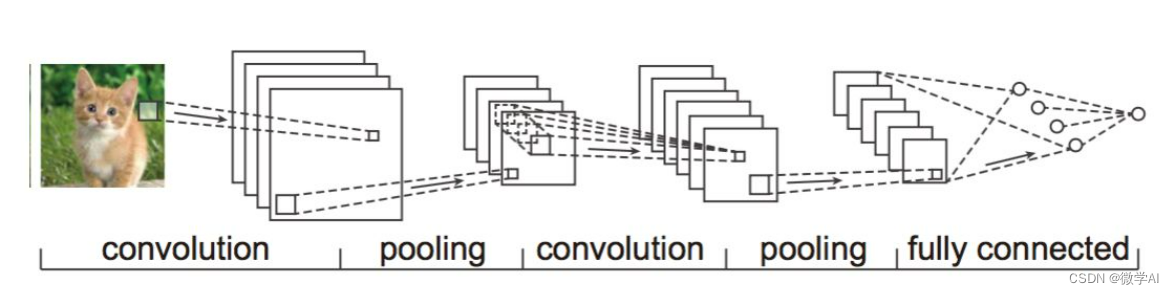
小微后面发现前面都是处理结构化表格数据和图像数据,那么对于语音、文本、音乐等数据好像不能适用了,于是他探索了循环神经网络。他发现这种网络结构非常适合处理序列数据。循环神经网络的结构与神经网络类似,但是神经元之间的连接形成了循环,以便它们可以记住之前的状态,并在当前状态下进一步处理数据。小微深入研究了循环神经网络的训练方法,并发现了一种叫做长短时记忆(LSTM)的技术,它可以让循环神经网络更好地处理长期的依赖关系。LSTM网络中的门机制可以控制信息的输入、输出和遗忘,从而提高网络的性能。

小微不仅研究了神经网络、卷积神经网络和循环神经网络,随着他越来越深入的研究,还涉猎了更多深度学习领域的知识。
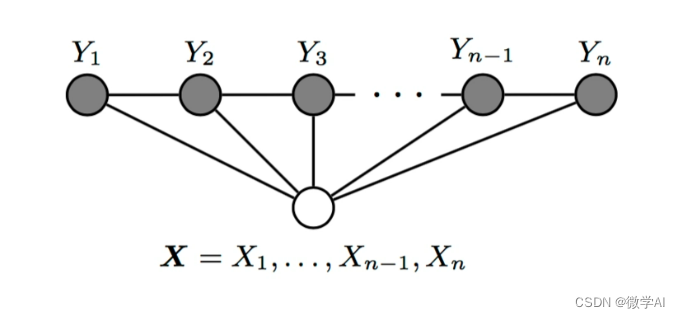
一天,小微听说了一种名为CRF(条件随机场)的模型,这是一种具有时序结构的概率图模型,可以处理诸如自然语言处理(NLP)中的序列标注、句法分析、话题分类等问题。
小微深入研究了CRF模型的原理和应用。他发现CRF模型的核心思想是将输入序列作为观测序列,并构建一些相关的潜变量作为标记序列。然后,通过学习样本标记序列和模型参数之间的关系,CRF模型可以判断给定观测序列的标记序列的概率。CRF模型在序列标注和结构预测等领域取得了很大成功,可以用于识别命名实体、识别情感倾向等。
对于自然语言处理,小微被transformer模型吸引。他发现,transformer模型是一种利用自注意力机制进行序列建模的深度学习模型。相较于 RNN 和 CNN,transformer 模型更高效、更容易并行化,广泛应用于神经机器翻译、文本生成、问答等任务。
小微深入研究了transformer模型的实现过程,他发现transformer模型是由编码器和解码器两个大部分主持,其中编码器和解码器主要由位置编码、自注意力机制、残差连接和前馈传播层、规范化层等部分组成。transformer采用自注意力机制对输入的序列进行编码,能够将目标和上下文联系起来,更好地捕捉序列数据之间的关系。

对于transformer模型的编码器部分,小微开始关注BERT模型。这是谷歌研究人员提出的一种预训练模型,在自然语言处理中取得了重大突破。BERT模型使用了Transformer网络的解码器部分,可以通过训练阶段学习不同自然语言处理任务之间的相似性,之后在具体任务上进行微调。
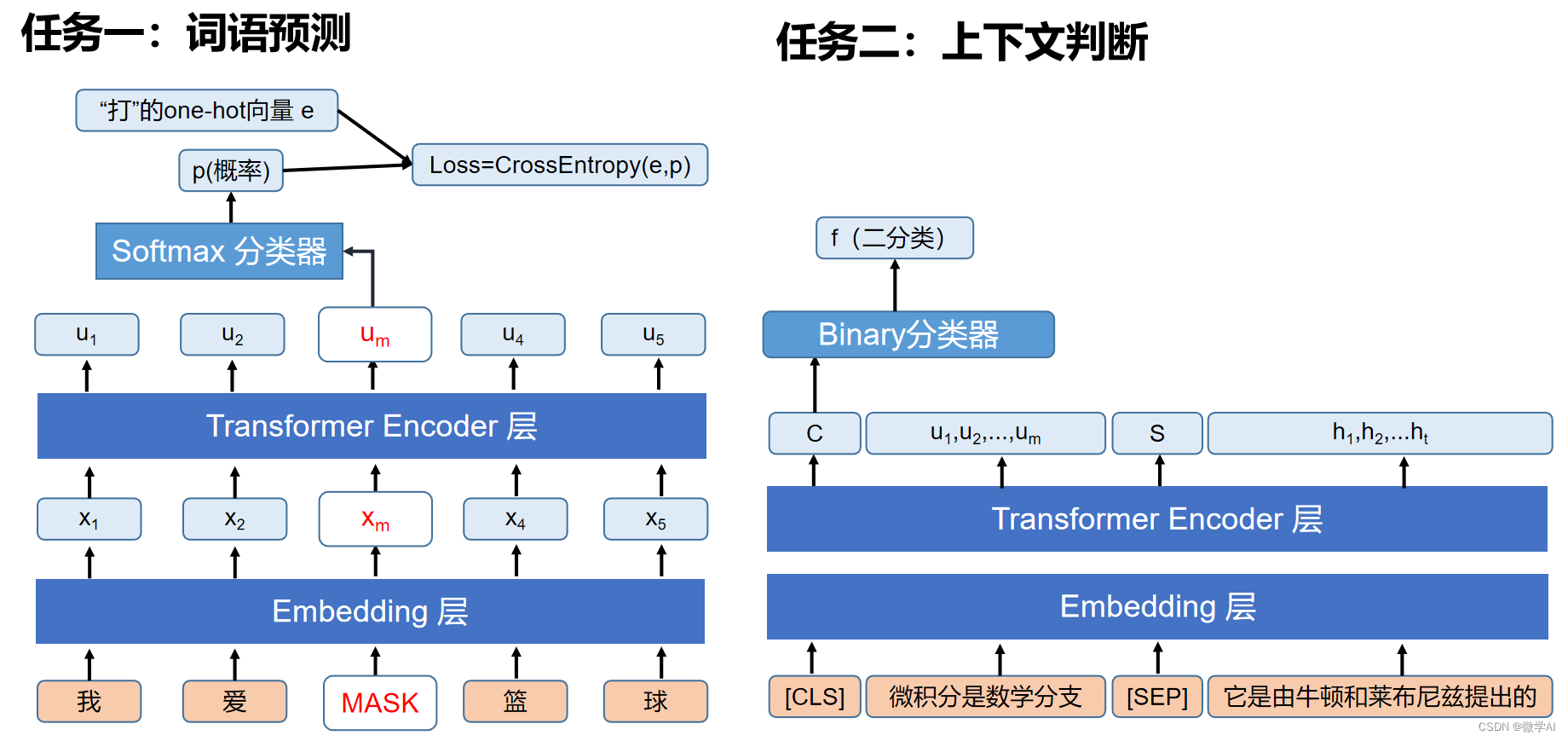
小微很激动,并立即开始研究BERT模型的工作原理。他发现,BERT模型是利用词语预测,上下文判断两大任务进行训练,并生成高质量的词向量表示。它可以对输入序列进行深度处理,并产生高质量的上下文表示。在训练阶段,BERT通过对大量语料进行无监督的预训练,获取了大量的词向量信息等,在具体任务上进行微调后,BERT可以取得很好的效果。
对于transformer模型的解码器部分,小微开始研究GPT模型,这是一种基于transformer网络的语言模型,旨在自动完成给定的NLP任务,如生成语句、问答等。
小微深入研究了GPT模型,他发现GPT模型的核心是基于transformer网络的自回归模型,每个预测token都是在之前已生成的token的基础上进行生成。 GPT模型的训练数据是大量文档,通过预测语言模型的下一个单词、句子衔接等任务的方式提高预测的精度。 GPT模型是一种非常强大的自然语言处理模型,性能在生成句子、问答等任务中表现突出,应用广泛。
小微研究了GPT系列,GPT由1代发展到3代,再到ChatGPT,这是革命性的改变,ChatGPT是美国OpenAI公司研发的功能强大的聊天机器人,他于2022年11月30日发布。ChatGPT是自然语言处理的天花板,它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流,甚至可以完成论文、文案,代码的编写。
到了2023年3月14日GPT4发布,功能比ChatGPT更加强大,拥有了多模态的能力,可以读懂图片的内容。
通过不断探索新的深度学习模型和算法,小微掌握了这些网络和模型的基本原理和实战应用经验,成为了一位卓有成就的人工智能专家。
登录后可发表评论
点击登录