目录
前言
一、分类和预测
分类
预测
二、关于分类和预测的问题
准备分类和预测的数据
评价分类和预测方法
混淆矩阵
评估准确率
参考资料
前言
分类:离散型、分类新数据
预测:连续型、预测未知值
描述属性:连续、离散
类别属性:离散
有监督学习:分类
训练样本有标签
对未知数据分类
无监督学习:
聚类
无标签
划分存在的聚类
一、分类和预测
分类
分类过程是一个两步的过程。第一步是模型建立阶段,或者称为训练阶段,这一步的目的是描述预先定义的数据类或概念集的分类器。在这一步会使用分类算法分析已有数据(训练集)来构造分类器。训练数据集由一组数据元组构成,每个数据元组假定已经属于一个事先指定的类别(由类别标记属性确定)。
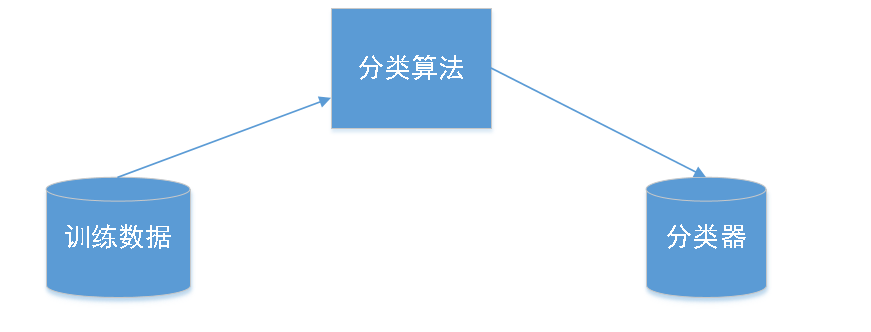
在分类的第二步,需要使用第一步得到的分类器进行分类,从而评估分类器的预测准确率。具体来说,由一组检验元组和相关联的类别标记所组成的测试数据集。
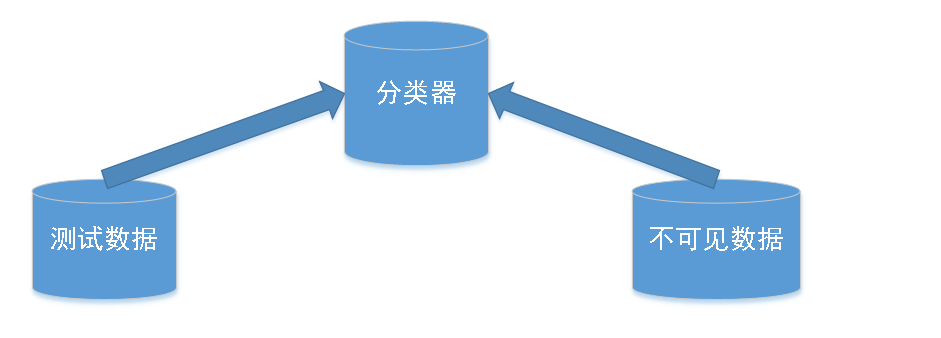
在机器学习中,分类也往往称为有监督学习,“有监督”指的是用于训练的数据元组的类别标记是已知的,新的数据基于训练数据集进行分类。与之对应的是聚类,在机器学习中称为无监督学习,“无监督"指的是用于训练的数据元组的类别标记是未知的,这种学习旨在识别隐含在数据中的类或簇。
预测
数据预测也是一个两步过程。与数据分类不同的是,对于所需要预测的属性值是连续值,而且是有序的;分类所需要预测的属性值是离散的、无序的。预测器与分类器类似,也可以看作一个映射或者函数y= f(x),其中x是输人元组,输出y是连续的或有序的值。与分类相同,测试数据集与训练数据集在预测任务中也应该是独立的。预测的准确率通过对每个检验元组r,利用y的预测值与实际已知值的差来评估。
二、关于分类和预测的问题
准备分类和预测的数据
对分类和预测所使用的数据进行预处理,预处理一般可以分为以下三个步骤:
(1)数据清理。主要目的是减少数据噪声和处理缺失值。
尽管大部分分类算法都有某种处理噪声和缺失值的机制,但是该步骤有助于减少学习时的混乱。
(2)相关分析。目的是移除数据中不相关或冗余的属性。
这样可以加快分类器训练速度,提高分类器准确率。
(3)数据转换。目的是泛化或规范化数据。
这种距离度量方法可以避免受不同属性不同初始值范围对度量结果的影响。
评价分类和预测方法
(1)准确率。
分类准确率指分类器预测新的或先前未出现过的数据元组的类别标记的能力。预测器的准确率指预测器猜测新的或先前未出现过的数据元组的预测属性值的准确程度。
(2)速度。
指建立模型(训练)和使用模型(分类/预测)的时间开销。
(3)鲁棒性。
指分类器或预测器处理噪声值或缺失值数据的能力。
(4)可伸缩性。
指针对大规模数据、分类器或预测器的处理能力。
(5)可解释性。
指分类器或预测器所提供的可理解和洞察的程度。
分类器或预测器在检测集上的准确率和错误率是两个常用的度量准则。检测集上的准确率指的是检测集中被正确分类或预测的元组所占的比例。相反,检测集上的错误率指的是检测集中被错误分类或预测的元组所占的比例。
混淆矩阵

一个分析分类器识别不同元组情况的有用工具。
真正(TruePositives)指分类器正确标记的正元组.TP
真负(TrueNegatives)是指分类器正确标记的负元组。TN
假正(FalsePositives)是错误标记的负元组,FP
假负(FalseNegatives)是错误标记的正元组。FN
正确率:
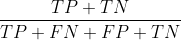
准确率:
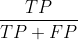
评估准确率
保持、随机子抽样、交叉验证是常用的基于给定数据的随机抽样划分,评估准确率的常用技术。这些技术的使用会增加总体计算开销,但是会有利于模型选择。
保持方法是一般讨论准确率默认的方法。这种方法将给定数据分为两个独立的集合:训练数据集和测试数据集。一般2/3的数据作为训练数据集,1/3的数据作为测试数据集。训练数据集用来建立模型,而准确率通过测试数据集来评估。
随机子抽样方法是保持方法的简单变形,它将保持方法重复k次,总的准确率估计取每次迭代准确率的平均值。
在k-交叉检验中,初始数据随机划分为k个互不相交的子集S1,S2,..Sk,每个子集的大小大致相等。训练和测试进行k次。在第i次迭代,子集Si用作测试集,其余的子集用来训练模型。
参考资料
《数据挖掘:方法与应用》徐华著