居然是全省第二 (广东 B 组省一共 91 人,前 2.1%),差点没把我笑死

测试链接:https://www.dotcpp.com/oj/train/1093/
测试结果还是蛮惨烈,主要原因有几个:
C 语言网的时间限制是 3 s:但实际比赛的时间限制都是 10 s 起步,甚至有 30 s 的莫名其妙的运行报错:我不知道 D 题的代码为什么部分样例会出现“运行错误”,那么简单的代码怎么都不可能访问越界啊 (上次省赛也有一道题的 oj 是 C 语言网出了问题)说到底还是我菜,写不出完美的代码,这篇题解供大家图一乐咯
A:2023 100?
【问题描述】
请求出在 12345678 至 98765432 中,有多少个数中完全不包含 2023 。
完全不包含 2023 是指无论将这个数的哪些数位移除都不能得到 2023 。
例如 20322175,33220022 都完全不包含 2023,而 20230415,20193213 则 含有 2023 (后者取第 1, 2, 6, 8 个数位) 。
【解析及代码】
数据规模也才 1e9 左右,暴力枚举就完了
利用 re 库的正则表达式进行匹配,非常方便,答案:85959030
import repat = re.compile(r'\d*'.join('2023'))nums = range(12345678, 98765432 + 1)print(sum(not re.search(pat, i) for i in map(str, nums)))
B:硬币兑换 100?
【问题描述】
小蓝手中有 2023 种不同面值的硬币,这些硬币全部是新版硬币,其中第 i (1 ≤ i ≤ 2023) 种硬币的面值为 i ,数量也为 i 个。硬币兑换机可以进行硬币兑 换,兑换规则为:交给硬币兑换机两个新版硬币 coin1 和 coin2 ,硬币兑换机会 兑换成一个面值为 coin1 + coin2 的旧版硬币。
小蓝可以用自己已有的硬币进行任意次数兑换,假设最终小蓝手中有 K 种不同面值的硬币(只看面值,不看新旧)并且第 i (1 ≤ i ≤ K) 种硬币的个数为 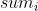 。小蓝想要使得
。小蓝想要使得 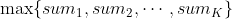 的值达到最大,请你帮他计算 这个值最大是多少。
的值达到最大,请你帮他计算 这个值最大是多少。
注意硬币兑换机只接受新版硬币进行兑换,并且兑换出的硬币全部是旧版硬币。
【解析及代码】
第一种思路是,根据面值 2023 的硬币数最多,直接尽可能地兑换面值 2023 的旧硬币,总数为: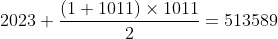
上述方法在兑换时使用的最大面值为 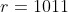 (因为用 1011 和 1012 凑成 2023 时,数量取决于 1011,所以不考虑 1012),最优的凑法是凑成面值 2023 (= 1011 × 2 + 1) 的旧硬币
(因为用 1011 和 1012 凑成 2023 时,数量取决于 1011,所以不考虑 1012),最优的凑法是凑成面值 2023 (= 1011 × 2 + 1) 的旧硬币
第二种思路是, 枚举用于兑换的新硬币最大面值 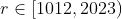 ,并兑换面值为
,并兑换面值为 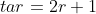 的旧硬币,此时用于兑换的新硬币的最小面值为
的旧硬币,此时用于兑换的新硬币的最小面值为 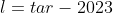
对于每一组 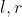 ,可以兑换面值为
,可以兑换面值为 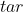 的旧硬币的个数为
的旧硬币的个数为 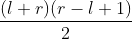 ,不难推导出这是个关于 r 的二次函数,也就是其有极大值
,不难推导出这是个关于 r 的二次函数,也就是其有极大值
枚举 r 并进行求解,最大值为:682425
ans = 0for r in range(1012, 2023): # 目标面值 tar = r * 2 + 1 l = tar - 2023 tmp = (l + r) * (r - l + 1) // 2 # 无更优时退出 if tmp < ans: break ans = tmp print(l, r, tmp)print(ans)
C:松散子序列 91?
【问题描述】
给定一个仅含小写字母的字符串 s ,假设 s 的一个子序列 t 的第 i 个字符 对应了原字符串中的第 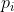 个字符。我们定义 s 的一个松散子序列为:对于 i > 1 总是有
个字符。我们定义 s 的一个松散子序列为:对于 i > 1 总是有 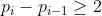 。设一个子序列的价值为其包含的每个字符的价值之和 (a ∼ z 分别为 1 ∼ 26) 。
。设一个子序列的价值为其包含的每个字符的价值之和 (a ∼ z 分别为 1 ∼ 26) 。
求 s 的松散子序列中的最大价值。
【输入格式】
输入一行包含一个字符串 s 。
【输出格式】
输出一行包含一个整数表示答案。
【样例】
| 输入 | 输出 |
| azaazaz | 78 |
【评测用例规模与约定】
| 20% | 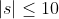 |
| 40% | 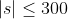 |
| 70% | 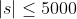 |
| 100% | 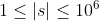 ,字符串中仅包含小写字母 ,字符串中仅包含小写字母 |
【解析及代码】
先利用 ord 函数,将小写字母转化为 1 ~ 26 的值,记为 value
创建一维列表 dp,以 dp[i] 表示第 i 个字符 (索引从 1 开始) 被包含时,松散子序列的最大价值
然后以 value = [1, 26, 1, 1, 1, 26, 1, 26] 为例:
当第 6 个字符 (第 2 个 26) 被包含时,因为松散子序列的定义有 dp[6] = max(dp[:5]) + 26然后又因为题目要求的是价值最大的松散子序列,所以被包含的字符之间的空隔不超过 2,此时可以进一步减少计算量,有 dp[6] = max(dp[3: 5]) + 26value = list(map(lambda s: ord(s) - 96, input()))# dp[i] 表示第 i 个字符被采用时的最高分数dp = [0] * (len(value) + 1)dp[1] = value[0]for i, v in zip(range(2, len(value) + 1), value[1:]): # 找到最优的前置状态: 最优松散子序列中各个数的间隔不超过 2 dp[i] = max(dp[max((0, i - 3)): i - 1]) + v# 最后两个数必有一个被包含print(max(dp[-2:]))
D:管道 36?
【问题描述】
有一根长度为 len 的横向的管道,该管道按照单位长度分为 len 段,每一段的中央有一个可开关的阀门和一个检测水流的传感器。
一开始管道是空的,位于 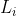 的阀门会在
的阀门会在 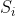 时刻打开,并不断让水流入管道。
时刻打开,并不断让水流入管道。
对于位于 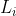 的阀门,它流入的水在
的阀门,它流入的水在 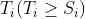 时刻会使得从第
时刻会使得从第 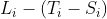 段到第
段到第 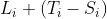 段的传感器检测到水流。
段的传感器检测到水流。
求管道中每一段中间的传感器都检测到有水流的最早时间。
【输入格式】
输入的第一行包含两个整数 n, len,用一个空格分隔,分别表示会打开的阀门数和管道长度。
接下来 n 行每行包含两个整数 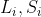 ,用一个空格分隔,表示位于第
,用一个空格分隔,表示位于第 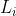 段管道中央的阀门会在
段管道中央的阀门会在 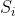 时刻打开。
时刻打开。
【输出格式】
输出一行包含一个整数表示答案。
【样例】
| 输入 | 输出 |
| 3 10 1 1 6 5 10 2 | 5 |
【评测用例规模与约定】
| 30% | 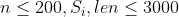 |
| 70% | 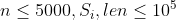 |
| 100% | 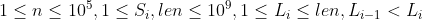 |
【解析及代码】
看不懂为什么会运行错误 ……
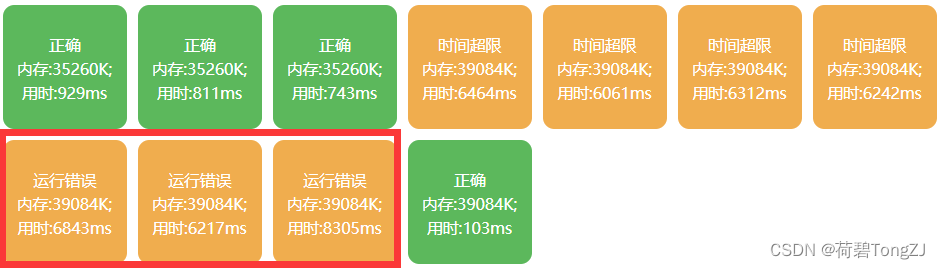
没有什么好的想法,直接暴力
n, length = map(int, input().split())# 经过的时间 = 扩散的长度cost = [float('inf')] * lengthfor _ in range(n): l, s = map(int, input().split()) l -= 1 for i in range(length): cost[i] = min((cost[i], abs(i - l) + s))print(max(cost))
E:保险箱
【问题描述】
小蓝有一个保险箱,保险箱上共有 n 位数字。
小蓝可以任意调整保险箱上的每个数字,每一次操作可以将其中一位增加 1 或减少 1。
当某位原本为 9 或 0 时可能会向前(左边)进位/退位,当最高位(左边第 一位)上的数字变化时向前的进位或退位忽略。
例如:
00000 的第 5 位减 1 变为 99999 ;
99999 的第 5 位减 1 变为 99998 ;
00000 的第 4 位减 1 变为 99990 ;
97993 的第 4 位加 1 变为 98003 ;
99909 的第 3 位加 1 变为 00009 。
保险箱上一开始有一个数字 x,小蓝希望把它变成 y,这样才能打开它,问小蓝最少需要操作的次数。
【输入格式】
输入的第一行包含一个整数 n 。
第二行包含一个 n 位整数 x 。
第三行包含一个 n 位整数 y 。
【输出格式】
输出一行包含一个整数表示答案。
【样例】
| 输入 | 输出 |
| 5 12349 54321 | 11 |
【评测用例规模与约定】
| 30% | 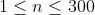 |
| 60% | 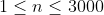 |
| 100% | 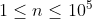 ,x,y 中仅包含数字 0 至 9,可能有前导零 ,x,y 中仅包含数字 0 至 9,可能有前导零 |
【解析及代码】
F:树上选点 5?
【问题描述】
给定一棵树,树根为 1,每个点的点权为 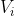 。
。
你需要找出若干个点 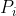 ,使得:
,使得:
1. 每两个点 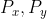 互不相邻;
互不相邻;
2. 每两个点 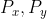 与树根的距离互不相同;
与树根的距离互不相同;
3. 找出的点的点权之和尽可能大。
请输出找到的这些点的点权和的最大值。
【输入格式】
输入的第一行包含一个整数 n 。
第二行包含 n − 1 个整数 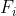 ,相邻整数之间使用一个空格分隔,分别表示第 2 至 n 个结点的父结点编号。
,相邻整数之间使用一个空格分隔,分别表示第 2 至 n 个结点的父结点编号。
第三行包含 n 个整数 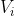 ,相邻整数之间使用一个空格分隔,分别表示每个结点的点权。
,相邻整数之间使用一个空格分隔,分别表示每个结点的点权。
【输出格式】
输出一行包含一个整数表示答案。
【样例】
| 输入 | 输出 |
| 5 1 2 3 2 2 1 9 3 5 | 11 |
【评测用例规模与约定】
| 40% | 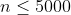 |
| 100% | 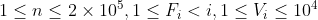 |
【解析及代码】
编写继承 list 的类 Node,用于存储子结点的序号,并用实例变量 v 记录点权
从根结点出发,搜索并得到各个结点的深度 (即与树根的距离),并根据深度添加到字典 depths
然后在枚举时利用 depths 来使得结点 i 和结点 j 的深度不同,并进一步利用 Node 类判断是否相邻
import itertools as itclass Node(list): def __init__(self, v): super().__init__() self.v = vn = int(input())father = list(map(lambda x: int(x) - 1, input().split()))nodes = list(map(Node, map(int, input().split())))# 添加子结点for i, dad in zip(range(1, n + 1), father): nodes[dad].append(i)# 各个深度的结点的字典depths = {}# 使用栈消除递归: 结点序号, 结点深度stack = [(0, 0)]while stack: i, depth = stack.pop() depths.setdefault(depth, []).append(i) # 子结点入栈 for j in nodes[i]: stack.append((j, depth + 1))ret = 0for d in depths: # 保证结点 i 和结点 j 的深度不同 for i in depths[d]: for j in it.chain(*(depths[d_] for d_ in depths if d_ != d)): # 判断结点是否相邻 if i not in nodes[j] and j not in nodes[i]: ret = max((ret, nodes[i].v + nodes[j].v))print(ret)
G:T 字消除
【问题描述】
小蓝正在玩一款游戏,游戏中有一个 n × n 大小的 01 矩阵 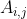 。
。
小蓝每次需要选择一个 T 字型的区域,且这个区域内至少要有一个 1 。选 中后,这个区域内所有的元素都会变成 0 。
给定游戏目前的矩阵,小蓝想知道他最多可以进行多少次上述操作。
T 字型区域是指形如 (x − 1, y) (x, y) (x + 1, y) (x, y + 1) 的四个点所形成的区域。其旋转 90, 180, 270 度的形式同样也视作 T 字形区域。
【输入格式】
输入包含多组数据。
输入的第一行包含一个整数 D 表示数据组数。
对于每组数据,第一行包含一个整数 n 。
接下来 n 行每行包含 n 个 0 或 1,表示矩阵 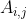 的每个位置的值。
的每个位置的值。
【输出格式】
输出 D 行,每行包含一个整数表示小蓝最多可以对当前询问中的矩阵操作的次数。
【样例】
| 输入 | 输出 | 说明 |
| 1 3 001 011 111 | 5 | 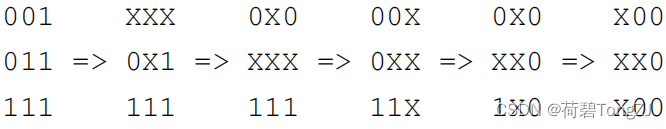 |
【评测用例规模与约定】
| 10% |  |
| 40% | 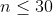 |
| 100% | 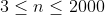 |
【解析及代码】
H:独一无二
【问题描述】
有一个包含 n 个点,m 条边的无向图,第 i 条边的边权为 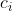 ,没有重边和自环。设
,没有重边和自环。设 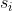 表示从结点 1 出发到达结点 i 的最短路的不同路径数 (i ∈ [1, n]), 显然可以通过删除若干条边使得
表示从结点 1 出发到达结点 i 的最短路的不同路径数 (i ∈ [1, n]), 显然可以通过删除若干条边使得 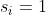 ,也就是有且仅有一条从 1 到 i 的最短 路,且保持最短路的路径长度不变,对于每个 i ,求出删除边数的最小值。
,也就是有且仅有一条从 1 到 i 的最短 路,且保持最短路的路径长度不变,对于每个 i ,求出删除边数的最小值。
【输入格式】
输入的第一行包含两个正整数 n, m。 接下来 m 行,每行包含三个正整数 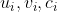 表示第 i 条边连接的两个点的编号和边权。
表示第 i 条边连接的两个点的编号和边权。
【输出格式】
输出 n 行,第 i 行包含一个正整数表示对于结点 i ,删除边数的最小值,如果 1 和 i 不连通,输出 −1 。
【样例】
| 输入 | 输出 | 说明 |
| 4 4 1 2 1 1 3 2 2 4 2 3 4 1 | 0 0 0 1 | 在给定的图中,只有 因为有两条最短路:1 → 2 → 4, 1 → 3 → 4, 任意删掉一条边后,就可以只剩一条最短路。 |
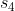 一开始为 2,
一开始为 2,【评测用例规模与约定】
| 30% | 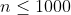 |
| 100% |  |
【解析及代码】
I:异或和 28?
【问题描述】
给一棵含有 n 个结点的有根树,根结点为 1 ,编号为 i 的点有点权 ![a_i (i \in [1, n])](http://zhangshiyu.com/zb_users/upload/2023/04/20230426142914168249055462697.gif) 。现在有两种操作,格式如下:
。现在有两种操作,格式如下:
现有长度为 m 的操作序列,请对于每个第二类操作给出正确的结果。
【输入格式】
输入的第一行包含两个正整数 n, m ,用一个空格分隔。
第二行包含 n 个整数 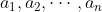 ,相邻整数之间使用一个空格分隔。
,相邻整数之间使用一个空格分隔。
接下来 n − 1 行,每行包含两个正整数 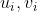 ,表示结点
,表示结点 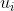 和
和 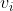 之间有一条边。
之间有一条边。
接下来 m 行,每行包含一个操作。
【输出格式】
输出若干行,每行对应一个查询操作的答案。
【样例】
| 输入 | 输出 |
| 4 4 1 2 3 4 1 2 1 3 2 4 2 1 1 1 0 2 1 2 2 | 4 5 6 |
【评测用例规模与约定】
| 30% | 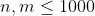 |
| 100% | 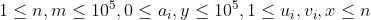 |
【解析及代码】
先看看异或这个操作的特性,比如 7(111) ^ 4(100) = 3(011),3(011) ^ 7(111) = 4(100)
所以,对于一个数组的异或和,如果其中的某一个数值被改变,异或上原来的数值、新的数值即可得到新的异或和
利用这个技巧,可以在初始化的时候预计算所有子树的异或和,并在每次更新点权时更新所有父结点的异或和
定义 Node 类,以存储树结点的信息,并进行异或和的计算:
search:因为题目给定的是“边”,所以只能知道每个树结点与哪个结点相连,而不知道父结点;从根结点开始搜索,利用这个函数可以找到所有树结点的父结点,并预计算异或和update:递归函数,给当前结点、所有父结点的异或和异或上参数 vchange:调用 update 函数修改异或和,并修改当前结点的 vclass Node: def __init__(self, info): super().__init__() # 父结点, 子结点 self.dad = None self.vex = set() # 索引, 价值, 子树异或和 self.i, self.v = info self.sum = self.v def search(self, dad): # 设置父结点 self.dad = dad self.vex.remove(dad) # 计算子树异或和 for child in self.vex: self.sum ^= nodes[child].search(self.i) delattr(self, 'vex') return self.sum def change(self, v): self.update(v ^ self.v) self.v = v def update(self, v): self.sum ^= v if self.dad >= 0: nodes[self.dad].update(v)n, m = map(int, input().split())nodes = list(map(Node, enumerate(map(int, input().split()))))# 添加父结点、子结点for _ in range(n - 1): u, v = map(lambda x: int(x) - 1, input().split()) nodes[u].vex.add(v) nodes[v].vex.add(u)# 查找父结点, 计算异或和nodes[0].vex.add(-1)nodes[0].search(-1)# 开始若干次操作for _ in range(m): oper, *args = map(int, input().split()) if oper == 1: x, y = args nodes[x - 1].change(y) else: print(nodes[args[0] - 1].sum)
J:混乱的数组 37?
【问题描述】
给定一个正整数 x,请找出一个尽可能短的仅含正整数的数组 A 使得 A 中 恰好有 x 对 i, j 满足 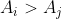 。 如果存在多个这样的数组,请输出字典序最小的那个。
。 如果存在多个这样的数组,请输出字典序最小的那个。
【输入格式】
输入一行包含一个整数表示 x 。
【输出格式】
输出两行。
第一行包含一个整数 n ,表示所求出的数组长度。
第二行包含 n 个整数 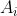 ,相邻整数之间使用一个空格分隔,依次表示数组中的每个数。
,相邻整数之间使用一个空格分隔,依次表示数组中的每个数。
【样例】
| 输入 | 输出 |
| 3 | 3 3 2 1 |
【评测用例规模与约定】
| 30% | 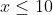 |
| 60% | 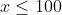 |
| 100% | 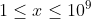 |
【解析及代码】
这道题的测试结果是“答案错误”,如果大家有正确的思路欢迎留言,我先讲讲我的
题目不是很完整的样子,需要我们自行推导一下附加条件
根据样例可知,[3 2 1] 包含 3 对 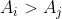 ,而且
,而且 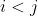
显然可得,长度为 n、元素从 n 到 1 的正整数数组可以提供的“对”数为: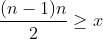
那么可解得 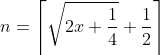 ,对于 x = 11,该数组就为 [6 5 4 3 2 1]
,对于 x = 11,该数组就为 [6 5 4 3 2 1]
上述数组实际提供的“对”数为 15,溢出的 4 对可以通过减小数组的值抹去
根据题目要求的“字典序最小”,所以应该减小数组的第一个数值,得 [2 5 4 3 2 1]
([2 5 4 3 2 1] 变换成 [2 4 3 2 1 1] 的思路还不是很完善,先留空)
import mathx = int(input())# (n - 0.5) ^ 2 = 2x + 0.25n = math.ceil(math.sqrt(2 * x + 0.25) + 0.5)array = list(range(n, 0, -1))cur = (n - 1) * n // 2# 除去溢出的 "对"array[0] -= cur - x# 等价变换if n >= 2 and array[0] <= array[1]: for i in range(1, n - 1): array[i] -= 1print(n)print(*array)