欢迎来到 Claffic 的博客 ???

“春风里,是谁 花一样烂漫?”
前言:
二叉树给大家讲解的差不多了,接下来就是二叉树的实际应用了:这期我们来讲堆,它是一种顺序结构的特殊二叉树,可以实现排序等功能,那就让我们开始吧!
目录
?Part1: 何为堆
1.堆的概念
2.堆的结构
?Part2: 堆的实现
1.前期准备
1.1项目创建
1.2结构定义
1.3堆的初始化
2.相关功能实现
2.1堆插入数据
2.2堆删除数据
2.3数组建堆
2.4判断堆是否为空
2.5获取堆顶元素
2.6堆的销毁
?Part3: 堆的应用
3.1堆排序(排升序)
3.2 TOP-K问题
Part1: 何为堆
1.堆的概念
将元素按照完全二叉树的顺序存储方式存储在一个一维数组中,并满足对应根结点数值大于两个孩子结点(称为大堆)或者小于两个孩子结点(称为小堆)。
单看概念是不足以理解的,与结构结合理解会更好:
2.堆的结构
还记得上期的 逻辑结构 和 物理结构 吗?
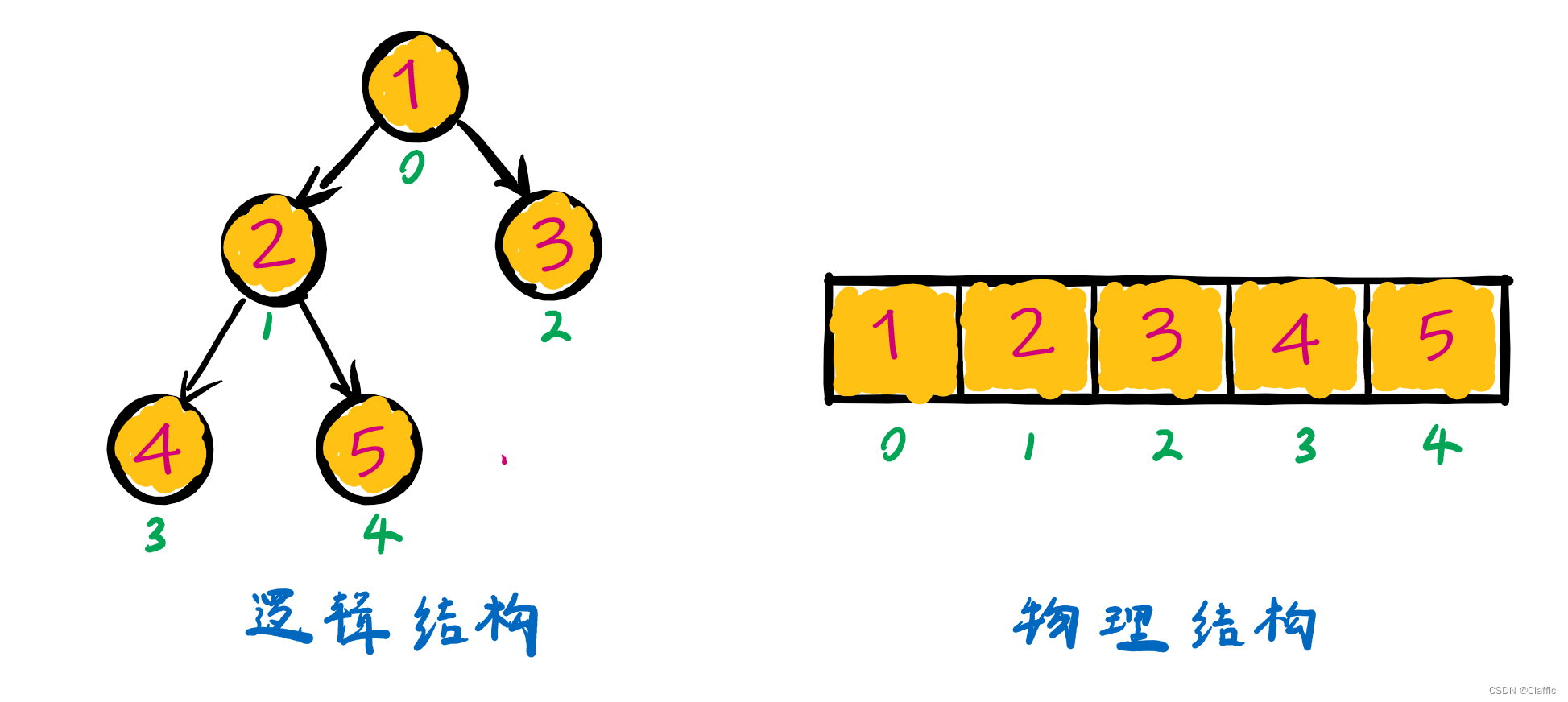
堆的逻辑结构是一颗 完全二叉树
堆的本质呢,是 数组 ,不过对数组中存储的数据顺序有着特殊的要求:
• 大堆:根节点数值大于两个孩子结点的数值;
• 小堆:根节点数值小于两个孩子结点的数值。
上例子:
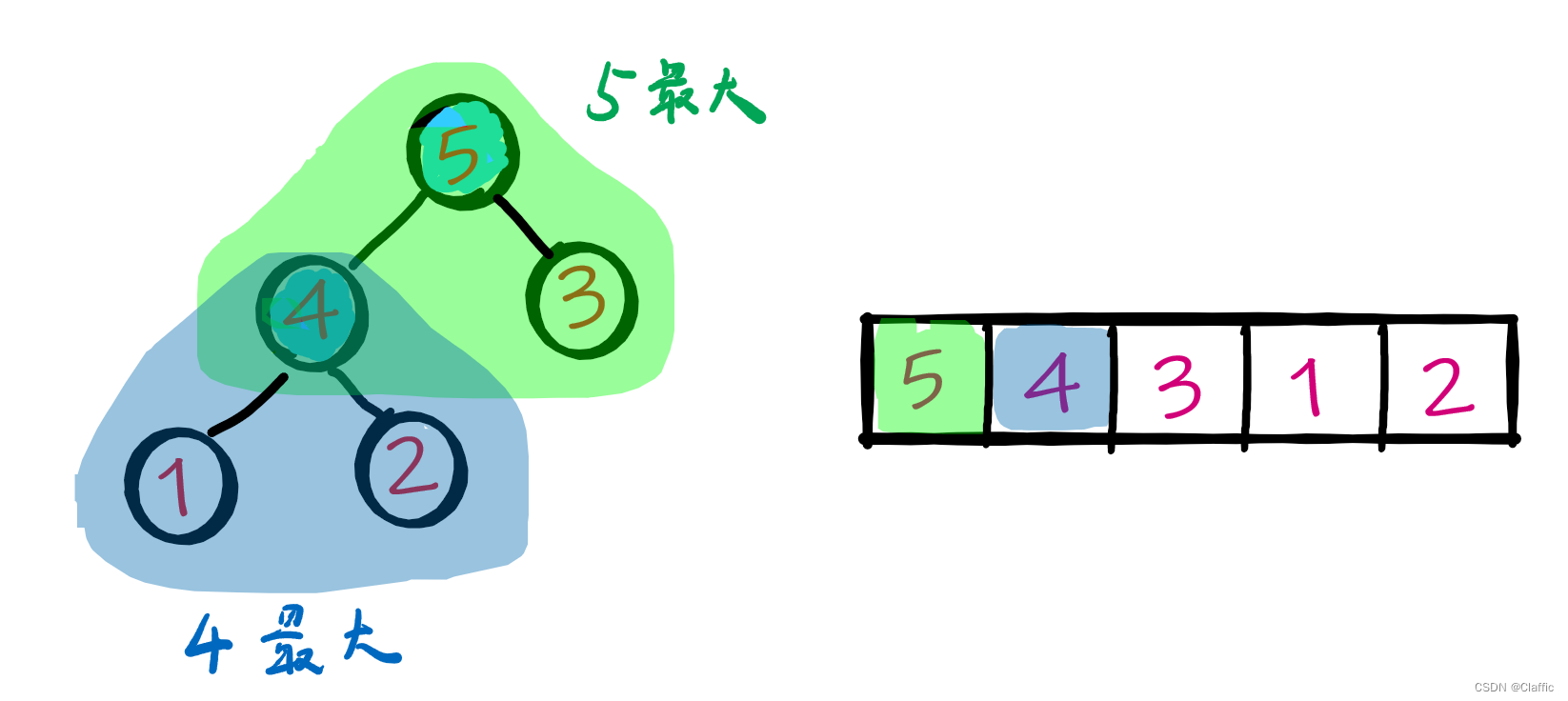
这是一个大堆
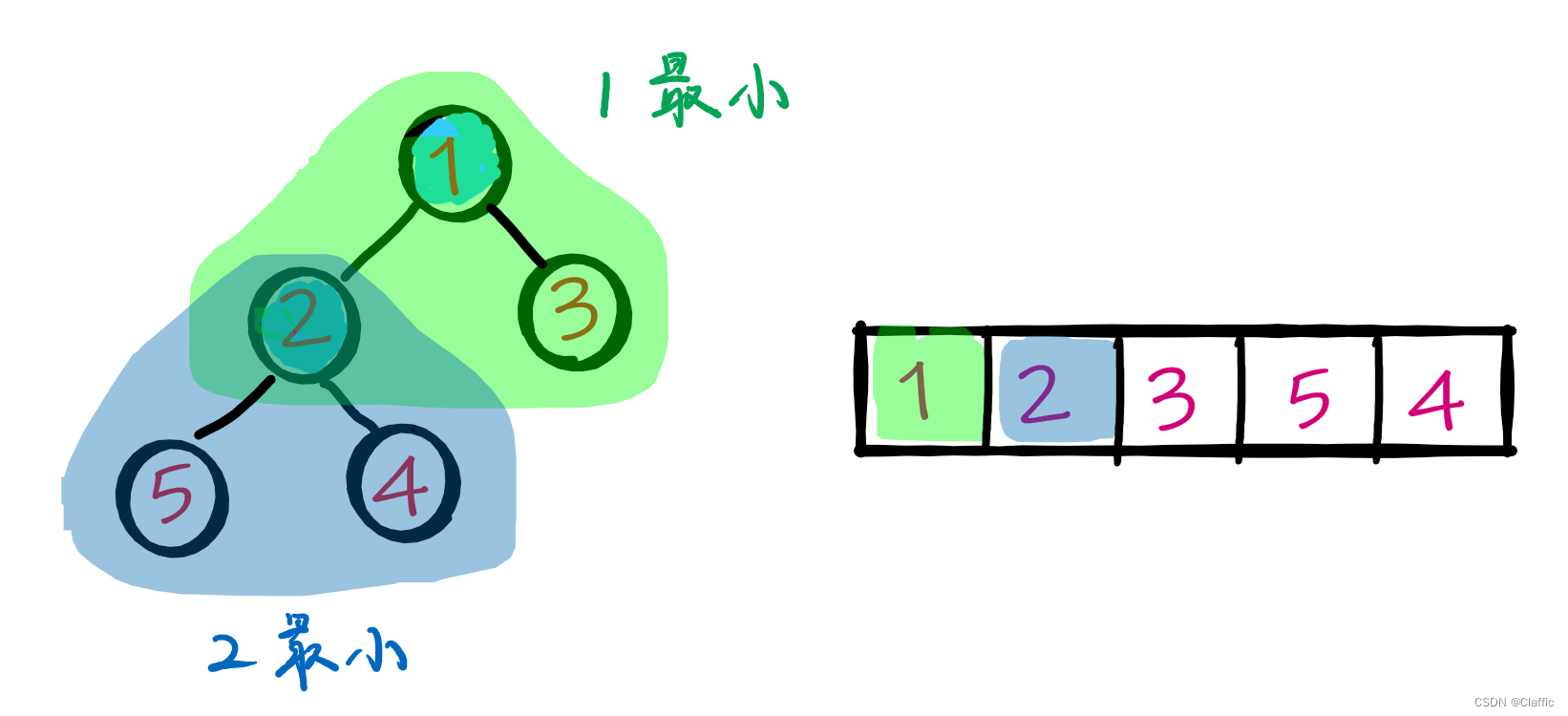
这是一个小堆
到这里,相信你已经知道什么是堆了。
记住堆的性质:
• 堆总是一颗完全二叉树
• 堆中某个结点的数值总是不大于或不小于双亲结点
Part2: 堆的实现
1.前期准备
1.1项目创建
Heap.h:头文件,声明所有函数;
Heap.c:源文件,实现各函数;
Test.c: 源文件,主函数所在项,可调用各函数。
1.2结构定义
堆的本质就是一个数组嘛,
默认整型数组,为方便相关操作的实现,再定义大小size和容量capacity:
typedef int HPDataType;typedef struct Heap{HPDataType* a;int size;int capacity;}HP;1.3堆的初始化
这里选择动态开辟内存,
初始容量为4个整型大小:
//堆的初始化void HeapInit(HP* php){assert(php);php->a = (HPDataType*)malloc(sizeof(HPDataType)*4);if (php->a == NULL){perror("malloc fail");return;}php->capacity = 4;php->size = 0;}2.相关功能实现
注意:我们这里默认实现大堆
2.1堆插入数据
插入数据前,要先判断下有没有满,定义容量和大小的好处就在这里,
直接通过 容量和大小是否相等 就可以,
如果满,默认扩展至先前容量的两倍;
if (php->size == php->capacity){HPDataType* tmp = (HPDataType*)realloc(php->a,sizeof(HPDataType) * php->capacity*2);if (tmp == NULL){perror("realloc fail");return;}php->a = tmp;php->capacity *= 2;}php->a[php->size] = x;php->size++;接下来就是对插入的数据进行调整了,
要注意:插入之前就是大堆或小堆(默认大堆),
我们需要做的就是将插在末尾的数据通过比较交换,使其在最合适的位置
这里用到的是 向上调整 :
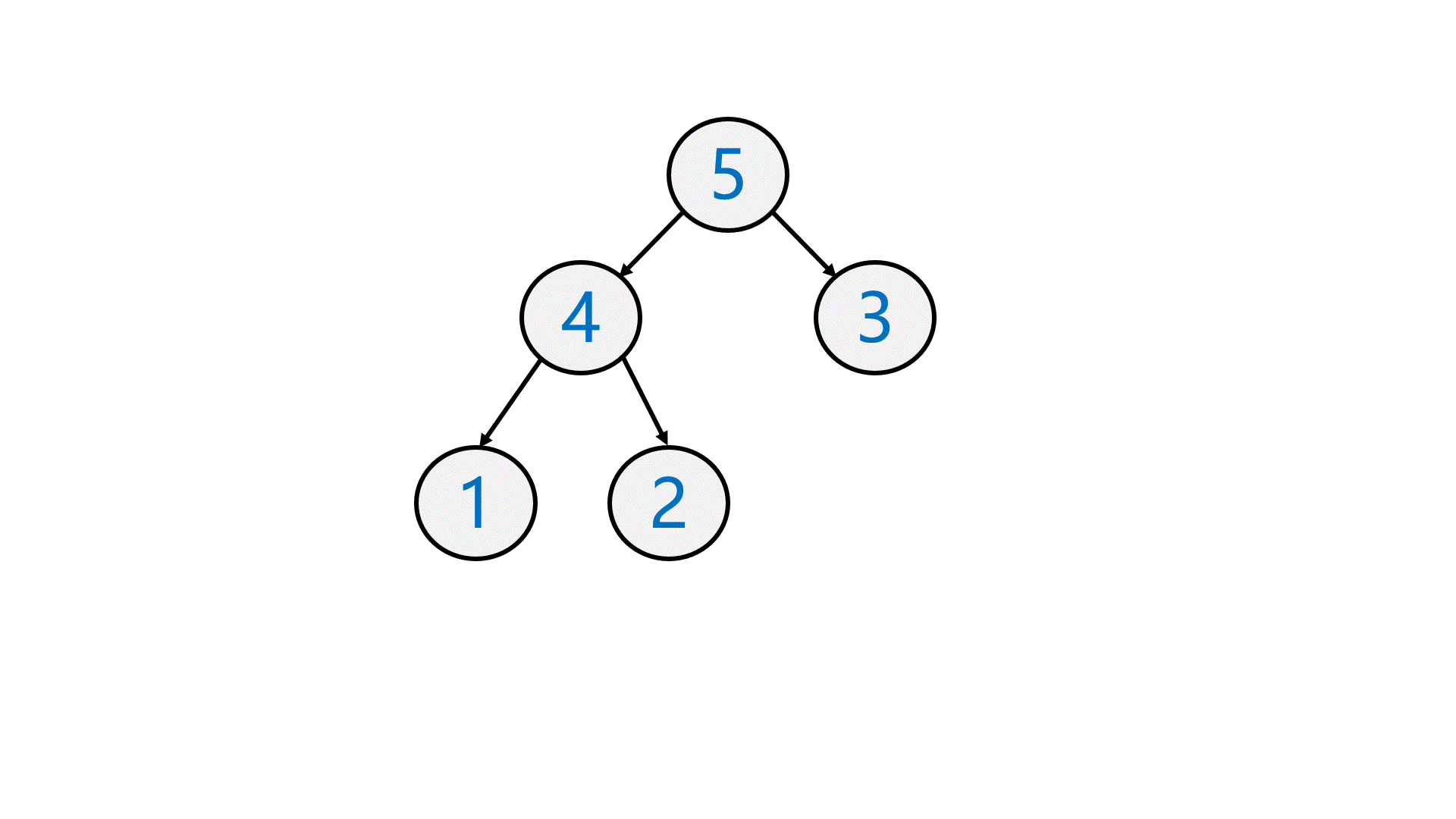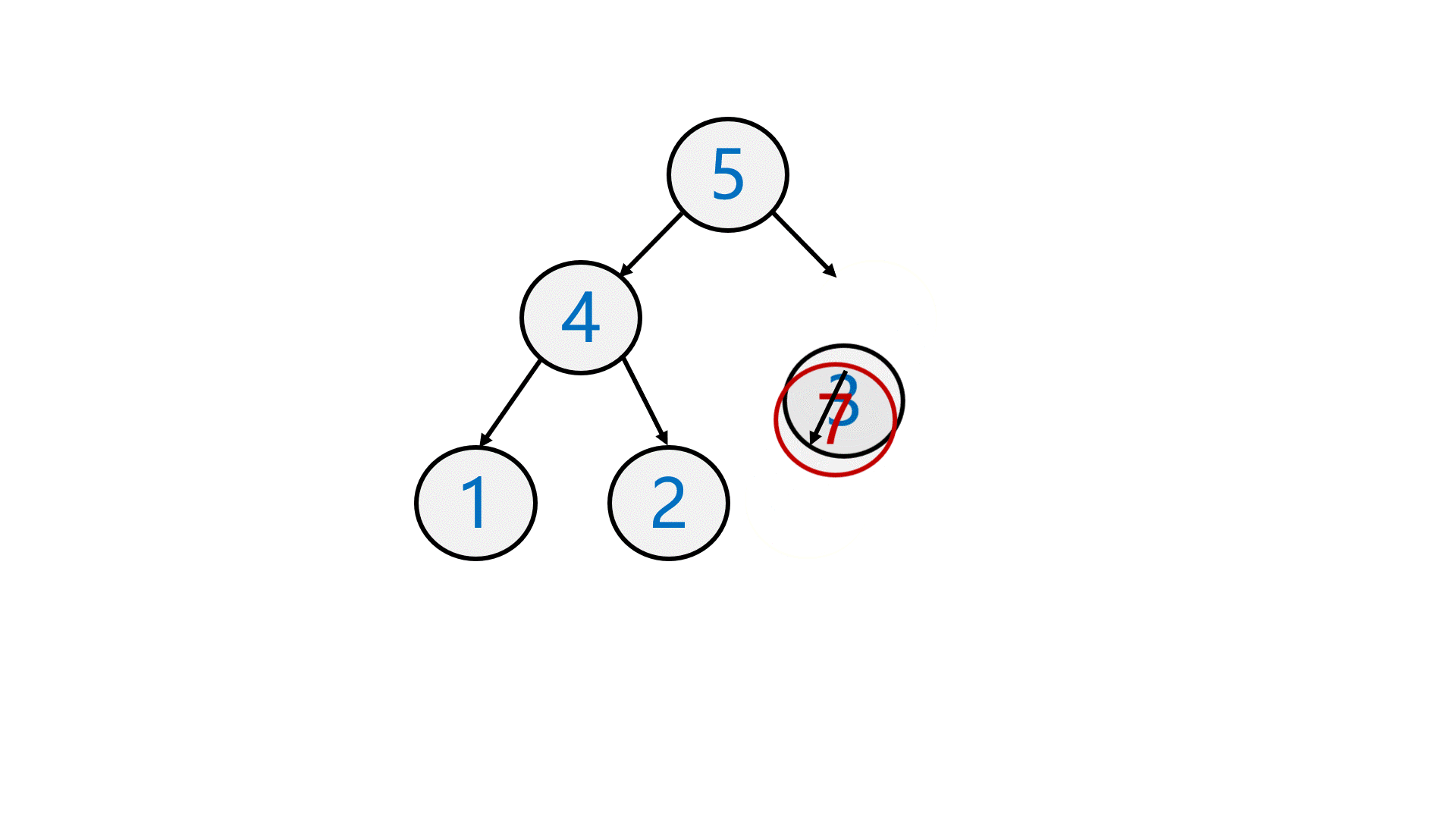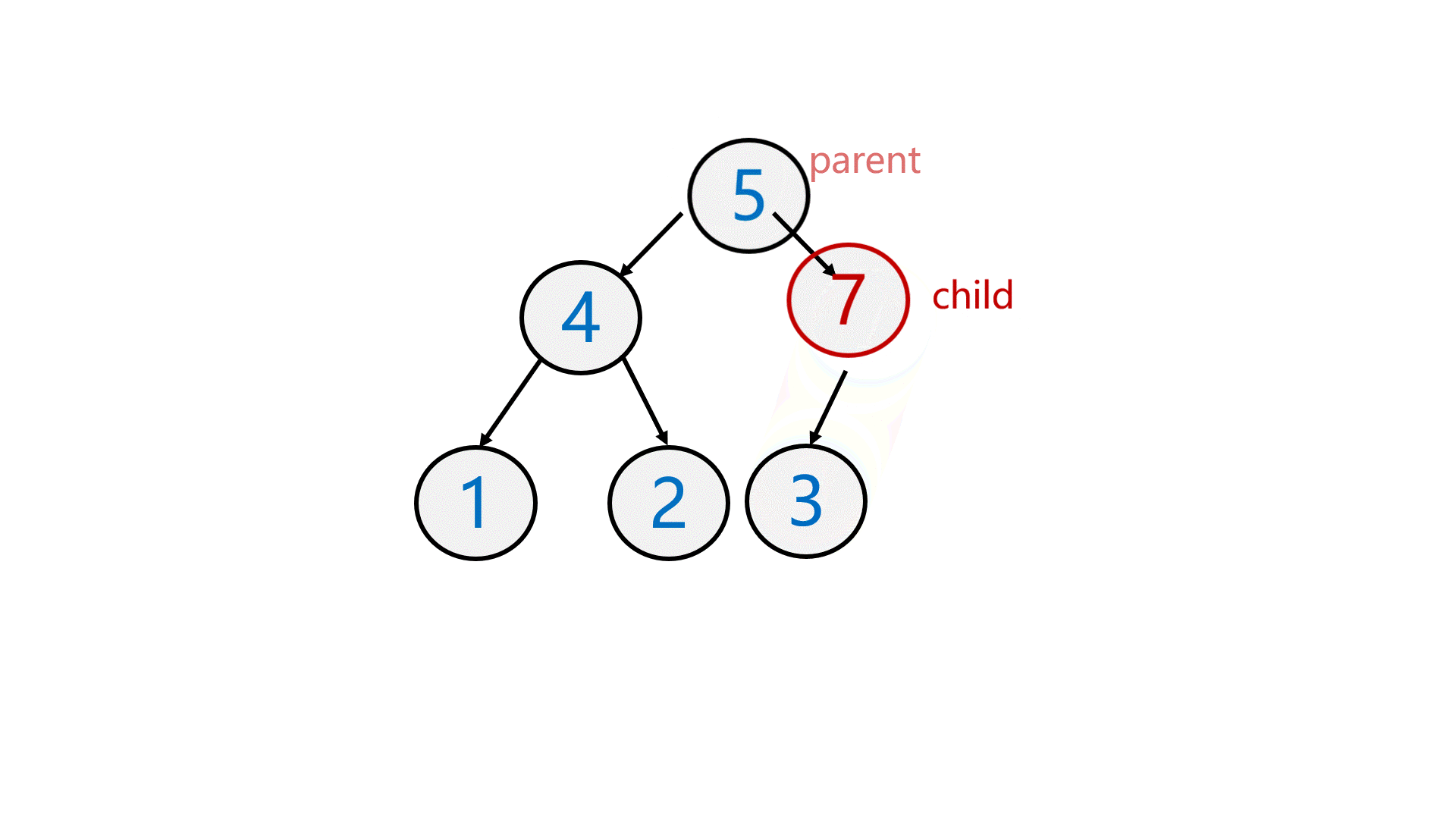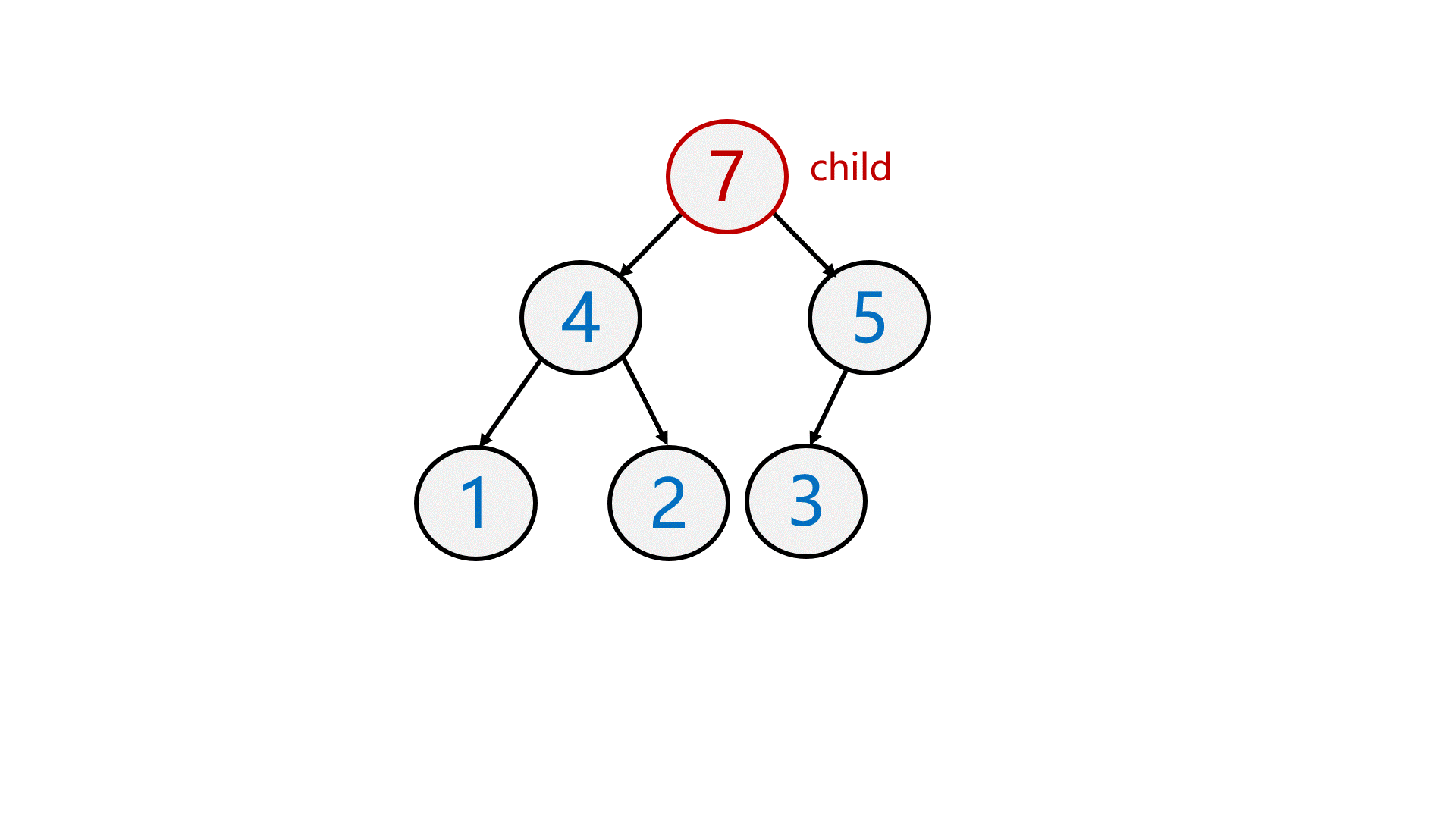
第一次做这种动图???
如图所示,在数组末尾插入数据后,需要跟双亲结点比较,再决定是否向上调整。
//向上调整void AdjustUp(HPDataType* a, int child){int parent = (child - 1) / 2;while (child > 0){if (a[parent] < a[child]){Swap(&a[parent], &a[child]);child = parent;parent = (child - 1) / 2;}elsebreak;}}所以最终代码:
//堆插入数据 向上调整 插入之前就是堆void HeapPush(HP* php, HPDataType x){assert(php);if (php->size == php->capacity){HPDataType* tmp = (HPDataType*)realloc(php->a,sizeof(HPDataType) * php->capacity*2);if (tmp == NULL){perror("realloc fail");return;}php->a = tmp;php->capacity *= 2;}php->a[php->size] = x;php->size++;AdjustUp(php->a, php->size - 1);}2.2堆删除数据
大堆删除数据,是指删除 最大根节点 。
那么怎样才能保证删除第一个数据之后,剩余的结点的双亲结点与孩子结点关系不乱呢?
这里有一个巧妙的办法:
先将第一个结点与最后一个结点 交换 ,再 删除 最后一个结点,最后 向下调整 。
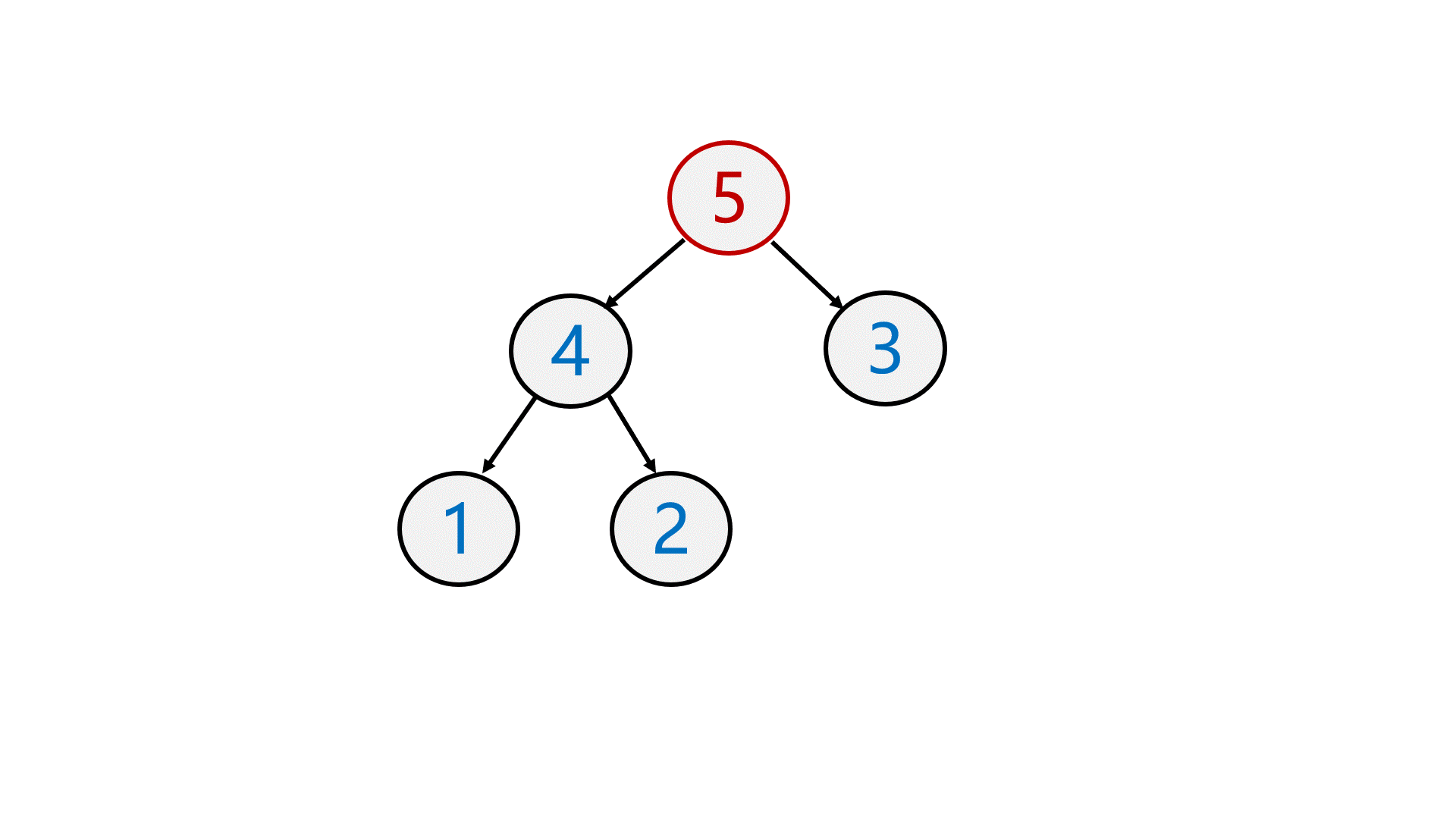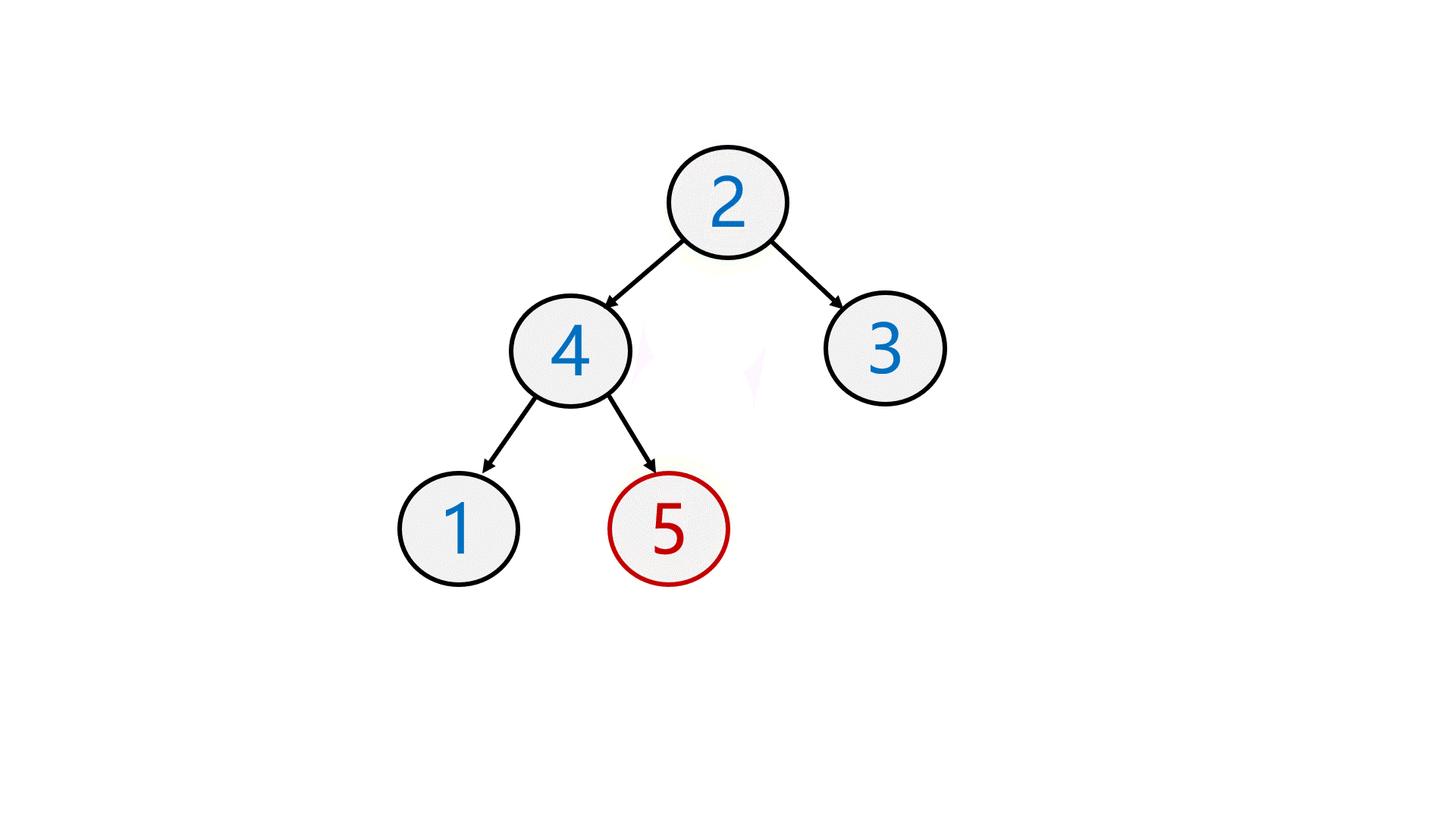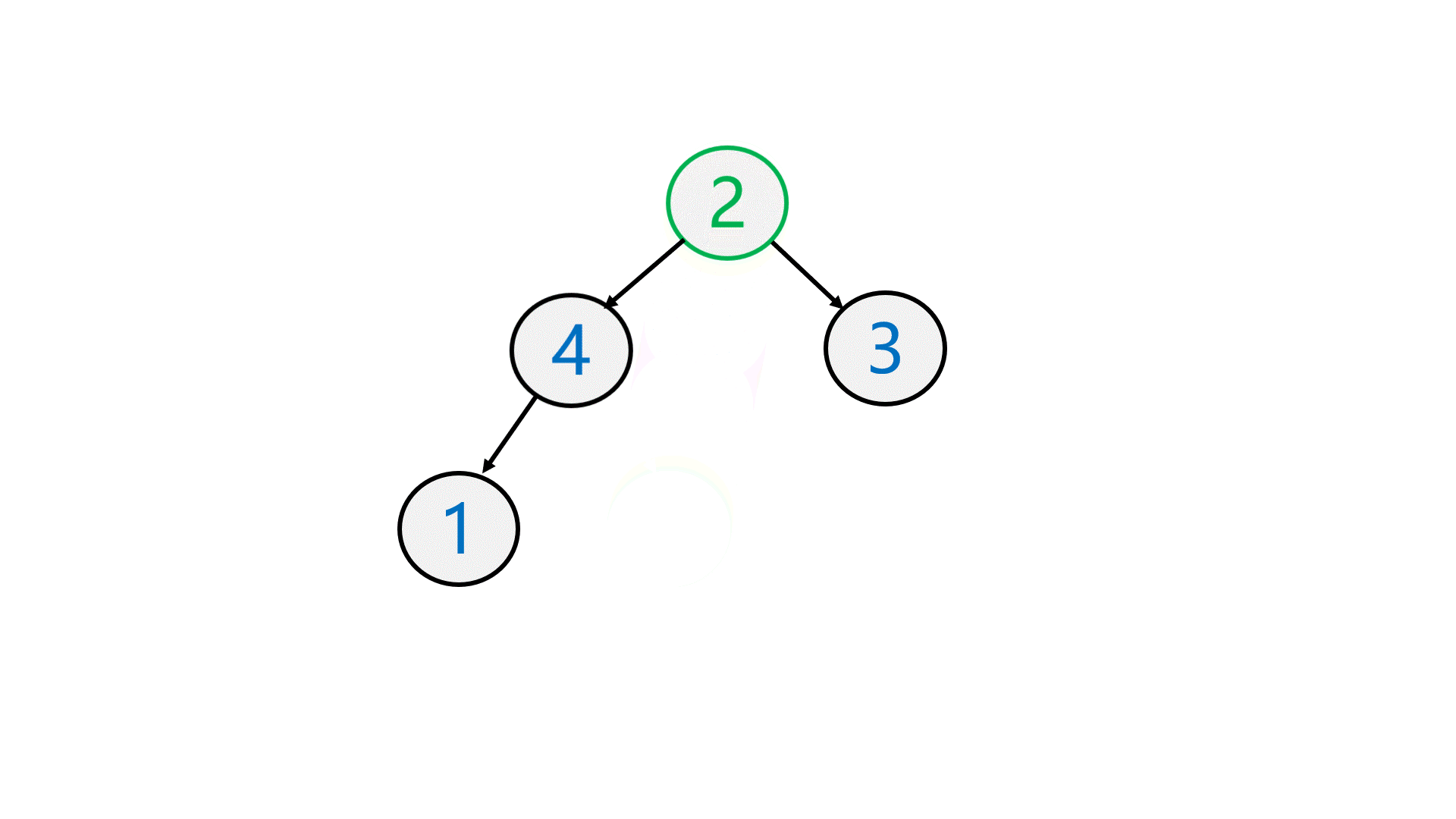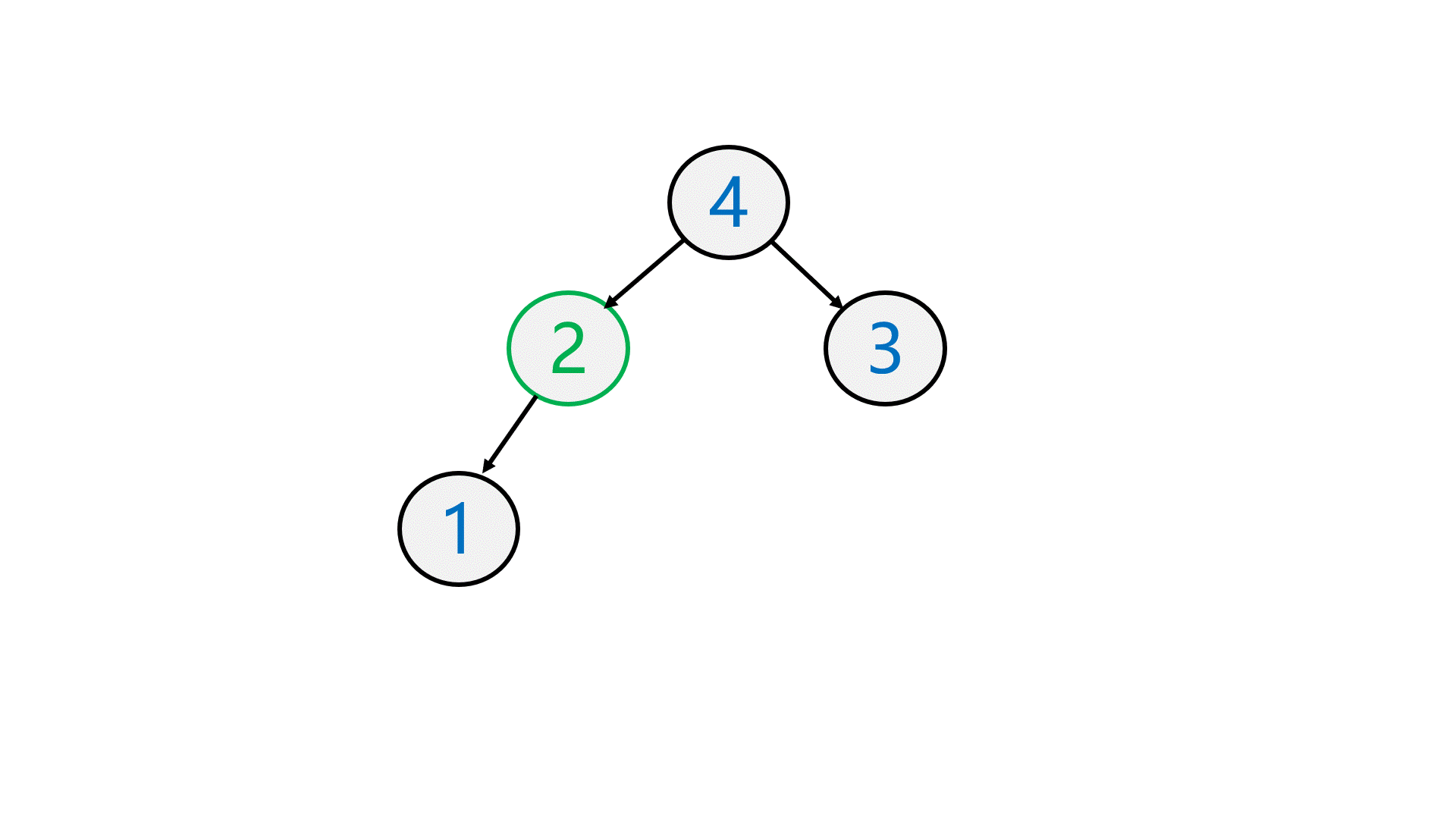
最后仍然保持是一个大堆
代码实现:
//堆删除数据 向下调整void HeapPop(HP* php){assert(php);assert(!HeapEmpty(php));Swap(&php->a[0], &php->a[php->size - 1]);php->size--;AdjustDown(php->a, php->size, 0);}//向下调整void AdjustDown(HPDataType* a, int n, int parent){int child = parent * 2 + 1;while (child < n){ //先判断child,防止越界,挑出较大的孩子结点if (child < n + 1 && a[child + 1] < a[child]){child++;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}2.3数组建堆
任意给一个数组,可不能保证它就是堆,
所以要利用数组来建堆,也叫用数组初始化堆。
前半部分的空间开辟不必多讲,重点放在建堆(默认建大堆)上:
方法一:向上调整
给一个数组,先从第一个数开始,逐渐扩大区间,每扩大一次就进行一次向上调整;
其实就是 模拟插入数值 罢了。
//建堆(默认建大堆),向上调整for (int i = 1; i < n; i++){AdjustUp(a, i);}方法二:向下调整
这种方法是从倒数第二层数组开始调整,依次向下调整。
//建堆,向下调整for (int i = (n - 2) / 2; i >= 0; i--){AdjustDown(a, n, i);}两种方法对比:
这里先告诉大家结论:
向下调整建堆(时间复杂度为:O(N))要优于向上调整建堆(时间复杂度为:O(N*logN))
准确计算方式:其实就是每层的结点个数乘以要向下/向上调整的层数,最后求和,比较下即可。
简单理解:
向下调整:结点多的调整次数少,结点少的调整次数多;
向上调整:结点少的调整次数少,结点多的调整次数多;
就这个描述,向下调整更平衡一些,在这种粗略理解下,向下调整优于向上调整。
2.4判断堆是否为空
直接判断大小是否为0即可。
//判空bool HeapEmpty(HP* php){assert(php);return php->size == 0;}2.5获取堆顶元素
返回数组的第一个值即可。
//获取堆顶元素HPDataType HeapTop(HP* php){assert(php);return php->a[0];}2.6堆的销毁
将数组释放置空,容量和大小归零。
//堆的销毁void HeapDestroy(HP* php){assert(php);free(php->a);php->a = NULL;php->capacity = 0;php->size = 0;}Part3: 堆的应用
3.1堆排序(排升序)
给你一个数组,要进行堆排序,首先要把它 变成堆 ,
考虑下这个问题:排升序,建大堆还是小堆?
答案是 建大堆 ,
因为大堆的最大根节点就是整个堆中最大的,我们只需要将这个最大值调整到最后就可以了;
如果是小堆,我们不能保证两个孩子结点的大小关系,调整起来就比大堆麻烦。
再者就是优先选择 向下调整 ,效率较高。
//向下调整(效率更高)for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}建完大堆,接下来就是数据位置的调整了:
将最大根节点调整到最后,然后通过调整,保持剩余结点依然是一个大堆。
是不是感觉与删除操作有些相似?
是的,这可以理解为 模拟删除操作 ,只不过被删除的数还是要保留的。
最终代码:
//堆排序void HeapSort(int* a, int n){//向下调整(效率更高)for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end--){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);}}3.2 TOP-K问题
给一个情景:
在世界所有的企业中选出世界500强。
这就涉及到TOP-K问题,简单理解,TOP-K问题就是在N个数字中选出K个数字,保证这K个数字任何一个都比剩余N-K个数字大。
建堆是必须的,但建大堆还是小堆?
这里有一个巧妙的办法:
1.前K个数字先建成一个小堆;
2.遍历剩余N-K个数字,遇到比堆顶数字大的就替它进堆,再进行向下调整。
这种方法巧妙在 大数向下沉,小数向上浮。最后大数把小数挤出堆,堆里的都是大数。
为了创建大量数据,这里利用随机数,将数据存储在文件当中:
void PrintTopK(const char* file, int k){// 用a中前k个元素建小堆int* topk = (int*)malloc(sizeof(int) * k);assert(topk);FILE* fout = fopen(file, "r");if (fout == NULL){perror("fopen error");return;}for (int i = 0; i < k; ++i){fscanf(fout, "%d", &topk[i]);}for (int i = (k - 2) / 2; i >= 0; --i){AdjustDown(topk, k, i);}// 将剩余n-k个元素依次与堆顶元素交换,不满就替换int val = 0;int ret = fscanf(fout, "%d", &val);while (ret != EOF){if (val > topk[0]){topk[0] = val;AdjustDown(topk, k, 0);}ret = fscanf(fout, "%d", &val);}for (int i = 0; i < k; i++){printf("%d ", topk[i]);}printf("\n");free(topk);fclose(fout);}
代码已上传至 我的gitee
拿走不谢~
总结:
这期知识密度较大,不仅有堆的实现,还有两个堆的应用,建议先将堆实现一波,再进行两个应用问题的解决~~~
码文不易
如果你觉得这篇文章还不错并且对你有帮助,不妨支持一波哦 ???