目录
前言一、背景和改进思路二、细节原理和源码讲解2.1、多尺度特征2.1.1、backbone生成多尺度特征2.1.2、多尺度位置编码 2.2、多尺度可变形注意力2.2.1、普通多头注意力:MultiHeadAttn2.2.2、可变形多头注意力:DeformAttn2.2.3、多尺度可变形多头注意力:MSDeformAttn2.2.4、源码分析 2.3、Deformable DETR:简单版2.3.1、DeformableTransformer2.3.2、Encoder2.3.3、Decoder2.3.4、Deformable DETR 2.4、高配版2.4.1、iterative bounding box refinement2.4.2、two stage 三、总结3.1、Deformable DETR VS DETR3.2、one-stage全部流程3.2、one-stage + 框矫正策略全部流程3.3、two stage策略 + 框矫正策略全部流程3.4、两个策略的本质是什么? 四、几个问题思考4.1、 为什么MSDeformAttn中的attention weight不是transform里面那样key来与query交互计算,而是由query经过全连接层得到的?4.2、为什么检测头回归分支回归的是偏移量而非绝对坐标值?4.3、为什么普通版class_embed和bbox_embed是共享版的,而iterative bounding box refinement和two-stage的class_embed和bbox_embed是非共享的? 五、EndReference
前言
上一篇讲完了DETR相关原理和源码,打算继续再学习DETR相关改进。这次要解读的是21年发表的一篇论文: ICLR 2021:Deformable DETR: Deformable Transformers for End-to-End Object Detection 。
先感谢这位知乎大佬,讲的太细了: Deformable DETR: 基于稀疏空间采样的注意力机制,让DCN与Transformer一起玩!
这篇解读,代码deformable detr是根据detr的源码改进来的,所以想理解deformable detr必须要先读懂detr,如果对detr的源码不是很了解的,可以先看看我之前写的detr相关的源码解读:
【DETR 论文解读】End-to-End Object Detection with Transformer
【DETR源码解析】一、整体模型解析
【DETR源码解析】二、Backbone模块
【DETR源码解析】三、Transformer模块
【DETR源码解析】四、损失计算和后处理模块
detr源码:https://github.com/facebookresearch/detr
detr注释注释:https://github.com/HuKai97/detr-annotations
因为deformable detr源码整体框架和就是基于detr的源码改进来的,所以不会很完整的讲解,主要讲一下改进的部分和相关的源码。这篇源码细节真的超级多…
deformable detr源码:https://github.com/fundamentalvision/Deformable-DETR
deformable detr源码注释:https://github.com/HuKai97/deformable-detr-annotations
一、背景和改进思路
DETR优点:消除了anchor和nms(用集合的思想回归出200个query之后再用匈牙利算法二分图匹配的方式得到最终的正样本和负样本),第一个做到了真正的 end-to-end 。
缺点:
收敛慢:训练起来非常慢,至少要训练500个epoch,比faster rcnn慢十几倍(注意力模块初始化比较稀疏,需要很长时间去学习,收敛比较慢);计算量大:对小目标性能很不好,因为detr是没法使用高分辨率的图片的,计算量太大了(计算量和整个图像像素点个数呈平方关系,计算量很大),而且没有使用多尺度特征;DCN(Deformable Convolution Networks):在卷积当中引入了学习空间几何形变的能力,不再是使用常规的领域矩阵卷积,而是让卷积自动的去学习需要需要卷积的周围像素,以此可以适应更加复杂的几何形变任务。
作者这里将DCN和DETR相结合,DETR不是收敛慢和计算量大嘛,而且主要的原因是transformer模块带来的频繁计算(每个位置需要计算和其他所有位置的相似度,而且不像卷积那样共享参数),那么很朴素的想法就是:让每个位置不必和所有位置交互计算,只需要和部分(学习来的,重要的部分)进行交互即可。这个思想不正和DCN的思想不谋而合,所以作者提出Deformable Attention模块,并且将这个模块很方便的应用到多尺度特征上。
二、细节原理和源码讲解
2.1、多尺度特征
2.1.1、backbone生成多尺度特征
上节提到了作者提出的Deformable Attention模块,可以很方便的处理多尺度特征。于是Deformable DETR在backbone(ResNet50)部分会提取不同尺度的特征,总共会提取4层。如下图,前三层分别来自ResNet50的Layer2-4,下采样率分别为8、16、32,再分别接一个1x1卷积+GroupNorm,将特征统一降维到256。第三层来自Layer4,经过一个3x3卷积 + GroupNorm,得到下采样率为64、将维到256的特征。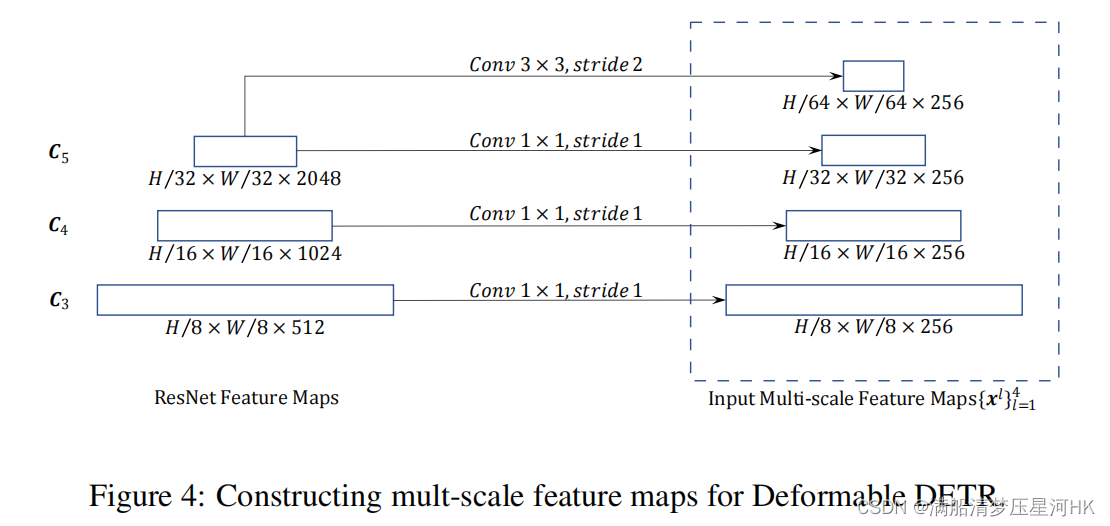
源码其实很简单,重新定义return_layers ,再调用torchvision.models._utils下的IntermediateLayerGetter函数抽取得到Layer2-4这三个不同尺度的输出特征图,代码backbone.py中:
class BackboneBase(nn.Module): def __init__(self, backbone: nn.Module, train_backbone: bool, return_interm_layers: bool): super().__init__() for name, parameter in backbone.named_parameters(): if not train_backbone or 'layer2' not in name and 'layer3' not in name and 'layer4' not in name: parameter.requires_grad_(False) if return_interm_layers: # return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"} return_layers = {"layer2": "0", "layer3": "1", "layer4": "2"} self.strides = [8, 16, 32] self.num_channels = [512, 1024, 2048] else: return_layers = {'layer4': "0"} self.strides = [32] self.num_channels = [2048] self.body = IntermediateLayerGetter(backbone, return_layers=return_layers) def forward(self, tensor_list: NestedTensor): # 输入特征图 [bs, C, H, W] -> 返回ResNet50中 layer2 layer3 layer4层的输出特征图 # 0 = [bs, 512, H/8, W/8] 1 = [bs, 1024, H/16, W/16] 2 = [bs, 2048, H/32, W/32] xs = self.body(tensor_list.tensors) out: Dict[str, NestedTensor] = {} for name, x in xs.items(): m = tensor_list.mask assert m is not None # 原图片mask下采样8、16、32倍 mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0] out[name] = NestedTensor(x, mask) # 3个不同尺度的输出特征和mask dict: 3 # 0: tensors[bs, 512, H/8, W/8] mask[bs, H/8, W/8] # 1: tensors[bs, 1024, H/16, W/16] mask[bs, H/16, W/16] # 3: tensors[bs, 2048, H/32, W/32] mask[bs, H/32, W/32] return out另外在deformable_detr.py中DeformableDETR类进一步使用这三个不同尺度的特征,分别接一个1x1conv + GroupNorm,再进一步Layer4接一个3x3conv + GroupNorm下采样,最后得到四个不同尺度的特征图:
class DeformableDETR(nn.Module): """ This is the Deformable DETR module that performs object detection """ def __init__(self, backbone, transformer, num_classes, num_queries, num_feature_levels, aux_loss=True, with_box_refine=False, two_stage=False): ... # 3个1x1conv + 1个3x3conv if num_feature_levels > 1: num_backbone_outs = len(backbone.strides) input_proj_list = [] for _ in range(num_backbone_outs): # 3个1x1conv in_channels = backbone.num_channels[_] # 512 1024 2048 input_proj_list.append(nn.Sequential( # conv1x1 -> 256 channel nn.Conv2d(in_channels, hidden_dim, kernel_size=1), nn.GroupNorm(32, hidden_dim), )) for _ in range(num_feature_levels - num_backbone_outs): # 1个3x3conv input_proj_list.append(nn.Sequential( nn.Conv2d(in_channels, hidden_dim, kernel_size=3, stride=2, padding=1), # 3x3conv s=2 -> 256channel nn.GroupNorm(32, hidden_dim), )) in_channels = hidden_dim self.input_proj = nn.ModuleList(input_proj_list) else: self.input_proj = nn.ModuleList([ nn.Sequential( nn.Conv2d(backbone.num_channels[0], hidden_dim, kernel_size=1), nn.GroupNorm(32, hidden_dim), )]) ... def forward(self, samples: NestedTensor): ... # 经过backbone resnet50 输出三个尺度的特征信息 features list:3 NestedTensor # 0 = mask[bs, W/8, H/8] tensors[bs, 512, W/8, H/8] # 1 = mask[bs, W/16, H/16] tensors[bs, 1024, W/16, H/16] # 2 = mask[bs, W/32, H/32] tensors[bs, 2048, W/32, H/32] # pos: 3个不同尺度的特征对应的3个位置编码(这里一步到位直接生成经过1x1conv降维后的位置编码) # 0: [bs, 256, H/8, W/8] 1: [bs, 256, H/16, W/16] 2: [bs, 256, H/32, W/32] features, pos = self.backbone(samples) # 前三个1x1conv + GroupNorm 前向传播 srcs = [] masks = [] for l, feat in enumerate(features): src, mask = feat.decompose() srcs.append(self.input_proj[l](src)) # 1x1 降维度 -> 256 masks.append(mask) # mask shape不变 assert mask is not None # 最后一层特征 -> conv3x3 + GroupNorm 前向传播 if self.num_feature_levels > len(srcs): _len_srcs = len(srcs) for l in range(_len_srcs, self.num_feature_levels): if l == _len_srcs: # C5层输出 bs x 2048 x H/32 x W/32 x -> bs x 256 x H/64 x W/64 3x3Conv s=2 src = self.input_proj[l](features[-1].tensors) else: src = self.input_proj[l](srcs[-1]) m = samples.mask # 这一层的特征图shape变为原来一半 mask shape也要变为原来一半 [bs, H/32, H/32] -> [bs, H/64, W/64] mask = F.interpolate(m[None].float(), size=src.shape[-2:]).to(torch.bool)[0] # 生成这一层的位置编码 [bs, 256, H/64, W/64] pos_l = self.backbone[1](NestedTensor(src, mask)).to(src.dtype) srcs.append(src) masks.append(mask) pos.append(pos_l) # 到了这一步就完成了全部的backbone的前向传播了 最终生成4个不同尺度的特征srcs已经对应的mask和位置编码pos # srcs: list4 0=[bs,256,H/8,W/8] 1=[bs,256,H/16,W/16] 2=[bs,256,H/32,W/32] 3=[bs,256,H/64,W/64] # masks: list4 0=[bs,H/8,W/8] 1=[bs,H/16,W/16] 2=[bs,H/32,W/32] 3=[bs,H/64,W/64] # pos: list4 0=[bs,256,H/8,W/8] 1=[bs,256,H/16,W/16] 2=[bs,256,H/32,W/32] 3=[bs,256,H/64,W/64]最后将这4个不同尺度的特征送入transformer中的encoder中,在Deformable Attention模块中使用这4个多尺度特征,后面再详谈。
2.1.2、多尺度位置编码
想要用这4个不同尺度的特征图,还有一个问题:位置编码问题。我们知道,DETR的使用的是单尺度特征,而且使用的是三角函数,不同位置的(x、y)坐标会生成不同的位置编码,这肯定没问题!
但是Deformable DETR是使用了4个不同尺度的特征,如果还是用原来的方法,那么在这些不同尺度的特征中,位于相同位置(x、y)坐标的位置会产生相同的位置编码,所以这个方法就无法区分这些不同特征相同位置的位置编码了。
针对这个问题,作者提出了一个’scale-level embedding’的变量,可以用来解决这个问题:区分不同特征相同位置的位置编码。源码在deformable_transformer.py的DeformableTransformer中定义了一个level_embed变量,然后在每一层的原始位置编码(pos_embed)的基础上加上对应的Scale-Level Embedding(level_embed )注意,每一层所有位置加上相同的level_embed 且 不同层的level_embed不同:
class DeformableTransformer(nn.Module): def __init__(self, d_model=256, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=1024, dropout=0.1, activation="relu", return_intermediate_dec=False, num_feature_levels=4, dec_n_points=4, enc_n_points=4, two_stage=False, two_stage_num_proposals=300): super().__init__() ... # scale-level position embedding [4, 256] 可学习的 # 因为deformable detr用到了多尺度特征 经过backbone会生成4个不同尺度的特征图 但是如果还是使用原先的sine position embedding # detr是针对h和w进行编码的 不同位置的特征点会对应不同的编码值 但是deformable detr不同的特征图的不同位置就有可能会产生相同的位置编码,就无法区分了 # 为了解决这个问题,这里引入level_embed这个遍历 不同层的特征图会有不同的level_embed 再让原先的每层位置编码+每层的level_embed # 这样就很好的区分不同层的位置编码了 而且这个level_embed是可学习的 self.level_embed = nn.Parameter(torch.Tensor(num_feature_levels, d_model)) ...def forward(self, srcs, masks, pos_embeds, query_embed=None):...for lvl, (src, mask, pos_embed) in enumerate(zip(srcs, masks, pos_embeds)):# pos_embed: detr的位置编码 仅仅可以区分h,w的位置 因此对应不同的特征图有相同的h、w位置的话,是无法区分的 pos_embed = pos_embed.flatten(2).transpose(1, 2) # [bs,c,h,w] -> [bs,hxw,c] # scale-level position embedding [bs,hxw,c] + [1,1,c] -> [bs,hxw,c] # 每一层所有位置加上相同的level_embed 且 不同层的level_embed不同 # 所以这里pos_embed + level_embed,这样即使不同层特征有相同的w和h,那么也会产生不同的lvl_pos_embed 这样就可以区分了 lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)好了,到此为止backbone就介绍完了,产生了4个不同尺度的特征以及相应的多尺度位置编码,可以送入transformer的encoder中使用这些多尺度特征,后面再接着看Transformer模块。
2.2、多尺度可变形注意力
2.2.1、普通多头注意力:MultiHeadAttn
transformer原理图: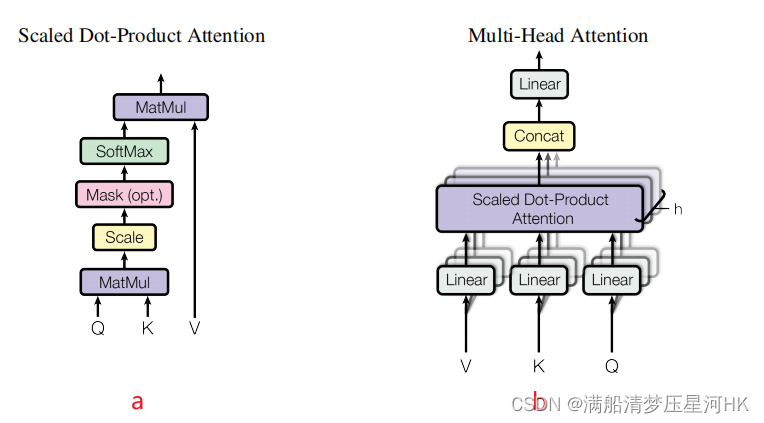
Transformer Attention的多头注意力公式如下: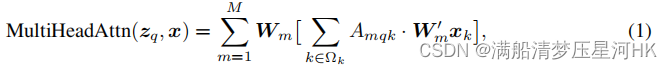
其中, x x x是输入特征, z q z_q zq表示 query,由 x x x经过 W q W_q Wq线性变换来的, k k k是key的索引, q q q是query的索引, M M M表示多头注意力的头数, m m m代表第几注意力头部, A m q k A_{mqk} Amqk表示第m头注意力权重(即上图a中一直到SoftMax的过程), W m ’ x k W^’_m x_k Wm’xk其实就是value,整个[]内的过程就是图a的全过程, W m W_m Wm是注意力施加在value之后的结果经过线性变换(也就是图b的Linear)从而得到不同头部的输出结果, Ω k \Omega_k Ωk表示所有key的集合。
仔细观察可以发现,其实上述的多头注意力公式对应的就是上图b的全过程(区别:只是少了一个concat)。
所以,普通的transfomer的多头注意力计算过程中,对每个头:每个位置的query会和所有位置的key计算注意力权重,并且施加在所有位置的value上。
2.2.2、可变形多头注意力:DeformAttn
什么是可变形注意力,大白话:query不是和全局每个位置的所有key都计算注意力权重,而是对每个query,仅在全局位置中采样 局部/部分 位置的key(自学习的方式),并且value也是局部位置的value,最后把这个局部/稀疏的注意力权重和局部value进行计算。
再看看可变形多头注意力公式如下: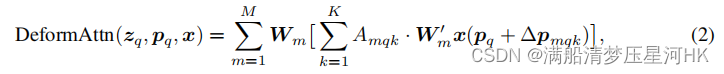
可以发现式2和式1很像,有两点区别:
2.2.3、多尺度可变形多头注意力:MSDeformAttn
最后再进一步看看可变形注意力是如何应用到多尺度特征上的,公式: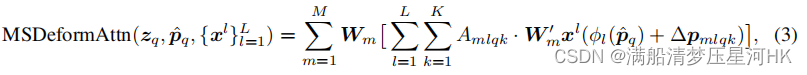
式3和式2也很像。区别:
2.2.4、源码分析
先理清三个重要变量:
参考点:reference points,各个特征层上的点,(0.5,0.5)x 4,(0.5,1.5)x 4,…(H-0.5,W-0.5)x 4 ,再除以H或W进行归一化;偏移量:offsets,网络自己学习的偏移量;采样点:reference points + offsets,每个特征点都会学习得到4个采样点,然后只计算这个特征点和这四个采样点的相似度即可,不需要学习和所有特征点的相似度;好了,看完了理论部分了,可能还是梦里懵懂,不要紧,有个印象就行,下面结合源码来分析,就可以明白其中的精妙:
第一步、计算参考点
one-stage的参考点是get_reference_points函数生成的,而two-stage参考点是通过gen_encoder_output_proposals函数生成的,后续two-stage再讲。
在deformable_transformer.py中DeformableTransformerEncoder类的get_reference_points函数:
@staticmethod def get_reference_points(spatial_shapes, valid_ratios, device): """ 生成参考点 reference points 为什么参考点是中心点? 为什么要归一化? spatial_shapes: 4个特征图的shape [4, 2] valid_ratios: 4个特征图中非padding部分的边长占其边长的比例 [bs, 4, 2] 如全是1 device: cuda:0 """ reference_points_list = [] # 遍历4个特征图的shape 比如 H_=100 W_=150 for lvl, (H_, W_) in enumerate(spatial_shapes): # 0.5 -> 99.5 取100个点 0.5 1.5 2.5 ... 99.5 # 0.5 -> 149.5 取150个点 0.5 1.5 2.5 ... 149.5 # ref_y: [100, 150] 第一行:150个0.5 第二行:150个1.5 ... 第100行:150个99.5 # ref_x: [100, 150] 第一行:0.5 1.5...149.5 100行全部相同 ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H_ - 0.5, H_, dtype=torch.float32, device=device), torch.linspace(0.5, W_ - 0.5, W_, dtype=torch.float32, device=device)) # [100, 150] -> [bs, 15000] 150个0.5 + 150个1.5 + ... + 150个99.5 -> 除以100 归一化 ref_y = ref_y.reshape(-1)[None] / (valid_ratios[:, None, lvl, 1] * H_) # [100, 150] -> [bs, 15000] 100个: 0.5 1.5 ... 149.5 -> 除以150 归一化 ref_x = ref_x.reshape(-1)[None] / (valid_ratios[:, None, lvl, 0] * W_) # [bs, 15000, 2] 每一项都是xy ref = torch.stack((ref_x, ref_y), -1) reference_points_list.append(ref) # list4: [bs, H/8*W/8, 2] + [bs, H/16*W/16, 2] + [bs, H/32*W/32, 2] + [bs, H/64*W/64, 2] -> # [bs, H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64, 2] reference_points = torch.cat(reference_points_list, 1) # reference_points: [bs, H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64, 2] -> [bs, H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64, 1, 2] # valid_ratios: [1, 4, 2] -> [1, 1, 4, 2] # 复制4份 每个特征点都有4个归一化参考点 -> [bs, H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64, 4, 2] reference_points = reference_points[:, :, None] * valid_ratios[:, None] # 4个flatten后特征图的归一化参考点坐标 return reference_points第二步、带入公式计算MSDeformAttn
再回顾下公式: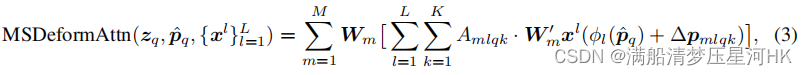
调用MSDeformAttn代码:
class MSDeformAttn(nn.Module): def __init__(self, d_model=256, n_levels=4, n_heads=8, n_points=4): """ Multi-Scale Deformable Attention Module :param d_model hidden dimension :param n_levels number of feature levels :param n_heads number of attention heads :param n_points number of sampling points per attention head per feature level """ super().__init__() if d_model % n_heads != 0: raise ValueError('d_model must be divisible by n_heads, but got {} and {}'.format(d_model, n_heads)) _d_per_head = d_model // n_heads # you'd better set _d_per_head to a power of 2 which is more efficient in our CUDA implementation if not _is_power_of_2(_d_per_head): warnings.warn("You'd better set d_model in MSDeformAttn to make the dimension of each attention head a power of 2 " "which is more efficient in our CUDA implementation.") self.im2col_step = 64 # 用于cuda算子 self.d_model = d_model # 特征层channel = 256 self.n_levels = n_levels # 多尺度特征 特征个数 = 4 self.n_heads = n_heads # 多头 = 8 self.n_points = n_points # 采样点个数 = 4 # 采样点的坐标偏移offset # 每个query在每个注意力头和每个特征层都需要采样n_points=4个采样点 每个采样点2D坐标 xy = 2 -> n_heads * n_levels * n_points * 2 = 256 self.sampling_offsets = nn.Linear(d_model, n_heads * n_levels * n_points * 2) # 每个query对应的所有采样点的注意力权重 n_heads * n_levels * n_points = 8x8x4=128 self.attention_weights = nn.Linear(d_model, n_heads * n_levels * n_points) # 线性变换得到value self.value_proj = nn.Linear(d_model, d_model) # 最后的线性变换得到输出结果 self.output_proj = nn.Linear(d_model, d_model) self._reset_parameters() # 生成初始化的偏置位置 + 注意力权重初始化 def _reset_parameters(self): # 生成初始化的偏置位置 + 注意力权重初始化 constant_(self.sampling_offsets.weight.data, 0.) # [8, ] 0, pi/4, pi/2, 3pi/4, pi, 5pi/4, 3pi/2, 7pi/4 thetas = torch.arange(self.n_heads, dtype=torch.float32) * (2.0 * math.pi / self.n_heads) # [8, 2] grid_init = torch.stack([thetas.cos(), thetas.sin()], -1) # [n_heads, n_levels, n_points, xy] = [8, 4, 4, 2] grid_init = (grid_init / grid_init.abs().max(-1, keepdim=True)[0]).view(self.n_heads, 1, 1, 2).repeat(1, self.n_levels, self.n_points, 1) # 同一特征层中不同采样点的坐标偏移肯定不能够一样 因此这里需要处理 # 对于第i个采样点,在8个头部和所有特征层中,其坐标偏移为: # (i,0) (i,i) (0,i) (-i,i) (-i,0) (-i,-i) (0,-i) (i,-i) 1<= i <= n_points # 从图形上看,形成的偏移位置相当于3x3正方形卷积核 去除中心 中心是参考点 for i in range(self.n_points): grid_init[:, :, i, :] *= i + 1 with torch.no_grad(): # 把初始化的偏移量的偏置bias设置进去 不计算梯度 self.sampling_offsets.bias = nn.Parameter(grid_init.view(-1)) constant_(self.attention_weights.weight.data, 0.) constant_(self.attention_weights.bias.data, 0.) xavier_uniform_(self.value_proj.weight.data) constant_(self.value_proj.bias.data, 0.) xavier_uniform_(self.output_proj.weight.data) constant_(self.output_proj.bias.data, 0.) def forward(self, query, reference_points, input_flatten, input_spatial_shapes, input_level_start_index, input_padding_mask=None): """ 【encoder】 query: 4个flatten后的特征图+4个flatten后特征图对应的位置编码 = src_flatten + lvl_pos_embed_flatten [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256] reference_points: 4个flatten后特征图对应的归一化参考点坐标 每个特征点有4个参考点 xy坐标 [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 4, 2] input_flatten: 4个flatten后的特征图=src_flatten [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256] input_spatial_shapes: 4个flatten后特征图的shape [4, 2] input_level_start_index: 4个flatten后特征图对应被flatten后的起始索引 [4] 如[0,15100,18900,19850] input_padding_mask: 4个flatten后特征图的mask [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64] """ N, Len_q, _ = query.shape # bs query length(每张图片所有特征点的数量) N, Len_in, _ = input_flatten.shape # bs query length(每张图片所有特征点的数量) assert (input_spatial_shapes[:, 0] * input_spatial_shapes[:, 1]).sum() == Len_in # value = w_v * x 通过线性变换将输入的特征图变换成value [bs, Len_q, 256] -> [bs, Len_q, 256] value = self.value_proj(input_flatten) # 将特征图mask过的地方(无效地方)的value用0填充 if input_padding_mask is not None: value = value.masked_fill(input_padding_mask[..., None], float(0)) # 把value拆分成8个head [bs, Len_q, 256] -> [bs, Len_q, 8, 32] value = value.view(N, Len_in, self.n_heads, self.d_model // self.n_heads) # 预测采样点的坐标偏移 [bs,Len_q,256] -> [bs,Len_q,256] -> [bs, Len_q, n_head, n_level, n_point, 2] = [bs, Len_q, 8, 4, 4, 2] sampling_offsets = self.sampling_offsets(query).view(N, Len_q, self.n_heads, self.n_levels, self.n_points, 2) # 预测采样点的注意力权重 [bs,Len_q,256] -> [bs,Len_q, 128] -> [bs, Len_q, 8, 4*4] attention_weights = self.attention_weights(query).view(N, Len_q, self.n_heads, self.n_levels * self.n_points) # 每个query在每个注意力头部内,每个特征层都采样4个特征点,即16个采样点(4x4),再对这16个采样点的注意力权重进行初始化 # [bs, Len_q, 8, 16] -> [bs, Len_q, 8, 16] -> [bs, Len_q, 8, 4, 4] attention_weights = F.softmax(attention_weights, -1).view(N, Len_q, self.n_heads, self.n_levels, self.n_points) # N, Len_q, n_heads, n_levels, n_points, 2 if reference_points.shape[-1] == 2: # one stage # [4, 2] 每个(h, w) -> (w, h) offset_normalizer = torch.stack([input_spatial_shapes[..., 1], input_spatial_shapes[..., 0]], -1) # [bs, Len_q, 1, n_point, 1, 2] + [bs, Len_q, n_head, n_level, n_point, 2] / [1, 1, 1, n_point, 1, 2] # -> [bs, Len_q, 1, n_levels, n_points, 2] # 参考点 + 偏移量/特征层宽高 = 采样点 sampling_locations = reference_points[:, :, None, :, None, :] \ + sampling_offsets / offset_normalizer[None, None, None, :, None, :] elif reference_points.shape[-1] == 4: # two stage + iterative bounding box refinement # 前两个是xy 后两个是wh # 初始化时offset是在 -n_points ~ n_points 范围之间 这里除以self.n_points是相当于把offset归一化到 0~1 # 然后再乘以宽高的一半 再加上参考点的中心坐标 这就相当于使得最后的采样点坐标总是位于proposal box内 # 相当于对采样范围进行了约束 减少了搜索空间 sampling_locations = reference_points[:, :, None, :, None, :2] \ + sampling_offsets / self.n_points * reference_points[:, :, None, :, None, 2:] * 0.5 else: raise ValueError( 'Last dim of reference_points must be 2 or 4, but get {} instead.'.format(reference_points.shape[-1])) # 输入:采样点位置、注意力权重、所有点的value # 具体过程:根据采样点位置从所有点的value中拿出对应的value,并且和对应的注意力权重进行weighted sum # 调用CUDA实现的MSDeformAttnFunction函数 需要编译 # [bs, Len_q, 256] output = MSDeformAttnFunction.apply( value, input_spatial_shapes, input_level_start_index, sampling_locations, attention_weights, self.im2col_step) # 最后进行公式中的线性运算 # [bs, Len_q, 256] output = self.output_proj(output) return output这里的MSDeformAttn是调用的CUDA实现的,具体过程是:根据采样点位置从所有点的value中拿出对应的value,并且和对应的注意力权重进行weighted sum,可以看看models/ops/functions/ms_deform_attn_func.py的ms_deform_attn_core_pytorch函数看看pytorch实现版本,看看核心思想:
def ms_deform_attn_core_pytorch(value, value_spatial_shapes, sampling_locations, attention_weights): # for debug and test only, # need to use cuda version instead N_, S_, M_, D_ = value.shape _, Lq_, M_, L_, P_, _ = sampling_locations.shape # 把value分割到各个特征层上得到对应的 list value value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes], dim=1) # 采样点坐标从[0,1] -> [-1, 1] F.grid_sample要求采样坐标归一化到[-1, 1] sampling_grids = 2 * sampling_locations - 1 sampling_value_list = [] for lid_, (H_, W_) in enumerate(value_spatial_shapes): # N_, H_*W_, M_, D_ -> N_, H_*W_, M_*D_ -> N_, M_*D_, H_*W_ -> N_*M_, D_, H_, W_ value_l_ = value_list[lid_].flatten(2).transpose(1, 2).reshape(N_*M_, D_, H_, W_) # 得到每个特征层的value list # N_, Lq_, M_, P_, 2 -> N_, M_, Lq_, P_, 2 -> N_*M_, Lq_, P_, 2 sampling_grid_l_ = sampling_grids[:, :, :, lid_].transpose(1, 2).flatten(0, 1) # 得到每个特征层的采样点 list # N_*M_, D_, Lq_, P_ 采样算法 根据每个特征层采样点到每个特征层的value进行采样 非采样点用0填充 sampling_value_l_ = F.grid_sample(value_l_, sampling_grid_l_, mode='bilinear', padding_mode='zeros', align_corners=False) sampling_value_list.append(sampling_value_l_) # (N_, Lq_, M_, L_, P_) -> (N_, M_, Lq_, L_, P_) -> (N_, M_, 1, Lq_, L_*P_) attention_weights = attention_weights.transpose(1, 2).reshape(N_*M_, 1, Lq_, L_*P_) # 注意力权重 和 采样后的value 进行 weighted sum output = (torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights).sum(-1).view(N_, M_*D_, Lq_) return output.transpose(1, 2).contiguous()2.3、Deformable DETR:简单版
这里简单的梳理一下Deformable Transformer的全过程,整体上和DETR类似,最主要是用多尺度可变形注意力替代了Encoder中的自注意力(self-attention)及Decoder中的交叉注意力(cross-attention)。
2.3.1、DeformableTransformer
第一步、为Encoder的输入做准备,将多尺度特征图、各特征图对应的mask、各特征图对应的位置编码、各特征图的宽高、各特征图flatten后的起始索引等信息展品。
class DeformableTransformer(nn.Module): def __init__(self, d_model=256, nhead=8, num_encoder_layers=6, num_decoder_layers=6, dim_feedforward=1024, dropout=0.1, activation="relu", return_intermediate_dec=False, num_feature_levels=4, dec_n_points=4, enc_n_points=4, two_stage=False, two_stage_num_proposals=300): super().__init__() self.d_model = d_model # 256 self.nhead = nhead # 8头注意力 self.two_stage = two_stage # False self.two_stage_num_proposals = two_stage_num_proposals # 300 encoder_layer = DeformableTransformerEncoderLayer(d_model, dim_feedforward, dropout, activation, num_feature_levels, nhead, enc_n_points) self.encoder = DeformableTransformerEncoder(encoder_layer, num_encoder_layers) decoder_layer = DeformableTransformerDecoderLayer(d_model, dim_feedforward, dropout, activation, num_feature_levels, nhead, dec_n_points) self.decoder = DeformableTransformerDecoder(decoder_layer, num_decoder_layers, return_intermediate_dec) # scale-level position embedding [4, 256] # 因为deformable detr用到了多尺度特征 经过backbone会生成4个不同尺度的特征图 但是如果还是使用原先的sine position embedding # detr是针对h和w进行编码的 不同位置的特征点会对应不同的编码值 但是deformable detr不同的特征图的不同位置就有可能会产生相同的位置编码,就无法区分了 # 为了解决这个问题,这里引入level_embed这个遍历 不同层的特征图会有不同的level_embed 再让原先的每层位置编码+每层的level_embed # 这样就很好的区分不同层的位置编码了 而且这个level_embed是可学习的 self.level_embed = nn.Parameter(torch.Tensor(num_feature_levels, d_model)) if two_stage: self.enc_output = nn.Linear(d_model, d_model) self.enc_output_norm = nn.LayerNorm(d_model) self.pos_trans = nn.Linear(d_model * 2, d_model * 2) self.pos_trans_norm = nn.LayerNorm(d_model * 2) else: self.reference_points = nn.Linear(d_model, 2) self._reset_parameters() def forward(self, srcs, masks, pos_embeds, query_embed=None): """ 经过backbone输出4个不同尺度的特征图srcs,以及这4个特征图对应的masks和位置编码 srcs: list4 0=[bs,256,H/8,W/8] 1=[bs,256,H/16,W/16] 2=[bs,256,H/32,W/32] 3=[bs,256,H/64,W/64] masks: list4 0=[bs,H/8,W/8] 1=[bs,H/16,W/16] 2=[bs,H/32,W/32] 3=[bs,H/64,W/64] pos_embeds: list4 0=[bs,256,H/8,W/8] 1=[bs,256,H/16,W/16] 2=[bs,256,H/32,W/32] 3=[bs,256,H/64,W/64] query_embed: query embedding 参数 [300, 512] """ assert self.two_stage or query_embed is not None # 为encoder的输入作准备:将多尺度特征图、各特征图对应的mask、位置编码、各特征图的高宽、各特征图flatten后的起始索引等展平 src_flatten = [] mask_flatten = [] lvl_pos_embed_flatten = [] spatial_shapes = [] for lvl, (src, mask, pos_embed) in enumerate(zip(srcs, masks, pos_embeds)): bs, c, h, w = src.shape # bs channel h w spatial_shape = (h, w) # 特征图shape spatial_shapes.append(spatial_shape) src = src.flatten(2).transpose(1, 2) # [bs,c,h,w] -> [bs,hxw,c] mask = mask.flatten(1) # [bs,h,w] -> [bs, hxw] # pos_embed: detr的位置编码 仅仅可以区分h,w的位置 因此对应不同的特征图有相同的h、w位置的话,是无法区分的 pos_embed = pos_embed.flatten(2).transpose(1, 2) # [bs,c,h,w] -> [bs,hxw,c] # scale-level position embedding [bs,hxw,c] + [1,1,c] -> [bs,hxw,c] # 每一层所有位置加上相同的level_embed 且 不同层的level_embed不同 # 所以这里pos_embed + level_embed,这样即使不同层特征有相同的w和h,那么也会产生不同的lvl_pos_embed 这样就可以区分了 lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1) lvl_pos_embed_flatten.append(lvl_pos_embed) src_flatten.append(src) mask_flatten.append(mask) # list4[bs, H/8 * W/8, 256] [bs, H/16 * W/16, 256] [bs, H/32 * W/32, 256] [bs, H/64 * W/64, 256] -> [bs, K, 256] # K = H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64 src_flatten = torch.cat(src_flatten, 1) # list4[bs, H/8 * W/8] [bs, H/16 * W/16] [bs, H/32 * W/32] [bs, H/64 * W/64] -> [bs, K] mask_flatten = torch.cat(mask_flatten, 1) # list4[bs, H/8 * W/8, 256] [bs, H/16 * W/16, 256] [bs, H/32 * W/32, 256] [bs, H/64 * W/64, 256] -> [bs, K, 256] lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1) # [4, h+w] 4个特征图的高和宽 spatial_shapes = torch.as_tensor(spatial_shapes, dtype=torch.long, device=src_flatten.device) # 不同尺度特征图对应被flatten的那个维度的起始索引 Tensor[4] 如[0,15100,18900,19850] level_start_index = torch.cat((spatial_shapes.new_zeros((1, )), spatial_shapes.prod(1).cumsum(0)[:-1])) # 各尺度特征图中非padding部分的边长占其边长的比例 [bs, 4, 2] 如全是1 valid_ratios = torch.stack([self.get_valid_ratio(m) for m in masks], 1)第二步、Encoder:输入上述所有展平数据,输入Encoder中学习各个位置的相似度,增强输入的特征。输出memory(编码后的特征),shape = [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256],第二个维度是所有的特征点数量
# [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256]memory = self.encoder(src_flatten, spatial_shapes, level_start_index, valid_ratios, lvl_pos_embed_flatten, mask_flatten)第三步:为decoder的输入作准备:得到参考点
这里暂时聊聊one-stage的情况,直接随机初始化 2D 参考点。
bs, _, c = memory.shape if self.two_stage: output_memory, output_proposals = self.gen_encoder_output_proposals(memory, mask_flatten, spatial_shapes) # hack implementation for two-stage Deformable DETR enc_outputs_class = self.decoder.class_embed[self.decoder.num_layers](output_memory) enc_outputs_coord_unact = self.decoder.bbox_embed[self.decoder.num_layers](output_memory) + output_proposals topk = self.two_stage_num_proposals topk_proposals = torch.topk(enc_outputs_class[..., 0], topk, dim=1)[1] topk_coords_unact = torch.gather(enc_outputs_coord_unact, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, 4)) topk_coords_unact = topk_coords_unact.detach() reference_points = topk_coords_unact.sigmoid() init_reference_out = reference_points pos_trans_out = self.pos_trans_norm(self.pos_trans(self.get_proposal_pos_embed(topk_coords_unact))) query_embed, tgt = torch.split(pos_trans_out, c, dim=2)else: # 默认执行 # 随机初始化 query_embed = nn.Embedding(num_queries, hidden_dim*2) # [300, 512] -> [300, 256] + [300, 256] query_embed, tgt = torch.split(query_embed, c, dim=1) # 初始化query pos [300, 256] -> [bs, 300, 256] query_embed = query_embed.unsqueeze(0).expand(bs, -1, -1) # 初始化query embedding [300, 256] -> [bs, 300, 256] tgt = tgt.unsqueeze(0).expand(bs, -1, -1) # 由query pos接一个全连接层 再归一化后的参考点中心坐标 [bs, 300, 256] -> [bs, 300, 2] reference_points = self.reference_points(query_embed).sigmoid() init_reference_out = reference_points # 初始化的归一化参考点坐标 [bs, 300, 2]第四步:Decoder解码特征并输出参考点
解码特征:hs: 6层decoder输出 [n_decoder, bs, num_query, d_model] = [6, bs, 300, 256]
参考点坐标:
init_reference_out: 初始化的参考点归一化中心坐标 [bs, 300, 2]
inter_references: 6层decoder学习到的参考点归一化中心坐标 [6, bs, 300, 2]
# decoder # tgt: 初始化query embedding [bs, 300, 256] # reference_points: 由query pos接一个全连接层 再归一化后的参考点中心坐标 [bs, 300, 2] # query_embed: query pos[bs, 300, 256] # memory: Encoder输出结果 [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256] # spatial_shapes: [4, 2] 4个特征层的shape # level_start_index: [4, ] 4个特征层flatten后的开始index # valid_ratios: [bs, 4, 2] # mask_flatten: 4个特征层flatten后的mask [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64] # hs: 6层decoder输出 [n_decoder, bs, num_query, d_model] = [6, bs, 300, 256] # inter_references: 6层decoder学习到的参考点归一化中心坐标 [6, bs, 300, 2] # one-stage=[n_decoder, bs, num_query, 2] two-stage=[n_decoder, bs, num_query, 4] hs, inter_references = self.decoder(tgt, reference_points, memory, spatial_shapes, level_start_index, valid_ratios, query_embed, mask_flatten) inter_references_out = inter_references if self.two_stage: return hs, init_reference_out, inter_references_out, enc_outputs_class, enc_outputs_coord_unact # hs: 6层decoder输出 [n_decoder, bs, num_query, d_model] = [6, bs, 300, 256] # init_reference_out: 初始化的参考点归一化中心坐标 [bs, 300, 2] # inter_references: 6层decoder学习到的参考点归一化中心坐标 [6, bs, 300, 2] # one-stage=[n_decoder, bs, num_query, 2] two-stage=[n_decoder, bs, num_query, 4] return hs, init_reference_out, inter_references_out, None, None2.3.2、Encoder
这里的Encoder和transformer最主要的区别是使用了可变形注意力代替了原生的自注意力,而且还引入了参考点这个概念。主要过程就是:生成参考点(固定值 不可学习)、调用6个encoder layer。
输入多尺度特征层:[bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256];
每个encoder layer都会不断学习特征层中每个位置和4个采样点的相关性,最终输出的特征是增强后的特征图:[bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256];
每个可变形注意力的query和value均来自flatten后的4个特征图,query = flatten后的4个特征图 + scale-level pos embedding,value = flatten后的4个特征图(后面会根据参考点再进行稀疏采样),key = 4个可学习的参考点。
class DeformableTransformerEncoder(nn.Module): def __init__(self, encoder_layer, num_layers): super().__init__() self.layers = _get_clones(encoder_layer, num_layers) # 6层DeformableTransformerEncoderLayer self.num_layers = num_layers # 6 @staticmethod def get_reference_points(spatial_shapes, valid_ratios, device): """ 生成参考点 reference points 为什么参考点是中心点? 为什么要归一化? spatial_shapes: 4个特征图的shape [4, 2] valid_ratios: 4个特征图中非padding部分的边长占其边长的比例 [bs, 4, 2] 如全是1 device: cuda:0 """ reference_points_list = [] # 遍历4个特征图的shape 比如 H_=100 W_=150 for lvl, (H_, W_) in enumerate(spatial_shapes): # 0.5 -> 99.5 取100个点 0.5 1.5 2.5 ... 99.5 # 0.5 -> 149.5 取150个点 0.5 1.5 2.5 ... 149.5 # ref_y: [100, 150] 第一行:150个0.5 第二行:150个1.5 ... 第100行:150个99.5 # ref_x: [100, 150] 第一行:0.5 1.5...149.5 100行全部相同 ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H_ - 0.5, H_, dtype=torch.float32, device=device), torch.linspace(0.5, W_ - 0.5, W_, dtype=torch.float32, device=device)) # [100, 150] -> [bs, 15000] 150个0.5 + 150个1.5 + ... + 150个99.5 -> 除以100 归一化 ref_y = ref_y.reshape(-1)[None] / (valid_ratios[:, None, lvl, 1] * H_) # [100, 150] -> [bs, 15000] 100个: 0.5 1.5 ... 149.5 -> 除以150 归一化 ref_x = ref_x.reshape(-1)[None] / (valid_ratios[:, None, lvl, 0] * W_) # [bs, 15000, 2] 每一项都是xy ref = torch.stack((ref_x, ref_y), -1) reference_points_list.append(ref) # list4: [bs, H/8*W/8, 2] + [bs, H/16*W/16, 2] + [bs, H/32*W/32, 2] + [bs, H/64*W/64, 2] -> # [bs, H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64, 2] reference_points = torch.cat(reference_points_list, 1) # reference_points: [bs, H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64, 2] -> [bs, H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64, 1, 2] # valid_ratios: [1, 4, 2] -> [1, 1, 4, 2] # 复制4份 每个特征点都有4个归一化参考点 -> [bs, H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64, 4, 2] reference_points = reference_points[:, :, None] * valid_ratios[:, None] # 4个flatten后特征图的归一化参考点坐标 return reference_points def forward(self, src, spatial_shapes, level_start_index, valid_ratios, pos=None, padding_mask=None): """ src: 多尺度特征图(4个flatten后的特征图) [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256] spatial_shapes: 4个特征图的shape [4, 2] level_start_index: [4] 4个flatten后特征图对应被flatten后的起始索引 如[0,15100,18900,19850] valid_ratios: 4个特征图中非padding部分的边长占其边长的比例 [bs, 4, 2] 如全是1 pos: 4个flatten后特征图对应的位置编码(多尺度位置编码) [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256] padding_mask: 4个flatten后特征图的mask [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64] """ output = src # 4个flatten后特征图的归一化参考点坐标 每个特征点有4个参考点 xy坐标 [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 4, 2] reference_points = self.get_reference_points(spatial_shapes, valid_ratios, device=src.device) for _, layer in enumerate(self.layers): output = layer(output, pos, reference_points, spatial_shapes, level_start_index, padding_mask) # 经过6层encoder增强后的新特征 每一层不断学习特征层中每个位置和4个采样点的相关性,最终输出的特征是增强后的特征图 # [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256] return outputclass DeformableTransformerEncoderLayer(nn.Module): def __init__(self, d_model=256, d_ffn=1024, dropout=0.1, activation="relu", n_levels=4, n_heads=8, n_points=4): super().__init__() # self attention self.self_attn = MSDeformAttn(d_model, n_levels, n_heads, n_points) self.dropout1 = nn.Dropout(dropout) self.norm1 = nn.LayerNorm(d_model) # ffn self.linear1 = nn.Linear(d_model, d_ffn) self.activation = _get_activation_fn(activation) self.dropout2 = nn.Dropout(dropout) self.linear2 = nn.Linear(d_ffn, d_model) self.dropout3 = nn.Dropout(dropout) self.norm2 = nn.LayerNorm(d_model) @staticmethod def with_pos_embed(tensor, pos): return tensor if pos is None else tensor + pos def forward_ffn(self, src): src2 = self.linear2(self.dropout2(self.activation(self.linear1(src)))) src = src + self.dropout3(src2) src = self.norm2(src) return src def forward(self, src, pos, reference_points, spatial_shapes, level_start_index, padding_mask=None): """ src: 多尺度特征图(4个flatten后的特征图) [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256] reference_points: 4个flatten后特征图对应的归一化参考点坐标 [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 4, 2] pos: 4个flatten后特征图对应的位置编码(多尺度位置编码) [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256] spatial_shapes: 4个特征图的shape [4, 2] level_start_index: [4] 4个flatten后特征图对应被flatten后的起始索引 如[0,15100,18900,19850] padding_mask: 4个flatten后特征图的mask [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64] """ # self attention + add + norm # query = flatten后的多尺度特征图 + scale-level pos # key = 采样点 每个特征点对应周围的4个可学习的采样点 # value = flatten后的多尺度特征图 src2 = self.self_attn(self.with_pos_embed(src, pos), reference_points, src, spatial_shapes, level_start_index, padding_mask) src = src + self.dropout1(src2) src = self.norm1(src) # ffn feed forward + add + norm src = self.forward_ffn(src) # [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256] return src2.3.3、Decoder
Decoder和transformer最主要的区别是使用了可变形注意力代替了原生的cross-attention,并且这里也需要预先生成(固定的 归一化的)参考点。
先随机初始化query_embed,再拆分为query(tgt)和query pos(query_embed),再用query pos(query_embed)接一个全连接层+sigmoid,得到归一化后的参考点中心坐标reference_points:[bs, 300, 2]。
再将query(tgt)、query pos(query_embed)、encoder输出memory和归一化后的参考点中心坐标reference_points输入decoder中。
self-attention:学习各个物体之间的关系/位置 ,可以知道图像当中哪些位置会存在物体 物体信息->tgt,所以qk都是query + query pos ,v就是query。
cross-attention:不断增强encoder的输出特征,将物体的信息不断加入encoder的输出特征中去,更好地表征了图像中的各个物体。所以q=query + query pos, k = reference_points, v=上一层输出的output。
class DeformableTransformerDecoder(nn.Module): def __init__(self, decoder_layer, num_layers, return_intermediate=False): super().__init__() self.layers = _get_clones(decoder_layer, num_layers) # 6层DeformableTransformerDecoderLayer self.num_layers = num_layers # 6 self.return_intermediate = return_intermediate # True 默认是返回所有Decoder层输出 计算所有层损失 # hack implementation for iterative bounding box refinement and two-stage Deformable DETR self.bbox_embed = None # 策略1 iterative bounding box refinement self.class_embed = None # 策略2 two-stage Deformable DETR def forward(self, tgt, reference_points, src, src_spatial_shapes, src_level_start_index, src_valid_ratios, query_pos=None, src_padding_mask=None): """ tgt: 预设的query embedding [bs, 300, 256] query_pos: 预设的query pos [bs, 300, 256] reference_points: query pos通过一个全连接层->2维 [bs, 300, 2] src: encoder最后的输出特征 即memory [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256] src_spatial_shapes: [4, 2] 4个特征层的原始shape src_level_start_index: [4,] 4个特征层flatten后的开始index src_padding_mask: 4个特征层flatten后的mask [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64] """ output = tgt intermediate = [] # 中间各层+首尾两层=6层输出的解码结果 intermediate_reference_points = [] # 中间各层+首尾两层输出的参考点(不断矫正) for lid, layer in enumerate(self.layers): # 得到参考点坐标 # two stage if reference_points.shape[-1] == 4: reference_points_input = reference_points[:, :, None] \ * torch.cat([src_valid_ratios, src_valid_ratios], -1)[:, None] else: # one stage模式下参考点是query pos通过一个全连接层线性变化为2维的 中心坐标形式(x,y) assert reference_points.shape[-1] == 2 # [bs, 300, 1, 2] * [bs, 1, 4, 2] -> [bs, 300, 4, 2]=[bs, n_query, n_lvl, 2] reference_points_input = reference_points[:, :, None] * src_valid_ratios[:, None] # decoder layer # output: [bs, 300, 256] = self-attention输出特征 + cross-attention输出特征 # 知道图像中物体与物体之间的关系 + encoder增强后的图像特征 + 图像与物体之间的关系 output = layer(output, query_pos, reference_points_input, src, src_spatial_shapes, src_level_start_index, src_padding_mask) # hack implementation for iterative bounding box refinement # 使用iterative bounding box refinement 这里的self.bbox_embed就不是None # 如果没有iterative bounding box refinement那么reference_points是不变的 # 每层参考点都会根据上一层的输出结果进行矫正 if self.bbox_embed is not None: tmp = self.bbox_embed[lid](output) # [bs, 300, 256] -> [bs, 300, 4(xywh)] if reference_points.shape[-1] == 4: # two stage new_reference_points = tmp + inverse_sigmoid(reference_points) new_reference_points = new_reference_points.sigmoid() else: # one stage assert reference_points.shape[-1] == 2 new_reference_points = tmp # 根据decoder每层解码的特征图->回归头(不共享参数) 得到相对参考点的偏移量xy # 然后再加上参考点坐标(反归一化),再进行sigmoid归一化 得到矫正的参考点 new_reference_points[..., :2] = tmp[..., :2] + inverse_sigmoid(reference_points) new_reference_points = new_reference_points.sigmoid() # reference_points: [bs, 300, 2] -> [bs, 300, 4] # .detach() 取消了梯度 因为这个参考点在各层相当于作为先验的角色 reference_points = new_reference_points.detach() if self.return_intermediate: intermediate.append(output) intermediate_reference_points.append(reference_points) # 默认返回6个decoder层输出一起计算损失 if self.return_intermediate: # 0 [6, bs, 300, 256] 6层decoder输出 # 1 [6, bs, 300, 2] 6层decoder的参考点归一化中心坐标 一般6层是相同的 # 但是如果是iterative bounding box refinement会不断学习迭代得到新的参考点 6层一半不同 return torch.stack(intermediate), torch.stack(intermediate_reference_points) return output, reference_pointsclass DeformableTransformerDecoderLayer(nn.Module): def __init__(self, d_model=256, d_ffn=1024, dropout=0.1, activation="relu", n_levels=4, n_heads=8, n_points=4): super().__init__() # cross attention self.cross_attn = MSDeformAttn(d_model, n_levels, n_heads, n_points) self.dropout1 = nn.Dropout(dropout) self.norm1 = nn.LayerNorm(d_model) # self attention self.self_attn = nn.MultiheadAttention(d_model, n_heads, dropout=dropout) self.dropout2 = nn.Dropout(dropout) self.norm2 = nn.LayerNorm(d_model) # ffn self.linear1 = nn.Linear(d_model, d_ffn) self.activation = _get_activation_fn(activation) self.dropout3 = nn.Dropout(dropout) self.linear2 = nn.Linear(d_ffn, d_model) self.dropout4 = nn.Dropout(dropout) self.norm3 = nn.LayerNorm(d_model) @staticmethod def with_pos_embed(tensor, pos): return tensor if pos is None else tensor + pos def forward_ffn(self, tgt): tgt2 = self.linear2(self.dropout3(self.activation(self.linear1(tgt)))) tgt = tgt + self.dropout4(tgt2) tgt = self.norm3(tgt) return tgt def forward(self, tgt, query_pos, reference_points, src, src_spatial_shapes, level_start_index, src_padding_mask=None): """" tgt: 预设的query embedding [bs, 300, 256] query_pos: 预设的query pos [bs, 300, 256] reference_points: query pos通过一个全连接层->2维 [bs, 300, 4, 2] = [bs, num_query, n_layer, 2] iterative bounding box refinement时 = [bs, num_query, n_layer, 4] src: 第一层是encoder的输出memory 第2-6层都是上一层输出的output src_spatial_shapes: [4, 2] 4个特征层的原始shape src_level_start_index: [4,] 4个特征层flatten后的开始index src_padding_mask: 4个特征层flatten后的mask [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64] """ # query embedding + query_pos q = k = self.with_pos_embed(tgt, query_pos) # self-attention # 第一个attention的目的:学习各个物体之间的关系/位置 可以知道图像当中哪些位置会存在物体 物体信息->tgt # 所以qk都是query embedding + query pos v就是query embedding tgt2 = self.self_attn(q.transpose(0, 1), k.transpose(0, 1), tgt.transpose(0, 1))[0].transpose(0, 1) tgt = tgt + self.dropout2(tgt2) tgt = self.norm2(tgt) # cross attention 使用(多尺度)可变形注意力模块替代原生的Transformer交叉注意力 # 第二个attention的目的:不断增强encoder的输出特征,将物体的信息不断加入encoder的输出特征中去,更好地表征了图像中的各个物体 # 所以q=query embedding + query pos, k = query pos通过一个全连接层->2维, v=上一层输出的output tgt2 = self.cross_attn(self.with_pos_embed(tgt, query_pos), reference_points, src, src_spatial_shapes, level_start_index, src_padding_mask) # add + norm tgt = tgt + self.dropout1(tgt2) tgt = self.norm1(tgt) # ffn = feed forward + add + norm tgt = self.forward_ffn(tgt) # [bs, 300, 256] self-attention输出特征 + cross-attention输出特征 # 最终的特征:知道图像中物体与物体之间的位置关系 + encoder增强后的图像特征 + 图像与物体之间的关系 return tgt2.3.4、Deformable DETR
class DeformableDETR(nn.Module): """ This is the Deformable DETR module that performs object detection """ def __init__(self, backbone, transformer, num_classes, num_queries, num_feature_levels, aux_loss=True, with_box_refine=False, two_stage=False): """ Initializes the model. Parameters: backbone: torch module of the backbone to be used. See backbone.py transformer: torch module of the transformer architecture. See transformer.py num_classes: number of object classes num_queries: number of object queries, ie detection slot. This is the maximal number of objects DETR can detect in a single image. For COCO, we recommend 100 queries. aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used. with_box_refine: iterative bounding box refinement two_stage: two-stage Deformable DETR """ super().__init__() self.num_queries = num_queries # 100 self.transformer = transformer # transformer hidden_dim = transformer.d_model # 256 self.class_embed = nn.Linear(hidden_dim, num_classes) # one-stage 共享分类头 self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3) # one-stage 共享回归头 self.num_feature_levels = num_feature_levels # encoder会生成4个不同尺度的特征层 4 # one-stage是object query # two-stage是reference points if not two_stage: self.query_embed = nn.Embedding(num_queries, hidden_dim*2) # 3个1x1conv + 1个3x3conv if num_feature_levels > 1: num_backbone_outs = len(backbone.strides) input_proj_list = [] for _ in range(num_backbone_outs): # 3个1x1conv in_channels = backbone.num_channels[_] # 512 1024 2048 input_proj_list.append(nn.Sequential( # conv1x1 -> 256 channel nn.Conv2d(in_channels, hidden_dim, kernel_size=1), nn.GroupNorm(32, hidden_dim), )) for _ in range(num_feature_levels - num_backbone_outs): # 1个3x3conv input_proj_list.append(nn.Sequential( nn.Conv2d(in_channels, hidden_dim, kernel_size=3, stride=2, padding=1), # 3x3conv s=2 -> 256channel nn.GroupNorm(32, hidden_dim), )) in_channels = hidden_dim self.input_proj = nn.ModuleList(input_proj_list) else: self.input_proj = nn.ModuleList([ nn.Sequential( nn.Conv2d(backbone.num_channels[0], hidden_dim, kernel_size=1), nn.GroupNorm(32, hidden_dim), )]) self.backbone = backbone # backbone Joiner 0 Backbone + 1 PositionEmbeddingSine self.aux_loss = aux_loss # True 计算辅助损失 6个decoder总损失 self.with_box_refine = with_box_refine # False 第一个策略 self.two_stage = two_stage # False 第二个策略 # 初始化 prior_prob = 0.01 bias_value = -math.log((1 - prior_prob) / prior_prob) self.class_embed.bias.data = torch.ones(num_classes) * bias_value nn.init.constant_(self.bbox_embed.layers[-1].weight.data, 0) nn.init.constant_(self.bbox_embed.layers[-1].bias.data, 0) for proj in self.input_proj: nn.init.xavier_uniform_(proj[0].weight, gain=1) nn.init.constant_(proj[0].bias, 0) # if two-stage, the last class_embed and bbox_embed is for region proposal generation # two stage:7个预测头 最后一个class_embed 和 bbox_embed 产生 region proposal # one stage:6个预测头 num_pred = (transformer.decoder.num_layers + 1) if two_stage else transformer.decoder.num_layers # iterative bounding box refinement # 对decoder每层都有不同的分类头和回归头 这里使用_get_clones(deepcopy) 则不同分类头和回归头参数不共享 if with_box_refine: self.class_embed = _get_clones(self.class_embed, num_pred) self.bbox_embed = _get_clones(self.bbox_embed, num_pred) nn.init.constant_(self.bbox_embed[0].layers[-1].bias.data[2:], -2.0) # hack implementation for iterative bounding box refinement # 不使用iterative bounding box refinement时self.transformer.decoder.bbox_embed=None # 反之decoder每一层都会预测bbox偏移量 使用这一层bbox偏移量对上一层的预测输出进行矫正 self.transformer.decoder.bbox_embed = self.bbox_embed else: nn.init.constant_(self.bbox_embed.layers[-1].bias.data[2:], -2.0) # 6/7层decoder共享同一个分类头/回归头 共享参数 如果是7层 最后一层就是第一阶段中proposal的预测 self.class_embed = nn.ModuleList([self.class_embed for _ in range(num_pred)]) # 6层/7层 self.bbox_embed = nn.ModuleList([self.bbox_embed for _ in range(num_pred)]) # 6层/7层 self.transformer.decoder.bbox_embed = None if two_stage: # hack implementation for two-stage 非共享分类头 self.transformer.decoder.class_embed = self.class_embed for box_embed in self.bbox_embed: nn.init.constant_(box_embed.layers[-1].bias.data[2:], 0.0) def forward(self, samples: NestedTensor): """ The forward expects a NestedTensor, which consists of: - samples.tensor: batched images, of shape [batch_size x 3 x H x W] - samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels It returns a dict with the following elements: - "pred_logits": the classification logits (including no-object) for all queries. Shape= [batch_size x num_queries x (num_classes + 1)] - "pred_boxes": The normalized boxes coordinates for all queries, represented as (center_x, center_y, height, width). These values are normalized in [0, 1], relative to the size of each individual image (disregarding possible padding). See PostProcess for information on how to retrieve the unnormalized bounding box. - "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list of dictionnaries containing the two above keys for each decoder layer. """ # check samples -> NestedTensor if not isinstance(samples, NestedTensor): samples = nested_tensor_from_tensor_list(samples) # 经过backbone resnet50 输出三个尺度的特征信息 features list:3 NestedTensor # 0 = mask[bs, W/8, H/8] tensors[bs, 512, W/8, H/8] # 1 = mask[bs, W/16, H/16] tensors[bs, 1024, W/16, H/16] # 2 = mask[bs, W/32, H/32] tensors[bs, 2048, W/32, H/32] # pos: 3个不同尺度的特征对应的3个位置编码(这里一步到位直接生成经过1x1conv降维后的位置编码) # 0: [bs, 256, H/8, W/8] 1: [bs, 256, H/16, W/16] 2: [bs, 256, H/32, W/32] features, pos = self.backbone(samples) # 前三个1x1conv + GroupNorm 前向传播 srcs = [] masks = [] for l, feat in enumerate(features): src, mask = feat.decompose() srcs.append(self.input_proj[l](src)) # 1x1 降维度 -> 256 masks.append(mask) # mask shape不变 assert mask is not None # 最后一层特征 -> conv3x3 + GroupNorm 前向传播 if self.num_feature_levels > len(srcs): _len_srcs = len(srcs) for l in range(_len_srcs, self.num_feature_levels): if l == _len_srcs: # C5层输出 bs x 2048 x H/32 x W/32 x -> bs x 256 x H/64 x W/64 3x3Conv s=2 src = self.input_proj[l](features[-1].tensors) else: src = self.input_proj[l](srcs[-1]) m = samples.mask # 这一层的特征图shape变为原来一半 mask shape也要变为原来一半 [bs, H/32, H/32] -> [bs, H/64, W/64] mask = F.interpolate(m[None].float(), size=src.shape[-2:]).to(torch.bool)[0] # 生成这一层的位置编码 [bs, 256, H/64, W/64] pos_l = self.backbone[1](NestedTensor(src, mask)).to(src.dtype) srcs.append(src) masks.append(mask) pos.append(pos_l) # 到了这一步就完成了全部的backbone的前向传播了 最终生成4个不同尺度的特征srcs已经对应的mask和位置编码pos # srcs: list4 0=[bs,256,H/8,W/8] 1=[bs,256,H/16,W/16] 2=[bs,256,H/32,W/32] 3=[bs,256,H/64,W/64] # masks: list4 0=[bs,H/8,W/8] 1=[bs,H/16,W/16] 2=[bs,H/32,W/32] 3=[bs,H/64,W/64] # pos: list4 0=[bs,256,H/8,W/8] 1=[bs,256,H/16,W/16] 2=[bs,256,H/32,W/32] 3=[bs,256,H/64,W/64] query_embeds = None if not self.two_stage: query_embeds = self.query_embed.weight # query_embeds: [300, 512] # [one-stage] # query_embeds = [300, 512] # hs: 6层decoder输出 [n_decoder, bs, num_query, d_model] = [6, bs, 300, 256] # init_reference_out: 初始化的参考点归一化中心坐标 [bs, 300, 2] # inter_references: 6层decoder学习到的参考点归一化中心坐标 [6, bs, 300, 2] # one-stage=[n_decoder, bs, num_query, 2] two-stage=[n_decoder, bs, num_query, 4] # enc_outputs_class = enc_outputs_coord_unact = None # [two-stage] # query_embeds = None hs, init_reference, inter_references, enc_outputs_class, enc_outputs_coord_unact = self.transformer(srcs, masks, pos, query_embeds) outputs_classes = [] # 分类结果 outputs_coords = [] # 回归结果 for lvl in range(hs.shape[0]): if lvl == 0: # [bs, 300, 2] xy reference = init_reference else: reference = inter_references[lvl - 1] # [bs, 300, 2] -> [bs, 300, 2] 反归一化 因为reference在定义的时候就sigmoid归一化了 reference = inverse_sigmoid(reference) # 分类头 1个全连接层 [bs, 300, 256] -> [bs, 300, num_classes] outputs_class = self.class_embed[lvl](hs[lvl]) # 回归头 3个全连接层 [bs, 300, 256] -> [bs, 300, 4] xywh xy是偏移量 tmp = self.bbox_embed[lvl](hs[lvl]) if reference.shape[-1] == 4: tmp += reference else: assert reference.shape[-1] == 2 tmp[..., :2] += reference # 偏移量 + 参考点坐标 -> 最终xy坐标 outputs_coord = tmp.sigmoid() # xywh -> 归一化 outputs_classes.append(outputs_class) outputs_coords.append(outputs_coord) outputs_class = torch.stack(outputs_classes) # [6, bs, 300, 91] outputs_coord = torch.stack(outputs_coords) # [6, bs, 300, 4] out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]} if self.aux_loss: out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord) if self.two_stage: enc_outputs_coord = enc_outputs_coord_unact.sigmoid() out['enc_outputs'] = {'pred_logits': enc_outputs_class, 'pred_boxes': enc_outputs_coord} # 'pred_logits': 最后一层的分类头输出 [bs, 300, num_classes] # 'pred_boxes': 最后一层的回归头输出 [bs, 300, xywh(归一化)] # 'aux_outputs': 其他中间5层的分类头和输出头 return out @torch.jit.unused def _set_aux_loss(self, outputs_class, outputs_coord): # this is a workaround to make torchscript happy, as torchscript # doesn't support dictionary with non-homogeneous values, such # as a dict having both a Tensor and a list. return [{'pred_logits': a, 'pred_boxes': b} for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]2.4、高配版
仔细看上面的源码会发现,作者还实现了高配版的deformable-detr,这涉及到两个改进策略:iterative bounding box refinement & two-stage。
2.4.1、iterative bounding box refinement
思想:翻译过来就是通过不断的迭代对bbox框进行校正,类似cascaded head那样,实际上也是coarse-to-fine不断矫正的一个过程。具体做法:每一层decoder运行之后,都会将这层decoder输出的output送入非共享的bbox head中,根据当前层预测得到的bbox xy坐标,对reference_points进行矫正,得到矫正后的reference_points,并以先验的reference_points送入下一层decoder,继续执行。所以和普通版不同的是,iterative bounding box refinement在每一次decoder中的reference_points都是不同的(简单版是相同的)。
注意:1. 各层的检测头部是不共享参数的;2. 校正后的bbox梯度会被阻断(detach),不会跨层传播
第一步、定义self.transformer.decoder.bbox_embed
DeformableDETR类:
# iterative bounding box refinement # 对decoder每层都有不同的分类头和回归头 这里使用_get_clones(deepcopy) 则不同分类头和回归头参数不共享 if with_box_refine: # 如果是two stage 则num_pred=7 最后一层就是第一阶段中proposal的预测 self.class_embed = _get_clones(self.class_embed, num_pred) self.bbox_embed = _get_clones(self.bbox_embed, num_pred) nn.init.constant_(self.bbox_embed[0].layers[-1].bias.data[2:], -2.0) # hack implementation for iterative bounding box refinement # 不使用iterative bounding box refinement时self.transformer.decoder.bbox_embed=None # 反之decoder每一层都会预测bbox偏移量 使用这一层bbox偏移量对上一层的预测输出进行矫正 self.transformer.decoder.bbox_embed = self.bbox_embed else: nn.init.constant_(self.bbox_embed.layers[-1].bias.data[2:], -2.0) # 6层decoder共享同一个分类头/回归头 共享参数 self.class_embed = nn.ModuleList([self.class_embed for _ in range(num_pred)]) # 6层 self.bbox_embed = nn.ModuleList([self.bbox_embed for _ in range(num_pred)]) # 6层 self.transformer.decoder.bbox_embed = None第二步、矫正每层decoder的参考点
DeformableTransformerDecoder类:
# hack implementation for iterative bounding box refinement# 使用iterative bounding box refinement 这里的self.bbox_embed就不是None# 如果没有iterative bounding box refinement那么reference_points是不变的# 每层参考点都会根据上一层的输出结果进行矫正if self.bbox_embed is not None: tmp = self.bbox_embed[lid](output) # [bs, 300, 256] -> [bs, 300, 4(xywh)] if reference_points.shape[-1] == 4: # two stage new_reference_points = tmp + inverse_sigmoid(reference_points) new_reference_points = new_reference_points.sigmoid() else: # one stage assert reference_points.shape[-1] == 2 new_reference_points = tmp # 根据decoder每层解码的特征图->回归头(不共享参数) 得到相对参考点的偏移量xy # 然后再加上参考点坐标(反归一化),再进行sigmoid归一化 得到矫正的参考点 new_reference_points[..., :2] = tmp[..., :2] + inverse_sigmoid(reference_points) new_reference_points = new_reference_points.sigmoid() # reference_points: [bs, 300, 2] -> [bs, 300, 4] # .detach() 取消了梯度 因为这个参考点在各层相当于作为先验的角色 reference_points = new_reference_points.detach()第三步、MSDeformAttn中获取采样点
# N, Len_q, n_heads, n_levels, n_points, 2 if reference_points.shape[-1] == 2: # one stage # [4, 2] 每个(h, w) -> (w, h) offset_normalizer = torch.stack([input_spatial_shapes[..., 1], input_spatial_shapes[..., 0]], -1) # [bs, Len_q, 1, n_point, 1, 2] + [bs, Len_q, n_head, n_level, n_point, 2] / [1, 1, 1, n_point, 1, 2] # -> [bs, Len_q, 1, n_levels, n_points, 2] # 参考点 + 偏移量/特征层宽高 = 采样点 sampling_locations = reference_points[:, :, None, :, None, :] \ + sampling_offsets / offset_normalizer[None, None, None, :, None, :] elif reference_points.shape[-1] == 4: # two stage iterative bounding box refinement # 前两个是xy 后两个是wh # 初始化时offset是在 -n_points ~ n_points 范围之间 这里除以self.n_points是相当于把offset归一化到 0~1 # 然后再乘以宽高的一半 再加上参考点的中心坐标 这就相当于使得最后的采样点坐标总是位于proposal box内 # 相当于对采样范围进行了约束 减少了搜索空间 sampling_locations = reference_points[:, :, None, :, None, :2] \ + sampling_offsets / self.n_points * reference_points[:, :, None, :, None, 2:] * 0.52.4.2、two stage
注意:two-stage策略必须和iterative bounding box refinement策略一起使用。
核心思想: Encoder会生成特征memory,再自己生成初步proposals(其实就是特征图上的点坐标 xywh)。然后分别使用非共享检测头的分类分支对memory进行分类预测,得到对每个类别的分类结果;再用回归分支进行回归预测,得到proposals的偏移量(xywh)。再用初步proposals + 偏移量 得到第一个阶段的预测proposals。然后选取top-k个分数最高的那批预测proposals作为Decoder的参考点。并且,Decoder的object query和 query pos都是由参考点通过位置嵌入(position embedding)再接上一个全连接层 + LN层处理生成的。
第一步、定义self.transformer.decoder.class_embed和bbox_embed
deformable_detr.py:
# if two-stage, the last class_embed and bbox_embed is for region proposal generation # two stage:7个预测头 最后一个class_embed 和 bbox_embed 产生 region proposal # one stage:6个预测头 num_pred = (transformer.decoder.num_layers + 1) if two_stage else transformer.decoder.num_layers # iterative bounding box refinement # 对decoder每层都有不同的分类头和回归头 这里使用_get_clones(deepcopy) 则不同分类头和回归头参数不共享 if with_box_refine: self.class_embed = _get_clones(self.class_embed, num_pred) self.bbox_embed = _get_clones(self.bbox_embed, num_pred) nn.init.constant_(self.bbox_embed[0].layers[-1].bias.data[2:], -2.0) # hack implementation for iterative bounding box refinement # 不使用iterative bounding box refinement时self.transformer.decoder.bbox_embed=None # 反之decoder每一层都会预测bbox偏移量 使用这一层bbox偏移量对上一层的预测输出进行矫正 self.transformer.decoder.bbox_embed = self.bbox_embed else: ...if two_stage: # hack implementation for two-stage self.transformer.decoder.class_embed = self.class_embed for box_embed in self.bbox_embed: nn.init.constant_(box_embed.layers[-1].bias.data[2:], 0.0)另外还要注意的是,如果是two stage,传入transformer中的query_embeds是为空的:
# one-stage是object query # two-stage是reference points if not two_stage: self.query_embed = nn.Embedding(num_queries, hidden_dim*2) query_embeds = None if not self.two_stage: query_embeds = self.query_embed.weight # query_embeds: [300, 512] # one-stage: query_embeds = [300, 512] # two-stage: # query_embeds = None hs, init_reference, inter_references, enc_outputs_class, enc_outputs_coord_unact = self.transformer(srcs, masks, pos, query_embeds)第二步、为decoder的输入作准备,得到参考点/先验框reference_points 、query(tgt)和query pos(query_embed)
deformable_transformer.py:
先定义一些处理结构:
if two_stage: # 对Encoder输出memory进行处理:全连接层 + 层归一化 self.enc_output = nn.Linear(d_model, d_model) self.enc_output_norm = nn.LayerNorm(d_model) # 对top-k proposal box进行处理得到最终的query和query pos self.pos_trans = nn.Linear(d_model * 2, d_model * 2) self.pos_trans_norm = nn.LayerNorm(d_model * 2) else: self.reference_points = nn.Linear(d_model, 2)生成参考点/先验框reference_points xywh,xy还是和encoder一样的特征图坐标中心点,wh=0.05 * (2**i),i是第几层特征层
def gen_encoder_output_proposals(self, memory, memory_padding_mask, spatial_shapes): """得到第一阶段预测的所有proposal box output_proposals和处理后的Encoder输出output_memory memory: Encoder输出特征 [bs, H/8 * W/8 + ... + H/64 * W/64, 256] memory_padding_mask: Encoder输出特征对应的mask [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64] spatial_shapes: [4, 2] backbone输出的4个特征图的shape """ N_, S_, C_ = memory.shape # bs H/8 * W/8 + ... + H/64 * W/64 256 base_scale = 4.0 proposals = [] _cur = 0 # 帮助找到mask中每个特征图的初始index for lvl, (H_, W_) in enumerate(spatial_shapes): # 如H_=76 W_=112 # 1、生成所有proposal box的中心点坐标xy # 展平后的mask [bs, 76, 112, 1] mask_flatten_ = memory_padding_mask[:, _cur:(_cur + H_ * W_)].view(N_, H_, W_, 1) valid_H = torch.sum(~mask_flatten_[:, :, 0, 0], 1) valid_W = torch.sum(~mask_flatten_[:, 0, :, 0], 1) # grid_y = [76, 112] 76行112列 第一行全是0 第二行全是1 ... 第76行全是75 # grid_x = [76, 112] 76行112列 76行全是 0 1 2 ... 111 grid_y, grid_x = torch.meshgrid(torch.linspace(0, H_ - 1, H_, dtype=torch.float32, device=memory.device), torch.linspace(0, W_ - 1, W_, dtype=torch.float32, device=memory.device)) # grid = [76, 112, 2(xy)] 这个特征图上的所有坐标点x,y grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1) scale = torch.cat([valid_W.unsqueeze(-1), valid_H.unsqueeze(-1)], 1).view(N_, 1, 1, 2) # [bs, 1, 1, 2(xy)] # [76, 112, 2(xy)] -> [1, 76, 112, 2] + 0.5 得到所有网格中心点坐标 这里和one-stage的get_reference_points函数原理是一样的 grid = (grid.unsqueeze(0).expand(N_, -1, -1, -1) + 0.5) / scale # 2、生成所有proposal box的宽高wh 第i层特征默认wh = 0.05 * (2**i) wh = torch.ones_like(grid) * 0.05 * (2.0 ** lvl) # 3、concat xy+wh -> proposal xywh [bs, 76x112, 4(xywh)] proposal = torch.cat((grid, wh), -1).view(N_, -1, 4) proposals.append(proposal) _cur += (H_ * W_) # concat 4 feature map proposals [bs, H/8 x W/8 + ... + H/64 x W/64] = [bs, 11312, 4] output_proposals = torch.cat(proposals, 1) # 筛选一下 xywh 都要处于(0.01,0.99)之间 output_proposals_valid = ((output_proposals > 0.01) & (output_proposals < 0.99)).all(-1, keepdim=True) # 这里为什么要用log(x/1-x)这个公式??? output_proposals = torch.log(output_proposals / (1 - output_proposals)) # mask的地方是无效的 直接用inf代替 output_proposals = output_proposals.masked_fill(memory_padding_mask.unsqueeze(-1), float('inf')) # 再按条件筛选一下 不符合的用用inf代替 output_proposals = output_proposals.masked_fill(~output_proposals_valid, float('inf')) output_memory = memory output_memory = output_memory.masked_fill(memory_padding_mask.unsqueeze(-1), float(0)) output_memory = output_memory.masked_fill(~output_proposals_valid, float(0)) # 对encoder输出进行处理:全连接层 + LayerNorm output_memory = self.enc_output_norm(self.enc_output(output_memory)) return output_memory, output_proposals再根据参考点/先验框reference_points xywh ,再利用非共享参数分类头和回归头的第7个head分别对处理过的Encoder的输出结果output_memory进行分类和回归。
提取分类结果第1个类别(其实我觉得这样做不是很合理,直接二分类判断前景背景不是更好嘛?)前topk个初步参考点output_proposals 的回归头结果作为Encoder层中的最终参考点reference_points ,再用这些reference_points 生成Docder的query和query pos:
# [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256] memory = self.encoder(src_flatten, spatial_shapes, level_start_index, valid_ratios, lvl_pos_embed_flatten, mask_flatten) # 为decoder的输入作准备:得到参考点、query embedding(tgt)和query pos(query_embed) # one-stage和two-stage的生成方式不同 # two-stage: 参考点=Encoder预测的top-k(300个)得分最高的proposal boxes,然后对参考点进行位置嵌入生成query和query pos # one-stage: query和query pos就是预设的query_embed,然后将query_embed经过全连接层输出2d参考点(归一化的中心坐标) bs, _, c = memory.shape if self.two_stage: # 对memory进行处理得到output_memory: [bs, H/8 * W/8 + ... + H/64 * W/64, 256] # 并生成初步output_proposals: [bs, H/8 * W/8 + ... + H/64 * W/64, 4] 其实就是特征图上的一个个的点坐标 output_memory, output_proposals = self.gen_encoder_output_proposals(memory, mask_flatten, spatial_shapes) # hack implementation for two-stage Deformable DETR # 多分类:[bs, H/8 * W/8 + ... + H/64 * W/64, 256] -> [bs, H/8 * W/8 + ... + H/64 * W/64, 91] # 其实个人觉得这里直接进行一个二分类足够了 enc_outputs_class = self.decoder.class_embed[self.decoder.num_layers](output_memory) # 回归:预测偏移量 + 参考点坐标 [bs, H/8 * W/8 + ... + H/64 * W/64, 4] # two-stage 必须和 iterative bounding box refinement一起使用 不然bbox_embed=None 报错 enc_outputs_coord_unact = self.decoder.bbox_embed[self.decoder.num_layers](output_memory) + output_proposals # 得到参考点reference_points/先验框 topk = self.two_stage_num_proposals # 300 # 直接用第一个类别的预测结果来算top-k,代表二分类 # 如果不使用iterative bounding box refinement那么所有class_embed共享参数 导致第二阶段对解码输出进行分类时都会偏向于第一个类别 # topk_proposals: [bs, 300] top300 index topk_proposals = torch.topk(enc_outputs_class[..., 0], topk, dim=1)[1] # topk_coords_unact: top300个分类得分最高的index对应的预测bbox [bs, 300, 4] topk_coords_unact = torch.gather(enc_outputs_coord_unact, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, 4)) topk_coords_unact = topk_coords_unact.detach() # 以先验框的形式存在 取消梯度 reference_points = topk_coords_unact.sigmoid() # 得到归一化参考点坐标 最终会送到decoder中作为初始的参考点 init_reference_out = reference_points # 生成Docder的query和query pos # 先对top-k proposal box进行位置编码,编码方式是给xywh每个都赋予128维 其中每个128维使用sine编码 最后用全连接层和LN处理 # 最终得到pos_trans_out: [bs, 300, 512] 前256为query pos(x、y信息) 后256为query(w、h信息) pos_trans_out = self.pos_trans_norm(self.pos_trans(self.get_proposal_pos_embed(topk_coords_unact))) query_embed, tgt = torch.split(pos_trans_out, c, dim=2) else: # 默认执行 # 随机初始化 query_embed = nn.Embedding(num_queries, hidden_dim*2) # [300, 512] -> [300, 256] + [300, 256] query_embed, tgt = torch.split(query_embed, c, dim=1) # 初始化query pos [300, 256] -> [bs, 300, 256] query_embed = query_embed.unsqueeze(0).expand(bs, -1, -1) # 初始化query embedding [300, 256] -> [bs, 300, 256] tgt = tgt.unsqueeze(0).expand(bs, -1, -1) # 由query pos接一个全连接层 再归一化后的参考点中心坐标 [bs, 300, 256] -> [bs, 300, 2] reference_points = self.reference_points(query_embed).sigmoid() init_reference_out = reference_points # 初始化的归一化参考点坐标 [bs, 300, 2]第三步、输入decoder中
注意这里的参考点(相当于anchor)是4D的:
# decoder # tgt: 初始化query embedding [bs, 300, 256] # reference_points: 由query pos接一个全连接层 再归一化后的参考点中心坐标 [bs, 300, 2] two-stage=[bs, 300, 4] # query_embed: query pos[bs, 300, 256] # memory: Encoder输出结果 [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256] # spatial_shapes: [4, 2] 4个特征层的shape # level_start_index: [4, ] 4个特征层flatten后的开始index # valid_ratios: [bs, 4, 2] # mask_flatten: 4个特征层flatten后的mask [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64] # hs: 6层decoder输出 [n_decoder, bs, num_query, d_model] = [6, bs, 300, 256] # inter_references: 6层decoder学习到的参考点归一化中心坐标 [6, bs, 300, 2] # one-stage=[n_decoder, bs, num_query, 2] two-stage=[n_decoder, bs, num_query, 4] hs, inter_references = self.decoder(tgt, reference_points, memory, spatial_shapes, level_start_index, valid_ratios, query_embed, mask_flatten)所以在MSDeformAttn计算采样点是不一样的:
# N, Len_q, n_heads, n_levels, n_points, 2 if reference_points.shape[-1] == 2: # one stage # [4, 2] 每个(h, w) -> (w, h) offset_normalizer = torch.stack([input_spatial_shapes[..., 1], input_spatial_shapes[..., 0]], -1) # [bs, Len_q, 1, n_point, 1, 2] + [bs, Len_q, n_head, n_level, n_point, 2] / [1, 1, 1, n_point, 1, 2] # -> [bs, Len_q, 1, n_levels, n_points, 2] # 参考点 + 偏移量/特征层宽高 = 采样点 sampling_locations = reference_points[:, :, None, :, None, :] \ + sampling_offsets / offset_normalizer[None, None, None, :, None, :] # two stage + iterative bounding box refinement elif reference_points.shape[-1] == 4: # 前两个是xy 后两个是wh # 初始化时offset是在 -n_points ~ n_points 范围之间 这里除以self.n_points是相当于把offset归一化到 0~1 # 然后再乘以宽高的一半 再加上参考点的中心坐标 这就相当于使得最后的采样点坐标总是位于proposal box内 # 相当于对采样范围进行了约束 减少了搜索空间 sampling_locations = reference_points[:, :, None, :, None, :2] \ + sampling_offsets / self.n_points * reference_points[:, :, None, :, None, 2:] * 0.5好了two-stage的主体代码就到这里了。
三、总结
3.1、Deformable DETR VS DETR
多尺度特征,并且使用scale-level pos embedding,用于区分不同的特征层;提出多尺度可变形注意力代替Encoder中的自注意力和Decoder中的交叉注意力;引入了参考点,某种程度上起到先验的作用(因为第2点);检测头部的回归分支预测的是bbox偏移量而非绝对坐标值(因为第3点);升级版:迭代的框校正策略 和 两阶段模式;3.2、one-stage全部流程
提前在DeformableDETR中生成6个共享分类头和6个共享回归头。
backbone输出3个不同尺度的特征,然后接上3个1x1conv和1个3x3conv,最后得到4个不同尺度的特征图;生成Encoder相对4个特征图固定的参考点xy坐标+4个不同尺度的特征图,输入encoder,得到增强版的特征图memory:[bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256];先随机初始化query_embed,再拆分为query(tgt)和query pos(query_embed),再用query pos(query_embed)接一个全连接层+sigmoid,得到Decoder归一化后的参考点中心坐标reference_points:[bs, 300, 2];将query、query pos、reference_points、memory送入decoder中,输出解码后的6个decoder输出特征图hs[6, bs, 300, 256],以及6层decoder参考点归一化中心坐标inter_references[6, bs, 300, 2](全部相同 都等于reference_points);6个decoder输出特征图 -> 共享分类头(1个全连接层),得到分类结果[6, bs, 300, 91];6个decoder输出特征图 -> 共享回归头(3个全连接层),得到回归中心点xy的偏移量和wh->[bs, 300, 4],xy的偏移量 + 参考点xy反归一化 -> 最终xy坐标,再对xywh归一化得到最终的回归结果[6, bs, 300, 4];3.2、one-stage + 框矫正策略全部流程
核心思想:每一层decoder运行之后,都会将这层decoder输出的output送入非共享的bbox head中,根据当前层预测得到的bbox xy坐标,对reference_points进行矫正,得到矫正后的reference_points,并以先验的知识代替下一层decoder的reference_points。代替原先的固定的reference_points,通过这种利用decoder不断矫正reference_points的思路来不断矫正bbox。
提前在DeformableDETR中生成6个非共享分类头和6个非共享回归头。
backbone输出3个不同尺度的特征,然后接上3个1x1conv和1个3x3conv,最后得到4个不同尺度的特征图;生成Encoder相对4个特征图固定的参考点xy坐标+4个不同尺度的特征图,输入encoder,得到增强版的特征图memory:[bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256];先随机初始化query_embed,再拆分为query(tgt)和query pos(query_embed),再用query pos(query_embed)接一个全连接层+sigmoid,得到Decoder归一化后的参考点中心坐标reference_points:[bs, 300, 2];将query、query pos、reference_points、memory送入一层decoder中,输出当前层解码后的输出特征图output[bs, 300, 256]。并利用未共享的bbox_embed对output进行bbox预测,得到偏移量xywh,再将reference_points反归一化 + xy偏移量得到新的new_reference_points[bs, 300, 2],并将new_reference_points作为下一层decoder的reference_points。最终生成6个decoder的输出特征图hs[6, bs, 300, 256]和6层decoder的归一化参考点inter_references[6, bs, 300, 2](全部不相同,每一层decoder的inter_references都会根据当前decoder层的解码特征output对其进行矫正,得到新的reference_points,作为下一个decoder的reference_points,一层一层的矫正reference_points,以更好的回归bbox)6个decoder输出特征图 -> 非共享分类头(1个全连接层),得到分类结果[6, bs, 300, 91];6个decoder输出特征图 -> 非共享回归头(3个全连接层),得到回归中心点xy的偏移量和wh->[bs, 300, 4],xy的偏移量 + 参考点xy反归一化 -> 最终xy坐标,再对xywh归一化得到最终的回归结果[6, bs, 300, 4];3.3、two stage策略 + 框矫正策略全部流程
Encoder会生成特征memory,再自己生成初步proposals(其实就是特征图上的点坐标 xywh)。然后分别使用非共享检测头的分类分支对memory进行分类预测,得到对每个类别的分类结果;再用回归分支进行回归预测,得到proposals的偏移量(xywh)。再用初步proposals + 偏移量 得到第一个阶段的预测proposals。然后选取top-k个分数最高的那批预测proposals作为Decoder的参考点。并且,Decoder的object query和 query pos都是由参考点通过位置嵌入(position embedding)再接上一个全连接层 + LN层处理生成的。
提前在DeformableDETR中生成7个非共享分类头和7个非共享回归头,其中第7个是用于在第一阶段的。
backbone输出3个不同尺度的特征,然后接上3个1x1conv和1个3x3conv,最后得到4个不同尺度的特征图;
生成Encoder的相对4个特征图固定的参考点xy坐标+4个不同尺度的特征图,输入encoder,得到增强版的特征图memory:[bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256];
生成Decoder的初步参考点/先验框output_proposals xywh,xy还是和encoder一样的特征图坐标中心点,wh=0.05 * (2**i),i是第几层特征层,并对Encoder输出进行处理得到output_memory;
利用非共享参数分类头和回归头的第7个head分别对处理过的Encoder的输出结果output_memory进行分类和回归,提取分类结果第1个类别前topk个初步参考点output_proposals 的回归头结果作为Encoder层中的最终参考点reference_points;
再用这些最终的参考点reference_points 生成Docder需要的的query和query pos
将query、query pos、reference_points、memory送入一层decoder中,输出当前层解码后的输出特征图output[bs, 300, 256]。并利用未共享的bbox_embed对output进行bbox预测,得到偏移量xywh,再将reference_points反归一化 + xy偏移量得到新的new_reference_points[bs, 300, 2],并将new_reference_points作为下一层decoder的reference_points。
最终生成6个decoder的输出特征图hs[6, bs, 300, 256]和6层decoder的归一化参考点inter_references[6, bs, 300, 2](全部不相同,每一层decoder的inter_references都会根据当前decoder层的解码特征output对其进行矫正,得到新的reference_points,作为下一个decoder的reference_points,一层一层的矫正reference_points,以更好的回归bbox)
6个decoder输出特征图 -> 非共享分类头(1个全连接层),得到分类结果[6, bs, 300, 91];
6个decoder输出特征图 -> 非共享回归头(3个全连接层),得到回归中心点xy的偏移量和wh->[bs, 300, 4],xy的偏移量 + 参考点xy反归一化 -> 最终xy坐标,再对xywh归一化得到最终的回归结果[6, bs, 300, 4];
3.4、两个策略的本质是什么?
Iterative Bounding Box Refinement:根据每一层decoder的输出对下一层decoder的参考点reference points进行矫正(原本参考点都是相同的)。
具体来说:每一层decoder运行之后,都会将这层decoder输出的output送入对应的非共享的bbox head中,根据当前层预测得到的bbox xy坐标,对reference_points进行矫正,得到矫正后的reference_points,并以先验的知识代替下一层decoder的reference_points,不断矫正bbox。
two-stage:根据Encoder的输出对参考点进行筛选,得到分类分数最高的top-k个参考点作为proposals,并且作为Decoder的参考点。而且Decoder中的query(tgt)和query pos都是由这些proposals生成的。
具体来说:将Encoder的输出输入到第7个非共享分类头和第7个非共享回归头,取第1个类别前topk个参考点作为筛选后的参考点,筛选得到回归平移量 + 参考点坐标 = 第一个阶段Encoder预测的proposals(作为第二个阶段Decoder的参考点)。
本质:两个策略都是通过改变decoder的参考点的质量来提升检测效果的。
四、几个问题思考
4.1、 为什么MSDeformAttn中的attention weight不是transform里面那样key来与query交互计算,而是由query经过全连接层得到的?
我们知道,在Transformer中,注意力权重是由query和key交互计算得到的。然而,在这里却像开挂般直接通过query经全连接层输出得到,为什么呢?要回答这个问题,就要先看看Deformable DETR的参考点(Reference Points)和 query之间的关系。
Encoder:参考点是特征点本身的位置坐标(特征坐标的中心点,如0.5 0.5),query = 特征 + scale-level position embedding;
Decoder:1阶段时,query obj和query pos都来自预设的query_embed,参考点由query pos经全连接层生成,最终query=query obj + query pos;2阶段时,由参考点经过位置嵌入生成query embedding和object query。
所以,综上参考点(reference points)和 query是存在一一对应的关系的(你生我,我生你)。所以,基于参考点位置采样插值出来的value自然就可以通过和query通过线性变换得到的注意力权重对应起来,也就不需要key和query来交互计算得到注意力权重了。
还有个问题:在Decoder中,两阶段由reference points生成query embedding是通过position embedding,而1-stage时由query embedding生成reference points时却用全连接层呢?
因为两阶段时参考点是从Encoder输出筛选出来的proposals,本身就有一定的物体位置信息了(虽然这个位置信息可能还不准确),因次有需要将此时的位置信息记录下来(通过position embedding 生成 query embedding);而一阶段,预设的query embedding本身就是随机初始化的,盲猜的东西,因此用线性变换来做维度映射得到参考点比较合理(自己去学习),因为毕竟其本身并没有实际意义的位置信息。
4.2、为什么检测头回归分支回归的是偏移量而非绝对坐标值?
因为相比于DETR,Deformable DETR多了一个很显眼的东西,参考点Reference Points。我们知道采样点的坐标 = 参考点坐标 + 坐标偏移量,也就是说采样点其实是在参考点附近的,
所以我们直接回归基于参考点的偏移量来预测采样点,这样比直接预测绝对坐标更易优化,更有利于模型学习。(这点和YOLO中的回归偏移量一个原理)
另外,由于采样特征中注入了注意力,而预测框是基于采样特征回归得到的,loss是基于回归结果计算的,梯度是通过loss反向传播的,因此最终学习到的注意力权重就会和预测框有相对较强的联系,这也起到了加速收敛的效果。
4.3、为什么普通版class_embed和bbox_embed是共享版的,而iterative bounding box refinement和two-stage的class_embed和bbox_embed是非共享的?
这一点在上面的源码注释有提到。因为第二阶段是通过取第一个类别的topk个第一阶段结果作为最终的proposals,所以如果是共享参数的化,最终第二个阶段预测的结果都会倾向于预测第一个类别。
所以我觉得这里的topk选取有问题,直接用一个二分类判断前背景不是更好嘛?
五、End
最后总结下整篇论文的思路和hightlight,方便以后自己复习回顾。
本篇论文作者洞悉了DETR收敛慢和小目标检测效果差的原因在于Transformer的注意力计算模块:它对全局密集的关系进行建模,这使得模型需要长时间去学习(关注)真正有意义的稀疏位置,同时还带来了高复杂度的计算与空间资源消耗。
联想到稀疏空间位置的学习是DCN的强项,但是DCN又却反关系建模能力,所以作者将DCN和Transformer结合在一起提出了Deformable DETR。
改进点:
多尺度特征,并且使用scale-level pos embedding,用于区分不同的特征层;提出多尺度可变形注意力代替Encoder中的自注意力和Decoder中的交叉注意力;引入了参考点,某种程度上起到先验的作用(因为第2点);检测头部的回归分支预测的是bbox偏移量而非绝对坐标值(因为第3点);升级版:迭代的框校正策略 和 两阶段模式;这篇论文的思想还是很好的,而且源码的代码量也很大,细节特别多,我大概断断续续看了10天左右才大致理清了模型部分的代码(太菜了)。
其实到这里我已经看完了DETR和Deformable DETR的源码了,但是我感觉对Decoder和Decoder中的query还是理解的不是很深,模模糊糊的感觉。不过没关系,在我讲解的下一篇论文DAB DETR中会深入的探讨Decoder 中的 query以及Decoder机制。
我会继续坚持分享源码讲解系列,下期再见~
Reference
b站: 深入理解DETR 系列中【Deformable DETR】
知乎: Deformable DETR: 基于稀疏空间采样的注意力机制,让DCN与Transformer一起玩!