文章目录
前言一、Pandas简介1.1 什么是Pandas1.2 Pandas应用 二、Series结构2.1 Series简介2.2 基本使用 三、DataFrame结构3.1 DataFrame简介3.2 基本使用 四、Pandas-CSV4.1 CSV简介4.2 读取CSV文件4.3 数据处理 五、数据清洗5.1 数据清洗的方法5.2 清洗案例 总结
前言
大家好,我是初心,很高兴再次和大家见面。这篇文章主要讲解Python数据分析三剑客之一——Pandas的数据分析运算,收录于初心的《大数据》专栏。
? 个人主页:初心%个人主页
? 个人简介:大家好,我是初心,一名正在努力的双非二本院校计算机专业学生
? 座右铭:理想主义的花,终究会盛开在浪漫主义的土壤里!???
? 欢迎大家:这里是CSDN,我记录知识的地方,喜欢的话请三连,有问题请私信?

一、Pandas简介
1.1 什么是Pandas
Pandas 是基于NumPy 的一种工具,该工具是为了 解决数据分析任务而创建的 。官方对它的解释是 “强大的Python数据分析支持库” ,Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。Pandas官网
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
1.2 Pandas应用
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
Series 是一种类似于 一维数组 的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
DataFrame 是一个 表格型 的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典。
二、Series结构
2.1 Series简介
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,构造函数如下:
pandas.Series( data, index, dtype, name, copy)| 参数 | 说明 |
|---|---|
| data | 一组数据(ndarray 类型) |
| index | 数据索引标签,如果不指定,默认从 0 开始 |
| dtype | 数据类型,默认会自己判断 |
| name | 设置名称 |
| copy | 拷贝数据,默认为 False |
Series简单示例代码和输出结果如下:
import pandas as pd # 数据a = [1,2,3]# Series对象,会将列表数据转化为一列myvar = pd.Series(a)print(myvar)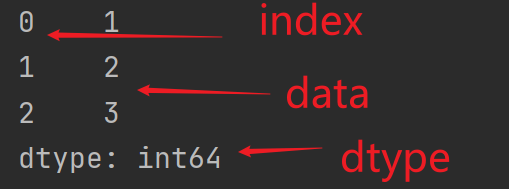
2.2 基本使用
根据索引值读取数据# 下标print(myvar[0])# 切片print(myvar[:3])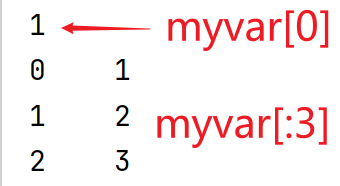
myvar = pd.Series(a,index=["x","y","z"])
sites = {1: 'Google', 2: 'Edge', 3: 'Firefox'}myvar = pd.Series(sites)print(myvar)
myvar = pd.Series(sites,name='Pandas Test')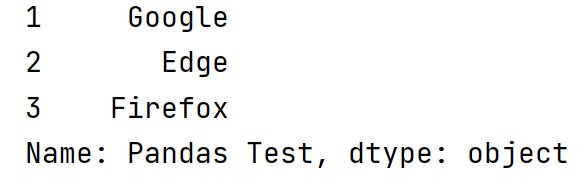
三、DataFrame结构
3.1 DataFrame简介
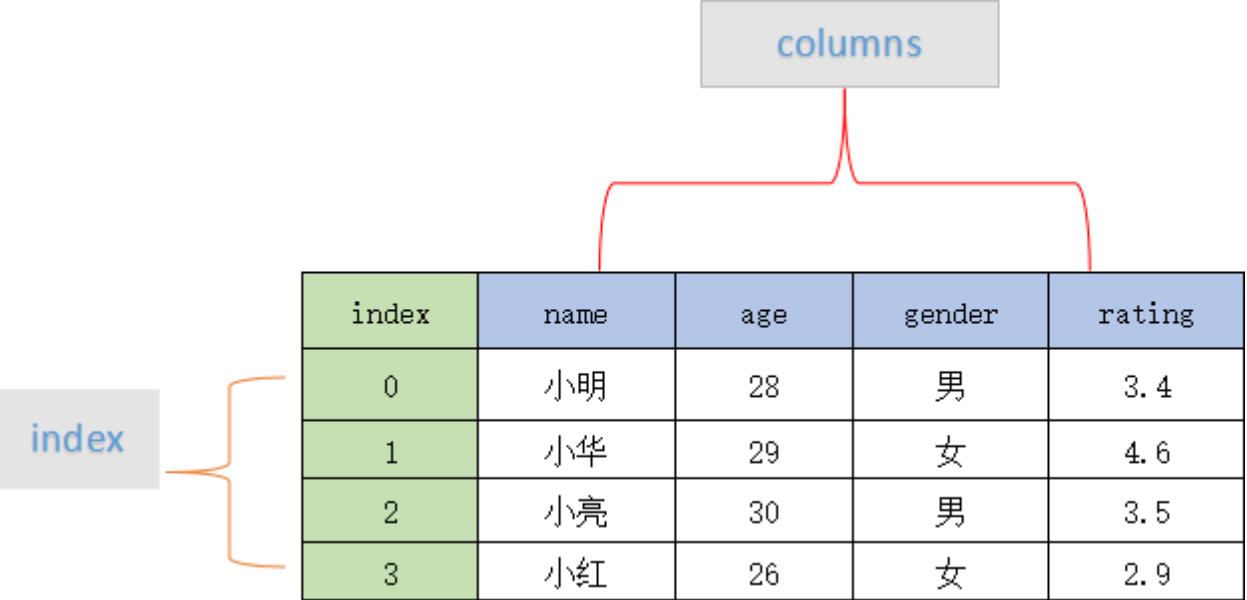
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。
DataFrame 的 每一行数据 都可以看成一个 Series 结构,只不过,DataFrame 为这些行中每个数据值增加了一个列标签。因此 DataFrame 其实是从 Series 的基础上演变而来。
可以这么说,掌握了 DataFrame 的用法,你就拥有了学习数据分析的基本能力。
3.2 基本使用
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)参数的含义和 Series 类似,column 表示列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
DataFrame 简单示例代码和输出结果如下:
import pandas as pd# 数据data = [['apple',10],['banana',12],['orange',31]]# 指定列索引df = pd.DataFrame(data,columns=['type','number'],dtype=float)print(df)import pandas as pd# ndarrays 数据data = {'type':['apple','banana','orange'],'age':[10,12,31]}# 创建dataframe对象df = pd.DataFrame(data)print(df)
# 字典列表data1 = [{'a':1,'b':2},{'a':10,'b':20,'c':30}]df = pd.DataFrame(data1)print(df)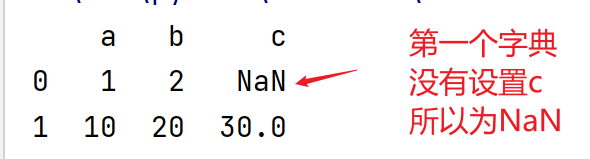
data = { 'calories': [420, 380, 390], 'duration': [50, 40, 45]}df = pd.DataFrame(data)# 返回第一行print(df.loc[1])print('*'*20)# 切片,返回前2行print(df.loc[:1])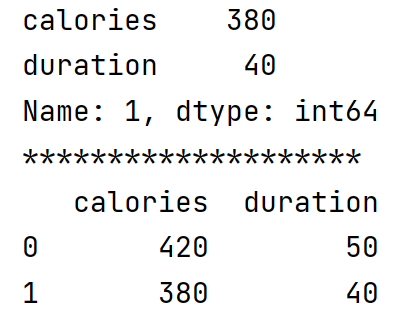
四、Pandas-CSV
4.1 CSV简介
CSV(Comma-Separated Values, 逗号分隔值 ,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
4.2 读取CSV文件
在 Pandas 中用于读取文本的函数有两个,分别是: read_csv() 和 read_table() ,它们能够 自动地将表格数据转换为 DataFrame 对象 。其中 read_csv 的语法格式如下:
pandas.read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer',names=None, index_col=None, usecols=None)这里要用到一个CSV文件(nba.csv),放在文末扫码可以领取。
read_csv() 函数简单示例代码和输出结果如下:
import pandas as pddf = pd.read_csv('nba.csv')print(df)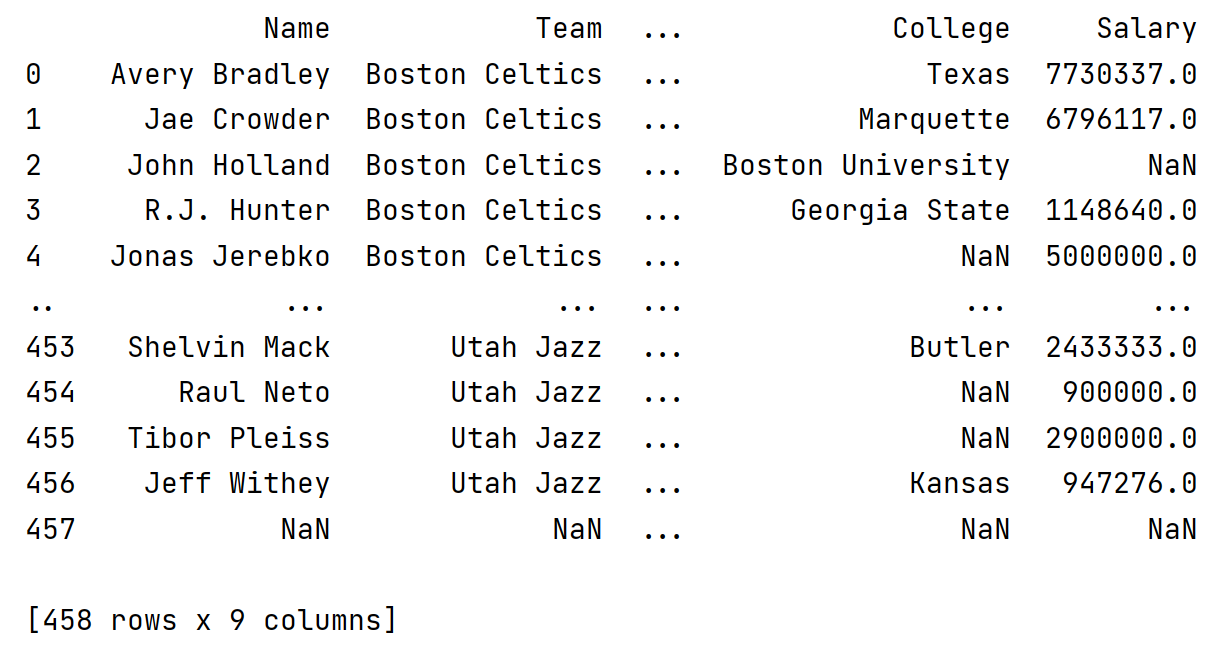
打印 dataframe 对象默认返回数据的前后5行,中间部分以点代替,如上图所示。要返回全部数据需要使用 to_string()函数。
存储 csv 文件使用 to_csv() 方法将 dataframe 对象存储为 csv 文件。
import pandas as pddf = pd.read_csv('nba.csv')print(df.head(3))# 存储前三行数据到 test.csv 文件df.to_csv('test.csv')4.3 数据处理
head() 函数head(n) 函数用于读取前 n 行,如果不填写 n ,默认返回5行。
print(df.head(3))tail(n) 函数用于读取后 n 行,如果不填写 n ,默认返回5行。
print(df.tail(3))info() 函数用于返回表格的一些基本信息。
print(df.info())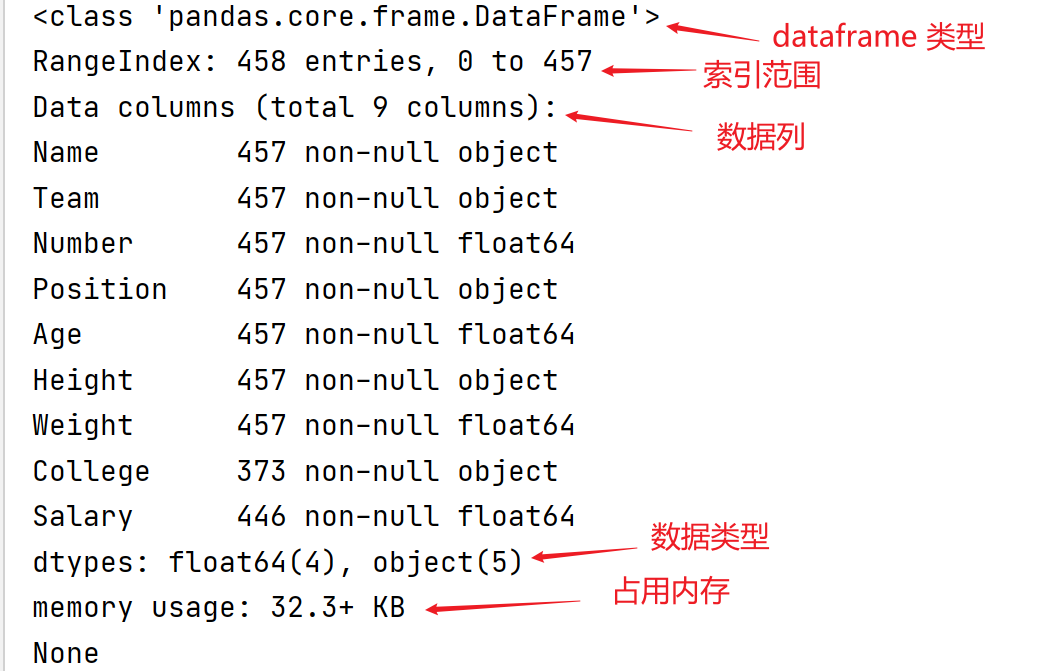
五、数据清洗
数据清洗是对一些没有用的数据进行处理的过程。
很多数据集存在 数据缺失、数据格式错误、错误数据或重复数据 的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理。
我们可以利用 Pandas包来进行数据清洗。
5.1 数据清洗的方法
| 异常类型 | 处理方法 |
|---|---|
| 重复值 | 一般采取删除法来处理,但有些重复值不能删除,例如订单明细数据或交易明细数据等。 |
| 缺失值 | 可以采取直接删除法,替换法或者插值法,常用的替换法有均值替换、前向、后向替换和常数替换 |
| 异常值 | 偏离正常范围的值,不是错误值,异常值往往采取盖帽法或者数据离散化 |
| 错误值 | 指的是数据格式错误,往往采取转换为相同格式的数据 |
5.2 清洗案例
清洗空值如果我们要删除包含空字段的行,可以使用 dropna() 方法 ,语法格式如下:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)| 参数 | 说明 |
|---|---|
| axis | 默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。 |
| how | 默认为 ‘any’ 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how=‘all’ 一行(或列)都是 NA 才去掉这整行。 |
| thresh | 设置需要多少非空值的数据才能保留。 |
| subset | 想要检查的列。如果是多个列,可以使用列名的 list 作为参数 |
| inplace | 如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。 |
使用 isnull() 函数 判断各个单元格是否为空。
import pandas as pd# 读取csv文件df = pd.read_csv('../csv/nba.csv')temp = df.head(6)# 判断各个单元格是否为空print(temp['College'].isnull())
Pandas 将 NAN 当作空值处理,我们也可以再定义空值 。
# 定义当作空值处理的数据missing_data = ['n/a','na','--']# 读取csv文件df = pd.read_csv('../csv/nba.csv',na_values=missing_data)我们可以用 fillna() 函数来替换一些空值。
# 替换所有df2 = df.fillna(123456)# 替换某一列df2 = df['College'].fillna(12345)Pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数) 。
# 临时dataframe对象temp = df.head(6)# 计算平均值mean = temp['Age'].mean()# 中位数median = temp['Age'].median()# 众数mode = temp['Age'].mode()# 使用中位数替换空值print(temp['College'].fillna(mean))数据格式错误的单元格会使数据分析变得困难,甚至不可能。我们可以通过包含空单元格的行,或者将列中的所有单元格转换为相同格式的数据。
to_datetime() 是格式化日期的函数。
我们可以对异常的数据进行替换或者移除。
import pandas as pd# 异常数据1823person = { 'name': ['xiaoguo', 'xiaojiang'], 'age': [20, 1823]}df = pd.DataFrame(person)# 修改异常数据df.loc(1)['age'] = 18print(df)如果我们要清洗重复数据,可以使用 duplicated() 函数 判断和 drop_duplicates() 函数 删除。
# 判断是否重复sign = df.duplicated('age')# 删除重复行temp = df.drop_duplicates('age')总结
以上就是本次要分享给大家的内容啦!本文简单介绍了 Pandas中的两种数据类型——Series和DataFrame,以及 csv 文件的读取,利用Pandas进行数据清洗。
? 初心致力于打造软件开发和大数据领域最通俗易懂的文章,希望能帮助到你。
? 当你真正喜欢做一件事时,自律就会成为你的本能。
? 本文由初心原创,首发于CSDN博客,喜欢的话记得点赞收藏哦!我们下期再见!