文章目录
贡献模型结构实验结论
贡献
提出用于高分辨率图像修复的aggregated contextual transformations(AOT),它允许捕获信息丰富的远程上下文和丰富的感兴趣模式,以进行上下文推理。设计了一个新的掩模预测任务来训练用于图像修复的判别器,使判别器可以区分真实patch和合成patch,从而有助于生成器合成细粒度纹理。模型结构
整体结构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yESa6D4H-1665994031910)(C:/Users/Husheng/Desktop/%E8%AE%BA%E6%96%87%E7%AC%94%E8%AE%B0.assets/image-20221016174451614.png)]](http://zhangshiyu.com/zb_users/upload/2023/04/20230411080134168117129498126.png)
AOT block
生成器先通过几层标准的卷积层进行编码,再通过AOT块,最后再通过转置卷积进行解码。
AOT块通过三个步骤采用拆分转换合并策略:
(1)拆分:AOT块将标准卷积的卷积核拆分为多个子核,每个子卷积核具有较少的输出通道;
(2)转换:每个子卷积核具有不同的膨胀率。较大的膨胀率使子卷积核能够关注到输入图像的较大区域,而使用较小膨胀率的子核则关注较小感受野的局部模式。
(3)聚合:来自不同感受野的上下文转换最终通过串联和标准卷积进行聚合,以进行特征融合。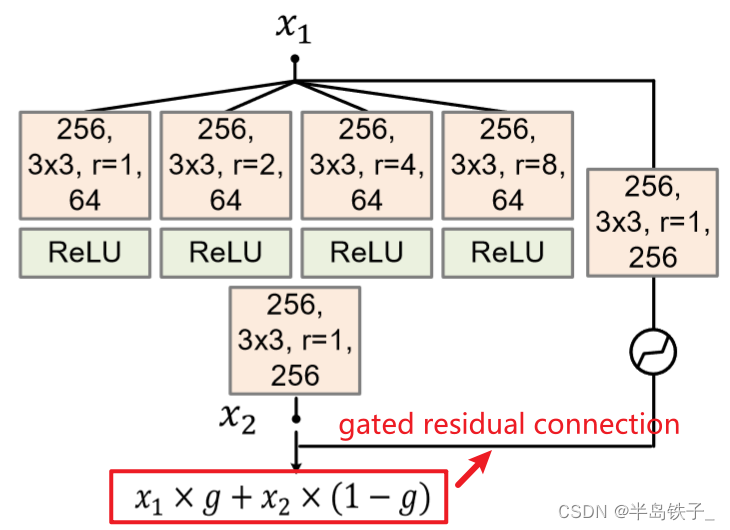
这样的设计能够让AOT块通过不同的视图预测图像的每个输出像素。
下面的公式中对传统的相同剩余连接进行改进,改进为选通剩余连接,聚合公式中g是空间可变门控值。这种空间变化的特征聚合在尽可能更新缺失区域内的特征的同时,保留缺失区域外的已知特征。
x 3 = x 1 × g + x 2 × ( 1 − g ) x_{3}=x_{1} \times g+x_{2}{\large }\times(1-g) x3=x1×g+x2×(1−g)
Soft Mask-Guided PatchGAN (SM-PatchGAN)
解决什么问题?
大多数深度修复模型往往基于重建损失(L1 Loss)生成所有可能解决方案的平均值,这会导致纹理模糊。
修复结果表示为:
z = x ⊙ ( 1 − m ) + G ( x ⊙ ( 1 − m ) , m ) ⊙ m z=x \odot(1-m)+G(x \odot(1-m), m) \odot m z=x⊙(1−m)+G(x⊙(1−m),m)⊙m
修复结果为两部分的叠加,原图像的完好区域和生成的空洞区域。其中,m为二进制掩码(0表示已知像素,1表示未知像素),即缺失区域表示为白色。
判别器的对抗损失:
L a d v D = E z ∼ p z [ ( D ( z ) − σ ( 1 − m ) ) 2 ] + E x ∼ p data [ ( D ( x ) − 1 ) 2 ] \begin{array}{c} L_{a d v}^{D}=\mathbb{E}_{z \sim p_{z}}\left[(D(z)-\sigma(1-m))^{2}\right]+ \mathbb{E}_{x \sim p_{\text {data }}}\left[(D(x)-1)^{2}\right] \end{array} LadvD=Ez∼pz[(D(z)−σ(1−m))2]+Ex∼pdata [(D(x)−1)2]
其中, σ \sigma σ 表示下采样和高斯滤波的合成函数。
生成器的对抗损失:
L a d v G = E z ∼ p z [ ( D ( z ) − 1 ) 2 ⊙ m ] L_{a d v}^{G}=\mathbb{E}_{z \sim p_{z}}\left[(D(z)-1)^{2} \odot m\right] LadvG=Ez∼pz[(D(z)−1)2⊙m]
判别器上的设计
对于判别器设计了soft patch-level mask。
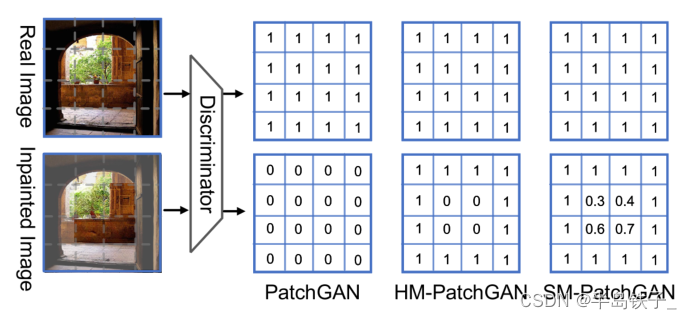
不同设计的比较:
PatchGAN的判别器将所有修复图像中的补丁都判别为假,这忽略了缺失区域之外的补丁确实来自真实图像。 而所提出的SM-PatchGAN能够将缺失区域的合成补丁与上下文的真实补丁区分开来,这可以增强鉴别器的能力。
HM-PatchGAN中没有使用高斯滤波器,从而忽略了修补图像的边界周围可能同时包含真实像素和合成像素。而所提出的SM-PatchGAN引入了高斯滤波器解决了这个问题。
总体优化
优化函数包括四个: L 1 L_1 L1 loss(重建损失)、style loss(风格损失)、perceptual loss(感知损失)和adversarial loss (对抗损失)。
(1) L 1 L_1 L1 loss确保像素级的重建精度
L r e c = ∥ x − G ( x ⊙ ( 1 − m ) , m ) ∥ 1 L_{r e c}=\|x-G(x \odot(1-m), m)\|_{1} Lrec=∥x−G(x⊙(1−m),m)∥1
(2)perceptual loss旨在最小化修复图像和真实图像的激活图之间的 L 1 L_1 L1距离
L p e r = ∑ i ∥ ϕ i ( x ) − ϕ i ( z ) ∥ 1 N i L_{p e r}=\sum_{i} \frac{\left\|\phi_{i}(x)-\phi_{i}(z)\right\|_{1}}{N_{i}} Lper=i∑Ni∥ϕi(x)−ϕi(z)∥1
其中, ϕ i \phi_{i} ϕi 来自预训练网络(如VGG19)第i层的激活图, N i N_i Ni 是 ϕ i \phi_{i} ϕi 中的总数量。
(3)style loss被定义为修复图像和真实图像深层特征的Gram矩阵之间的 L 1 L_1 L1距离:
L s t y = E i [ ∥ ϕ i ( x ) T ϕ i ( x ) − ϕ i ( z ) T ϕ i ( z ) ∥ 1 ] L_{s t y}=\mathbb{E}_{i}\left[\left\|\phi_{i}(x)^{T} \phi_{i}(x)-\phi_{i}(z)^{T} \phi_{i}(z)\right\|_{1}\right] Lsty=Ei[∥ ∥ϕi(x)Tϕi(x)−ϕi(z)Tϕi(z)∥ ∥1]
(4)adversarial loss
L a d v = E z ∼ p z [ ( D ( z ) − 1 ) 2 ⊙ m ] L_{a d v}=\mathbb{E}_{z \sim p_{z}}\left[(D(z)-1)^{2} \odot m\right] Ladv=Ez∼pz[(D(z)−1)2⊙m]
总的优化目标:
L = λ a d v L a d v G + λ r e c L r e c + λ p e r L p e r + λ s t y L s t y L=\lambda_{a d v} L_{a d v}^{G}+\lambda_{r e c} L_{r e c}+\lambda_{p e r} L_{p e r}+\lambda_{s t y} L_{s t y} L=λadvLadvG+λrecLrec+λperLper+λstyLsty
参数设置: λ a d v \lambda_{a d v} λadv = 0.01, λ r e c \lambda_{rec} λrec = 1, λ p e r \lambda_{per} λper = 0.1, λ s t y \lambda_{sty} λsty = 250。
实现细节
SM-PatchGAN中的高斯滤波处理,将高斯核的核大小设置为了70×70。为了避免归一化层引起的颜色偏移问题,移除了生成器网络中的所有归一化层。
训练参数设置:
一个mini-batch中,随机采8张图片和相应的掩码。生成器和鉴别器的学习率都为 1 0 − 4 10^{-4} 10−4,使用 β 1 = 0 和 β 2 = 0.9 \beta_{1}=0 \text { 和 } \beta_{2}=0.9 β1=0 和 β2=0.9 的优化器。使用ImageNet数据集上预训练的VGG19作为预训练网络,用于计算风格损失和感知损失。
实验
使用的数据集
Places2、CELEBA-HQ、QMUL-OpenLogo
掩膜数据集
论文Image Inpainting for Irregular Holes Using Partial Convolutions中所提供的掩膜数据集,也是大多数图像修复任务中所使用的。
对比的模型基准
(1)CA:Context encoders: Feature learning by inpainting. (2016)
(2)PEN-Net:Learning pyramid-context encoder network for high-quality image inpainting. (2019)
(3)PConv:Image inpainting for irregular holes using partial convolutions. (2018)
(4)EdgeConnect:Edgeconnect: Generative image inpainting with adversarial edge learning. (2019)
(5)GatedConv:Free-form image inpainting with gated convolution. (2019)
(6)HiFill :Contextual residual aggregation for ultra high-resolution image inpainting. (2020)
(7)MNPS :High-resolution image inpainting using multi-scale neural patch synthesis. (2017)
上述7个模型都是Image Inpainting领域比较经典的模型。
评估标准
L 1 L_1 L1 error、PSNR、SSIM、FID
然后就是定性实验、定量实验、User Study,结果肯定都优于其他,就不总结了,细节看论文。
消融实验
验证AOT-GAN中三种组成要素的有效性 :gated contextual transformations(选通上下文转换)、gated residual connections(选通残余连接)、SM-PatchGAN discriminator(SM PatchGAN鉴别器)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FFFnbluv-1665994031911)(C:/Users/Husheng/Desktop/%E8%AE%BA%E6%96%87%E7%AC%94%E8%AE%B0.assets/image-20221017153851827.png)]](http://zhangshiyu.com/zb_users/upload/2023/04/20230411080134168117129452235.png)
结论
局限性
(1)AOT块的分支数和扩张率是根据经验性的研究和设置,当图像大小改变时,可能就要重新去设置参数,无法自适应。
(2)在实际应用(如logo移除)中很难自动分割logo的区域。