进程地址空间
一、引入二、虚拟地址与物理内存的联系三、为什么要有虚拟地址空间
一、引入
对于C/C++程序,我们眼中的内存是这样的: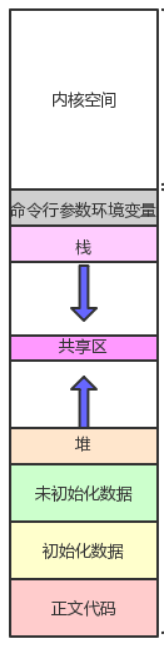
我们利用这种对于与内存的理解看一下下面这段代码:
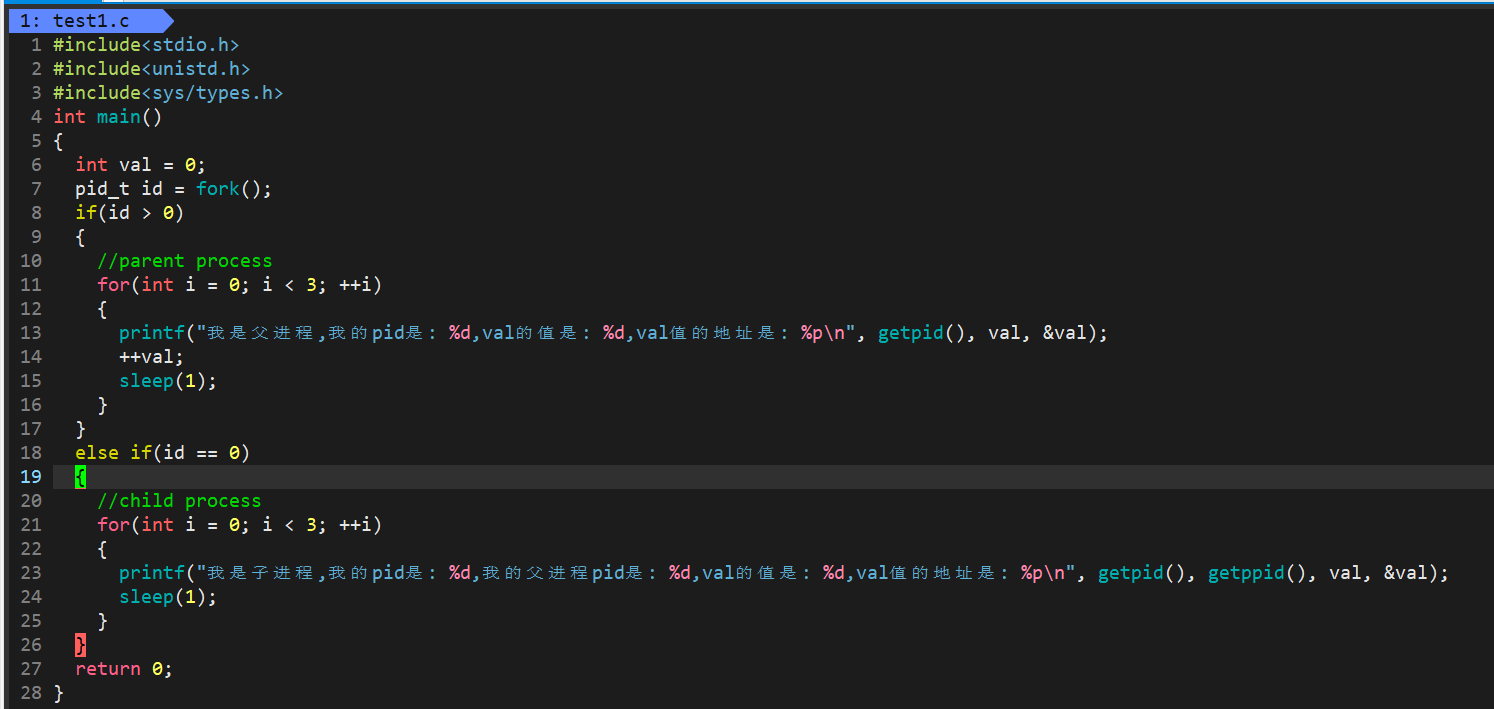
运行结果:

观察父子进程中 val 变量的值,以及 val 的地址,我们发现父子进程中 val 的地址都是同一个地址 但是 val 的值并不相同,这是什么意思???内存中同一个地址却存放了两个不同的变量值?这显然是不可能的!地址具有唯一性,地址处存放的数据也具有唯一性!
一种合理的解释是:我们在C程序中所用到的地址的一个虚拟地址,并不是真正的物理内存地址!
在C/C++程序中我们所使用到的地址都是虚拟地址,这些虚拟地址组合起来就形成了虚拟地址空间,在Linux中虚拟地址空间被一个叫struct mm_struct的结构体所管理。
那么我们想知道这个程序的虚拟地址空间到底虚拟了多大的内存呢?
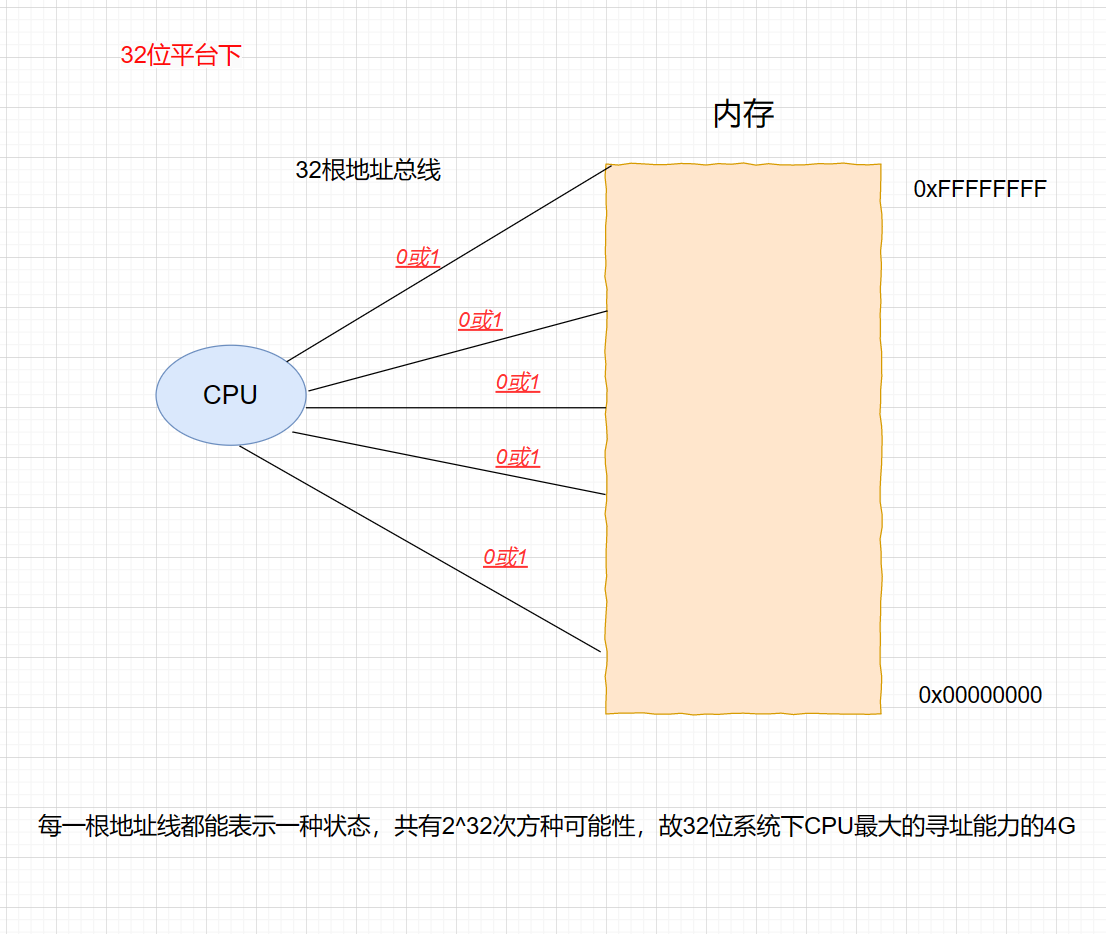
答案是:每个进程所能访问的最大的虚拟地址空间由计算机的硬件平台决定,具体地说是由 CPU 的位数决定的。
比如 32 位的 CPU 决定了虚拟地址空间的大小为 [ 0 , 2 32 − 1 ] [0 ,2^{32}-1] [0,232−1],即 0x00000000 - 0xFFFFFFFF,也就是我们常说的 4 GB 虚拟内存空间。如果是 64 位的CPU,那么寻址范围是 [ 0 , 2 64 − 1 ] [0 ,2^{64}-1] [0,264−1],即 0x0000000000000000 - 0xFFFFFFFFFFFFFFFF,共有 17 179 864 184 GB。
所以开头我们看到的内存其实是操作系统为我们程序虚拟的虚拟地址空间,这个虚拟地址空间的分配如下:
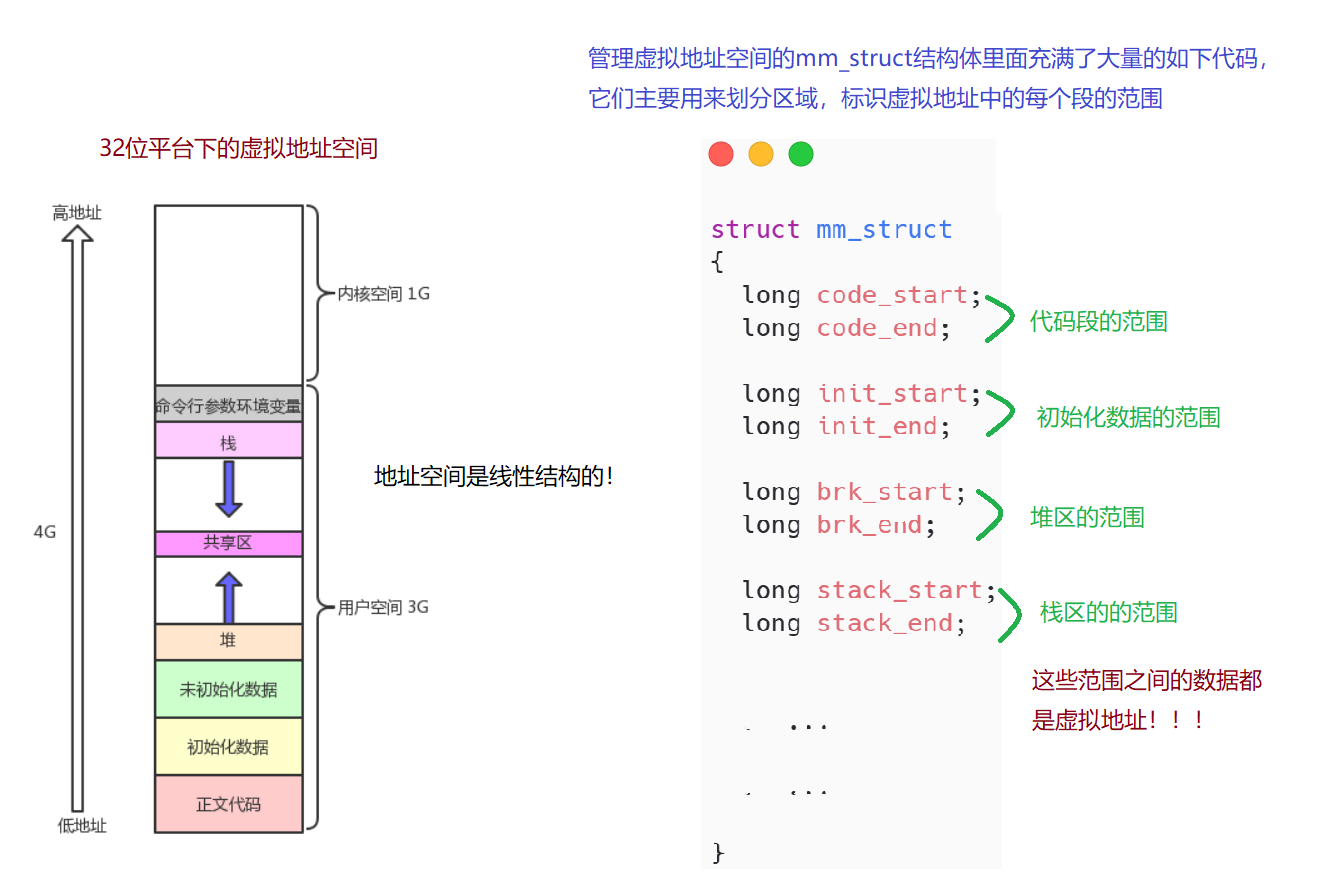
二、虚拟地址与物理内存的联系
经过上面的介绍我们知道了原来我们认为内存其实是虚拟地址空间,但是我们的代码与数据是要真真实实的存储在物理内存中,虚拟地址空间里面存放的仅仅是一些代码和数据的虚拟地址,那么我们是怎么通过虚拟地址来找到物理内存中的代码与数据呢?
答案是:通过一种数据结构——页表和一种硬件——MMU(内存管理单元),通过页表来进行虚拟地址与物理地址一 一对应从而找到相应的代码与数据
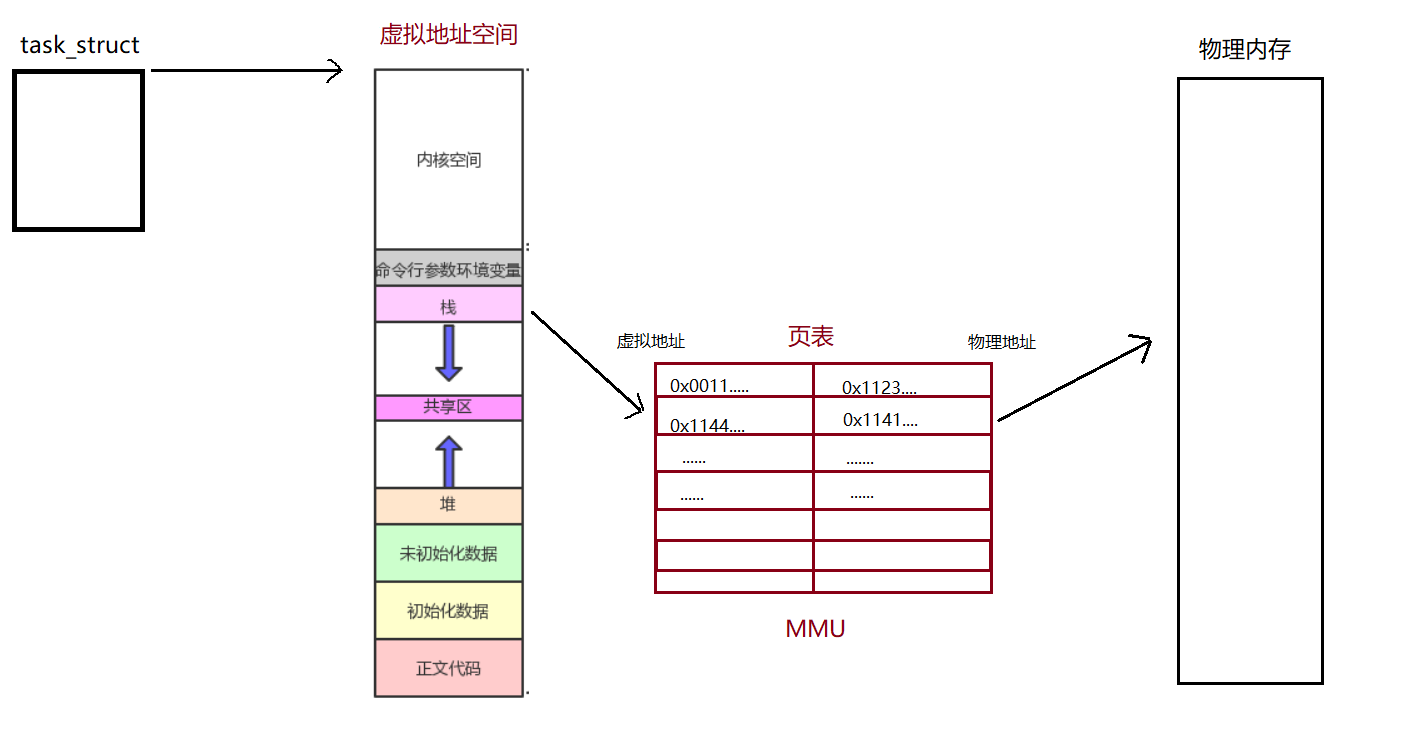
明白了这些后我们再来看开头的问题,为什么同一个地址存放的是不同的数据?
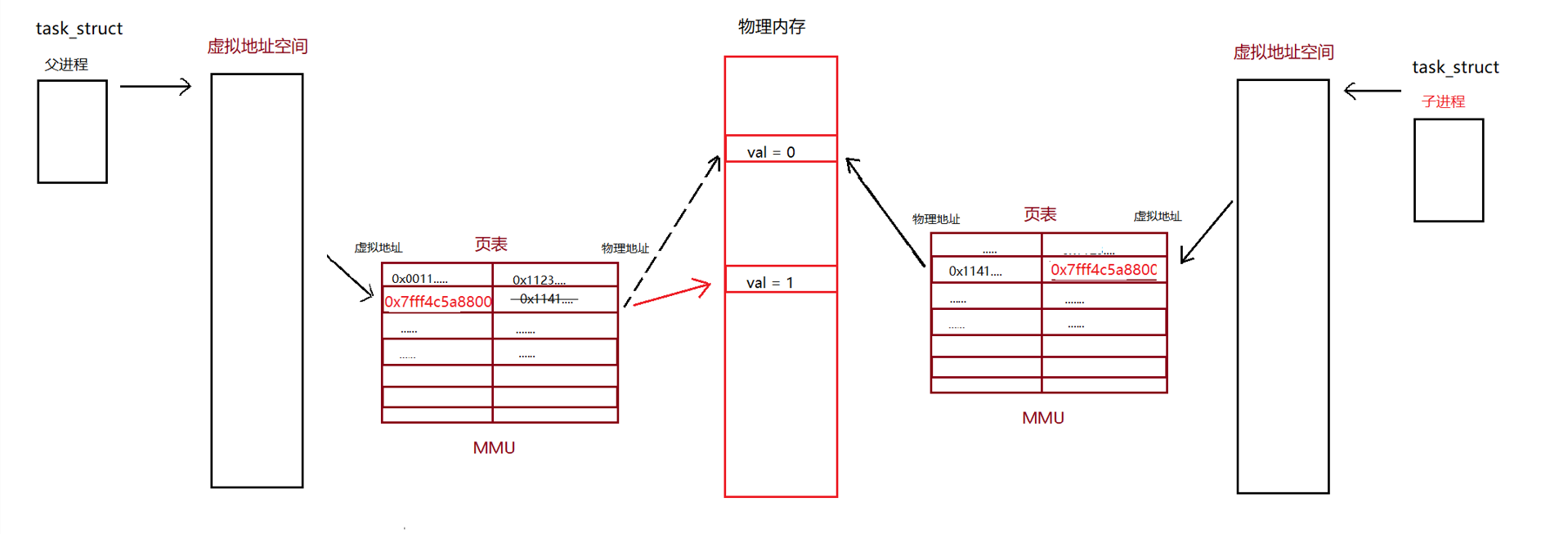
在父进程刚开始创建子进程时,子进程是的大多数数据(如:task_struct , 虚拟程地址空间等数据)都是以父进程为模板创建而来的,因此在最初时父进程与子进程的虚拟地址空间和页表是相同的,然后父进程尝试去修改变量 val 的值,由于进程具有独立性,操作系统不能让父进程的修改影响到子进程,于是发生了写时拷贝,操作系统先在物理内存中重新找一块空间保存了父进程修改后的 val 值,然后将父进程页表中对应物理地址进行更改。
注意:虚拟地址不更改,只改变物理地址!因为物理地址实实在在的变化了,虚拟地址没有必要更改。
三、为什么要有虚拟地址空间
可能你会觉得为什么要有虚拟地址空间呢?我们的进程为什么不直接使用物理地址呢?直接使用物理地址还能减少中间层提高运行的效率。
要回答这个问题我们可以从下面几个的角度来回答:
防止地址随意访问,保护物理内存与其他进程如果我们没有虚拟地址空间,当我们在内存中运行两个程序时,如果其中在一个进程中发生了越界访问,那么就有可能访问到其他的进程,这样进程之间就会互相影响了,进程的独立性就无法保证了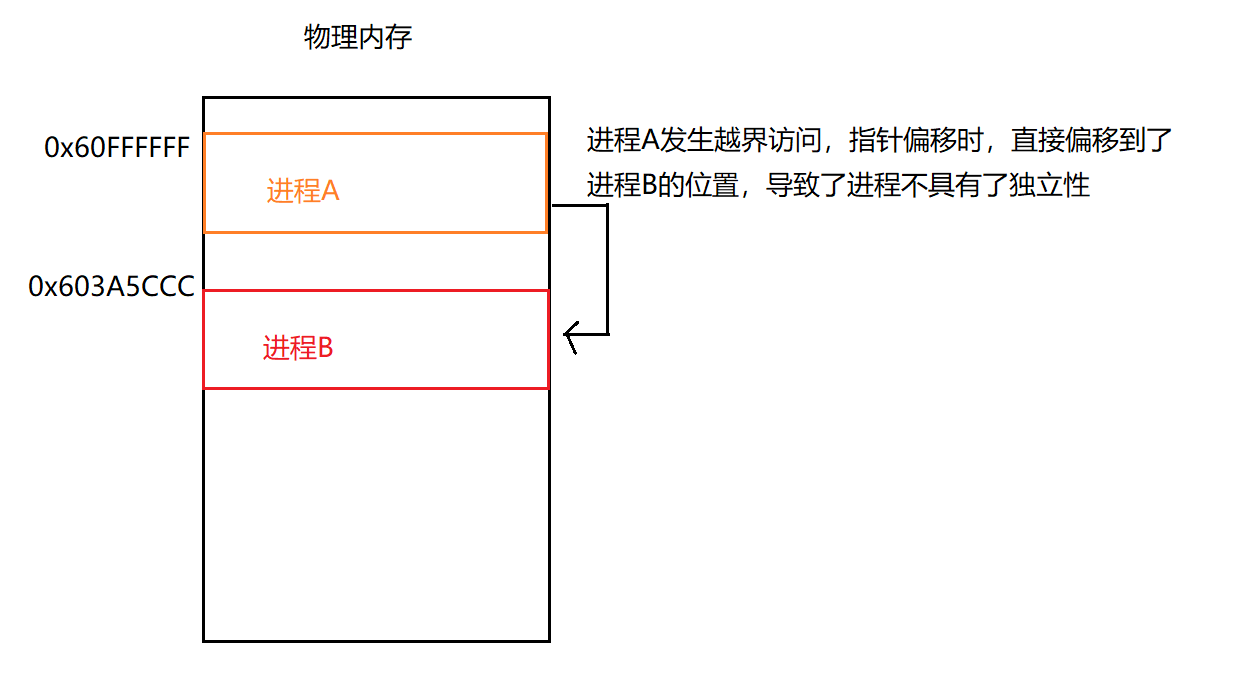
有了虚拟地址空间以后我们便可以通过页表来进行判断越界后的地址与接下来的操作是否统一的,如果是统一的便进行映射。
这里我们先来谈一谈
malloc的本质,malloc函数是在调用后向OS申请内存,操作系统立马给你,还是需要的时候在给你呢 ?答案是:在你需要的时候给你!!!
那么为什么会是这样的呢?因为操作系统要管理好所有的软硬件资源,OS一般不允许任何的浪费或者不高效的行为出现!
我们在申请完内存以后并不一定立马使用,在你申请成功之后,和你使用之前,就以一段小小的时间窗口,这个空间没有被正常使用,但是别人用不了,于是这块空间就处于了闲置状态! 这是OS不允许的!
于是我们在用
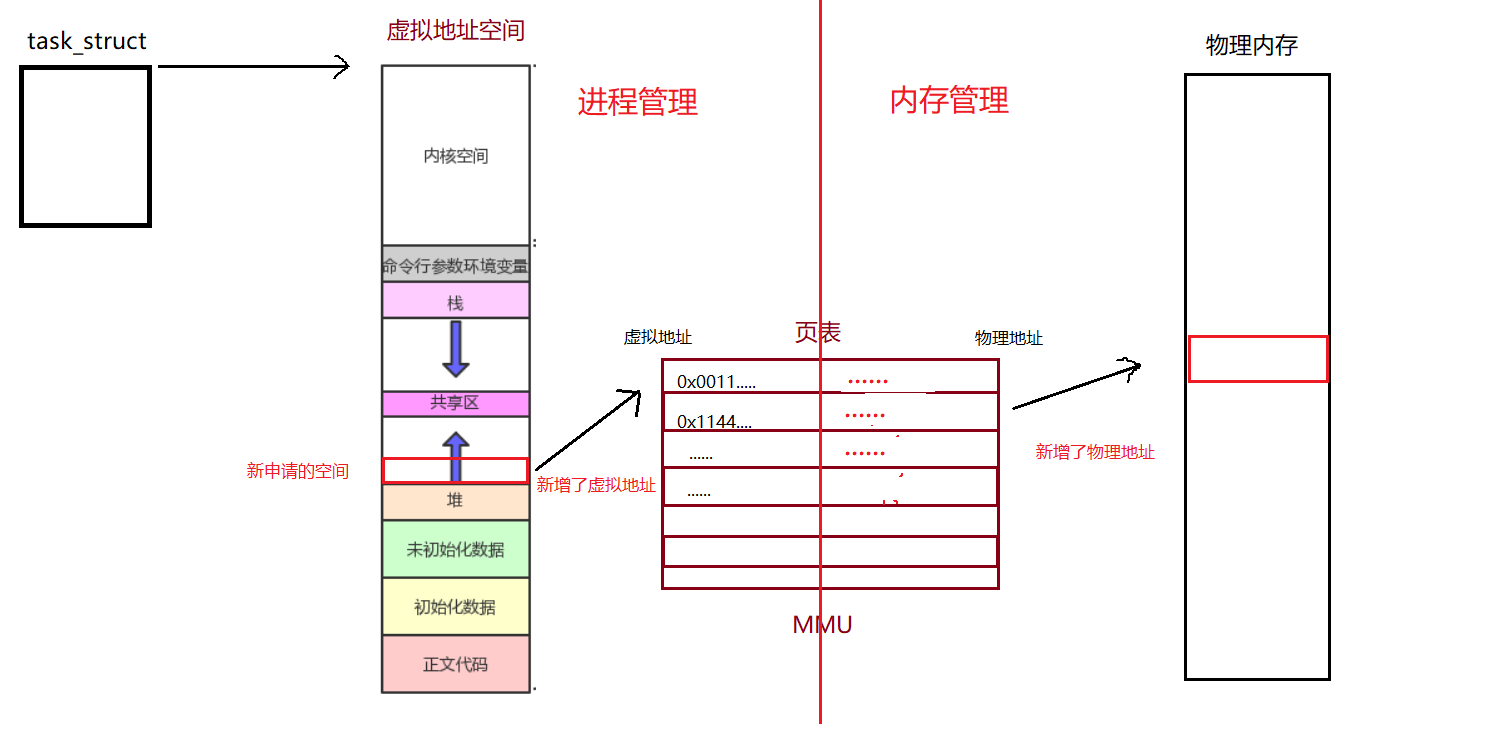
malloc申请空间时OS其实是先通过task_struct找到虚拟地址空间和管理虚拟地址空间的mm_struct结构体,然后对于虚拟地址空间的内容进行修改并将mm_struct里关于堆区的范围进行修改,然后页表中关于虚拟地址的部分的内容会进行增加,但是新增的虚拟地址去没有与实际的物理地址建立映射关系,只有当你要使用你申请的空间时,OS才会真正的为你分配空间,并将页表中新增的虚拟地址对应的物理地址的映射关系建立起来!这时OS才真正的完成了内存分配!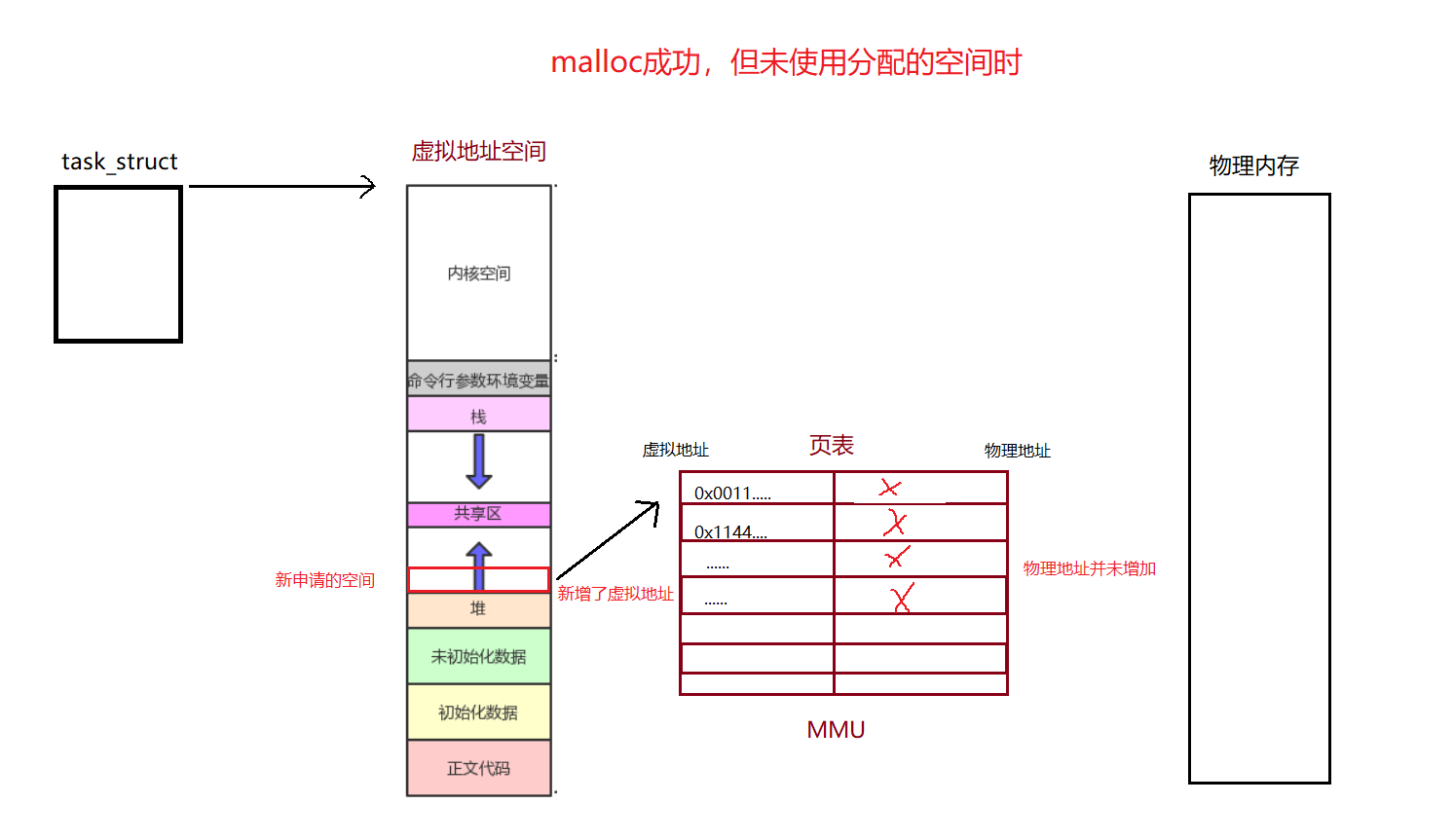
这个时候,我们将页表从中间一分为二,左边就是进程管理,右边就是内存管理,进程管理发生错误不影响内存管理,内存管理出现错误不影响进程管理,这样我们就实现了进程与内存管理的解耦合!
在这里我们来讨论一下我们的程序在被编译的时候,没有被加载到内存,我们的程序内部有没有地址呢?
答案是:有的!
我们的C/C++程序在被编译时就采用了虚拟地址空间的方式进行编译,并将数据按照代码段,已初始化数据段,未初始化数据段等方式进行分类存储。当我们的程序加载进内存时,我们的程序可以分批式的将程序的数据段,代码段,分批的加载进地址空间中。
注意:编译好的程序并没有堆区和栈区,只有加载进内存时形成进程时才有堆区与栈区!
有了地址空间之后我们的进程便不再关心代码与数据究竟在内存中的哪里,我们每个进程都是以统一的视角——虚拟地址空间的方式来待自己的代码与数据。