Pytorch 中打印网络结构及其参数的方法与实现
文章标签:
《随便一记》
1. print 直接输出网络结构
print(model)print 只能打印最基本的网络结构,显示每一层的操作,输出结果如下:
Classifier( (cnn): Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU() (3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (4): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (5): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (6): ReLU() (7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (8): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (10): ReLU() (11): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (12): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (13): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (14): ReLU() (15): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (16): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (17): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (18): ReLU() (19): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) (fc): Sequential( (0): Linear(in_features=8192, out_features=1024, bias=True) (1): ReLU() (2): Linear(in_features=1024, out_features=512, bias=True) (3): ReLU() (4): Linear(in_features=512, out_features=11, bias=True) ))2. from torchsummary import summary
summary(model,(3,128,128))torchsummary 中的 summary 可以打印每一层的shape, 参数量,输出结果如下:
---------------------------------------------------------------- Layer (type) Output Shape Param #================================================================ Conv2d-1 [-1, 64, 128, 128] 1,792 BatchNorm2d-2 [-1, 64, 128, 128] 128 ReLU-3 [-1, 64, 128, 128] 0 MaxPool2d-4 [-1, 64, 64, 64] 0 Conv2d-5 [-1, 128, 64, 64] 73,856 BatchNorm2d-6 [-1, 128, 64, 64] 256 ReLU-7 [-1, 128, 64, 64] 0 MaxPool2d-8 [-1, 128, 32, 32] 0 Conv2d-9 [-1, 256, 32, 32] 295,168 BatchNorm2d-10 [-1, 256, 32, 32] 512 ReLU-11 [-1, 256, 32, 32] 0 MaxPool2d-12 [-1, 256, 16, 16] 0 Conv2d-13 [-1, 512, 16, 16] 1,180,160 BatchNorm2d-14 [-1, 512, 16, 16] 1,024 ReLU-15 [-1, 512, 16, 16] 0 MaxPool2d-16 [-1, 512, 8, 8] 0 Conv2d-17 [-1, 512, 8, 8] 2,359,808 BatchNorm2d-18 [-1, 512, 8, 8] 1,024 ReLU-19 [-1, 512, 8, 8] 0 MaxPool2d-20 [-1, 512, 4, 4] 0 Linear-21 [-1, 1024] 8,389,632 ReLU-22 [-1, 1024] 0 Linear-23 [-1, 512] 524,800 ReLU-24 [-1, 512] 0 Linear-25 [-1, 11] 5,643================================================================Total params: 12,833,803Trainable params: 12,833,803Non-trainable params: 0----------------------------------------------------------------Input size (MB): 0.19Forward/backward pass size (MB): 49.59Params size (MB): 48.96Estimated Total Size (MB): 98.73----------------------------------------------------------------3. from torchinfo import summary
注意使用时需要给定 batchsize
summary(model,(1, 3,128,128))torchinfo 的 summary 更加友好,我个人觉得是 print 和 torchsummary 的 summary 的结合体!推荐!!!输出结果如下:
==================================================================================Layer (type:depth-idx) Output Shape Param #==================================================================================Classifier [1, 11] --├─Sequential: 1-1 [1, 512, 4, 4] --│ └─Conv2d: 2-1 [1, 64, 128, 128] 1,792│ └─BatchNorm2d: 2-2 [1, 64, 128, 128] 128│ └─ReLU: 2-3 [1, 64, 128, 128] --│ └─MaxPool2d: 2-4 [1, 64, 64, 64] --│ └─Conv2d: 2-5 [1, 128, 64, 64] 73,856│ └─BatchNorm2d: 2-6 [1, 128, 64, 64] 256│ └─ReLU: 2-7 [1, 128, 64, 64] --│ └─MaxPool2d: 2-8 [1, 128, 32, 32] --│ └─Conv2d: 2-9 [1, 256, 32, 32] 295,168│ └─BatchNorm2d: 2-10 [1, 256, 32, 32] 512│ └─ReLU: 2-11 [1, 256, 32, 32] --│ └─MaxPool2d: 2-12 [1, 256, 16, 16] --│ └─Conv2d: 2-13 [1, 512, 16, 16] 1,180,160│ └─BatchNorm2d: 2-14 [1, 512, 16, 16] 1,024│ └─ReLU: 2-15 [1, 512, 16, 16] --│ └─MaxPool2d: 2-16 [1, 512, 8, 8] --│ └─Conv2d: 2-17 [1, 512, 8, 8] 2,359,808│ └─BatchNorm2d: 2-18 [1, 512, 8, 8] 1,024│ └─ReLU: 2-19 [1, 512, 8, 8] --│ └─MaxPool2d: 2-20 [1, 512, 4, 4] --├─Sequential: 1-2 [1, 11] --│ └─Linear: 2-21 [1, 1024] 8,389,632│ └─ReLU: 2-22 [1, 1024] --│ └─Linear: 2-23 [1, 512] 524,800│ └─ReLU: 2-24 [1, 512] --│ └─Linear: 2-25 [1, 11] 5,643==================================================================================Total params: 12,833,803Trainable params: 12,833,803Non-trainable params: 0Total mult-adds (G): 1.10==================================================================================Input size (MB): 0.20Forward/backward pass size (MB): 31.99Params size (MB): 51.34Estimated Total Size (MB): 83.53==================================================================================4. Netron 可视化网络结构
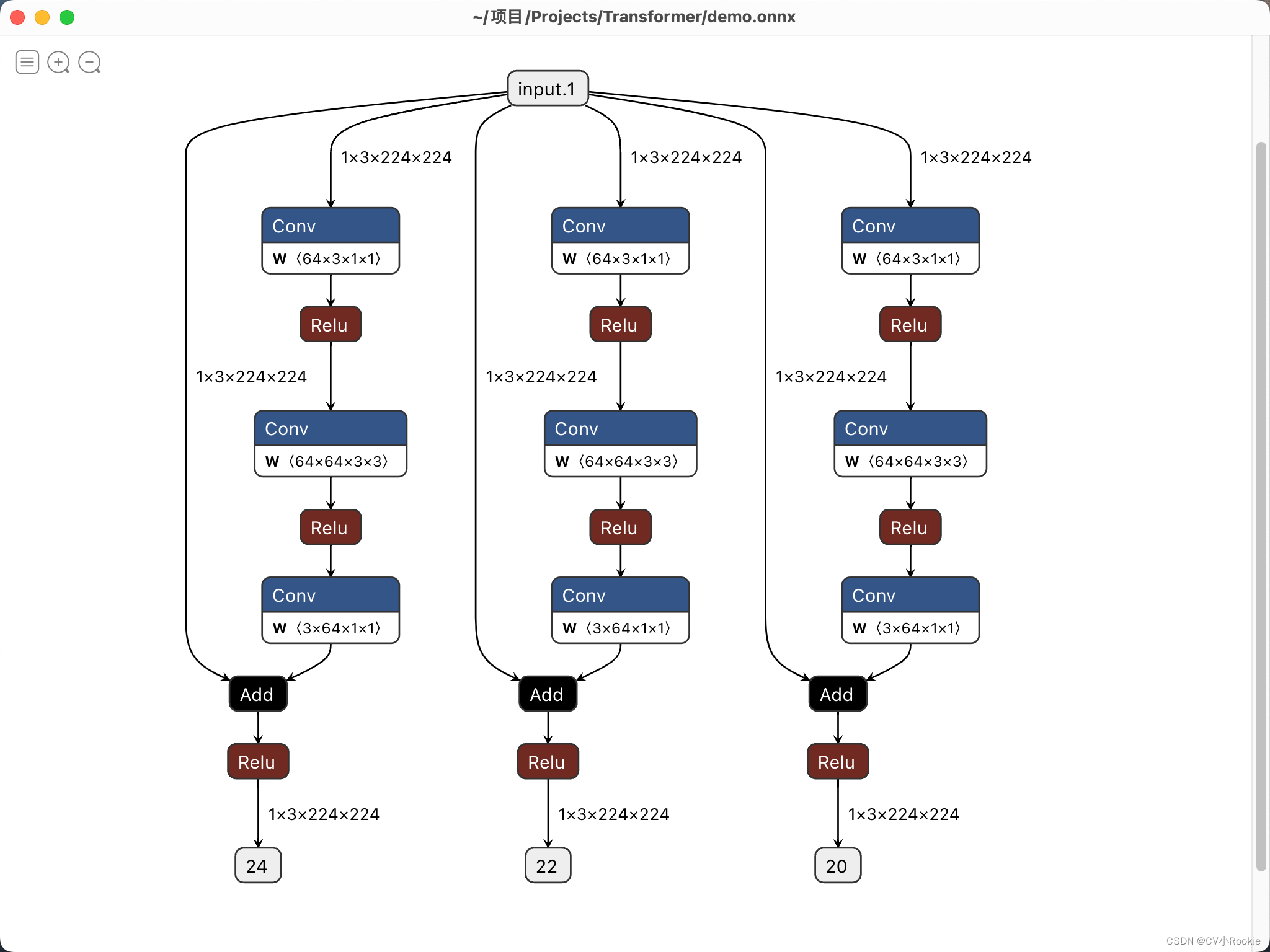
model = 自己的网络 # 针对有网络模型,但还没有训练保存 .pth 文件的情况 input = torch.randn(1, 3, 224, 224) # 随机生成一个输入 modelpath = "./demo.onnx" # 定义模型结构保存的路径 torch.onnx.export(model, input, modelpath) # 导出并保存 netron.start(modelpath) # # 针对已经存在网络模型 .pth 文件的情况 # import netron # # modelpath = "./demo.onnx" # 定义模型数据保存的路径 # netron.start(modelpath) # 输出网络结构但是在我电脑上有个bug就是网页打不开(mac m1)
最后我下载了neutron的app,成功打开,链接:https://gitcode.net/mirrors/lutzroeder/netron?utm_source=csdn_github_accelerator
登录后可发表评论
点击登录