交通数据(1)——加州高速路网PeMS交通数据
一、PeMS数据介绍1. 数据来源2. 数据特点3. 数据诊断与处理4. PeMS数据格式 二、相关数据下载1. 相关数据链接2. 数据爬虫下载3. 部分路网数据集(持续更新中···)
一、PeMS数据介绍
1. 数据来源
PeMS提供了一个统一的交通数据数据库,该数据库由加州运输公司在加州的高速公路上收集,以及其他加州运输公司和合作机构的数据集。这些数据可以让用户对高速公路性能进行统一、全面的评估,基于对高速公路网络当前状态的了解做出运营决策,分析拥堵瓶颈以确定潜在的补救措施,并做出更好的整体决策。
智能交通系统(ITS)车辆检测站( Vehicle Detector Stations: VDS);流量统计站: Traffic Census Stations;Weight-In-Motion (WIM)传感器;加州公路巡警(CHP)事故数据;交通事故监测和分析系统(TASAS)事故数据;······
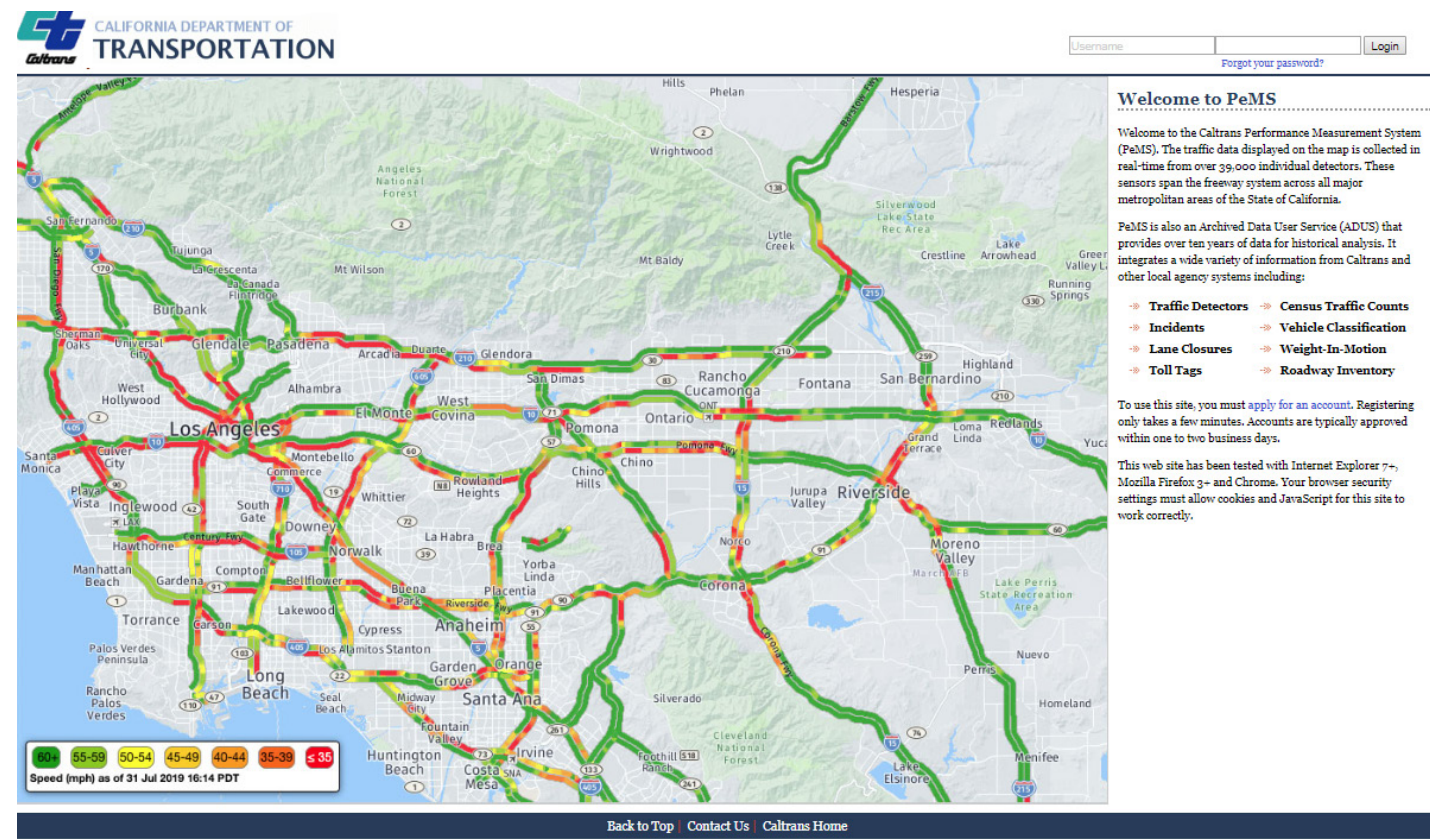
2. 数据特点
超过44,681个检测器每30秒报告一次数据;一旦完成编译30秒的数据集,没有任何间隙,数据就会被聚合成5分钟的增量。各种性能数据可用,如容量、速度、延迟、车辆行驶里程(VMT)、车辆行驶小时(VHT)、行驶时间和年平均日交通流量(AADT);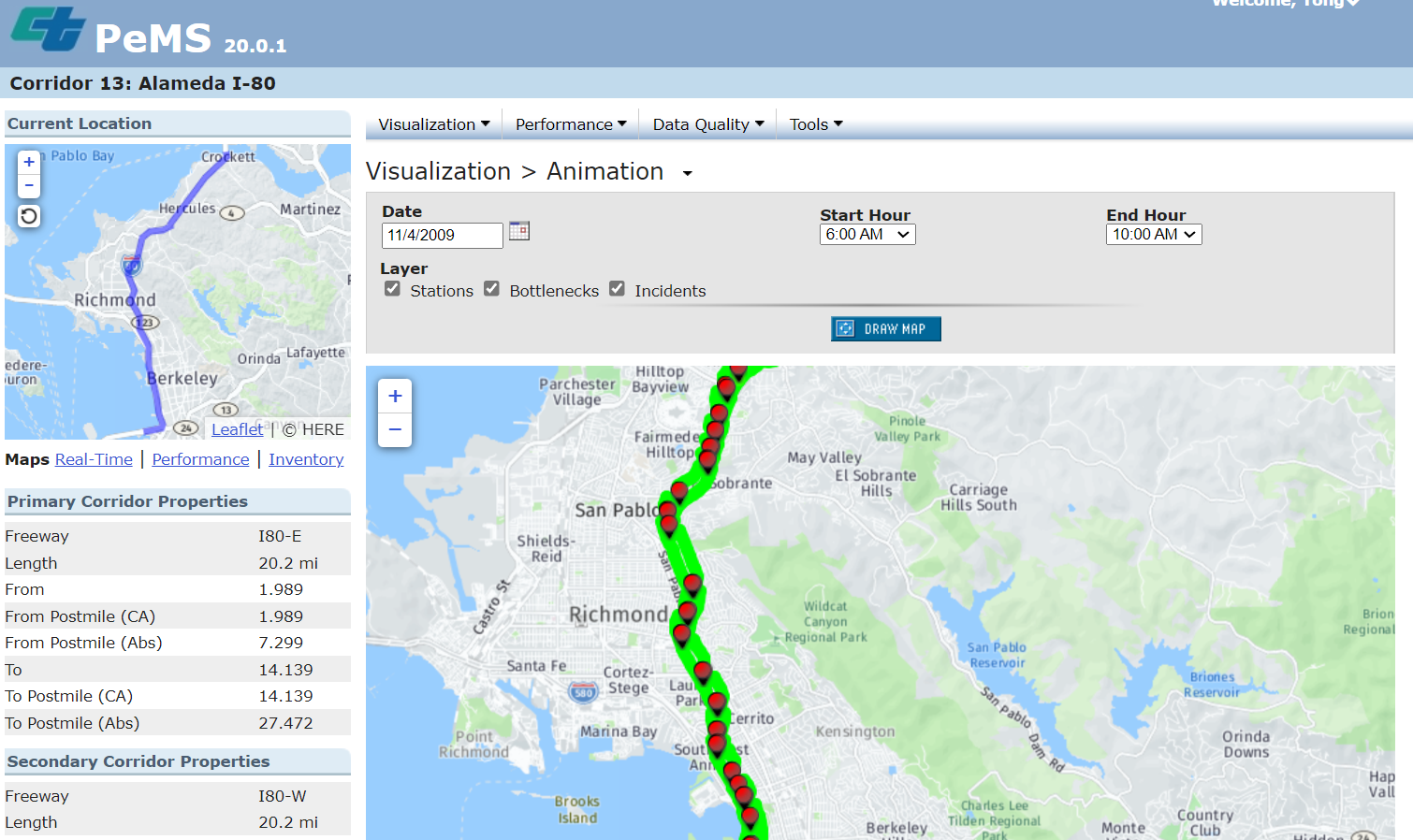
3. 数据诊断与处理
个别检波器站(VDS)偶尔会发生故障、停止工作或停止发送数据。这些错误可能因各种原因发生,包括错误的连接、通信丢失或控制器故障。每当这些错误发生时,数据集就会出现空白。没有完整的数据集(至少没有明显的不准确性),绩效度量是无法估计的。PeMS会使用一种称为数据输入的过程估计数据(为了计算性能度量)。该过程包括全面的算法,以填补空白的数据集与准确的估计。
基于局部系数的邻接线性回归——数据空白是通过来自同一位置邻近车道的检测器以及直接上下游位置的检测器的信息来填充的;基于全局系数的邻居线性回归——当PeMS确定某些检测器从未报告合理的数据时,系统会查看整个区域的检测器数据中的一般关系,以填补空白;临时中间值——pem查看长时间内相似时间和每周天数的数据值。这些数据值的中位数用于填补空白;集群中值——PeMS检查一周内来自具有类似流量模式的检测器的数据,以填补数据空白。4. PeMS数据格式
DashboardsMapsPlots and graphsTablesExport to text/spreadsheet fileAnimation video.部分数据解释如下:
(1)Maps
PeMS中有四个不同的地图:实时地图、性能地图、库存地图和搜索地图(Real-Time Map, the Performance Map, the Inventory Map, and the Search Map)。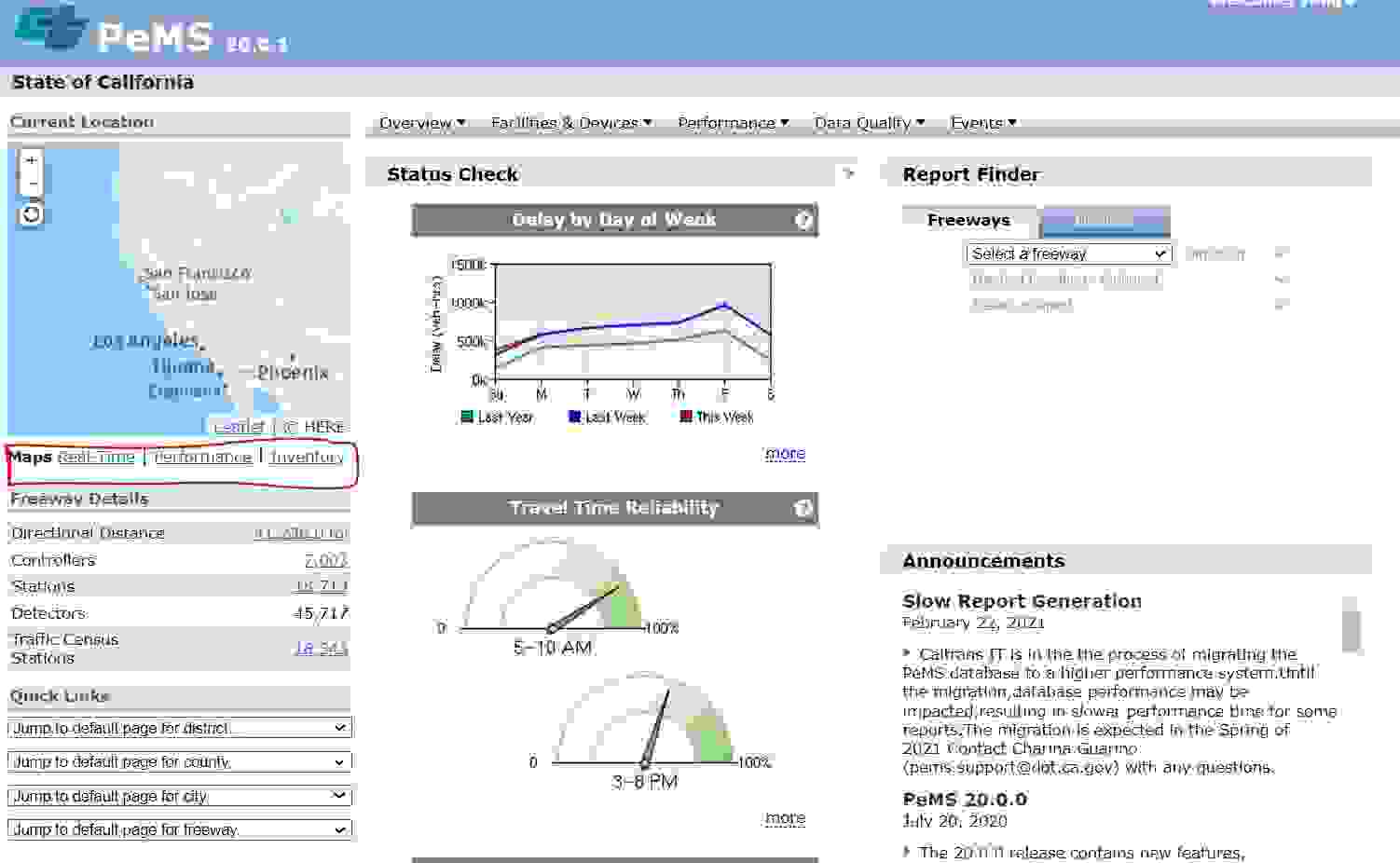
(2)Plots and Charts
PeMS提供多种类型的性能度量图和图表,如流量或速度的聚合图、服务水平条形图、区域数量饼图、速度等高线图和拥塞概述图。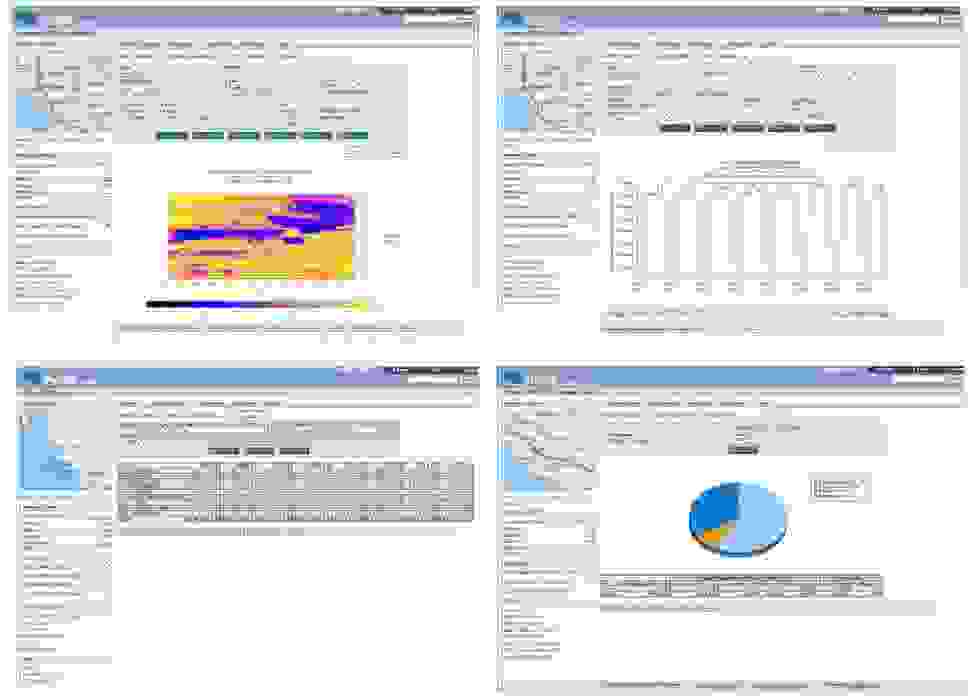
(3)Tables
PeMS在大多数报告中,默认的输出格式是图表或图表。为了生成表,用户必须通过单击按钮选择表输出选项。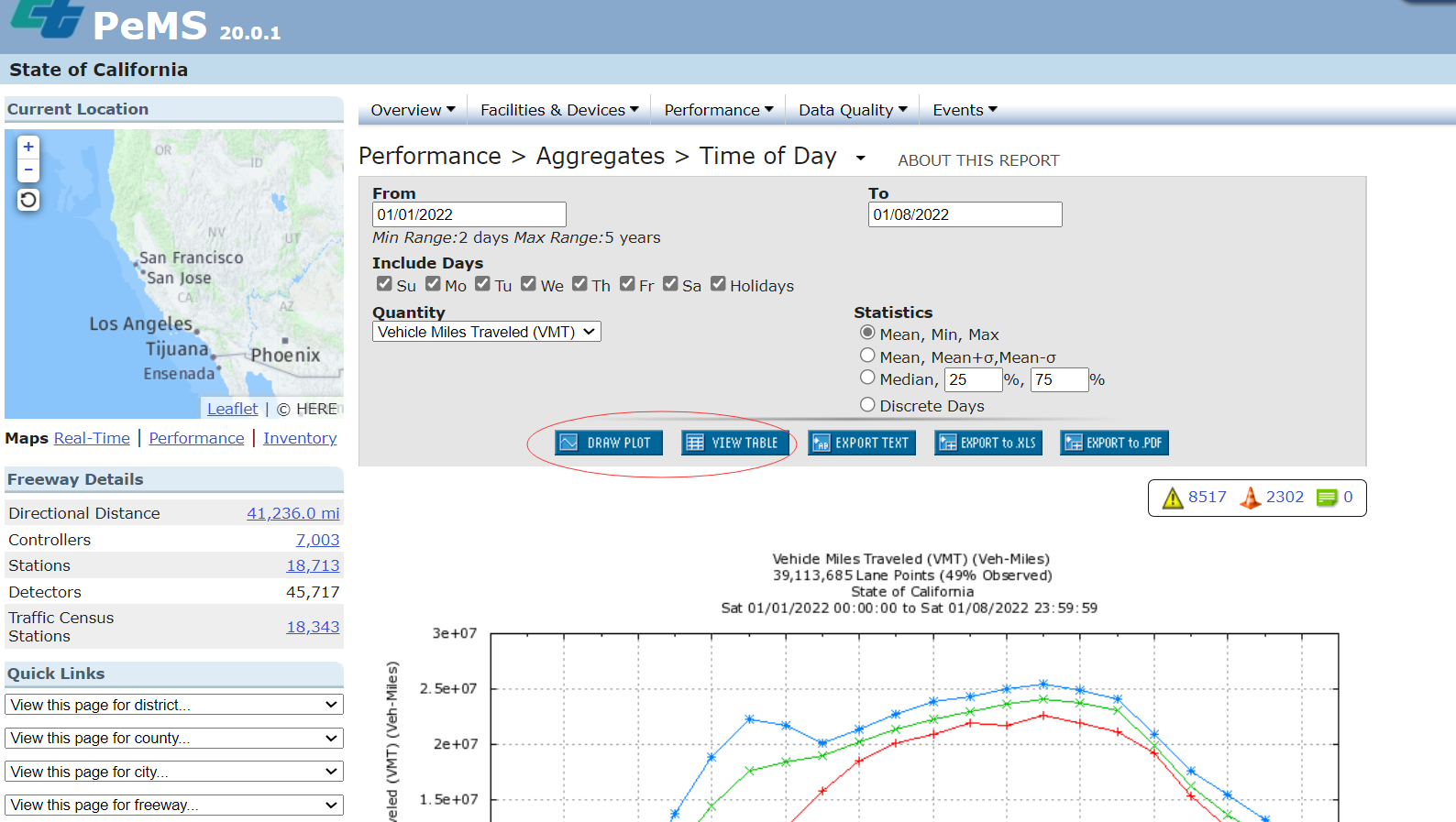
PeMS允许用户将大多数报告中的数据导出到单独的文本文件或电子表格文件(Microsoft Excel . xls)。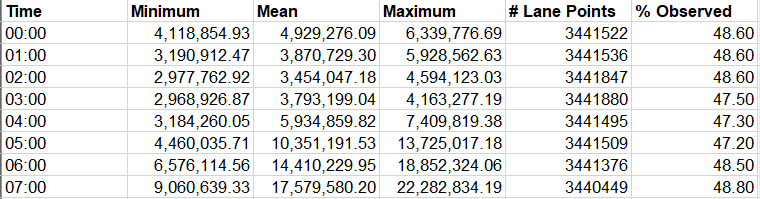
(4)Animation Videos
当在高速公路路段或走廊上进行空间层面的分析时,用户可以生成动画视频。动画视频提供了一种方式来查看交通状况的变化,因为他们发生在特定的日期和时间。只需选择日期、开始和结束时间以及所需的里程限制。用户可以选择显示以下数据元素:速度、瓶颈、事件、容量和站点。点击播放按钮可以让用户看到交通状况随时间变化的动画。要控制动画速度,请选择或取消选择地图右下角的箭头。动画可以暂停,让用户对给定时刻的数据进行更详细的调查。用户还可以单击动画条,将动画快进或快退到所需的时间点。用户可以通过双击某个位置、使用鼠标滚轮或使用地图左上角的缩放比例按钮来放大或缩小动画。
二、相关数据下载
1. 相关数据链接
PeMS数据官网下载链接:http://pems.dot.ca.gov.
PeMS论坛链接:http://pemsforum.dot.ca.gov/.
PeMS用户指导手册:https://github.com/sttCharon/PeMS_Data
2. 数据爬虫下载
此代码转载博客地址:https://blog.csdn.net/w771792694/article/details/103075534:
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2019/11/14 21:23# @Author : Chenchen Wei# @Description: 下载PeMS流量数据,一次下载一周数据,并将下载的周数据进行合并import timeimport osimport numpy as npimport pandas as pdimport requestsdef time_2_timestamp(input, lags=True): """默认True: 时间转化为时间戳, 包含时差计算""" if lags: timeArray = time.strptime(input, "%Y-%m-%d %H:%M") # 转换成时间戳 return int(time.mktime(timeArray) + 8 * 60 * 60) # 时差计算 else: time_local = time.localtime(input - 8 * 60 * 60) return time.strftime("%Y-%m-%d %H:%M", time_local)def download(save_path, vds, start_time, end_time): """时间转化为时间戳""" start_stamp, end_stamp = time_2_timestamp(start_time), time_2_timestamp(end_time) i = 1 for begin in range(start_stamp, end_stamp, 60 * 60 * 24 * 7): url = get_url(vds, begin) down_load_data(save_path, url, i) i += 1 print('Sleeping...') time.sleep(15) # 下载完成休息五秒def down_load_data(save_path, url, i): headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} data = {"redirect": "", "username": "账号", "password": "密码", "login": "Login"} session = requests.session() response = session.post(url, headers=headers, data=data) response = session.get(url) with open(save_path + '\\' + str(i) + '.xlsx', 'wb') as f: f.write(response.content) print('下载成功')def get_url(vds, begin): str_begin = time_2_timestamp(begin, False) s_begin = str_begin[5:7] + '%2F' + str_begin[8:10] + '%2F' + str_begin[:4] + '+00%3A00', end = begin + 60 * 60 * 24 * 7 - 60 str_end = time_2_timestamp(end, False) s_end = str_end[5:7] + '%2F' + str_end[8:10] + '%2F' + str_end[:4] + '+23%3A59', url = 'http://pems.dot.ca.gov/?report_form=1&dnode=VDS&content=loops&export=xls&station_id=' \ + str(vds) + '&s_time_id=' + str(begin) + '&s_time_id_f=' + str(s_begin) + '&e_time_id=' + str( end) + '&e_time_id_f=' + str(s_end) + '&tod=all&tod_from=0&tod_to=0&dow_0=on&dow_1=on&dow_2=on&dow_3=on&dow_4=on&dow_5=on&dow_6' \ '=on&holidays=on&q=flow&q2=&gn=5min&agg=on&lane1=on&lane2=on&lane3=on&lane4=on' # print(url) print('获取url: vds[%s] %s --- %s' % (str(vds), str_begin, str_end)) return urldef combine_download_data(vds, path): num = len(os.listdir(path)) dfs = pd.read_excel(path + '\\1.xlsx', index_col=None).values for i in range(2, num + 1): df = pd.read_excel(path + '\\' + str(i) + '.xlsx', index_col=None).values dfs = np.row_stack((dfs, df)) pd.DataFrame(dfs).to_csv(path + '\\' + str(vds) + '_combine.csv', index=None, header=None) print('合并文件保存成功')if __name__ == '__main__': save_path = r'G:\文档\交通数据集\加州数据集\自动下载数据' # 文件保存路径 vds_list = [602467, 602468] # 需要下载的VDS列表 start_time, end_time = '2019-01-01 00:00', '2019-01-14 23:59' # 数据下载开始于结束时间,每次下载一周,无数据则下载为空文件 for vds in vds_list: name = start_time[2:10] + '_' + end_time[2:10] save_paths = save_path + '\\' + name + '\\' + str(vds) # 创建文件保存路径 if not os.path.exists(save_paths): os.makedirs(save_paths) print('开始下载:%s %s---%s' % (str(vds), start_time, end_time)) download(save_paths, vds, start_time, end_time) # 下载文件 combine_download_data(vds, save_paths) # 将单个VDS下载文件进行合并3. 部分路网数据集(持续更新中···)
PeMS数据集:https://github.com/sttCharon/PeMS_Data