Python 使用netCDF4读写nc文件以及截取nc文件经纬度范围内的数据
简单介绍nc文件的读写操作,以及实现输入nc文件和坐标范围,输出一个新的nc文件的功能
环境
python3.8.13
netcdf4 1.5.7 py38h3de5c98_1
numpy 1.23.1 py38h7a0a035_0
读写nc文件代码
导入netCDF4和np包
import netCDF4 as ncimport numpy as np读取nc文件
# 打开文件dataset = nc.Dataset(r'H:\test.nc')# 维度print('1. Dimensions: ',dataset.dimensions)# 变量print('2. Variables: ',dataset.variables.keys())# 全局属性 ncattrs获取name getncattr获取valueprint('3. Global attribute\'s names: ', dataset.ncattrs(), '\n4. Global attribute\'s values: ', [dataset.getncattr(i) for i in dataset.ncattrs()])# 以下为输出结果,有三个维度,分别是'depth','lat','lon',十三个变量'depth', 'lat', 'lon', 'time', 'tau', 'water_u', 'water_u_bottom', 'water_v', 'water_v_bottom', 'water_temp', 'water_temp_bottom', 'salinity', 'salinity_bottom', 'surf_el'#1. Dimensions: {'depth': <class 'netCDF4._netCDF4.Dimension'>: name = 'depth', size = 40, 'lat': <class 'netCDF4._netCDF4.Dimension'>: name = 'lat', size = 1501, 'lon': <class 'netCDF4._netCDF4.Dimension'>: name = 'lon', size = 1191}#2. Variables: dict_keys(['depth', 'lat', 'lon', 'time', 'tau', 'water_u', 'water_u_bottom', 'water_v', 'water_v_bottom', 'water_temp', 'water_temp_bottom', 'salinity', 'salinity_bottom', 'surf_el'])#3. Global attribute's names: ['classification_level', 'distribution_statement', 'downgrade_date', 'classification_authority', 'institution', 'source', 'history', 'field_type', 'Conventions'] #4. Global attribute's values: ['UNCLASSIFIED', 'Approved for public release. Distribution unlimited.', 'not applicable', 'not applicable', 'Naval Oceanographic Office', 'HYCOM archive file', 'archv2ncdf3z', 'instantaneous', 'CF-1.6 NAVO_netcdf_v1.1']访问变量
单个变量
water_temp = dataset.variables['water_temp'][:]print(water_temp.shape)# 输出#(40, 1501, 1191)所有变量
# 访问所有变量for name in dataset.variables.keys(): data = dataset.variables[name][:] print(data.shape)# 输出#(40,)#(1501,)#(1191,)#()#()#(40, 1501, 1191)#(1501, 1191)#(40, 1501, 1191)#(1501, 1191)#(40, 1501, 1191)#(1501, 1191)#(40, 1501, 1191)#(1501, 1191)#(1501, 1191)访问变量的属性
for name in dataset.variables.keys():# 根据名称获取变量 var = dataset.variables[name] for attr in var.ncattrs(): # 属性名,属性值 print(attr,var.getncattr(attr))# 结果太长就不列出来了最后关闭文件
dataset.close()写入nc文件
# 创建一个新的数据集newdataset = nc.Dataset(r'H:\testout.nc','w')# 创建维度 维度名,维度长度(默认None)newdataset.createDimension('lat',10)newdataset.createDimension('lon',10)# 创建变量 变量名,数据类型(numpy中的数据类型),维度(如果不给维度,则变量是标量)lat = newdataset.createVariable('lat',np.float32,('lat'))lon = newdataset.createVariable('lon',np.float32,('lon'))water_temp = newdataset.createVariable('water_temp',np.float32,('lat','lon'))# 给变量赋值lat[:] = np.arange(10)lon[:] = np.arange(10)water_temp[:] = np.arange(10 * 10).reshape(10,10)newdataset.close()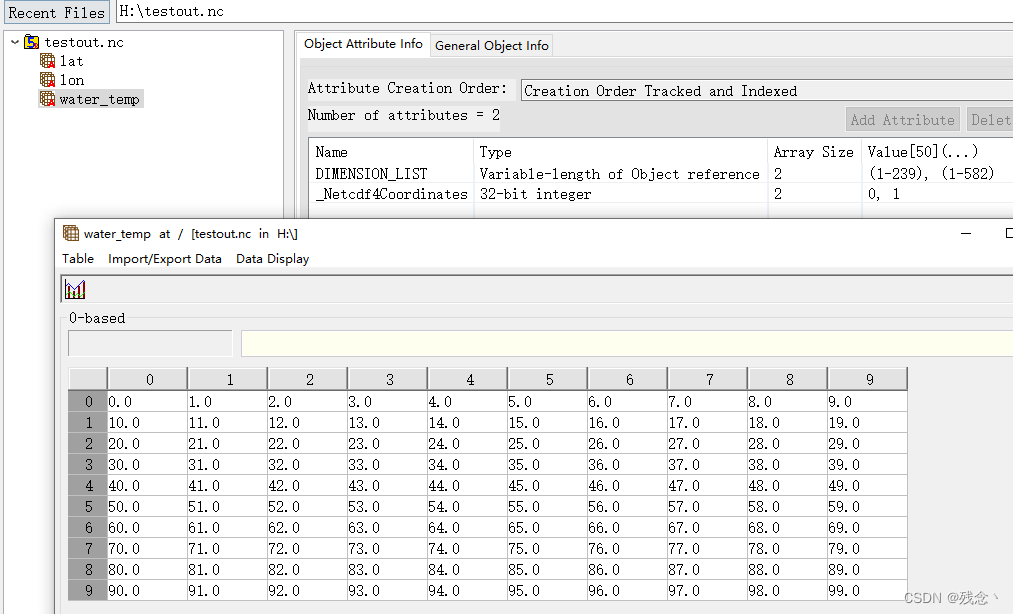
截取目标区域的数据生成新的nc文件
导入包
import netCDF4 as ncimport numpy as np打开已有的nc文件,并且读取出全局属性,变量名称,维度信息
filename = r'H:\test.nc'dataset = nc.Dataset(filename)# 定义需要的经纬度范围extent = [18.,27.,121.,135.]# 全局属性存入global_attrs_dict中global_attrs = dataset.ncattrs()global_attrs_dict = {}for attr in global_attrs: print(attr,dataset.getncattr(attr)) global_attrs_dict[attr] = dataset.getncattr(attr)# 根据经纬度大小,获取索引范围x1,x2,y1,y2old_lat = dataset.variables['lat'][:]old_lon = dataset.variables['lon'][:]x1 = np.searchsorted(old_lat,extent[0]) + 1x2 = np.searchsorted(old_lat,extent[1])y1 = np.searchsorted(old_lon,extent[2]) + 1y2 = np.searchsorted(old_lon,extent[3])# 新的经纬度new_lat = old_lat[x1:x2]new_lon = old_lon[y1:y2]# 获取维度信息dims = dataset.dimensions# 获取变量名列表variables_list = list(dataset.variables.keys())新建nc文件,写入维度,全局属性,变量属性以及数据
# 新建一个nc文件newfilename = r'H:\output.nc'newdataset = nc.Dataset(newfilename,'w')# 创建维度for item in dims.items(): size = item[1].size if item[1].name == 'lat': size = len(new_lat) if item[1].name == 'lon': size = len(new_lon) newdataset.createDimension(item[1].name, size)# 设置新nc文件的全局属性newdataset.setncatts(global_attrs_dict)# 写入裁剪后的数据for varname in variables_list: print('current variable: %s' % varname) var = dataset.variables[varname] # 创建变量 newdataset.createVariable(varname,var.dtype,var.dimensions) # 获取变量属性 var_attr_dict = {} for attr in var.ncattrs(): var_attr_dict[attr] = var.getncattr(attr) newvar = newdataset.variables[varname] # 写入变量属性 newvar.setncatts(var_attr_dict) # 获取维度信息 dims_name_list = list(newvar.dimensions) # 若有经度或维度,则需要进行截取 if 'lon' in dims_name_list or 'lat' in dims_name_list: # 1维数据 if len(dims_name_list) == 1: if 'lon' in dims_name_list: newvar[:] = var[:][y1:y2] elif 'lat' in dims_name_list: newvar[:] = var[:][x1:x2] # 2维数据 elif len(dims_name_list) == 2: newvar[:] = var[:][x1:x2,y1:y2] # 3维数据 elif len(dims_name_list) == 3: newvar[:] = var[:][:,x1:x2,y1:y2] else: # 数据中只有三维及以下数据,因此不处理超过三维的数据 raise ValueError('variable %s\'s dimension > 3.' %varname) # 无经纬度,不需要截取数据 else: newvar[:] = var[:]# 关闭文件newdataset.close()dataset.close()参考
netCDF4 API 文档