目录
数据预处理
去除停用词
构建LDA模型
可视化——pyLDAvis
主题个数确认
困惑度计算
一致性得分
数据预处理
该步骤可自行处理,用excel也好,用python也罢,只要将待分析文本处理为csv或txt存储格式即可。注意:一条文本占一行
例如感想.txt:
我喜欢吃汉堡
小明喜欢吃螺蛳粉
螺蛳粉外卖好贵
以上句子来源于吃完一个汉堡还想再点碗螺蛳粉,但外卖好贵从而选择放弃的我
去除停用词
import reimport jieba as jbdef stopwordslist(filepath): stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()] return stopwords# 对句子进行分词def seg_sentence(sentence): sentence = re.sub(u'[0-9\.]+', u'', sentence) #jb.add_word('词汇')# 这里是加入自定义的词来补充jieba词典 sentence_seged = jb.cut(sentence.strip()) stopwords = stopwordslist('自己搜来的停用词表.txt') # 这里加载停用词的路径 outstr = '' for word in sentence_seged: if word not in stopwords and word.__len__()>1: if word != '\t': outstr += word outstr += " " return outstrinputs = open('感想.txt', 'r', encoding='utf-8')outputs = open('感想分词.txt', 'w',encoding='utf-8')for line in inputs: line_seg = seg_sentence(line) # 这里的返回值是字符串 outputs.write(line_seg + '\n')outputs.close()inputs.close()该步骤生成感想分词.txt:
我 喜欢 吃 汉堡
小明 喜欢 吃 螺蛳粉
螺蛳粉 外卖 好贵
句子 来源于 吃完 一个 汉堡 再点碗 螺蛳粉 外卖 好贵 选择 放弃
构建LDA模型
假设主题个数设为4个(num_topics的参数)
import codecsfrom gensim import corporafrom gensim.models import LdaModelfrom gensim.corpora import Dictionarytrain = []fp = codecs.open('感想分词.txt','r',encoding='utf8')for line in fp: if line != '': line = line.split() train.append([w for w in line])dictionary = corpora.Dictionary(train)corpus = [dictionary.doc2bow(text) for text in train]lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=4, passes=100)# num_topics:主题数目# passes:训练伦次# num_words:每个主题下输出的term的数目for topic in lda.print_topics(num_words = 20): termNumber = topic[0] print(topic[0], ':', sep='') listOfTerms = topic[1].split('+') for term in listOfTerms: listItems = term.split('*') print(' ', listItems[1], '(', listItems[0], ')', sep='')可视化——pyLDAvis
import pyLDAvis.gensim_models'''插入之前的代码片段'''import codecsfrom gensim import corporafrom gensim.models import LdaModelfrom gensim.corpora import Dictionarytrain = []fp = codecs.open('感想分词.txt','r',encoding='utf8')for line in fp: if line != '': line = line.split() train.append([w for w in line])dictionary = corpora.Dictionary(train)corpus = [dictionary.doc2bow(text) for text in train]lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=4, passes=100)# num_topics:主题数目# passes:训练伦次# num_words:每个主题下输出的term的数目for topic in lda.print_topics(num_words = 20): termNumber = topic[0] print(topic[0], ':', sep='') listOfTerms = topic[1].split('+') for term in listOfTerms: listItems = term.split('*') print(' ', listItems[1], '(', listItems[0], ')', sep='') d=pyLDAvis.gensim_models.prepare(lda, corpus, dictionary)'''lda: 计算好的话题模型corpus: 文档词频矩阵dictionary: 词语空间'''#pyLDAvis.show(d)#展示在浏览器# pyLDAvis.displace(d) #展示在notebook的output cell中pyLDAvis.save_html(d, 'lda_pass4.html')这样就会生成看起来很炫酷的图啦(只是示例):

主题个数确认
计算不同参数下结果的 Perlexity(困惑度)和 Coherence score(一致性评分),选择困惑度最低且一致性评分最高的参数值作为最终参数设定。
困惑度计算
import gensimfrom gensim import corpora, modelsimport matplotlib.pyplot as pltimport matplotlibfrom nltk.tokenize import RegexpTokenizerfrom nltk.stem.porter import PorterStemmer # 准备数据PATH = "感想分词.txt" #已经进行了分词的文档(如何分词前面的文章有介绍) file_object2=open(PATH,encoding = 'utf-8',errors = 'ignore').read().split('\n') data_set=[] #建立存储分词的列表for i in range(len(file_object2)): result=[] seg_list = file_object2[i].split() #读取没一行文本 for w in seg_list :#读取每一行分词 result.append(w) data_set.append(result)print(data_set) #输出所有分词列表 dictionary = corpora.Dictionary(data_set) # 构建 document-term matrixcorpus = [dictionary.doc2bow(text) for text in data_set]Lda = gensim.models.ldamodel.LdaModel # 创建LDA对象 #计算困惑度def perplexity(num_topics): ldamodel = Lda(corpus, num_topics=num_topics, id2word = dictionary, passes=50) #passes为迭代次数,次数越多越精准 print(ldamodel.print_topics(num_topics=num_topics, num_words=20)) #num_words为每个主题下的词语数量 print(ldamodel.log_perplexity(corpus)) return ldamodel.log_perplexity(corpus) # 绘制困惑度折线图x = range(1,20) #主题范围数量y = [perplexity(i) for i in x]plt.plot(x, y)plt.xlabel('主题数目')plt.ylabel('困惑度大小')plt.rcParams['font.sans-serif']=['SimHei']matplotlib.rcParams['axes.unicode_minus']=Falseplt.title('主题-困惑度变化情况')plt.show()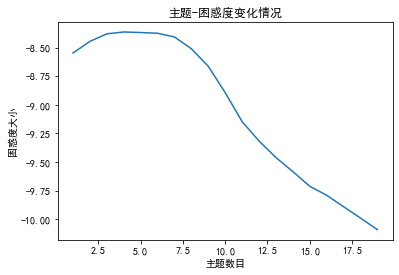
一致性得分
import gensimfrom gensim import corpora, modelsimport matplotlib.pyplot as pltimport matplotlibfrom nltk.tokenize import RegexpTokenizerfrom nltk.stem.porter import PorterStemmerimport gensimimport gensim.corpora as corporafrom gensim.utils import simple_preprocessfrom gensim.models import CoherenceModel # 准备数据PATH = "感想分词.txt" #已经进行了分词的文档(如何分词前面的文章有介绍) file_object2=open(PATH,encoding = 'utf-8',errors = 'ignore').read().split('\n') data_set=[] #建立存储分词的列表for i in range(len(file_object2)): result=[] seg_list = file_object2[i].split() #读取没一行文本 for w in seg_list :#读取每一行分词 result.append(w) data_set.append(result)print(data_set) #输出所有分词列表 dictionary = corpora.Dictionary(data_set) # 构建 document-term matrixcorpus = [dictionary.doc2bow(text) for text in data_set]Lda = gensim.models.ldamodel.LdaModel # 创建LDA对象 def coherence(num_topics): ldamodel = Lda(corpus, num_topics=num_topics, id2word = dictionary, passes=50) #passes为迭代次数,次数越多越精准 coherence_model_lda = CoherenceModel(model=ldamodel, texts=data_set, dictionary=dictionary, coherence='c_v') coherence_lda = coherence_model_lda.get_coherence() print('\nCoherence Score: ', coherence_lda) return coherence_lda # 绘制困惑度折线图x = range(1,20) #主题范围数量y = [coherence(i) for i in x]plt.plot(x,y)plt.xlabel('主题数目')plt.ylabel('coherence大小')plt.rcParams['font.sans-serif']=['SimHei']matplotlib.rcParams['axes.unicode_minus']=Falseplt.title('主题-coherence变化情况')plt.show()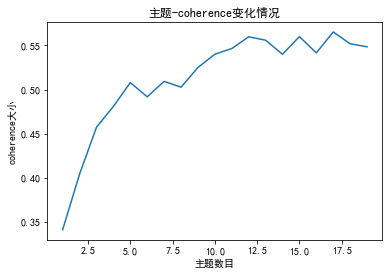
结语
整个流程就大致是这样啦!有问题欢迎一起交流!!
