文章目录
:star:BF算法代码实现BF的改进思路 :star:KMP算法?next数组?代码实现优化next数组最终代码
⭐️BF算法
BF算法,即暴力(Brute Force)算法,是普通的模式匹配算法,BF算法的思想就是将主串S的第一个字符与模式串P的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。BF算法是一种蛮力算法。
代码实现
int BF(const char* S, const char* P){assert(S && P);int i = 0;int j = 0;int lenS = strlen(S);int lenP = strlen(P);while (i < lenS && j < lenP){if (S[i] == P[j]){i++;j++;}else{i = i - j + 1;j = 0;}}if (j >= lenP){return i - j;}return -1;}return -1;}BF的改进思路
在最坏的情况下,模式串只有最后一个字符和主串不一样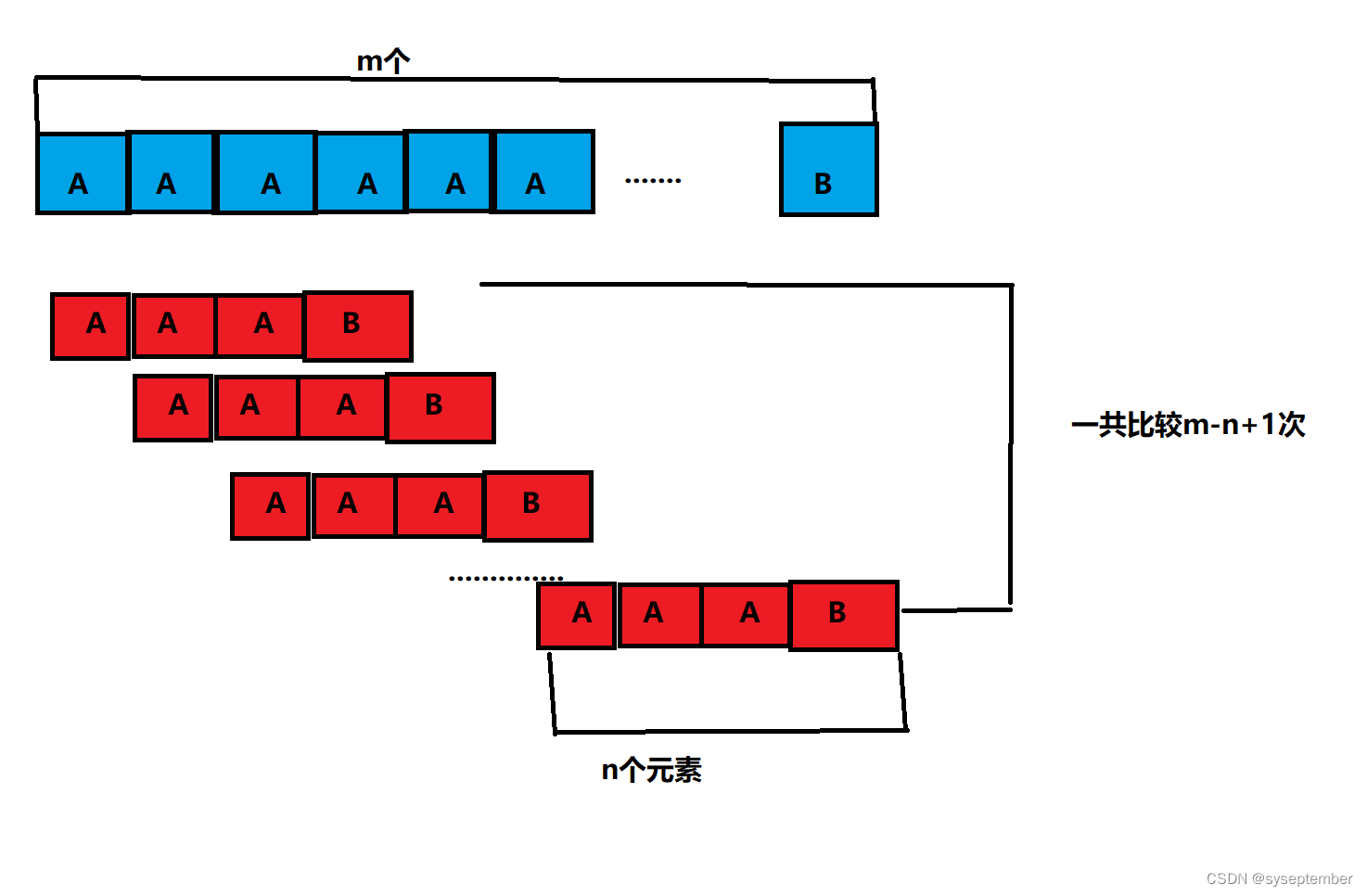
BF最坏的情况时间复杂度是O(mn),效率太低了
我们很难降低字符串比较的复杂度(因为比较两个字符串,真的只能逐个比较字符)。因此,我们考虑降低比较的趟数。如果比较的趟数能降到足够低,那么总的复杂度也将会下降很多。要优化一个算法,首先要回答的问题是“我手上有什么信息?” 我们手上的信息是否足够、是否有效,决定了我们能把算法优化到何种程度。请记住:尽可能利用残余的信息,是KMP算法的思想所在。
⭐️KMP算法
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。KMP算法的时间复杂度O(m+n)
区别:KMP 和 BF 唯一不一样的地方在,主串的 str1 并不会回退,并且 str2 也不会移动到 0 号位置,而是移动到某一个特别位置
上面概念有点抽象,我们举一个具体例子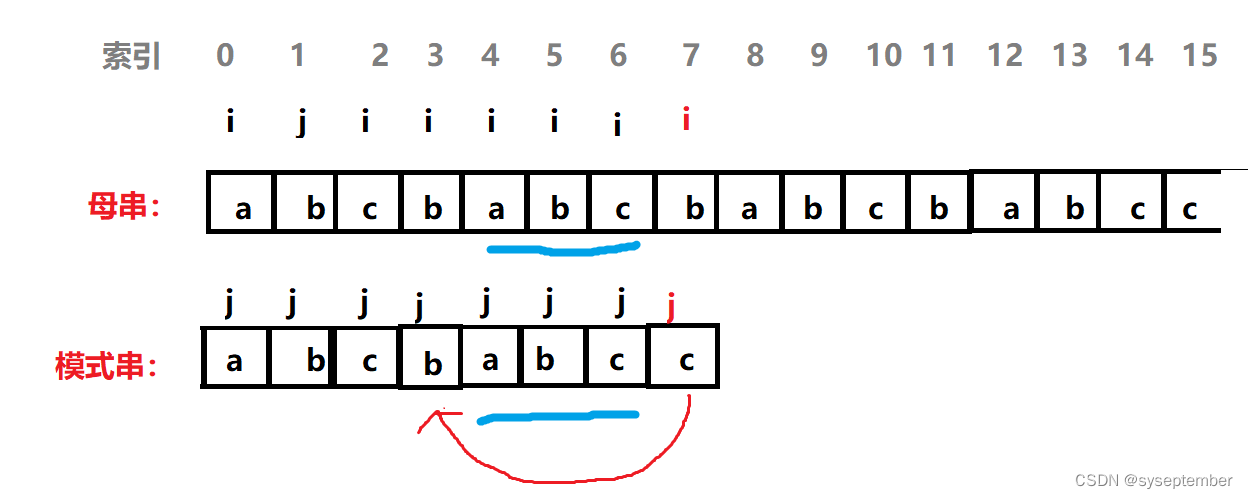
请记住:KMP算法和BF算法不同的是BF中发现匹配失败str1会回退到前一个位置的下一个位置,str2回退到模式串起始位置,KMP匹配失败后str1(i)不回退,str2(j)回退到某一个位置,这个位置可能是模式串的起始位置,也可能不是起始位置。
如果j想回退到某一个位置,这个位置应该满足这几个条件
第二个原因是因为i是不动的,所以接下来想要从移动后的j继续向后匹配的前提就是i前面k个字符和移动后的j前面k个字符完全相同
我们将最终目的是寻找j的回退位置,现在我们已经知道了回退位置所需要满足的条件,根据第2个条件,我们可以推出j回退的位置前面k个字符和j回退前的k个字符相等
这是因为j回退后位置的前k个字符和i前k个字符相等,而i位置的前k个字符右和j回退前的前k个字符相等(因为i和j所指的位置前面全部是匹配的),所以我们能推出j回退后的位置前面k个字符与j回退前的位置前面k个字符相同(非常重要!!!我们就是通过这个条件来找到j的回退位置)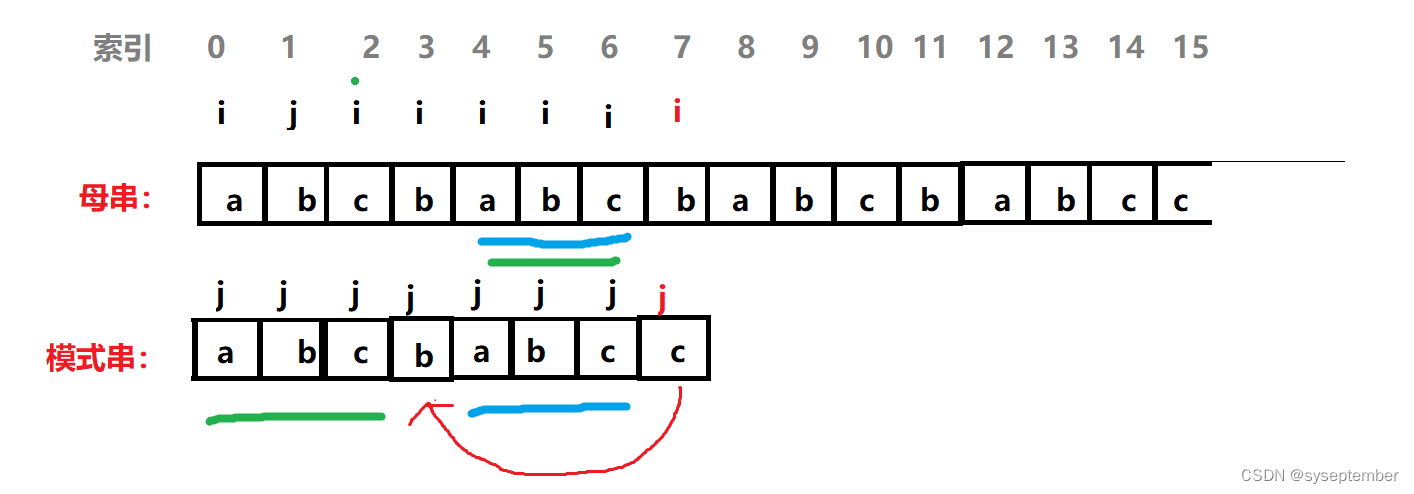
目前为止,我们将寻找j的回退位置这个问题转化成了一个寻找某个位置,这个位置前面k个字符和j回退前位置的前k个字符相等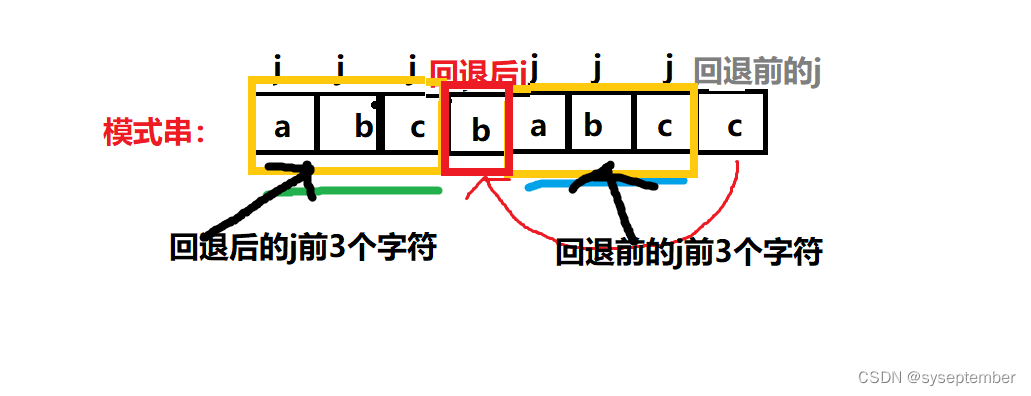
接下来,我们引入next数组,通过next数组我们就能知道j到底要回到到什么位置,请继续往下看
?next数组?
KMP 的精髓就是 next 数组:也就是用 next[j] = k;来表示,每一个模式串中的j对应一个 K 值,K就是j移动后的位置(next数组对应的是模式串,每一个模式串都有自己的next数组,并且next数组的元素个数等于模式串的长度)
如下是对next数组的定义
next[0]一定是-1,next[1]一定是0对于next[j],j>=2时,next[j]的值就是 模式串中下标为j的元素前面的k个元素与模式串中下标为0的元素后面k个元素完全相等的最大k值举例:
例如对于模式串"abcbabcc"
它的next数组是{-1, 0, 0, 0, 0, 1, 2, 3}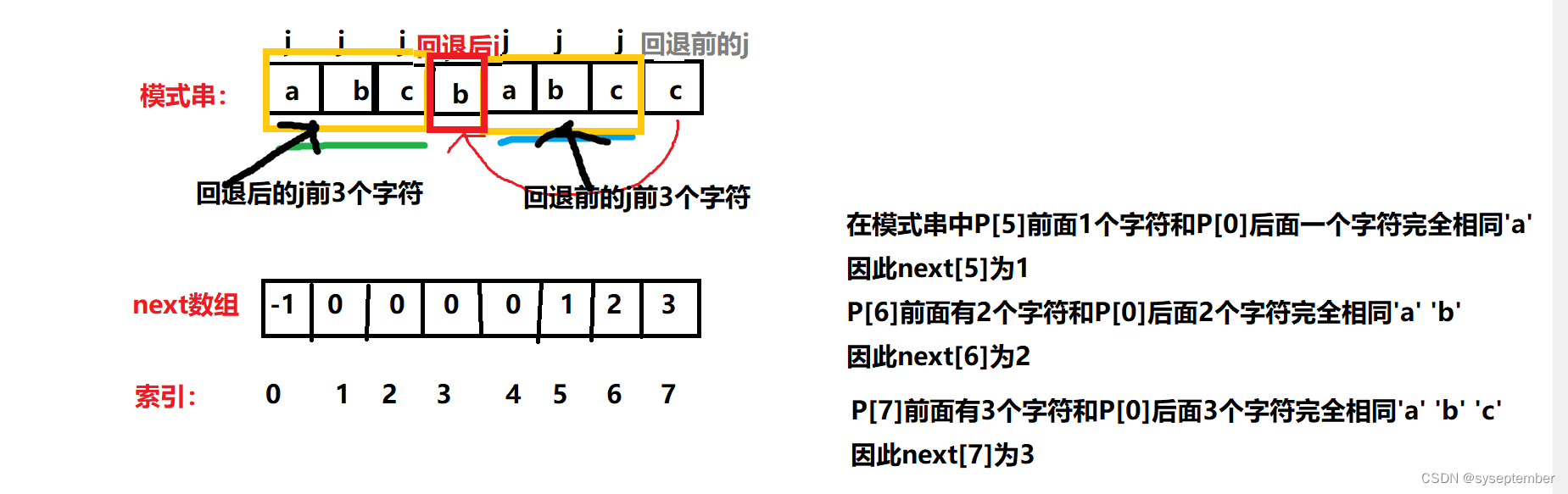
next数组的作用
若i与j的位置不匹配,则j直接返回到next[j]的位置(再次判断i和j的位置是否匹配,仍然不匹配,继续退回到next[j]),因为根据next数组的定义,next[j]的值就是P[j]前k个元素与P[0]后k个元素相等的最大k值,而j返回到k的位置恰好可以保证此时j前面的k个元素和i前面的k个元素完全相同!!!
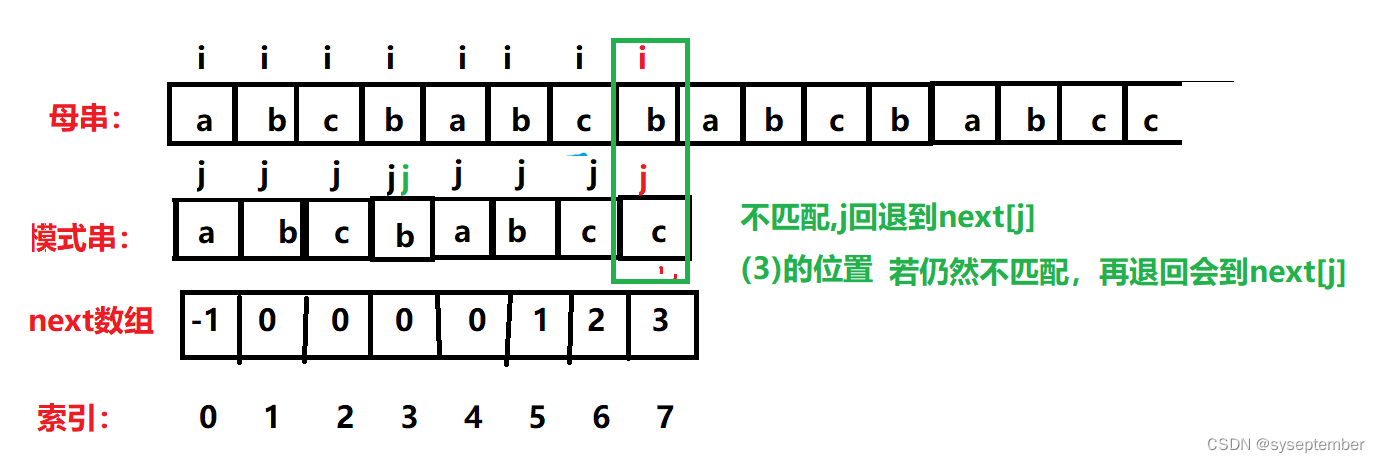
?next数组练习
练习 1: 举例对于”ababcabcdabcde”, 求其的 next 数组?
-1 0 0 1 2 0 1 2 0 0 1 2 0 0
练习 2: 再对”abcabcabcabcdabcde”,求其的 next 数组? "
-1 0 0 0 1 2 3 4 5 6 7 8 9 0 1 2 3 0
我们可以发现以下规律,如果next数组的值要增加,那么只能在之前的值上增加1,如果next数组的值要减小,可以一次减少多个数
?看到这里,我们来理一下我们的思路,首先:KMP算法和BF的算法本质就是KMP发现匹配失败后i的值不变,j回退到某一个位置;其次:我们分析了回退的位置需要满足一个条件(j回退后的位置前面k个字符和j回退前的k个字符相等)才有可能继续与主串匹配;现在:我们根据回退的位置需要满足的条件引出了next数组(next[j]的值就是模式串与主串补不匹配后j退回的位置),我们接下来要做的就是通过代码求出next数组,一但我们求出了next数组,我们就可以知道j回退的位置具体是哪里了j
?next数组的求解?
我们手写next数组很容易,因为我们用眼睛可以观察出P[j]前面K个元素和P[0]后面K个元素相同的最大K值,但是计算机无法观察出来,因此我们需要寻找规律
由next数组练习我们可以发现以下规律:如果next数组的值要增加,那么只能在之前的值上增加1,如果next数组的值要减小,可以一次减少多个数
证明如果要next数组的值要增加,只能在前一个的值上增加1反证法证明:假设next[i]==k,next[j]==k+2(j>i并且中间没有元素等于k+1)
由next数组定义可知P[0]~P[k-1]==P[j-k]~P[j-1],P[0]~P[k+1]==P[j-k-2]~P[j+1],
则一定有P[k]==P[j],于是有P[0]~P[k]==P[j-k]~P[j]这说明了i和j中间一定有元素P[m]==k+1
与假设矛盾,因此推出如果next数组的值要增加,那么只能在之前的值上增加1如果要next数组的值要减少,可以减少多个数这点毋庸置疑,无需证明
求解next数组还差最后一步,什么时候next数组的值要增加呢?
由前面的例子可知: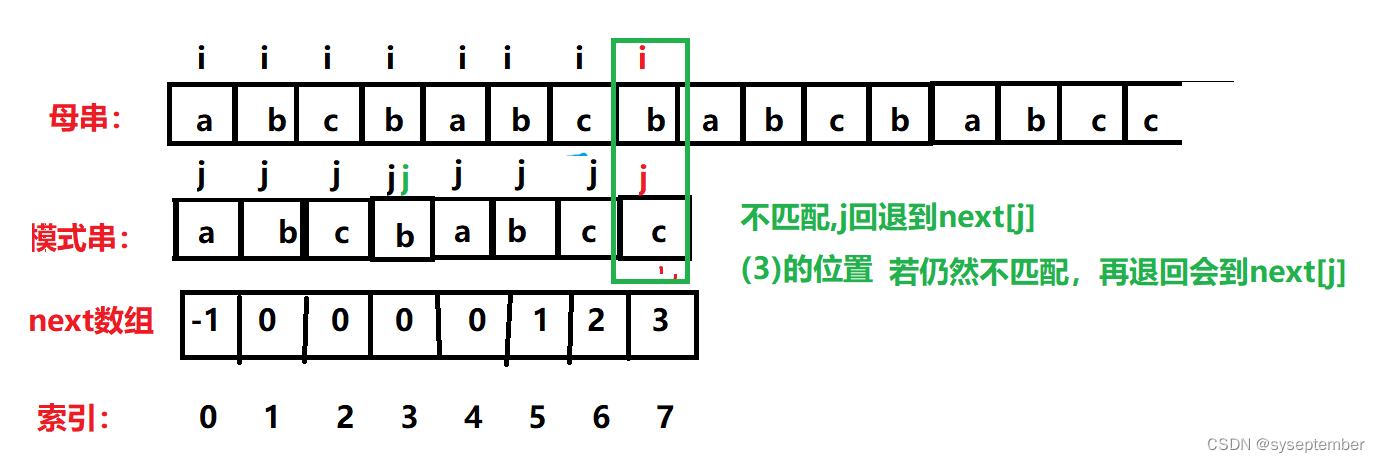
假设next[j]==k,可以推出P[0]~P[k-1]==P[j-k]~P[j-1],
如果想让next[j+1]==k,则需要满足P[0]~P[k]==P[j+1-k]~P[j],只需要在已知条件加上P[k]==P[j]
所以当P[j]==P[k]时,next[j+1]==k+1
如果P[j]!=P[k],我们就让new_k=next[k],再来判断P[j]是否等于P[new_k],如果相等P[j+1]==new_k+1
至此,我们就已经求出next数组中所有的值了
实现next数组
void GetNext(int* next, const char* P, size_t lenP){assert(next && P);if (lenP == 0)return;next[0] = -1;next[1] = 0;int j = 2;//下一项int k = 0;//前一项的kwhile (j < lenP)//next数组为遍历完{//k有可能回退到起始位置if (k == -1 || P[j - 1] == P[k]){next[j] = k + 1;j++;k++;}else{k = next[k];}}}?理清思路
在发现主串与模式串匹配失败后,我们将j回退到某一个位置,这个位置由next[j]的值决定,因为next[j]存放的就是P[0]后面k个元素和P[j]前面k个元素完全相同的最大k值,回到下标为k的位置可以保证此时j的前面刚好有k个元素和i前面的k个元素相匹配,一步退到失配后最有可能匹配成功的地方(KMP算法只退到可能匹配成功的地方),不需要像BF算法在一次失配后接着试剩下的所有位置会不会成功通过分析,我们得知了next数组得求值方法,当P[j]==P[k] (k==next[j]),next[j+1]==k+1当P[j]!=P[k]时,另k==next[k]直到P[j]==P[k]
代码实现
void GetNext(int* next, const char* P, size_t lenP){assert(next && P);next[0] = -1;next[1] = 0;size_t j = 2;//下一项size_t k = 0;//前一项的kwhile (j < lenP)//next数组为遍历完{//k有可能回退到起始位置if (k == -1 || P[j - 1] == P[k]){next[j] = k + 1;j++;k++;}else{k = next[k];}}}int KMP(const char* S, const char* P){assert(S && P);int lenS = strlen(S);int lenP = strlen(P);int* next = (int*)malloc(sizeof(int) * lenP);assert(next);GetNext(next, P, lenP);int i = 0;int j = 0;while (i < lenS && j < lenP){if ((j == -1) || (S[i] == P[j])){i++;j++;}else{j = next[j];}}free(next);if (j >= lenP)return i - j;return -1;}优化next数组
将next数组优化为nextval数组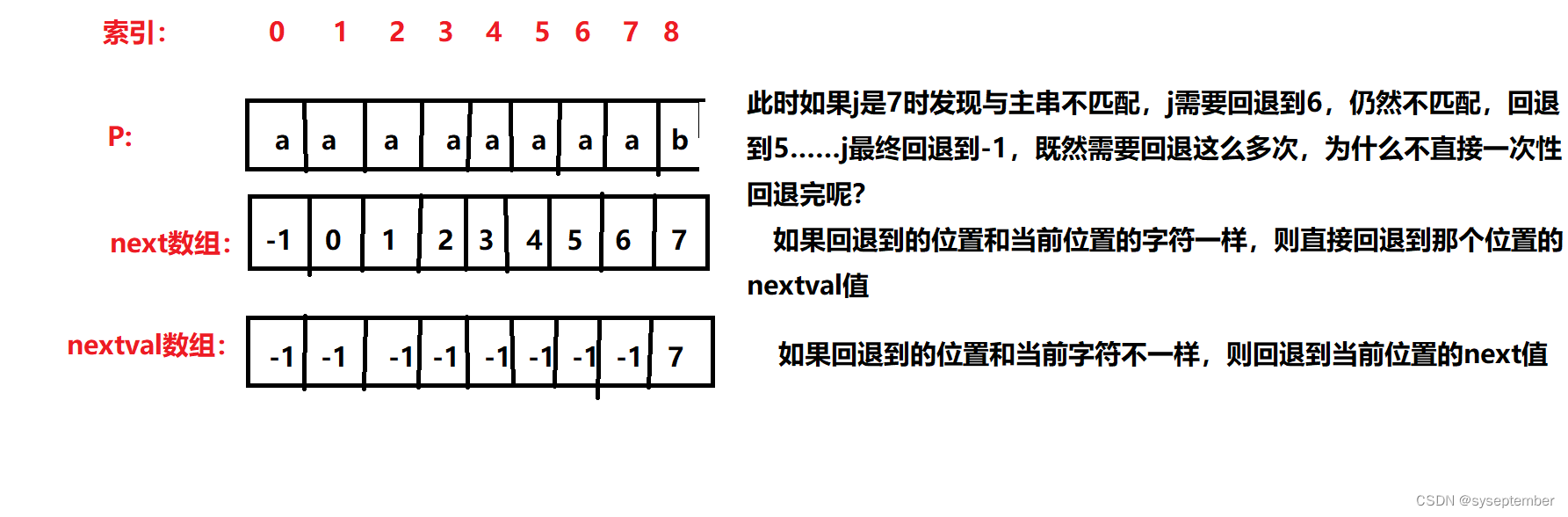
练习:
模式串 t=‘abcaabbcabcaabdab’ ,该模式串的 next 数组的值为( D ) , nextval 数组的值为 (F)
。
A. 0 1 1 1 2 2 1 1 1 2 3 4 5 6 7 1 2 B. 0 1 1 1 2 1 2 1 1 2 3 4 5 6 1 1 2
C. 0 1 1 1 0 0 1 3 1 0 1 1 0 0 7 0 1 D. 0 1 1 1 2 2 3 1 1 2 3 4 5 6 7 1 2
E. 0 1 1 0 0 1 1 1 0 1 1 0 0 1 7 0 1 F. 0 1 1 0 2 1 3 1 0 1 1 0 2 1 7 0 1
最终代码
void GetNext(int* next, const char* P, size_t lenP){assert(next && P);next[0] = -1;next[1] = 0;size_t j = 2;//下一项size_t k = 0;//前一项的kwhile (j < lenP)//next数组为遍历完{//k有可能回退到起始位置if (k == -1 || P[j - 1] == P[k]){next[j] = k + 1;j++;k++;}else{k = next[k];}}}//优化next数组void GetNextVal(int* nextVal, const int* next, const char* P){assert(nextVal && next);nextVal[0] = -1;for (size_t i = 1; i < strlen(P); i++){//回退位置的字符等于当前字符,回退到那个位置的nextVal值处if (P[i] == P[next[i]]){nextVal[i] = nextVal[next[i]];}//回退的位置的字符不等于当前字符,回退到当前位置的next值处else{nextVal[i] = next[i];}}}int KMP(const char* S, const char* P){assert(S && P);int lenS = strlen(S);int lenP = strlen(P);int* next = (int*)malloc(sizeof(int) * lenP);int* nextVal = (int*)malloc(sizeof(int) * lenP);assert(next);GetNext(next, P, lenP);GetNextVal(nextVal, next, P);int i = 0;int j = 0;while (i < lenS && j < lenP){if ((j == -1) || (S[i] == P[j])){i++;j++;}else{j = nextVal[j];}}free(next);if (j >= lenP)return i - j;return -1;}int main(){char* str = "ababcabcdabcde";char* sub = "abcd";printf("%d\n", KMP(str, sub));return 0;}至此整个KMP算法我们已经实现了,不得不承认确实很复杂,我花了2个下午才弄明白?,如果还有哪里不懂得地方,可以看看这个视频【完整版】终于有人讲清楚了KMP算法,Java语言C语言实现,一定要静下心来看!!!